


More on Web3 & Crypto

Alex Bentley
3 years ago
Why Bill Gates thinks Bitcoin, crypto, and NFTs are foolish
Microsoft co-founder Bill Gates assesses digital assets while the bull is caged.

Bill Gates is well-respected.
Reasonably. He co-founded and led Microsoft during its 1980s and 1990s revolution.
After leaving Microsoft, Bill Gates pursued other interests. He and his wife founded one of the world's largest philanthropic organizations, Bill & Melinda Gates Foundation. He also supports immunizations, population control, and other global health programs.
When Gates criticized Bitcoin, cryptocurrencies, and NFTs, it made news.
Bill Gates said at the 58th Munich Security Conference...
“You have an asset class that’s 100% based on some sort of greater fool theory that somebody’s going to pay more for it than I do.”
Gates means digital assets. Like many bitcoin critics, he says digital coins and tokens are speculative.
And he's not alone. Financial experts have dubbed Bitcoin and other digital assets a "bubble" for a decade.
Gates also made fun of Bored Ape Yacht Club and NFTs, saying, "Obviously pricey digital photographs of monkeys will help the world."
Why does Bill Gates dislike digital assets?
According to Gates' latest comments, Bitcoin, cryptos, and NFTs aren't good ways to hold value.
Bill Gates is a better investor than Elon Musk.
“I’m used to asset classes, like a farm where they have output, or like a company where they make products,” Gates said.
The Guardian claimed in April 2021 that Bill and Melinda Gates owned the most U.S. farms. Over 242,000 acres of farmland.
The Gates couple has enough farmland to cover Hong Kong.

Bill Gates is a classic investor. He wants companies with an excellent track record, strong fundamentals, and good management. Or tangible assets like land and property.
Gates prefers the "old economy" over the "new economy"
Gates' criticism of Bitcoin and cryptocurrency ventures isn't surprising. These digital assets lack all of Gates's investing criteria.
Volatile digital assets include Bitcoin. Their costs might change dramatically in a day. Volatility scares risk-averse investors like Gates.
Gates has a stake in the old financial system. As Microsoft's co-founder, Gates helped develop a dominant tech company.
Because of his business, he's one of the world's richest men.
Bill Gates is invested in protecting the current paradigm.
He won't invest in anything that could destroy the global economy.
When Gates criticizes Bitcoin, cryptocurrencies, and NFTs, he's suggesting they're a hoax. These soapbox speeches are one way he protects his interests.
Digital assets aren't a bad investment, though. Many think they're the future.
Changpeng Zhao and Brian Armstrong are two digital asset billionaires. Two crypto exchange CEOs. Binance/Coinbase.
Digital asset revolution won't end soon.
If you disagree with Bill Gates and plan to invest in Bitcoin, cryptocurrencies, or NFTs, do your own research and understand the risks.
But don’t take Bill Gates’ word for it.
He’s just an old rich guy with a lot of farmland.
He has a lot to lose if Bitcoin and other digital assets gain global popularity.
This post is a summary. Read the full article here.

