




More on Personal Growth

Sad NoCoiner
3 years ago
Two Key Money Principles You Should Understand But Were Never Taught

Prudence is advised. Be debt-free. Be frugal. Spend less.
This advice sounds nice, but it rarely works.
Most people never learn these two money rules. Both approaches will impact how you see personal finance.
It may safeguard you from inflation or the inability to preserve money.
Let’s dive in.
#1: Making long-term debt your ally
High-interest debt hurts consumers. Many credit cards carry 25% yearly interest (or more), so always pay on time. Otherwise, you’re losing money.
Some low-interest debt is good. Especially when buying an appreciating asset with borrowed money.
Inflation helps you.
If you borrow $800,000 at 3% interest and invest it at 7%, you'll make $32,000 (4%).
As money loses value, fixed payments get cheaper. Your assets' value and cash flow rise.
The never-in-debt crowd doesn't know this. They lose money paying off mortgages and low-interest loans early when they could have bought assets instead.
#2: How To Buy Or Build Assets To Make Inflation Irrelevant
Dozens of studies demonstrate actual wage growth is static; $2.50 in 1964 was equivalent to $22.65 now.
These reports never give solutions unless they're selling gold.
But there is one.
Assets beat inflation.
$100 invested into the S&P 500 would have an inflation-adjusted return of 17,739.30%.
Likewise, you can build assets from nothing. Doing is easy and quick. The returns can boost your income by 10% or more.
The people who obsess over inflation inadvertently make the problem worse for themselves. They wait for The Big Crash to buy assets. Or they moan about debt clocks and spending bills instead of seeking a solution.
Conclusion
Being ultra-prudent is like playing golf with a putter to avoid hitting the ball into the water. Sure, you might not slice a drive into the pond. But, you aren’t going to play well either. Or have very much fun.
Money has rules.
Avoiding debt or investment risks will limit your rewards. Long-term, being too cautious hurts your finances.
Disclaimer: This article is for entertainment purposes only. It is not financial advice, always do your own research.

Merve Yılmaz
3 years ago
Dopamine detox
This post is for you if you can't read or study for 5 minutes.

If you clicked this post, you may be experiencing problems focusing on tasks. A few minutes of reading may tire you. Easily distracted? Using social media and video games for hours without being sidetracked may impair your dopamine system.
When we achieve a goal, the brain secretes dopamine. It might be as simple as drinking water or as crucial as college admission. Situations vary. Various events require different amounts.
Dopamine is released when we start learning but declines over time. Social media algorithms provide new material continually, making us happy. Social media use slows down the system. We can't continue without an award. We return to social media and dopamine rewards.
Mice were given a button that released dopamine into their brains to study the hormone. The mice lost their hunger, thirst, and libido and kept pressing the button. Think this is like someone who spends all day gaming or on Instagram?
When we cause our brain to release so much dopamine, the brain tries to balance it in 2 ways:
1- Decreases dopamine production
2- Dopamine cannot reach its target.
Too many quick joys aren't enough. We'll want more joys. Drugs and alcohol are similar. Initially, a beer will get you drunk. After a while, 3-4 beers will get you drunk.
Social media is continually changing. Updates to these platforms keep us interested. When social media conditions us, we can't read a book.
Same here. I used to complete a book in a day and work longer without distraction. Now I'm addicted to Instagram. Daily, I spend 2 hours on social media. This must change. My life needs improvement. So I started the 50-day challenge.
I've compiled three dopamine-related methods.
Recommendations:
Day-long dopamine detox
First, take a day off from all your favorite things. Social media, gaming, music, junk food, fast food, smoking, alcohol, friends. Take a break.
Hanging out with friends or listening to music may seem pointless. Our minds are polluted. One day away from our pleasures can refresh us.
2. One-week dopamine detox by selecting
Choose one or more things to avoid. Social media, gaming, music, junk food, fast food, smoking, alcohol, friends. Try a week without Instagram or Twitter. I use this occasionally.
One week all together
One solid detox week. It's the hardest program. First or second options are best for dopamine detox. Time will help you.
You can walk, read, or pray during a dopamine detox. Many options exist. If you want to succeed, you must avoid instant gratification. Success after hard work is priceless.

