







More on NFTs & Art
Scott Duke Kominers
3 years ago
NFT Creators Go Creative Commons Zero (cc0)
On January 1, "Public Domain Day," thousands of creative works immediately join the public domain. The original creator or copyright holder loses exclusive rights to reproduce, adapt, or publish the work, and anybody can use it. It happens with movies, poems, music, artworks, books (where creative rights endure 70 years beyond the author's death), and sometimes source code.
Public domain creative works open the door to new uses. 400,000 sound recordings from before 1923, including Winnie-the-Pooh, were released this year. With most of A.A. Milne's 1926 Winnie-the-Pooh characters now available, we're seeing innovative interpretations Milne likely never planned. The ancient hyphenated version of the honey-loving bear is being adapted for a horror movie: "Winnie-the-Pooh: Blood and Honey"... with Pooh and Piglet as the baddies.
Counterintuitively, experimenting and recombination can occasionally increase IP value. Open source movements allow the public to build on (or fork and duplicate) existing technologies. Permissionless innovation helps Android, Linux, and other open source software projects compete. Crypto's success at attracting public development is also due to its support of open source and "remix culture," notably in NFT forums.
Production memes
NFT projects use several IP strategies to establish brands, communities, and content. Some preserve regular IP protections; others offer NFT owners the opportunity to innovate on connected IP; yet others have removed copyright and other IP safeguards.
By using the "Creative Commons Zero" (cc0) license, artists can intentionally select for "no rights reserved." This option permits anyone to benefit from derivative works without legal repercussions. There's still a lot of confusion between copyrights and NFTs, so nothing here should be considered legal, financial, tax, or investment advice. Check out this post for an overview of copyright vulnerabilities with NFTs and how authors can protect owners' rights. This article focuses on cc0.
Nouns, a 2021 project, popularized cc0 for NFTs. Others followed, including: A Common Place, Anonymice, Blitmap, Chain Runners, Cryptoadz, CryptoTeddies, Goblintown, Gradis, Loot, mfers, Mirakai, Shields, and Terrarium Club are cc0 projects.
Popular crypto artist XCOPY licensed their 1-of-1 NFT artwork "Right-click and Save As Guy" under cc0 in January, exactly one month after selling it. cc0 has spawned many derivatives.

"Right-click Save As Guy" by XCOPY (1)/derivative works (2)
XCOPY said Monday he would apply cc0 to "all his existing art." "We haven't seen a cc0 summer yet, but I think it's approaching," said the artist. - predicting a "DeFi summer" in 2020, when decentralized finance gained popularity.
Why do so many NFT authors choose "no rights"?
Promoting expansions of the original project to create a more lively and active community is one rationale. This makes sense in crypto, where many value open sharing and establishing community.
Creativity depends on cultural significance. NFTs may allow verifiable ownership of any digital asset, regardless of license, but cc0 jumpstarts "meme-ability" by actively, not passively, inviting derivative works. As new derivatives are made and shared, attention might flow back to the original, boosting its reputation. This may inspire new interpretations, leading in a flywheel effect where each derivative adds to the original's worth - similar to platform network effects, where platforms become more valuable as more users join them.
cc0 licence allows creators "seize production memes."

Physical items are also using cc0 NFT assets, thus it's not just a digital phenomenon. The Nouns Vision initiative turned the square-framed spectacles shown on each new NounsDAO NFT ("one per day, forever") into luxury sunglasses. Blitmap's pixel-art has been used on shoes, apparel, and caps. In traditional IP regimes, a single owner controls creation, licensing, and production.
The physical "blitcap" (3rd level) is a descendant of the trait in the cc0 Chain Runners collection (2nd), which uses the "logo" from cc0 Blitmap (1st)! The Logo is Blitmap token #84 and has been used as a trait in various collections. The "Dom Rose" is another popular token. These homages reference Blitmap's influence as a cc0 leader, as one of the earliest NFT projects to proclaim public domain intents. A new collection, Citizens of Tajigen, emerged last week with a Blitcap characteristic.
These derivatives can be a win-win for everyone, not just the original inventors, especially when using NFT assets to establish unique brands. As people learn about the derivative, they may become interested in the original. If you see someone wearing Nouns glasses on the street (or in a Super Bowl ad), you may desire a pair, but you may also be interested in buying an original NounsDAO NFT or related derivative.

