



More on Entrepreneurship/Creators

Edward Williams
3 years ago
I currently manage 4 profitable online companies. I find all the generic advice and garbage courses very frustrating. The only advice you need is this.

This is for young entrepreneurs, especially in tech.
People give useless success advice on TikTok and Reddit. Early risers, bookworms, etc. Entrepreneurship courses. Work hard and hustle.
False. These aren't successful traits.
I mean, organization is good. As someone who founded several businesses and now works at a VC firm, I find these tips to be clichés.
Based on founding four successful businesses and working with other successful firms, here's my best actionable advice:
1. Choose a sector or a niche and become an expert in it.
This is more generic than my next tip, but it's a must-do that's often overlooked. Become an expert in the industry or niche you want to enter. Discover everything.
Buy (future) competitors' products. Understand consumers' pain points. Market-test. Target keyword combos. Learn technical details.
The most successful businesses I've worked with were all formed by 9-5 employees. They knew the industry's pain points. They started a business targeting these pain points.
2. Choose a niche or industry crossroads to target.
How do you choose an industry or niche? What if your industry is too competitive?
List your skills and hobbies. Randomness is fine. Find an intersection between two interests or skills.
Say you build websites well. You like cars.
Web design is a *very* competitive industry. Cars and web design?
Instead of web design, target car dealers and mechanics. Build a few fake demo auto mechanic websites, then cold call shops with poor websites. Verticalize.
I've noticed a pattern:
Person works in a particular industry for a corporation.
Person gains expertise in the relevant industry.
Person quits their job and launches a small business to address a problem that their former employer was unwilling to address.
I originally posted this on Reddit and it seemed to have taken off so I decided to share it with you all.
Focus on the product. When someone buys from you, you convince them the product's value exceeds the price. It's not fair and favors the buyer.
Creating a superior product or service will win. Narrowing this helps you outcompete others.
You may be their only (lucky) option.

Aaron Dinin, PhD
3 years ago
I put my faith in a billionaire, and he destroyed my business.
How did his money blind me?

Like most fledgling entrepreneurs, I wanted a mentor. I met as many nearby folks with "entrepreneur" in their LinkedIn biographies for coffee.
These meetings taught me a lot, and I'd suggest them to any new creator. Attention! Meeting with many experienced entrepreneurs means getting contradictory advice. One entrepreneur will tell you to do X, then the next one you talk to may tell you to do Y, which are sometimes opposites. You'll have to chose which suggestion to take after the chats.
I experienced this. Same afternoon, I had two coffee meetings with experienced entrepreneurs. The first meeting was with a billionaire entrepreneur who took his company public.
I met him in a swanky hotel lobby and ordered a drink I didn't pay for. As a fledgling entrepreneur, money was scarce.
During the meeting, I demoed the software I'd built, he liked it, and we spent the hour discussing what features would make it a success. By the end of the meeting, he requested I include a killer feature we both agreed would attract buyers. The feature was complex and would require some time. The billionaire I was sipping coffee with in a beautiful hotel lobby insisted people would love it, and that got me enthusiastic.
The second meeting was with a young entrepreneur who had recently raised a small amount of investment and looked as eager to pitch me as I was to pitch him. I forgot his name. I mostly recall meeting him in a filthy coffee shop in a bad section of town and buying his pricey cappuccino. Water for me.
After his pitch, I demoed my app. When I was done, he barely noticed. He questioned my customer acquisition plan. Who was my client? What did they offer? What was my plan? Etc. No decent answers.
After our meeting, he insisted I spend more time learning my market and selling. He ignored my questions about features. Don't worry about features, he said. Customers will request features. First, find them.
Putting your faith in results over relevance
Problems plagued my afternoon. I met with two entrepreneurs who gave me differing advice about how to proceed, and I had to decide which to pursue. I couldn't decide.
Ultimately, I followed the advice of the billionaire.
Obviously.
Who wouldn’t? That was the guy who clearly knew more.
A few months later, I constructed the feature the billionaire said people would line up for.
The new feature was unpopular. I couldn't even get the billionaire to answer an email showing him what I'd done. He disappeared.
