


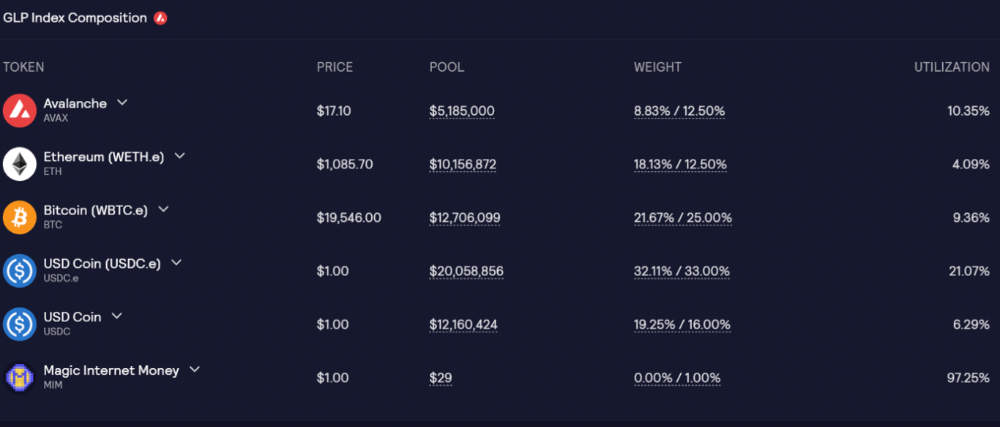
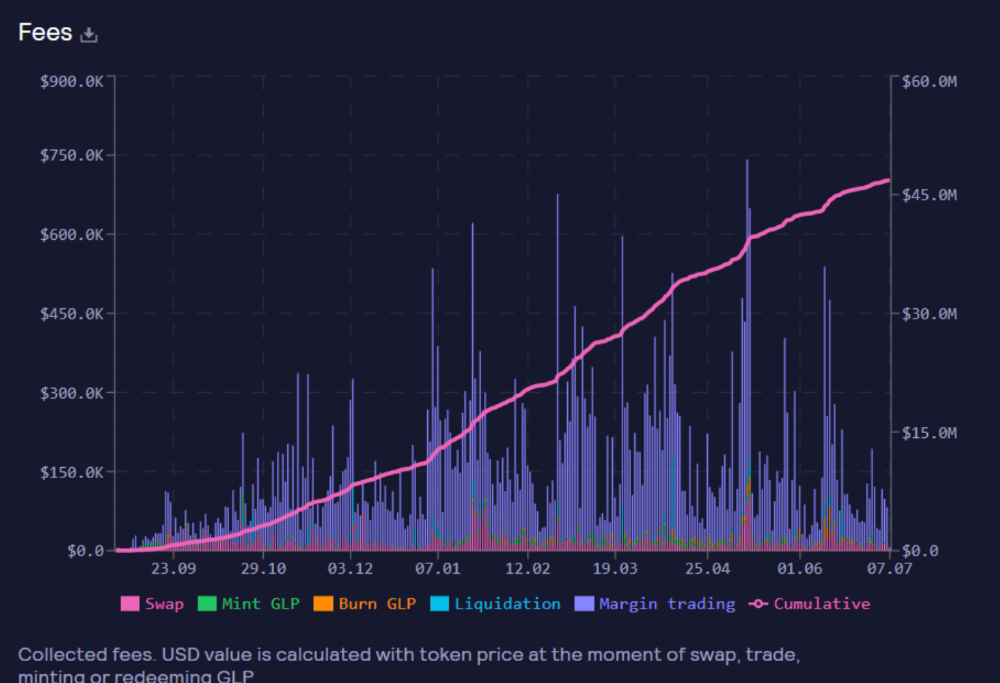
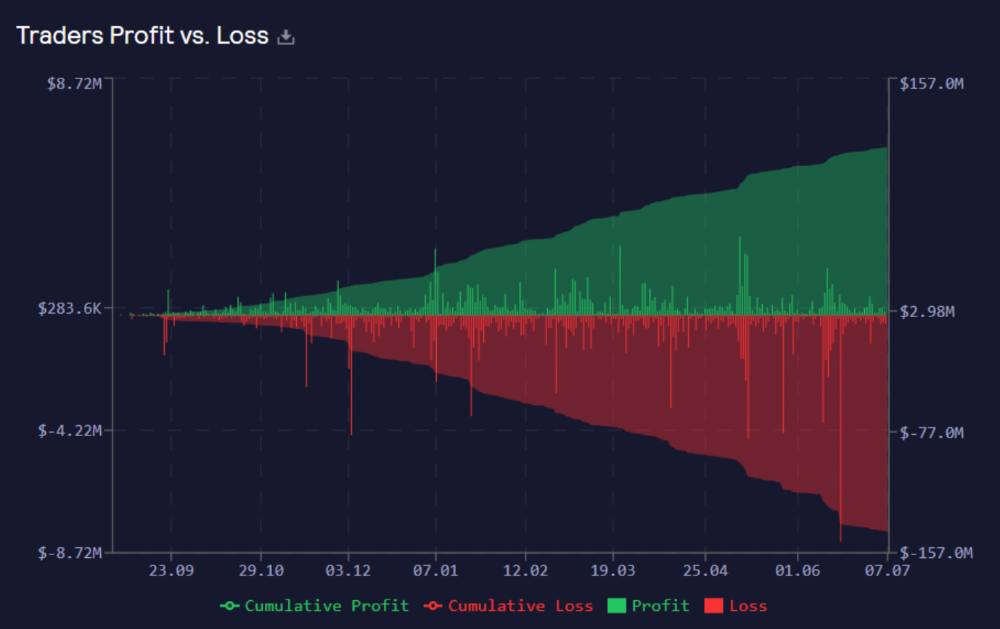
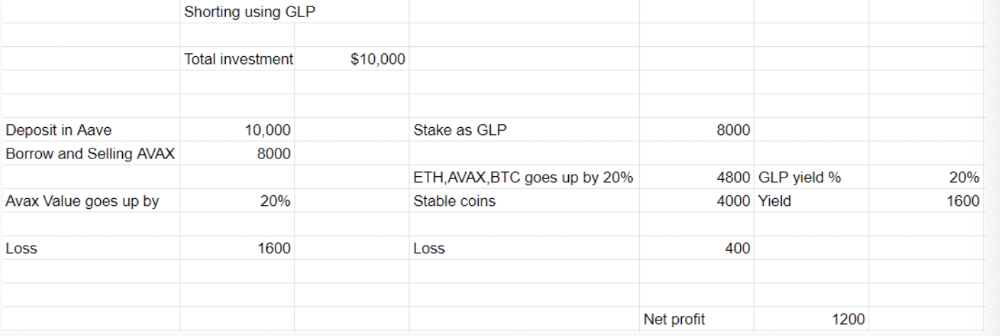
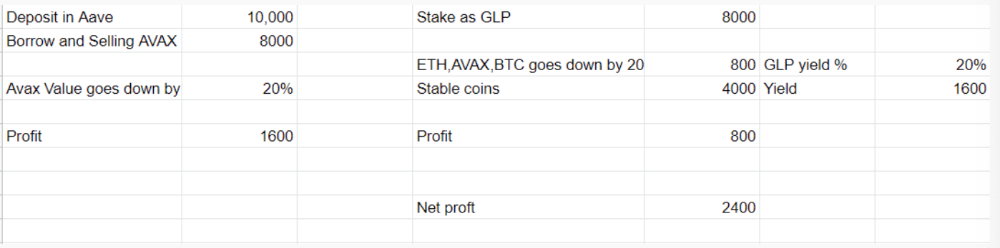
More on Web3 & Crypto

Ryan Weeks
3 years ago
Terra fiasco raises TRON's stablecoin backstop
After Terra's algorithmic stablecoin collapsed in May, TRON announced a plan to increase the capital backing its own stablecoin.
