


Jack Dorsey and Jay-Z Launch 'Bitcoin Academy' in Brooklyn rapper's home
The new Bitcoin Academy will teach Jay-Marcy Z's Houses neighbors "What is Cryptocurrency."
Jay-Z grew up in Brooklyn's Marcy Houses. The rapper and Block CEO Jack Dorsey are giving back to his hometown by creating the Bitcoin Academy.
The Bitcoin Academy will offer online and in-person classes, including "What is Money?" and "What is Blockchain?"
The program will provide participants with a mobile hotspot and a small amount of Bitcoin for hands-on learning.
Students will receive dinner and two evenings of instruction until early September. The Shawn Carter Foundation will help with on-the-ground instruction.
Jay-Z and Dorsey announced the program Thursday morning. It will begin at Marcy Houses but may be expanded.
Crypto Blockchain Plug and Black Bitcoin Billionaire, which has received a grant from Block, will teach the classes.
Jay-Z, Dorsey reunite
Jay-Z and Dorsey have previously worked together to promote a Bitcoin and crypto-based future.
In 2021, Dorsey's Block (then Square) acquired the rapper's streaming music service Tidal, which they propose using for NFT distribution.
Dorsey and Jay-Z launched an endowment in 2021 to fund Bitcoin development in Africa and India.
Dorsey is funding the new Bitcoin Academy out of his own pocket (as is Jay-Z), but he's also pushed crypto-related charitable endeavors at Block, including a $5 million fund backed by corporate Bitcoin interest.
This post is a summary. Read full article here
More on Web3 & Crypto

Dylan Smyth
4 years ago
10 Ways to Make Money Online in 2022
As a tech-savvy person (and software engineer) or just a casual technology user, I'm sure you've had this same question countless times: How do I make money online? and how do I make money with my PC/Mac?
You're in luck! Today, I will list the top 5 easiest ways to make money online. Maybe a top ten in the future? Top 5 tips for 2022.
1. Using the gig economy
There are many websites on the internet that allow you to earn extra money using skills and equipment that you already own.
I'm referring to the gig economy. It's a great way to earn a steady passive income from the comfort of your own home. For some sites, premium subscriptions are available to increase sales and access features like bidding on more proposals.
Some of these are:
- Freelancer
- Upwork
- Fiverr (⭐ my personal favorite)
- TaskRabbit
2. Mineprize
MINEPRIZE is a great way to make money online. What's more, You need not do anything! You earn money by lending your idle CPU power to MINEPRIZE.
To register with MINEPRIZE, all you need is an email address and a password. Let MINEPRIZE use your resources, and watch the money roll in! You can earn up to $100 per month by letting your computer calculate. That's insane.
3. Writing
“O Romeo, Romeo, why art thou Romeo?” Okay, I admit that not all writing is Shakespearean. To be a copywriter, you'll need to be fluent in English. Thankfully, we don't have to use typewriters anymore.
Writing is a skill that can earn you a lot of money (claps for the rhyme).
Here are a few ways you can make money typing on your fancy keyboard:
Self-publish a book
Write scripts for video creators
Write for social media
Book-checking
Content marketing help
What a list within a list!
4. Coding
Yes, kids. You've probably coded before if you understand
You've probably coded before if you understand
print("hello world");
Computational thinking (or coding) is one of the most lucrative ways to earn extra money, or even as a main source of income.
Of course, there are hardcode coders (like me) who write everything line by line, binary di — okay, that last part is a bit exaggerated.
But you can also make money by writing websites or apps or creating low code or no code platforms.
But you can also make money by writing websites or apps or creating low code or no code platforms.
Some low-code platforms
Sheet : spreadsheets to apps :
Loading... We'll install your new app... No-Code Your team can create apps and automate tasks. Agile…
www.appsheet.com
Low-code platform | Business app creator - Zoho Creator
Work is going digital, and businesses of all sizes must adapt quickly. Zoho Creator is a...
www.zoho.com
Sell your data with TrueSource. NO CODE NEEDED
Upload data, configure your product, and earn in minutes.
www.truesource.io
Cool, huh?
5. Created Content
If we use the internet correctly, we can gain unfathomable wealth and extra money. But this one is a bit more difficult. Unlike some of the other items on this list, it takes a lot of time up front.
I'm referring to sites like YouTube and Medium. It's a great way to earn money both passively and actively. With the likes of Jake- and Logan Paul, PewDiePie (a.k.a. Felix Kjellberg) and others, it's never too late to become a millionaire on YouTube. YouTubers are always rising to the top with great content.
6. NFTs and Cryptocurrency
It is now possible to amass large sums of money by buying and selling digital assets on NFTs and cryptocurrency exchanges. Binance's Initial Game Offer rewards early investors who produce the best results.
One awesome game sold a piece of its plot for US$7.2 million! It's Axie Infinity. It's free and available on Google Play and Apple Store.
7. Affiliate Marketing
Affiliate marketing is a form of advertising where businesses pay others (like bloggers) to promote their goods and services. Here's an example. I write a blog (like this one) and post an affiliate link to an item I recommend buying — say, a camera — and if you buy the camera, I get a commission!
These programs pay well:
- Elementor
- AWeber
- Sendinblue
- ConvertKit\sLeadpages
- GetResponse
- SEMRush\sFiverr
- Pabbly
8. Start a blog
Now, if you're a writer or just really passionate about something or a niche, blogging could potentially monetize that passion!
Create a blog about anything you can think of. It's okay to start right here on Medium, as I did.
9. Dropshipping
And I mean that in the best possible way — drop shopping is ridiculously easy to set up, but difficult to maintain for some.
Luckily, Shopify has made setting up an online store a breeze. Drop-shipping from Alibaba and DHGate is quite common. You've got a winner if you can find a local distributor willing to let you drop ship their product!
10. Set up an Online Course
If you have a skill and can articulate it, online education is for you.
Skillshare, Pluralsight, and Coursera have all made inroads in recent years, upskilling people with courses that YOU can create and earn from.
That's it for today! Please share if you liked this post. If not, well —

TheRedKnight
3 years ago
Say goodbye to Ponzi yields - A new era of decentralized perpetual
Decentralized perpetual may be the next crypto market boom; with tons of perpetual popping up, let's look at two protocols that offer organic, non-inflationary yields.
Decentralized derivatives exchanges' market share has increased tenfold in a year, but it's still 2% of CEXs'. DEXs have a long way to go before they can compete with centralized exchanges in speed, liquidity, user experience, and composability.
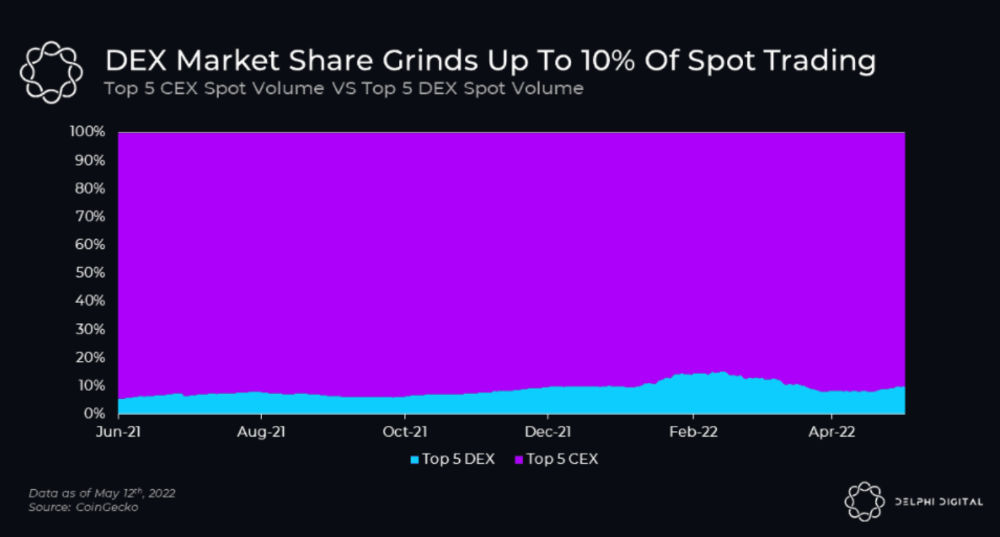
I'll cover gains.trade and GMX protocol in Polygon, Avalanche, and Arbitrum. Both protocols support leveraged perpetual crypto, stock, and Forex trading.
