



More on Entrepreneurship/Creators

Scrum Ventures
3 years ago
Trends from the Winter 2022 Demo Day at Y Combinators

Y Combinators Winter 2022 Demo Day continues the trend of more startups engaging in accelerator Demo Days. Our team evaluated almost 400 projects in Y Combinator's ninth year.
After Winter 2021 Demo Day, we noticed a hurry pushing shorter rounds, inflated valuations, and larger batches.
Despite the batch size, this event's behavior showed a return to normalcy. Our observations show that investors evaluate and fund businesses more carefully. Unlike previous years, more YC businesses gave investors with data rooms and thorough pitch decks in addition to valuation data before Demo Day.
Demo Day pitches were virtual and fast-paced, limiting unplanned meetings. Investors had more time and information to do their due research before meeting founders. Our staff has more time to study diverse areas and engage with interesting entrepreneurs and founders.
This was one of the most regionally diversified YC cohorts to date. This year's Winter Demo Day startups showed some interesting tendencies.
Trends and Industries to Watch Before Demo Day
Demo day events at any accelerator show how investment competition is influencing startups. As startups swiftly become scale-ups and big success stories in fintech, e-commerce, healthcare, and other competitive industries, entrepreneurs and early-stage investors feel pressure to scale quickly and turn a notion into actual innovation.
Too much eagerness can lead founders to focus on market growth and team experience instead of solid concepts, technical expertise, and market validation. Last year, YC Winter Demo Day funding cycles ended too quickly and valuations were unrealistically high.
Scrum Ventures observed a longer funding cycle this year compared to last year's Demo Day. While that seems promising, many factors could be contributing to change, including:
Market patterns are changing and the economy is becoming worse.
the industries that investors are thinking about.
Individual differences between each event batch and the particular businesses and entrepreneurs taking part
The Winter 2022 Batch's Trends
Each year, we also wish to examine trends among early-stage firms and YC event participants. More international startups than ever were anticipated to present at Demo Day.
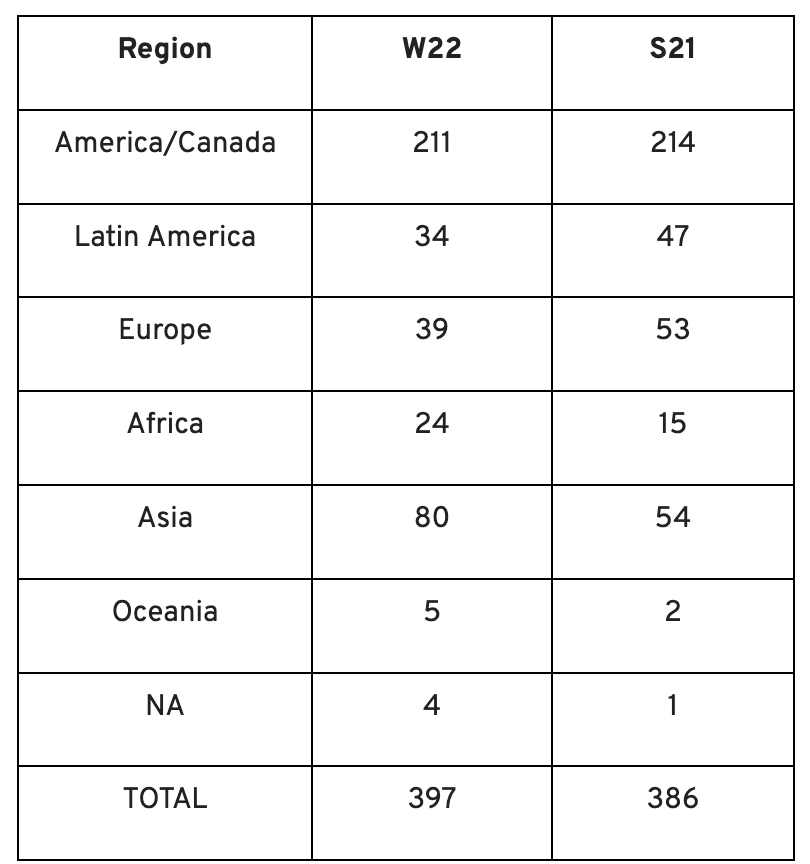
Less than 50% of demo day startups were from the U.S. For the S21 batch, firms from outside the US were most likely in Latin America or Europe, however this year's batch saw a large surge in startups situated in Asia and Africa.
YC Startup Directory
163 out of 399 startups were B2B software and services companies. Financial, healthcare, and consumer startups were common.
Our team doesn't plan to attend every pitch or speak with every startup's founders or team members. Let's look at cleantech, Web3, and health and wellness startup trends.
Our Opinions Following Conversations with 87 Startups at Demo Day
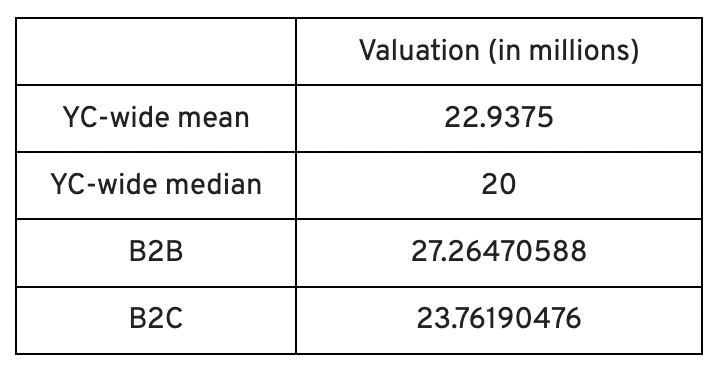
In the lead-up to Demo Day, we spoke with 87 of the 125 startups going. Compared to B2C enterprises, B2B startups had higher average valuations. A few outliers with high valuations pushed B2B and B2C means above the YC-wide mean and median.
Many of these startups develop business and technology solutions we've previously covered. We've seen API, EdTech, creative platforms, and cybersecurity remain strong and increase each year.
While these persistent tendencies influenced the startups Scrum Ventures looked at and the founders we interacted with on Demo Day, new trends required more research and preparation. Let's examine cleantech, Web3, and health and wellness startups.
Hardware and software that is green
Cleantech enterprises demand varying amounts of funding for hardware and software. Although the same overarching trend is fueling the growth of firms in this category, each subgroup has its own strategy and technique for investigation and identifying successful investments.
Many cleantech startups we spoke to during the YC event are focused on helping industrial operations decrease or recycle carbon emissions.
Carbon Crusher: Creating carbon negative roads
Phase Biolabs: Turning carbon emissions into carbon negative products and carbon neutral e-fuels
Seabound: Capturing carbon dioxide emissions from ships
Fleetzero: Creating electric cargo ships
Impossible Mining: Sustainable seabed mining
Beyond Aero: Creating zero-emission private aircraft
Verdn: Helping businesses automatically embed environmental pledges for product and service offerings, boost customer engagement
AeonCharge: Allowing electric vehicle (EV) drivers to more easily locate and pay for EV charging stations
Phoenix Hydrogen: Offering a hydrogen marketplace and a connected hydrogen hub platform to connect supply and demand for hydrogen fuel and simplify hub planning and partner program expansion
Aklimate: Allowing businesses to measure and reduce their supply chain’s environmental impact
Pina Earth: Certifying and tracking the progress of businesses’ forestry projects
AirMyne: Developing machines that can reverse emissions by removing carbon dioxide from the air
Unravel Carbon: Software for enterprises to track and reduce their carbon emissions
Web3: NFTs, the metaverse, and cryptocurrency
Web3 technologies handle a wide range of business issues. This category includes companies employing blockchain technology to disrupt entertainment, finance, cybersecurity, and software development.
Many of these startups overlap with YC's FinTech trend. Despite this, B2C and B2B enterprises were evenly represented in Web3. We examined:
Stablegains: Offering consistent interest on cash balance from the decentralized finance (DeFi) market
LiquiFi: Simplifying token management with automated vesting contracts, tax reporting, and scheduling. For companies, investors, and finance & accounting
NFTScoring: An NFT trading platform
CypherD Wallet: A multichain wallet for crypto and NFTs with a non-custodial crypto debit card that instantly converts coins to USD
Remi Labs: Allowing businesses to more easily create NFT collections that serve as access to products, memberships, events, and more
Cashmere: A crypto wallet for Web3 startups to collaboratively manage funds
Chaingrep: An API that makes blockchain data human-readable and tokens searchable
Courtyard: A platform for securely storing physical assets and creating 3D representations as NFTs
Arda: “Banking as a Service for DeFi,” an API that FinTech companies can use to embed DeFi products into their platforms
earnJARVIS: A premium cryptocurrency management platform, allowing users to create long-term portfolios
Mysterious: Creating community-specific experiences for Web3 Discords
Winter: An embeddable widget that allows businesses to sell NFTs to users purchasing with a credit card or bank transaction
SimpleHash: An API for NFT data that provides compatibility across blockchains, standardized metadata, accurate transaction info, and simple integration
Lifecast: Tools that address motion sickness issues for 3D VR video
Gym Class: Virtual reality (VR) multiplayer basketball video game
WorldQL: An asset API that allows NFT creators to specify multiple in-game interpretations of their assets, increasing their value
Bonsai Desk: A software development kit (SDK) for 3D analytics
Campfire: Supporting virtual social experiences for remote teams
Unai: A virtual headset and Visual World experience
Vimmerse: Allowing creators to more easily create immersive 3D experiences
Fitness and health
Scrum Ventures encountered fewer health and wellness startup founders than Web3 and Cleantech. The types of challenges these organizations solve are still diverse. Several of these companies are part of a push toward customization in healthcare, an area of biotech set for growth for companies with strong portfolios and experienced leadership.
Here are several startups we considered:
Syrona Health: Personalized healthcare for women in the workplace
Anja Health: Personalized umbilical cord blood banking and stem cell preservation
Alfie: A weight loss program focused on men’s health that coordinates medical care, coaching, and “community-based competition” to help users lose an average of 15% body weight
Ankr Health: An artificial intelligence (AI)-enabled telehealth platform that provides personalized side effect education for cancer patients and data collection for their care teams
Koko — A personalized sleep program to improve at-home sleep analysis and training
Condition-specific telehealth platforms and programs:
Reviving Mind: Chronic care management covered by insurance and supporting holistic, community-oriented health care
Equipt Health: At-home delivery of prescription medical equipment to help manage chronic conditions like obstructive sleep apnea
LunaJoy: Holistic women’s healthcare management for mental health therapy, counseling, and medication
12 Startups from YC's Winter 2022 Demo Day to Watch
Bobidi: 10x faster AI model improvement
Artificial intelligence (AI) models have become a significant tool for firms to improve how well and rapidly they process data. Bobidi helps AI-reliant firms evaluate their models, boosting data insights in less time and reducing data analysis expenditures. The business has created a gamified community that offers a bug bounty for AI, incentivizing community members to test and find weaknesses in clients' AI models.
Magna: DeFi investment management and token vesting
Magna delivers rapid, secure token vesting so consumers may turn DeFi investments into primitives. Carta for Web3 allows enterprises to effortlessly distribute tokens to staff or investors. The Magna team hopes to allow corporations use locked tokens as collateral for loans, facilitate secondary liquidity so investors can sell shares on a public exchange, and power additional DeFi applications.
Perl Street: Funding for infrastructure
This Fintech firm intends to help hardware entrepreneurs get financing by [democratizing] structured finance, unleashing billions for sustainable infrastructure and next-generation hardware solutions. This network has helped hardware entrepreneurs achieve more than $140 million in finance, helping companies working on energy storage devices, EVs, and creating power infrastructure.
CypherD: Multichain cryptocurrency wallet
CypherD seeks to provide a multichain crypto wallet so general customers can explore Web3 products without knowledge hurdles. The startup's beta app lets consumers access crypto from EVM blockchains. The founders have crypto, financial, and startup experience.
Unravel Carbon: Enterprise carbon tracking and offsetting
Unravel Carbon's AI-powered decarbonization technology tracks companies' carbon emissions. Singapore-based startup focuses on Asia. The software can use any company's financial data to trace the supply chain and calculate carbon tracking, which is used to make regulatory disclosures and suggest carbon offsets.
LunaJoy: Precision mental health for women
LunaJoy helped women obtain mental health support throughout life. The platform combines data science to create a tailored experience, allowing women to access psychotherapy, medication management, genetic testing, and health coaching.
Posh: Automated EV battery recycling
Posh attempts to solve one of the EV industry's largest logistical difficulties. Millions of EV batteries will need to be decommissioned in the next decade, and their precious metals and residual capacity will go unused for some time. Posh offers automated, scalable lithium battery disassembly, making EV battery recycling more viable.
Unai: VR headset with 5x higher resolution
Unai stands apart from metaverse companies. Its VR headgear has five times the resolution of existing options and emphasizes human expression and interaction in a remote world. Maxim Perumal's method of latency reduction powers current VR headsets.
Palitronica: Physical infrastructure cybersecurity
Palitronica blends cutting-edge hardware and software to produce networked electronic systems that support crucial physical and supply chain infrastructure. The startup's objective is to build solutions that defend national security and key infrastructure from cybersecurity threats.
Reality Defender: Deepfake detection
Reality Defender alerts firms to bogus users and changed audio, video, and image files. Reality Deference's API and web app score material in real time to prevent fraud, improve content moderation, and detect deception.
Micro Meat: Infrastructure for the manufacture of cell-cultured meat
MicroMeat promotes sustainable meat production. The company has created technologies to scale up bioreactor-grown meat muscle tissue from animal cells. Their goal is to scale up cultured meat manufacturing so cultivated meat products can be brought to market feasibly and swiftly, boosting worldwide meat consumption.
Fleetzero: Electric cargo ships
This startup's battery technology will make cargo ships more sustainable and profitable. Fleetzero's electric cargo ships have five times larger profit margins than fossil fuel ships. Fleetzeros' founder has marine engineering, ship operations, and enterprise sales and business experience.