Within a few months, I shut down the company, wasting all the time and effort I'd invested into constructing the killer feature the billionaire said I required.
Would follow the struggling entrepreneur's advice have saved my company? It would have saved me time in retrospect. Potential consumers would have told me they didn't want what I was producing, and I could have shut down the company sooner or built something they did want. Both outcomes would have been better.
Now I know, but not then. I favored achievement above relevance.
Success vs. relevance
The millionaire gave me advice on building a large, successful public firm. A successful public firm is different from a startup. Priorities change in the last phase of business building, which few entrepreneurs reach. He gave wonderful advice to founders trying to double their stock values in two years, but it wasn't beneficial for me.
The other failing entrepreneur had relevant, recent experience. He'd recently been in my shoes. We still had lots of problems. He may not have achieved huge success, but he had valuable advice on how to pass the closest hurdle.
The money blinded me at the moment. Not alone So much of company success is defined by money valuations, fundraising, exits, etc., so entrepreneurs easily fall into this trap. Money chatter obscures the value of knowledge.
Don't base startup advice on a person's income. Focus on what and when the person has learned. Relevance to you and your goals is more important than a person's accomplishments when considering advice.

Carter Kilmann
3 years ago
I finally achieved a $100K freelance income. Here's what I wish I knew.

We love round numbers, don't we? $100,000 is a frequent freelancing milestone. You feel like six figures means you're doing something properly.
You've most likely already conquered initial freelancing challenges like finding clients, setting fair pricing, coping with criticism, getting through dry spells, managing funds, etc.
You think I must be doing well. Last month, my freelance income topped $100,000.
That may not sound impressive considering I've been freelancing for 2.75 years, but I made 30% of that in the previous four months, which is crazy.
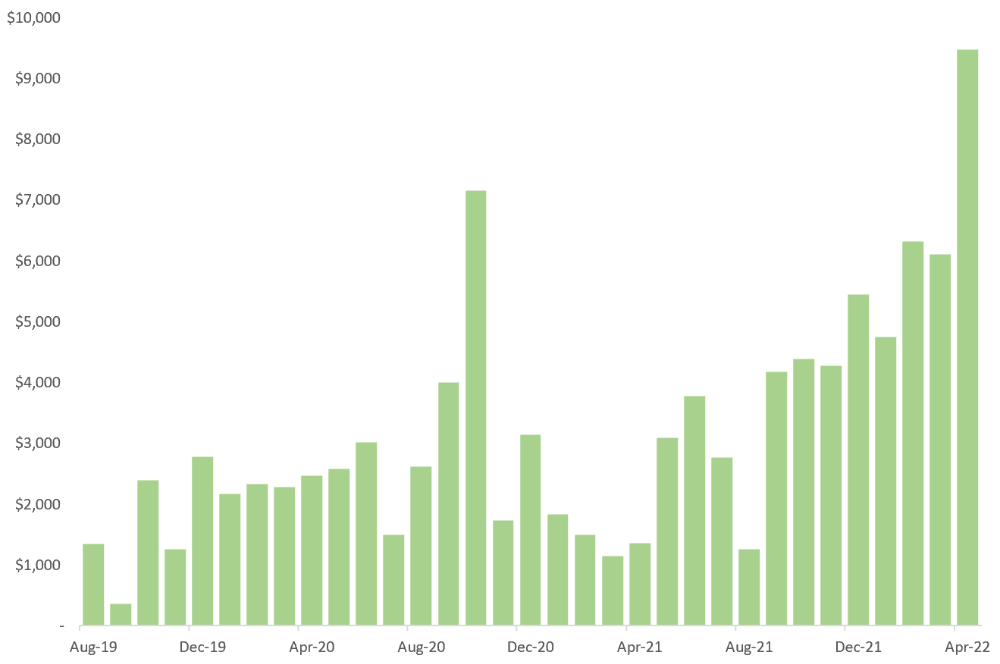
Here are the things I wish I'd known during the early days of self-employment that would have helped me hit $100,000 faster.
1. The Volatility of Freelancing Will Stabilize.
Freelancing is risky. No surprise.
Here's an example.
October 2020 was my best month, earning $7,150. Between $4,004 in September and $1,730 in November. Unsteady.
