



More on Web3 & Crypto

mbvissers.eth
3 years ago
Why does every smart contract seem to implement ERC165?

ERC165 (or EIP-165) is a standard utilized by various open-source smart contracts like Open Zeppelin or Aavegotchi.
What's it? You must implement? Why do we need it? I'll describe the standard and answer any queries.
What is ERC165
ERC165 detects and publishes smart contract interfaces. Meaning? It standardizes how interfaces are recognized, how to detect if they implement ERC165, and how a contract publishes the interfaces it implements. How does it work?
Why use ERC165? Sometimes it's useful to know which interfaces a contract implements, and which version.
Identifying interfaces
An interface function's selector. This verifies an ABI function. XORing all function selectors defines an interface in this standard. The following code demonstrates.
// SPDX-License-Identifier: UNLICENCED
pragma solidity >=0.8.0 <0.9.0;
interface Solidity101 {
function hello() external pure;
function world(int) external pure;
}
contract Selector {
function calculateSelector() public pure returns (bytes4) {
Solidity101 i;
return i.hello.selector ^ i.world.selector;
// Returns 0xc6be8b58
}
function getHelloSelector() public pure returns (bytes4) {
Solidity101 i;
return i.hello.selector;
// Returns 0x19ff1d21
}
function getWorldSelector() public pure returns (bytes4) {
Solidity101 i;
return i.world.selector;
// Returns 0xdf419679
}
}This code isn't necessary to understand function selectors and how an interface's selector can be determined from the functions it implements.
Run that sample in Remix to see how interface function modifications affect contract function output.
Contracts publish their implemented interfaces.
We can identify interfaces. Now we must disclose the interfaces we're implementing. First, import IERC165 like so.
pragma solidity ^0.4.20;
interface ERC165 {
/// @notice Query if a contract implements an interface
/// @param interfaceID The interface identifier, as specified in ERC-165
/// @dev Interface identification is specified in ERC-165.
/// @return `true` if the contract implements `interfaceID` and
/// `interfaceID` is not 0xffffffff, `false` otherwise
function supportsInterface(bytes4 interfaceID) external view returns (bool);
}We still need to build this interface in our smart contract. ERC721 from OpenZeppelin is a good example.
// SPDX-License-Identifier: MIT
// OpenZeppelin Contracts (last updated v4.5.0) (token/ERC721/ERC721.sol)
pragma solidity ^0.8.0;
import "./IERC721.sol";
import "./extensions/IERC721Metadata.sol";
import "../../utils/introspection/ERC165.sol";
// ...
contract ERC721 is Context, ERC165, IERC721, IERC721Metadata {
// ...
function supportsInterface(bytes4 interfaceId) public view virtual override(ERC165, IERC165) returns (bool) {
return
interfaceId == type(IERC721).interfaceId ||
interfaceId == type(IERC721Metadata).interfaceId ||
super.supportsInterface(interfaceId);
}
// ...
}I deleted unnecessary code. The smart contract imports ERC165, IERC721 and IERC721Metadata. The is keyword at smart contract declaration implements all three.
Kind (interface).
Note that type(interface).interfaceId returns the same as the interface selector.
We override supportsInterface in the smart contract to return a boolean that checks if interfaceId is the same as one of the implemented contracts.
Super.supportsInterface() calls ERC165 code. Checks if interfaceId is IERC165.
function supportsInterface(bytes4 interfaceId) public view virtual override returns (bool) {
return interfaceId == type(IERC165).interfaceId;
}So, if we run supportsInterface with an interfaceId, our contract function returns true if it's implemented and false otherwise. True for IERC721, IERC721Metadata, andIERC165.
Conclusion
I hope this post has helped you understand and use ERC165 and why it's employed.
Have a great day, thanks for reading!