Why these protocols?
Decentralized GMX Gains protocol
Organic yield: path to sustainability
I've never trusted Defi's non-organic yields. Example: XYZ protocol. 20–75% of tokens may be set aside as farming rewards to provide liquidity, according to tokenomics.
Say you provide ETH-USDC liquidity. They advertise a 50% APR reward for this pair, 10% from trading fees and 40% from farming rewards. Only 10% is real, the rest is "Ponzi." The "real" reward is in protocol tokens.
Why keep this token? Governance voting or staking rewards are promoted services.
Most liquidity providers expect compensation for unused tokens. Basic psychological principles then? — Profit.
Nobody wants governance tokens. How many out of 100 care about the protocol's direction and will vote?
Staking increases your token's value. Currently, they're mostly non-liquid. If the protocol is compromised, you can't withdraw funds. Most people are sceptical of staking because of this.
"Free tokens," lack of use cases, and skepticism lead to tokens moving south. No farming reward protocols have lasted.
It may have shown strength in a bull market, but what about a bear market?
What is decentralized perpetual?
A perpetual contract is a type of futures contract that doesn't expire. So one can hold a position forever.
You can buy/sell any leveraged instruments (Long-Short) without expiration.
In centralized exchanges like Binance and coinbase, fees and revenue (liquidation) go to the exchanges, not users.
Users can provide liquidity that traders can use to leverage trade, and the revenue goes to liquidity providers.
Gains.trade and GMX protocol are perpetual trading platforms with a non-inflationary organic yield for liquidity providers.
GMX protocol
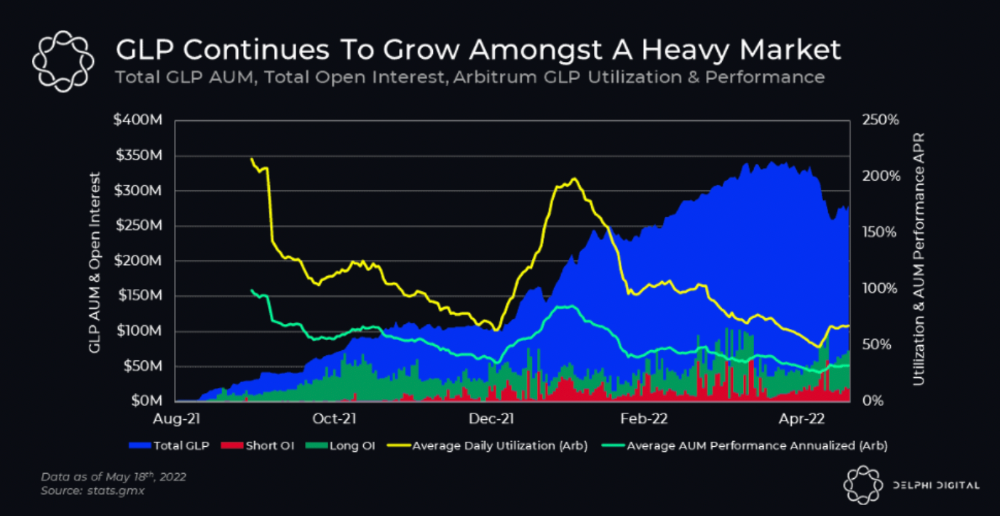
GMX is an Arbitrum and Avax protocol that rewards in ETH and Avax. GLP uses a fast oracle to borrow the "true price" from other trading venues, unlike a traditional AMM.
GLP and GMX are protocol tokens. GLP is used for leveraged trading, swapping, etc.
GLP is a basket of tokens, including ETH, BTC, AVAX, stablecoins, and UNI, LINK, and Stablecoins.
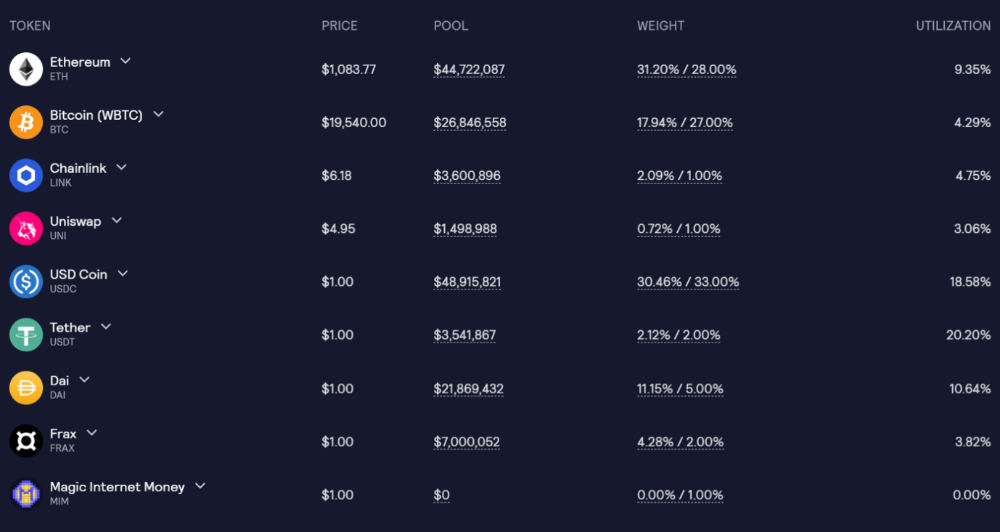
GLP composition on arbitrum
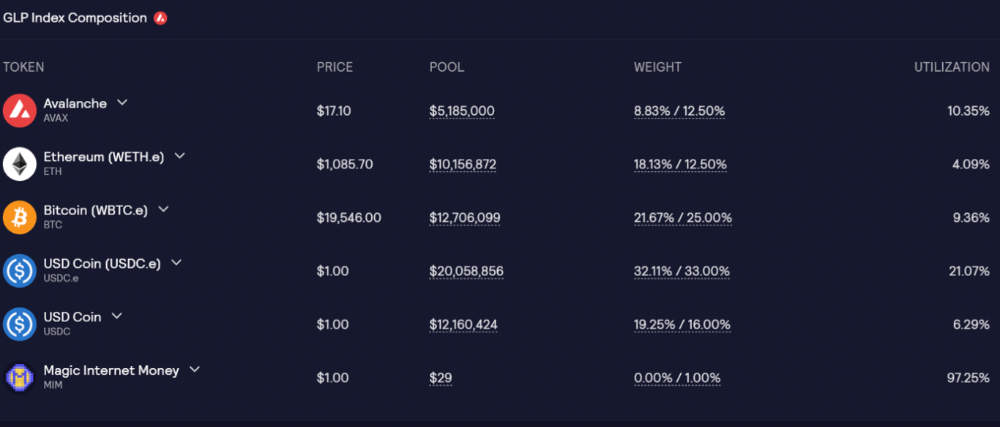
GLP composition on Avalanche
GLP token rebalances based on usage, providing liquidity without loss.