Mangu Solutions
3 years ago
Growing a New App to $15K/mo in 6 Months [SaaS Case Study]
Discover How We Used Facebook Ads to Grow a New Mobile App from $0 to $15K MRR in Just 6 Months and Our Strategy to Hit $100K a Month.
Our client introduced a mobile app for Poshmark resellers in December and wanted as many to experience it and subscribe to the monthly plan.
An Error We Committed
We initiated a Facebook ad campaign with a "awareness" goal, not "installs." This sent them to a landing page that linked to the iPhone App Store and Android Play Store. Smart, right?
We got some installs, but we couldn't tell how many came from the ad versus organic/other channels because the objective we chose only reported landing page clicks, not app installs.
We didn't know which interest groups/audiences had the best cost per install (CPI) to optimize and scale our budget.
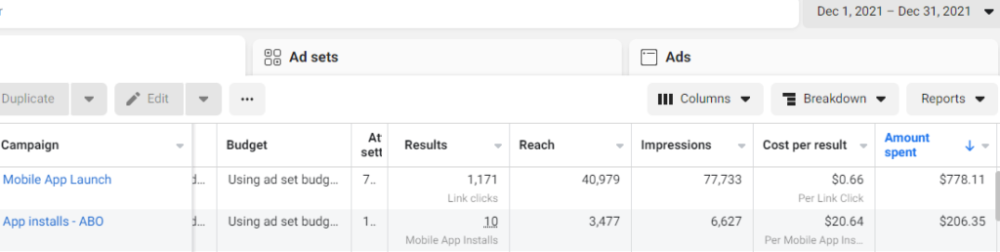
After spending $700 without adequate data (installs and trials report), we stopped the campaign and worked with our client's app developer to set up app events tracking.
This allowed us to create an installs campaign and track installs, trials, and purchases (in some cases).
Finding a Successful Audience
Once we knew what ad sets brought in what installs at what cost, we began optimizing and testing other interest groups and audiences, growing the profitable low CPI ones and eliminating the high CPI ones.
We did all our audience testing using an ABO campaign (Ad Set Budget Optimization), spending $10 to $30 on each ad set for three days and optimizing afterward. All ad sets under $30 were moved to a CBO campaign (Campaign Budget Optimization).
We let Facebook's AI decide how much to spend on each ad set, usually the one most likely to convert at the lowest cost.
If the CBO campaign maintains a nice CPI, we keep increasing the budget by $50 every few days or duplicating it sometimes in order to double the budget. This is how we've scaled to $400/day profitably.

