




More on Science

Katherine Kornei
4 years ago
The InSight lander from NASA has recorded the greatest tremor ever felt on Mars.
The magnitude 5 earthquake was responsible for the discharge of energy that was 10 times greater than the previous record holder.
Any Martians who happen to be reading this should quickly learn how to duck and cover.
NASA's Jet Propulsion Laboratory in Pasadena, California, reported that on May 4, the planet Mars was shaken by an earthquake of around magnitude 5, making it the greatest Marsquake ever detected to this point. The shaking persisted for more than six hours and unleashed more than ten times as much energy as the earthquake that had previously held the record for strongest.
The event was captured on record by the InSight lander, which is operated by the United States Space Agency and has been researching the innards of Mars ever since it touched down on the planet in 2018 (SN: 11/26/18). The epicenter of the earthquake was probably located in the vicinity of Cerberus Fossae, which is located more than 1,000 kilometers away from the lander.
The surface of Cerberus Fossae is notorious for being broken up and experiencing periodic rockfalls. According to geophysicist Philippe Lognonné, who is the lead investigator of the Seismic Experiment for Interior Structure, the seismometer that is onboard the InSight lander, it is reasonable to assume that the ground is moving in that area. "This is an old crater from a volcanic eruption."
Marsquakes, which are similar to earthquakes in that they give information about the interior structure of our planet, can be utilized to investigate what lies beneath the surface of Mars (SN: 7/22/21). And according to Lognonné, who works at the Institut de Physique du Globe in Paris, there is a great deal that can be gleaned from analyzing this massive earthquake. Because the quality of the signal is so high, we will be able to focus on the specifics.