Freelancing is regrettably like that. Moving clients. Content requirements change. Allocating so much time to personal pursuits wasn't smart, but yet.
Stabilizing income takes time. Consider my rolling three-month average income since I started freelancing. My three-month average monthly income. In February, this metric topped $5,000. Now, it's in the mid-$7,000s, but it took a while to get there.
Finding freelance gigs that provide high pay, high volume, and recurring revenue is difficult. But it's not impossible.
TLDR: Don't expect a steady income increase at first. Be patient.
2. You Have More Value Than You Realize.
Writing is difficult. Assembling words, communicating a message, and provoking action are a puzzle.
People are willing to pay you for it because they can't do what you do or don't have enough time.
Keeping that in mind can have huge commercial repercussions.
When talking to clients, don't tiptoe. You can ignore ridiculous deadlines. You don't have to take unmanageable work.
You solve an issue, so make sure you get rightly paid.
TLDR: Frame services as problem-solutions. This will let you charge more and set boundaries.
3. Increase Your Prices.
I studied hard before freelancing. I read articles and watched videos about writing businesses.
I didn't want to work for pennies. Despite this clarity, I had no real strategy to raise my rates.
I then luckily stumbled into higher-paying work. We discussed fees and hours with a friend who launched a consulting business. It's subjective and speculative because value isn't standardized. One company may laugh at your charges. If your solution helps them create a solid ROI, another client may pay $200 per hour.
When he told me he charged his first client $125 per hour, I thought, Why not?
A new-ish client wanted to discuss a huge forthcoming project, so I raised my rates. They knew my worth, so they didn't blink when I handed them my new number.
TLDR: Increase rates periodically (e.g., every 6 or 12 months). Writing skill develops with practice. You'll gain value over time.
4. Remember Your Limits.
If you can squeeze additional time into a day, let me know. I can't manipulate time yet.
We all have time and economic limits. You could theoretically keep boosting rates, but your prospect pool diminishes. Outsourcing and establishing extra revenue sources might boost monthly revenues.
I've devoted a lot of time to side projects (hopefully extra cash sources), but I've only just started outsourcing. I wish I'd tried this earlier.
If you can discover good freelancers, you can grow your firm without sacrificing time.
TLDR: Expand your writing network immediately. You'll meet freelancers who understand your daily grind and locate reference sources.
5. Every Action You Take Involves an Investment. Be Certain to Select Correctly.
Investing in stocks or crypto requires paying money, right?
In business, time is your currency (and maybe money too). Your daily habits define your future. If you spend time collecting software customers and compiling content in the space, you'll end up with both. So be sure.
I only spend around 50% of my time on client work, therefore it's taken me nearly three years to earn $100,000. I spend the remainder of my time on personal projects including a freelance book, an investment newsletter, and this blog.
Why? I don't want to rely on client work forever. So, I'm working on projects that could pay off later and help me live a more fulfilling life.
TLDR: Consider the long-term impact of your time commitments, and don't overextend. You can only make so many "investments" in a given time.
6. LinkedIn Is an Endless Mine of Gold. Use It.
Why didn't I use LinkedIn earlier?
I designed a LinkedIn inbound lead strategy that generates 12 leads a month and a few high-quality offers. As a result, I've turned down good gigs. Wish I'd begun earlier.
If you want to create a freelance business, prioritize LinkedIn. Too many freelancers ignore this site, missing out on high-paying clients. Build your profile, post often, and interact.
TLDR: Study LinkedIn's top creators. Once you understand their audiences, start posting and participating daily.
For 99% of People, Freelancing is Not a Get-Rich-Quick Scheme.
Here's a list of things I wish I'd known when I started freelancing.
Although it is erratic, freelancing eventually becomes stable.
You deserve respect and discretion over how you conduct business because you have solved an issue.
Increase your charges rather than undervaluing yourself. If necessary, add a reminder to your calendar. Your worth grows with time.
In order to grow your firm, outsource jobs. After that, you can work on the things that are most important to you.
Take into account how your present time commitments may affect the future. It will assist in putting things into perspective and determining whether what you are doing is indeed worthwhile.
Participate on LinkedIn. You'll get better jobs as a result.