ANDREW SINGER
3 years ago
Crypto seen as the ‘future of money’ in inflation-mired countries
Crypto as the ‘future of money' in inflation-stricken nations
Citizens of devalued currencies “need” crypto. “Nice to have” in the developed world.
According to Gemini's 2022 Global State of Crypto report, cryptocurrencies “evolved from what many considered a niche investment into an established asset class” last year.
More than half of crypto owners in Brazil (51%), Hong Kong (51%), and India (54%), according to the report, bought cryptocurrency for the first time in 2021.
The study found that inflation and currency devaluation are powerful drivers of crypto adoption, especially in emerging market (EM) countries:
“Respondents in countries that have seen a 50% or greater devaluation of their currency against the USD over the last decade were more than 5 times as likely to plan to purchase crypto in the coming year.”
Between 2011 and 2021, the real lost 218 percent of its value against the dollar, and 45 percent of Brazilians surveyed by Gemini said they planned to buy crypto in 2019.
The rand (South Africa's currency) has fallen 103 percent in value over the last decade, second only to the Brazilian real, and 32 percent of South Africans expect to own crypto in the coming year. Mexico and India, the third and fourth highest devaluation countries, followed suit.
Compared to the US dollar, Hong Kong and the UK currencies have not devalued in the last decade. Meanwhile, only 5% and 8% of those surveyed in those countries expressed interest in buying crypto.
What can be concluded? Noah Perlman, COO of Gemini, sees various crypto use cases depending on one's location.
‘Need to have' investment in countries where the local currency has devalued against the dollar, whereas in the developed world it is still seen as a ‘nice to have'.
Crypto as money substitute
As an adjunct professor at New York University School of Law, Winston Ma distinguishes between an asset used as an inflation hedge and one used as a currency replacement.
Unlike gold, he believes Bitcoin (BTC) is not a “inflation hedge”. They acted more like growth stocks in 2022. “Bitcoin correlated more closely with the S&P 500 index — and Ether with the NASDAQ — than gold,” he told Cointelegraph. But in the developing world, things are different:
“Inflation may be a primary driver of cryptocurrency adoption in emerging markets like Brazil, India, and Mexico.”
According to Justin d'Anethan, institutional sales director at the Amber Group, a Singapore-based digital asset firm, early adoption was driven by countries where currency stability and/or access to proper banking services were issues. Simply put, he said, developing countries want alternatives to easily debased fiat currencies.
“The larger flows may still come from institutions and developed countries, but the actual users may come from places like Lebanon, Turkey, Venezuela, and Indonesia.”
“Inflation is one of the factors that has and continues to drive adoption of Bitcoin and other crypto assets globally,” said Sean Stein Smith, assistant professor of economics and business at Lehman College.
But it's only one factor, and different regions have different factors, says Stein Smith. As a “instantaneously accessible, traceable, and cost-effective transaction option,” investors and entrepreneurs increasingly recognize the benefits of crypto assets. Other places promote crypto adoption due to “potential capital gains and returns”.
According to the report, “legal uncertainty around cryptocurrency,” tax questions, and a general education deficit could hinder adoption in Asia Pacific and Latin America. In Africa, 56% of respondents said more educational resources were needed to explain cryptocurrencies.
Not only inflation, but empowering our youth to live better than their parents without fear of failure or allegiance to legacy financial markets or products, said Monica Singer, ConsenSys South Africa lead. Also, “the issue of cash and remittances is huge in Africa, as is the issue of social grants.”
Money's future?
The survey found that Brazil and Indonesia had the most cryptocurrency ownership. In each country, 41% of those polled said they owned crypto. Only 20% of Americans surveyed said they owned cryptocurrency.
These markets are more likely to see cryptocurrencies as the future of money. The survey found:
“The majority of respondents in Latin America (59%) and Africa (58%) say crypto is the future of money.”
Brazil (66%), Nigeria (63%), Indonesia (61%), and South Africa (57%). Europe and Australia had the fewest believers, with Denmark at 12%, Norway at 15%, and Australia at 17%.
Will the Ukraine conflict impact adoption?
The poll was taken before the war. Will the devastating conflict slow global crypto adoption growth?
With over $100 million in crypto donations directly requested by the Ukrainian government since the war began, Stein Smith says the war has certainly brought crypto into the mainstream conversation.
“This real-world demonstration of decentralized money's power could spur wider adoption, policy debate, and increased use of crypto as a medium of exchange.”
But the war may not affect all developing nations. “The Ukraine war has no impact on African demand for crypto,” Others loom larger. “Yes, inflation, but also a lack of trust in government in many African countries, and a young demographic very familiar with mobile phones and the internet.”
A major success story like Mpesa in Kenya has influenced the continent and may help accelerate crypto adoption. Creating a plan when everyone you trust fails you is directly related to the African spirit, she said.
On the other hand, Ma views the Ukraine conflict as a sort of crisis check for cryptocurrencies. For those in emerging markets, the Ukraine-Russia war has served as a “stress test” for the cryptocurrency payment rail, he told Cointelegraph.
“These emerging markets may see the greatest future gains in crypto adoption.”
Inflation and currency devaluation are persistent global concerns. In such places, Bitcoin and other cryptocurrencies are now seen as the “future of money.” Not in the developed world, but that could change with better regulation and education. Inflation and its impact on cash holdings are waking up even Western nations.
Read original post here.

Marco Manoppo
3 years ago
Failures of DCG and Genesis
Don't sleep with your own sister.