DANIEL CLERY
3 years ago
Can space-based solar power solve Earth's energy problems?
Better technology and lower launch costs revive science-fiction tech.
Airbus engineers showed off sustainable energy's future in Munich last month. They captured sunlight with solar panels, turned it into microwaves, and beamed it into an airplane hangar, where it lighted a city model. The test delivered 2 kW across 36 meters, but it posed a serious question: Should we send enormous satellites to capture solar energy in space? In orbit, free of clouds and nighttime, they could create power 24/7 and send it to Earth.
Airbus engineer Jean-Dominique Coste calls it an engineering problem. “But it’s never been done at [large] scale.”
Proponents of space solar power say the demand for green energy, cheaper space access, and improved technology might change that. Once someone invests commercially, it will grow. Former NASA researcher John Mankins says it might be a trillion-dollar industry.
Myriad uncertainties remain, including whether beaming gigawatts of power to Earth can be done efficiently and without burning birds or people. Concept papers are being replaced with ground and space testing. The European Space Agency (ESA), which supported the Munich demo, will propose ground tests to member nations next month. The U.K. government offered £6 million to evaluate innovations this year. Chinese, Japanese, South Korean, and U.S. agencies are working. NASA policy analyst Nikolai Joseph, author of an upcoming assessment, thinks the conversation's tone has altered. What formerly appeared unattainable may now be a matter of "bringing it all together"
NASA studied space solar power during the mid-1970s fuel crunch. A projected space demonstration trip using 1970s technology would have cost $1 trillion. According to Mankins, the idea is taboo in the agency.
Space and solar power technology have evolved. Photovoltaic (PV) solar cell efficiency has increased 25% over the past decade, Jones claims. Telecoms use microwave transmitters and receivers. Robots designed to repair and refuel spacecraft might create solar panels.
Falling launch costs have boosted the idea. A solar power satellite large enough to replace a nuclear or coal plant would require hundreds of launches. ESA scientist Sanjay Vijendran: "It would require a massive construction complex in orbit."
SpaceX has made the idea more plausible. A SpaceX Falcon 9 rocket costs $2600 per kilogram, less than 5% of what the Space Shuttle did, and the company promised $10 per kilogram for its giant Starship, slated to launch this year. Jones: "It changes the equation." "Economics rules"
Mass production reduces space hardware costs. Satellites are one-offs made with pricey space-rated parts. Mars rover Perseverance cost $2 million per kilogram. SpaceX's Starlink satellites cost less than $1000 per kilogram. This strategy may work for massive space buildings consisting of many identical low-cost components, Mankins has long contended. Low-cost launches and "hypermodularity" make space solar power economical, he claims.
Better engineering can improve economics. Coste says Airbus's Munich trial was 5% efficient, comparing solar input to electricity production. When the Sun shines, ground-based solar arrays perform better. Studies show space solar might compete with existing energy sources on price if it reaches 20% efficiency.
Lighter parts reduce costs. "Sandwich panels" with PV cells on one side, electronics in the middle, and a microwave transmitter on the other could help. Thousands of them build a solar satellite without heavy wiring to move power. In 2020, a team from the U.S. Naval Research Laboratory (NRL) flew on the Air Force's X-37B space plane.
NRL project head Paul Jaffe said the satellite is still providing data. The panel converts solar power into microwaves at 8% efficiency, but not to Earth. The Air Force expects to test a beaming sandwich panel next year. MIT will launch its prototype panel with SpaceX in December.
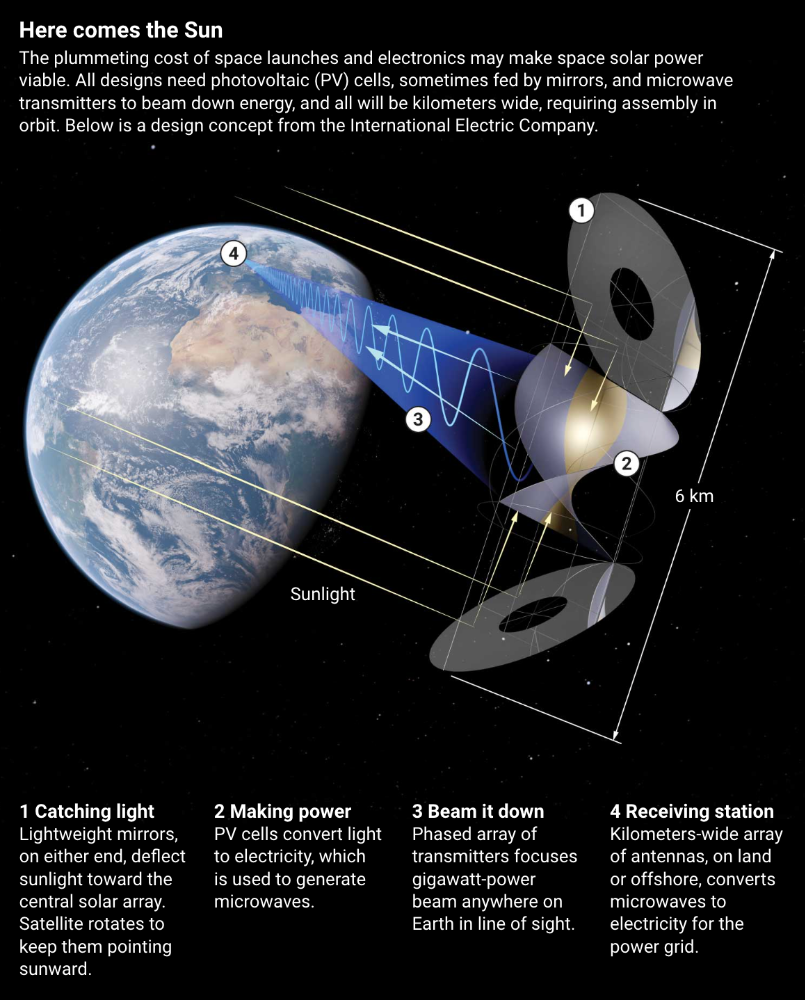
As a satellite orbits, the PV side of sandwich panels sometimes faces away from the Sun since the microwave side must always face Earth. To maintain 24-hour power, a satellite needs mirrors to keep that side illuminated and focus light on the PV. In a 2012 NASA study by Mankins, a bowl-shaped device with thousands of thin-film mirrors focuses light onto the PV array.
International Electric Company's Ian Cash has a new strategy. His proposed satellite uses enormous, fixed mirrors to redirect light onto a PV and microwave array while the structure spins (see graphic, above). 1 billion minuscule perpendicular antennas act as a "phased array" to electronically guide the beam toward Earth, regardless of the satellite's orientation. This design, argues Cash, is "the most competitive economically"
If a space-based power plant ever flies, its power must be delivered securely and efficiently. Jaffe's team at NRL just beamed 1.6 kW over 1 km, and teams in Japan, China, and South Korea have comparable attempts. Transmitters and receivers lose half their input power. Vijendran says space solar beaming needs 75% efficiency, "preferably 90%."
Beaming gigawatts through the atmosphere demands testing. Most designs aim to produce a beam kilometers wide so every ship, plane, human, or bird that strays into it only receives a tiny—hopefully harmless—portion of the 2-gigawatt transmission. Receiving antennas are cheap to build but require a lot of land, adds Jones. You could grow crops under them or place them offshore.
Europe's public agencies currently prioritize space solar power. Jones: "There's a devotion you don't see in the U.S." ESA commissioned two solar cost/benefit studies last year. Vijendran claims it might match ground-based renewables' cost. Even at a higher price, equivalent to nuclear, its 24/7 availability would make it competitive.
ESA will urge member states in November to fund a technical assessment. If the news is good, the agency will plan for 2025. With €15 billion to €20 billion, ESA may launch a megawatt-scale demonstration facility by 2030 and a gigawatt-scale facility by 2040. "Moonshot"