Blitmap Logo Hat (1), Chain Runners #780 ft. Hat (2), and Blitmap Original "Logo #87" (3)
Co-creating open source
NFTs' power comes from smart contract technology's intrinsic composability. Many smart contracts can be integrated or stacked to generate richer applications.
"Money Legos" describes how decentralized finance ("DeFi") smart contracts interconnect to generate new financial use cases. Yearn communicates with MakerDAO's stablecoin $DAI and exchange liquidity provider Curve by calling public smart contract methods. NFTs and their underlying smart contracts can operate as the base-layer framework for recombining and interconnecting culture and creativity.
cc0 gives an NFT's enthusiast community authority to develop new value layers whenever, wherever, and however they wish.
Multiple cc0 projects are playable characters in HyperLoot, a Loot Project knockoff.
Open source and Linux's rise are parallels. When the internet was young, Microsoft dominated the OS market with Windows. Linux (and its developer Linus Torvalds) championed a community-first mentality, freely available the source code without restrictions. This led to developers worldwide producing new software for Linux, from web servers to databases. As people (and organizations) created world-class open source software, Linux's value proposition grew, leading to explosive development and industry innovation. According to Truelist, Linux powers 96.3% of the top 1 million web servers and 85% of smartphones.
With cc0 licensing empowering NFT community builders, one might hope for long-term innovation. Combining cc0 with NFTs "turns an antagonistic game into a co-operative one," says NounsDAO cofounder punk4156. It's important on several levels. First, decentralized systems from open source to crypto are about trust and coordination, therefore facilitating cooperation is crucial. Second, the dynamics of this cooperation work well in the context of NFTs because giving people ownership over their digital assets allows them to internalize the results of co-creation through the value that accrues to their assets and contributions, which incentivizes them to participate in co-creation in the first place.
Licensed to create
If cc0 projects are open source "applications" or "platforms," then NFT artwork, metadata, and smart contracts provide the "user interface" and the underlying blockchain (e.g., Ethereum) is the "operating system." For these apps to attain Linux-like potential, more infrastructure services must be established and made available so people may take advantage of cc0's remixing capabilities.
These services are developing. Zora protocol and OpenSea's open source Seaport protocol enable open, permissionless NFT marketplaces. A pixel-art-rendering engine was just published on-chain to the Ethereum blockchain and integrated into OKPC and ICE64. Each application improves blockchain's "out-of-the-box" capabilities, leading to new apps created from the improved building blocks.
Web3 developer growth is at an all-time high, yet it's still a small fraction of active software developers globally. As additional developers enter the field, prospective NFT projects may find more creative and infrastructure Legos for cc0 and beyond.
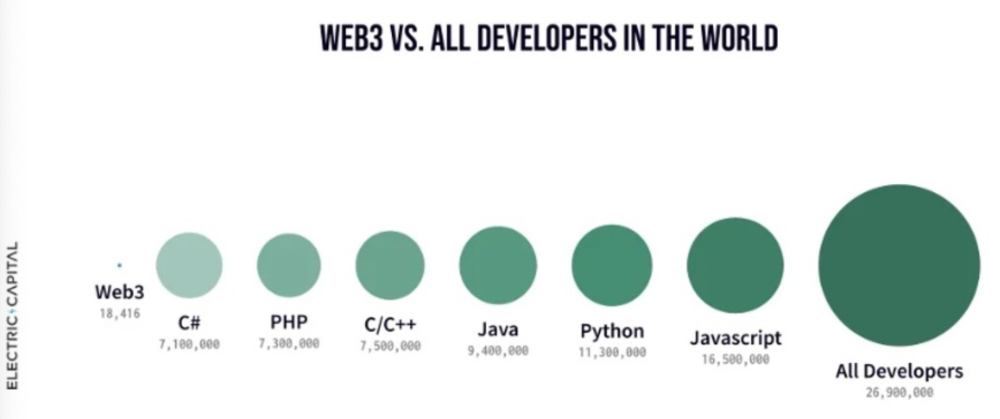
Electric Capital Developer Report (2021), p. 122
Growth requires composability. Users can easily integrate digital assets developed on public standards and compatible infrastructure into other platforms. The Loot Project is one of the first to illustrate decentralized co-creation, worldbuilding, and more in NFTs. This example was low-fi or "incomplete" aesthetically, providing room for imagination and community co-creation.
