


A quick guide to formatting your text on INTΞGRITY
[06/20/2022 update] We have now implemented a powerful text editor, but you can still use markdown.
Markdown:
Headers
SYNTAX:
# This is a heading 1
## This is a heading 2
### This is a heading 3
#### This is a heading 4
RESULT:
This is a heading 1
This is a heading 2
This is a heading 3
This is a heading 4
Emphasis
SYNTAX:
**This text will be bold**
~~Strikethrough~~
*You **can** combine them*
RESULT:
This text will be italic
This text will be bold
You can combine them
Images
SYNTAX:

RESULT:
Videos
SYNTAX:
https://www.youtube.com/watch?v=7KXGZAEWzn0
RESULT:
Links
SYNTAX:
[Int3grity website](https://www.int3grity.com)
RESULT:
Tweets
SYNTAX:
https://twitter.com/samhickmann/status/1503800505864130561
RESULT:
Blockquotes
SYNTAX:
> Human beings face ever more complex and urgent problems, and their effectiveness in dealing with these problems is a matter that is critical to the stability and continued progress of society. \- Doug Engelbart, 1961
RESULT:
Human beings face ever more complex and urgent problems, and their effectiveness in dealing with these problems is a matter that is critical to the stability and continued progress of society. - Doug Engelbart, 1961
Inline code
SYNTAX:
Text inside `backticks` on a line will be formatted like code.
RESULT:
Text inside backticks on a line will be formatted like code.
Code blocks
SYNTAX:
'''js
function fancyAlert(arg) {
if(arg) {
$.facebox({div:'#foo'})
}
}
'''
RESULT:
function fancyAlert(arg) {
if(arg) {
$.facebox({div:'#foo'})
}
}
Maths
We support LaTex to typeset math. We recommend reading the full documentation on the official website
SYNTAX:
$$[x^n+y^n=z^n]$$
RESULT:
[x^n+y^n=z^n]
Tables
SYNTAX:
| header a | header b |
| ---- | ---- |
| row 1 col 1 | row 1 col 2 |
RESULT:
| header a | header b | header c |
|---|---|---|
| row 1 col 1 | row 1 col 2 | row 1 col 3 |
(Edited)
More on Web3 & Crypto

CyberPunkMetalHead
3 years ago
It's all about the ego with Terra 2.0.
UST depegs and LUNA crashes 99.999% in a fraction of the time it takes the Moon to orbit the Earth.
Fat Man, a Terra whistle-blower, promises to expose Do Kwon's dirty secrets and shady deals.