Matt Ward
3 years ago
Is Web3 nonsense?
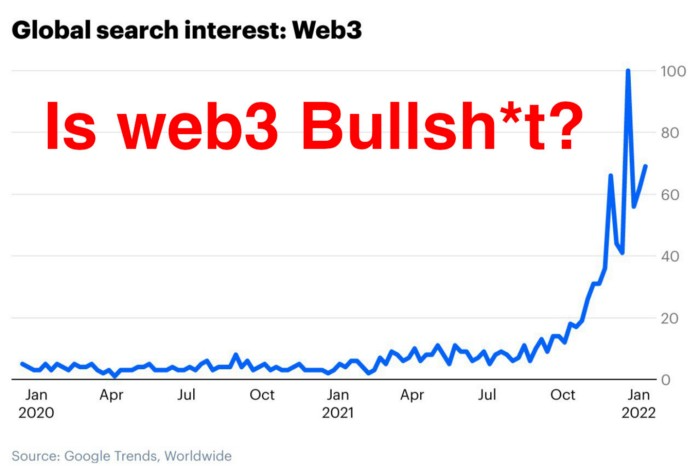
Crypto and blockchain have rebranded as web3. They probably thought it sounded better and didn't want the baggage of scam ICOs, STOs, and skirted securities laws.
It was like Facebook becoming Meta. Crypto's biggest players wanted to change public (and regulator) perception away from pump-and-dump schemes.
After the 2018 ICO gold rush, it's understandable. Every project that raised millions (or billions) never shipped a meaningful product.
Like many crazes, charlatans took the money and ran.
Despite its grifter past, web3 is THE hot topic today as more founders, venture firms, and larger institutions look to build the future decentralized internet.
Supposedly.
How often have you heard: This will change the world, fix the internet, and give people power?
Why are most of web3's biggest proponents (and beneficiaries) the same rich, powerful players who built and invested in the modern internet? It's like they want to remake and own the internet.
Something seems off about that.
Why are insiders getting preferential presale terms before the public, allowing early investors and proponents to flip dirt cheap tokens and advisors shares almost immediately after the public sale?
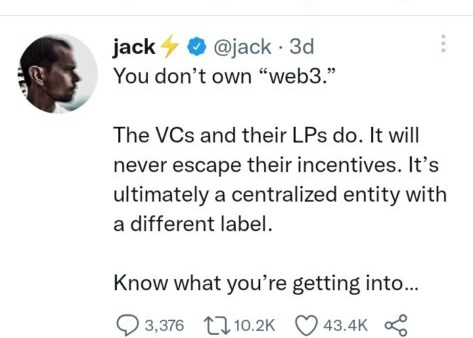
It's a good gig with guaranteed markups, no risk or progress.
If it sounds like insider trading, it is, at least practically. This is clear when people talk about blockchain/web3 launches and tokens.
Fast money, quick flips, and guaranteed markups/returns are common.
Incentives-wise, it's hard to blame them. Who can blame someone for following the rules to win? Is it their fault or regulators' for not leveling the playing field?
It's similar to oil companies polluting for profit, Instagram depressing you into buying a new dress, or pharma pushing an unnecessary pill.
All of that is fair game, at least until we change the playbook, because people (and corporations) change for pain or love. Who doesn't love money?
belief based on money gain
Sinclair:
“It is difficult to get a man to understand something when his salary depends upon his not understanding it.”
Bitcoin, blockchain, and web3 analogies?
Most blockchain and web3 proponents are true believers, not cynical capitalists. They believe blockchain's inherent transparency and permissionless trust allow humanity to evolve beyond our reptilian ways and build a better decentralized and democratic world.
They highlight issues with the modern internet and monopoly players like Google, Facebook, and Apple. Decentralization fixes everything
If we could give power back to the people and get governments/corporations/individuals out of the way, we'd fix everything.
Blockchain solves supply chain and child labor issues in China.
To meet Paris climate goals, reduce emissions. Create a carbon token.
Fixing online hatred and polarization Web3 Twitter and Facebook replacement.

Web3 must just be the answer for everything… your “perfect” silver bullet.
Nothing fits everyone. Blockchain has pros and cons like everything else.
Blockchain's viral, ponzi-like nature has an MLM (mid level marketing) feel. If you bought Taylor Swift's NFT, your investment is tied to her popularity.
Probably makes you promote Swift more. Play music loudly.
Here's another example:
Imagine if Jehovah’s Witnesses (or evangelical preachers…) got paid for every single person they converted to their cause.
It becomes a self-fulfilling prophecy as their faith and wealth grow.
Which breeds extremism? Ultra-Orthodox Jews are an example. maximalists