Michael Hunter, MD
3 years ago
5 Drugs That May Increase Your Risk of Dementia

While our genes can't be changed easily, you can avoid some dementia risk factors. Today we discuss dementia and five drugs that may increase risk.
Memory loss appears to come with age, but we're not talking about forgetfulness. Sometimes losing your car keys isn't an indication of dementia. Dementia impairs the capacity to think, remember, or make judgments. Dementia hinders daily tasks.
Alzheimers is the most common dementia. Dementia is not normal aging, unlike forgetfulness. Aging increases the risk of Alzheimer's and other dementias. A family history of the illness increases your risk, according to the Mayo Clinic (USA).
Given that our genes are difficult to change (I won't get into epigenetics), what are some avoidable dementia risk factors? Certain drugs may cause cognitive deterioration.
Today we look at four drugs that may cause cognitive decline.
Dementia and benzodiazepines
Benzodiazepine sedatives increase brain GABA levels. Example benzodiazepines:
Diazepam (Valium) (Valium)
Alprazolam (Xanax) (Xanax)
Clonazepam (Klonopin) (Klonopin)
Addiction and overdose are benzodiazepine risks. Yes! These medications don't raise dementia risk.
USC study: Benzodiazepines don't increase dementia risk in older adults.
Benzodiazepines can produce short- and long-term amnesia. This memory loss hinders memory formation. Extreme cases can permanently impair learning and memory. Anterograde amnesia is uncommon.
2. Statins and dementia
Statins reduce cholesterol. They prevent a cholesterol-making chemical. Examples:
Atorvastatin (Lipitor) (Lipitor)
Fluvastatin (Lescol XL) (Lescol XL)
Lovastatin (Altoprev) (Altoprev)
Pitavastatin (Livalo, Zypitamag) (Livalo, Zypitamag)
Pravastatin (Pravachol) (Pravachol)
Rosuvastatin (Crestor, Ezallor) (Crestor, Ezallor)
Simvastatin (Zocor) (Zocor)
This finding is contentious. Harvard's Brigham and Womens Hospital's Dr. Joann Manson says:
“I think that the relationship between statins and cognitive function remains controversial. There’s still not a clear conclusion whether they help to prevent dementia or Alzheimer’s disease, have neutral effects, or increase risk.”
This one's off the dementia list.
3. Dementia and anticholinergic drugs
Anticholinergic drugs treat many conditions, including urine incontinence. Drugs inhibit acetylcholine (a brain chemical that helps send messages between cells). Acetylcholine blockers cause drowsiness, disorientation, and memory loss.
First-generation antihistamines, tricyclic antidepressants, and overactive bladder antimuscarinics are common anticholinergics among the elderly.
Anticholinergic drugs may cause dementia. One study found that taking anticholinergics for three years or more increased the risk of dementia by 1.54 times compared to three months or less. After stopping the medicine, the danger may continue.
4. Drugs for Parkinson's disease and dementia
Cleveland Clinic (USA) on Parkinson's:
Parkinson's disease causes age-related brain degeneration. It causes delayed movements, tremors, and balance issues. Some are inherited, but most are unknown. There are various treatment options, but no cure.
Parkinson's medications can cause memory loss, confusion, delusions, and obsessive behaviors. The drug's effects on dopamine cause these issues.
A 2019 JAMA Internal Medicine study found powerful anticholinergic medications enhance dementia risk.
Those who took anticholinergics had a 1.5 times higher chance of dementia. Individuals taking antidepressants, antipsychotic drugs, anti-Parkinson’s drugs, overactive bladder drugs, and anti-epileptic drugs had the greatest risk of dementia.
Anticholinergic medicines can lessen Parkinson's-related tremors, but they slow cognitive ability. Anticholinergics can cause disorientation and hallucinations in those over 70.
5. Antiepileptic drugs and dementia
The risk of dementia from anti-seizure drugs varies with drugs. Levetiracetam (Keppra) improves Alzheimer's cognition.
One study linked different anti-seizure medications to dementia. Anti-epileptic medicines increased the risk of Alzheimer's disease by 1.15 times in the Finnish sample and 1.3 times in the German population. Depakote, Topamax are drugs.
You might also like