If I could give my old self (and other freelancers) one bit of advice, it's this:
Despite appearances, you're making progress.
Each job. Tweets. Newsletters. Progress. It's simpler to see retroactively than in the moment.
Consistent, intentional work pays off. No good comes from doing nothing. You must set goals, divide them into time-based targets, and then optimize your calendar.
Then you'll understand you're doing well.
Want to learn more? I’ll teach you.
You might also like

ANDREW SINGER
4 years ago
Crypto seen as the ‘future of money’ in inflation-mired countries
Crypto as the ‘future of money' in inflation-stricken nations
Citizens of devalued currencies “need” crypto. “Nice to have” in the developed world.
According to Gemini's 2022 Global State of Crypto report, cryptocurrencies “evolved from what many considered a niche investment into an established asset class” last year.
More than half of crypto owners in Brazil (51%), Hong Kong (51%), and India (54%), according to the report, bought cryptocurrency for the first time in 2021.
The study found that inflation and currency devaluation are powerful drivers of crypto adoption, especially in emerging market (EM) countries:
“Respondents in countries that have seen a 50% or greater devaluation of their currency against the USD over the last decade were more than 5 times as likely to plan to purchase crypto in the coming year.”
Between 2011 and 2021, the real lost 218 percent of its value against the dollar, and 45 percent of Brazilians surveyed by Gemini said they planned to buy crypto in 2019.
The rand (South Africa's currency) has fallen 103 percent in value over the last decade, second only to the Brazilian real, and 32 percent of South Africans expect to own crypto in the coming year. Mexico and India, the third and fourth highest devaluation countries, followed suit.
Compared to the US dollar, Hong Kong and the UK currencies have not devalued in the last decade. Meanwhile, only 5% and 8% of those surveyed in those countries expressed interest in buying crypto.
What can be concluded? Noah Perlman, COO of Gemini, sees various crypto use cases depending on one's location.
‘Need to have' investment in countries where the local currency has devalued against the dollar, whereas in the developed world it is still seen as a ‘nice to have'.
Crypto as money substitute
As an adjunct professor at New York University School of Law, Winston Ma distinguishes between an asset used as an inflation hedge and one used as a currency replacement.
Unlike gold, he believes Bitcoin (BTC) is not a “inflation hedge”. They acted more like growth stocks in 2022. “Bitcoin correlated more closely with the S&P 500 index — and Ether with the NASDAQ — than gold,” he told Cointelegraph. But in the developing world, things are different:
“Inflation may be a primary driver of cryptocurrency adoption in emerging markets like Brazil, India, and Mexico.”
According to Justin d'Anethan, institutional sales director at the Amber Group, a Singapore-based digital asset firm, early adoption was driven by countries where currency stability and/or access to proper banking services were issues. Simply put, he said, developing countries want alternatives to easily debased fiat currencies.
“The larger flows may still come from institutions and developed countries, but the actual users may come from places like Lebanon, Turkey, Venezuela, and Indonesia.”
“Inflation is one of the factors that has and continues to drive adoption of Bitcoin and other crypto assets globally,” said Sean Stein Smith, assistant professor of economics and business at Lehman College.
But it's only one factor, and different regions have different factors, says Stein Smith. As a “instantaneously accessible, traceable, and cost-effective transaction option,” investors and entrepreneurs increasingly recognize the benefits of crypto assets. Other places promote crypto adoption due to “potential capital gains and returns”.
According to the report, “legal uncertainty around cryptocurrency,” tax questions, and a general education deficit could hinder adoption in Asia Pacific and Latin America. In Africa, 56% of respondents said more educational resources were needed to explain cryptocurrencies.
Not only inflation, but empowering our youth to live better than their parents without fear of failure or allegiance to legacy financial markets or products, said Monica Singer, ConsenSys South Africa lead. Also, “the issue of cash and remittances is huge in Africa, as is the issue of social grants.”
Money's future?
The survey found that Brazil and Indonesia had the most cryptocurrency ownership. In each country, 41% of those polled said they owned crypto. Only 20% of Americans surveyed said they owned cryptocurrency.