Loot began with a series of Loot bag NFTs, each listing eight "adventure things" in white writing on a black backdrop (such as Loot Bag #5726's "Katana, Divine Robe, Great Helm, Wool Sash, Divine Slippers, Chain Gloves, Amulet, Gold Ring"). Dom Hofmann's free Loot bags served as a foundation for the community.
Several projects have begun metaphorical (lore) and practical (game development) world-building in a short time, with artists contributing many variations to the collective "Lootverse." They've produced games (Realms & The Crypt), characters (Genesis Project, Hyperloot, Loot Explorers), storytelling initiatives (Banners, OpenQuill), and even infrastructure (The Rift).
Why cc0 and composability? Because consumers own and control Loot bags, they may use them wherever they choose by connecting their crypto wallets. This allows users to participate in multiple derivative projects, such as Genesis Adventurers, whose characters appear in many others — creating a decentralized franchise not owned by any one corporation.

Genesis Project's Genesis Adventurer (1) with HyperLoot (2) and Loot Explorer (3) versions
When to go cc0
There are several IP development strategies NFT projects can use. When it comes to cc0, it’s important to be realistic. The public domain won't make a project a runaway success just by implementing the license. cc0 works well for NFT initiatives that can develop a rich, enlarged ecosystem.
Many of the most successful cc0 projects have introduced flexible intellectual property. The Nouns brand is as obvious for a beer ad as for real glasses; Loot bags are simple primitives that make sense in all adventure settings; and the Goblintown visual style looks good on dwarfs, zombies, and cranky owls as it does on Val Kilmer.
The ideal cc0 NFT project gives builders the opportunity to add value:
vertically, by stacking new content and features directly on top of the original cc0 assets (for instance, as with games built on the Loot ecosystem, among others), and
horizontally, by introducing distinct but related intellectual property that helps propagate the original cc0 project’s brand (as with various Goblintown derivatives, among others).
These actions can assist cc0 NFT business models. Because cc0 NFT projects receive royalties from secondary sales, third-party extensions and derivatives can boost demand for the original assets.
Using cc0 license lowers friction that could hinder brand-reinforcing extensions or lead to them bypassing the original. Robbie Broome recently argued (in the context of his cc0 project A Common Place) that giving away his IP to cc0 avoids bad rehashes down the line. If UrbanOutfitters wanted to put my design on a tee, they could use the actual work instead of hiring a designer. CC0 can turn competition into cooperation.
Community agreement about core assets' value and contribution can help cc0 projects. Cohesion and engagement are key. Using the above examples: Developers can design adventure games around whatever themes and item concepts they desire, but many choose Loot bags because of the Lootverse's community togetherness. Flipmap shared half of its money with the original Blitmap artists in acknowledgment of that project's core role in the community. This can build a healthy culture within a cc0 project ecosystem. Commentator NiftyPins said it was smart to acknowledge the people that constructed their universe. Many OG Blitmap artists have popped into the Flipmap discord to share information.
cc0 isn't a one-size-fits-all answer; NFTs formed around well-established brands may prefer more restrictive licenses to preserve their intellectual property and reinforce exclusivity. cc0 has some superficial similarities to permitting NFT owners to market the IP connected with their NFTs (à la Bored Ape Yacht Club), but there is a significant difference: cc0 holders can't exclude others from utilizing the same IP. This can make it tougher for holders to develop commercial brands on cc0 assets or offer specific rights to partners. Holders can still introduce enlarged intellectual property (such as backstories or derivatives) that they control.
Blockchain technologies and the crypto ethos are decentralized and open-source. This makes it logical for crypto initiatives to build around cc0 content models, which build on the work of the Creative Commons foundation and numerous open source pioneers.