Protocol "runs" on Staking GLP. Depending on their chain, the protocol will reward users with ETH or AVAX. Current rewards are 22 percent (15.71 percent in ETH and the rest in escrowed GMX) and 21 percent (15.72 percent in AVAX and the rest in escrowed GMX). escGMX and ETH/AVAX percentages fluctuate.
Where is the yield coming from?
Swap fees, perpetual interest, and liquidations generate yield. 70% of fees go to GLP stakers, 30% to GMX. Organic yields aren't paid in inflationary farm tokens.
Escrowed GMX is vested GMX that unlocks in 365 days. To fully unlock GMX, you must farm the Escrowed GMX token for 365 days. That means less selling pressure for the GMX token.
GMX's status
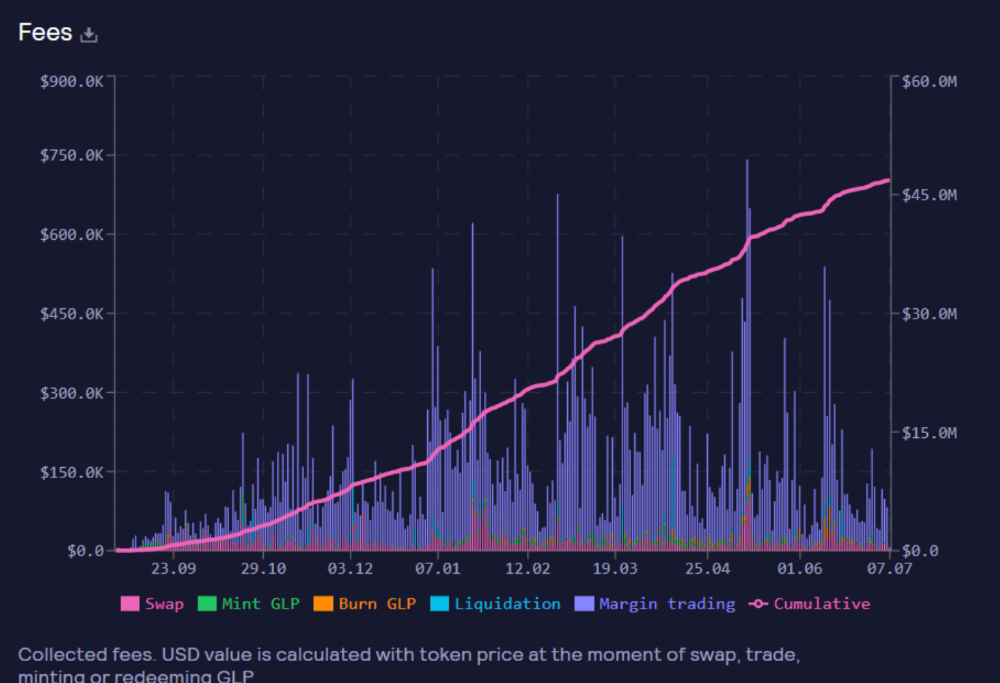
These are the fees in Arbitrum in the past 11 months by GMX.
GMX works like a casino, which increases fees. Most fees come from Margin trading, which means most traders lose money; this money goes to the casino, or GLP stakers.
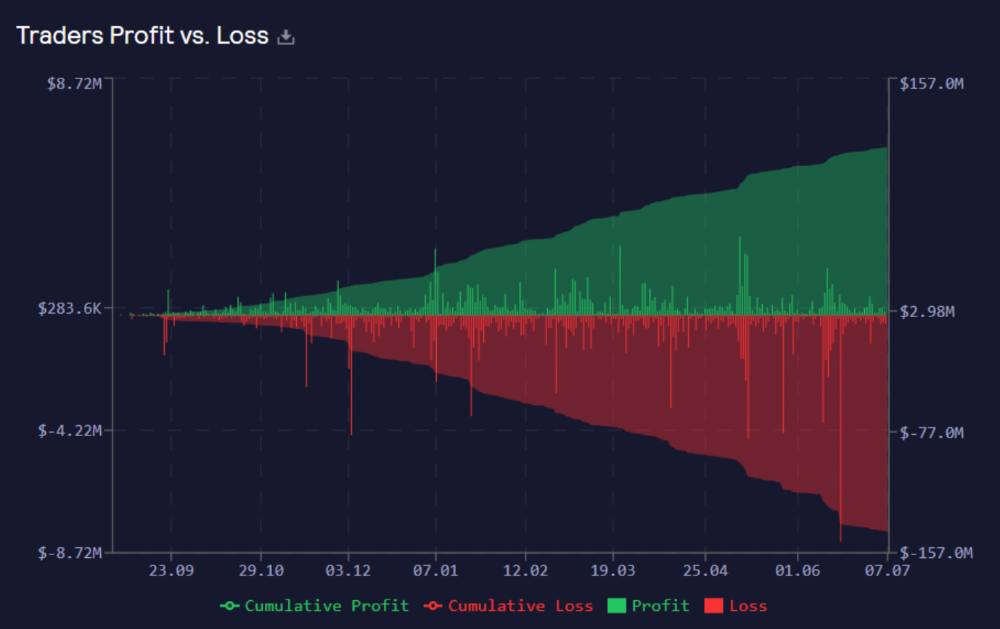
Strategies
My personal strategy is to DCA into GLP when markets hit bottom and stake it; GLP will be less volatile with extra staking rewards.
GLP YoY return vs. naked buying
Let's say I invested $10,000 in BTC, AVAX, and ETH in January.
BTC price: 47665$
ETH price: 3760$
AVAX price: $145
Current prices
BTC $21,000 (Down 56 percent )
ETH $1233 (Down 67.2 percent )
AVAX $20.36 (Down 85.95 percent )
Your $10,000 investment is now worth around $3,000.
How about GLP? My initial investment is 50% stables and 50% other assets ( Assuming the coverage ratio for stables is 50 percent at that time)
Without GLP staking yield, your value is $6500.
Let's assume the average APR for GLP staking is 23%, or $1500. So 8000$ total. It's 50% safer than holding naked assets in a bear market.
In a bull market, naked assets are preferable to GLP.
Short farming using GLP
Simple GLP short farming.
You use a stable asset as collateral to borrow AVAX. Sell it and buy GLP. Even if GLP rises, it won't rise as fast as AVAX, so we can get yields.
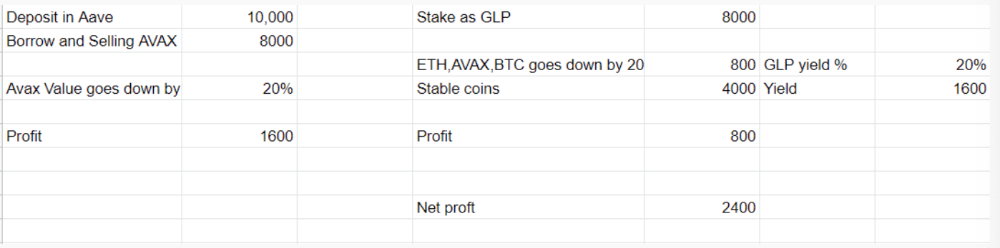
Let's do the maths
You deposit $10,000 USDT in Aave and borrow Avax. Say you borrow $8,000; you sell it, buy GLP, and risk 20%.