USDD, a near-carbon copy of Terra's UST, arrived on the TRON blockchain on May 5. TRON founder Justin Sun says USDD will be overcollateralized after initially being pegged algorithmically to the US dollar.
A reserve of cryptocurrencies and stablecoins will be kept at 130 percent of total USDD issuance, he said. TRON described the collateral ratio as "guaranteed" and said it would begin publishing real-time updates on June 5.
Currently, the reserve contains 14,040 bitcoin (around $418 million), 140 million USDT, 1.9 billion TRX, and 8.29 billion TRX in a burning contract.
Sun: "We want to hybridize USDD." We have an algorithmic stablecoin and TRON DAO Reserve.
algorithmic failure
USDD was designed to incentivize arbitrageurs to keep its price pegged to the US dollar by trading TRX, TRON's token, and USDD. Like Terra, TRON signaled its intent to establish a bitcoin and cryptocurrency reserve to support USDD in extreme market conditions.
Still, Terra's UST failed despite these safeguards. The stablecoin veered sharply away from its dollar peg in mid-May, bringing down Terra's LUNA and wiping out $40 billion in value in days. In a frantic attempt to restore the peg, billions of dollars in bitcoin were sold and unprecedented volumes of LUNA were issued.
Sun believes USDD, which has a total circulating supply of $667 million, can be backed up.
"Our reserve backing is diversified." Bitcoin and stablecoins are included. USDC will be a small part of Circle's reserve, he said.
TRON's news release lists the reserve's assets as bitcoin, TRX, USDC, USDT, TUSD, and USDJ.
All Bitcoin addresses will be signed so everyone knows they belong to us, Sun said.
Not giving in
Sun told that the crypto industry needs "decentralized" stablecoins that regulators can't touch.
Sun said the Luna Foundation Guard, a Singapore-based non-profit that raised billions in cryptocurrency to buttress UST, mismanaged the situation by trying to sell to panicked investors.
He said, "We must be ahead of the market." We want to stabilize the market and reduce volatility.
Currently, TRON finances most of its reserve directly, but Sun says the company hopes to add external capital soon.
Before its demise, UST holders could park the stablecoin in Terra's lending platform Anchor Protocol to earn 20% interest, which many deemed unsustainable. TRON's JustLend is similar. Sun hopes to raise annual interest rates from 17.67% to "around 30%."
This post is a summary. Read full article here
:max_bytes(150000):strip_icc():gifv():format(webp)/reiff_headshot-5bfc2a60c9e77c00519a70bd.jpg)
Nathan Reiff
3 years ago
Howey Test and Cryptocurrencies: 'Every ICO Is a Security'
What Is the Howey Test?
To determine whether a transaction qualifies as a "investment contract" and thus qualifies as a security, the Howey Test refers to the U.S. Supreme Court cass: the Securities Act of 1933 and the Securities Exchange Act of 1934. According to the Howey Test, an investment contract exists when "money is invested in a common enterprise with a reasonable expectation of profits from others' efforts."
The test applies to any contract, scheme, or transaction. The Howey Test helps investors and project backers understand blockchain and digital currency projects. ICOs and certain cryptocurrencies may be found to be "investment contracts" under the test.
Understanding the Howey Test
The Howey Test comes from the 1946 Supreme Court case SEC v. W.J. Howey Co. The Howey Company sold citrus groves to Florida buyers who leased them back to Howey. The company would maintain the groves and sell the fruit for the owners. Both parties benefited. Most buyers had no farming experience and were not required to farm the land.
The SEC intervened because Howey failed to register the transactions. The court ruled that the leaseback agreements were investment contracts.
This established four criteria for determining an investment contract. Investing contract:
- An investment of money
- n a common enterprise
- With the expectation of profit
- To be derived from the efforts of others
In the case of Howey, the buyers saw the transactions as valuable because others provided the labor and expertise. An income stream was obtained by only investing capital. As a result of the Howey Test, the transaction had to be registered with the SEC.
Howey Test and Cryptocurrencies
Bitcoin is notoriously difficult to categorize. Decentralized, they evade regulation in many ways. Regardless, the SEC is looking into digital assets and determining when their sale qualifies as an investment contract.
