




More on Entrepreneurship/Creators

Caleb Naysmith
3 years ago
Ads Coming to Medium?
Could this happen?
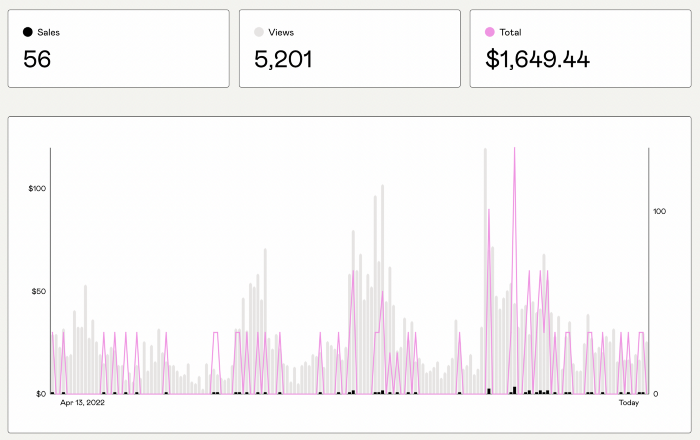
Medium isn't like other social media giants. It wasn't a dot-com startup that became a multi-trillion-dollar social media firm. It launched in 2012 but didn't gain popularity until later. Now, it's one of the largest sites by web traffic, but it's still little compared to most. Most of Medium's traffic is external, but they don't run advertisements, so it's all about memberships.
Medium isn't profitable, but they don't disclose how terrible the problem is. Most of the $163 million they raised has been spent or used for acquisitions. If the money turns off, Medium can't stop paying its writers since the site dies. Writers must be paid, but they can't substantially slash payment without hurting the platform. The existing model needs scale to be viable and has a low ceiling. Facebook and other free social media platforms are struggling to retain users. Here, you must pay to appreciate it, and it's bad for writers AND readers. If I had the same Medium stats on YouTube, I'd make thousands of dollars a month.
Then what? Medium has tried to monetize by offering writers a cut of new members, but that's unsustainable. People-based growth is limited. Imagine recruiting non-Facebook users and getting them to pay to join. Some may, but I'd rather write.
Alternatives:
Donation buttons
Tiered subscriptions ($5, $10, $25, etc.)
Expanding content
and these may be short-term fixes, but they're not as profitable as allowing ads. Advertisements can pay several dollars per click and cents every view. If you get 40,000 views a month like me, that's several thousand instead of a few hundred. Also, Medium would have enough money to split ad revenue with writers, who would make more. I'm among the top 6% of Medium writers. Only 6% of Medium writers make more than $100, and I made $500 with 35,000 views last month. Compared to YouTube, the top 1% of Medium authors make a lot. Mr. Beast and PewDiePie make MILLIONS a month, yet top Medium writers make tens of thousands. Sure, paying 3 or 4 people a few grand, or perhaps tens of thousands, will keep them around. What if great authors leveraged their following to go huge on YouTube and abandoned Medium? If people use Medium to get successful on other platforms, Medium will be continuously cycling through authors and paying them to stay.
Ads might make writing on Medium more profitable than making videos on YouTube because they could preserve the present freemium model and pay users based on internal views. The $5 might be ad-free.
Consider: Would you accept Medium ads? A $5 ad-free version + pay-as-you-go, etc. What are your thoughts on this?
Original post available here

Scrum Ventures
3 years ago
Trends from the Winter 2022 Demo Day at Y Combinators

Y Combinators Winter 2022 Demo Day continues the trend of more startups engaging in accelerator Demo Days. Our team evaluated almost 400 projects in Y Combinator's ninth year.
After Winter 2021 Demo Day, we noticed a hurry pushing shorter rounds, inflated valuations, and larger batches.
Despite the batch size, this event's behavior showed a return to normalcy. Our observations show that investors evaluate and fund businesses more carefully. Unlike previous years, more YC businesses gave investors with data rooms and thorough pitch decks in addition to valuation data before Demo Day.
Demo Day pitches were virtual and fast-paced, limiting unplanned meetings. Investors had more time and information to do their due research before meeting founders. Our staff has more time to study diverse areas and engage with interesting entrepreneurs and founders.
This was one of the most regionally diversified YC cohorts to date. This year's Winter Demo Day startups showed some interesting tendencies.
Trends and Industries to Watch Before Demo Day
Demo day events at any accelerator show how investment competition is influencing startups. As startups swiftly become scale-ups and big success stories in fintech, e-commerce, healthcare, and other competitive industries, entrepreneurs and early-stage investors feel pressure to scale quickly and turn a notion into actual innovation.
Too much eagerness can lead founders to focus on market growth and team experience instead of solid concepts, technical expertise, and market validation. Last year, YC Winter Demo Day funding cycles ended too quickly and valuations were unrealistically high.
Scrum Ventures observed a longer funding cycle this year compared to last year's Demo Day. While that seems promising, many factors could be contributing to change, including:
Market patterns are changing and the economy is becoming worse.
the industries that investors are thinking about.
Individual differences between each event batch and the particular businesses and entrepreneurs taking part
The Winter 2022 Batch's Trends
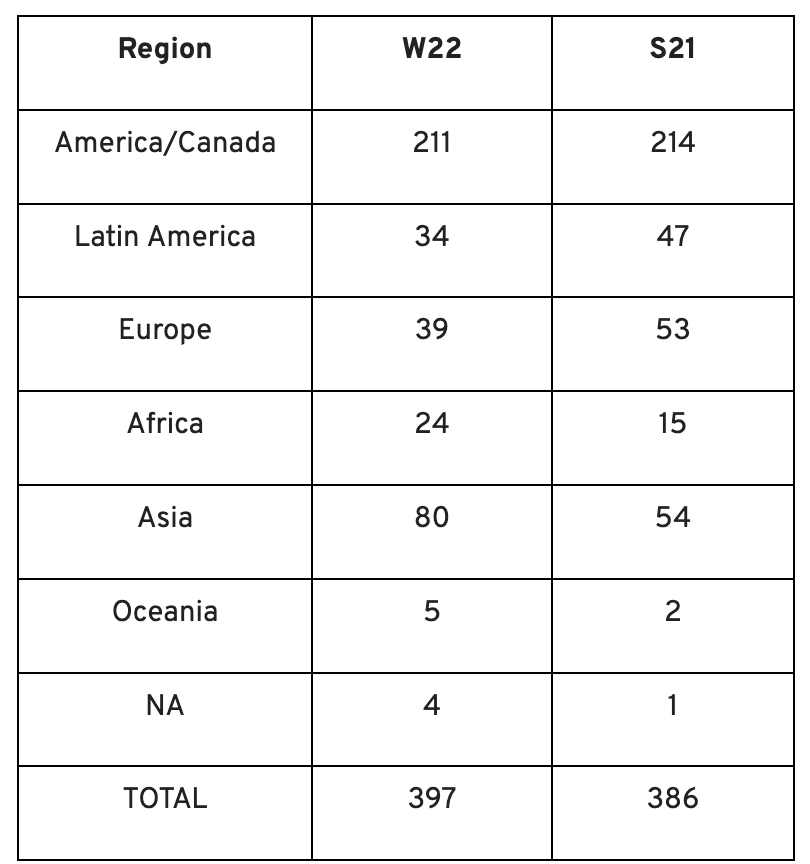
Each year, we also wish to examine trends among early-stage firms and YC event participants. More international startups than ever were anticipated to present at Demo Day.
Less than 50% of demo day startups were from the U.S. For the S21 batch, firms from outside the US were most likely in Latin America or Europe, however this year's batch saw a large surge in startups situated in Asia and Africa.
YC Startup Directory
163 out of 399 startups were B2B software and services companies. Financial, healthcare, and consumer startups were common.
Our team doesn't plan to attend every pitch or speak with every startup's founders or team members. Let's look at cleantech, Web3, and health and wellness startup trends.