Finding Successful Creatives
Per campaign, we tested 2-6 images/videos. Same ad copy and CTA. There was no clear winner because some images did better with some interest groups.
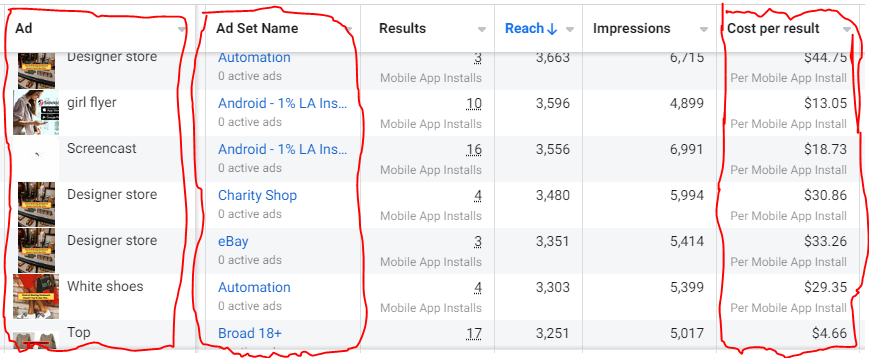
The image above with mail packages, for example, got us a cheap CPI of $9.71 from our Goodwill Stores interest group but, a high $48 CPI from our lookalike audience. Once we had statistically significant data, we turned off the high-cost ad.
New marketers who are just discovering A/B testing may assume it's black and white — winner and loser. However, Facebook ads' machine learning and reporting has gotten so sophisticated that it's hard to call a creative a flat-out loser, but rather a 'bad fit' for some audiences, and perfect for others.
You can see how each creative performs across age groups and optimize.
How Many Installs Did It Take Us to Earn $15K Per Month?
Six months after paying $25K, we got 1,940 app installs, 681 free trials, and 522 $30 monthly subscriptions. 522 * $30 gives us $15,660 in monthly recurring revenue (MRR).
Next, what? $100K per month
The conversation above is with the app's owner. We got on a 30-minute call where I shared how I plan to get the app to be making $100K a month like I’ve done for other businesses.
Reverse Engineering $100K
Formula:
For $100K/month, we need 3,334 people to pay $30/month. 522 people pay that. We need 2,812 more paid users.
522 paid users from 1,940 installs is a 27% conversion rate. To hit $100K/month, we need 10,415 more installs. Assuming...
With a $400 daily ad spend, we average 40 installs per day. This means that if everything stays the same, it would take us 260 days (around 9 months) to get to $100K a month (MRR).
Conclusion
You must market your goods to reach your income objective (without waiting forever). Paid ads is the way to go if you hate knocking on doors or irritating friends and family (who aren’t scalable anyways).
You must also test and optimize different angles, audiences, interest groups, and creatives.

Navdeep Yadav
3 years ago
31 startup company models (with examples)
Many people find the internet's various business models bewildering.
This article summarizes 31 startup e-books.
1. Using the freemium business model (free plus premium),
The freemium business model offers basic software, games, or services for free and charges for enhancements.
Examples include Slack, iCloud, and Google Drive
Provide a rudimentary, free version of your product or service to users.
Google Drive and Dropbox offer 15GB and 2GB of free space but charge for more.
Freemium business model details (Click here)
2. The Business Model of Subscription
Subscription business models sell a product or service for recurring monthly or yearly revenue.
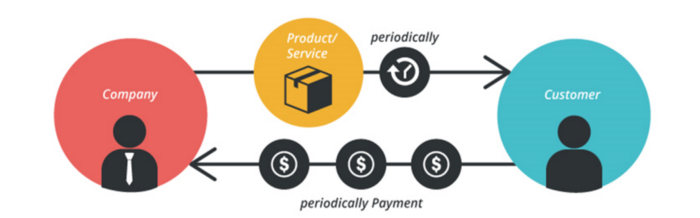
Examples: Tinder, Netflix, Shopify, etc
It's the next step to Freemium if a customer wants to pay monthly for premium features.
Subscription Business Model (Click here)
3. A market-based business strategy
It's an e-commerce site or app where third-party sellers sell products or services.
Examples are Amazon and Fiverr.
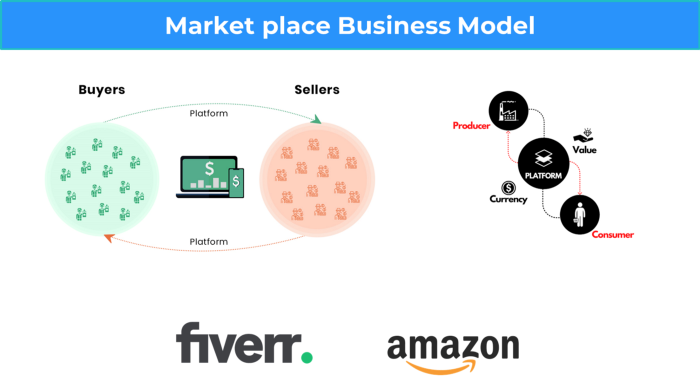
On Amazon's marketplace, a third-party vendor sells a product.
Freelancers on Fiverr offer specialized skills like graphic design.
Marketplace's business concept is explained.
4. Business plans using aggregates
In the aggregator business model, the service is branded.
Uber, Airbnb, and other examples
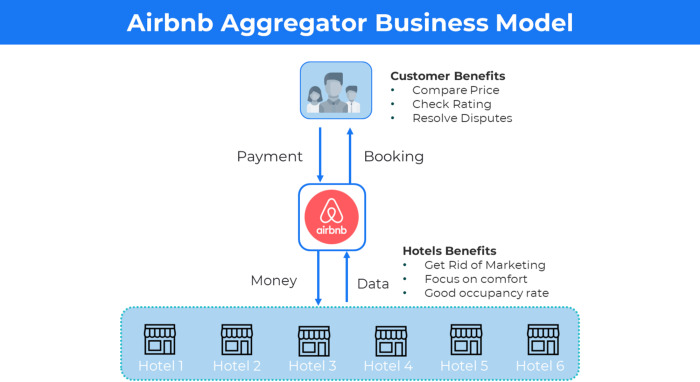
Marketplace and Aggregator business models differ.