The SEC claims that selling digital assets meets the "investment of money" test because fiat money or other digital assets are being exchanged. Like the "common enterprise" test.
Whether a digital asset qualifies as an investment contract depends on whether there is a "expectation of profit from others' efforts."
For example, buyers of digital assets may be relying on others' efforts if they expect the project's backers to build and maintain the digital network, rather than a dispersed community of unaffiliated users. Also, if the project's backers create scarcity by burning tokens, the test is met. Another way the "efforts of others" test is met is if the project's backers continue to act in a managerial role.
These are just a few examples given by the SEC. If a project's success is dependent on ongoing support from backers, the buyer of the digital asset is likely relying on "others' efforts."
Special Considerations
If the SEC determines a cryptocurrency token is a security, many issues arise. It means the SEC can decide whether a token can be sold to US investors and forces the project to register.
In 2017, the SEC ruled that selling DAO tokens for Ether violated federal securities laws. Instead of enforcing securities laws, the SEC issued a warning to the cryptocurrency industry.
Due to the Howey Test, most ICOs today are likely inaccessible to US investors. After a year of ICOs, then-SEC Chair Jay Clayton declared them all securities.
SEC Chairman Gensler Agrees With Predecessor: 'Every ICO Is a Security'
Howey Test FAQs
How Do You Determine If Something Is a Security?
The Howey Test determines whether certain transactions are "investment contracts." Securities are transactions that qualify as "investment contracts" under the Securities Act of 1933 and the Securities Exchange Act of 1934.
The Howey Test looks for a "investment of money in a common enterprise with a reasonable expectation of profits from others' efforts." If so, the Securities Act of 1933 and the Securities Exchange Act of 1934 require disclosure and registration.
Why Is Bitcoin Not a Security?
Former SEC Chair Jay Clayton clarified in June 2018 that bitcoin is not a security: "Cryptocurrencies: Replace the dollar, euro, and yen with bitcoin. That type of currency is not a security," said Clayton.
Bitcoin, which has never sought public funding to develop its technology, fails the SEC's Howey Test. However, according to Clayton, ICO tokens are securities.
A Security Defined by the SEC
In the public and private markets, securities are fungible and tradeable financial instruments. The SEC regulates public securities sales.
The Supreme Court defined a security offering in SEC v. W.J. Howey Co. In its judgment, the court defines a security using four criteria:
- An investment contract's existence
- The formation of a common enterprise
- The issuer's profit promise
- Third-party promotion of the offering
Read original post.

Sam Hickmann
3 years ago
Token taxonomy: Utility vs Security vs NFT
Let's examine the differences between the three main token types and their functions.
As Ethereum grew, the term "token" became a catch-all term for all assets built on the Ethereum blockchain. However, different tokens were grouped based on their applications and features, causing some confusion. Let's examine the modification of three main token types: security, utility, and non-fungible.
Utility tokens
They provide a specific utility benefit (or a number of such). A utility token is similar to a casino chip, a table game ticket, or a voucher. Depending on the terms of issuing, they can be earned and used in various ways. A utility token is a type of token that represents a tool or mechanism required to use the application in question. Like a service, a utility token's price is determined by supply and demand. Tokens can also be used as a bonus or reward mechanism in decentralized systems: for example, if you like someone's work, give them an upvote and they get a certain number of tokens. This is a way for authors or creators to earn money indirectly.
The most common way to use a utility token is to pay with them instead of cash for discounted goods or services.
Utility tokens are the most widely used by blockchain companies. Most cryptocurrency exchanges accept fees in native utility tokens.
Utility tokens can also be used as a reward. Companies tokenize their loyalty programs so that points can be bought and sold on blockchain exchanges. These tokens are widely used in decentralized companies as a bonus system. You can use utility tokens to reward creators for their contributions to a platform, for example. It also allows members to exchange tokens for specific bonuses and rewards on your site.
Unlike security tokens, which are subject to legal restrictions, utility tokens can be freely traded.