NFT creators that choose cc0 must select how involved they want to be in building the ecosystem. Some cc0 project leaders, like Chain Runners' developers, have kept building on top of the initial cc0 assets, creating an environment derivative projects can plug into. Dom Hofmann stood back from Loot, letting the community lead. (Dom is also working on additional cc0 NFT projects for the company he formed to build Blitmap.) Other authors have chosen out totally, like sartoshi, who announced his exit from the cc0 project he founded, mfers, and from the NFT area by publishing a final edition suitably named "end of sartoshi" and then deactivating his Twitter account. A multi-signature wallet of seven mfers controls the project's smart contract.
cc0 licensing allows a robust community to co-create in ways that benefit all members, regardless of original creators' continuous commitment. We foresee more organized infrastructure and design patterns as NFT matures. Like open source software, value capture frameworks may see innovation. (We could imagine a variant of the "Sleepycat license," which requires commercial software to pay licensing fees when embedding open source components.) As creators progress the space, we expect them to build unique rights and licensing strategies. cc0 allows NFT producers to bootstrap ideas that may take off.

nft now
3 years ago
Instagram NFTs Are Here… How does this affect artists?
Instagram (IG) is officially joining NFT. With the debut of new in-app NFT functionalities, influential producers can interact with blockchain tech on the social media platform.
Meta unveiled intentions for an Instagram NFT marketplace in March, but these latest capabilities focus more on content sharing than commerce. And why shouldn’t they? IG's entry into the NFT market is overdue, given that Twitter and Discord are NFT hotspots.
The NFT marketplace/Web3 social media race has continued to expand, with the expected Coinbase NFT Beta now live and blazing a trail through the NFT ecosystem.
IG's focus is on visual art. It's unlike any NFT marketplace or platform. IG NFTs and artists: what's the deal? Let’s take a look.
What are Instagram’s NFT features anyways?
As said, not everyone has Instagram's new features. 16 artists, NFT makers, and collectors can now post NFTs on IG by integrating third-party digital wallets (like Rainbow or MetaMask) in-app. IG doesn't charge to publish or share digital collectibles.
NFTs displayed on the app have a "shimmer" aesthetic effect. NFT posts also have a "digital collectable" badge that lists metadata such as the creator and/or owner, the platform it was created on, a brief description, and a blockchain identification.
Meta's social media NFTs have launched on Instagram, but the company is also preparing to roll out digital collectibles on Facebook, with more on the way for IG. Currently, only Ethereum and Polygon are supported, but Flow and Solana will be added soon.
How will artists use these new features?
Artists are publishing NFTs they developed or own on IG by linking third-party digital wallets. These features have no NFT trading aspects built-in, but are aimed to let authors share NFTs with IG audiences.
Creators, like IG-native aerial/street photographer Natalie Amrossi (@misshattan), are discovering novel uses for IG NFTs.
Amrossi chose to not only upload his own NFTs but also encourage other artists in the field. "That's the beauty of connecting your wallet and sharing NFTs. It's not just what you make, but also what you accumulate."
Amrossi has been producing and posting Instagram art for years. With IG's NFT features, she can understand Instagram's importance in supporting artists.
Web2 offered Amrossi the tools to become an artist and make a life. "Before 'influencer' existed, I was just making art. Instagram helped me reach so many individuals and brands, giving me a living.
Even artists without millions of viewers are encouraged to share NFTs on IG. Wilson, a relatively new name in the NFT space, seems to have already gone above and beyond the scope of these new IG features. By releasing "Losing My Mind" via IG NFT posts, she has evaded the lack of IG NFT commerce by using her network to market her multi-piece collection.
"'Losing My Mind' is a long-running photo series. Wilson was preparing to release it as NFTs before IG approached him, so it was a perfect match.
Wilson says the series is about Black feminine figures and media depiction. Respectable effort, given POC artists have been underrepresented in NFT so far.
“Over the past year, I've had mental health concerns that made my emotions so severe it was impossible to function in daily life, therefore that prompted this photo series. Every Wednesday and Friday for three weeks, I'll release a new Meta photo for sale.
Wilson hopes these new IG capabilities will help develop a connection between the NFT community and other internet subcultures that thrive on Instagram.
“NFTs can look scary as an outsider, but seeing them on your daily IG feed makes it less foreign,” adds Wilson. I think Instagram might become a hub for NFT aficionados, making them more accessible to artists and collectors.
