



More on Leadership

Bart Krawczyk
2 years ago
Understanding several Value Proposition kinds will help you create better goods.
Fixing problems isn't enough.
Numerous articles and how-to guides on value propositions focus on fixing consumer concerns.
Contrary to popular opinion, addressing customer pain rarely suffices. Win your market category too.

Core Value Statement
Value proposition usually means a product's main value.
Its how your product solves client problems. The product's core.
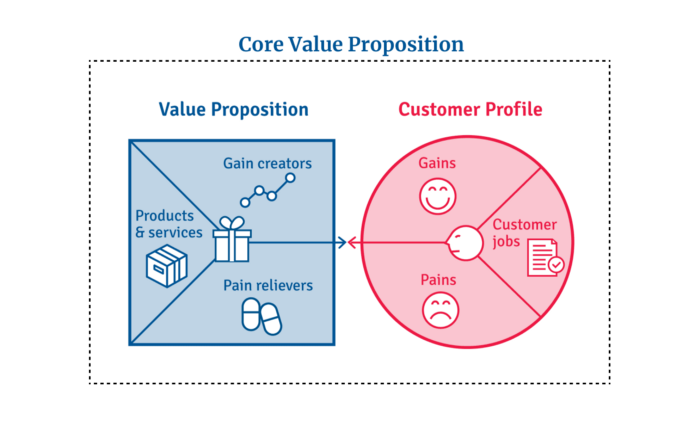
Answering these questions creates a relevant core value proposition:
What tasks is your customer trying to complete? (Jobs for clients)
How much discomfort do they feel while they perform this? (pains)
What would they like to see improved or changed? (gains)
After that, you create products and services that alleviate those pains and give value to clients.
Value Proposition by Category
Your product belongs to a market category and must follow its regulations, regardless of its value proposition.
Creating a new market category is challenging. Fitting into customers' product perceptions is usually better than trying to change them.
New product users simplify market categories. Products are labeled.
Your product will likely be associated with a collection of products people already use.
Example: IT experts will use your communication and management app.
If your target clients think it's an advanced mail software, they'll compare it to others and expect things like:
comprehensive calendar
spam detectors
adequate storage space
list of contacts
etc.
If your target users view your product as a task management app, things change. You can survive without a contact list, but not status management.
Find out what your customers compare your product to and if it fits your value offer. If so, adapt your product plan to dominate this market. If not, try different value propositions and messaging to put the product in the right context.
Finished Value Proposition
A comprehensive value proposition is when your solution addresses user problems and wins its market category.
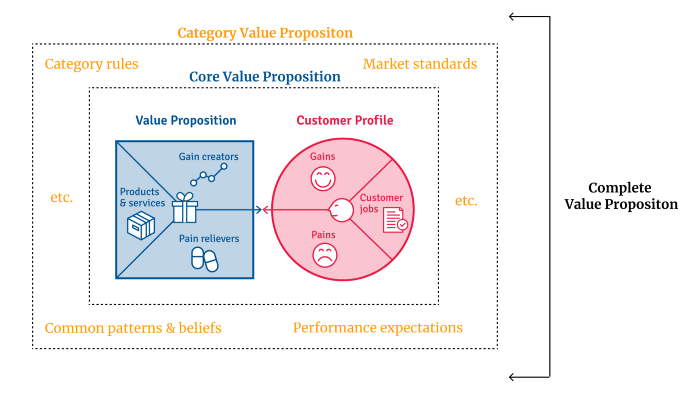
Addressing simply the primary value proposition may produce a valuable and original product, but it may struggle to cross the chasm into the mainstream market. Meeting expectations is easier than changing views.
Without a unique value proposition, you will drown in the red sea of competition.
To conclude:
Find out who your target consumer is and what their demands and problems are.
To meet these needs, develop and test a primary value proposition.
Speak with your most devoted customers. Recognize the alternatives they use to compare you against and the market segment they place you in.
Recognize the requirements and expectations of the market category.
To meet or surpass category standards, modify your goods.
Great products solve client problems and win their category.

KonstantinDr
3 years ago
Early Adopters And the Fifth Reason WHY
Product management wizardry.

