



More on Entrepreneurship/Creators

Stephen Moore
3 years ago
Adam Neumanns is working to create the future of living in a classic example of a guy failing upward.
The comeback tour continues…

First, he founded a $47 billion co-working company (sorry, a “tech company”).
He established WeLive to disrupt apartment life.
Then he created WeGrow, a school that tossed aside the usual curriculum to feed children's souls and release their potential.
He raised the world’s consciousness.
Then he blew it all up (without raising the world’s consciousness). (He bought a wave pool.)
Adam Neumann's WeWork business burned investors' money. The founder sailed off with unimaginable riches, leaving long-time employees with worthless stocks and the company bleeding money. His track record, which includes a failing baby clothing company, should have stopped investors cold.
Once the dust settled, folks went on. We forgot about the Neumanns! We forgot about the private jets, company retreats, many houses, and WeWork's crippling. In that moment, the prodigal son of entrepreneurship returned, choosing the blockchain as his industry. His homecoming tour began with Flowcarbon, which sold Goddess Nature Tokens to lessen companies' carbon footprints.
Did it work?
Of course not.
Despite receiving $70 million from Andreessen Horowitz's a16z, the project has been halted just two months after its announcement.
This triumph should lower his grade.
Neumann seems to have moved on and has another revolutionary idea for the future of living. Flow (not Flowcarbon) aims to help people live in flow and will launch in 2023. It's the classic Neumann pitch: lofty goals, yogababble, and charisma to attract investors.
It's a winning formula for one investment fund. a16z has backed the project with its largest single check, $350 million. It has a splash page and 3,000 rental units, but is valued at over $1 billion. The blog post praised Neumann for reimagining the office and leading a paradigm-shifting global company.

Flow's mission is to solve the nation's housing crisis. How? Idk. It involves offering community-centric services in apartment properties to the same remote workforce he once wooed with free beer and a pingpong table. Revolutionary! It seems the goal is to apply WeWork's goals of transforming physical spaces and building community to apartments to solve many of today's housing problems.
The elevator pitch probably sounded great.
At least a16z knows it's a near-impossible task, calling it a seismic shift. Marc Andreessen opposes affordable housing in his wealthy Silicon Valley town. As details of the project emerge, more investors will likely throw ethics and morals out the window to go with the flow, throwing money at a man known for burning through it while building toxic companies, hoping he can bank another fantasy valuation before it all crashes.
Insanity is repeating the same action and expecting a different result. Everyone on the Neumann hype train needs to sober up.
Like WeWork, this venture Won’tWork.
Like before, it'll cause a shitstorm.

Jerry Keszka
3 years ago
10 Crazy Useful Free Websites No One Told You About But You Needed
The internet is a massive information resource. With so much stuff, it's easy to forget about useful websites. Here are five essential websites you may not have known about.

1. Companies.tools
Companies.tools are what successful startups employ. This website offers a curated selection of design, research, coding, support, and feedback resources. Ct has the latest app development platform and greatest client feedback method.
2. Excel Formula Bot
Excel Formula Bot can help if you forget a formula. Formula Bot uses AI to convert text instructions into Excel formulas, so you don't have to remember them.
Just tell the Bot what to do, and it will do it. Excel Formula Bot can calculate sales tax and vacation days. When you're stuck, let the Bot help.
3.TypeLit
TypeLit helps you improve your typing abilities while reading great literature.
TypeLit.io lets you type any book or dozens of preset classics. TypeLit provides real-time feedback on accuracy and speed.
Goals and progress can be tracked. Why not improve your typing and learn great literature with TypeLit?
4. Calm Schedule
Finding a meeting time that works for everyone is difficult. Personal and business calendars might be difficult to coordinate.
Synchronize your two calendars to save time and avoid problems. You may avoid searching through many calendars for conflicts and keep your personal information secret. Having one source of truth for personal and work occasions will help you never miss another appointment.
https://calmcalendar.com/
5. myNoise
myNoise makes the outside world quieter. myNoise is the right noise for a noisy office or busy street.
If you can't locate the right noise, make it. MyNoise unlocks the world. Shut out distractions. Thank your ears.
6. Synthesia
Professional videos require directors, filmmakers, editors, and animators. Now, thanks to AI, you can generate high-quality videos without video editing experience.
AI avatars are crucial. You can design a personalized avatar using a web-based software like synthesia.io. Our avatars can lip-sync in over 60 languages, so you can make worldwide videos. There's an AI avatar for every video goal.
Not free. Amazing service, though.
7. Cleaning-up-images
Have you shot a wonderful photo just to notice something in the background? You may have a beautiful headshot but wish to erase an imperfection.
Cleanup.pictures removes undesirable objects from photos. Our algorithms will eliminate the selected object.
Cleanup.pictures can help you obtain the ideal shot every time. Next time you take images, let Cleanup.pictures fix any flaws.
8. PDF24 Tools
Editing a PDF can be a pain. Most of us don't know Adobe Acrobat's functionalities. Why buy something you'll rarely use? Better options exist.
PDF24 is an online PDF editor that's free and subscription-free. Rotate, merge, split, compress, and convert PDFs in your browser. PDF24 makes document signing easy.
Upload your document, sign it (or generate a digital signature), and download it. It's easy and free. PDF24 is a free alternative to pricey PDF editing software.
9. Class Central
Finding online classes is much easier. Class Central has classes from Harvard, Stanford, Coursera, Udemy, and Google, Amazon, etc. in one spot.
Whether you want to acquire a new skill or increase your knowledge, you'll find something. New courses bring variety.
10. Rome2rio
Foreign travel offers countless transport alternatives. How do you get from A to B? It’s easy!
Rome2rio will show you the best method to get there, including which mode of transport is ideal.
Plane
Car
Train
Bus
Ferry
Driving
Shared bikes
Walking
Do you know any free, useful websites?