These markets are more likely to see cryptocurrencies as the future of money. The survey found:
“The majority of respondents in Latin America (59%) and Africa (58%) say crypto is the future of money.”
Brazil (66%), Nigeria (63%), Indonesia (61%), and South Africa (57%). Europe and Australia had the fewest believers, with Denmark at 12%, Norway at 15%, and Australia at 17%.
Will the Ukraine conflict impact adoption?
The poll was taken before the war. Will the devastating conflict slow global crypto adoption growth?
With over $100 million in crypto donations directly requested by the Ukrainian government since the war began, Stein Smith says the war has certainly brought crypto into the mainstream conversation.
“This real-world demonstration of decentralized money's power could spur wider adoption, policy debate, and increased use of crypto as a medium of exchange.”
But the war may not affect all developing nations. “The Ukraine war has no impact on African demand for crypto,” Others loom larger. “Yes, inflation, but also a lack of trust in government in many African countries, and a young demographic very familiar with mobile phones and the internet.”
A major success story like Mpesa in Kenya has influenced the continent and may help accelerate crypto adoption. Creating a plan when everyone you trust fails you is directly related to the African spirit, she said.
On the other hand, Ma views the Ukraine conflict as a sort of crisis check for cryptocurrencies. For those in emerging markets, the Ukraine-Russia war has served as a “stress test” for the cryptocurrency payment rail, he told Cointelegraph.
“These emerging markets may see the greatest future gains in crypto adoption.”
Inflation and currency devaluation are persistent global concerns. In such places, Bitcoin and other cryptocurrencies are now seen as the “future of money.” Not in the developed world, but that could change with better regulation and education. Inflation and its impact on cash holdings are waking up even Western nations.
Read original post here.

Cory Doctorow
3 years ago
The current inflation is unique.
New Stiglitz just dropped.

Here's the inflation story everyone believes (warning: it's false): America gave the poor too much money during the recession, and now the economy is awash with free money, which made them so rich they're refusing to work, meaning the economy isn't making anything. Prices are soaring due to increased cash and missing labor.
Lawrence Summers says there's only one answer. We must impoverish the poor: raise interest rates, cause a recession, and eliminate millions of jobs, until the poor are stripped of their underserved fortunes and return to work.
https://pluralistic.net/2021/11/20/quiet-part-out-loud/#profiteering
This is nonsense. Countries around the world suffered inflation during and after lockdowns, whether they gave out humanitarian money to keep people from starvation. America has slightly greater inflation than other OECD countries, but it's not due to big relief packages.
The Causes of and Responses to Today's Inflation, a Roosevelt Institute report by Nobel-winning economist Joseph Stiglitz and macroeconomist Regmi Ira, debunks this bogus inflation story and offers a more credible explanation for inflation.
https://rooseveltinstitute.org/wp-content/uploads/2022/12/RI CausesofandResponsestoTodaysInflation Report 202212.pdf
Sharp interest rate hikes exacerbate the slump and increase inflation, the authors argue. They compare monetary policy inflation cures to medieval bloodletting, where doctors repeated the same treatment until the patient recovered (for which they received credit) or died (which was more likely).
Let's discuss bloodletting. Inflation hawks warn of the wage price spiral, when inflation rises and powerful workers bargain for higher pay, driving up expenses, prices, and wages. This is the fairy-tale narrative of the 1970s, and it's true except that OPEC's embargo drove up oil prices, which produced inflation. Oh well.
Let's be generous to seventies-haunted inflation hawks and say we're worried about a wage-price spiral. Fantastic! No. Real wages are 2.3% lower than they were in Oct 2021 after peaking in June at 4.8%.
Why did America's powerful workers take a paycut rather than demand inflation-based pay? Weak unions, globalization, economic developments.
Workers don't expect inflation to rise, so they're not requesting inflationary hikes. Inflationary expectations have remained moderate, consistent with our data interpretation.
https://www.newyorkfed.org/microeconomics/sce#/
Neither are workers. Working people see surplus savings as wealth and spend it gradually over their lives, despite rising demand. People may have saved money by staying in during the lockdown, but they don't eat out every night to make up for it. Instead, they keep those savings as precautionary balances. This is why the economy is lagging.