Security tokens
Security tokens are essentially traditional securities like shares, bonds, and investment fund units in a crypto token form.
The key distinction is that security tokens are typically issued by private firms (rather than public companies) that are not listed on stock exchanges and in which you can not invest right now. Banks and large venture funds used to be the only sources of funding. A person could only invest in private firms if they had millions of dollars in their bank account. Privately issued security tokens outperform traditional public stocks in terms of yield. Private markets grew 50% faster than public markets over the last decade, according to McKinsey Private Equity Research.
A security token is a crypto token whose value is derived from an external asset or company. So it is governed as security (read about the Howey test further in this article). That is, an ownership token derives its value from the company's valuation, assets on the balance sheet, or dividends paid to token holders.
Why are Security Tokens Important?
Cryptocurrency is a lucrative investment. Choosing from thousands of crypto assets can mean the difference between millionaire and bankrupt. Without security tokens, crypto investing becomes riskier and generating long-term profits becomes difficult. These tokens have lower risk than other cryptocurrencies because they are backed by real assets or business cash flows. So having them helps to diversify a portfolio and preserve the return on investment in riskier assets.
Security tokens open up new funding avenues for businesses. As a result, investors can invest in high-profit businesses that are not listed on the stock exchange.
The distinction between utility and security tokens isn't as clear as it seems. However, this increases the risk for token issuers, especially in the USA. The Howey test is the main pillar regulating judicial precedent in this area.
What is a Howey Test?
An "investment contract" is determined by the Howey Test, a lawsuit settled by the US Supreme Court. If it does, it's a security and must be disclosed and registered under the Securities Act of 1933 and the Securities Exchange Act of 1934.
If the SEC decides that a cryptocurrency token is a security, a slew of issues arise. In practice, this ensures that the SEC will decide when a token can be offered to US investors and if the project is required to file a registration statement with the SEC.
Due to the Howey test's extensive wording, most utility tokens will be classified as securities, even if not intended to be. Because of these restrictions, most ICOs are not available to US investors. When asked about ICOs in 2018, then-SEC Chairman Jay Clayton said they were securities. The given statement adds to the risk. If a company issues utility tokens without registering them as securities, the regulator may impose huge fines or even criminal charges.
What other documents regulate tokens?
Securities Act (1993) or Securities Exchange Act (1934) in the USA; MiFID directive and Prospectus Regulation in the EU. These laws require registering the placement of security tokens, limiting their transfer, but protecting investors.
Utility tokens have much less regulation. The Howey test determines whether a given utility token is a security. Tokens recognized as securities are now regulated as such. Having a legal opinion that your token isn't makes the implementation process much easier. Most countries don't have strict regulations regarding utility tokens except KYC (Know Your Client) and AML (Anti Money-Laundering).
As cryptocurrency and blockchain technologies evolve, more countries create UT regulations. If your company is based in the US, be aware of the Howey test and the Bank Secrecy Act. It classifies UTs and their issuance as money transmission services in most states, necessitating a license and strict regulations. Due to high regulatory demands, UT issuers try to avoid the United States as a whole. A new law separating utility tokens from bank secrecy act will be introduced in the near future, giving hope to American issuers.
The rest of the world has much simpler rules requiring issuers to create basic investor disclosures. For example, the latest European legislation (MiCA) allows businesses to issue utility tokens without regulator approval. They must also prepare a paper with all the necessary information for the investors.
A payment token is a utility token that is used to make a payment. They may be subject to electronic money laws.
Because non-fungible tokens are a new instrument, there is no regulating paper yet. However, if the NFT is fractionalized, the smaller tokens acquired may be seen as securities.
NFT Tokens
Collectible tokens are also known as non-fungible tokens. Their distinctive feature is that they denote unique items such as artwork, merch, or ranks. Unlike utility tokens, which are fungible, meaning that two of the same tokens are identical, NFTs represent a unit of possession that is strictly one of a kind. In a way, NFTs are like baseball cards, each one unique and valuable.