Jim Siwek
3 years ago
In 2022, can a lone developer be able to successfully establish a SaaS product?

In the early 2000s, I began developing SaaS. I helped launch an internet fax service that delivered faxes to email inboxes. Back then, it saved consumers money and made the procedure easier.
Google AdWords was young then. Anyone might establish a new website, spend a few hundred dollars on keywords, and see dozens of new paying clients every day. That's how we launched our new SaaS, and these clients stayed for years. Our early ROI was sky-high.
Changing times
The situation changed dramatically after 15 years. Our paid advertising cost $200-$300 for every new customer. Paid advertising takes three to four years to repay.
Fortunately, we still had tens of thousands of loyal clients. Good organic rankings gave us new business. We needed less sponsored traffic to run a profitable SaaS firm.
Is it still possible?
Since selling our internet fax firm, I've dreamed about starting a SaaS company. One I could construct as a lone developer and progressively grow a dedicated customer base, as I did before in a small team.
It seemed impossible to me. Solo startups couldn't afford paid advertising. SEO was tough. Even the worst SaaS startup ideas attracted VC funding. How could I compete with startups that could hire great talent and didn't need to make money for years (or ever)?
The One and Only Way to Learn
After years of talking myself out of SaaS startup ideas, I decided to develop and launch one. I needed to know if a solitary developer may create a SaaS app in 2022.
Thus, I did. I invented webwriter.ai, an AI-powered writing tool for website content, from hero section headlines to blog posts, this year. I soft-launched an MVP in July.
Considering the Issue
Now that I've developed my own fully capable SaaS app for site builders and developers, I wonder if it's still possible. Can webwriter.ai be successful?
I know webwriter.ai's proposal is viable because Jasper.ai and Grammarly are also AI-powered writing tools. With competition comes validation.
To Win, Differentiate
To compete with well-funded established brands, distinguish to stand out to a portion of the market. So I can speak directly to a target user, unlike larger competition.
I created webwriter.ai to help web builders and designers produce web content rapidly. This may be enough differentiation for now.
Budget-Friendly Promotion
When paid search isn't an option, we get inventive. There are more tools than ever to promote a new website.
Organic Results
on social media (Twitter, Instagram, TikTok, LinkedIn)
Marketing with content that is compelling
Link Creation
Listings in directories
references made in blog articles and on other websites
Forum entries
The Beginning of the Journey
As I've labored to construct my software, I've pondered a new mantra. Not sure where that originated from, but I like it. I'll live by it and teach my kids:
“Do the work.”
You might also like

M.G. Siegler
3 years ago
Apple: Showing Ads on Your iPhone
This report from Mark Gurman has stuck with me:
In the News and Stocks apps, the display ads are no different than what you might get on an ad-supported website. In the App Store, the ads are for actual apps, which are probably more useful for Apple users than mortgage rates. Some people may resent Apple putting ads in the News and Stocks apps. After all, the iPhone is supposed to be a premium device. Let’s say you shelled out $1,000 or more to buy one, do you want to feel like Apple is squeezing more money out of you just to use its standard features? Now, a portion of ad revenue from the News app’s Today tab goes to publishers, but it’s not clear how much. Apple also lets publishers advertise within their stories and keep the vast majority of that money. Surprisingly, Today ads also appear if you subscribe to News+ for $10 per month (though it’s a smaller number).
I use Apple News often. It's a good general news catch-up tool, like Twitter without the BS. Customized notifications are helpful. Fast and lovely. Except for advertisements. I have Apple One, which includes News+, and while I understand why the magazines still have brand ads, it's ridiculous to me that Apple enables web publishers to introduce awful ads into this experience. Apple's junky commercials are ridiculous.
We know publishers want and probably requested this. Let's keep Apple News ad-free for the much smaller percentage of paid users, and here's your portion. (Same with Stocks, which is more sillier.)
Paid app placement in the App Store is a wonderful approach for developers to find new users (though far too many of those ads are trying to trick users, in my opinion).
Apple is also planning to increase ads in its Maps app. This sounds like Google Maps, and I don't like it. I never find these relevant, and they clutter up the user experience. Apple Maps now has a UI advantage (though not a data/search one, which matters more).
Apple is nickel-and-diming its customers. We spend thousands for their products and premium services like Apple One. We all know why: income must rise, and new firms are needed to scale. This will eventually backfire.