After a year, ETH, AVAX, and BTC rise 20%. GLP is $8800. $800 vanishes. 20% yields $1600. You're profitable. Shorting Avax costs $1600. (Assumptions-ETH, AVAX, BTC move the same, GLP yield is 20%. GLP has a 50:50 stablecoin/others ratio. Aave won't liquidate
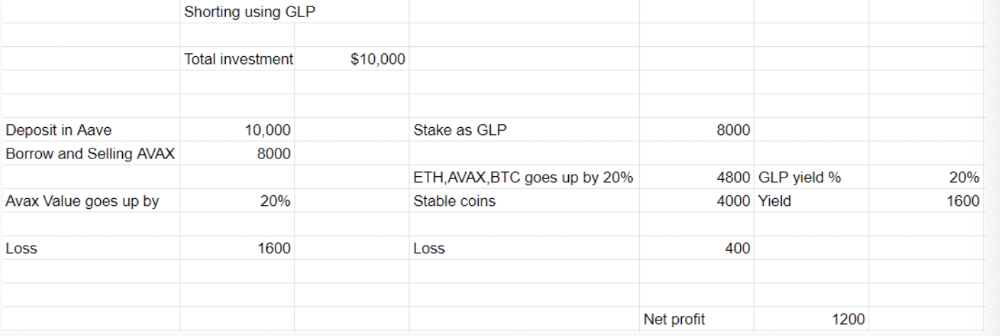
In naked Avax shorting, Avax falls 20% in a year. You'll make $1600. If you buy GLP and stake it using the sold Avax and BTC, ETH and Avax go down by 20% - your profit is 20%, but with the yield, your total gain is $2400.
Issues with GMX
GMX's historical funding rates are always net positive, so long always pays short. This makes long-term shorts less appealing.
Oracle price discovery isn't enough. This limitation doesn't affect Bitcoin and ETH, but it affects less liquid assets. Traders can buy and sell less liquid assets at a lower price than their actual cost as long as GMX exists.
As users must provide GLP liquidity, adding more assets to GMX will be difficult. Next iteration will have synthetic assets.
Gains Protocol
Best leveraged trading platform. Smart contract-based decentralized protocol. 46 crypto pairs can be leveraged 5–150x and 10 Forex pairs 5–1000x. $10 DAI @ 150x (min collateral x leverage pos size is $1500 DAI). No funding fees, no KYC, trade DAI from your wallet, keep funds.
DAI single-sided staking and the GNS-DAI pool are important parts of Gains trading. GNS-DAI stakers get 90% of trading fees and 100% swap fees. 10 percent of trading fees go to DAI stakers, which is currently 14 percent!
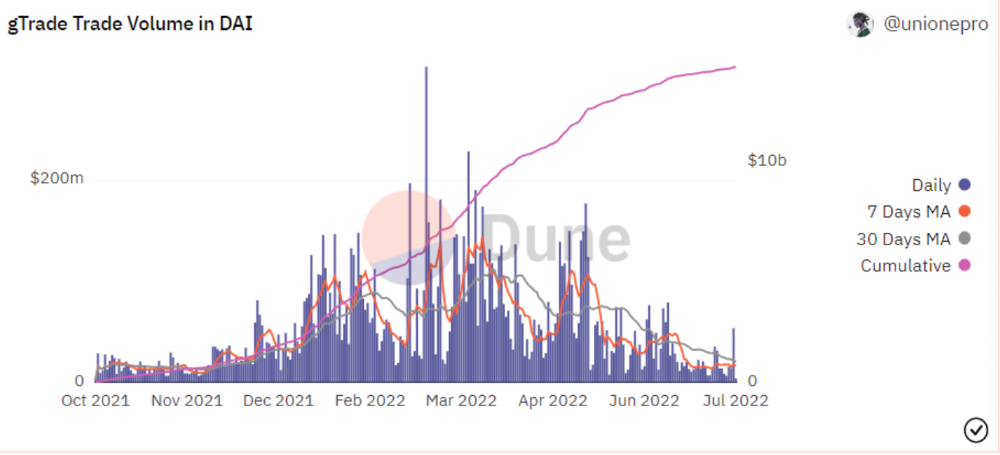
Trade volume
When a trader opens a trade, the leverage and profit are pulled from the DAI pool. If he loses, the protocol yield goes to the stakers.
If the trader's win rate is high and the DAI pool slowly depletes, the GNS token is minted and sold to refill DAI. Trader losses are used to burn GNS tokens. 25%+ of GNS is burned, making it deflationary.
Due to high leverage and volatility of crypto assets, most traders lose money and the protocol always wins, keeping GNS deflationary.
Gains uses a unique decentralized oracle for price feeds, which is better for leverage trading platforms. Let me explain.
Gains uses chainlink price oracles, not its own price feeds. Chainlink oracles only query centralized exchanges for price feeds every minute, which is unsuitable for high-precision trading.
Gains created a custom oracle that queries the eight chainlink nodes for the current price and, on average, for trade confirmation. This model eliminates every-second inquiries, which waste gas but are more efficient than chainlink's per-minute price.
This price oracle helps Gains open and close trades instantly, eliminate scam wicks, etc.
Other benefits include:
Stop-loss guarantee (open positions updated)
No scam wicks
Spot-pricing
Highest possible leverage
Fixed-spreads. During high volatility, a broker can increase the spread, which can hit your stop loss without the price moving.
Trade directly from your wallet and keep your funds.
>90% loss before liquidation (Some platforms liquidate as little as -50 percent)
KYC-free
Directly trade from wallet; keep funds safe
Further improvements
GNS-DAI liquidity providers fear the impermanent loss, so the protocol is migrating to its own liquidity and single staking GNS vaults. This allows users to stake GNS without permanent loss and obtain 90% DAI trading fees by staking. This starts in August.
Their upcoming improvements can be found here.
Gains constantly add new features and change pairs. It's an interesting protocol.
Conclusion
Next bull run, watch decentralized perpetual protocols. Effective tokenomics and non-inflationary yields may attract traders and liquidity providers. But still, there is a long way for them to develop, and I don't see them tackling the centralized exchanges any time soon until they fix their inherent problems and improve fast enough.
Read the full post here.

Crypto Zen Monk
2 years ago
How to DYOR in the world of cryptocurrency
RESEARCH
We must create separate ideas and handle our own risks to be better investors. DYOR is crucial.
The only thing unsustainable is your cluelessness.
DYOR: Why
On social media, there is a lot of false information and divergent viewpoints. All of these facts might be accurate, but they might not be appropriate for your portfolio and investment preferences.
You become a more knowledgeable investor thanks to DYOR.
DYOR improves your portfolio's risk management.
My DYOR resources are below.

Messari: Major Blockchains' Activities
New York-based Messari provides cryptocurrency open data libraries.
Major blockchains offer 24-hour on-chain volume. https://messari.io/screener/most-active-chains-DB01F96B
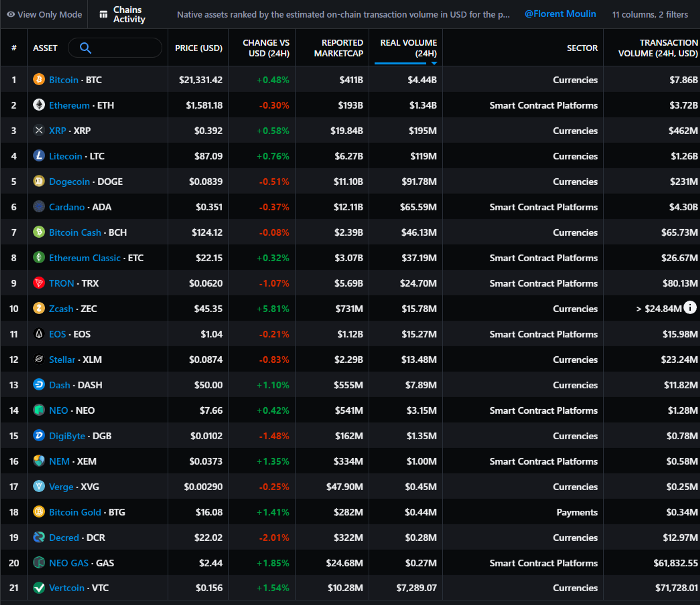
What to do
Invest in stable cryptocurrencies. Sort Messari by Real Volume (24H) or Reported Market Cap.