As for today, the most recognizable NFT function is to preserve the fact of possession. Owning an NFT with a particular gif, meme, or sketch does not transfer the intellectual right to the possessor, but is analogous to owning an original painting signed by the author.
Collectible tokens can also be used as digital souvenirs, so to say. Businesses can improve their brand image by issuing their own branded NFTs, which represent ranks or achievements within the corporate ecosystem. Gamifying business ecosystems would allow people to connect with a brand and feel part of a community.
Which type of tokens is right for you as a business to raise capital?
For most businesses, it's best to raise capital with security tokens by selling existing shares to global investors. Utility tokens aren't meant to increase in value over time, so leave them for gamification and community engagement. In a blockchain-based business, however, a utility token is often the lifeblood of the operation, and its appreciation potential is directly linked to the company's growth. You can issue multiple tokens at once, rather than just one type. It exposes you to various investors and maximizes the use of digital assets.
Which tokens should I buy?
There are no universally best tokens. Their volatility, industry, and risk-reward profile vary. This means evaluating tokens in relation to your overall portfolio and personal preferences: what industries do you understand best, what excites you, how do you approach taxes, and what is your planning horizon? To build a balanced portfolio, you need to know these factors.
Conclusion
The three most common types of tokens today are security, utility, and NFT. Security tokens represent stocks, mutual funds, and bonds. Utility tokens can be perceived as an inside-product "currency" or "ignition key" that grants you access to goods and services or empowers with other perks. NFTs are unique collectible units that identify you as the owner of something.
You might also like

Sammy Abdullah
3 years ago
SaaS payback period data
It's ok and even desired to be unprofitable if you're gaining revenue at a reasonable cost and have 100%+ net dollar retention, meaning you never lose customers and expand them. To estimate the acceptable cost of new SaaS revenue, we compare new revenue to operating loss and payback period. If you pay back the customer acquisition cost in 1.5 years and never lose them (100%+ NDR), you're doing well.
To evaluate payback period, we compared new revenue to net operating loss for the last 73 SaaS companies to IPO since October 2017. (55 out of 73). Here's the data. 1/(new revenue/operating loss) equals payback period. New revenue/operating loss equals cost of new revenue.
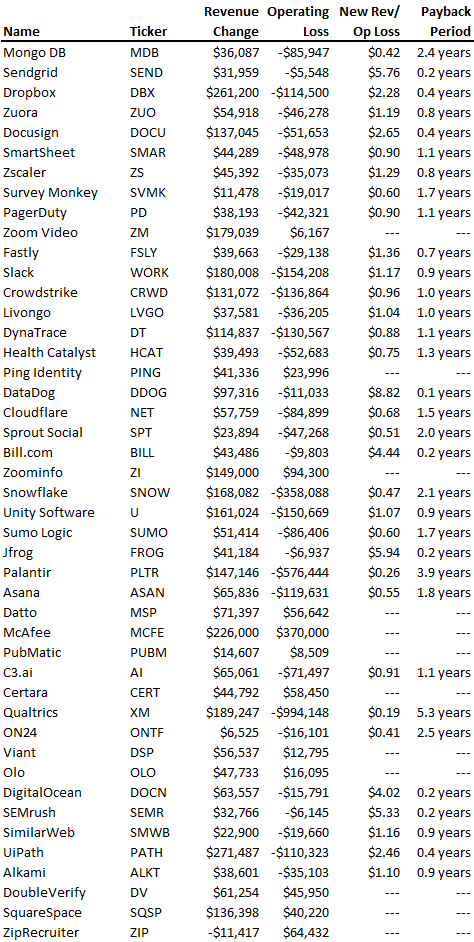
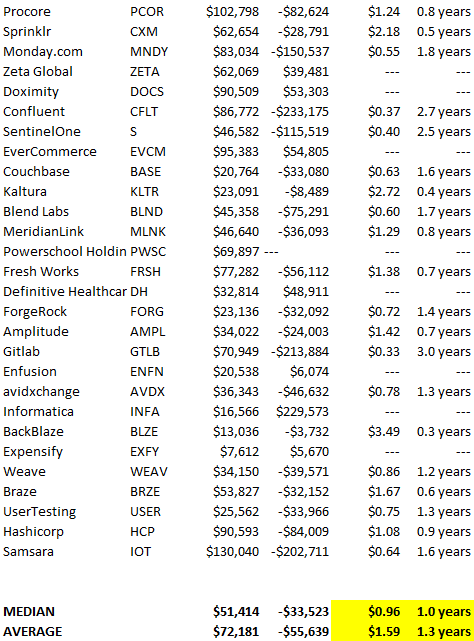
Payback averages a year. 55 SaaS companies that weren't profitable at IPO got a 1-year payback. Outstanding. If you pay for a customer in a year and never lose them (100%+ NDR), you're establishing a valuable business. The average was 1.3 years, which is within the 1.5-year range.