Our Opinions Following Conversations with 87 Startups at Demo Day
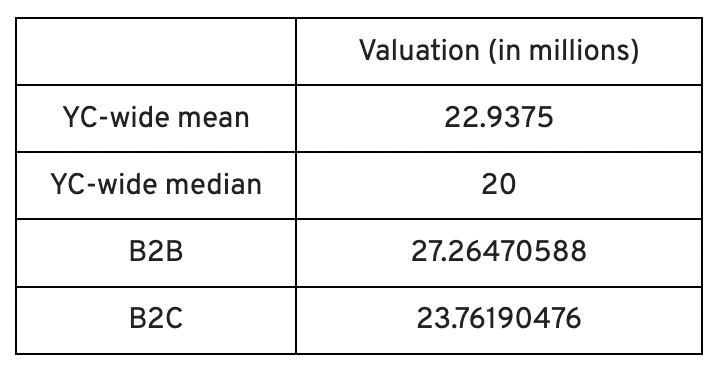
In the lead-up to Demo Day, we spoke with 87 of the 125 startups going. Compared to B2C enterprises, B2B startups had higher average valuations. A few outliers with high valuations pushed B2B and B2C means above the YC-wide mean and median.
Many of these startups develop business and technology solutions we've previously covered. We've seen API, EdTech, creative platforms, and cybersecurity remain strong and increase each year.
While these persistent tendencies influenced the startups Scrum Ventures looked at and the founders we interacted with on Demo Day, new trends required more research and preparation. Let's examine cleantech, Web3, and health and wellness startups.
Hardware and software that is green
Cleantech enterprises demand varying amounts of funding for hardware and software. Although the same overarching trend is fueling the growth of firms in this category, each subgroup has its own strategy and technique for investigation and identifying successful investments.
Many cleantech startups we spoke to during the YC event are focused on helping industrial operations decrease or recycle carbon emissions.
Carbon Crusher: Creating carbon negative roads
Phase Biolabs: Turning carbon emissions into carbon negative products and carbon neutral e-fuels
Seabound: Capturing carbon dioxide emissions from ships
Fleetzero: Creating electric cargo ships
Impossible Mining: Sustainable seabed mining
Beyond Aero: Creating zero-emission private aircraft
Verdn: Helping businesses automatically embed environmental pledges for product and service offerings, boost customer engagement
AeonCharge: Allowing electric vehicle (EV) drivers to more easily locate and pay for EV charging stations
Phoenix Hydrogen: Offering a hydrogen marketplace and a connected hydrogen hub platform to connect supply and demand for hydrogen fuel and simplify hub planning and partner program expansion
Aklimate: Allowing businesses to measure and reduce their supply chain’s environmental impact
Pina Earth: Certifying and tracking the progress of businesses’ forestry projects
AirMyne: Developing machines that can reverse emissions by removing carbon dioxide from the air
Unravel Carbon: Software for enterprises to track and reduce their carbon emissions
Web3: NFTs, the metaverse, and cryptocurrency
Web3 technologies handle a wide range of business issues. This category includes companies employing blockchain technology to disrupt entertainment, finance, cybersecurity, and software development.
Many of these startups overlap with YC's FinTech trend. Despite this, B2C and B2B enterprises were evenly represented in Web3. We examined:
Stablegains: Offering consistent interest on cash balance from the decentralized finance (DeFi) market
LiquiFi: Simplifying token management with automated vesting contracts, tax reporting, and scheduling. For companies, investors, and finance & accounting
NFTScoring: An NFT trading platform
CypherD Wallet: A multichain wallet for crypto and NFTs with a non-custodial crypto debit card that instantly converts coins to USD
Remi Labs: Allowing businesses to more easily create NFT collections that serve as access to products, memberships, events, and more
Cashmere: A crypto wallet for Web3 startups to collaboratively manage funds
Chaingrep: An API that makes blockchain data human-readable and tokens searchable
Courtyard: A platform for securely storing physical assets and creating 3D representations as NFTs
Arda: “Banking as a Service for DeFi,” an API that FinTech companies can use to embed DeFi products into their platforms
earnJARVIS: A premium cryptocurrency management platform, allowing users to create long-term portfolios
Mysterious: Creating community-specific experiences for Web3 Discords
Winter: An embeddable widget that allows businesses to sell NFTs to users purchasing with a credit card or bank transaction
SimpleHash: An API for NFT data that provides compatibility across blockchains, standardized metadata, accurate transaction info, and simple integration
Lifecast: Tools that address motion sickness issues for 3D VR video
Gym Class: Virtual reality (VR) multiplayer basketball video game
WorldQL: An asset API that allows NFT creators to specify multiple in-game interpretations of their assets, increasing their value
Bonsai Desk: A software development kit (SDK) for 3D analytics
Campfire: Supporting virtual social experiences for remote teams
Unai: A virtual headset and Visual World experience
Vimmerse: Allowing creators to more easily create immersive 3D experiences
Fitness and health
Scrum Ventures encountered fewer health and wellness startup founders than Web3 and Cleantech. The types of challenges these organizations solve are still diverse. Several of these companies are part of a push toward customization in healthcare, an area of biotech set for growth for companies with strong portfolios and experienced leadership.
Here are several startups we considered:
Syrona Health: Personalized healthcare for women in the workplace
Anja Health: Personalized umbilical cord blood banking and stem cell preservation
Alfie: A weight loss program focused on men’s health that coordinates medical care, coaching, and “community-based competition” to help users lose an average of 15% body weight
Ankr Health: An artificial intelligence (AI)-enabled telehealth platform that provides personalized side effect education for cancer patients and data collection for their care teams
Koko — A personalized sleep program to improve at-home sleep analysis and training
Condition-specific telehealth platforms and programs:
Reviving Mind: Chronic care management covered by insurance and supporting holistic, community-oriented health care
Equipt Health: At-home delivery of prescription medical equipment to help manage chronic conditions like obstructive sleep apnea
LunaJoy: Holistic women’s healthcare management for mental health therapy, counseling, and medication
12 Startups from YC's Winter 2022 Demo Day to Watch
Bobidi: 10x faster AI model improvement
Artificial intelligence (AI) models have become a significant tool for firms to improve how well and rapidly they process data. Bobidi helps AI-reliant firms evaluate their models, boosting data insights in less time and reducing data analysis expenditures. The business has created a gamified community that offers a bug bounty for AI, incentivizing community members to test and find weaknesses in clients' AI models.
Magna: DeFi investment management and token vesting
Magna delivers rapid, secure token vesting so consumers may turn DeFi investments into primitives. Carta for Web3 allows enterprises to effortlessly distribute tokens to staff or investors. The Magna team hopes to allow corporations use locked tokens as collateral for loans, facilitate secondary liquidity so investors can sell shares on a public exchange, and power additional DeFi applications.
Perl Street: Funding for infrastructure
This Fintech firm intends to help hardware entrepreneurs get financing by [democratizing] structured finance, unleashing billions for sustainable infrastructure and next-generation hardware solutions. This network has helped hardware entrepreneurs achieve more than $140 million in finance, helping companies working on energy storage devices, EVs, and creating power infrastructure.
CypherD: Multichain cryptocurrency wallet
CypherD seeks to provide a multichain crypto wallet so general customers can explore Web3 products without knowledge hurdles. The startup's beta app lets consumers access crypto from EVM blockchains. The founders have crypto, financial, and startup experience.
Unravel Carbon: Enterprise carbon tracking and offsetting
Unravel Carbon's AI-powered decarbonization technology tracks companies' carbon emissions. Singapore-based startup focuses on Asia. The software can use any company's financial data to trace the supply chain and calculate carbon tracking, which is used to make regulatory disclosures and suggest carbon offsets.
LunaJoy: Precision mental health for women
LunaJoy helped women obtain mental health support throughout life. The platform combines data science to create a tailored experience, allowing women to access psychotherapy, medication management, genetic testing, and health coaching.
Posh: Automated EV battery recycling
Posh attempts to solve one of the EV industry's largest logistical difficulties. Millions of EV batteries will need to be decommissioned in the next decade, and their precious metals and residual capacity will go unused for some time. Posh offers automated, scalable lithium battery disassembly, making EV battery recycling more viable.