Early adopters buy a product even if it hasn't hit the market or has flaws.
Who are the early adopters?
Early adopters try a new technology or product first. Early adopters are interested in trying or buying new technologies and products before others. They're risk-tolerant and can provide initial cash flow and product reviews. They help a company's new product or technology gain social proof.
Early adopters are most common in the technology industry, but they're in every industry. They don't follow the crowd. They seek innovation and report product flaws before mass production. If the product works well, the first users become loyal customers, and colleagues value their opinion.
What to do with early adopters?
They can be used to collect feedback and initial product promotion, first sales, and product value validation.
How to find early followers?
Start with your immediate environment and target audience. Communicate with them to see if they're interested in your value proposition.
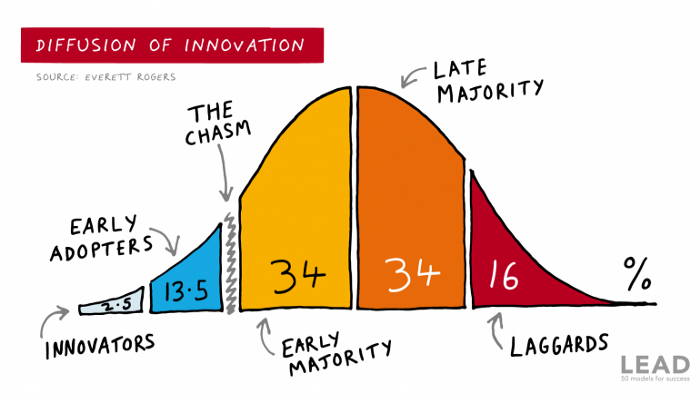
1) Innovators (2.5% of the population) are risk-takers seeking novelty. These people are the first to buy new and trendy items and drive social innovation. However, these people are usually elite;
Early adopters (13.5%) are inclined to accept innovations but are more cautious than innovators; they start using novelties when innovators or famous people do;
3) The early majority (34%) is conservative; they start using new products when many people have mastered them. When the early majority accepted the innovation, it became ingrained in people's minds.
4) Attracting 34% of the population later means the novelty has become a mass-market product. Innovators are using newer products;
5) Laggards (16%) are the most conservative, usually elderly people who use the same products.

Stages of new information acceptance
1. The information is strange and rejected by most. Accepted only by innovators;
2. When early adopters join, more people believe it's not so bad; when a critical mass is reached, the novelty becomes fashionable and most people use it.
3. Fascination with a novelty peaks, then declines; the majority and laggards start using it later; novelty becomes obsolete; innovators master something new.
Problems with early implementation
Early adopter sales have disadvantages.
Higher risk of defects
Selling to first-time users increases the risk of defects. Early adopters are often influential, so this can affect the brand's and its products' long-term perception.
Not what was expected
First-time buyers may be disappointed by the product. Marketing messages can mislead consumers, and if the first users believe the company misrepresented the product, this will affect future sales.
Compatibility issues
Some technological advances cause compatibility issues. Consumers may be disappointed if new technology is incompatible with their electronics.
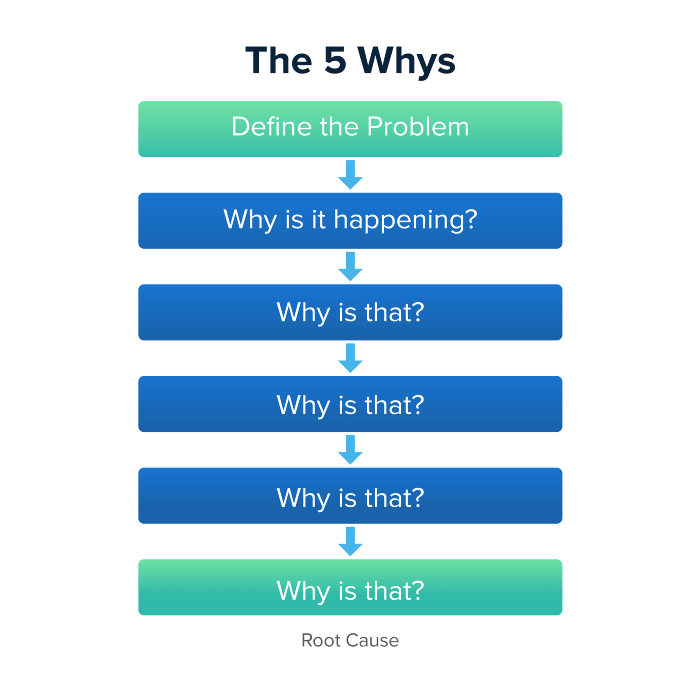
Method 5 WHY

Let's talk about 5 why, a good tool for finding project problems' root causes. This method is also known as the five why rule, method, or questions.
The 5 why technique came from Toyota's lean manufacturing and helps quickly determine a problem's root cause.
On one, two, and three, you simply do this:
We identify and frame the issue for which a solution is sought.
We frequently ponder this question. The first 2-3 responses are frequently very dull, making you want to give up on this pointless exercise. However, after that, things get interesting. And occasionally it's so fascinating that you question whether you really needed to know.
We consider the final response, ponder it, and choose a course of action.
Always do the 5 whys with the customer or team to have a reasonable discussion and better understand what's happening.
And the “five whys” is a wonderful and simplest tool for introspection. With the accumulated practice, it is used almost automatically in any situation like “I can’t force myself to work, the mood is bad in the morning” or “why did I decide that I have no life without this food processor for 20,000 rubles, which will take half of my rather big kitchen.”
An illustration of the five whys
A simple, but real example from my work practice that I think is very indicative, given the participants' low IT skills. Anonymized, of course.
Users spend too long looking for tender documents.
Why? Because they must search through many company tender documents.
Why? Because the system can't filter department-specific bids.
Why? Because our contract management system requirements didn't include a department-tender link. That's it, right? We'll add a filter and be happy. but still…
why? Because we based the system's requirements on regulations for working with paper tender documents (when they still had envelopes and autopsies), not electronic ones, and there was no search mechanism.
Why? We didn't consider how our work would change when switching from paper to electronic tenders when drafting the requirements.
Now I know what to do in the future. We add a filter, enter department data, and teach users to use it. This is tactical, but strategically we review the same forgotten requirements to make all the necessary changes in a package, plus we include it in the checklist for the acceptance of final requirements for the future.
Errors when using 5 why
Five whys seems simple, but it can be misused.
Popular ones:
The accusation of everyone and everything is then introduced. After all, the 5 why method focuses on identifying the underlying causes rather than criticizing others. As a result, at the third step, it is not a good idea to conclude that the system is ineffective because users are stupid and that we can therefore do nothing about it.
to fight with all my might so that the outcome would be exactly 5 reasons, neither more nor less. 5 questions is a typical number (it sounds nice, yes), but there could be 3 or 7 in actuality.
Do not capture in-between responses. It is difficult to overestimate the power of the written or printed word, so the result is so-so when the focus is lost. That's it, I suppose. Simple, quick, and brilliant, like other project management tools.
Conclusion
Today we analyzed important study elements:
Early adopters and 5 WHY We've analyzed cases and live examples of how these methods help with product research and growth point identification. Next, consider the HADI cycle.