70% of lottery winners go broke within five years. You've heard the last one. People who got rich quickly without setbacks and hard work often lose it all. My father said, "Easy money is easily lost," and a wealthy friend who owns a family office said, "The first generation makes it, the second generation spends it, and the third generation blows it."
This is evident. Corrupt politicians in developing countries live lavishly, buying their third wives' fifth Hermès bag and celebrating New Year's at The Brando Resort. A successful businessperson from humble beginnings is more conservative with money. More so if they're atom-based, not bit-based. They value money.
Crypto can "feel" easy. I have nothing against capital market investing. The global financial system is shady, but that's another topic. The problem started when those who took advantage of easy money started affecting other businesses. VCs did minimal due diligence on FTX because they needed deal flow and returns for their LPs. Lenders did minimum diligence and underwrote ludicrous loans to 3AC because they needed revenue.
Alameda (hence FTX) and 3AC made "easy money" Genesis and DCG aren't. Their businesses are more conventional, but they underestimated how "easy money" can hurt them.
Genesis has been the victim of easy money hubris and insolvency, losing $1 billion+ to 3AC and $200M to FTX. We discuss the implications for the broader crypto market.
Here are the quick takeaways:
Genesis is one of the largest and most notable crypto lenders and prime brokerage firms.
DCG and Genesis have done related party transactions, which can be done right but is a bad practice.
Genesis owes DCG $1.5 billion+.
If DCG unwinds Grayscale's GBTC, $9-10 billion in BTC will hit the market.
DCG will survive Genesis.
What happened?
Let's recap the FTX shenanigan from two weeks ago. Shenanigans! Delphi's tweet sums up the craziness. Genesis has $175M in FTX.
Cred's timeline: I hate bad crisis management. Yes, admitting their balance sheet hole right away might've sparked more panic, and there's no easy way to convey your trouble, but no one ever learns.
By November 23, rumors circulated online that the problem could affect Genesis' parent company, DCG. To address this, Barry Silbert, Founder, and CEO of DCG released a statement to shareholders.
A few things are confirmed thanks to this statement.
DCG owes $1.5 billion+ to Genesis.
$500M is due in 6 months, and the rest is due in 2032 (yes, that’s not a typo).
Unless Barry raises new cash, his last-ditch efforts to repay the money will likely push the crypto market lower.
Half a year of GBTC fees is approximately $100M.
They can pay $500M with GBTC.
With profits, sell another port.
Genesis has hired a restructuring adviser, indicating it is in trouble.
Rehypothecation
Every crypto problem in the past year seems to be rehypothecation between related parties, excessive leverage, hubris, and the removal of the money printer. The Bankless guys provided a chart showing 2021 crypto yield.

In June 2022, @DataFinnovation published a great investigation about 3AC and DCG. Here's a summary.
3AC borrowed BTC from Genesis and pledged it to create Grayscale's GBTC shares.
3AC uses GBTC to borrow more money from Genesis.
This lets 3AC leverage their capital.
3AC's strategy made sense because GBTC had a premium, creating "free money."
GBTC's discount and LUNA's implosion caused problems.
3AC lost its loan money in LUNA.
Margin called on 3ACs' GBTC collateral.
DCG bought GBTC to avoid a systemic collapse and a larger discount.
Genesis lost too much money because 3AC can't pay back its loan. DCG "saved" Genesis, but the FTX collapse hurt Genesis further, forcing DCG and Genesis to seek external funding.
bruh…
Learning Experience
Co-borrowing. Unnecessary rehypothecation. Extra space. Governance disaster. Greed, hubris. Crypto has repeatedly shown it can recreate traditional financial system disasters quickly. Working in crypto is one of the best ways to learn crazy financial tricks people will do for a quick buck much faster than if you dabble in traditional finance.
Moving Forward
I think the crypto industry needs to consider its future. This is especially true for professionals. I'm not trying to scare you. In 2018 and 2020, I had doubts. No doubts now. Detailing the crypto industry's potential outcomes helped me gain certainty and confidence in its future. This includes VCs' benefits and talking points during the bull market, as well as what would happen if government regulations became hostile, etc. Even if that happens, I'm certain. This is permanent. I may write a post about that soon.
Sincerely,
M.
You might also like

Hasan AboulHasan
3 years ago
High attachment products can help you earn money automatically.