Leah
3 years ago
The Burnout Recovery Secrets Nobody Is Talking About

What works and what’s just more toxic positivity
Just keep at it; you’ll get it.
I closed the Zoom call and immediately dropped my head. Open tabs included material on inspiration, burnout, and recovery.
I searched everywhere for ways to avoid burnout.
It wasn't that I needed to keep going, change my routine, employ 8D audio playlists, or come up with fresh ideas. I had several ideas and a schedule. I knew what to do.
I wasn't interested. I kept reading, changing my self-care and mental health routines, and writing even though it was tiring.
Since burnout became a psychiatric illness in 2019, thousands have shared their experiences. It's spreading rapidly among writers.
What is the actual key to recovering from burnout?
Every A-list burnout story emphasizes prevention. Other lists provide repackaged self-care tips. More discuss mental health.
It's like the mid-2000s, when pink quotes about bubble baths saturated social media.
The self-care mania cost us all. Self-care is crucial, but utilizing it to address everything didn't work then or now.
How can you recover from burnout?
Time
Are extended breaks actually good for you? Most people need a break every 62 days or so to avoid burnout.
Real-life burnout victims all took breaks. Perhaps not a long hiatus, but breaks nonetheless.
Burnout is slow and gradual. It takes little bits of your motivation and passion at a time. Sometimes it’s so slow that you barely notice or blame it on other things like stress and poor sleep.
Burnout doesn't come overnight; neither will recovery.
I don’t care what anyone else says the cure for burnout is. It has to be time because time is what gave us all burnout in the first place.
You might also like

Elnaz Sarraf
3 years ago
Why Bitcoin's Crash Could Be Good for Investors

The crypto market crashed in June 2022. Bitcoin and other cryptocurrencies hit their lowest prices in over a year, causing market panic. Some believe this crash will benefit future investors.
Before I discuss how this crash might help investors, let's examine why it happened. Inflation in the U.S. reached a 30-year high in 2022 after Russia invaded Ukraine. In response, the U.S. Federal Reserve raised interest rates by 0.5%, the most in almost 20 years. This hurts cryptocurrencies like Bitcoin. Higher interest rates make people less likely to invest in volatile assets like crypto, so many investors sold quickly.
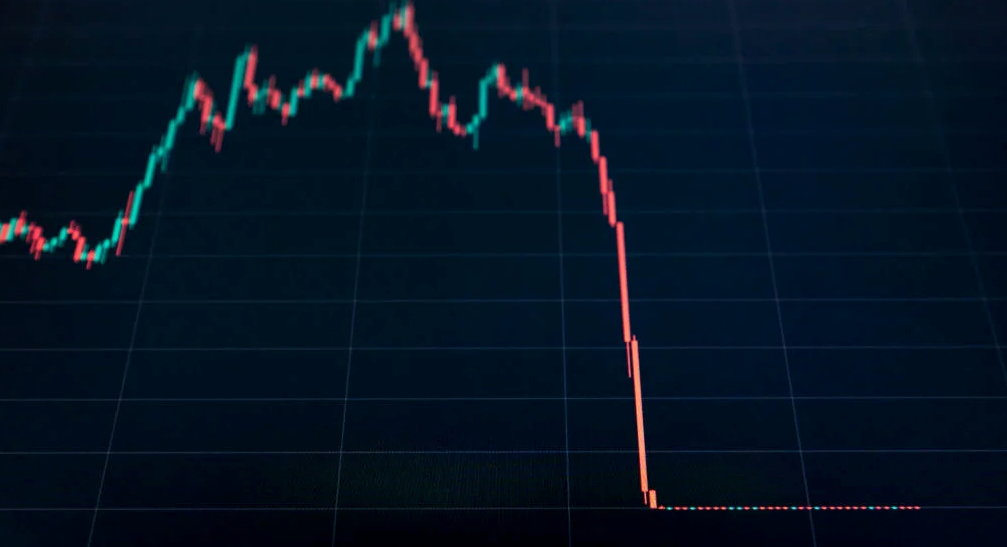
The crypto market collapsed. Bitcoin, Ethereum, and Binance dropped 40%. Other cryptos crashed so hard they were delisted from almost every exchange. Bitcoin peaked in April 2022 at $41,000, but after the May interest rate hike, it crashed to $28,000. Bitcoin investors were worried. Even in bad times, this crash is unprecedented.
Bitcoin wasn't "doomed." Before the crash, LUNA was one of the top 5 cryptos by market cap. LUNA was trading around $80 at the start of May 2022, but after the rate hike?
Less than 1 cent. LUNA lost 99.99% of its value in days and was removed from every crypto exchange. Bitcoin's "crash" isn't as devastating when compared to LUNA.
Many people said Bitcoin is "due" for a LUNA-like crash and that the only reason it hasn't crashed is because it's bigger. Still false. If so, Bitcoin should be worth zero by now. We didn't. Instead, Bitcoin reached 28,000, then 29k, 30k, and 31k before falling to 18k. That's not the world's greatest recovery, but it shows Bitcoin's safety.
Bitcoin isn't falling constantly. It fell because of the initial shock of interest rates, but not further. Now, Bitcoin's value is more likely to rise than fall. Bitcoin's low price also attracts investors. They know what prices Bitcoin can reach with enough hype, and they want to capitalize on low prices before it's too late.