Caspar Mahoney
2 years ago
Changing Your Mindset From a Project to a Product
Product game mindsets? How do these vary from Project mindset?
1950s spawned the Iron Triangle. Project people everywhere know and live by it. In stakeholder meetings, it is used to stretch the timeframe, request additional money, or reduce scope.
Quality was added to this triangle as things matured.
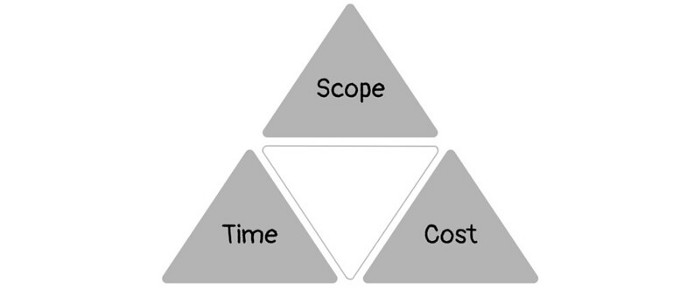
Quality was intended to be transformative, but none of these principles addressed why we conduct projects.
Value and benefits are key.
Product value is quantified by ROI, revenue, profit, savings, or other metrics. For me, every project or product delivery is about value.
Most project managers, especially those schooled 5-10 years or more ago (thousands working in huge corporations worldwide), understand the world in terms of the iron triangle. What does that imply? They worry about:
a) enough time to get the thing done.
b) have enough resources (budget) to get the thing done.
c) have enough scope to fit within (a) and (b) >> note, they never have too little scope, not that I have ever seen! although, theoretically, this could happen.
Boom—iron triangle.
To make the triangle function, project managers will utilize formal governance (Steering) to move those things. Increase money, scope, or both if time is short. Lacking funds? Increase time, scope, or both.
In current product development, shifting each item considerably may not yield value/benefit.
Even terrible. This approach will fail because it deprioritizes Value/Benefit by focusing the major stakeholders (Steering participants) and delivery team(s) on Time, Scope, and Budget restrictions.
Pre-agile, this problem was terrible. IT projects failed wildly. History is here.
Value, or benefit, is central to the product method. Product managers spend most of their time planning value-delivery paths.
Product people consider risk, schedules, scope, and budget, but value comes first. Let me illustrate.
Imagine managing internal products in an enterprise. Your core customer team needs a rapid text record of a chat to fix a problem. The consumer wants a feature/features added to a product you're producing because they think it's the greatest spot.
Project-minded, I may say;
Ok, I have budget as this is an existing project, due to run for a year. This is a new requirement to add to the features we’re already building. I think I can keep the deadline, and include this scope, as it sounds related to the feature set we’re building to give the desired result”.
This attitude repeats Scope, Time, and Budget.
Since it meets those standards, a project manager will likely approve it. If they have a backlog, they may add it and start specking it out assuming it will be built.
Instead, think like a product;
What problem does this feature idea solve? Is that problem relevant to the product I am building? Can that problem be solved quicker/better via another route ? Is it the most valuable problem to solve now? Is the problem space aligned to our current or future strategy? or do I need to alter/update the strategy?
A product mindset allows you to focus on timing, resource/cost, feasibility, feature detail, and so on after answering the aforementioned questions.
The above oversimplifies because
Leadership in discovery