The Terra community has voted to relaunch Terra LUNA on a new blockchain. The Terra 2.0 Pheonix-1 blockchain went live on May 28, 2022, and people were airdropped the new LUNA, now called LUNA, while the old LUNA became LUNA Classic.
Does LUNA deserve another chance? To answer this, or at least start a conversation about the Terra 2.0 chain's advantages and limitations, we must assess its fundamentals, ideology, and long-term vision.
Whatever the result, our analysis must be thorough and ruthless. A failure of this magnitude cannot happen again, so we must magnify every potential breaking point by 10.
Will UST and LUNA holders be compensated in full?
The obvious. First, and arguably most important, is to restore previous UST and LUNA holders' bags.
Terra 2.0 has 1,000,000,000,000 tokens to distribute.
25% of a community pool
Holders of pre-attack LUNA: 35%
10% of aUST holders prior to attack
Holders of LUNA after an attack: 10%
UST holders as of the attack: 20%
Every LUNA and UST holder has been compensated according to the above proposal.
According to self-reported data, the new chain has 210.000.000 tokens and a $1.3bn marketcap. LUNC and UST alone lost $40bn. The new token must fill this gap. Since launch:
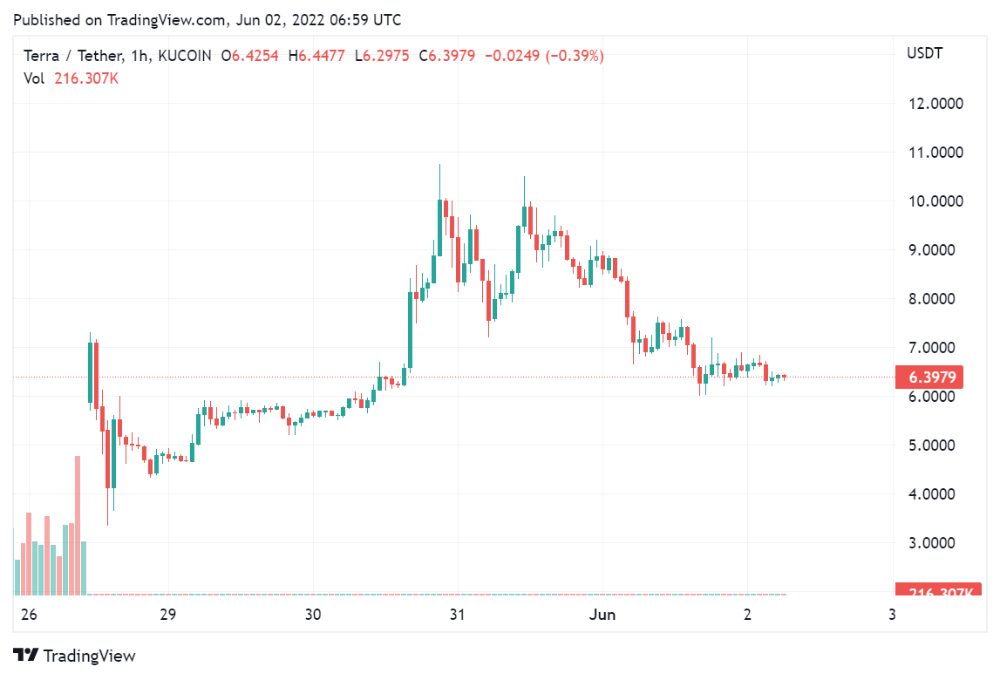
LUNA holders collectively own $1b worth of LUNA if we subtract the 25% community pool airdrop from the current market cap and assume airdropped LUNA was never sold.
At the current supply, the chain must grow 40 times to compensate holders. At the current supply, LUNA must reach $240.
LUNA needs a full-on Bull Market to make LUNC and UST holders whole.
Who knows if you'll be whole? From the time you bought to the amount and price, there are too many variables to determine if Terra can cover individual losses.
The above distribution doesn't consider individual cases. Terra didn't solve individual cases. It would have been huge.
What does LUNA offer in terms of value?
UST's marketcap peaked at $18bn, while LUNC's was $41bn. LUNC and UST drove the Terra chain's value.
After it was confirmed (again) that algorithmic stablecoins are bad, Terra 2.0 will no longer support them.
Algorithmic stablecoins contributed greatly to Terra's growth and value proposition. Terra 2.0 has no product without algorithmic stablecoins.
Terra 2.0 has an identity crisis because it has no actual product. It's like Volkswagen faking carbon emission results and then stopping car production.
A project that has already lost the trust of its users and nearly all of its value cannot survive without a clear and in-demand use case.
Do Kwon, how about him?
Oh, the Twitter-caller-poor? Who challenges crypto billionaires to break his LUNA chain? Who dissolved Terra Labs South Korea before depeg? Arrogant guy?
That's not a good image for LUNA, especially when making amends. I think he should step down and let a nicer person be Terra 2.0's frontman.
The verdict
Terra has a terrific community with an arrogant, unlikeable leader. The new LUNA chain must grow 40 times before it can start making up its losses, and even then, not everyone's losses will be covered.
I won't invest in Terra 2.0 or other algorithmic stablecoins in the near future. I won't be near any Do Kwon-related project within 100 miles. My opinion.
Can Terra 2.0 be saved? Comment below.

Marco Manoppo
3 years ago
Failures of DCG and Genesis
Don't sleep with your own sister.