Amazon and Fiverr link merchants and customers and take a 10-20% revenue split.
Uber and Airbnb-style aggregator Join these businesses and provide their products.
5. The pay-as-you-go concept of business
This is a consumption-based pricing system. Cloud companies use it.
Example: Amazon Web Service and Google Cloud Platform (GCP) (AWS)
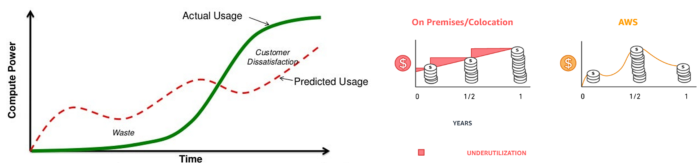
AWS, an Amazon subsidiary, offers over 200 pay-as-you-go cloud services.
“In short, the more you use the more you pay”
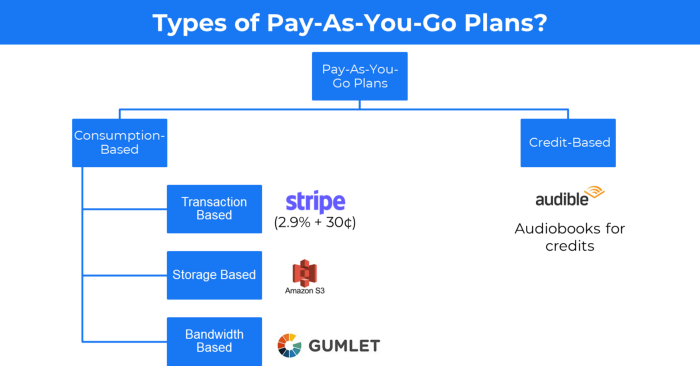
When it's difficult to divide clients into pricing levels, pay-as-you is employed.
6. The business model known as fee-for-service (FFS)
FFS charges fixed and variable fees for each successful payment.
For instance, PayU, Paypal, and Stripe
Stripe charges 2.9% + 30 per payment.
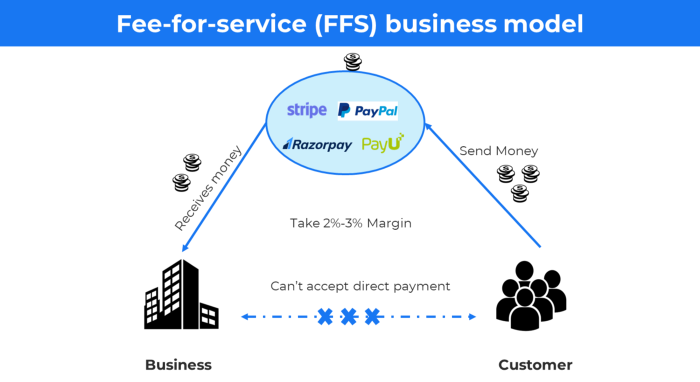
These firms offer a payment gateway to take consumer payments and deposit them to a business account.
Fintech business model
7. EdTech business strategy
In edtech, you generate money by selling material or teaching as a service.
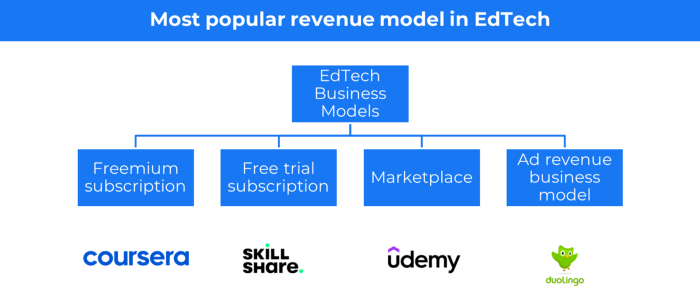
edtech business models
Freemium When course content is free but certification isn't, e.g. Coursera
FREE TRIAL SkillShare offers free trials followed by monthly or annual subscriptions.
Self-serving marketplace approach where you pick what to learn.
Ad-revenue model The company makes money by showing adverts to its huge user base.
Lock-in business strategy
Lock in prevents customers from switching to a competitor's brand or offering.
It uses switching costs or effort to transmit (soft lock-in), improved brand experience, or incentives.
Apple, SAP, and other examples
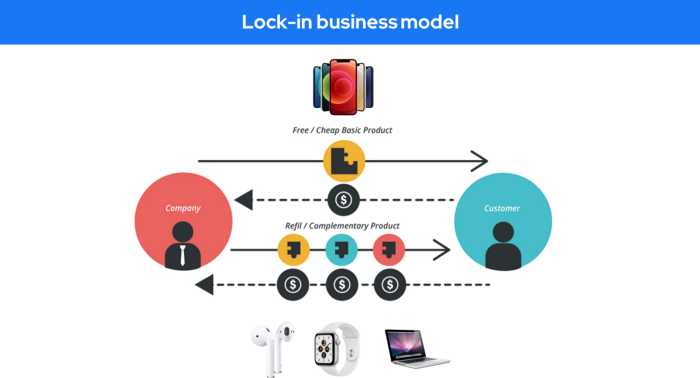
Apple offers an iPhone and then locks you in with extra hardware (Watch, Airpod) and platform services (Apple Store, Apple Music, cloud, etc.).
9. Business Model for API Licensing
APIs let third-party apps communicate with your service.
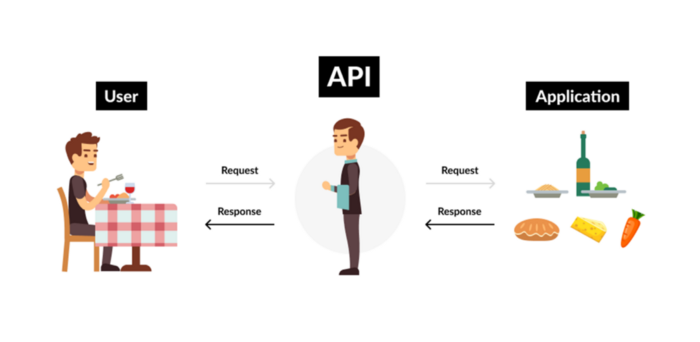
Uber and Airbnb use Google Maps APIs for app navigation.
Examples are Google Map APIs (Map), Sendgrid (Email), and Twilio (SMS).
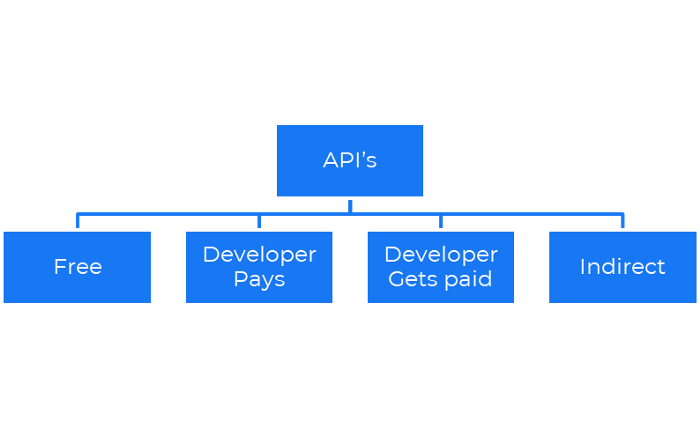
Business models for APIs
Free: The simplest API-driven business model that enables unrestricted API access for app developers. Google Translate and Facebook are two examples.
Developer Pays: Under this arrangement, service providers such as AWS, Twilio, Github, Stripe, and others must be paid by application developers.
The developer receives payment: These are the compensated content producers or developers who distribute the APIs utilizing their work. For example, Amazon affiliate programs
10. Open-source enterprise
Open-source software can be inspected, modified, and improved by anybody.
For instance, use Firefox, Java, or Android.
Google paid Mozilla $435,702 million to be their primary search engine in 2018.
Open-source software profits in six ways.
Paid assistance The Project Manager can charge for customization because he is quite knowledgeable about the codebase.
A full database solution is available as a Software as a Service (MongoDB Atlas), but there is a fee for the monitoring tool.
Open-core design R studio is a better GUI substitute for open-source applications.
sponsors of GitHub Sponsorships benefit the developers in full.
demands for paid features Earn Money By Developing Open Source Add-Ons for Current Products
Open-source business model
11. The business model for data
If the software or algorithm collects client data to improve or monetize the system.
Open AI GPT3 gets smarter with use.
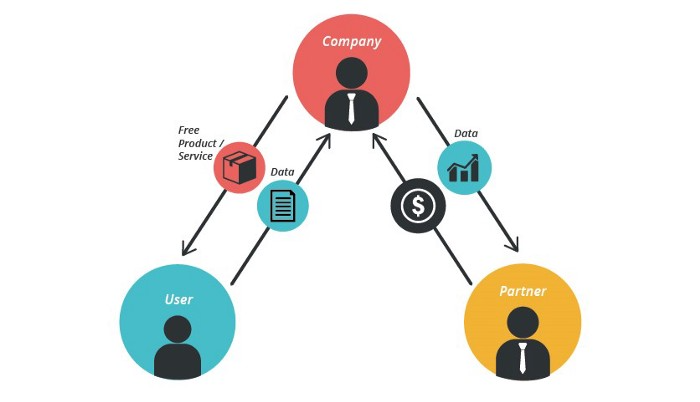
Foursquare allows users to exchange check-in locations.
Later, they compiled large datasets to enable retailers like Starbucks launch new outlets.
12. Business Model Using Blockchain
Blockchain is a distributed ledger technology that allows firms to deploy smart contracts without a central authority.
Examples include Alchemy, Solana, and Ethereum.
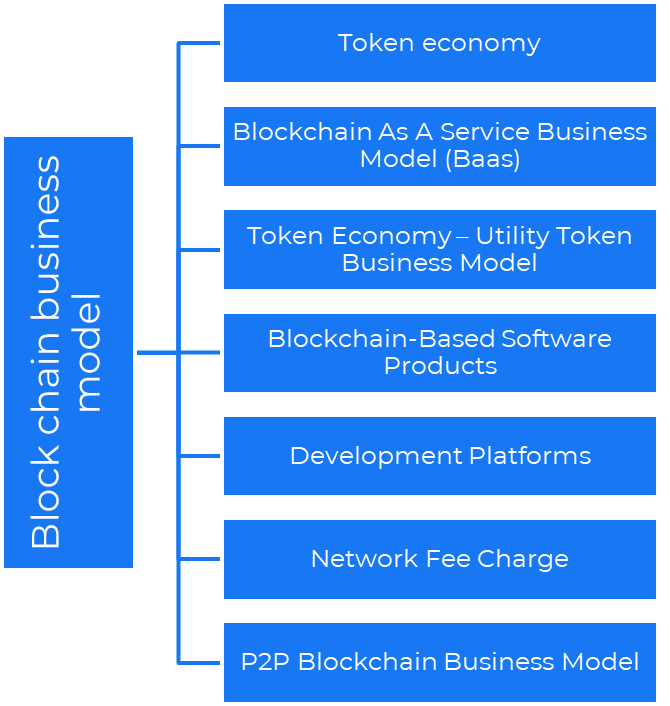
Business models using blockchain
Economy of tokens or utility When a business uses a token business model, it issues some kind of token as one of the ways to compensate token holders or miners. For instance, Solana and Ethereum
Bitcoin Cash P2P Business Model Peer-to-peer (P2P) blockchain technology permits direct communication between end users. as in IPFS
Enterprise Blockchain as a Service (Baas) BaaS focuses on offering ecosystem services similar to those offered by Amazon (AWS) and Microsoft (Azure) in the web 3 sector. Example: Ethereum Blockchain as a Service with Bitcoin (EBaaS).
Blockchain-Based Aggregators With AWS for blockchain, you can use that service by making an API call to your preferred blockchain. As an illustration, Alchemy offers nodes for many blockchains.
13. The free-enterprise model
In the freeterprise business model, free professional accounts are led into the funnel by the free product and later become B2B/enterprise accounts.
For instance, Slack and Zoom
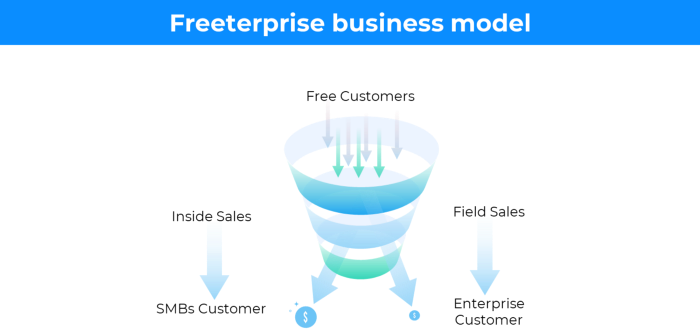
Freeterprise companies flourish through collaboration.
Start with a free professional account to build an enterprise.
14. Business plan for razor blades
It's employed in hardware where one piece is sold at a loss and profits are made through refills or add-ons.
Gillet razor & blades, coffee machine & beans, HP printer & cartridge, etc.
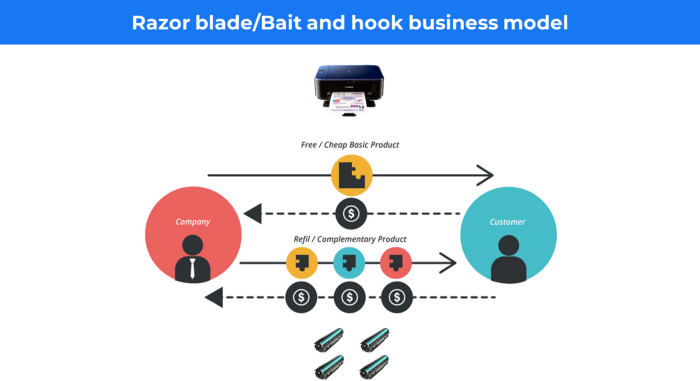
Sony sells the Playstation console at a loss but makes up for it by selling games and charging for online services.
Advantages of the Razor-Razorblade Method
lowers the risk a customer will try a product. enables buyers to test the goods and services without having to pay a high initial investment.
The product's ongoing revenue stream has the potential to generate sales that much outweigh the original investments.
Razor blade business model
15. The business model of direct-to-consumer (D2C)
In D2C, the company sells directly to the end consumer through its website using a third-party logistic partner.
Examples include GymShark and Kylie Cosmetics.
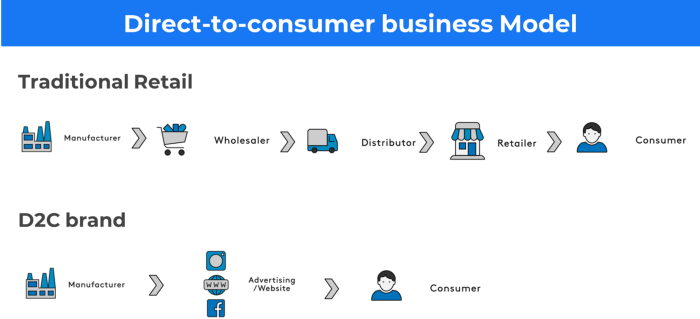
D2C brands can only expand via websites, marketplaces (Amazon, eBay), etc.
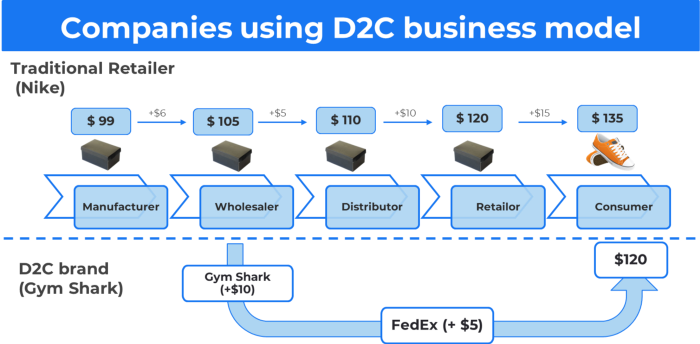
D2C benefits
Lower reliance on middlemen = greater profitability
You now have access to more precise demographic and geographic customer data.
Additional space for product testing
Increased customisation throughout your entire product line-Inventory Less
16. Business model: White Label vs. Private Label
Private label/White label products are made by a contract or third-party manufacturer.
Most amazon electronics are made in china and white-labeled.
Amazon supplements and electronics.
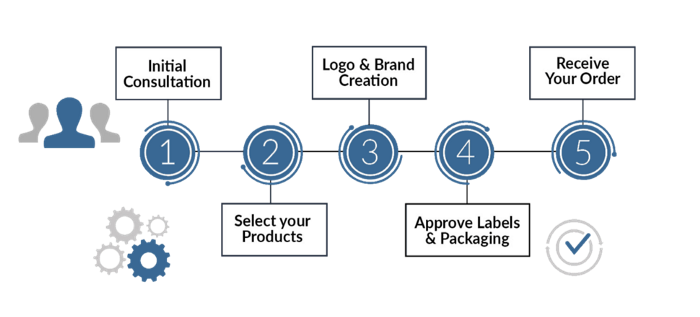
Contract manufacturers handle everything after brands select product quantities on design labels.
17. The franchise model
The franchisee uses the franchisor's trademark, branding, and business strategy (company).
For instance, KFC, Domino's, etc.
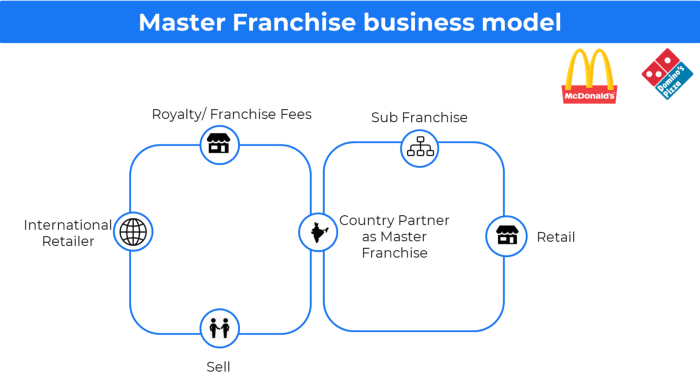
Subway, Domino, Burger King, etc. use this business strategy.