Unai: VR headset with 5x higher resolution
Unai stands apart from metaverse companies. Its VR headgear has five times the resolution of existing options and emphasizes human expression and interaction in a remote world. Maxim Perumal's method of latency reduction powers current VR headsets.
Palitronica: Physical infrastructure cybersecurity
Palitronica blends cutting-edge hardware and software to produce networked electronic systems that support crucial physical and supply chain infrastructure. The startup's objective is to build solutions that defend national security and key infrastructure from cybersecurity threats.
Reality Defender: Deepfake detection
Reality Defender alerts firms to bogus users and changed audio, video, and image files. Reality Deference's API and web app score material in real time to prevent fraud, improve content moderation, and detect deception.
Micro Meat: Infrastructure for the manufacture of cell-cultured meat
MicroMeat promotes sustainable meat production. The company has created technologies to scale up bioreactor-grown meat muscle tissue from animal cells. Their goal is to scale up cultured meat manufacturing so cultivated meat products can be brought to market feasibly and swiftly, boosting worldwide meat consumption.
Fleetzero: Electric cargo ships
This startup's battery technology will make cargo ships more sustainable and profitable. Fleetzero's electric cargo ships have five times larger profit margins than fossil fuel ships. Fleetzeros' founder has marine engineering, ship operations, and enterprise sales and business experience.

Sanjay Priyadarshi
3 years ago
Meet a Programmer Who Turned Down Microsoft's $10,000,000,000 Acquisition Offer
Failures inspire young developers

Jason citron created many products.
These products flopped.
Microsoft offered $10 billion for one of these products.
He rejected the offer since he was so confident in his success.
Let’s find out how he built a product that is currently valued at $15 billion.
Early in his youth, Jason began learning to code.
Jason's father taught him programming and IT.
His father wanted to help him earn money when he needed it.
Jason created video games and websites in high school.
Jason realized early on that his IT and programming skills could make him money.
Jason's parents misjudged his aptitude for programming.
Jason frequented online programming communities.
He looked for web developers. He created websites for those people.
His parents suspected Jason sold drugs online. When he said he used programming to make money, they were shocked.
They helped him set up a PayPal account.
Florida higher education to study video game creation
Jason never attended an expensive university.
He studied game design in Florida.
“Higher Education is an interesting part of society… When I work with people, the school they went to never comes up… only thing that matters is what can you do…At the end of the day, the beauty of silicon valley is that if you have a great idea and you can bring it to the life, you can convince a total stranger to give you money and join your project… This notion that you have to go to a great school didn’t end up being a thing for me.”
Jason's life was altered by Steve Jobs' keynote address.
After graduating, Jason joined an incubator.
Jason created a video-dating site first.
Bad idea.
Nobody wanted to use it when it was released, so they shut it down.
He made a multiplayer game.
It was released on Bebo. 10,000 people played it.
When Steve Jobs unveiled the Apple app store, he stopped playing.
The introduction of the app store resembled that of a new gaming console.
Jason's life altered after Steve Jobs' 2008 address.
“Whenever a new video game console is launched, that’s the opportunity for a new video game studio to get started, it’s because there aren’t too many games available…When a new PlayStation comes out, since it’s a new system, there’s only a handful of titles available… If you can be a launch title you can get a lot of distribution.”
Apple's app store provided a chance to start a video game company.
They released an app after 5 months of work.
Aurora Feint is the game.
Jason believed 1000 players in a week would be wonderful. A thousand players joined in the first hour.
Over time, Aurora Feints' game didn't gain traction. They don't make enough money to keep playing.
They could only make enough for one month.
Instead of buying video games, buy technology
Jason saw that they established a leaderboard, chat rooms, and multiplayer capabilities and believed other developers would want to use these.
They opted to sell the prior game's technology.
OpenFeint.
Assisting other game developers
They had no money in the bank to create everything needed to make the technology user-friendly.
Jason and Daniel designed a website saying:
“If you’re making a video game and want to have a drop in multiplayer support, you can use our system”
TechCrunch covered their website launch, and they gained a few hundred mailing list subscribers.
They raised seed funding with the mailing list.
Nearly all iPhone game developers started adopting the Open Feint logo.
“It was pretty wild… It was really like a whole social platform for people to play with their friends.”
What kind of a business model was it?
OpenFeint originally planned to make the software free for all games. As the game gained popularity, they demanded payment.
They later concluded it wasn't a good business concept.
It became free eventually.
Acquired for $104 million
Open Feint's users and employees grew tremendously.
GREE bought OpenFeint for $104 million in April 2011.
GREE initially committed to helping Jason and his team build a fantastic company.
Three or four months after the acquisition, Jason recognized they had a different vision.
He quit.
Jason's Original Vision for the iPad
Jason focused on distribution in 2012 to help businesses stand out.
The iPad market and user base were growing tremendously.
Jason said the iPad may replace mobile gadgets.
iPad gamers behaved differently than mobile gamers.
People sat longer and experienced more using an iPad.
“The idea I had was what if we built a gaming business that was more like traditional video games but played on tablets as opposed to some kind of mobile game that I’ve been doing before.”
Unexpected insight after researching the video game industry
Jason learned from studying the gaming industry that long-standing companies had advantages beyond a single release.
Previously, long-standing video game firms had their own distribution system. This distribution strategy could buffer time between successful titles.
Sony, Microsoft, and Valve all have gaming consoles and online stores.
So he built a distribution system.
He created a group chat app for gamers.
He envisioned a team-based multiplayer game with text and voice interaction.
His objective was to develop a communication network, release more games, and start a game distribution business.
Remaking the video game League of Legends
Jason and his crew reimagined a League of Legends game mode for 12-inch glass.
They adapted the game for tablets.
League of Legends was PC-only.
So they rebuilt it.
They overhauled the game and included native mobile experiences to stand out.
Hammer and Chisel was the company's name.
18 people worked on the game.
The game was funded. The game took 2.5 years to make.
Was the game a success?
July 2014 marked the game's release. The team's hopes were dashed.
Critics initially praised the game.
Initial installation was widespread.
The game failed.
As time passed, the team realized iPad gaming wouldn't increase much and mobile would win.
Jason was given a fresh idea by Stan Vishnevskiy.
Stan Vishnevskiy was a corporate engineer.
He told Jason about his plan to design a communication app without a game.
This concept seeded modern strife.
“The insight that he really had was to put a couple of dots together… we’re seeing our customers communicating around our own game with all these different apps and also ourselves when we’re playing on PC… We should solve that problem directly rather than needing to build a new game…we should start making it on PC.”
So began Discord.
Online socializing with pals was the newest trend.
Jason grew up playing video games with his friends.
He never played outside.
Jason had many great moments playing video games with his closest buddy, wife, and brother.
Discord was about providing a location for you and your group to speak and hang out.
Like a private cafe, bedroom, or living room.
Discord was developed for you and your friends on computers and phones.
You can quickly call your buddies during a game to conduct a conference call. Put the call on speaker and talk while playing.
Discord wanted to give every player a unique experience. Because coordinating across apps was a headache.
The entire team started concentrating on Discord.
Jason decided Hammer and Chisel would focus on their chat app.
Jason didn't want to make a video game.
How Discord attracted the appropriate attention
During the first five months, the entire team worked on the game and got feedback from friends.
This ensures product improvement. As a result, some teammates' buddies started utilizing Discord.
The team knew it would become something, but the result was buggy. App occasionally crashed.
Jason persuaded a gamer friend to write on Reddit about the software.
New people would find Discord. Why not?
Reddit users discovered Discord and 50 started using it frequently.
Discord was launched.
Rejecting the $10 billion acquisition proposal
Discord has increased in recent years.
It sends billions of messages.
Discord's users aren't tracked. They're privacy-focused.
Purchase offer
Covid boosted Discord's user base.
Weekly, billions of messages were transmitted.
Microsoft offered $10 billion for Discord in 2021.
Jason sold Open Feint for $104m in 2011.
This time, he believed in the product so much that he rejected Microsoft's offer.