People don't buy non-traded goods with pandemic savings (basically, imports). Imports don't multiply like domestic purchases. If you buy a loaf of bread from the corner baker for $1 and they spend it at the tavern across the street, that dollar generates $3 in economic activity. Spending a dollar on foreign goods leaves the country and any multiplier effect happens there, not in the US.
Only marginally higher wages. The ECI is up 1.6% from 2019. Almost all gains went to the 25% lowest-paid Americans. Contrary to the inflation worry about too much savings, these workers don't make enough to save, even post-pandemic.
Recreation and transit spending are at or below pre-pandemic levels. Higher food and hotel prices (which doesn’t mean we’re buying more food than we were in 2019, just that it costs more).
What causes inflation if not greedy workers, free money, and high demand? The most expensive domestic goods produce the biggest revenues for their manufacturers. They charge you more without paying their workers or suppliers more.
The largest price-gougers are funneling their earnings to rich people who store it offshore through stock buybacks and dividends. A $1 billion stock buyback doesn't buy $1 billion in bread.
Five factors influence US inflation today:
I. Price rises for energy and food
II. shifts in consumer tastes
III. supply interruptions (mainly autos);
IV. increased rents (due to telecommuting);
V. monopoly (AKA price-gouging).
None can be remedied by raising interest rates or laying off workers.
Russia's invasion of Ukraine, omicron, and China's Zero Covid policy all disrupted the flow of food, energy, and production inputs. The price went higher because we made less.
After Russia invaded Ukraine, oil prices spiked, and sanctions made it worse. But that was February. By October, oil prices had returned to pre-pandemic, 2015 levels attributable to global economic adjustments, including a shift to renewables. Every new renewable installation reduces oil consumption and affects oil prices.
High food prices have a simple solution. The US and EU have bribed farmers not to produce for 50 years. If the war continues, this program may end, and food prices may decline.
Demand changes. We want different things than in 2019, not more. During the lockdown, people substituted goods. Half of the US toilet-paper supply in 2019 was on commercial-sized rolls. This is created from different mills and stock than our toilet paper.
Lockdown pushed toilet paper demand to residential rolls, causing shortages (the TP hoarding story was just another pandemic urban legend). Because supermarket stores don't have accounts with commercial paper distributors, ordering from languishing stores was difficult. Kleenex and paper towel substitutions caused greater shortages.
All that drove increased costs in numerous product categories, and there were more cases. These increases are transient, caused by supply chain inefficiencies that are resolving.
Demand for frontline staff saw a one-time repricing of pay, which is being recouped as we speak.
Illnesses. Brittle, hollowed-out global supply chains aggravated this. The constant pursuit of cheap labor and minimal regulation by monopolies that dominate most sectors means things are manufactured in far-flung locations. Financialization means any surplus capital assets were sold off years ago, leaving firms with little production slack. After the epidemic, several of these systems took years to restart.
Automobiles are to blame. Financialization and monopolization consolidated microchip and auto production in Taiwan and China. When the lockdowns came, these worldwide corporations cancelled their chip orders, and when they placed fresh orders, they were at the back of the line.
That drove up car prices, which is why the US has slightly higher inflation than other wealthy countries: the economy is car-centric. Automobile prices account for 9% of the CPI. France: 3.6%
Rent shocks and telecommuting. After the epidemic, many professionals moved to exurbs, small towns, and the countryside to work from home. As commercial properties were vacated, it was impractical to adapt them for residential use due to planning restrictions. Addressing these restrictions will cut rent prices more than raising inflation rates, which halts housing construction.
Statistical mirages cause some rent inflation. The CPI estimates what homeowners would pay to rent their properties. When rents rise in your neighborhood, the CPI believes you're spending more on rent even if you have a 30-year fixed-rate mortgage.
Market dominance. Almost every area of the US economy is dominated by monopolies, whose CEOs disclose on investor calls that they use inflation scares to jack up prices and make record profits.
https://pluralistic.net/2022/02/02/its-the-economy-stupid/#overinflated
Long-term profit margins are rising. Markups averaged 26% from 1960-1980. 2021: 72%. Market concentration explains 81% of markup increases (e.g. monopolization). Profit margins reach a 70-year high in 2022. These elements interact. Monopolies thin out their sectors, making them brittle and sensitive to shocks.