Bitcoin and blockchain are causes, religions. It's a money-making movement and ideal.
We're good at convincing ourselves of things we want to believe, hence filter bubbles.
I ignore anything that doesn't fit my worldview and seek out like-minded people, which algorithms amplify.
Then what?
Is web3 merely a new scam?
No, never!
Blockchain has many crucial uses.
Sending money home/abroad without bank fees;
Like fleeing a war-torn country and converting savings to Bitcoin;
Like preventing Twitter from silencing dissidents.
Permissionless, trustless databases could benefit society and humanity. There are, however, many limitations.
Lost password?
What if you're cheated?
What if Trump/Putin/your favorite dictator incites a coup d'état?
What-ifs abound. Decentralization's openness brings good and bad.
No gatekeepers or firefighters to rescue you.
ISIS's fundraising is also frictionless.
Community-owned apps with bad interfaces and service.
Trade-offs rule.
So what compromises does web3 make?
What are your trade-offs? Decentralization has many strengths and flaws. Like Bitcoin's wasteful proof-of-work or Ethereum's political/wealth-based proof-of-stake.
To ensure the survival and veracity of the network/blockchain and to safeguard its nodes, extreme measures have been designed/put in place to prevent hostile takeovers aimed at altering the blockchain, i.e., adding money to your own wallet (account), etc.
These protective measures require significant resources and pose challenges. Reduced speed and throughput, high gas fees (cost to submit/write a transaction to the blockchain), and delayed development times, not to mention forked blockchain chains oops, web3 projects.
Protecting dissidents or rogue regimes makes sense. You need safety, privacy, and calm.
First-world life?
What if you assumed EVERYONE you saw was out to rob/attack you? You'd never travel, trust anyone, accomplish much, or live fully. The economy would collapse.
It's like an ant colony where half the ants do nothing but wait to be attacked.
Waste of time and money.
11% of the US budget goes to the military. Imagine what we could do with the $766B+ we spend on what-ifs annually.
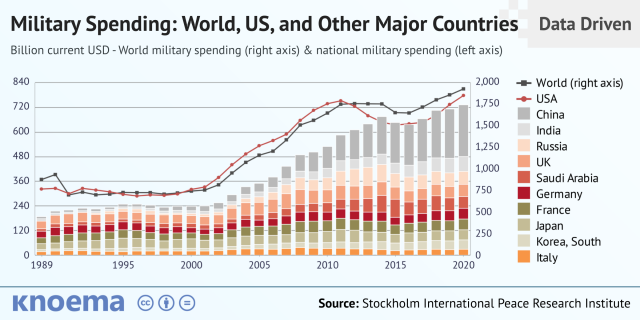
Is so much hypothetical security needed?
Blockchain and web3 are similar.
Does your app need permissionless decentralization? Does your scooter-sharing company really need a proof-of-stake system and 1000s of nodes to avoid Russian hackers? Why?
Worst-case scenario? It's not life or death, unless you overstate the what-ifs. Web3 proponents find improbable scenarios to justify decentralization and tokenization.
Do I need a token to prove ownership of my painting? Unless I'm a master thief, I probably bought it.
despite losing the receipt.
I do, however, love Web 3.
Enough Web3 bashing for now. Understand? Decentralization isn't perfect, but it has huge potential when applied to the right problems.
I see many of the right problems as disrupting big tech's ruthless monopolies. I wrote several years ago about how tokenized blockchains could be used to break big tech's stranglehold on platforms, marketplaces, and social media.
Tokenomics schemes can be used for good and are powerful. Here’s how.
Before the ICO boom, I made a series of predictions about blockchain/crypto's future. It's still true.
Here's where I was then and where I see web3 going:
My 11 Big & Bold Predictions for Blockchain
In the near future, people may wear crypto cash rings or bracelets.
While some governments repress cryptocurrency, others will start to embrace it.
Blockchain will fundamentally alter voting and governance, resulting in a more open election process.
Money freedom will lead to a more geographically open world where people will be more able to leave when there is unrest.
Blockchain will make record keeping significantly easier, eliminating the need for a significant portion of government workers whose sole responsibility is paperwork.
Overrated are smart contracts.

6. Tokens will replace company stocks.
7. Blockchain increases real estate's liquidity, value, and volatility.
8. Healthcare may be most affected.
9. Crypto could end privacy and lead to Minority Report.
10. New companies with network effects will displace incumbents.
11. Soon, people will wear rings or bracelets with crypto cash.
Some have already happened, while others are still possible.
Time will tell if they happen.
And finally:
What will web3 be?
Who will be in charge?
Closing remarks
Hope you enjoyed this web3 dive. There's much more to say, but that's for another day.
We're writing history as we go.
Tech regulation, mergers, Bitcoin surge How will history remember us?
What about web3 and blockchain?
Is this a revolution or a tulip craze?
Remember, actions speak louder than words (share them in the comments).
Your turn.