“I was talking to some people in the team about which way we could go… The good thing was that most of the team wanted to continue building.”
Last time, Discord was valued at $15 billion.
Discord raised money on March 12, 2022.
The $15 billion corporation raised $500 million in 2021.
You might also like

Shalitha Suranga
3 years ago
The Top 5 Mathematical Concepts Every Programmer Needs to Know
Using math to write efficient code in any language

Programmers design, build, test, and maintain software. Employ cases and personal preferences determine the programming languages we use throughout development. Mobile app developers use JavaScript or Dart. Some programmers design performance-first software in C/C++.
A generic source code includes language-specific grammar, pre-implemented function calls, mathematical operators, and control statements. Some mathematical principles assist us enhance our programming and problem-solving skills.
We all use basic mathematical concepts like formulas and relational operators (aka comparison operators) in programming in our daily lives. Beyond these mathematical syntaxes, we'll see discrete math topics. This narrative explains key math topics programmers must know. Master these ideas to produce clean and efficient software code.
Expressions in mathematics and built-in mathematical functions
A source code can only contain a mathematical algorithm or prebuilt API functions. We develop source code between these two ends. If you create code to fetch JSON data from a RESTful service, you'll invoke an HTTP client and won't conduct any math. If you write a function to compute the circle's area, you conduct the math there.
When your source code gets more mathematical, you'll need to use mathematical functions. Every programming language has a math module and syntactical operators. Good programmers always consider code readability, so we should learn to write readable mathematical expressions.
Linux utilizes clear math expressions.
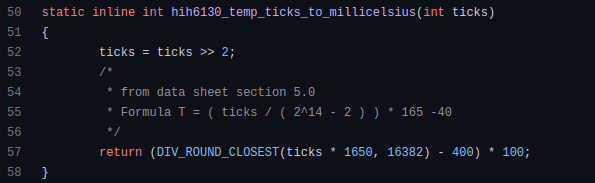
Inbuilt max and min functions can minimize verbose if statements.
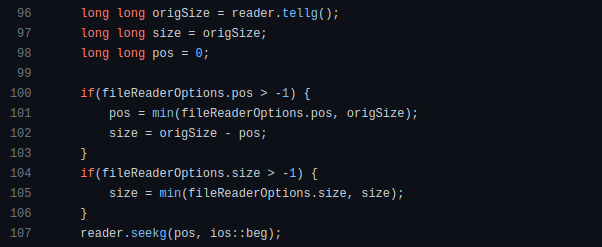
How can we compute the number of pages needed to display known data? In such instances, the ceil function is often utilized.
import math as m
results = 102
items_per_page = 10
pages = m.ceil(results / items_per_page)
print(pages)Learn to write clear, concise math expressions.
Combinatorics in Algorithm Design
Combinatorics theory counts, selects, and arranges numbers or objects. First, consider these programming-related questions. Four-digit PIN security? what options exist? What if the PIN has a prefix? How to locate all decimal number pairs?
Combinatorics questions. Software engineering jobs often require counting items. Combinatorics counts elements without counting them one by one or through other verbose approaches, therefore it enables us to offer minimum and efficient solutions to real-world situations. Combinatorics helps us make reliable decision tests without missing edge cases. Write a program to see if three inputs form a triangle. This is a question I commonly ask in software engineering interviews.
Graph theory is a subfield of combinatorics. Graph theory is used in computerized road maps and social media apps.
Logarithms and Geometry Understanding
Geometry studies shapes, angles, and sizes. Cartesian geometry involves representing geometric objects in multidimensional planes. Geometry is useful for programming. Cartesian geometry is useful for vector graphics, game development, and low-level computer graphics. We can simply work with 2D and 3D arrays as plane axes.
GetWindowRect is a Windows GUI SDK geometric object.
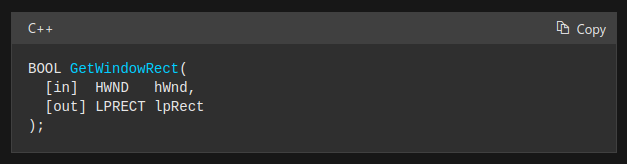
High-level GUI SDKs and libraries use geometric notions like coordinates, dimensions, and forms, therefore knowing geometry speeds up work with computer graphics APIs.
How does exponentiation's inverse function work? Logarithm is exponentiation's inverse function. Logarithm helps programmers find efficient algorithms and solve calculations. Writing efficient code involves finding algorithms with logarithmic temporal complexity. Programmers prefer binary search (O(log n)) over linear search (O(n)). Git source specifies O(log n):
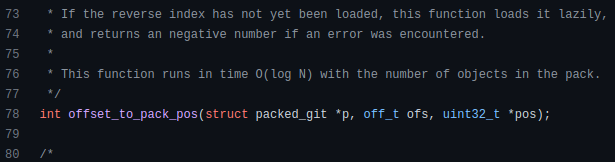
Logarithms aid with programming math. Metas Watchman uses a logarithmic utility function to find the next power of two.
Employing Mathematical Data Structures
Programmers must know data structures to develop clean, efficient code. Stack, queue, and hashmap are computer science basics. Sets and graphs are discrete arithmetic data structures. Most computer languages include a set structure to hold distinct data entries. In most computer languages, graphs can be represented using neighboring lists or objects.
Using sets as deduped lists is powerful because set implementations allow iterators. Instead of a list (or array), store WebSocket connections in a set.
Most interviewers ask graph theory questions, yet current software engineers don't practice algorithms. Graph theory challenges become obligatory in IT firm interviews.
Recognizing Applications of Recursion
A function in programming isolates input(s) and output(s) (s). Programming functions may have originated from mathematical function theories. Programming and math functions are different but similar. Both function types accept input and return value.
Recursion involves calling the same function inside another function. In its implementation, you'll call the Fibonacci sequence. Recursion solves divide-and-conquer software engineering difficulties and avoids code repetition. I recently built the following recursive Dart code to render a Flutter multi-depth expanding list UI:
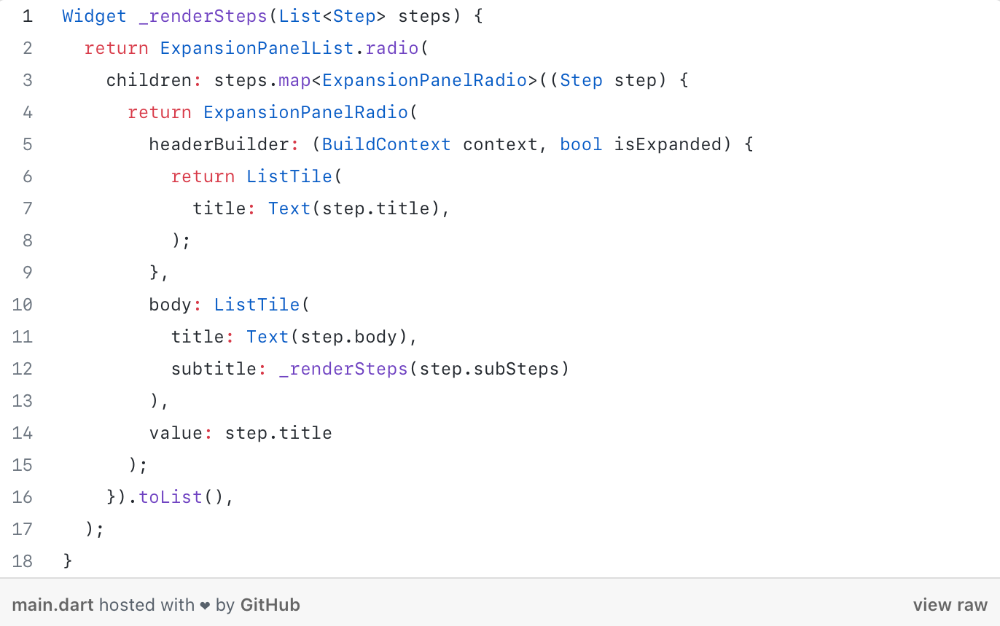
Recursion is not the natural linear way to solve problems, hence thinking recursively is difficult. Everything becomes clear when a mathematical function definition includes a base case and recursive call.