If we're worried about a shrinking workforce, there are more humanitarian and sensible solutions than causing a recession and mass unemployment. Instead, we may boost US production capacity by easing workers' entry into the workforce.
https://pluralistic.net/2022/06/01/factories-to-condos-pipeline/#stuff-not-money
US female workforce participation ranks towards the bottom of developed countries. Many women can't afford to work due to America's lack of daycare, low earnings, and bad working conditions in female-dominated fields. If America doesn't have enough workers, childcare subsidies and minimum wages can help.
By contrast, driving the country into recession with interest-rate hikes will reduce employment, and the last recruited (women, minorities) are the first fired and the last to be rehired. Forcing America into recession won't enhance its capacity to create what its people want; it will degrade it permanently.
Nothing the Fed does can stop price hikes from international markets, lack of supply chain investment, COVID-19 disruptions, climate change, the Ukraine war, or market power. They can worsen it. When supply problems generate inflation, raising interest rates decreases investments that can remedy shortages.
Increasing interest rates won't cut rents since landlords pass on the expenses and high rates restrict investment in new dwellings where tenants could escape the costs.
Fixing the supply fixes supply-side inflation. Increase renewables investment (as the Inflation Reduction Act does). Monopolies can be busted (as the IRA does). Reshore key goods (as the CHIPS Act does). Better pay and child care attract employees.
Windfall taxes can claw back price-gouging corporations' monopoly earnings.
https://pluralistic.net/2022/03/15/sanctions-financing/#soak-the-rich
In 2008, we ruled out fiscal solutions (bailouts for debtors) and turned to monetary policy (bank bailouts). This preserved the economy but increased inequality and eroded public trust.
Monetary policy won't help. Even monetary policy enthusiasts recognize an 18-month lag between action and result. That suggests monetary tightening is unnecessary. Like the medieval bloodletter, central bankers whose interest rate hikes don't work swiftly may do more of the same, bringing the economy to its knees.
Interest rates must rise. Zero-percent interest fueled foolish speculation and financialization. Increasing rates will stop this. Increasing interest rates will destroy the economy and dampen inflation.
Then what? All recent evidence indicate to inflation decreasing on its own, as the authors argue. Supply side difficulties are finally being overcome, evidence shows. Energy and food prices are showing considerable mean reversion, which is disinflationary.
The authors don't recommend doing nothing. Best case scenario, they argue, is that the Fed won't keep raising interest rates until morale improves.

Ari Joury, PhD
3 years ago
7 ways to turn into a major problem-solver

For some people, the glass is half empty. For others, it’s half full. And for some, the question is, How do I get this glass totally full again?
Problem-solvers are the last group. They're neutral. Pragmatists.
Problems surround them. They fix things instead of judging them. Problem-solvers improve the world wherever they go.
Some fail. Sometimes their good intentions have terrible results. Like when they try to help a grandma cross the road because she can't do it alone but discover she never wanted to.
Most programmers, software engineers, and data scientists solve problems. They use computer code to fix problems they see.
Coding is best done by understanding and solving the problem.
Despite your best intentions, building the wrong solution may have negative consequences. Helping an unwilling grandma cross the road.
How can you improve problem-solving?
1. Examine your presumptions.
Don’t think There’s a grandma, and she’s unable to cross the road. Therefore I must help her over the road. Instead think This grandma looks unable to cross the road. Let’s ask her whether she needs my help to cross it.
Maybe the grandma can’t cross the road alone, but maybe she can. You can’t tell for sure just by looking at her. It’s better to ask.
Maybe the grandma wants to cross the road. But maybe she doesn’t. It’s better to ask!
Building software is similar. Do only I find this website ugly? Who can I consult?
We all have biases, mental shortcuts, and worldviews. They simplify life.
Problem-solving requires questioning all assumptions. They might be wrong!
Think less. Ask more.
Secondly, fully comprehend the issue.
Grandma wants to cross the road? Does she want flowers from the shop across the street?
Understanding the problem advances us two steps. Instead of just watching people and their challenges, try to read their intentions.