William Brucee
3 years ago
This person is probably Satoshi Nakamoto.

Who founded bitcoin is the biggest mystery in technology today, not how it works.
On October 31, 2008, Satoshi Nakamoto posted a whitepaper to a cryptography email list. Still confused by the mastermind who changed monetary history.
Journalists and bloggers have tried in vain to uncover bitcoin's creator. Some candidates self-nominated. We're still looking for the mystery's perpetrator because none of them have provided proof.
One person. I'm confident he invented bitcoin. Let's assess Satoshi Nakamoto before I reveal my pick. Or what he wants us to know.
Satoshi's P2P Foundation biography says he was born in 1975. He doesn't sound or look Japanese. First, he wrote the whitepaper and subsequent articles in flawless English. His sleeping habits are unusual for a Japanese person.
Stefan Thomas, a Bitcoin Forum member, displayed Satoshi's posting timestamps. Satoshi Nakamoto didn't publish between 2 and 8 p.m., Japanese time. Satoshi's identity may not be real.
Why would he disguise himself?
There is a legitimate explanation for this
Phil Zimmermann created PGP to give dissidents an open channel of communication, like Pretty Good Privacy. US government seized this technology after realizing its potential. Police investigate PGP and Zimmermann.
This technology let only two people speak privately. Bitcoin technology makes it possible to send money for free without a bank or other intermediary, removing it from government control.
How much do we know about the person who invented bitcoin?
Here's what we know about Satoshi Nakamoto now that I've covered my doubts about his personality.
Satoshi Nakamoto first appeared with a whitepaper on metzdowd.com. On Halloween 2008, he presented a nine-page paper on a new peer-to-peer electronic monetary system.

Using the nickname satoshi, he created the bitcointalk forum. He kept developing bitcoin and created bitcoin.org. Satoshi mined the genesis block on January 3, 2009.
Satoshi Nakamoto worked with programmers in 2010 to change bitcoin's protocol. He engaged with the bitcoin community. Then he gave Gavin Andresen the keys and codes and transferred community domains. By 2010, he'd abandoned the project.
The bitcoin creator posted his goodbye on April 23, 2011. Mike Hearn asked Satoshi if he planned to rejoin the group.
“I’ve moved on to other things. It’s in good hands with Gavin and everyone.”
Nakamoto Satoshi
The man who broke the banking system vanished. Why?

Satoshi's wallets held 1,000,000 BTC. In December 2017, when the price peaked, he had over US$19 billion. Nakamoto had the 44th-highest net worth then. He's never cashed a bitcoin.
This data suggests something happened to bitcoin's creator. I think Hal Finney is Satoshi Nakamoto .
Hal Finney had ALS and died in 2014. I suppose he created the future of money, then he died, leaving us with only rumors about his identity.
Hal Finney, who was he?
Hal Finney graduated from Caltech in 1979. Student peers voted him the smartest. He took a doctoral-level gravitational field theory course as a freshman. Finney's intelligence meets the first requirement for becoming Satoshi Nakamoto.
Students remember Finney holding an Ayn Rand book. If he'd read this, he may have developed libertarian views.
His beliefs led him to a small group of freethinking programmers. In the 1990s, he joined Cypherpunks. This action promoted the use of strong cryptography and privacy-enhancing technologies for social and political change. Finney helped them achieve a crypto-anarchist perspective as self-proclaimed privacy defenders.
Zimmermann knew Finney well.
Hal replied to a Cypherpunk message about Phil Zimmermann and PGP. He contacted Phil and became PGP Corporation's first member, retiring in 2011. Satoshi Nakamoto quit bitcoin in 2011.
Finney improved the new PGP protocol, but he had to do so secretly. He knew about Phil's PGP issues. I understand why he wanted to hide his identity while creating bitcoin.
Why did he pretend to be from Japan?
His envisioned persona was spot-on. He resided near scientist Dorian Prentice Satoshi Nakamoto. Finney could've assumed Nakamoto's identity to hide his. Temple City has 36,000 people, so what are the chances they both lived there? A cryptographic genius with the same name as Bitcoin's creator: coincidence?
Things went differently, I think.
I think Hal Finney sent himself Satoshis messages. I know it's odd. If you want to conceal your involvement, do as follows. He faked messages and transferred the first bitcoins to himself to test the transaction mechanism, so he never returned their money.
Hal Finney created the first reusable proof-of-work system. The bitcoin protocol. In the 1990s, Finney was intrigued by digital money. He invented CRypto cASH in 1993.
Legacy
Hal Finney's contributions should not be forgotten. Even if I'm wrong and he's not Satoshi Nakamoto, we shouldn't forget his bitcoin contribution. He helped us achieve a better future.
You might also like