Conclusion
Every codebase uses arithmetic operators, relational operators, and expressions. To build mathematical expressions, we typically employ log, ceil, floor, min, max, etc. Combinatorics, geometry, data structures, and recursion help implement algorithms. Unless you operate in a pure mathematical domain, you may not use calculus, limits, and other complex math in daily programming (i.e., a game engine). These principles are fundamental for daily programming activities.
Master the above math fundamentals to build clean, efficient code.

Johnny Harris
4 years ago
The REAL Reason Putin is Invading Ukraine [video with transcript]
Transcript:
[Reporter] The Russian invasion of Ukraine.
Momentum is building for a war between Ukraine and Russia.
[Reporter] Tensions between Russia and the West
are growing rapidly.
[Reporter] President Biden considering deploying
thousands of troops to Eastern Europe.
There are now 100,000 troops
on the Eastern border of Ukraine.
Russia is setting up field hospitals on this border.
Like this is what preparation for war looks like.
A legitimate war.
Ukrainian troops are watching and waiting,
saying they are preparing for a fight.
The U.S. has ordered the families of embassy staff
to leave Ukraine.
Britain has sent all of their nonessential staff home.
And now the U.S. is sending tons of weapons and munitions
to Ukraine's army.
And we're even considering deploying
our own troops to the region.
I mean, this thing is heating up.
Meanwhile, Russia and the West have been in Geneva
and Brussels trying to talk it out,
and sort of getting nowhere.
The message is very clear.
Should Russia take further aggressive actions
against Ukraine the costs will be severe
and the consequences serious.
It's a scary, grim momentum that is unpredictable.
And the chances of miscalculation
and escalation are growing.
I want to explain what's going on here,
but I want to show you that this isn't just
typical geopolitical behavior.
Stuff that can just be explained on the map.
Instead, to understand why 100,000 troops are camped out
on Ukraine's Eastern border, ready for war,
you have to understand Russia
and how it's been cut down over the ages
from the Slavic empire that dominated this whole region
to then the Soviet Union,
which was defeated in the nineties.
And what you really have to understand here
is how that history is transposed
onto the brain of one man.
This guy, Vladimir Putin.
This is a story about regional domination
and struggles between big powers,
but really it's the story about
what Vladimir Putin really wants.
[Reporter] Russian troops moving swiftly
to take control of military bases in Crimea.
[Reporter] Russia has amassed more than 100,000 troops
and a lot of military hardware
at the border with Ukraine.
Let's dive back in.
Okay. Let's get up to speed on what's happening here.
And I'm just going to quickly give you the highlight version
of like the news that's happening,
because I want to get into the juicy part,
which is like why, the roots of all of this.
So let's go.
A few months ago, Russia started sending
more and more troops to this border.
It's this massive border between Ukraine and Russia.
They said they were doing a military exercise,
but the rest of the world was like,
"Yeah, we totally believe you Russia. Pshaw."
This was right before this big meeting
where North American and European countries
were coming together to talk about a lot
of different things, like these countries often do
in these diplomatic summits.
But soon, because of Russia's aggressive behavior
coming in and setting up 100,000 troops
on the border with Ukraine,
the entire summit turned into a whole, "WTF Russia,
what are you doing on the border of Ukraine," meeting.
Before the meeting Putin comes out and says,
"Listen, I have some demands for the West."
And everyone's like, "Okay, Russia, what are your demands?
You know, we have like, COVID19 right now.
And like, that's like surging.
So like, we don't need your like,
bluster about what your demands are."
And Putin's like, "No, here's my list of demands."
Putin's demands for the summit were this:
number one, that NATO, which is this big military alliance
between U.S., Canada, and Europe stop expanding,
meaning they don't let any new members in, okay.
So, Russia is like, "No more new members to your, like,
cool military club that I don't like.
You can't have any more members."
Number two, that NATO withdraw all of their troops
from anywhere in Eastern Europe.
Basically Putin is saying,
"I can veto any military cooperation
or troops going between countries
that have to do with Eastern Europe,
the place that used to be the Soviet Union."
Okay, and number three, Putin demands that America vow
not to protect its allies in Eastern Europe
with nuclear weapons.
"LOL," said all of the other countries,
"You're literally nuts, Vladimir Putin.
Like these are the most ridiculous demands, ever."
But there he is, Putin, with these demands.
These very, very aggressive demands.
And he sort of is implying that if his demands aren't met,
he's going to invade Ukraine.
I mean, it doesn't work like this.
This is not how international relations work.
You don't just show up and say like,
"I'm not gonna allow other countries to join your alliance
because it makes me feel uncomfortable."
But what I love about this list of demands
from Vladimir Putin for this summit
is that it gives us a clue
on what Vladimir Putin really wants.
What he's after here.
You read them closely and you can grasp his intentions.
But to grasp those intentions
you have to understand what NATO is.
and what Russia and Ukraine used to be.
(dramatic music)
Okay, so a while back I made this video
about why Russia is so damn big,
where I explain how modern day Russia started here in Kiev,
which is actually modern day Ukraine.
In other words, modern day Russia, as we know it,
has its original roots in Ukraine.
These places grew up together
and they eventually became a part
of the same mega empire called the Soviet Union.
They were deeply intertwined,
not just in their history and their culture,
but also in their economy and their politics.
So it's after World War II,
it's like the '50s, '60s, '70s, and NATO was formed,
the North Atlantic Treaty Organization.
This was a military alliance between all of these countries,
that was meant to sort of deter the Soviet Union
from expanding and taking over the world.
But as we all know, the Soviet Union,
which was Russia and all of these other countries,
collapsed in 1991.
And all of these Soviet republics,
including Ukraine, became independent,
meaning they were not now a part
of one big block of countries anymore.
But just because the border's all split up,
it doesn't mean that these cultural ties actually broke.
Like for example, the Soviet leader at the time
of the collapse of the Soviet Union, this guy, Gorbachev,
he was the son of a Ukrainian mother and a Russian father.
Like he grew up with his mother singing him
Ukrainian folk songs.
In his mind, Ukraine and Russia were like one thing.
So there was a major reluctance to accept Ukraine
as a separate thing from Russia.
In so many ways, they are one.
There was another Russian at the time
who did not accept this new division.
This young intelligence officer, Vladimir Putin,
who was starting to rise up in the ranks
of postSoviet Russia.
There's this amazing quote from 2005
where Putin is giving this stateoftheunionlike address,
where Putin declares the collapse of the Soviet Union,
quote, "The greatest catastrophe of the 20th century.
And as for the Russian people, it became a genuine tragedy.
Tens of millions of fellow citizens and countrymen
found themselves beyond the fringes of Russian territory."
Do you see how he frames this?
The Soviet Union were all one people in his mind.
And after it collapsed, all of these people
who are a part of the motherland were now outside
of the fringes or the boundaries of Russian territory.
First off, fact check.
Greatest catastrophe of the 20th century?
Like, do you remember what else happened
in the 20th century, Vladimir?
(ominous music)
Putin's worry about the collapse of this one people
starts to get way worse when the West, his enemy,
starts showing up to his neighborhood
to all these exSoviet countries that are now independent.
The West starts selling their ideology
of democracy and capitalism and inviting them
to join their military alliance called NATO.
And guess what?
These countries are totally buying it.
All these exSoviet countries are now joining NATO.
And some of them, the EU.
And Putin is hating this.
He's like not only did the Soviet Union divide
and all of these people are now outside
of the Russia motherland,
but now they're being persuaded by the West
to join their military alliance.
This is terrible news.
Over the years, this continues to happen,
while Putin himself starts to chip away
at Russian institutions, making them weaker and weaker.
He's silencing his rivals
and he's consolidating power in himself.
(triumphant music)
And in the past few years,
he's effectively silenced anyone who can challenge him;
any institution, any court,
or any political rival have all been silenced.
It's been decades since the Soviet Union fell,
but as Putin gains more power,
he still sees the region through the lens
of the old Cold War, Soviet, Slavic empire view.