What does it all mean for the NFT space?
Meta's NFT and metaverse activities will continue to impact Instagram's NFT ecosystem. Many think it will be for the better, as IG NFT frauds are another problem hurting the NFT industry.
IG's new NFT features seem similar to Twitter's PFP NFT verifications, but Instagram's tools should help cut down on scams as users can now verify the creation and ownership of whole NFT collections included in IG posts.
Given the number of visual artists and NFT creators on IG, it might become another hub for NFT fans, as Wilson noted. If this happens, it raises questions about Instagram success. Will artists be incentivized to distribute NFTs? Or will those with a large fanbase dominate?
Elise Swopes (@swopes) believes these new features should benefit smaller artists. Swopes was one of the first profiles placed to Instagram's original suggested user list in 2012.
Swopes says she wants IG to be a magnet for discovery and understands the value of NFT artists and producers.
"I'd love to see IG become a focus of discovery for everyone, not just the Beeples and Apes and PFPs. That's terrific for them, but [IG NFT features] are more about using new technology to promote emerging artists, Swopes added.
“Especially music artists. It's everywhere. Dancers, writers, painters, sculptors, musicians. My element isn't just for digital artists; it can be anything. I'm delighted to witness people's creativity."
Swopes, Wilson, and Amrossi all believe IG's new features can help smaller artists. It remains to be seen how these new features will effect the NFT ecosystem once unlocked for the rest of the IG NFT community, but we will likely see more social media NFT integrations in the months and years ahead.
Read the full article here

Sea Launch
4 years ago
A guide to NFT pre-sales and whitelists
Before we dig through NFT whitelists and pre-sales, if you know absolutely nothing about NFTs, check our NFT Glossary.
What are pre-sales and whitelists on NFTs?
An NFT pre-sale, as the name implies, allows community members or early supporters of an NFT project to mint before the public, usually via a whitelist or mint pass.
Coin collectors can use mint passes to claim NFTs during the public sale. Because the mint pass is executed by “burning” an NFT into a specific crypto wallet, the collector is not concerned about gas price spikes.
A whitelist is used to approve a crypto wallet address for an NFT pre-sale. In a similar way to an early access list, it guarantees a certain number of crypto wallets can mint one (or more) NFT.
New NFT projects can do a pre-sale without a whitelist, but whitelists are good practice to avoid gas wars and a fair shot at minting an NFT before launching in competitive NFT marketplaces like Opensea, Magic Eden, or CNFT.
Should NFT projects do pre-sales or whitelists? 👇
The reasons to do pre-sales or a whitelist for NFT creators:
Time the market and gain traction.
Pre-sale or whitelists can help NFT projects gauge interest early on.
Whitelist spots filling up quickly is usually a sign of a successful launch, though it does not guarantee NFT longevity (more on that later). Also, full whitelists create FOMO and momentum for the public sale among non-whitelisted NFT collectors.
If whitelist signups are low or slow, projects may need to work on their vision, community, or product. Or the market is in a bear cycle. In either case, it aids NFT projects in market timing.
Reward the early NFT Community members.
Pre-sale and whitelists can help NFT creators reward early supporters.
First, by splitting the minting process into two phases, early adopters get a chance to mint one or more NFTs from their collection at a discounted or even free price.
Did you know that BAYC started at 0.08 eth each? A serum that allowed you to mint a Mutant Ape has become as valuable as the original BAYC.
(2) Whitelists encourage early supporters to help build a project's community in exchange for a slot or status. If you invite 10 people to the NFT Discord community, you get a better ranking or even a whitelist spot.
Pre-sale and whitelisting have become popular ways for new projects to grow their communities and secure future buyers.
Prevent gas wars.
Most new NFTs are created on the Ethereum blockchain, which has the highest transaction fees (also known as gas) (Solana, Cardano, Polygon, Binance Smart Chain, etc).
An NFT public sale is a gas war when a large number of NFT collectors (or bots) try to mint an NFT at the same time.
Competing collectors are willing to pay higher gas fees to prioritize their transaction and out-price others when upcoming NFT projects are hyped and very popular.
Pre-sales and whitelisting prevent gas wars by breaking the minting process into smaller batches of members or season launches.