Bitcoin's crash was bad, but in a way it wasn't. To understand, consider 2021. In March 2021, Bitcoin surpassed $60k for the first time. Elon Musk's announcement in May that he would no longer support Bitcoin caused a massive crash in the crypto market. In May 2017, Bitcoin's price hit $29,000. Elon Musk's statement isn't worth more than the Fed raising rates. Many expected this big announcement to kill Bitcoin.

Not so. Bitcoin crashed from $58k to $31k in 2021. Bitcoin fell from $41k to $28k in 2022. This crash is smaller. Bitcoin's price held up despite tensions and stress, proving investors still believe in it. What happened after the initial crash in the past?
Bitcoin fell until mid-July. This is also something we’re not seeing today. After a week, Bitcoin began to improve daily. Bitcoin's price rose after mid-July. Bitcoin's price fluctuated throughout the rest of 2021, but it topped $67k in November. Despite no major changes, the peak occurred after the crash. Elon Musk seemed uninterested in crypto and wasn't likely to change his mind soon. What triggered this peak? Nothing, really. What really happened is that people got over the initial statement. They forgot.
Internet users have goldfish-like attention spans. People quickly forgot the crash's cause and were back investing in crypto months later. Despite the market's setbacks, more crypto investors emerged by the end of 2017. Who gained from these peaks? Bitcoin investors who bought low. Bitcoin not only recovered but also doubled its ROI. It was like a movie, and it shows us what to expect from Bitcoin in the coming months.
The current Bitcoin crash isn't as bad as the last one. LUNA is causing market panic. LUNA and Bitcoin are different cryptocurrencies. LUNA crashed because Terra wasn’t able to keep its peg with the USD. Bitcoin is unanchored. It's one of the most decentralized investments available. LUNA's distrust affected crypto prices, including Bitcoin, but it won't last forever.
This is why Bitcoin will likely rebound in the coming months. In 2022, people will get over the rise in interest rates and the crash of LUNA, just as they did with Elon Musk's crypto stance in 2021. When the world moves on to the next big controversy, Bitcoin's price will soar.
Bitcoin may recover for another reason. Like controversy, interest rates fluctuate. The Russian invasion caused this inflation. World markets will stabilize, prices will fall, and interest rates will drop.
Next, lower interest rates could boost Bitcoin's price. Eventually, it will happen. The U.S. economy can't sustain such high interest rates. Investors will put every last dollar into Bitcoin if interest rates fall again.
Bitcoin has proven to be a stable investment. This boosts its investment reputation. Even if Ethereum dethrones Bitcoin as crypto king one day (or any other crypto, for that matter). Bitcoin may stay on top of the crypto ladder for a while. We'll have to wait a few months to see if any of this is true.
This post is a summary. Read the full article here.

Jenn Leach
3 years ago
How Much I Got Paid by YouTube for a 68 Million Views Video
My nameless, faceless channel case study

The Numbers
I anonymize this YouTube channel.
It's in a trendy, crowded niche. Sharing it publicly will likely enhance competition.
I'll still share my dashboard numbers:

A year ago, the video was released.

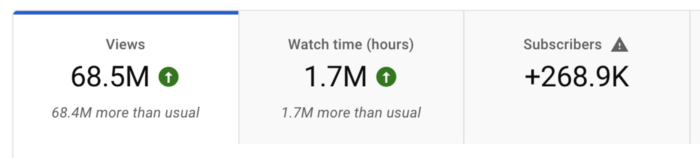
What I earned
I'll stop stalling. Here's a screenshot of my YouTube statistics page displaying Adsense profits.
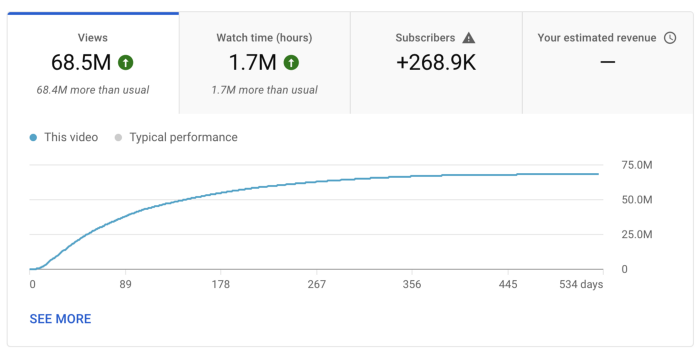
YouTube Adsense made me ZERO dollars.
OMG!
How is this possible?
YouTube Adsense can't monetize my niche. This is typical in faceless niches like TikTok's rain videos. If they were started a while ago, I'm sure certain rain accounts are monetized, but not today.
I actually started a soothing sounds faceless YouTube channel. This was another account of mine.
I looped Pexels films for hours. No background music, just wind, rain, etc.
People could watch these videos to relax or get ready for bed. They're ideal for background noise and relaxation.
They're long-lasting, too. It's easy to make a lot from YouTube Adsense if you insert ads.
Anyway, I tried to monetize it and couldn’t. This was about a year ago. That’s why I doubt new accounts in this genre would be able to get approved for ads.
Back to my faceless channel with 68 million views.
I received nothing from YouTube Adsense, but I made money elsewhere.
Getting paid by the gods of affiliate marketing
Place links in the video and other videos on the channel to get money. Visitors that buy through your affiliate link earn you a commission.
This video earned many clicks on my affiliate links.
I linked to a couple of Amazon products, a YouTube creator tool, my kofi link, and my subscribe link.
Sponsorships
Brands pay you to include ads in your videos.
This video led to many sponsorships.
I've done dozens of sponsorship campaigns that paid $40 to $50 for an end screen to $450 for a preroll ad.
Last word
Overall, I made less than $3,000.
If I had time, I'd be more proactive with sponsorships. You can pitch brand sponsorships. This actually works.
I'd do that if I could rewind time.
I still can, but I think the reaction rate would be higher closer to the viral video's premiere date.