Coingecko: Research on Ecosystems
Top 10 Ecosystems by Coingecko are good.
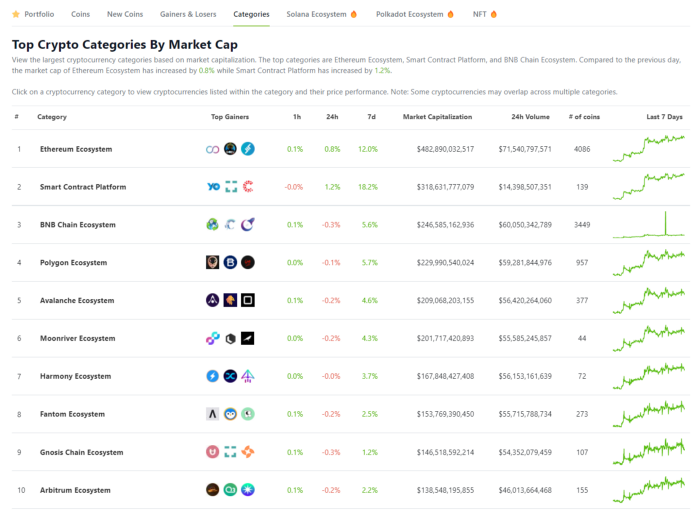
What to do
Invest in quality.
Leading ten Ecosystems by Market Cap
There are a lot of coins in the ecosystem (second last column of above chart)
CoinGecko's Market Cap Crypto Categories Market capitalization-based cryptocurrency categories. Ethereum Ecosystem www.coingecko.com
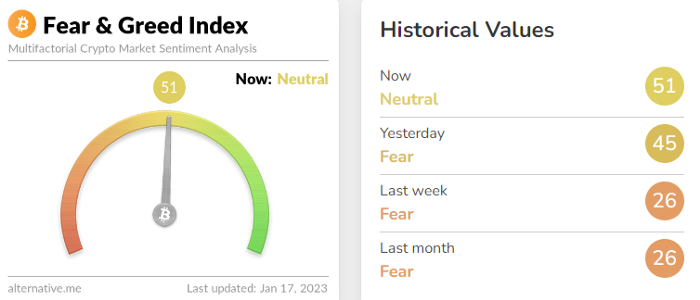
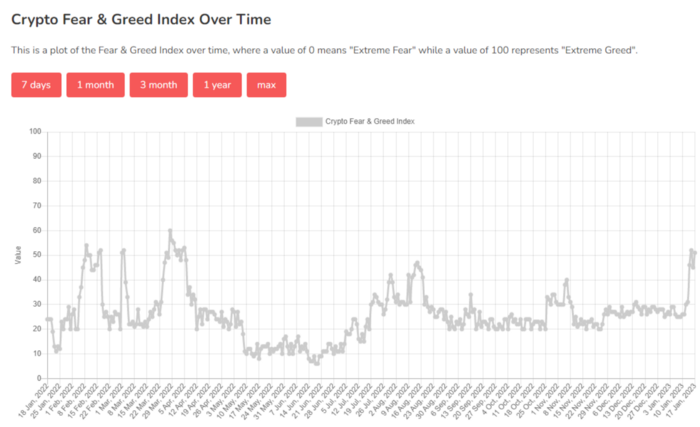
Fear & Greed Index for Bitcoin (FGI)
The Bitcoin market sentiment index ranges from 0 (extreme dread) to 100. (extreme greed).
How to Apply
See market sentiment:
Extreme fright = opportunity to buy
Extreme greed creates sales opportunity (market due for correction).
Glassnode
Glassnode gives facts, information, and confidence to make better Bitcoin, Ethereum, and cryptocurrency investments and trades.
Explore free and paid metrics.
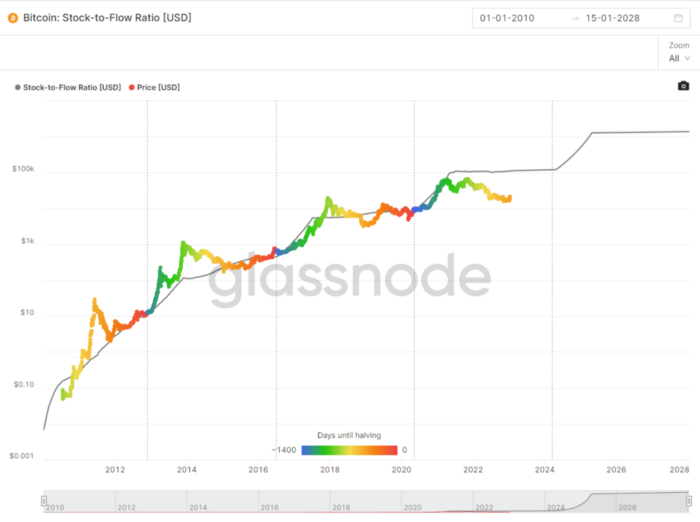
Stock to Flow Ratio: Application
The popular Stock to Flow Ratio concept believes scarcity drives value. Stock to flow is the ratio of circulating Bitcoin supply to fresh production (i.e. newly mined bitcoins). The S/F Ratio has historically predicted Bitcoin prices. PlanB invented this metric.
Utilization: Ethereum Hash Rate
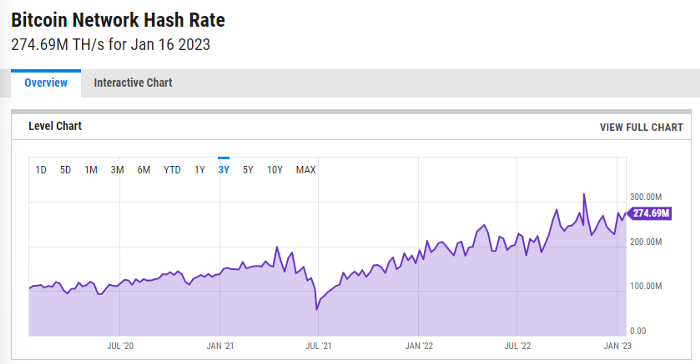
Ethereum miners produce an estimated number of hashes per second.
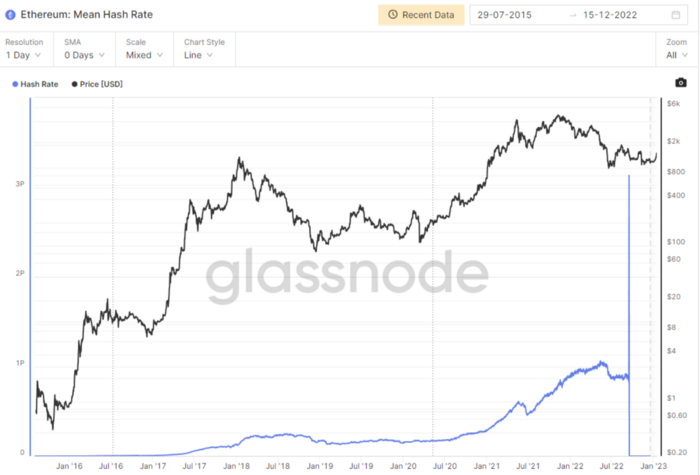
ycharts: Hash rate of the Bitcoin network
TradingView
TradingView is your go-to tool for investment analysis, watch lists, technical analysis, and recommendations from other traders/investors.