1eth1da
3 years ago
6 Rules to build a successful NFT Community in 2022

Too much NFT, Discord, and shitposting.
How do you choose?
How do you recruit more members to join your NFT project?
In 2021, a successful NFT project required:
Monkey/ape artwork
Twitter and Discord bot-filled
Roadmap overpromise
Goal was quick cash.
2022 and the years after will change that.
These are 6 Rules for a Strong NFT Community in 2022:
THINK LONG TERM
This relates to roadmap planning. Hype and dumb luck may drive NFT projects (ahem, goblins) but rarely will your project soar.
Instead, consider sustainability.
Plan your roadmap based on your team's abilities.
Do what you're already doing, but with NFTs, make it bigger and better.
You shouldn't copy a project's roadmap just because it was profitable.
This will lead to over-promising, team burnout, and an RUG NFT project.
OFFER VALUE
Building a great community starts with giving.
Why are musicians popular?
Because they offer entertainment for everyone, a random person becomes a fan, and more fans become a cult.
That's how you should approach your community.
TEAM UP
A great team helps.
An NFT project could have 3 or 2 people.
Credibility trumps team size.
Make sure your team can answer community questions, resolve issues, and constantly attend to them.
Don't overwork and burn out.
Your community will be able to recognize that you are trying too hard and give up on the project.
BUILD A GREAT PRODUCT
Bored Ape Yacht Club altered the NFT space.
Cryptopunks transformed NFTs.
Many others did, including Okay Bears.
What made them that way?
Because they answered a key question.
What is my NFT supposed to be?
Before planning art, this question must be answered.
NFTs can't be just jpegs.
What does it represent?
Is it a Metaverse-ready project?
What blockchain are you going to be using and why?
Set some ground rules for yourself. This helps your project's direction.
These questions will help you and your team set a direction for blockchain, NFT, and Web3 technology.
EDUCATE ON WEB3
The more the team learns about Web3 technology, the more they can offer their community.
Think tokens, metaverse, cross-chain interoperability and more.
BUILD A GREAT COMMUNITY
Several projects mistreat their communities.
They treat their community like "customers" and try to sell them NFT.
Providing Whitelists and giveaways aren't your only community-building options.
Think bigger.
Consider them family and friends, not wallets.
Consider them fans.
These are some tips to start your NFT project.

Camilla Dudley
3 years ago
How to gain Twitter followers: A 101 Guide

No wonder brands use Twitter to reach their audience. 53% of Twitter users buy new products first.
Twitter growth does more than make your brand look popular. It helps clients trust your business. It boosts your industry standing. It shows clients, prospects, and even competitors you mean business.
How can you naturally gain Twitter followers?
Share useful information
Post visual content
Tweet consistently
Socialize
Spread your @name everywhere.
Use existing customers
Promote followers
Share useful information
Twitter users join conversations and consume material. To build your followers, make sure your material appeals to them and gives value, whether it's sales, product lessons, or current events.
Use Twitter Analytics to learn what your audience likes.
Explore popular topics by utilizing relevant keywords and hashtags. Check out this post on how to use Twitter trends.
Post visual content
97% of Twitter users focus on images, so incorporating media can help your Tweets stand out. Visuals and videos make content more engaging and memorable.
Tweet often
Your audience should expect regular content updates. Plan your ideas and tweet during crucial seasons and events with a content calendar.
Socialize
Twitter connects people. Do more than tweet. Follow industry leaders. Retweet influencers, engage with thought leaders, and reply to mentions and customers to boost engagement.
Micro-influencers can promote your brand or items. They can help you gain new audiences' trust.
Spread your @name everywhere.
Maximize brand exposure. Add a follow button on your website, link to it in your email signature and newsletters, and promote it on business cards or menus.
Use existing customers
Emails can be used to find existing Twitter clients. Upload your email contacts and follow your customers on Twitter to start a dialogue.
Promote followers
Run a followers campaign to boost your organic growth. Followers campaigns promote your account to a particular demographic, and you only pay when someone follows you.
Consider short campaigns to enhance momentum or an always-on campaign to gain new followers.
Increasing your brand's Twitter followers takes effort and experimentation, but the payback is huge.
👋 Follow me on twitter

Francesca Furchtgott
3 years ago
Giving customers what they want or betraying the values of the brand?
A J.Crew collaboration for fashion label Eveliina Vintage is not a paradox; it is a solution.