New revenue costs $0.96 on average. These SaaS companies lost $0.96 every $1 of new revenue last year. Again, impressive. Average new revenue per operating loss was $1.59.
Loss-in-operations definition. Operating loss revenue COGS S&M R&D G&A (technical point: be sure to use the absolute value of operating loss). It's wrong to only consider S&M costs and ignore other business costs. Operating loss and new revenue are measured over one year to eliminate seasonality.
Operating losses are desirable if you never lose a customer and have a quick payback period, especially when SaaS enterprises are valued on ARR. The payback period should be under 1.5 years, the cost of new income < $1, and net dollar retention 100%.

Jim Siwek
3 years ago
In 2022, can a lone developer be able to successfully establish a SaaS product?

In the early 2000s, I began developing SaaS. I helped launch an internet fax service that delivered faxes to email inboxes. Back then, it saved consumers money and made the procedure easier.
Google AdWords was young then. Anyone might establish a new website, spend a few hundred dollars on keywords, and see dozens of new paying clients every day. That's how we launched our new SaaS, and these clients stayed for years. Our early ROI was sky-high.
Changing times
The situation changed dramatically after 15 years. Our paid advertising cost $200-$300 for every new customer. Paid advertising takes three to four years to repay.
Fortunately, we still had tens of thousands of loyal clients. Good organic rankings gave us new business. We needed less sponsored traffic to run a profitable SaaS firm.
Is it still possible?
Since selling our internet fax firm, I've dreamed about starting a SaaS company. One I could construct as a lone developer and progressively grow a dedicated customer base, as I did before in a small team.
It seemed impossible to me. Solo startups couldn't afford paid advertising. SEO was tough. Even the worst SaaS startup ideas attracted VC funding. How could I compete with startups that could hire great talent and didn't need to make money for years (or ever)?
The One and Only Way to Learn
After years of talking myself out of SaaS startup ideas, I decided to develop and launch one. I needed to know if a solitary developer may create a SaaS app in 2022.
Thus, I did. I invented webwriter.ai, an AI-powered writing tool for website content, from hero section headlines to blog posts, this year. I soft-launched an MVP in July.
Considering the Issue
Now that I've developed my own fully capable SaaS app for site builders and developers, I wonder if it's still possible. Can webwriter.ai be successful?
I know webwriter.ai's proposal is viable because Jasper.ai and Grammarly are also AI-powered writing tools. With competition comes validation.
To Win, Differentiate
To compete with well-funded established brands, distinguish to stand out to a portion of the market. So I can speak directly to a target user, unlike larger competition.
I created webwriter.ai to help web builders and designers produce web content rapidly. This may be enough differentiation for now.
Budget-Friendly Promotion
When paid search isn't an option, we get inventive. There are more tools than ever to promote a new website.
Organic Results
on social media (Twitter, Instagram, TikTok, LinkedIn)
Marketing with content that is compelling
Link Creation
Listings in directories
references made in blog articles and on other websites
Forum entries
The Beginning of the Journey
As I've labored to construct my software, I've pondered a new mantra. Not sure where that originated from, but I like it. I'll live by it and teach my kids:
“Do the work.”

Michael Hunter, MD
3 years ago
5 Drugs That May Increase Your Risk of Dementia

While our genes can't be changed easily, you can avoid some dementia risk factors. Today we discuss dementia and five drugs that may increase risk.