Research for a cryptocurrency project
Two key questions every successful project must ask: Q1: What is this project trying to solve? Is it a big problem or minor? Q2: How does this project make money?
Each cryptocurrency:
Check out the white paper.
check out the project's internet presence on github, twitter, and medium.
the transparency of it
Verify the team structure and founders. Verify their LinkedIn profile, academic history, and other qualifications. Search for their names with scam.
Where to purchase and use cryptocurrencies Is it traded on trustworthy exchanges?
From CoinGecko and CoinMarketCap, we may learn about market cap, circulations, and other important data.
The project must solve a problem. Solving a problem is the goal of the founders.
Avoid projects that resemble multi-level marketing or ponzi schemes.
Your use of social media
Use social media carefully or ignore it: Twitter, TradingView, and YouTube
Someone said this before and there are some truth to it. Social media bullish => short.
Your Behavior
Investigate. Spend time. You decide. Worth it!
Only you have the best interest in your financial future.
You might also like

Shalitha Suranga
3 years ago
The Top 5 Mathematical Concepts Every Programmer Needs to Know
Using math to write efficient code in any language

Programmers design, build, test, and maintain software. Employ cases and personal preferences determine the programming languages we use throughout development. Mobile app developers use JavaScript or Dart. Some programmers design performance-first software in C/C++.
A generic source code includes language-specific grammar, pre-implemented function calls, mathematical operators, and control statements. Some mathematical principles assist us enhance our programming and problem-solving skills.
We all use basic mathematical concepts like formulas and relational operators (aka comparison operators) in programming in our daily lives. Beyond these mathematical syntaxes, we'll see discrete math topics. This narrative explains key math topics programmers must know. Master these ideas to produce clean and efficient software code.
Expressions in mathematics and built-in mathematical functions
A source code can only contain a mathematical algorithm or prebuilt API functions. We develop source code between these two ends. If you create code to fetch JSON data from a RESTful service, you'll invoke an HTTP client and won't conduct any math. If you write a function to compute the circle's area, you conduct the math there.
When your source code gets more mathematical, you'll need to use mathematical functions. Every programming language has a math module and syntactical operators. Good programmers always consider code readability, so we should learn to write readable mathematical expressions.
Linux utilizes clear math expressions.
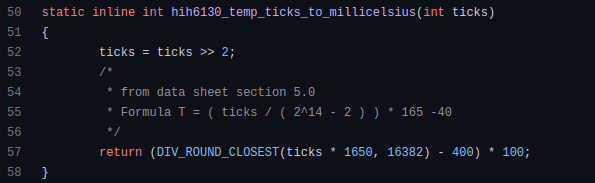
Inbuilt max and min functions can minimize verbose if statements.
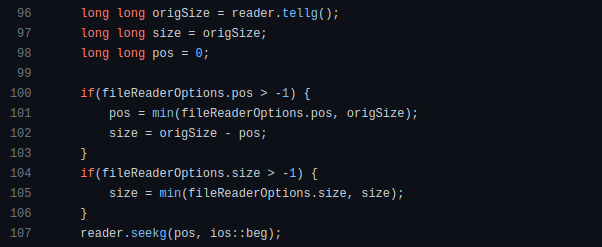
How can we compute the number of pages needed to display known data? In such instances, the ceil function is often utilized.
import math as m
results = 102
items_per_page = 10
pages = m.ceil(results / items_per_page)
print(pages)Learn to write clear, concise math expressions.
Combinatorics in Algorithm Design
Combinatorics theory counts, selects, and arranges numbers or objects. First, consider these programming-related questions. Four-digit PIN security? what options exist? What if the PIN has a prefix? How to locate all decimal number pairs?
Combinatorics questions. Software engineering jobs often require counting items. Combinatorics counts elements without counting them one by one or through other verbose approaches, therefore it enables us to offer minimum and efficient solutions to real-world situations. Combinatorics helps us make reliable decision tests without missing edge cases. Write a program to see if three inputs form a triangle. This is a question I commonly ask in software engineering interviews.
Graph theory is a subfield of combinatorics. Graph theory is used in computerized road maps and social media apps.
Logarithms and Geometry Understanding
Geometry studies shapes, angles, and sizes. Cartesian geometry involves representing geometric objects in multidimensional planes. Geometry is useful for programming. Cartesian geometry is useful for vector graphics, game development, and low-level computer graphics. We can simply work with 2D and 3D arrays as plane axes.
GetWindowRect is a Windows GUI SDK geometric object.
High-level GUI SDKs and libraries use geometric notions like coordinates, dimensions, and forms, therefore knowing geometry speeds up work with computer graphics APIs.
How does exponentiation's inverse function work? Logarithm is exponentiation's inverse function. Logarithm helps programmers find efficient algorithms and solve calculations. Writing efficient code involves finding algorithms with logarithmic temporal complexity. Programmers prefer binary search (O(log n)) over linear search (O(n)). Git source specifies O(log n):
Logarithms aid with programming math. Metas Watchman uses a logarithmic utility function to find the next power of two.
Employing Mathematical Data Structures
Programmers must know data structures to develop clean, efficient code. Stack, queue, and hashmap are computer science basics. Sets and graphs are discrete arithmetic data structures. Most computer languages include a set structure to hold distinct data entries. In most computer languages, graphs can be represented using neighboring lists or objects.
Using sets as deduped lists is powerful because set implementations allow iterators. Instead of a list (or array), store WebSocket connections in a set.
Most interviewers ask graph theory questions, yet current software engineers don't practice algorithms. Graph theory challenges become obligatory in IT firm interviews.
Recognizing Applications of Recursion
A function in programming isolates input(s) and output(s) (s). Programming functions may have originated from mathematical function theories. Programming and math functions are different but similar. Both function types accept input and return value.
Recursion involves calling the same function inside another function. In its implementation, you'll call the Fibonacci sequence. Recursion solves divide-and-conquer software engineering difficulties and avoids code repetition. I recently built the following recursive Dart code to render a Flutter multi-depth expanding list UI:
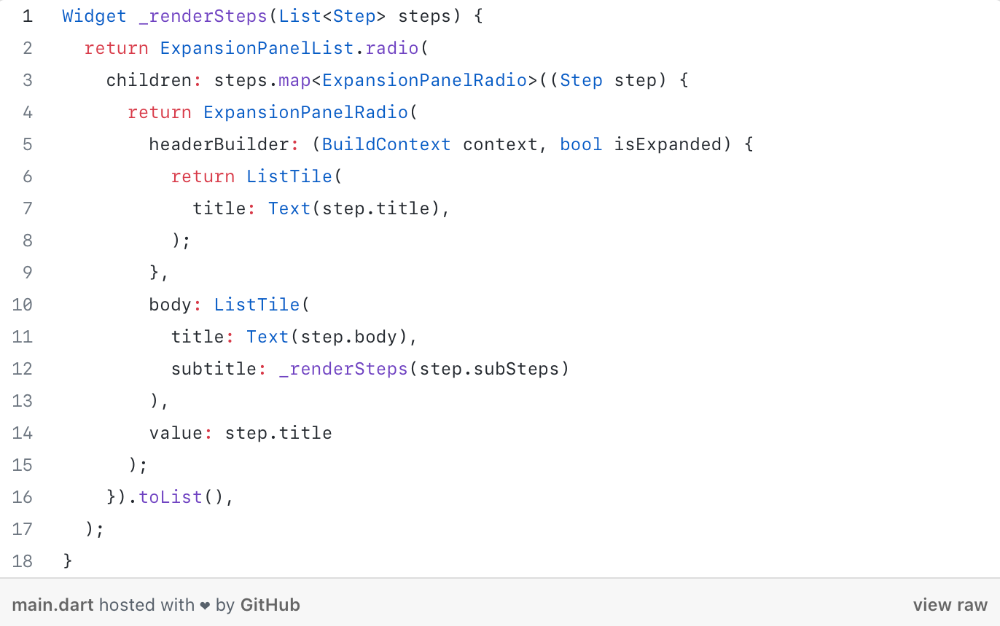
Recursion is not the natural linear way to solve problems, hence thinking recursively is difficult. Everything becomes clear when a mathematical function definition includes a base case and recursive call.