Project managers are facilitators of ideas. This is as far as they normally go in the ‘idea’ space.
Business Requirements collection in classic project delivery requires extensive upfront documentation.
Agile project delivery analyzes requirements iteratively.
However, the project manager is a facilitator/planner first and foremost, therefore topic knowledge is not expected.
I mean business domain, not technical domain (to confuse matters, it is true that in some instances, it can be both technical and business domains that are important for a single individual to master).
Product managers are domain experts. They will become one if they are training/new.
They lead discovery.
Product Manager-led discovery is much more than requirements gathering.
Requirements gathering involves a Business Analyst interviewing people and documenting their requests.
The project manager calculates what fits and what doesn't using their Iron Triangle (presumably in their head) and reports back to Steering.
If this requirements-gathering exercise failed to identify requirements, what would a project manager do? or bewildered by project requirements and scope?
They would tell Steering they need a Business SME or Business Lead assigning or more of their time.
Product discovery requires the Product Manager's subject knowledge and a new mindset.
How should a Product Manager handle confusing requirements?
Product Managers handle these challenges with their talents and tools. They use their own knowledge to fill in ambiguity, but they have the discipline to validate those assumptions.
To define the problem, they may perform qualitative or quantitative primary research.
They might discuss with UX and Engineering on a whiteboard and test assumptions or hypotheses.
Do Product Managers escalate confusing requirements to Steering/Senior leaders? They would fix that themselves.
Product managers raise unclear strategy and outcomes to senior stakeholders. Open talks, soft skills, and data help them do this. They rarely raise requirements since they have their own means of handling them without top stakeholder participation.
Discovery is greenfield, exploratory, research-based, and needs higher-order stakeholder management, user research, and UX expertise.
Product Managers also aid discovery. They lead discovery. They will not leave customer/user engagement to a Business Analyst. Administratively, a business analyst could aid. In fact, many product organizations discourage business analysts (rely on PM, UX, and engineer involvement with end-users instead).
The Product Manager must drive user interaction, research, ideation, and problem analysis, therefore a Product professional must be skilled and confident.
Creating vs. receiving and having an entrepreneurial attitude

Product novices and project managers focus on details rather than the big picture. Project managers prefer spreadsheets to strategy whiteboards and vision statements.
These folks ask their manager or senior stakeholders, "What should we do?"
They then elaborate (in Jira, in XLS, in Confluence or whatever).
They want that plan populated fast because it reduces uncertainty about what's going on and who's supposed to do what.
Skilled Product Managers don't only ask folks Should we?
They're suggesting this, or worse, Senior stakeholders, here are some options. After asking and researching, they determine what value this product adds, what problems it solves, and what behavior it changes.
Therefore, to move into Product, you need to broaden your view and have courage in your ability to discover ideas, find insightful pieces of information, and collate them to form a valuable plan of action. You are constantly defining RoI and building Business Cases, so much so that you no longer create documents called Business Cases, it is simply ingrained in your work through metrics, intelligence, and insights.
Product Management is not a free lunch.
Plateless.
Plates and food must be prepared.
In conclusion, Product Managers must make at least three mentality shifts:
You put value first in all things. Time, money, and scope are not as important as knowing what is valuable.
You have faith in the field and have the ability to direct the search. YYou facilitate, but you don’t just facilitate. You wouldn't want to limit your domain expertise in that manner.
You develop concepts, strategies, and vision. You are not a waiter or an inbox where other people can post suggestions; you don't merely ask folks for opinion and record it. However, you excel at giving things that aren't clearly spoken or written down physical form.
You might also like