He sees this region as one big block
that has been torn apart by outside forces.
"The greatest catastrophe of the 20th century."
And the worst situation of all of these,
according to Putin, is Ukraine,
which was like the gem of the Soviet Union.
There was tons of cultural heritage.
Again, Russia sort of started in Ukraine,
not to mention it was a very populous
and industrious, resourcerich place.
And over the years Ukraine has been drifting west.
It hasn't joined NATO yet, but more and more,
it's been electing proWestern presidents.
It's been flirting with membership in NATO.
It's becoming less and less attached
to the Russian heritage that Putin so adores.
And more than half of Ukrainians say
that they'd be down to join the EU.
64% of them say that it would be cool joining NATO.
But Putin can't handle this. He is in total denial.
Like an exboyfriend who handle his exgirlfriend
starting to date someone else,
Putin can't let Ukraine go.
He won't let go.
So for the past decade,
he's been trying to keep the West out
and bring Ukraine back into the motherland of Russia.
This usually takes the form of Putin sending
secret soldiers from Russia into Ukraine
to help the people in Ukraine who want to like separate
from Ukraine and join Russia.
It also takes the form of, oh yeah,
stealing entire parts of Ukraine for Russia.
Russian troops moving swiftly to take control
of military bases in Crimea.
Like in 2014, Putin just did this.
To what America is officially calling
a Russian invasion of Ukraine.
He went down and just snatched this bit of Ukraine
and folded it into Russia.
So you're starting to see what's going on here.
Putin's life's work is to salvage what he calls
the greatest catastrophe of the 20th century,
the division and the separation
of the Soviet republics from Russia.
So let's get to present day. It's 2022.
Putin is at it again.
And honestly, if you really want to understand
the mind of Vladimir Putin and his whole view on this,
you have to read this.
"On the History of Unity of Russians and Ukrainians,"
by Vladimir Putin.
A blog post that kind of sounds
like a ninth grade history essay.
In this essay, Vladimir Putin argues
that Russia and Ukraine are one people.
He calls them essentially the same historical
and spiritual space.
Kind of beautiful writing, honestly.
Anyway, he argues that the division
between the two countries is due to quote,
"a deliberate effort by those forces
that have always sought to undermine our unity."
And that the formula they use, these outside forces,
is a classic one: divide and rule.
And then he launches into this super indepth,
like 10page argument, as to every single historical beat
of Ukraine and Russia's history
to make this argument that like,
this is one people and the division is totally because
of outside powers, i.e. the West.
Okay, but listen, there's this moment
at the end of the post,
that actually kind of hit me in a big way.
He says this, "Just have a look at Austria and Germany,
or the U.S. and Canada, how they live next to each other.
Close in ethnic composition, culture,
and in fact, sharing one language,
they remain sovereign states with their own interests,
with their own foreign policy.
But this does not prevent them
from the closest integration or allied relations.
They have very conditional, transparent borders.
And when crossing them citizens feel at home.
They create families, study, work, do business.
Incidentally, so do millions of those born in Ukraine
who now live in Russia.
We see them as our own close people."
I mean, listen, like,
I'm not in support of what Putin is doing,
but like that, it's like a pretty solid like analogy.
If China suddenly showed up and started like
coaxing Canada into being a part of its alliance,
I would be a little bit like, "What's going on here?"
That's what Putin feels.
And so I kind of get what he means there.
There's a deep heritage and connection between these people.
And he's seen that falter and dissolve
and he doesn't like it.
He clearly genuinely feels a brotherhood
and this deep heritage connection
with the people of Ukraine.
Okay, okay, okay, okay. Putin, I get it.
Your essay is compelling there at the end.
You're clearly very smart and wellread.
But this does not justify what you've been up to. Okay?
It doesn't justify sending 100,000 troops to the border
or sending cyber soldiers to sabotage
the Ukrainian government, or annexing territory,
fueling a conflict that has killed
tens of thousands of people in Eastern Ukraine.
No. Okay.
No matter how much affection you feel for Ukrainian heritage
and its connection to Russia, this is not okay.
Again, it's like the boyfriend
who genuinely loves his girlfriend.
They had a great relationship,
but they broke up and she's free to see whomever she wants.
But Putin is not ready to let go.
[Man In Blue Shirt] What the hell's wrong with you?
I love you, Jessica.
What the hell is wrong with you?
Dude, don't fucking touch me.
I love you. Worldstar!
What is wrong with you? Just stop!
Putin has constructed his own reality here.
One in which Ukraine is actually being controlled
by shadowy Western forces
who are holding the people of Ukraine hostage.
And if that he invades, it will be a swift victory
because Ukrainians will accept him with open arms.
The great liberator.
(triumphant music)
Like, this guy's a total romantic.
He's a history buff and a romantic.
And he has a hill to die on here.
And it is liberating the people
who have been taken from the Russian motherland.
Kind of like the abusive boyfriend, who's like,
"She actually really loves me,
but it's her annoying friends
who were planting all these ideas in her head.
That's why she broke up with me."
And it's like, "No, dude, she's over you."
[Man In Blue Shirt] What the hell is wrong with you?
I love you, Jessica.
I mean, maybe this video should be called
Putin is just like your abusive exboyfriend.
[Man In Blue Shirt] What the hell is wrong with you?
I love you, Jessica!
Worldstar! What's wrong with you?
Okay. So where does this leave us?
It's 2022, Putin is showing up to these meetings in Europe
to tell them where he stands.
He says, "NATO, you cannot expand anymore. No new members.
And you need to withdraw all your troops
from Eastern Europe, my neighborhood."
He knows these demands will never be accepted
because they're ludicrous.
But what he's doing is showing a false effort to say,
"Well, we tried to negotiate with the West,
but they didn't want to."
Hence giving a little bit more justification
to a Russian invasion.
So will Russia invade? Is there war coming?
Maybe; it's impossible to know
because it's all inside of the head of this guy.
But, if I were to make the best argument
that war is not coming tomorrow,
I would look at a few things.
Number one, war in Ukraine would be incredibly costly
for Vladimir Putin.
Russia has a far superior army to Ukraine's,
but still, Ukraine has a very good army
that is supported by the West
and would give Putin a pretty bad bloody nose
in any invasion.
Controlling territory in Ukraine would be very hard.
Ukraine is a giant country.
They would fight back and it would be very hard
to actually conquer and take over territory.
Another major point here is that if Russia invades Ukraine,
this gives NATO new purpose.
If you remember, NATO was created because of the Cold War,
because the Soviet Union was big and nuclear powered.
Once the Soviet Union fell,
NATO sort of has been looking for a new purpose
over the past couple of decades.
If Russia invades Ukraine,
NATO suddenly has a brand new purpose to unite
and to invest in becoming more powerful than ever.
Putin knows that.
And it would be very bad news for him if that happened.
But most importantly, perhaps the easiest clue
for me to believe that war isn't coming tomorrow
is the Russian propaganda machine
is not preparing the Russian people for an invasion.
In 2014, when Russia was about to invade
and take over Crimea, this part of Ukraine,
there was a barrage of state propaganda
that prepared the Russian people
that this was a justified attack.
So when it happened, it wasn't a surprise
and it felt very normal.
That isn't happening right now in Russia.
At least for now. It may start happening tomorrow.
But for now, I think Putin is showing up to the border,
flexing his muscles and showing the West that he is earnest.
I'm not sure that he's going to invade tomorrow,
but he very well could.
I mean, read the guy's blog post
and you'll realize that he is a romantic about this.
He is incredibly idealistic about the glory days
of the Slavic empires, and he wants to get it back.
So there is dangerous momentum towards war.
And the way war works is even a small little, like, fight,
can turn into the other guy
doing something bigger and crazier.
And then the other person has to respond
with something a little bit bigger.
That's called escalation.
And there's not really a ceiling
to how much that momentum can spin out of control.
That is why it's so scary when two nuclear countries
go to war with each other,
because there's kind of no ceiling.
So yeah, it's dangerous. This is scary.
I'm not sure what happens next here,
but the best we can do is keep an eye on this.