Conclusion
Every codebase uses arithmetic operators, relational operators, and expressions. To build mathematical expressions, we typically employ log, ceil, floor, min, max, etc. Combinatorics, geometry, data structures, and recursion help implement algorithms. Unless you operate in a pure mathematical domain, you may not use calculus, limits, and other complex math in daily programming (i.e., a game engine). These principles are fundamental for daily programming activities.
Master the above math fundamentals to build clean, efficient code.

Katharine Valentino
3 years ago
A Gun-toting Teacher Is Like a Cook With Rat Poison
Pink or blue AR-15s?
A teacher teaches; a gun kills. Killing isn't teaching. Killing is opposite of teaching.
Without 27 school shootings this year, we wouldn't be talking about arming teachers. Gun makers, distributors, and the NRA cause most school shootings. Gun makers, distributors, and the NRA wouldn't be huge business if weapons weren't profitable.
Guns, ammo, body armor, holsters, concealed carriers, bore sights, cleaner kits, spare magazines and speed loaders, gun safes, and ear protection are sold. And more guns.
And lots more profit.
Guns aren't bread. You eat a loaf of bread in a week or so and then must buy more. Bread makers will make money. Winchester 94.30–30 1899 Lever Action Rifle from 1894 still kills. (For safety, I won't link to the ad.) Gun makers don't object if you collect antique weapons, but they need you to buy the latest, in-style killing machine. The youngster who killed 19 students and 2 teachers at Robb Elementary School in Uvalde, Texas, used an AR-15. Better yet, two.
Salvador Ramos, the Robb Elementary shooter, is a "killing influencer" He pushes consumers to buy items, which benefits manufacturers and distributors. Like every previous AR-15 influencer, he profits Colt, the rifle's manufacturer, and 52,779 gun dealers in the U.S. Ramos and other AR-15 influences make us fear for our safety and our children's. Fearing for our safety, we acquire 20 million firearms a year and live in a gun culture.
So now at school, we want to arm teachers.
Consider. Which of your teachers would you have preferred in body armor with a gun drawn?
Miss Summers? Remember her bringing daisies from her yard to second grade? She handed each student a beautiful flower. Miss Summers loved everyone, even those with AR-15s. She can't shoot.
Frasier? Mr. Frasier turned a youngster over down to explain "invert." Mr. Frasier's hands shook when he wasn't flipping fifth-graders and fractions. He may have shot wrong.
Mrs. Barkley barked in high school English class when anyone started an essay with "But." Mrs. Barkley dubbed Abie a "Jewboy" and gave him terrible grades. Arming Miss Barkley is like poisoning the chef.
Think back. Do you remember a teacher with a gun? No. Arming teachers so the gun industry can make more money is the craziest idea ever.
Or maybe you agree with Ted Cruz, the gun lobby-bought senator, that more guns reduce gun violence. After the next school shooting, you'll undoubtedly talk about arming teachers and pupils. Colt will likely develop a backpack-sized, lighter version of its popular killing machine in pink and blue for kids and boys. The MAR-15? (M for mini).
This post is a summary. Read the full one here.

Julie Plavnik
3 years ago
Why the Creator Economy needs a Web3 upgrade
Looking back into the past can help you understand what's happening today and why.

"Creator economy" conjures up images of originality, sincerity, and passion. Where do Michelangelos and da Vincis push advancement with their gifts without battling for bread and proving themselves posthumously?
Creativity has been as long as humanity, but it's just recently become a new economic paradigm. We even talk about Web3 now.
Let's examine the creative economy's history to better comprehend it. What brought us here? Looking back can help you understand what's happening now.
No yawning, I promise 😉.
Creator Economy's history
Long, uneven transition to creator economy. Let's examine the economic and societal changes that led us there.
1. Agriculture to industry
Mid-18th-century Industrial Revolution led to shift from agriculture to manufacturing. The industrial economy lasted until World War II.
The industrial economy's principal goal was to provide more affordable, accessible commodities.
Unlike today, products were scarce and inaccessible.
To fulfill its goals, industrialization triggered enormous economic changes, moving power from agrarians to manufacturers. Industrialization brought hard work, rivalry, and new ideas connected to production and automation. Creative thinkers focused on that then.
It doesn't mean music, poetry, or painting had no place back then. They weren't top priority. Artists were independent. The creative field wasn't considered a different economic subdivision.
2. The consumer economy
Manufacturers produced more things than consumers desired after World War II. Stuff was no longer scarce.
The economy must make customers want to buy what the market offers.
The consumer economic paradigm supplanted the industrial one. Customers (or consumers) replaced producers as the new economic center.
Salesmen, marketing, and journalists also played key roles (TV, radio, newspapers, etc.). Mass media greatly boosted demand for goods, defined trends, and changed views regarding nearly everything.
Mass media also gave rise to pop culture, which focuses on mass-market creative products. Design, printing, publishing, multi-media, audio-visual, cinematographic productions, etc. supported pop culture.
The consumer paradigm generated creative occupations and activities, unlike the industrial economy. Creativity was limited by the need for wide appeal.
Most creators were corporate employees.
Creating a following and making a living from it were difficult.
Paul Saffo said that only journalists and TV workers were known. Creators who wished to be known relied on producers, publishers, and other gatekeepers. To win their favor was crucial. Luck was the best tactic.
3. The creative economy
Consumer economy was digitized in the 1990s. IT solutions transformed several economic segments. This new digital economy demanded innovative, digital creativity.
Later, states declared innovation a "valuable asset that creates money and jobs." They also introduced the "creative industries" and the "creative economy" (not creator!) and tasked themselves with supporting them. Australia and the UK were early adopters.
Individual skill, innovation, and intellectual property fueled the creative economy. Its span covered design, writing, audio, video material, etc. The creative economy required IT-powered activity.
The new challenge was to introduce innovations to most economic segments and meet demand for digital products and services.
Despite what the title "creative economy" may imply, it was primarily oriented at meeting consumer needs. It didn't provide inventors any new options to become entrepreneurs. Instead of encouraging innovators to flourish on their own, the creative economy emphasized "employment-based creativity."
4. The creator economy
Next, huge IT platforms like Google, Facebook, YouTube, and others competed with traditional mainstream media.
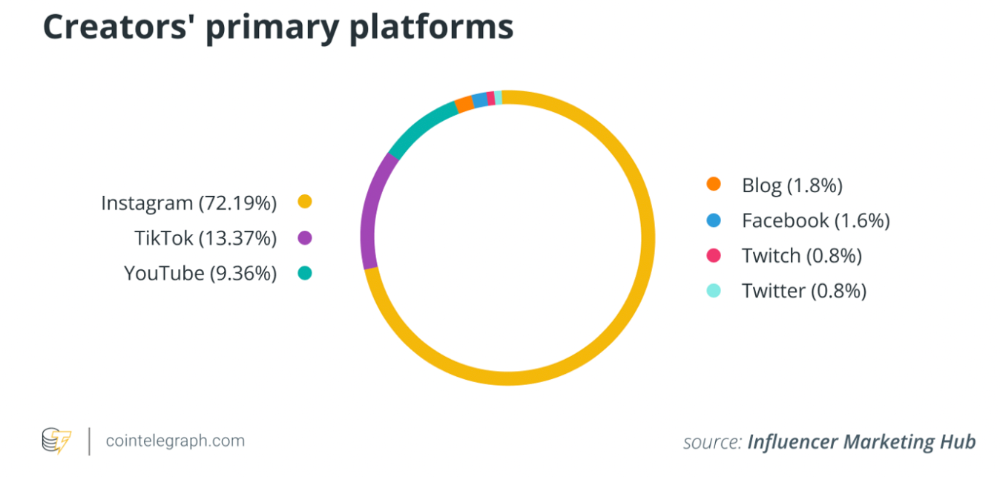
During the 2008 global financial crisis, these mediums surpassed traditional media. People relied on them for information, knowledge, and networking. That was a digital media revolution. The creator economy started there.