Liam Vaughan
3 years ago
Investors can bet big on almost anything on a new prediction market.
Kalshi allows five-figure bets on the Grammys, the next Covid wave, and future SEC commissioners. Worst-case scenario
On Election Day 2020, two young entrepreneurs received a call from the CFTC chairman. Luana Lopes Lara and Tarek Mansour spent 18 months trying to start a new type of financial exchange. Instead of betting on stock prices or commodity futures, people could trade instruments tied to real-world events, such as legislation, the weather, or the Oscar winner.
Heath Tarbert, a Trump appointee, shouted "Congratulations." "You're competing with 1840s-era markets. I'm sure you'll become a powerhouse too."
Companies had tried to introduce similar event markets in the US for years, but Tarbert's agency, the CFTC, said no, arguing they were gambling and prone to cheating. Now the agency has reversed course, approving two 24-year-olds who will have first-mover advantage in what could become a huge new asset class. Kalshi Inc. raised $30 million from venture capitalists within weeks of Tarbert's call, his representative says. Mansour, 26, believes this will be bigger than crypto.
Anyone who's read The Wisdom of Crowds knows prediction markets' potential. Well-designed markets can help draw out knowledge from disparate groups, and research shows that when money is at stake, people make better predictions. Lopes Lara calls it a "bullshit tax." That's why Google, Microsoft, and even the US Department of Defense use prediction markets internally to guide decisions, and why university-linked political betting sites like PredictIt sometimes outperform polls.
Regulators feared Wall Street-scale trading would encourage investors to manipulate reality. If the stakes are high enough, traders could pressure congressional staffers to stall a bill or bet on whether Kanye West's new album will drop this week. When Lopes Lara and Mansour pitched the CFTC, senior regulators raised these issues. Politically appointed commissioners overruled their concerns, and one later joined Kalshi's board.
Will Kanye’s new album come out next week? Yes or no?
Kalshi's victory was due more to lobbying and legal wrangling than to Silicon Valley-style innovation. Lopes Lara and Mansour didn't invent anything; they changed a well-established concept's governance. The result could usher in a new era of market-based enlightenment or push Wall Street's destructive tendencies into the real world.
If Kalshi's founders lacked experience to bolster their CFTC application, they had comical youth success. Lopes Lara studied ballet at the Brazilian Bolshoi before coming to the US. Mansour won France's math Olympiad. They bonded over their work ethic in an MIT computer science class.
Lopes Lara had the idea for Kalshi while interning at a New York hedge fund. When the traders around her weren't working, she noticed they were betting on the news: Would Apple hit a trillion dollars? Kylie Jenner? "It was anything," she says.
Are mortgage rates going up? Yes or no?
Mansour saw the business potential when Lopes Lara suggested it. He interned at Goldman Sachs Group Inc., helping investors prepare for the UK leaving the EU. Goldman sold clients complex stock-and-derivative combinations. As he discussed it with Lopes Lara, they agreed that investors should hedge their risk by betting on Brexit itself rather than an imperfect proxy.
Lopes Lara and Mansour hypothesized how a marketplace might work. They settled on a "event contract," a binary-outcome instrument like "Will inflation hit 5% by the end of the month?" The contract would settle at $1 (if the event happened) or zero (if it didn't), but its price would fluctuate based on market sentiment. After a good debate, a politician's election odds may rise from 50 to 55. Kalshi would charge a commission on every trade and sell data to traders, political campaigns, businesses, and others.
In October 2018, five months after graduation, the pair flew to California to compete in a hackathon for wannabe tech founders organized by the Silicon Valley incubator Y Combinator. They built a website in a day and a night and presented it to entrepreneurs the next day. Their prototype barely worked, but they won a three-month mentorship program and $150,000. Michael Seibel, managing director of Y Combinator, said of their idea, "I had to take a chance!"
Will there be another moon landing by 2025?
Seibel's skepticism was rooted in America's historical wariness of gambling. Roulette, poker, and other online casino games are largely illegal, and sports betting was only legal in a few states until May 2018. Kalshi as a risk-hedging platform rather than a bookmaker seemed like a good idea, but convincing the CFTC wouldn't be easy. In 2012, the CFTC said trading on politics had no "economic purpose" and was "contrary to the public interest."
Lopes Lara and Mansour cold-called 60 Googled lawyers during their time at Y Combinator. Everyone advised quitting. Mansour recalls the pain. Jeff Bandman, a former CFTC official, helped them navigate the agency and its characters.
When they weren’t busy trying to recruit lawyers, Lopes Lara and Mansour were meeting early-stage investors. Alfred Lin of Sequoia Capital Operations LLC backed Airbnb, DoorDash, and Uber Technologies. Lin told the founders their idea could capitalize on retail trading and challenge how the financial world manages risk. "Come back with regulatory approval," he said.
In the US, even small bets on most events were once illegal. Under the Commodity Exchange Act, the CFTC can stop exchanges from listing contracts relating to "terrorism, assassination, war" and "gaming" if they are "contrary to the public interest," which was often the case.
Will subway ridership return to normal? Yes or no?
In 1988, as academic interest in the field grew, the agency allowed the University of Iowa to set up a prediction market for research purposes, as long as it didn't make a profit or advertise and limited bets to $500. PredictIt, the biggest and best-known political betting platform in the US, also got an exemption thanks to an association with Victoria University of Wellington in New Zealand. Today, it's a sprawling marketplace with its own subculture and lingo. PredictIt users call it "Rules Cuck Panther" when they lose on a technicality. Major news outlets cite PredictIt's odds on Discord and the Star Spangled Gamblers podcast.
CFTC limits PredictIt bets to $850. To keep traders happy, PredictIt will often run multiple variations of the same question, listing separate contracts for two dozen Democratic primary candidates, for example. A trader could have more than $10,000 riding on a single outcome. Some of the site's traders are current or former campaign staffers who can answer questions like "How many tweets will Donald Trump post from Nov. 20 to 27?" and "When will Anthony Scaramucci's role as White House communications director end?"
According to PredictIt co-founder John Phillips, politicians help explain the site's accuracy. "Prediction markets work well and are accurate because they attract people with superior information," he said in a 2016 podcast. “In the financial stock market, it’s called inside information.”
Will Build Back Better pass? Yes or no?
Trading on nonpublic information is illegal outside of academia, which presented a dilemma for Lopes Lara and Mansour. Kalshi's forecasts needed to be accurate. Kalshi must eliminate insider trading as a regulated entity. Lopes Lara and Mansour wanted to build a high-stakes PredictIt without the anarchy or blurred legal lines—a "New York Stock Exchange for Events." First, they had to convince regulators event trading was safe.
When Lopes Lara and Mansour approached the CFTC in the spring of 2019, some officials in the Division of Market Oversight were skeptical, according to interviews with people involved in the process. For all Kalshi's talk of revolutionizing finance, this was just a turbocharged version of something that had been rejected before.