The reasons to do pre-sales or a whitelists for NFT collectors:
How do I get on an NFT whitelist?
- Popular NFT collections act as a launchpad for other new or hyped NFT collections.
Example: Interfaces NFTs gives out 100 whitelist spots to Deadfellaz NFTs holders. Both NFT projects win. Interfaces benefit from Deadfellaz's success and brand equity.
In this case, to get whitelisted NFT collectors need to hold that specific NFT that is acting like a launchpad.
- A NFT studio or collection that launches a new NFT project and rewards previous NFT holders with whitelist spots or pre-sale access.
The whitelist requires previous NFT holders or community members.
NFT Alpha Groups are closed, small, tight-knit Discord servers where members share whitelist spots or giveaways from upcoming NFTs.
The benefit of being in an alpha group is getting information about new NFTs first and getting in on pre-sale/whitelist before everyone else.
There are some entry barriers to alpha groups, but if you're active in the NFT community, you'll eventually bump into, be invited to, or form one.
- A whitelist spot is awarded to members of an NFT community who are the most active and engaged.
This participation reward is the most democratic. To get a chance, collectors must work hard and play to their strengths.
Whitelisting participation examples:
- Raffle, games and contest: NFT Community raffles, games, and contests. To get a whitelist spot, invite 10 people to X NFT Discord community.
- Fan art: To reward those who add value and grow the community by whitelisting the best fan art and/or artists is only natural.
- Giveaways: Lucky number crypto wallet giveaways promoted by an NFT community. To grow their communities and for lucky collectors, NFT projects often offer free NFT.
- Activate your voice in the NFT Discord Community. Use voice channels to get NFT teams' attention and possibly get whitelisted.
The advantage of whitelists or NFT pre-sales.
Chainalysis's NFT stats quote is the best answer:
“Whitelisting isn’t just some nominal reward — it translates to dramatically better investing results. OpenSea data shows that users who make the whitelist and later sell their newly-minted NFT gain a profit 75.7% of the time, versus just 20.8% for users who do so without being whitelisted. Not only that, but the data suggests it’s nearly impossible to achieve outsized returns on minting purchases without being whitelisted.” Full report here.
Sure, it's not all about cash. However, any NFT collector should feel secure in their investment by owning a piece of a valuable and thriving NFT project. These stats help collectors understand that getting in early on an NFT project (via whitelist or pre-sale) will yield a better and larger return.
The downsides of pre-sales & whitelists for NFT creators.
Pre-sales and whitelist can cause issues for NFT creators and collectors.
NFT flippers
NFT collectors who only want to profit from early minting (pre-sale) or low mint cost (via whitelist). To sell the NFT in a secondary market like Opensea or Solanart, flippers go after the discounted price.
For example, a 1000 Solana NFT collection allows 100 people to mint 1 Solana NFT at 0.25 SOL. The public sale price for the remaining 900 NFTs is 1 SOL. If an NFT collector sells their discounted NFT for 0.5 SOL, the secondary market floor price is below the public mint.
This may deter potential NFT collectors. Furthermore, without a cap in the pre-sale minting phase, flippers can get as many NFTs as possible to sell for a profit, dumping them in secondary markets and driving down the floor price.
Hijacking NFT sites, communities, and pre-sales phase
People try to scam the NFT team and their community by creating oddly similar but fake websites, whitelist links, or NFT's Discord channel.
Established and new NFT projects must be vigilant to always make sure their communities know which are the official links, how a whitelist or pre-sale rules and how the team will contact (or not) community members.
Another way to avoid the scams around the pre-sale phase, NFT projects opt to create a separate mint contract for the whitelisted crypto wallets and then another for the public sale phase.
Scam NFT projects
We've seen a lot of mid-mint or post-launch rug pulls, indicating that some bad NFT projects are trying to scam NFT communities and marketplaces for quick profit. What happened to Magic Eden's launchpad recently will help you understand the scam.
We discussed the benefits and drawbacks of NFT pre-sales and whitelists for both projects and collectors.
Finally, some practical tools and tips for finding new NFTs 👇
Tools & resources to find new NFT on pre-sale or to get on a whitelist:
In order to never miss an update, important pre-sale dates, or a giveaway, create a Tweetdeck or Tweeten Twitter dashboard with hyped NFT project pages, hashtags ( #NFTGiveaways , #NFTCommunity), or big NFT influencers.