Don't ask, How can I help grandma cross the road? Why would this grandma cross the road? What's her goal?
Understand what people want before proposing solutions.
3. Request more information. This is not a scam!
People think great problem solvers solve problems immediately. False!
Problem-solvers study problems. Understanding the problem makes solving it easy.
When you see a grandma struggling to cross the road, you want to grab her elbow and pull her over. However, a good problem solver would ask grandma what she wants. So:
Problem solver: Excuse me, ma’am? Do you wish to get over the road? Grandma: Yes indeed, young man! Thanks for asking. Problem solver: What do you want to do on the other side? Grandma: I want to buy a bouquet of flowers for my dear husband. He loves flowers! I wish the shop wasn’t across this busy road… Problem solver: Which flowers does your husband like best? Grandma: He loves red dahlia. I usually buy about 20 of them. They look so pretty in his vase at the window! Problem solver: I can get those dahlia for you quickly. Go sit on the bench over here while you’re waiting; I’ll be back in five minutes. Grandma: You would do that for me? What a generous young man you are!
A mediocre problem solver would have helped the grandma cross the road, but he might have forgotten that she needs to cross again. She must watch out for cars and protect her flowers on the way back.
A good problem solver realizes that grandma's husband wants 20 red dahlias and completes the task.
4- Rapid and intense brainstorming
Understanding a problem makes solutions easy. However, you may not have all the information needed to solve the problem.
Additionally, retrieving crucial information can be difficult.
You could start a blog. You don't know your readers' interests. You can't ask readers because you don't know who they are.
Brainstorming works here. Set a stopwatch (most smartphones have one) to ring after five minutes. In the remaining time, write down as many topics as possible.
No answer is wrong. Note everything.
Sort these topics later. Programming or data science? What might readers scroll past—are these your socks this morning?
Rank your ideas intuitively and logically. Write Medium stories using the top 35 ideas.
5 - Google it.
Doctor Google may answer this seemingly insignificant question. If you understand your problem, try googling or binging.
Someone has probably had your problem before. The problem-solver may have posted their solution online.
Use others' experiences. If you're social, ask a friend or coworker for help.
6 - Consider it later
Rest your brain.
Reread. Your brain needs rest to function.
Hustle culture encourages working 24/7. It doesn't take a neuroscientist to see that this is mental torture.
Leave an unsolvable problem. Visit friends, take a hot shower, or do whatever you enjoy outside of problem-solving.
Nap.
I get my best ideas in the morning after working on a problem. I couldn't have had these ideas last night.
Sleeping subconsciously. Leave it alone and you may be surprised by the genius it produces.
7 - Learn to live with frustration
There are problems that you’ll never solve.
Mathematicians are world-class problem-solvers. The brightest minds in history have failed to solve many mathematical problems.
A Gordian knot problem can frustrate you. You're smart!
Frustration-haters don't solve problems well. They choose simple problems to avoid frustration.
No. Great problem solvers want to solve a problem but know when to give up.
Frustration initially hurts. You adapt.
Famous last words
If you read this article, you probably solve problems. We've covered many ways to improve, so here's a summary:
Test your presumptions. Is the issue the same for everyone else when you see one? Or are your prejudices and self-judgments misguiding you?
Recognize the issue completely. On the surface, a problem may seem straightforward, but what's really going on? Try to see what the current situation might be building up to by thinking two steps ahead of the current situation.
Request more information. You are no longer a high school student. A two-sentence problem statement is not sufficient to provide a solution. Ask away if you need more details!
Think quickly and thoroughly. In a constrained amount of time, try to write down all your thoughts. All concepts are worthwhile! Later, you can order them.
Google it. There is a purpose for the internet. Use it.
Consider it later at night. A rested mind is more creative. It might seem counterintuitive to leave a problem unresolved. But while you're sleeping, your subconscious will handle the laborious tasks.
Accept annoyance as a normal part of life. Don't give up if you're feeling frustrated. It's a step in the procedure. It's also perfectly acceptable to give up on a problem because there are other, more pressing issues that need to be addressed.
You might feel stupid sometimes, but that just shows that you’re human. You care about the world and you want to make it better.
At the end of the day, that’s all there is to problem solving — making the world a little bit better.