The DMO couldn't see the big picture. The staff review was supposed to ensure Kalshi could complete a checklist, "23 Core Principles of a Designated Contract Market," which included keeping good records and having enough money. The five commissioners decide. With Trump as president, three of them were ideologically pro-market.
Lopes Lara, Mansour, and their lawyer Bandman, an ex-CFTC official, answered the DMO's questions while lobbying the commissioners on Zoom about the potential of event markets to mitigate risks and make better decisions. Before each meeting, they would write a script and memorize it word for word.
Will student debt be forgiven? Yes or no?
Several prediction markets that hadn't sought regulatory approval bolstered Kalshi's case. Polymarket let customers bet hundreds of thousands of dollars anonymously using cryptocurrencies, making it hard to track. Augur, which facilitates private wagers between parties using blockchain, couldn't regulate bets and hadn't stopped users from betting on assassinations. Kalshi, by comparison, argued it was doing everything right. (The CFTC fined Polymarket $1.4 million for operating an unlicensed exchange in January 2022. Polymarket says it's now compliant and excited to pioneer smart contract-based financial solutions with regulators.
Kalshi was approved unanimously despite some DMO members' concerns about event contracts' riskiness. "Once they check all the boxes, they're in," says a CFTC insider.
Three months after CFTC approval, Kalshi announced funding from Sequoia, Charles Schwab, and Henry Kravis. Sequoia's Lin, who joined the board, said Tarek, Luana, and team created a new way to invest and engage with the world.
The CFTC hadn't asked what markets the exchange planned to run since. After approval, Lopes Lara and Mansour had the momentum. Kalshi's March list of 30 proposed contracts caused chaos at the DMO. The division handles exchanges that create two or three new markets a year. Kalshi’s business model called for new ones practically every day.
Uncontroversial proposals included weather and GDP questions. Others, on the initial list and later, were concerning. DMO officials feared Covid-19 contracts amounted to gambling on human suffering, which is why war and terrorism markets are banned. (Similar logic doomed ex-admiral John Poindexter's Policy Analysis Market, a Bush-era plan to uncover intelligence by having security analysts bet on Middle East events.) Regulators didn't see how predicting the Grammy winners was different from betting on the Patriots to win the Super Bowl. Who, other than John Legend, would need to hedge the best R&B album winner?
Event contracts raised new questions for the DMO's product review team. Regulators could block gaming contracts that weren't in the public interest under the Commodity Exchange Act, but no one had defined gaming. It was unclear whether the CFTC had a right or an obligation to consider whether a contract was in the public interest. How was it to determine public interest? Another person familiar with the CFTC review says, "It was a mess." The agency didn't comment.
CFTC staff feared some event contracts could be cheated. Kalshi wanted to run a bee-endangerment market. The DMO pushed back, saying it saw two problems symptomatic of the asset class: traders could press government officials for information, and officials could delay adding the insects to the list to cash in.
The idea that traders might manipulate prediction markets wasn't paranoid. In 2013, academics David Rothschild and Rajiv Sethi found that an unidentified party lost $7 million buying Mitt Romney contracts on Intrade, a now-defunct, unlicensed Irish platform, in the runup to the 2012 election. The authors speculated that the trader, whom they dubbed the “Romney Whale,” may have been looking to boost morale and keep donations coming in.
Kalshi said manipulation and insider trading are risks for any market. It built a surveillance system and said it would hire a team to monitor it. "People trade on events all the time—they just use options and other instruments. This brings everything into the open, Mansour says. Kalshi didn't include election contracts, a red line for CFTC Democrats.
Lopes Lara and Mansour were ready to launch kalshi.com that summer, but the DMO blocked them. Product reviewers were frustrated by spending half their time on an exchange that represented a tiny portion of the derivatives market. Lopes Lara and Mansour pressed politically appointed commissioners during the impasse.
Tarbert, the chairman, had moved on, but Kalshi found a new supporter in Republican Brian Quintenz, a crypto-loving former hedge fund manager. He was unmoved by the DMO's concerns, arguing that speculation on Kalshi's proposed events was desirable and the agency had no legal standing to prevent it. He supported a failed bid to allow NFL futures earlier this year. Others on the commission were cautious but supportive. Given the law's ambiguity, they worried they'd be on shaky ground if Kalshi sued if they blocked a contract. Without a permanent chairman, the agency lacked leadership.
To block a contract, DMO staff needed a majority of commissioners' support, which they didn't have in all but a few cases. "We didn't have the votes," a reviewer says, paraphrasing Hamilton. By the second half of 2021, new contract requests were arriving almost daily at the DMO, and the demoralized and overrun division eventually accepted defeat and stopped fighting back. By the end of the year, three senior DMO officials had left the agency, making it easier for Kalshi to list its contracts unimpeded.
Today, Kalshi is growing. 32 employees work in a SoHo office with big windows and exposed brick. Quintenz, who left the CFTC 10 months after Kalshi was approved, is on its board. He joined because he was interested in the market's hedging and risk management opportunities.
Mid-May, the company's website had 75 markets, such as "Will Q4 GDP be negative?" Will NASA land on the moon by 2025? The exchange recently reached 2 million weekly contracts, a jump from where it started but still a small number compared to other futures exchanges. Early adopters are PredictIt and Polymarket fans. Bets on the site are currently capped at $25,000, but Kalshi hopes to increase that to $100,000 and beyond.
With the regulatory drawbridge down, Lopes Lara and Mansour must move quickly. Chicago's CME Group Inc. plans to offer index-linked event contracts. Kalshi will release a smartphone app to attract customers. After that, it hopes to partner with a big brokerage. Sequoia is a major investor in Robinhood Markets Inc. Robinhood users could have access to Kalshi so that after buying GameStop Corp. shares, they'd be prompted to bet on the Oscars or the next Fed commissioner.
Some, like Illinois Democrat Sean Casten, accuse Robinhood and its competitors of gamifying trading to encourage addiction, but Kalshi doesn't seem worried. Mansour says Kalshi's customers can't bet more than they've deposited, making debt difficult. Eventually, he may introduce leveraged bets.
Tension over event contracts recalls another CFTC episode. Brooksley Born proposed regulating the financial derivatives market in 1994. Alan Greenspan and others in the government opposed her, saying it would stifle innovation and push capital overseas. Unrestrained, derivatives grew into a trillion-dollar industry until 2008, when they sparked the financial crisis.
Today, with a midterm election looming, it seems reasonable to ask whether Kalshi plans to get involved. Elections have historically been the biggest draw in prediction markets, with 125 million shares traded on PredictIt for 2020. “We can’t discuss specifics,” Mansour says. “All I can say is, you know, we’re always working on expanding the universe of things that people can trade on.”
Any election contracts would need CFTC approval, which may be difficult with three Democratic commissioners. A Republican president would change the equation.