Eveliina Vintage's capsule collection debuted yesterday at J.Crew. This J.Crew partnership stopped me in my tracks.
Eveliina Vintage sells vintage goods. Eeva Musacchia founded the shop in Finland in the 1970s. It's recognized for its one-of-a-kind slip dresses from the 1930s and 1940s.
I wondered why a vintage brand would partner with a mass shop. Fast fashion against vintage shopping? Will Eveliina Vintages customers be turned off?
But Eveliina Vintages customers don't care about sustainability. They want Eveliina's Instagram look. Eveliina Vintage collaborated with J.Crew to give customers what they wanted: more Eveliina at a lower price.
Vintage: A Fashion Option That Is Eco-Conscious
Secondhand shopping is a trendy response to quick fashion. J.Crew releases hundreds of styles annually. Waste and environmental damage have been criticized. A pair of jeans requires 1,800 gallons of water. J.Crew's limited-time deals promote more purchases. J.Crew items are likely among those Americans wear 7 times before discarding.
Consumers and designers have emphasized sustainability in recent years. Stella McCartney and Eileen Fisher are popular eco-friendly brands. They've also flocked to ThredUp and similar sites.
Gap, Levis, and Allbirds have listened to consumer requests. They promote recycling, ethical sourcing, and secondhand shopping.
Secondhand shoppers feel good about reusing and recycling clothing that might have ended up in a landfill.
Eco-conscious fashionistas shop vintage. These shoppers enjoy the thrill of the hunt (that limited-edition Chanel bag!) and showing off a unique piece (nobody will have my look!). They also reduce their environmental impact.
Is Eveliina Vintage capitalizing on an aesthetic or is it a sustainable brand?
Eveliina Vintage emphasizes environmental responsibility. Vogue's Amanda Musacchia emphasized sustainability. Amanda, founder Eeva's daughter, is a company leader.
But Eveliina's press message doesn't address sustainability, unlike Instagram. Scarcity and fame rule.
Eveliina Vintages Instagram has see-through dresses and lace-trimmed slip dresses. Celebrities and influencers are often photographed in Eveliina's apparel, which has 53,000+ followers. Vogue appreciates Eveliina's style. Multiple publications discuss Alexa Chung's Eveliina dress.
Eveliina Vintage markets its one-of-a-kind goods. It teases future content, encouraging visitors to return. Scarcity drives demand and raises clothing prices. One dress is $1,600+, but most are $500-$1,000.
The catch: Eveliina can't monetize its expanding popularity due to exorbitant prices and limited quantity. Why?
Most people struggle to pay for their clothing. But Eveliina Vintage lacks those more affordable entry-level products, in contrast to other luxury labels that sell accessories or perfume.
Many people have trouble fitting into their clothing. The bodies of most women in the past were different from those for which vintage clothing was designed. Each Eveliina dress's specific measurements are mentioned alongside it. Be careful, you can fall in love with an ill-fitting dress.
No matter how many people can afford it and fit into it, there is only one item to sell. To get the item before someone else does, those people must be on the Eveliina Vintage website as soon as it becomes available.
A Way for Eveliina Vintage to Make Money (and Expand) with J.Crew Its following
Eveliina Vintages' cooperation with J.Crew makes commercial sense.
This partnership spreads Eveliina's style. Slightly better pricing The $390 outfits have multicolored slips and gauzy cotton gowns. Sizes range from 00 to 24, which is wider than vintage racks.
Eveliina Vintage customers like the combination. Excited comments flood the brand's Instagram launch post. Nobody is mocking the 50-year-old vintage brand's fast-fashion partnership.
Vintage may be a sustainable fashion trend, but that's not why Eveliina's clients love the brand. They only care about the old look.
And that is a tale as old as fashion.