Search for upcoming NFT launches that have been vetted by the marketplace and try to get whitelisted before the public launch.
Save-timing discovery platforms like sealaunch.xyz for NFT pre-sales and upcoming launches. How can we help 100x NFT collectors get projects? A project's official social media links, description, pre-sale or public sale dates, price and supply. We're also working with Dune on NFT data analysis to help NFT collectors make better decisions.
Don't invest what you can't afford to lose because a) the project may fail or become rugged. Find NFTs projects that you want to be a part of and support.
Read original post here
You might also like

Glorin Santhosh
3 years ago
In his final days, Steve Jobs sent an email to himself. What It Said Was This
An email capturing Steve Jobs's philosophy.

Steve Jobs may have been the most inspired and driven entrepreneur.
He worked on projects because he wanted to leave a legacy.
Steve Jobs' final email to himself encapsulated his philosophy.
After his death from pancreatic cancer in October 2011, Laurene Powell Jobs released the email. He was 56.
Read: Steve Jobs by Walter Isaacson (#BestSeller)
The Email:
September 2010 Steve Jobs email:
“I grow little of the food I eat, and of the little I do grow, I do not breed or perfect the seeds.” “I do not make my own clothing. I speak a language I did not invent or refine,” he continued. “I did not discover the mathematics I use… I am moved by music I did not create myself.”
Jobs ended his email by reflecting on how others created everything he uses.
He wrote:
“When I needed medical attention, I was helpless to help myself survive.”

The Apple co-founder concluded by praising humanity.
“I did not invent the transistor, the microprocessor, object-oriented programming, or most of the technology I work with. I love and admire my species, living and dead, and am totally dependent on them for my life and well-being,” he concluded.
The email was made public as a part of the Steve Jobs Archive, a website that was launched in tribute to his legacy.
Steve Jobs' widow founded the internet archive. Apple CEO Tim Cook and former design leader Jony Ive were prominent guests.
Steve Jobs has always inspired because he shows how even the best can be improved.
High expectations were always there, and they were consistently met.
We miss him because he was one of the few with lifelong enthusiasm and persona.

Greg Satell
3 years ago
Focus: The Deadly Strategic Idea You've Never Heard Of (But Definitely Need To Know!

Steve Jobs' initial mission at Apple in 1997 was to destroy. He killed the Newton PDA and Macintosh clones. Apple stopped trying to please everyone under Jobs.
Afterward, there were few highly targeted moves. First, the pink iMac. Modest success. The iPod, iPhone, and iPad made Apple the world's most valuable firm. Each maneuver changed the company's center of gravity and won.
That's the idea behind Schwerpunkt, a German military term meaning "focus." Jobs didn't need to win everywhere, just where it mattered, so he focused Apple's resources on a few key goods. Finding your Schwerpunkt is more important than charts and analysis for excellent strategy.
Comparison of Relative Strength and Relative Weakness
The iPod, Apple's first major hit after Jobs' return, didn't damage Microsoft and the PC, but instead focused Apple's emphasis on a fledgling, fragmented market that generated "sucky" products. Apple couldn't have taken on the computer titans at this stage, yet it beat them.
The move into music players used Apple's particular capabilities, especially its ability to build simple, easy-to-use interfaces. Jobs' charisma and stature, along his understanding of intellectual property rights from Pixar, helped him build up iTunes store, which was a quagmire at the time.
In Good Strategy | Bad Strategy, management researcher Richard Rumelt argues that good strategy uses relative strength to counter relative weakness. To discover your main point, determine your abilities and where to effectively use them.
Steve Jobs did that at Apple. Microsoft and Dell, who controlled the computer sector at the time, couldn't enter the music player business. Both sought to produce iPod competitors but failed. Apple's iPod was nobody else's focus.
Finding The Center of Attention
In a military engagement, leaders decide where to focus their efforts by assessing commanders intent, the situation on the ground, the topography, and the enemy's posture on that terrain. Officers spend their careers learning about schwerpunkt.