Trent Lapinski
4 years ago
What The Hell Is A Crypto Punk?
We are Crypto Punks, and we are changing your world.
A “Crypto Punk” is a new generation of entrepreneurs who value individual liberty and collective value creation and co-creation through decentralization. While many Crypto Punks were born and raised in a digital world, some of the early pioneers in the crypto space are from the Oregon Trail generation. They were born to an analog world, but grew up simultaneously alongside the birth of home computing, the Internet, and mobile computing.
A Crypto Punk’s world view is not the same as previous generations. By the time most Crypto Punks were born everything from fiat currency, the stock market, pharmaceuticals, the Internet, to advanced operating systems and microprocessing were already present or emerging. Crypto Punks were born into pre-existing conditions and systems of control, not governed by logic or reason but by greed, corporatism, subversion, bureaucracy, censorship, and inefficiency.
All Systems Are Human Made
Crypto Punks understand that all systems were created by people and that previous generations did not have access to information technologies that we have today. This is why Crypto Punks have different values than their parents, and value liberty, decentralization, equality, social justice, and freedom over wealth, money, and power. They understand that the only path forward is to work together to build new and better systems that make the old world order obsolete.
Unlike the original cypher punks and cyber punks, Crypto Punks are a new iteration or evolution of these previous cultures influenced by cryptography, blockchain technology, crypto economics, libertarianism, holographics, democratic socialism, and artificial intelligence. They are tasked with not only undoing the mistakes of previous generations, but also innovating and creating new ways of solving complex problems with advanced technology and solutions.
Where Crypto Punks truly differ is in their understanding that computer systems can exist for more than just engagement and entertainment, but actually improve the human condition by automating bureaucracy and inefficiency by creating more efficient economic incentives and systems.
Crypto Punks Value Transparency and Do Not Trust Flawed, Unequal, and Corrupt Systems
Crypto Punks have a strong distrust for inherently flawed and corrupt systems. This why Crypto Punks value transparency, free speech, privacy, and decentralization. As well as arguably computer systems over human powered systems.
Crypto Punks are the children of the Great Recession, and will never forget the economic corruption that still enslaves younger generations.
Crypto Punks were born to think different, and raised by computers to view reality through an LED looking glass. They will not surrender to the flawed systems of economic wage slavery, inequality, censorship, and subjection. They will literally engineer their own unstoppable financial systems and trade in cryptography over fiat currency merely to prove that belief systems are more powerful than corruption.
Crypto Punks are here to help achieve freedom from world governments, corporations and bankers who monetizine our data to control our lives.
Crypto Punks Decentralize
Despite all the evils of the world today, Crypto Punks know they have the power to create change. This is why Crypto Punks are optimistic about the future despite all the indicators that humanity is destined for failure.
Crypto Punks believe in systems that prioritize people and the planet above profit. Even so, Crypto Punks still believe in capitalistic systems, but only capitalistic systems that incentivize good behaviors that do not violate the common good for the sake of profit.
Cyber Punks Are Co-Creators
We are Crypto Punks, and we will build a better world for all of us. For the true price of creation is not in US dollars, but through working together as equals to replace the unequal and corrupt greedy systems of previous generations.
Where they have failed, Crypto Punks will succeed. Not because we want to, but because we have to. The world we were born into is so corrupt and its systems so flawed and unequal we were never given a choice.
We have to be the change we seek.
We are Crypto Punks.
Either help us, or get out of our way.
Are you a Crypto Punk?