Many people pick a franchise because opening a restaurant is risky.
18. Ad-based business model
Social media and search engine giants exploit search and interest data to deliver adverts.
Google, Meta, TikTok, and Snapchat are some examples.
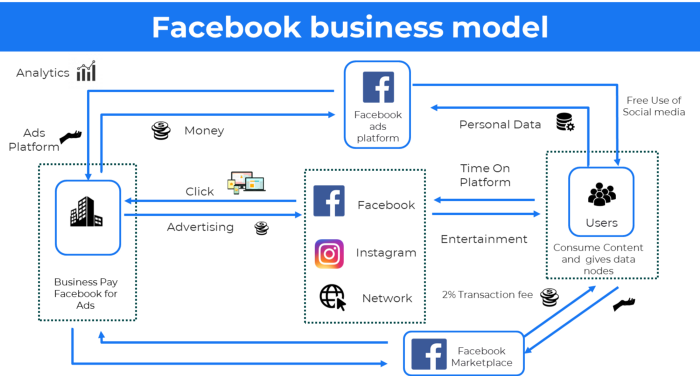
Users don't pay for the service or product given, e.g. Google users don't pay for searches.
In exchange, they collected data and hyper-personalized adverts to maximize revenue.
19. Business plan for octopuses
Each business unit functions separately but is connected to the main body.
Instance: Oyo