The new economic paradigm aimed to engage and convert clients. The creator economy allowed customers to engage, interact, and provide value, unlike the consumer economy. It gave them instruments to promote themselves as "products" and make money.
Writers, singers, painters, and other creators have a great way to reach fans. Instead of appeasing old-fashioned gatekeepers (producers, casting managers, publishers, etc.), they can use the platforms to express their talent and gain admirers. Barriers fell.
It's not only for pros. Everyone with a laptop and internet can now create.
2022 creator economy:
Since there is no academic description for the current creator economy, we can freestyle.
The current (or Web2) creator economy is fueled by interactive digital platforms, marketplaces, and tools that allow users to access, produce, and monetize content.
No entry hurdles or casting in the creative economy. Sign up and follow platforms' rules. Trick: A platform's algorithm aggregates your data and tracks you. This is the payment for participation.
The platforms offer content creation, design, and ad distribution options. This is platforms' main revenue source.
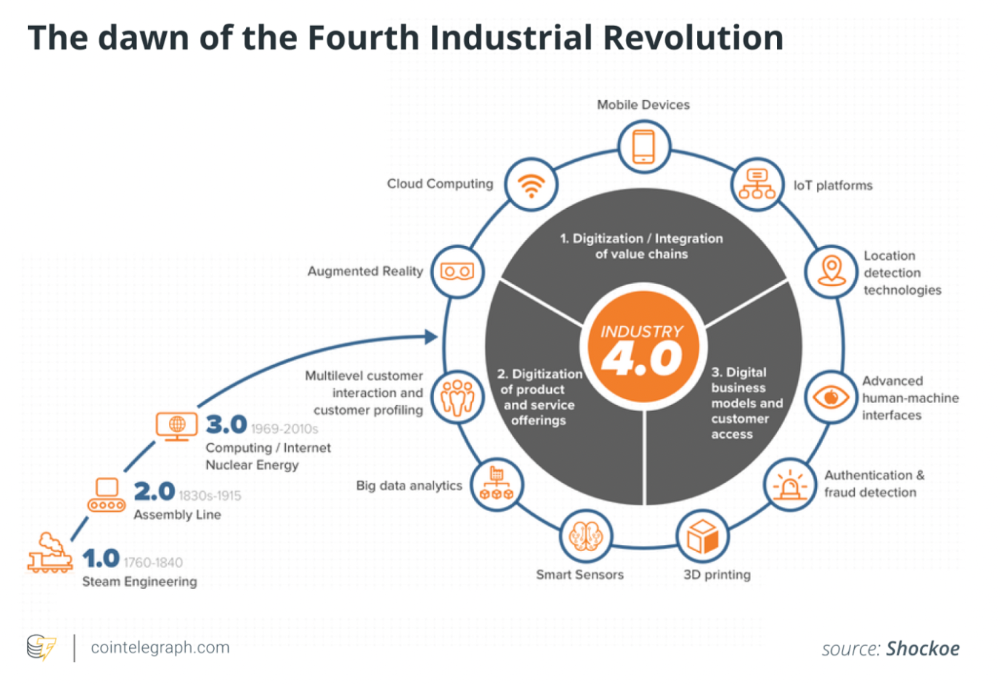
The creator economy opens many avenues for creators to monetize their work. Artists can now earn money through advertising, tipping, brand sponsorship, affiliate links, streaming, and other digital marketing activities.
Even if your content isn't digital, you can utilize platforms to promote it, interact and convert your audience, and more. No limits. However, some of your income always goes to a platform (well, a huge one).
The creator economy aims to empower online entrepreneurship by offering digital marketing tools and reducing impediments.
Barriers remain. They are just different. Next articles will examine these.
Why update the creator economy for Web3?
I could address this question by listing the present creator economy's difficulties that led us to contemplate a Web3 upgrade.
I don't think these difficulties are the main cause. The mentality shift made us see these challenges and understand there was a better reality without them.
Crypto drove this thinking shift. It promoted disintermediation, independence from third-party service providers, 100% data ownership, and self-sovereignty. Crypto has changed the way we view everyday things.
Crypto's disruptive mission has migrated to other economic segments. It's now called Web3. Web3's creator economy is unique.
Here's the essence of the Web3 economy:
Eliminating middlemen between creators and fans.
100% of creators' data, brand, and effort.
Business and money-making transparency.
Authentic originality above ad-driven content.
In the next several articles, I'll explain. We'll also discuss the creator economy and Web3's remedies.
Final thoughts
The creator economy is the organic developmental stage we've reached after all these social and economic transformations.
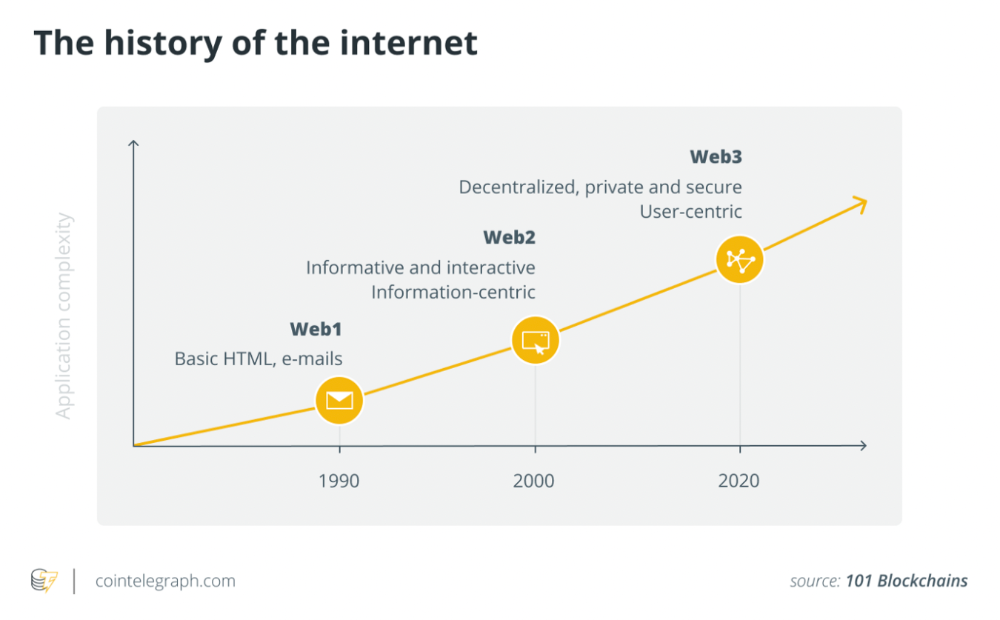
The Web3 paradigm of the creator economy intends to allow creators to construct their own independent "open economy" and directly monetize it without a third party.
If this approach succeeds, we may enter a new era of wealth creation where producers aren't only the products. New economies will emerge.
This article is a summary. To read the full post, click here.