At least for now, we better understand
what Putin really wants out of all of this.
Thanks for watching.

John Rampton
3 years ago
Ideas for Samples of Retirement Letters

Ready to quit full-time? No worries.
Baby Boomer retirement has accelerated since COVID-19 began. In 2020, 29 million boomers retire. Over 3 million more than in 2019. 75 million Baby Boomers will retire by 2030.
First, quit your work to enjoy retirement. Leave a professional legacy. Your retirement will start well. It all starts with a retirement letter.
Retirement Letter
Retirement letters are formal resignation letters. Different from other resignation letters, these don't tell your employer you're leaving. Instead, you're quitting.
Since you're not departing over grievances or for a better position or higher income, you may usually terminate the relationship amicably. Consulting opportunities are possible.
Thank your employer for their support and give them transition information.
Resignation letters aren't merely a formality. This method handles wages, insurance, and retirement benefits.
Retirement letters often accompany verbal notices to managers. Schedule a meeting before submitting your retirement letter to discuss your plans. The letter will be stored alongside your start date, salary, and benefits in your employee file.
Retirement is typically well-planned. Employers want 6-12 months' notice.
Summary
Guidelines for Giving Retirement Notice
Components of a Successful Retirement Letter
Template for Retirement Letter
Ideas for Samples of Retirement Letters
First Example of Retirement Letter
Second Example of Retirement Letter
Third Example of Retirement Letter
Fourth Example of Retirement Letter
Fifth Example of Retirement Letter
Sixth Example of Retirement Letter
Seventh Example of Retirement Letter
Eighth Example of Retirement Letter
Ninth Example of Retirement Letter
Tenth Example of Retirement Letter
Frequently Asked Questions
1. What is a letter of retirement?
2. Why should you include a letter of retirement?
3. What information ought to be in your retirement letter?
4. Must I provide notice?
5. What is the ideal retirement age?
Guidelines for Giving Retirement Notice
While starting a new phase, you're also leaving a job you were qualified for. You have years of experience. So, it may not be easy to fill a retirement-related vacancy.
Talk to your boss in person before sending a letter. Notice is always appreciated. Properly announcing your retirement helps you and your organization transition.
How to announce retirement:
Learn about the retirement perks and policies offered by the company. The first step in figuring out whether you're eligible for retirement benefits is to research your company's retirement policy.
Don't depart without providing adequate notice. You should give the business plenty of time to replace you if you want to retire in a few months.
Help the transition by offering aid. You could be a useful resource if your replacement needs training.
Contact the appropriate parties. The original copy should go to your boss. Give a copy to HR because they will manage your 401(k), pension, and health insurance.
Investigate the option of working as a consultant or part-time. If you desire, you can continue doing some limited work for the business.
Be nice to others. Describe your achievements and appreciation. Additionally, express your gratitude for giving you the chance to work with such excellent coworkers.
Make a plan for your future move. Simply updating your employer on your goals will help you maintain a good working relationship.
Use a formal letter or email to formalize your plans. The initial step is to speak with your supervisor and HR in person, but you must also give written notice.
Components of a Successful Retirement Letter
To write a good retirement letter, keep in mind the following:
A formal salutation. Here, the voice should be deliberate, succinct, and authoritative.
Be specific about your intentions. The key idea of your retirement letter is resignation. Your decision to depart at this time should be reflected in your letter. Remember that your intention must be clear-cut.
Your deadline. This information must be in resignation letters. Laws and corporate policies may both stipulate a minimum amount of notice.
A kind voice. Your retirement letter shouldn't contain any resentments, insults, or other unpleasantness. Your letter should be a model of professionalism and grace. A straightforward thank you is a terrific approach to accomplish that.
Your ultimate goal. Chaos may start to happen as soon as you turn in your resignation letter. Your position will need to be filled. Additionally, you will have to perform your obligations up until a successor is found. Your availability during the interim period should be stated in your resignation letter.
Give us a way to reach you. Even if you aren't consulting, your company will probably get in touch with you at some point. They might send you tax documents and details on perks. By giving your contact information, you can make this process easier.
Template for Retirement Letter
Identify
Title you held
Address
Supervisor's name
Supervisor’s position
Company name
HQ address
Date
[SUPERVISOR],
1.
Inform that you're retiring. Include your last day worked.
2.
Employer thanks. Mention what you're thankful for. Describe your accomplishments and successes.
3.
Helping moves things ahead. Plan your retirement. Mention your consultancy interest.
Sincerely,
[Signature]
First and last name
Phone number
Personal Email
Ideas for Samples of Retirement Letters
First Example of Retirement Letter
Martin D. Carey
123 Fleming St
Bloomfield, New Jersey 07003
(555) 555-1234
June 6th, 2022
Willie E. Coyote
President
Acme Co
321 Anvil Ave
Fairfield, New Jersey 07004
Dear Mr. Coyote,
This letter notifies Acme Co. of my retirement on August 31, 2022.
There has been no other organization that has given me that sense of belonging and purpose.
My fifteen years at the helm of the Structural Design Division have given me a strong sense of purpose. I’ve been fortunate to have your support, and I’ll be always grateful for the opportunity you offered me.
I had a difficult time making this decision. As a result of finding a small property in Arizona where we will be able to spend our remaining days together, my wife and I have decided to officially retire.
In spite of my regret at being unable to contribute to the firm we’ve built, I believe it is wise to move on.
My heart will always belong to Acme Co. Thank you for the opportunity and best of luck in the years to come.
Sincerely,
Martin D. Carey
Second Example of Retirement Letter
Gustavo Fring
Los Pollas Hermanos
12000–12100 Coors Rd SW,
Albuquerque, New Mexico 87045
Dear Mr. Fring,
I write this letter to announce my formal retirement from Los Pollas Hermanos as manager, effective October 15.
As an employee at Los Pollas Hermanos, I appreciate all the great opportunities you have given me. It has been a pleasure to work with and learn from my colleagues for the past 10 years, and I am looking forward to my next challenge.
If there is anything I can do to assist during this time, please let me know.
Sincerely,
Linda T. Crespo
Third Example of Retirement Letter
William M. Arviso
4387 Parkview Drive
Tustin, CA 92680
May 2, 2023
Tony Stark
Owner
Stark Industries
200 Industrial Avenue
Long Beach, CA 90803
Dear Tony:
I’m writing to inform you that my final day of work at Stark Industries will be May14, 2023. When that time comes, I intend to retire.
As I embark on this new chapter in my life, I would like to thank you and the entire Stark Industries team for providing me with so many opportunities. You have all been a pleasure to work with and I will miss you all when I retire.
I am glad to assist you with the transition in any way I can to ensure your new hire has a seamless experience. All ongoing projects will be completed until my retirement date, and all key information will be handed over to the team.
Once again, thank you for the opportunity to be part of the Stark Industries team. All the best to you and the team in the days to come.
Please do not hesitate to contact me if you require any additional information. In order to finalize my retirement plans, I’ll meet with HR and can provide any details that may be necessary.
Sincerely,
(Signature)
William M. Arviso
Fourth Example of Retirement Letter
Garcia, Barbara
First Street, 5432
New York City, NY 10001
(1234) (555) 123–1234
1 October 2022
Gunther
Owner
Central Perk
199 Lafayette St.
New York City, NY 10001
Mr. Gunther,
The day has finally arrived. As I never imagined, I will be formally retiring from Central Perk on November 1st, 2022.
Considering how satisfied I am with my current position, this may surprise you. It would be best if I retired now since my health has deteriorated, so I think this is a good time to do so.
There is no doubt that the past two decades have been wonderful. Over the years, I have seen a small coffee shop grow into one of the city’s top destinations.
It will be hard for me to leave this firm without wondering what more success we could have achieved. But I’m confident that you and the rest of the Central Perk team will achieve great things.
My family and I will never forget what you’ve done for us, and I am grateful for the chance you’ve given me. My house is always open to you.
Sincerely Yours
Garcia, Barbara
Fifth Example of Retirement Letter
Pat Williams
618 Spooky Place
Monstropolis, 23221
123–555–0031
pwilliams@email.com
Feb. 16, 2022
Mike Wazowski
Co-CEO
Monters, Inc.