OYO is Asia's Airbnb, operating hotels, co-working, co-living, and vacation houses.
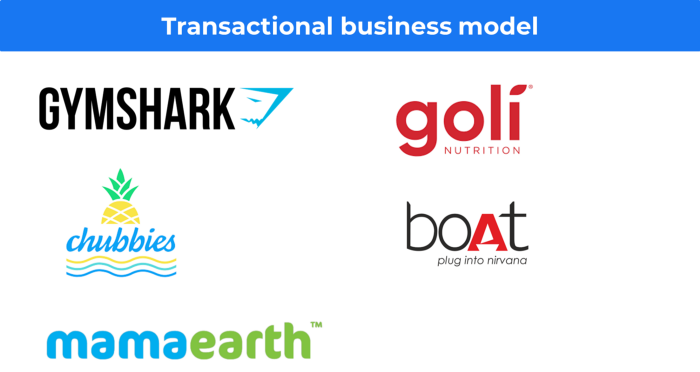
20, Transactional business model, number
Sales to customers produce revenue.
E-commerce sites and online purchases employ SSL.
Goli is an ex-GymShark.
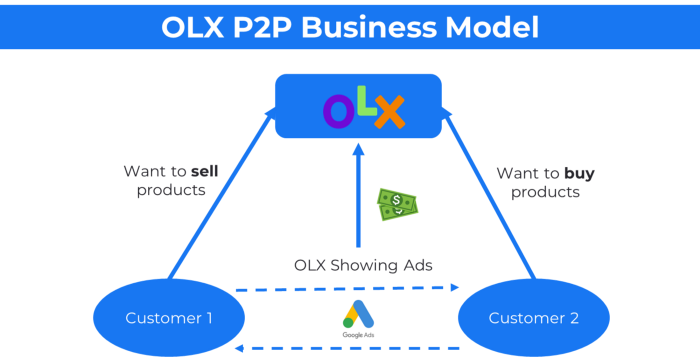
21. The peer-to-peer (P2P) business model
In P2P, two people buy and sell goods and services without a third party or platform.
Consider OLX.
22. P2P lending as a manner of operation
In P2P lending, one private individual (P2P Lender) lends/invests or borrows money from another (P2P Borrower).
Instance: Kabbage
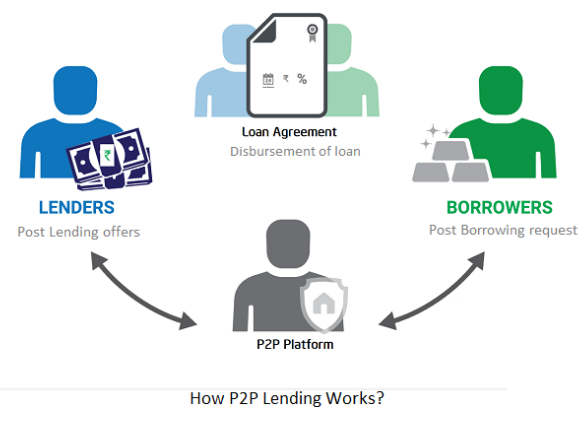
Social lending lets people lend and borrow money directly from each other without an intermediary financial institution.
23. A business model for brokers
Brokerages charge a commission or fee for their services.
Examples include eBay, Coinbase, and Robinhood.
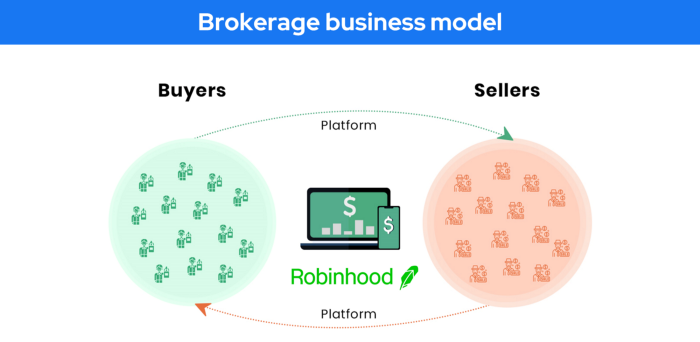
Brokerage businesses are common in Real estate, finance, and online and operate on this model.

Buy/sell similar models Examples include financial brokers, insurance brokers, and others who match purchase and sell transactions and charge a commission.
These brokers charge an advertiser a fee based on the date, place, size, or type of an advertisement. This is known as the classified-advertiser model. For instance, Craiglist
24. Drop shipping as an industry
Dropshipping allows stores to sell things without holding physical inventories.
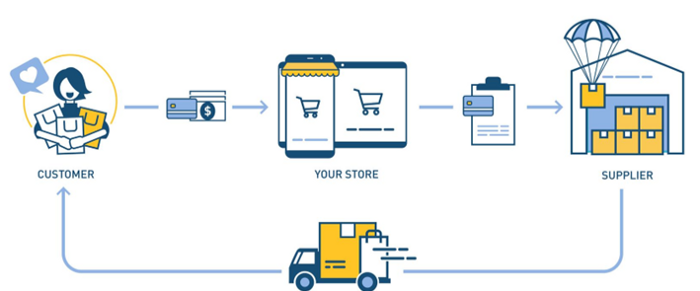
When a customer orders, use a third-party supplier and logistic partners.
Retailer product portfolio and customer experience Fulfiller The consumer places the order.
Dropshipping advantages
Less money is needed (Low overhead-No Inventory or warehousing)
Simple to start (costs under $100)
flexible work environment
New product testing is simpler
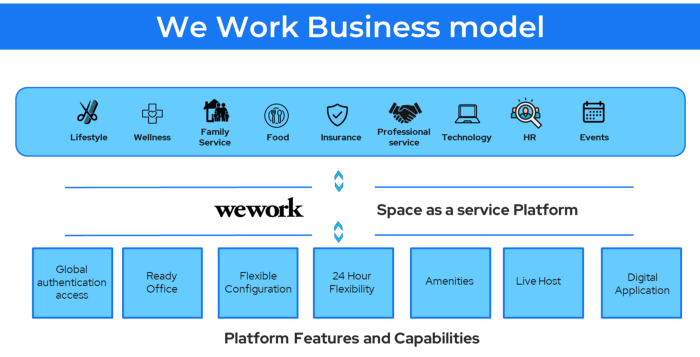
25. Business Model for Space as a Service
It's centered on a shared economy that lets millennials live or work in communal areas without ownership or lease.
Consider WeWork and Airbnb.
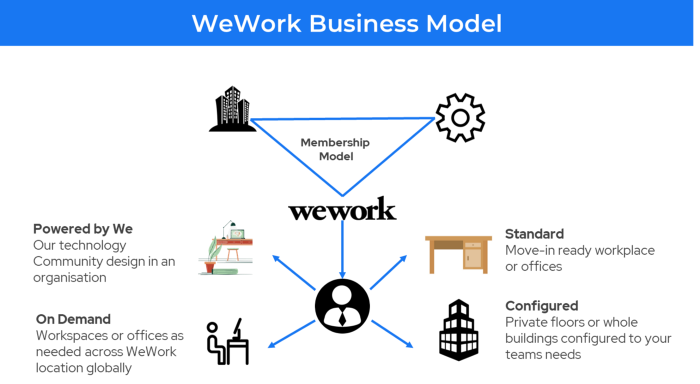
WeWork helps businesses with real estate, legal compliance, maintenance, and repair.
26. The business model for third-party logistics (3PL)
In 3PL, a business outsources product delivery, warehousing, and fulfillment to an external logistics company.
Examples include Ship Bob, Amazon Fulfillment, and more.

3PL partners warehouse, fulfill, and return inbound and outbound items for a charge.
Inbound logistics involves bringing products from suppliers to your warehouse.
Outbound logistics refers to a company's production line, warehouse, and customer.

27. The last-mile delivery paradigm as a commercial strategy
Last-mile delivery is the collection of supply chain actions that reach the end client.
Examples include Rappi, Gojek, and Postmates.
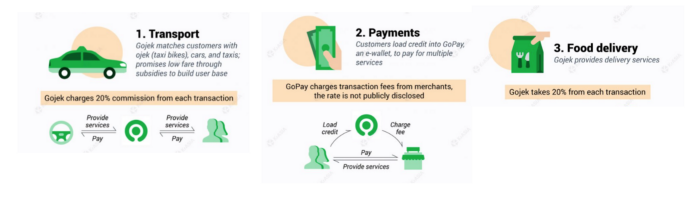
Last-mile is tied to on-demand and has a nighttime peak.
28. The use of affiliate marketing
Affiliate marketing involves promoting other companies' products and charging commissions.
Examples include Hubspot, Amazon, and Skillshare.