The woman
3 years ago
Why Google's Hiring Process is Brilliant for Top Tech Talent
Without a degree and experience, you can get a high-paying tech job.

Most organizations follow this hiring rule: you chat with HR, interview with your future boss and other senior managers, and they make the final hiring choice.
If you've ever applied for a job, you know how arduous it can be. A newly snapped photo and a glossy resume template can wear you out. Applying to Google can change this experience.
According to an Universum report, Google is one of the world's most coveted employers. It's not simply the search giant's name and reputation that attract candidates, but its role requirements or lack thereof.
Candidates no longer need a beautiful resume, cover letter, Ivy League laurels, or years of direct experience. The company requires no degree or experience.
Elon Musk started it. He employed the two-hands test to uncover talented non-graduates. The billionaire eliminated the requirement for experience.
Google is deconstructing traditional employment with programs like the Google Project Management Degree, a free online and self-paced professional credential course.
Google's hiring is interesting. After its certification course, applicants can work in project management. Instead of academic degrees and experience, the company analyzes coursework.
Google finds the best project managers and technical staff in exchange. Google uses three strategies to find top talent.
Chase down the innovators
Google eliminates restrictions like education, experience, and others to find the polar bear amid the snowfall. Google's free project management education makes project manager responsibilities accessible to everyone.
Many jobs don't require a degree. Overlooking individuals without a degree can make it difficult to locate a candidate who can provide value to a firm.
Firsthand knowledge follows the same rule. A lack of past information might be an employer's benefit. This is true for creative teams or businesses that prefer to innovate.
Or when corporations conduct differently from the competition. No-experience candidates can offer fresh perspectives. Fast Company reports that people with no sales experience beat those with 10 to 15 years of experience.
Give the aptitude test first priority.
Google wants the best candidates. Google wouldn't be able to receive more applications if it couldn't screen them for fit. Its well-organized online training program can be utilized as a portfolio.
Google learns a lot about an applicant through completed assignments. It reveals their ability, leadership style, communication capability, etc. The course mimics the job to assess candidates' suitability.
Basic screening questions might provide information to compare candidates. Any size small business can use screening questions and test projects to evaluate prospective employees.
Effective training for employees
Businesses must train employees regardless of their hiring purpose. Formal education and prior experience don't guarantee success. Maintaining your employees' professional knowledge gaps is key to their productivity and happiness. Top-notch training can do that. Learning and development are key to employee engagement, says Bob Nelson, author of 1,001 Ways to Engage Employees.
Google's online certification program isn't available everywhere. Improving the recruiting process means emphasizing aptitude over experience and a degree. Instead of employing new personnel and having them work the way their former firm trained them, train them how you want them to function.
If you want to know more about Google’s recruiting process, we recommend you watch the movie “Internship.”

Desiree Peralta
3 years ago
How to Use the 2023 Recession to Grow Your Wealth Exponentially
This season's three best money moves.