Yucel F. Sahan
3 years ago
How I Created the Day's Top Product on Product Hunt
In this article, I'll describe a weekend project I started to make something. It was Product Hunt's #1 of the Day, #2 Weekly, and #4 Monthly product.


How did I make Landing Page Checklist so simple? Building and launching took 3 weeks. I worked 3 hours a day max. Weekends were busy.
It's sort of a long story, so scroll to the bottom of the page to see what tools I utilized to create Landing Page Checklist :x
As a matter of fact, it all started with the startups-investments blog; Startup Bulletin, that I started writing in 2018. No, don’t worry, I won’t be going that far behind. The twitter account where I shared the blog posts of this newsletter was inactive for a looong time. I was holding this Twitter account since 2009, I couldn’t bear to destroy it. At the same time, I was thinking how to evaluate this account.
So I looked for a weekend assignment.
Weekend undertaking: Generate business names
Barash and I established a weekend effort to stay current. Building things helped us learn faster.
Simple. Startup Name Generator The utility generated random startup names. After market research for SEO purposes, we dubbed it Business Name Generator.
Backend developer Barash dislikes frontend work. He told me to write frontend code. Chakra UI and Tailwind CSS were recommended.
It was the first time I have heard about Tailwind CSS.
Before this project, I made mobile-web app designs in Sketch and shared them via Zeplin. I can read HTML-CSS or React code, but not write it. I didn't believe myself but followed Barash's advice.
My home page wasn't responsive when I started. Here it was:)
And then... Product Hunt had something I needed. Me-only! A website builder that gives you clean Tailwind CSS code and pre-made web components (like Elementor). Incredible.
I bought it right away because it was so easy to use. Best part: It's not just index.html. It includes all needed files. Like
postcss.config.js
README.md
package.json
among other things, tailwind.config.js
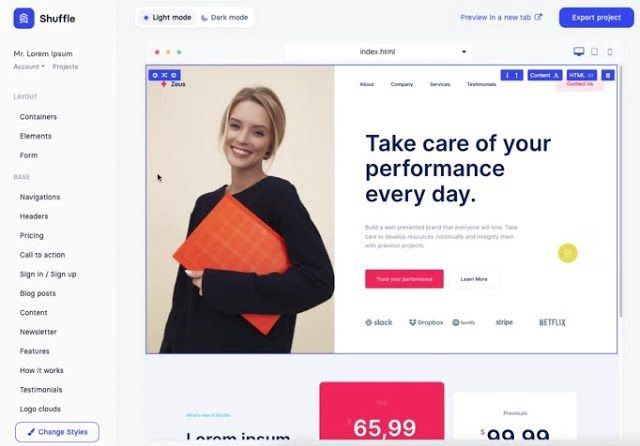
This is for non-techies.
Tailwind.build; which is Shuffle now, allows you to create and export projects for free (with limited features). You can try it by visiting their website.
After downloading the project, you can edit the text and graphics in Visual Studio (or another text editor). This HTML file can be hosted whenever.
Github is an easy way to host a landing page.
your project via Shuffle for export
your website's content, edit
Create a Gitlab, Github, or Bitbucket account.
to Github, upload your project folder.
Integrate Vercel with your Github account (or another platform below)
Allow them to guide you in steps.
Finally. If you push your code to Github using Github Desktop, you'll do it quickly and easily.
Speaking of; here are some hosting and serverless backend services for web applications and static websites for you host your landing pages for FREE!
I host landingpage.fyi on Vercel but all is fine. You can choose any platform below with peace in mind.
Vercel
Render
Netlify
After connecting your project/repo to Vercel, you don’t have to do anything on Vercel. Vercel updates your live website when you update Github Desktop. Wow!
Tails came out while I was using tailwind.build. Although it's prettier, tailwind.build is more mobile-friendly. I couldn't resist their lovely parts. Tails :)
Tails have several well-designed parts. Some components looked awful on mobile, but this bug helped me understand Tailwind CSS.
Unlike Shuffle, Tails does not include files when you export such as config.js, main.js, README.md. It just gives you the HTML code. Suffle.dev is a bit ahead in this regard and with mobile-friendly blocks if you ask me. Of course, I took advantage of both.
creativebusinessnames.co is inactive, but I'll leave a deployment link :)
Adam Wathan's YouTube videos and Tailwind's official literature helped me, but I couldn't have done it without Tails and Shuffle. These tools helped me make landing pages. I shouldn't have started over.
So began my Tailwind CSS adventure. I didn't build landingpage. I didn't plan it to be this long; sorry.
I learnt a lot while I was playing around with Shuffle and Tails Builders.
Long story short I built landingpage.fyi with the help of these tools;
Learning, building, and distribution
Shuffle (Started with a Shuffle Template)
Tails (Used components from here)
Sketch (to handle icons, logos, and .svg’s)
metatags.io (Auto Generator Meta Tags)
Vercel (Hosting)
Github Desktop (Pushing code to Github -super easy-)
Visual Studio Code (Edit my code)
Mailerlite (Capture Emails)
Jarvis / Conversion.ai (%90 of the text on website written by AI 😇 )
CookieHub (Consent Management)
That's all. A few things:
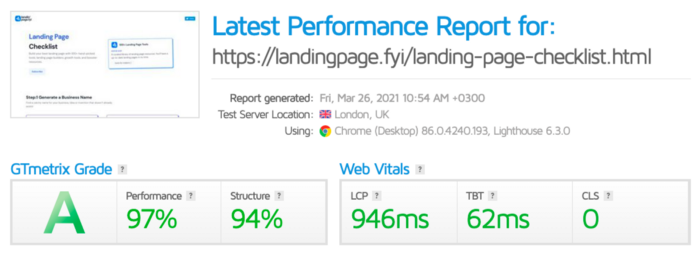
The Outcome
.fyi Domain: Why?

I'm often asked this.
I don't know, but I wanted to include the landing page term. Popular TLDs are gone. I saw my alternatives. brief and catchy.
CSS Tailwind Resources
I'll share project resources like Tails and Shuffle.
Beginner Tailwind (I lately enrolled in this course but haven’t completed it yet.)
Thanks for reading my blog's first post. Please share if you like it.