Your favorite youtube channel probably uses these short amazon links to get 5% of sales.
Affiliate marketing's benefits
In exchange for a success fee or commission, it enables numerous independent marketers to promote on its behalf.
Ensure system transparency by giving the influencers a specific tracking link and an online dashboard to view their profits.
Learn about the newest bargains and have access to promotional materials.
29. The business model for virtual goods
This is an in-app purchase for an intangible product.
Examples include PubG, Roblox, Candy Crush, etc.
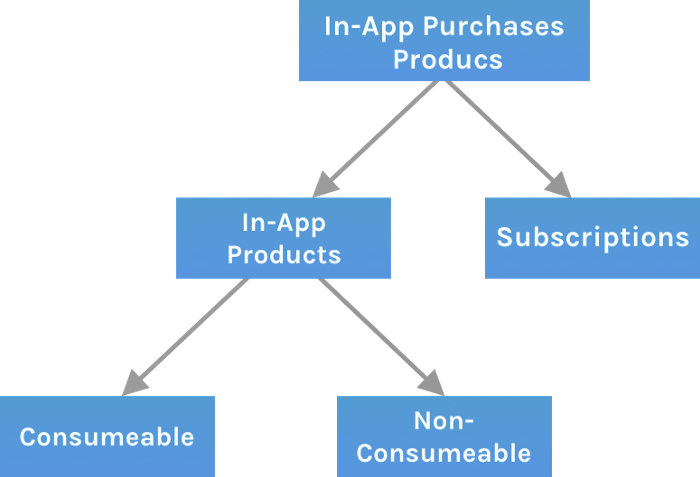
Consumables are like gaming cash that runs out. Non-consumable products provide a permanent advantage without repeated purchases.
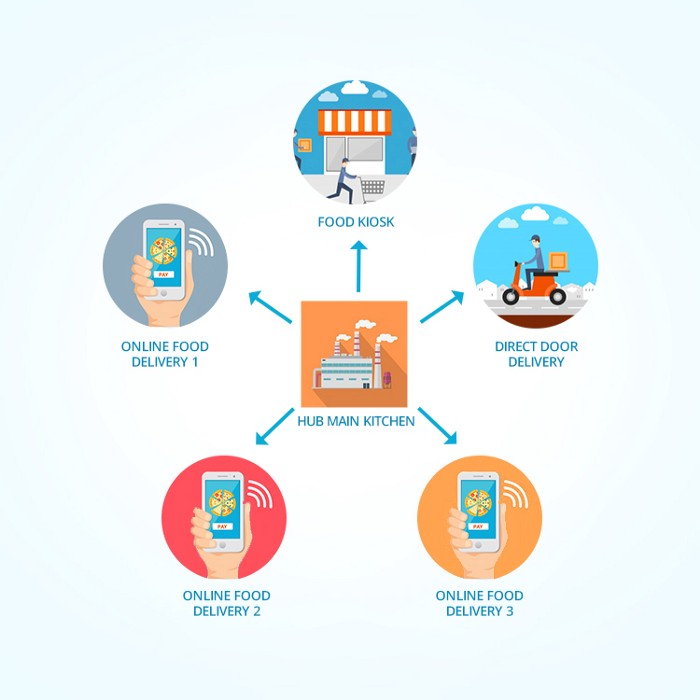
30. Business Models for Cloud Kitchens
Ghost, Dark, Black Box, etc.
Delivery-only restaurant.
These restaurants don't provide dine-in, only delivery.
For instance, NextBite and Faasos
31. Crowdsourcing as a Business Model
Crowdsourcing = Using the crowd as a platform's source.
In crowdsourcing, you get support from people around the world without hiring them.
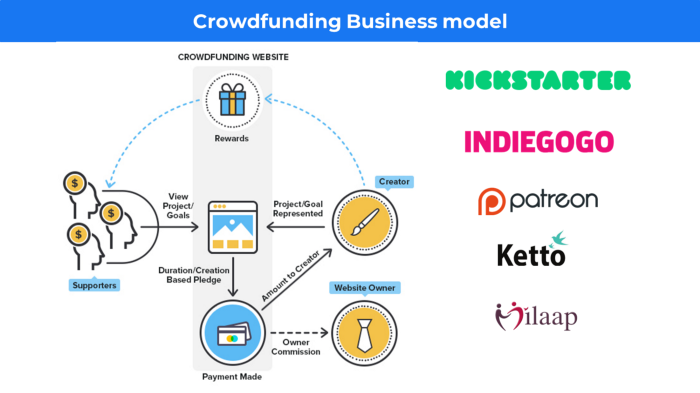
Crowdsourcing sites
Open-Source Software gives access to the software's source code so that developers can edit or enhance it. Examples include Firefox browsers and Linux operating systems.
Crowdfunding The oculus headgear would be an example of crowdfunding in essence, with no expectations.
You might also like

Jan-Patrick Barnert
3 years ago
Wall Street's Bear Market May Stick Around
If history is any guide, this bear market might be long and severe.
This is the S&P 500 Index's fourth such incident in 20 years. The last bear market of 2020 was a "shock trade" caused by the Covid-19 pandemic, although earlier ones in 2000 and 2008 took longer to bottom out and recover.
Peter Garnry, head of equities strategy at Saxo Bank A/S, compares the current selloff to the dotcom bust of 2000 and the 1973-1974 bear market marked by soaring oil prices connected to an OPEC oil embargo. He blamed high tech valuations and the commodity crises.
"This drop might stretch over a year and reach 35%," Garnry wrote.
Here are six bear market charts.
Time/depth
The S&P 500 Index plummeted 51% between 2000 and 2002 and 58% during the global financial crisis; it took more than 1,000 trading days to recover. The former took 638 days to reach a bottom, while the latter took 352 days, suggesting the present selloff is young.
Valuations
Before the tech bubble burst in 2000, valuations were high. The S&P 500's forward P/E was 25 times then. Before the market fell this year, ahead values were near 24. Before the global financial crisis, stocks were relatively inexpensive, but valuations dropped more than 40%, compared to less than 30% now.
Earnings
Every stock crash, especially earlier bear markets, returned stocks to fundamentals. The S&P 500 decouples from earnings trends but eventually recouples.
Support
Central banks won't support equity investors just now. The end of massive monetary easing will terminate a two-year bull run that was among the strongest ever, and equities may struggle without cheap money. After years of "don't fight the Fed," investors must embrace a new strategy.
Bear Haunting Bear
If the past is any indication, rising government bond yields are bad news. After the financial crisis, skyrocketing rates and a falling euro pushed European stock markets back into bear territory in 2011.
Inflation/rates
The current monetary policy climate differs from past bear markets. This is the first time in a while that markets face significant inflation and rising rates.
This post is a summary. Read full article here

Caspar Mahoney
3 years ago
Changing Your Mindset From a Project to a Product
Product game mindsets? How do these vary from Project mindset?
1950s spawned the Iron Triangle. Project people everywhere know and live by it. In stakeholder meetings, it is used to stretch the timeframe, request additional money, or reduce scope.
Quality was added to this triangle as things matured.
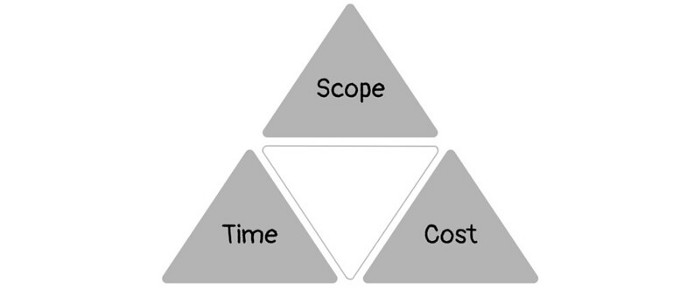
Quality was intended to be transformative, but none of these principles addressed why we conduct projects.
Value and benefits are key.
Product value is quantified by ROI, revenue, profit, savings, or other metrics. For me, every project or product delivery is about value.
Most project managers, especially those schooled 5-10 years or more ago (thousands working in huge corporations worldwide), understand the world in terms of the iron triangle. What does that imply? They worry about:
a) enough time to get the thing done.
b) have enough resources (budget) to get the thing done.
c) have enough scope to fit within (a) and (b) >> note, they never have too little scope, not that I have ever seen! although, theoretically, this could happen.
Boom—iron triangle.
To make the triangle function, project managers will utilize formal governance (Steering) to move those things. Increase money, scope, or both if time is short. Lacking funds? Increase time, scope, or both.
In current product development, shifting each item considerably may not yield value/benefit.
Even terrible. This approach will fail because it deprioritizes Value/Benefit by focusing the major stakeholders (Steering participants) and delivery team(s) on Time, Scope, and Budget restrictions.
Pre-agile, this problem was terrible. IT projects failed wildly. History is here.
Value, or benefit, is central to the product method. Product managers spend most of their time planning value-delivery paths.
Product people consider risk, schedules, scope, and budget, but value comes first. Let me illustrate.
Imagine managing internal products in an enterprise. Your core customer team needs a rapid text record of a chat to fix a problem. The consumer wants a feature/features added to a product you're producing because they think it's the greatest spot.
Project-minded, I may say;
Ok, I have budget as this is an existing project, due to run for a year. This is a new requirement to add to the features we’re already building. I think I can keep the deadline, and include this scope, as it sounds related to the feature set we’re building to give the desired result”.
This attitude repeats Scope, Time, and Budget.
Since it meets those standards, a project manager will likely approve it. If they have a backlog, they may add it and start specking it out assuming it will be built.
Instead, think like a product;
What problem does this feature idea solve? Is that problem relevant to the product I am building? Can that problem be solved quicker/better via another route ? Is it the most valuable problem to solve now? Is the problem space aligned to our current or future strategy? or do I need to alter/update the strategy?
A product mindset allows you to focus on timing, resource/cost, feasibility, feature detail, and so on after answering the aforementioned questions.
The above oversimplifies because
Leadership in discovery