Stephen Moore
3 years ago
Web 2 + Web 3 = Web 5.
Monkey jpegs and shitcoins have tarnished Web3's reputation. Let’s move on.

Web3 was called "the internet's future."
Well, 'crypto bros' shouted about it loudly.
As quickly as it arrived to be the next internet, it appears to be dead. It's had scandals, turbulence, and crashes galore:
Web 3.0's cryptocurrencies have crashed. Bitcoin's all-time high was $66,935. This month, Ethereum fell from $2130 to $1117. Six months ago, the cryptocurrency market peaked at $3 trillion. Worst is likely ahead.
Gas fees make even the simplest Web3 blockchain transactions unsustainable.
Terra, Luna, and other dollar pegs collapsed, hurting crypto markets. Celsius, a crypto lender backed by VCs and Canada's second-largest pension fund, and Binance, a crypto marketplace, have withheld money and coins. They're near collapse.
NFT sales are falling rapidly and losing public interest.
Web3 has few real-world uses, like most crypto/blockchain technologies. Web3's image has been tarnished by monkey profile pictures and shitcoins while failing to become decentralized (the whole concept is controlled by VCs).
The damage seems irreparable, leaving Web3 in the gutter.
Step forward our new saviour — Web5
Fear not though, as hero awaits to drag us out of the Web3 hellscape. Jack Dorsey revealed his plan to save the internet quickly.
Dorsey has long criticized Web3, believing that VC capital and silicon valley insiders have created a centralized platform. In a tweet that upset believers and VCs (he was promptly blocked by Marc Andreessen), Dorsey argued, "You don't own "Web3." VCs and LPs do. Their incentives prevent it. It's a centralized organization with a new name.
Dorsey announced Web5 on June 10 in a very Elon-like manner. Block's TBD unit will work on the project (formerly Square).
Web5's pitch is that users will control their own data and identity. Bitcoin-based. Sound familiar? The presentation pack's official definition emphasizes decentralization. Web5 is a decentralized web platform that enables developers to write decentralized web apps using decentralized identifiers, verifiable credentials, and decentralized web nodes, returning ownership and control over identity and data to individuals.
Web5 would be permission-less, open, and token-less. What that means for Earth is anyone's guess. Identity. Ownership. Blockchains. Bitcoin. Different.
Web4 appears to have been skipped, forever destined to wish it could have shown the world what it could have been. (It was probably crap.) As this iteration combines Web2 and Web3, simple math and common sense add up to 5. Or something.
Dorsey and his team have had this idea simmering for a while. Daniel Buchner, a member of Block's Decentralized Identity team, said, "We're finishing up Web5's technical components."
Web5 could be the project that decentralizes the internet. It must be useful to users and convince everyone to drop the countless Web3 projects, products, services, coins, blockchains, and websites being developed as I write this.
Web5 may be too late for Dorsey and the incoming flood of creators.
Web6 is planned!
The next months and years will be hectic and less stable than the transition from Web 1.0 to Web 2.0.
Web1 was around 1991-2004.
Web2 ran from 2004 to 2021. (though the Web3 term was first used in 2014, it only really gained traction years later.)
Web3 lasted a year.
Web4 is dead.
Silicon Valley billionaires are turning it into a startup-style race, each disrupting the next iteration until they crack it. Or destroy it completely.
Web5 won't last either.