70% of lottery winners go broke within five years. You've heard the last one. People who got rich quickly without setbacks and hard work often lose it all. My father said, "Easy money is easily lost," and a wealthy friend who owns a family office said, "The first generation makes it, the second generation spends it, and the third generation blows it."
This is evident. Corrupt politicians in developing countries live lavishly, buying their third wives' fifth Hermès bag and celebrating New Year's at The Brando Resort. A successful businessperson from humble beginnings is more conservative with money. More so if they're atom-based, not bit-based. They value money.
Crypto can "feel" easy. I have nothing against capital market investing. The global financial system is shady, but that's another topic. The problem started when those who took advantage of easy money started affecting other businesses. VCs did minimal due diligence on FTX because they needed deal flow and returns for their LPs. Lenders did minimum diligence and underwrote ludicrous loans to 3AC because they needed revenue.
Alameda (hence FTX) and 3AC made "easy money" Genesis and DCG aren't. Their businesses are more conventional, but they underestimated how "easy money" can hurt them.
Genesis has been the victim of easy money hubris and insolvency, losing $1 billion+ to 3AC and $200M to FTX. We discuss the implications for the broader crypto market.
Here are the quick takeaways:
Genesis is one of the largest and most notable crypto lenders and prime brokerage firms.
DCG and Genesis have done related party transactions, which can be done right but is a bad practice.
Genesis owes DCG $1.5 billion+.
If DCG unwinds Grayscale's GBTC, $9-10 billion in BTC will hit the market.
DCG will survive Genesis.
What happened?
Let's recap the FTX shenanigan from two weeks ago. Shenanigans! Delphi's tweet sums up the craziness. Genesis has $175M in FTX.
Cred's timeline: I hate bad crisis management. Yes, admitting their balance sheet hole right away might've sparked more panic, and there's no easy way to convey your trouble, but no one ever learns.
By November 23, rumors circulated online that the problem could affect Genesis' parent company, DCG. To address this, Barry Silbert, Founder, and CEO of DCG released a statement to shareholders.
A few things are confirmed thanks to this statement.
DCG owes $1.5 billion+ to Genesis.
$500M is due in 6 months, and the rest is due in 2032 (yes, that’s not a typo).
Unless Barry raises new cash, his last-ditch efforts to repay the money will likely push the crypto market lower.
Half a year of GBTC fees is approximately $100M.
They can pay $500M with GBTC.
With profits, sell another port.
Genesis has hired a restructuring adviser, indicating it is in trouble.
Rehypothecation
Every crypto problem in the past year seems to be rehypothecation between related parties, excessive leverage, hubris, and the removal of the money printer. The Bankless guys provided a chart showing 2021 crypto yield.

In June 2022, @DataFinnovation published a great investigation about 3AC and DCG. Here's a summary.
3AC borrowed BTC from Genesis and pledged it to create Grayscale's GBTC shares.
3AC uses GBTC to borrow more money from Genesis.
This lets 3AC leverage their capital.
3AC's strategy made sense because GBTC had a premium, creating "free money."
GBTC's discount and LUNA's implosion caused problems.
3AC lost its loan money in LUNA.
Margin called on 3ACs' GBTC collateral.
DCG bought GBTC to avoid a systemic collapse and a larger discount.
Genesis lost too much money because 3AC can't pay back its loan. DCG "saved" Genesis, but the FTX collapse hurt Genesis further, forcing DCG and Genesis to seek external funding.
bruh…
Learning Experience
Co-borrowing. Unnecessary rehypothecation. Extra space. Governance disaster. Greed, hubris. Crypto has repeatedly shown it can recreate traditional financial system disasters quickly. Working in crypto is one of the best ways to learn crazy financial tricks people will do for a quick buck much faster than if you dabble in traditional finance.
Moving Forward
I think the crypto industry needs to consider its future. This is especially true for professionals. I'm not trying to scare you. In 2018 and 2020, I had doubts. No doubts now. Detailing the crypto industry's potential outcomes helped me gain certainty and confidence in its future. This includes VCs' benefits and talking points during the bull market, as well as what would happen if government regulations became hostile, etc. Even if that happens, I'm certain. This is permanent. I may write a post about that soon.
Sincerely,
M.

Miguel Saldana
3 years ago
Crypto Inheritance's Catch-22
Security, privacy, and a strategy!

How to manage digital assets in worst-case scenarios is a perennial crypto concern. Since blockchain and bitcoin technology is very new, this hasn't been a major issue. Many early developers are still around, and many groups created around this technology are young and feel they have a lot of life remaining. This is why inheritance and estate planning in crypto should be handled promptly. As cryptocurrency's intrinsic worth rises, many people in the ecosystem are holding on to assets that might represent generational riches. With that much value, it's crucial to have a plan. Creating a solid plan entails several challenges.
the initial hesitation in coming up with a plan
The technical obstacles to ensuring the assets' security and privacy
the passing of assets from a deceased or incompetent person
Legal experts' lack of comprehension and/or understanding of how to handle and treat cryptocurrency.
This article highlights several challenges, a possible web3-native solution, and how to learn more.

The Challenge of Inheritance:
One of the biggest hurdles to inheritance planning is starting the conversation. As humans, we don't like to think about dying. Early adopters will experience crazy gains as cryptocurrencies become more popular. Creating a plan is crucial if you wish to pass on your riches to loved ones. Without a plan, the technical and legal issues I barely mentioned above would erode value by requiring costly legal fees and/or taxes, and you could lose everything if wallets and assets are not distributed appropriately (associated with the private keys). Raising awareness of the consequences of not having a plan should motivate people to make one.