Project managers are facilitators of ideas. This is as far as they normally go in the ‘idea’ space.
Business Requirements collection in classic project delivery requires extensive upfront documentation.
Agile project delivery analyzes requirements iteratively.
However, the project manager is a facilitator/planner first and foremost, therefore topic knowledge is not expected.
I mean business domain, not technical domain (to confuse matters, it is true that in some instances, it can be both technical and business domains that are important for a single individual to master).
Product managers are domain experts. They will become one if they are training/new.
They lead discovery.
Product Manager-led discovery is much more than requirements gathering.
Requirements gathering involves a Business Analyst interviewing people and documenting their requests.
The project manager calculates what fits and what doesn't using their Iron Triangle (presumably in their head) and reports back to Steering.
If this requirements-gathering exercise failed to identify requirements, what would a project manager do? or bewildered by project requirements and scope?
They would tell Steering they need a Business SME or Business Lead assigning or more of their time.
Product discovery requires the Product Manager's subject knowledge and a new mindset.
How should a Product Manager handle confusing requirements?
Product Managers handle these challenges with their talents and tools. They use their own knowledge to fill in ambiguity, but they have the discipline to validate those assumptions.
To define the problem, they may perform qualitative or quantitative primary research.
They might discuss with UX and Engineering on a whiteboard and test assumptions or hypotheses.
Do Product Managers escalate confusing requirements to Steering/Senior leaders? They would fix that themselves.
Product managers raise unclear strategy and outcomes to senior stakeholders. Open talks, soft skills, and data help them do this. They rarely raise requirements since they have their own means of handling them without top stakeholder participation.
Discovery is greenfield, exploratory, research-based, and needs higher-order stakeholder management, user research, and UX expertise.
Product Managers also aid discovery. They lead discovery. They will not leave customer/user engagement to a Business Analyst. Administratively, a business analyst could aid. In fact, many product organizations discourage business analysts (rely on PM, UX, and engineer involvement with end-users instead).
The Product Manager must drive user interaction, research, ideation, and problem analysis, therefore a Product professional must be skilled and confident.
Creating vs. receiving and having an entrepreneurial attitude

Product novices and project managers focus on details rather than the big picture. Project managers prefer spreadsheets to strategy whiteboards and vision statements.
These folks ask their manager or senior stakeholders, "What should we do?"
They then elaborate (in Jira, in XLS, in Confluence or whatever).
They want that plan populated fast because it reduces uncertainty about what's going on and who's supposed to do what.
Skilled Product Managers don't only ask folks Should we?
They're suggesting this, or worse, Senior stakeholders, here are some options. After asking and researching, they determine what value this product adds, what problems it solves, and what behavior it changes.
Therefore, to move into Product, you need to broaden your view and have courage in your ability to discover ideas, find insightful pieces of information, and collate them to form a valuable plan of action. You are constantly defining RoI and building Business Cases, so much so that you no longer create documents called Business Cases, it is simply ingrained in your work through metrics, intelligence, and insights.
Product Management is not a free lunch.
Plateless.
Plates and food must be prepared.
In conclusion, Product Managers must make at least three mentality shifts:
You put value first in all things. Time, money, and scope are not as important as knowing what is valuable.
You have faith in the field and have the ability to direct the search. YYou facilitate, but you don’t just facilitate. You wouldn't want to limit your domain expertise in that manner.
You develop concepts, strategies, and vision. You are not a waiter or an inbox where other people can post suggestions; you don't merely ask folks for opinion and record it. However, you excel at giving things that aren't clearly spoken or written down physical form.

Jano le Roux
3 years ago
My Top 11 Tools For Building A Modern Startup, With A Free Plan
The best free tools are probably unknown to you.
Modern startups are easy to build.
Start with free tools.
Let’s go.
Web development — Webflow
Code-free HTML, CSS, and JS.
Webflow isn't like Squarespace, Wix, or Shopify.
It's a super-fast no-code tool for professionals to construct complex, highly-responsive websites and landing pages.
Webflow can help you add animations like those on Apple's website to your own site.
I made the jump from WordPress a few years ago and it changed my life.
No damn plugins. No damn errors. No damn updates.
The best, you can get started on Webflow for free.
Data tracking — Airtable
Spreadsheet wings.
Airtable combines spreadsheet flexibility with database power without code.
Airtable is modern.
Airtable has modularity.
Scaling Airtable is simple.
Airtable, one of the most adaptable solutions on this list, is perfect for client data management.
Clients choose customized service packages. Airtable consolidates data so you can automate procedures like invoice management and focus on your strengths.
Airtable connects with so many tools that rarely creates headaches. Airtable scales when you do.
Airtable's flexibility makes it a potential backend database.
Design — Figma
Better, faster, easier user interface design.
Figma rocks!
It’s fast.
It's free.
It's adaptable
First, design in Figma.
Iterate.
Export development assets.
Figma lets you add more team members as your company grows to work on each iteration simultaneously.
Figma is web-based, so you don't need a powerful PC or Mac to start.
Task management — Trello
Unclock jobs.
Tacky and terrifying task management products abound. Trello isn’t.
Those that follow Marie Kondo will appreciate Trello.
Everything is clean.
Nothing is complicated.
Everything has a place.
Compared to other task management solutions, Trello is limited. And that’s good. Too many buttons lead to too many decisions lead to too many hours wasted.
Trello is a must for teamwork.
Domain email — Zoho
Free domain email hosting.
Professional email is essential for startups. People relied on monthly payments for too long. Nope.
Zoho offers 5 free professional emails.
It doesn't have Google's UI, but it works.
VPN — Proton VPN
Fast Swiss VPN protects your data and privacy.
Proton VPN is secure.
Proton doesn't record any data.
Proton is based in Switzerland.
Swiss privacy regulation is among the most strict in the world, therefore user data are protected. Switzerland isn't a 14 eye country.
Journalists and activists trust Proton to secure their identities while accessing and sharing information authoritarian governments don't want them to access.
Web host — Netlify
Free fast web hosting.
Netlify is a scalable platform that combines your favorite tools and APIs to develop high-performance sites, stores, and apps through GitHub.
Serverless functions and environment variables preserve API keys.
Netlify's free tier is unmissable.
100GB of free monthly bandwidth.
Free 125k serverless operations per website each month.
Database — MongoDB
Create a fast, scalable database.
MongoDB is for small and large databases. It's a fast and inexpensive database.
Free for the first million reads.
Then, for each million reads, you must pay $0.10.
MongoDB's free plan has:
Encryption from end to end
Continual authentication
field-level client-side encryption
If you have a large database, you can easily connect MongoDB to Webflow to bypass CMS limits.
Automation — Zapier
Time-saving tip: automate repetitive chores.
Zapier simplifies life.
Zapier syncs and connects your favorite apps to do impossibly awesome things.
If your online store is connected to Zapier, a customer's purchase can trigger a number of automated actions, such as:
The customer is being added to an email chain.
Put the information in your Airtable.
Send a pre-programmed postcard to the customer.
Alexa, set the color of your smart lights to purple.
Zapier scales when you do.
Email & SMS marketing — Omnisend
Email and SMS marketing campaigns.
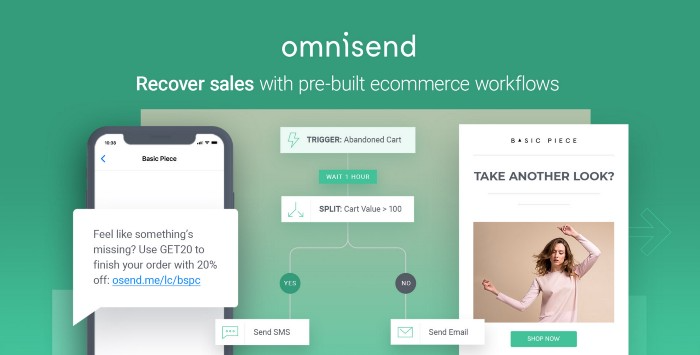
This is an excellent Mailchimp option for magical emails. Omnisend's processes simplify email automation.
I love the interface's cleanliness.
Omnisend's free tier includes web push notifications.
Send up to:
500 emails per month
60 maximum SMSs
500 Web Push Maximum
Forms and surveys — Tally
Create flexible forms that people enjoy.
Typeform is clean but restricting. Sometimes you need to add many questions. Tally's needed sometimes.
Tally is flexible and cheaper than Typeform.
99% of Tally's features are free and unrestricted, including:
Unlimited forms
Countless submissions
Collect payments
File upload
Tally lets you examine what individuals contributed to forms before submitting them to see where they get stuck.
Airtable and Zapier connectors automate things further. If you pay, you can apply custom CSS to fit your brand.
See.
Free tools are the greatest.
Let's use them to launch a startup.