“Millionaires are made in recessions.” — Time Capital
We're in a serious downturn, whether or not we're in a recession.
97% of business owners are decreasing costs by more than 10%, and all markets are down 30%.
If you know what you're doing and analyze the markets correctly, this is your chance to become a millionaire.
In any recession, there are always excellent possibilities to seize. Real estate, crypto, stocks, enterprises, etc.
What you do with your money could influence your future riches.
This article analyzes the three key markets, their circumstances for 2023, and how to profit from them.
Ways to make money on the stock market.
If you're conservative like me, you should invest in an index fund. Most of these funds are down 10-30% of ATH:
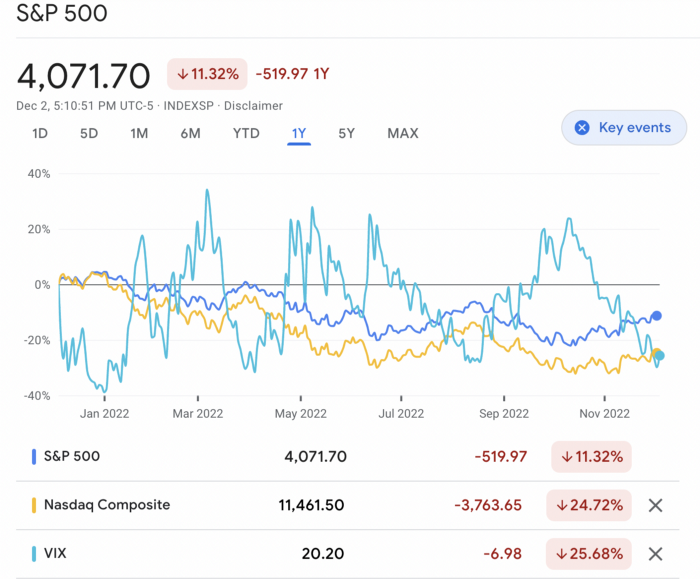
In earlier recessions, most money index funds lost 20%. After this downturn, they grew and passed the ATH in subsequent months.
Now is the greatest moment to invest in index funds to grow your money in a low-risk approach and make 20%.
If you want to be risky but wise, pick companies that will get better next year but are struggling now.
Even while we can't be 100% confident of a company's future performance, we know some are strong and will have a fantastic year.
Microsoft (down 22%), JPMorgan Chase (15.6%), Amazon (45%), and Disney (33.8%).
These firms give dividends, so you can earn passively while you wait.
So I consider that a good strategy to make wealth in the current stock market is to create two portfolios: one based on index funds to earn 10% to 20% profit when the corrections end, and the other based on individual stocks of popular and strong companies to earn 20%-30% return and dividends while you wait.
How to profit from the downturn in the real estate industry.
With rising mortgage rates, it's the worst moment to buy a home if you don't want to be eaten by banks. In the U.S., interest rates are double what they were three years ago, so buying now looks foolish.
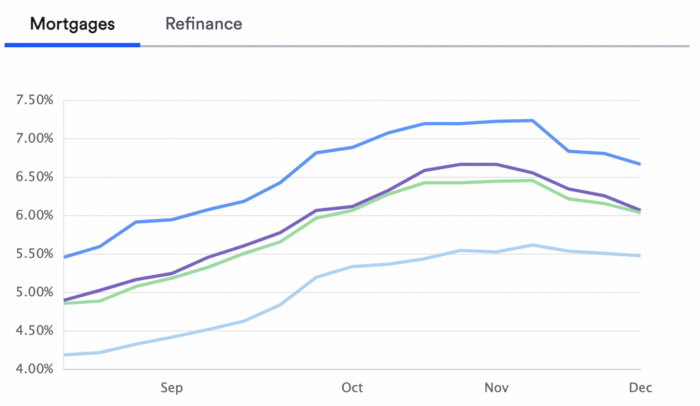
Due to these rates, property prices are falling, but that won't last long since individuals will take advantage.
According to historical data, now is the ideal moment to buy a house for the next five years and perhaps forever.
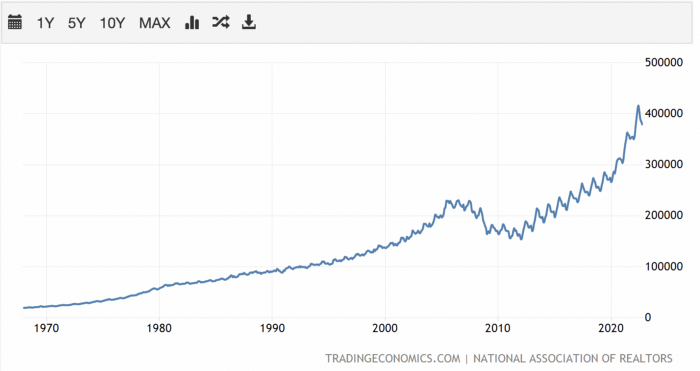
If you can buy a house, do it. You can refinance the interest at a lower rate with acceptable credit, but not the house price.
Take advantage of the housing market prices now because you won't find a decent deal when rates normalize.
How to profit from the cryptocurrency market.
This is the riskiest market to tackle right now, but it could offer the most opportunities if done appropriately.
The most powerful cryptocurrencies are down more than 60% from last year: $68,990 for BTC and $4,865 for ETH.
If you focus on those two coins, you can make 30%-60% without waiting for them to return to their ATH, and they're low enough to be a solid investment.
I don't encourage trying other altcoins because the crypto market is in crisis and you can lose everything if you're greedy.
Still, the main Cryptos are a good investment provided you store them in an external wallet and follow financial gurus' security advice.
Last thoughts
We can't anticipate a recession until it ends. We can't forecast a market or asset's lowest point, therefore waiting makes little sense.
If you want to develop your wealth, assess the money prospects on all the marketplaces and initiate long-term trades.
Many millionaires are made during recessions because they don't fear negative figures and use them to scale their money.