Affiliate marketing is a popular online moneymaker. You promote others' products and get commissions. Affiliate marketing requires constant product promotion.
Affiliate marketing can be profitable even without much promotion. Yes, this is Autopilot Money.
How to Pick an Affiliate Program to Generate Income Autonomously
Autopilot moneymaking requires a recurring affiliate marketing program.
Finding the best product and testing it takes a lot of time and effort.
Here are three ways to choose the best service or product to promote:
Find a good attachment-rate product or service.
When choosing a product, ask if you can easily switch to another service. Attachment rate is how much people like a product.
Higher attachment rates mean better Autopilot products.
Consider promoting GetResponse. It's a 33% recurring commission email marketing tool. This means you get 33% of the customer's plan as long as he pays.
GetResponse has a high attachment rate because it's hard to leave and start over with another tool.
2. Pick a good or service with a lot of affiliate assets.
Check if a program has affiliate assets or creatives before joining.
Images and banners to promote the product in your business.
They save time; I look for promotional creatives. Creatives or affiliate assets are website banners or images. This reduces design time.
3. Select a service or item that consumers already adore.
New products are hard to sell. Choosing a trusted company's popular product or service is helpful.
As a beginner, let people buy a product they already love.
Online entrepreneurs and digital marketers love Systeme.io. It offers tools for creating pages, email marketing, funnels, and more. This product guarantees a high ROI.
Make the product known!
Affiliate marketers struggle to get traffic. Using affiliate marketing to make money is easier than you think if you have a solid marketing strategy.
Your plan should include:
1- Publish affiliate-related blog posts and SEO-optimize them
2- Sending new visitors product-related emails
3- Create a product resource page.
4-Review products
5-Make YouTube videos with links in the description.
6- Answering FAQs about your products and services on your blog and Quora.
7- Create an eCourse on how to use this product.
8- Adding Affiliate Banners to Your Website.
With these tips, you can promote your products and make money on autopilot.

Shalitha Suranga
3 years ago
The Top 5 Mathematical Concepts Every Programmer Needs to Know
Using math to write efficient code in any language