Memory loss appears to come with age, but we're not talking about forgetfulness. Sometimes losing your car keys isn't an indication of dementia. Dementia impairs the capacity to think, remember, or make judgments. Dementia hinders daily tasks.
Alzheimers is the most common dementia. Dementia is not normal aging, unlike forgetfulness. Aging increases the risk of Alzheimer's and other dementias. A family history of the illness increases your risk, according to the Mayo Clinic (USA).
Given that our genes are difficult to change (I won't get into epigenetics), what are some avoidable dementia risk factors? Certain drugs may cause cognitive deterioration.
Today we look at four drugs that may cause cognitive decline.
Dementia and benzodiazepines
Benzodiazepine sedatives increase brain GABA levels. Example benzodiazepines:
Diazepam (Valium) (Valium)
Alprazolam (Xanax) (Xanax)
Clonazepam (Klonopin) (Klonopin)
Addiction and overdose are benzodiazepine risks. Yes! These medications don't raise dementia risk.
USC study: Benzodiazepines don't increase dementia risk in older adults.
Benzodiazepines can produce short- and long-term amnesia. This memory loss hinders memory formation. Extreme cases can permanently impair learning and memory. Anterograde amnesia is uncommon.
2. Statins and dementia
Statins reduce cholesterol. They prevent a cholesterol-making chemical. Examples:
Atorvastatin (Lipitor) (Lipitor)
Fluvastatin (Lescol XL) (Lescol XL)
Lovastatin (Altoprev) (Altoprev)
Pitavastatin (Livalo, Zypitamag) (Livalo, Zypitamag)
Pravastatin (Pravachol) (Pravachol)
Rosuvastatin (Crestor, Ezallor) (Crestor, Ezallor)
Simvastatin (Zocor) (Zocor)
This finding is contentious. Harvard's Brigham and Womens Hospital's Dr. Joann Manson says:
“I think that the relationship between statins and cognitive function remains controversial. There’s still not a clear conclusion whether they help to prevent dementia or Alzheimer’s disease, have neutral effects, or increase risk.”
This one's off the dementia list.
3. Dementia and anticholinergic drugs
Anticholinergic drugs treat many conditions, including urine incontinence. Drugs inhibit acetylcholine (a brain chemical that helps send messages between cells). Acetylcholine blockers cause drowsiness, disorientation, and memory loss.
First-generation antihistamines, tricyclic antidepressants, and overactive bladder antimuscarinics are common anticholinergics among the elderly.
Anticholinergic drugs may cause dementia. One study found that taking anticholinergics for three years or more increased the risk of dementia by 1.54 times compared to three months or less. After stopping the medicine, the danger may continue.
4. Drugs for Parkinson's disease and dementia
Cleveland Clinic (USA) on Parkinson's:
Parkinson's disease causes age-related brain degeneration. It causes delayed movements, tremors, and balance issues. Some are inherited, but most are unknown. There are various treatment options, but no cure.
Parkinson's medications can cause memory loss, confusion, delusions, and obsessive behaviors. The drug's effects on dopamine cause these issues.
A 2019 JAMA Internal Medicine study found powerful anticholinergic medications enhance dementia risk.
Those who took anticholinergics had a 1.5 times higher chance of dementia. Individuals taking antidepressants, antipsychotic drugs, anti-Parkinson’s drugs, overactive bladder drugs, and anti-epileptic drugs had the greatest risk of dementia.
Anticholinergic medicines can lessen Parkinson's-related tremors, but they slow cognitive ability. Anticholinergics can cause disorientation and hallucinations in those over 70.
5. Antiepileptic drugs and dementia
The risk of dementia from anti-seizure drugs varies with drugs. Levetiracetam (Keppra) improves Alzheimer's cognition.
One study linked different anti-seizure medications to dementia. Anti-epileptic medicines increased the risk of Alzheimer's disease by 1.15 times in the Finnish sample and 1.3 times in the German population. Depakote, Topamax are drugs.