Will Lockett
3 years ago
The World Will Change With MIT's New Battery

It's cheaper, faster charging, longer lasting, safer, and better for the environment.
Batteries are the future. Next-gen and planet-saving technology, including solar power and EVs, require batteries. As these smart technologies become more popular, we find that our batteries can't keep up. Lithium-ion batteries are expensive, slow to charge, big, fast to decay, flammable, and not environmentally friendly. MIT just created a new battery that eliminates all of these problems. So, is this the battery of the future? Or is there a catch?
When I say entirely new, I mean it. This battery employs no currently available materials. Its electrodes are constructed of aluminium and pure sulfur instead of lithium-complicated ion's metals and graphite. Its electrolyte is formed of molten chloro-aluminate salts, not an organic solution with lithium salts like lithium-ion batteries.
How does this change in materials help?
Aluminum, sulfur, and chloro-aluminate salts are abundant, easy to acquire, and cheap. This battery might be six times cheaper than a lithium-ion battery and use less hazardous mining. The world and our wallets will benefit.
But don’t go thinking this means it lacks performance.
This battery charged in under a minute in tests. At 25 degrees Celsius, the battery will charge 25 times slower than at 110 degrees Celsius. This is because the salt, which has a very low melting point, is in an ideal state at 110 degrees and can carry a charge incredibly quickly. Unlike lithium-ion, this battery self-heats when charging and discharging, therefore no external heating is needed.
Anyone who's seen a lithium-ion battery burst might be surprised. Unlike lithium-ion batteries, none of the components in this new battery can catch fire. Thus, high-temperature charging and discharging speeds pose no concern.
These batteries are long-lasting. Lithium-ion batteries don't last long, as any iPhone owner can attest. During charging, metal forms a dendrite on the electrode. This metal spike will keep growing until it reaches the other end of the battery, short-circuiting it. This is why phone batteries only last a few years and why electric car range decreases over time. This new battery's molten salt slows deposition, extending its life. This helps the environment and our wallets.
These batteries are also energy dense. Some lithium-ion batteries have 270 Wh/kg energy density (volume and mass). Aluminum-sulfur batteries could have 1392 Wh/kg, according to calculations. They'd be 5x more energy dense. Tesla's Model 3 battery would weigh 96 kg instead of 480 kg if this battery were used. This would improve the car's efficiency and handling.
These calculations were for batteries without molten salt electrolyte. Because they don't reflect the exact battery chemistry, they aren't a surefire prediction.
This battery seems great. It will take years, maybe decades, before it reaches the market and makes a difference. Right?
Nope. The project's scientists founded Avanti to develop and market this technology.
So we'll soon be driving cheap, durable, eco-friendly, lightweight, and ultra-safe EVs? Nope.
This battery must be kept hot to keep the salt molten; otherwise, it won't work and will expand and contract, causing damage. This issue could be solved by packs that can rapidly pre-heat, but that project is far off.
Rapid and constant charge-discharge cycles make these batteries ideal for solar farms, homes, and EV charging stations. The battery is constantly being charged or discharged, allowing it to self-heat and maintain an ideal temperature.
These batteries aren't as sexy as those making EVs faster, more efficient, and cheaper. Grid batteries are crucial to our net-zero transition because they allow us to use more low-carbon energy. As we move away from fossil fuels, we'll need millions of these batteries, so the fact that they're cheap, safe, long-lasting, and environmentally friendly will be huge. Who knows, maybe EVs will use this technology one day. MIT has created another world-changing technology.