Programmers design, build, test, and maintain software. Employ cases and personal preferences determine the programming languages we use throughout development. Mobile app developers use JavaScript or Dart. Some programmers design performance-first software in C/C++.
A generic source code includes language-specific grammar, pre-implemented function calls, mathematical operators, and control statements. Some mathematical principles assist us enhance our programming and problem-solving skills.
We all use basic mathematical concepts like formulas and relational operators (aka comparison operators) in programming in our daily lives. Beyond these mathematical syntaxes, we'll see discrete math topics. This narrative explains key math topics programmers must know. Master these ideas to produce clean and efficient software code.
Expressions in mathematics and built-in mathematical functions
A source code can only contain a mathematical algorithm or prebuilt API functions. We develop source code between these two ends. If you create code to fetch JSON data from a RESTful service, you'll invoke an HTTP client and won't conduct any math. If you write a function to compute the circle's area, you conduct the math there.
When your source code gets more mathematical, you'll need to use mathematical functions. Every programming language has a math module and syntactical operators. Good programmers always consider code readability, so we should learn to write readable mathematical expressions.
Linux utilizes clear math expressions.
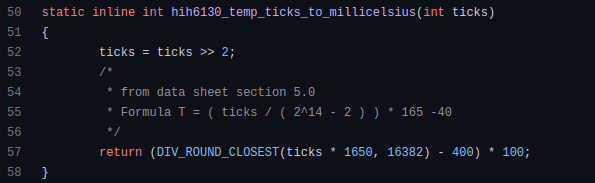
Inbuilt max and min functions can minimize verbose if statements.
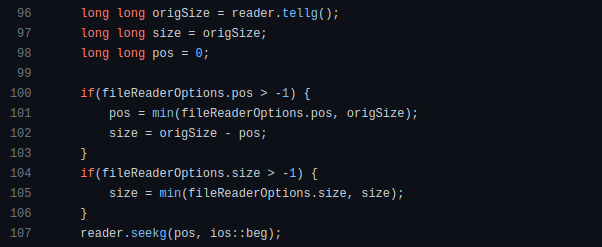
How can we compute the number of pages needed to display known data? In such instances, the ceil function is often utilized.
import math as m
results = 102
items_per_page = 10
pages = m.ceil(results / items_per_page)
print(pages)Learn to write clear, concise math expressions.
Combinatorics in Algorithm Design
Combinatorics theory counts, selects, and arranges numbers or objects. First, consider these programming-related questions. Four-digit PIN security? what options exist? What if the PIN has a prefix? How to locate all decimal number pairs?
Combinatorics questions. Software engineering jobs often require counting items. Combinatorics counts elements without counting them one by one or through other verbose approaches, therefore it enables us to offer minimum and efficient solutions to real-world situations. Combinatorics helps us make reliable decision tests without missing edge cases. Write a program to see if three inputs form a triangle. This is a question I commonly ask in software engineering interviews.
Graph theory is a subfield of combinatorics. Graph theory is used in computerized road maps and social media apps.
Logarithms and Geometry Understanding
Geometry studies shapes, angles, and sizes. Cartesian geometry involves representing geometric objects in multidimensional planes. Geometry is useful for programming. Cartesian geometry is useful for vector graphics, game development, and low-level computer graphics. We can simply work with 2D and 3D arrays as plane axes.
GetWindowRect is a Windows GUI SDK geometric object.
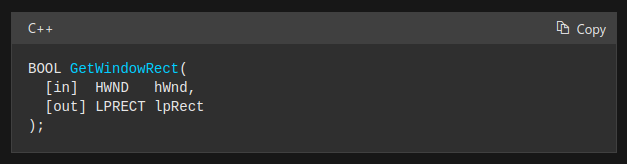
High-level GUI SDKs and libraries use geometric notions like coordinates, dimensions, and forms, therefore knowing geometry speeds up work with computer graphics APIs.
How does exponentiation's inverse function work? Logarithm is exponentiation's inverse function. Logarithm helps programmers find efficient algorithms and solve calculations. Writing efficient code involves finding algorithms with logarithmic temporal complexity. Programmers prefer binary search (O(log n)) over linear search (O(n)). Git source specifies O(log n):
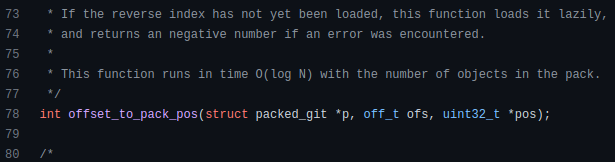
Logarithms aid with programming math. Metas Watchman uses a logarithmic utility function to find the next power of two.
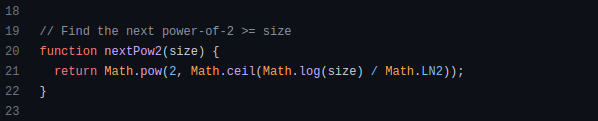
Employing Mathematical Data Structures
Programmers must know data structures to develop clean, efficient code. Stack, queue, and hashmap are computer science basics. Sets and graphs are discrete arithmetic data structures. Most computer languages include a set structure to hold distinct data entries. In most computer languages, graphs can be represented using neighboring lists or objects.
Using sets as deduped lists is powerful because set implementations allow iterators. Instead of a list (or array), store WebSocket connections in a set.
Most interviewers ask graph theory questions, yet current software engineers don't practice algorithms. Graph theory challenges become obligatory in IT firm interviews.
Recognizing Applications of Recursion
A function in programming isolates input(s) and output(s) (s). Programming functions may have originated from mathematical function theories. Programming and math functions are different but similar. Both function types accept input and return value.
Recursion involves calling the same function inside another function. In its implementation, you'll call the Fibonacci sequence. Recursion solves divide-and-conquer software engineering difficulties and avoids code repetition. I recently built the following recursive Dart code to render a Flutter multi-depth expanding list UI:
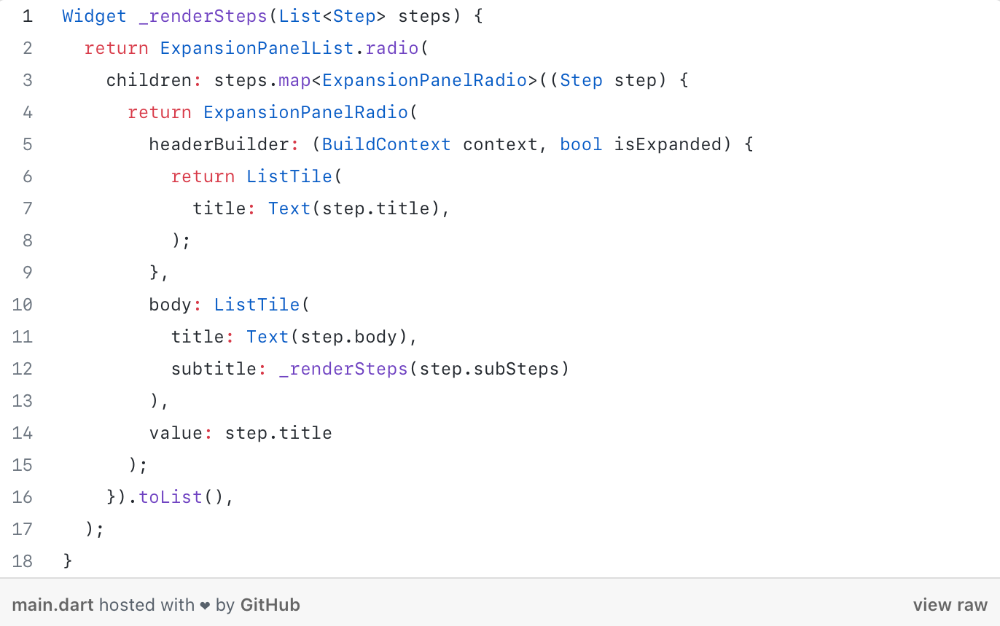
Recursion is not the natural linear way to solve problems, hence thinking recursively is difficult. Everything becomes clear when a mathematical function definition includes a base case and recursive call.
Conclusion
Every codebase uses arithmetic operators, relational operators, and expressions. To build mathematical expressions, we typically employ log, ceil, floor, min, max, etc. Combinatorics, geometry, data structures, and recursion help implement algorithms. Unless you operate in a pure mathematical domain, you may not use calculus, limits, and other complex math in daily programming (i.e., a game engine). These principles are fundamental for daily programming activities.
Master the above math fundamentals to build clean, efficient code.