Business executives must assess internal strengths including personnel, technology, and information, market context, competitive environment, and external partner ecosystems. Steve Jobs was a master at analyzing forces when he returned to Apple.
He believed Apple could integrate technology and design for the iPod and that the digital music player industry sucked. By analyzing competitors' products, he was convinced he could produce a smash by putting 1000 tunes in my pocket.
The only difficulty was there wasn't the necessary technology. External ecosystems were needed. On a trip to Japan to meet with suppliers, a Toshiba engineer claimed the company had produced a tiny memory drive approximately the size of a silver dollar.
Jobs knew the memory drive was his focus. He wrote a $10 million cheque and acquired exclusive technical rights. For a time, none of his competitors would be able to recreate his iPod with the 1000 songs in my pocket.
How to Enter the OODA Loop
John Boyd invented the OODA loop as a pilot to better his own decision-making. First OBSERVE your surroundings, then ORIENT that information using previous knowledge and experiences. Then you DECIDE and ACT, which changes the circumstance you must observe, orient, decide, and act on.
Steve Jobs used the OODA loop to decide to give Toshiba $10 million for a technology it had no use for. He compared the new information with earlier observations about the digital music market.
Then something much more interesting happened. The iPod was an instant hit, changing competition. Other computer businesses that competed in laptops, desktops, and servers created digital music players. Microsoft's Zune came out in 2006, Dell's Digital Jukebox in 2004. Both flopped.
By then, Apple was poised to unveil the iPhone, which would cause its competitors to Observe, Orient, Decide, and Act. Boyd named this OODA Loop infiltration. They couldn't gain the initiative by constantly reacting to Apple.
Microsoft and Dell were titans back then, but it's hard to recall. Apple went from near bankruptcy to crushing its competition via Schwerpunkt.
Rather than a destination, it is a journey
Trying to win everywhere is a strategic blunder. Win significant fights, not trivial skirmishes. Identifying a focal point to direct resources and efforts is the essence of Schwerpunkt.
When Steve Jobs returned to Apple, PC firms were competing, but he focused on digital music players, and the iPod made Apple a player. He launched the iPhone when his competitors were still reacting. When Steve Jobs said, "One more thing," at the end of a product presentation, he had a new focus.
Schwerpunkt isn't static; it's dynamic. Jobs' ability to observe, refocus, and modify the competitive backdrop allowed Apple to innovate consistently. His strategy was tailored to Apple's capabilities, customers, and ecosystem. Microsoft or Dell, better suited for the enterprise sector, couldn't succeed with a comparable approach.
There is no optimal strategy, only ones suited to a given environment, when relative strength might be used against relative weakness. Discovering the center of gravity where you can break through is more of a journey than a destination; it will become evident after you reach.

Leah
3 years ago
The Burnout Recovery Secrets Nobody Is Talking About

What works and what’s just more toxic positivity
Just keep at it; you’ll get it.
I closed the Zoom call and immediately dropped my head. Open tabs included material on inspiration, burnout, and recovery.
I searched everywhere for ways to avoid burnout.
It wasn't that I needed to keep going, change my routine, employ 8D audio playlists, or come up with fresh ideas. I had several ideas and a schedule. I knew what to do.
I wasn't interested. I kept reading, changing my self-care and mental health routines, and writing even though it was tiring.
Since burnout became a psychiatric illness in 2019, thousands have shared their experiences. It's spreading rapidly among writers.
What is the actual key to recovering from burnout?
Every A-list burnout story emphasizes prevention. Other lists provide repackaged self-care tips. More discuss mental health.
It's like the mid-2000s, when pink quotes about bubble baths saturated social media.
The self-care mania cost us all. Self-care is crucial, but utilizing it to address everything didn't work then or now.
How can you recover from burnout?
Time
Are extended breaks actually good for you? Most people need a break every 62 days or so to avoid burnout.
Real-life burnout victims all took breaks. Perhaps not a long hiatus, but breaks nonetheless.
Burnout is slow and gradual. It takes little bits of your motivation and passion at a time. Sometimes it’s so slow that you barely notice or blame it on other things like stress and poor sleep.
Burnout doesn't come overnight; neither will recovery.
I don’t care what anyone else says the cure for burnout is. It has to be time because time is what gave us all burnout in the first place.