324 Scare Road
Monstropolis
Dear Mr. Wazowski,
As a formal notice of my upcoming retirement, I am submitting this letter. I will be leaving Monters, Inc. on April 13.
These past 10 years as a marketing associate have provided me with many opportunities. Since we started our company a decade ago, we have seen the face of harnessing screams change dramatically into harnessing laughter. During my time working with this dynamic marketing team, I learned a lot about customer behavior and marketing strategies. Working closely with some of our long-standing clients, such as Boo, was a particular pleasure.
I would be happy to assist with the transition following my retirement. It would be my pleasure to assist in the hiring or training of my replacement. In order to spend more time with my family, I will also be able to offer part-time consulting services.
After I retire, I plan to cash out the eight unused vacation days I’ve accumulated and take my pension as a lump sum.
Thank you for the opportunity to work with Monters, Inc. In the years to come, I wish you all the best!
Sincerely,
Paul Williams
Sixth Example of Retirement Letter
Dear Micheal,
As In my tenure at Dunder Mifflin Paper Company, I have given everything I had. It has been an honor to work here. But I have decided to move on to new challenges and retire from my position — mainly bears, beets, and Battlestar Galactia.
I appreciate the opportunity to work here and learn so much. During my time at this company, I will always remember the good times and memories we shared. Wishing you all the best in the future.
Sincerely,
Dwight K. Shrute
Your signature
May 16
Seventh Example of Retirement Letter
Greetings, Bill
I am announcing my retirement from Initech, effective March 15, 2023.
Over the course of my career here, I’ve had the privilege of working with so many talented and inspiring people.
In 1999, when I began working as a customer service representative, we were a small organization located in a remote office park.
The fact that we now occupy a floor of the Main Street office building with over 150 employees continues to amaze me.
I am looking forward to spending more time with family and traveling the country in our RV. Although I will be sad to leave.
Please let me know if there are any extra steps I can take to facilitate this transfer.
Sincerely,
Frankin, RenitaEighth Example of Retirement Letter
Height Example of Retirement Letter
Bruce,
Please accept my resignation from Wayne Enterprises as Marketing Communications Director. My last day will be August 1, 2022.
The decision to retire has been made after much deliberation. Now that I have worked in the field for forty years, I believe it is a good time to begin completing my bucket list.
It was not easy for me to decide to leave the company. Having worked at Wayne Enterprises has been rewarding both professionally and personally. There are still a lot of memories associated with my first day as a college intern.
My intention was not to remain with such an innovative company, as you know. I was able to see the big picture with your help, however. Today, we are a force that is recognized both nationally and internationally.
In addition to your guidance, the bold, visionary leadership of our company contributed to the growth of our company.
My departure from the company coincides with a particularly hectic time. Despite my best efforts, I am unable to postpone my exit.
My position would be well served by an internal solution. I have a more than qualified marketing manager in Caroline Crown. It would be a pleasure to speak with you about this.
In case I can be of assistance during the switchover, please let me know. Contact us at (555)555–5555. As part of my responsibilities, I am responsible for making sure all work is completed to Wayne Enterprise’s stringent requirements. Having the opportunity to work with you has been a pleasure. I wish you continued success with your thriving business.
Sincerely,
Cash, Cole
Marketing/Communications
Ninth Example of Retirement Letter
Norman, Jamie
2366 Hanover Street
Whitestone, NY 11357
555–555–5555
15 October 2022
Mr. Lippman
Head of Pendant Publishing
600 Madison Ave.
New York, New York
Respected Mr. Lippman,
Please accept my resignation effective November 1, 2022.
Over the course of my ten years at Pendant Publishing, I’ve had a great deal of fun and I’m quite grateful for all the assistance I’ve received.
It was a pleasure to wake up and go to work every day because of our outstanding corporate culture and the opportunities for promotion and professional advancement available to me.
While I am excited about retiring, I am going to miss being part of our team. It’s my hope that I’ll be able to maintain the friendships I’ve formed here for a long time to come.
In case I can be of assistance prior to or following my departure, please let me know. If I can assist in any way to ensure a smooth transfer to my successor, I would be delighted to do so.
Sincerely,
Signed (hard copy letter)
Norman, Jamie
Tenth Example of Retirement Letter
17 January 2023
Greg S. Jackson
Cyberdyne Systems
18144 El Camino Real,
Sunnyvale, CA
Respected Mrs. Duncan,
I am writing to inform you that I will be resigning from Cyberdyne Systems as of March 1, 2023. I’m grateful to have had this opportunity, and it was a difficult decision to make.
My development as a programmer and as a more seasoned member of the organization has been greatly assisted by your coaching.
I have been proud of Cyberdyne Systems’ ethics and success throughout my 25 years at the company. Starting as a mailroom clerk and currently serving as head programmer.
The portfolios of our clients have always been handled with the greatest care by my colleagues. It is our employees and services that have made Cyberdyne Systems the success it is today.
During my tenure as head of my division, I’ve increased our overall productivity by 800 percent, and I expect that trend to continue after I retire.
In light of the fact that the process of replacing me may take some time, I would like to offer my assistance in any way I can.
The greatest contender for this job is Troy Ledford, my current assistant.
Also, before I leave, I would be willing to teach any partners how to use the programmer I developed to track and manage the development of Skynet.
Over the next few months, I’ll be enjoying vacations with my wife as well as my granddaughter moving to college.
If Cyberdyne Systems has any openings for consultants, please let me know. It has been a pleasure working with you over the last 25 years. I appreciate your concern and care.
Sincerely,
Greg S, Jackson
Questions and Answers
1. What is a letter of retirement?
Retirement letters tell your supervisor you're retiring. This informs your employer that you're departing, like a letter. A resignation letter also requests retirement benefits.
Supervisors frequently receive retirement letters and verbal resignations. Before submitting your retirement letter, meet to discuss your plans. This letter will be filed with your start date, salary, and benefits.
2. Why should you include a letter of retirement?
Your retirement letter should explain why you're leaving. When you quit, your manager and HR department usually know. Regardless, a retirement letter might help you leave on a positive tone. It ensures they have the necessary papers.
In your retirement letter, you tell the firm your plans so they can find your replacement. You may need to stay in touch with your company after sending your retirement letter until a successor is identified.
3. What information ought to be in your retirement letter?
Format it like an official letter. Include your retirement plans and retirement-specific statistics. Date may be most essential.
In some circumstances, benefits depend on when you resign and retire. A date on the letter helps HR or senior management verify when you gave notice and how long.
In addition to your usual salutation, address your letter to your manager or supervisor.
The letter's body should include your retirement date and transition arrangements. Tell them whether you plan to help with the transition or train a new employee. You may have a three-month time limit.
Tell your employer your job title, how long you've worked there, and your biggest successes. Personalize your letter by expressing gratitude for your career and outlining your retirement intentions. Finally, include your contact info.
4. Must I provide notice?
Two-week notice isn't required. Your company may require it. Some state laws contain exceptions.
Check your contract, company handbook, or HR to determine your retirement notice. Resigning may change the policy.
Regardless of your company's policy, notification is standard. Entry-level or junior jobs can be let go so the corporation can replace them.
Middle managers, high-level personnel, and specialists may take months to replace. Two weeks' notice is a courtesy. Start planning months ahead.
You can finish all jobs at that period. Prepare transition documents for coworkers and your replacement.
5. What is the ideal retirement age?
Depends on finances, state, and retirement plan. The average American retires at 62. The average retirement age is 66, according to Gallup's 2021 Economy and Personal Finance Survey.
Remember:
Before the age of 59 1/2, withdrawals from pre-tax retirement accounts, such as 401(k)s and IRAs, are subject to a penalty.
Benefits from Social Security can be accessed as early as age 62.
Medicare isn't available to you till you're 65,
Depending on the year of your birth, your Full Retirement Age (FRA) will be between 66 and 67 years old.
If you haven't taken them already, your Social Security benefits increase by 8% annually between ages 6 and 77.