Leah
3 years ago
The Burnout Recovery Secrets Nobody Is Talking About

What works and what’s just more toxic positivity
Just keep at it; you’ll get it.
I closed the Zoom call and immediately dropped my head. Open tabs included material on inspiration, burnout, and recovery.
I searched everywhere for ways to avoid burnout.
It wasn't that I needed to keep going, change my routine, employ 8D audio playlists, or come up with fresh ideas. I had several ideas and a schedule. I knew what to do.
I wasn't interested. I kept reading, changing my self-care and mental health routines, and writing even though it was tiring.
Since burnout became a psychiatric illness in 2019, thousands have shared their experiences. It's spreading rapidly among writers.
What is the actual key to recovering from burnout?
Every A-list burnout story emphasizes prevention. Other lists provide repackaged self-care tips. More discuss mental health.
It's like the mid-2000s, when pink quotes about bubble baths saturated social media.
The self-care mania cost us all. Self-care is crucial, but utilizing it to address everything didn't work then or now.
How can you recover from burnout?
Time
Are extended breaks actually good for you? Most people need a break every 62 days or so to avoid burnout.
Real-life burnout victims all took breaks. Perhaps not a long hiatus, but breaks nonetheless.
Burnout is slow and gradual. It takes little bits of your motivation and passion at a time. Sometimes it’s so slow that you barely notice or blame it on other things like stress and poor sleep.
Burnout doesn't come overnight; neither will recovery.
I don’t care what anyone else says the cure for burnout is. It has to be time because time is what gave us all burnout in the first place.

Greg Lim
4 years ago
How I made $160,000 from non-fiction books
I've sold over 40,000 non-fiction books on Amazon and made over $160,000 in six years while writing on the side.
I have a full-time job and three young sons; I can't spend 40 hours a week writing. This article describes my journey.
I write mainly tech books:
Thanks to my readers, many wrote positive evaluations. Several are bestsellers.
A few have been adopted by universities as textbooks:
My books' passive income allows me more time with my family.
Knowing I could quit my job and write full time gave me more confidence. And I find purpose in my work (i am in christian ministry).
I'm always eager to write. When work is a dread or something bad happens, writing gives me energy. Writing isn't scary. In fact, I can’t stop myself from writing!
Writing has also established my tech authority. Universities use my books, as I've said. Traditional publishers have asked me to write books.
These mindsets helped me become a successful nonfiction author:
1. You don’t have to be an Authority
Yes, I have computer science experience. But I'm no expert on my topics. Before authoring "Beginning Node.js, Express & MongoDB," my most profitable book, I had no experience with those topics. Node was a new server-side technology for me. Would that stop me from writing a book? It can. I liked learning a new technology. So I read the top three Node books, took the top online courses, and put them into my own book (which makes me know more than 90 percent of people already).
I didn't have to worry about using too much jargon because I was learning as I wrote. An expert forgets a beginner's hardship.
"The fellow learner can aid more than the master since he knows less," says C.S. Lewis. The problem he must explain is recent. The expert has forgotten.”
2. Solve a micro-problem (Niching down)
I didn't set out to write a definitive handbook. I found a market with several challenges and wrote one book. Ex:
- Instead of web development, what about web development using Angular?
- Instead of Blockchain, what about Blockchain using Solidity and React?
- Instead of cooking recipes, how about a recipe for a specific kind of diet?
- Instead of Learning math, what about Learning Singapore Math?
3. Piggy Backing Trends
The above topics may still be a competitive market. E.g. Angular, React. To stand out, include the latest technologies or trends in your book. Learn iOS 15 instead of iOS programming. Instead of personal finance, what about personal finance with NFTs.
Even though you're a newbie author, your topic is well-known.
4. Publish short books
My books are known for being direct. Many people like this:
Your reader will appreciate you cutting out the fluff and getting to the good stuff. A reader can finish and review your book.
Second, short books are easier to write. Instead of creating a 500-page book for $50 (which few will buy), write a 100-page book that answers a subset of the problem and sell it for less. (You make less, but that's another subject). At least it got published instead of languishing. Less time spent creating a book means less time wasted if it fails. Write a small-bets book portfolio like Daniel Vassallo!
Third, it's $2.99-$9.99 on Amazon (gets 70 percent royalties for ebooks). Anything less receives 35% royalties. $9.99 books have 20,000–30,000 words. If you write more and charge more over $9.99, you get 35% royalties. Why not make it a $9.99 book?
(This is the ebook version.) Paperbacks cost more. Higher royalties allow for higher prices.
5. Validate book idea
Amazon will tell you if your book concept, title, and related phrases are popular. See? Check its best-sellers list.
150,000 is preferable. It sells 2–3 copies daily. Consider your rivals. Profitable niches have high demand and low competition.
Don't be afraid of competitive niches. First, it shows high demand. Secondly, what are the ways you can undercut the completion? Better book? Or cheaper option? There was lots of competition in my NodeJS book's area. None received 4.5 stars or more. I wrote a NodeJS book. Today, it's a best-selling Node book.
What’s Next
So long. Part II follows. Meanwhile, I will continue to write more books!
Follow my journey on Twitter.
This post is a summary. Read full article here