Cody Collins
3 years ago
The direction of the economy is as follows.
What quarterly bank earnings reveal

Big banks know the economy best. Unless we’re talking about a housing crisis in 2007…
Banks are crucial to the U.S. economy. The Fed, communities, and investments exchange money.
An economy depends on money flow. Banks' views on the economy can affect their decision-making.
Most large banks released quarterly earnings and forward guidance last week. Others were pessimistic about the future.
What Makes Banks Confident
Bank of America's profit decreased 30% year-over-year, but they're optimistic about the economy. Comparatively, they're bullish.
Who banks serve affects what they see. Bank of America supports customers.
They think consumers' future is bright. They believe this for many reasons.
The average customer has decent credit, unless the system is flawed. Bank of America's new credit card and mortgage borrowers averaged 771. New-car loan and home equity borrower averages were 791 and 797.
2008's housing crisis affected people with scores below 620.
Bank of America and the economy benefit from a robust consumer. Major problems can be avoided if individuals maintain spending.
Reasons Other Banks Are Less Confident
Spending requires income. Many companies, mostly in the computer industry, have announced they will slow or freeze hiring. Layoffs are frequently an indication of poor times ahead.
BOA is positive, but investment banks are bearish.
Jamie Dimon, CEO of JPMorgan, outlined various difficulties our economy could confront.
But geopolitical tension, high inflation, waning consumer confidence, the uncertainty about how high rates have to go and the never-before-seen quantitative tightening and their effects on global liquidity, combined with the war in Ukraine and its harmful effect on global energy and food prices are very likely to have negative consequences on the global economy sometime down the road.
That's more headwinds than tailwinds.
JPMorgan, which helps with mergers and IPOs, is less enthusiastic due to these concerns. Incoming headwinds signal drying liquidity, they say. Less business will be done.
Final Reflections
I don't think we're done. Yes, stocks are up 10% from a month ago. It's a long way from old highs.
I don't think the stock market is a strong economic indicator.
Many executives foresee a 2023 recession. According to the traditional definition, we may be in a recession when Q2 GDP statistics are released next week.
Regardless of criteria, I predict the economy will have a terrible year.
Weekly layoffs are announced. Inflation persists. Will prices return to 2020 levels if inflation cools? Perhaps. Still expensive energy. Ukraine's war has global repercussions.
I predict BOA's next quarter earnings won't be as bullish about the consumer's strength.