Controlling Change:
Having an inheritance plan for your digital assets is crucial, but managing the guts and bolts poses a new set of difficulties. Privacy and security provided by maintaining your own wallet provide different issues than traditional finances and assets. Traditional finance is centralized (say a stock brokerage firm). You can assign another person to handle the transfer of your assets. In crypto, asset transfer is reimagined. One may suppose future transaction management is doable, but the user must consent, creating an impossible loop.
I passed away and must send a transaction to the person I intended to deliver it to.
I have to confirm or authorize the transaction, but I'm dead.
In crypto, scheduling a future transaction wouldn't function. To transfer the wallet and its contents, we'd need the private keys and/or seed phrase. Minimizing private key exposure is crucial to protecting your crypto from hackers, social engineering, and phishing. People have lost private keys after utilizing Life Hack-type tactics to secure them. People that break and hide their keys, lose them, or make them unreadable won't help with managing and/or transferring. This will require a derived solution.

Legal Challenges and Implications
Unlike routine cryptocurrency transfers and transactions, local laws may require special considerations. Even in the traditional world, estate/inheritance taxes, how assets will be split, and who executes the will must be considered. Many lawyers aren't crypto-savvy, which complicates the matter. There will be many hoops to jump through to safeguard your crypto and traditional assets and give them to loved ones.
Knowing RUFADAA/UFADAA, depending on your state, is vital for Americans. UFADAA offers executors and trustees access to online accounts (which crypto wallets would fall into). RUFADAA was changed to limit access to the executor to protect assets. RUFADAA outlines how digital assets are administered following death and incapacity in the US.
A Succession Solution
Having a will and talking about who would get what is the first step to having a solution, but using a Dad Mans Switch is a perfect tool for such unforeseen circumstances. As long as the switch's controller has control, nothing happens. Losing control of the switch initiates a state transition.
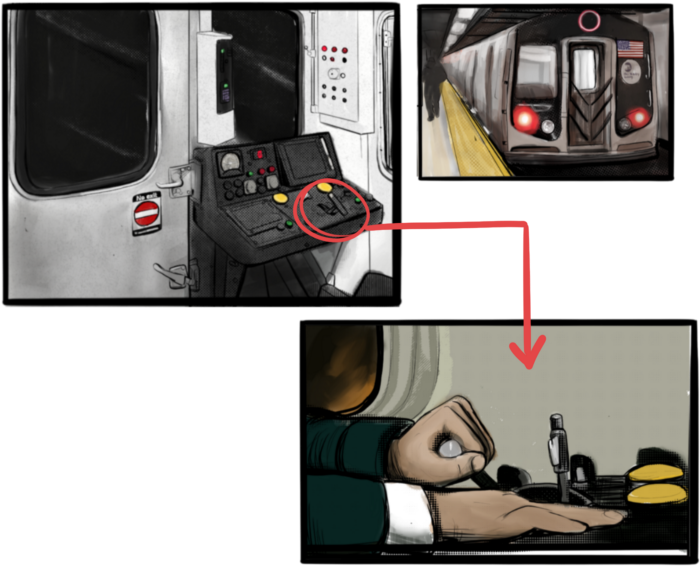
Subway or railway operations are examples. Modern control systems need the conductor to hold a switch to keep the train going. If they can't, the train stops.

Enter Sarcophagus
Sarcophagus is a decentralized dead man's switch built on Ethereum and Arweave. Sarcophagus allows actors to maintain control of their possessions even while physically unable to do so. Using a programmable dead man's switch and dual encryption, anything can be kept and passed on. This covers assets, secrets, seed phrases, and other use cases to provide authority and control back to the user and release trustworthy services from this work. Sarcophagus is built on a decentralized, transparent open source codebase. Sarcophagus is there if you're unprepared.

You might also like

Jumanne Rajabu Mtambalike
4 years ago
10 Years of Trying to Manage Time and Improve My Productivity.
I've spent the last 10 years of my career mastering time management. I've tried different approaches and followed multiple people and sources. My knowledge is summarized.
Great people, including entrepreneurs, master time management. I learned time management in college. I was studying Computer Science and Finance and leading Tanzanian students in Bangalore, India. I had 24 hours per day to do this and enjoy campus. I graduated and received several awards. I've learned to maximize my time. These tips and tools help me finish quickly.
Eisenhower-Box
I don't remember when I read the article. James Clear, one of my favorite bloggers, introduced me to the Eisenhower Box, which I've used for years. Eliminate waste to master time management. By grouping your activities by importance and urgency, the tool helps you prioritize what matters and drop what doesn't. If it's urgent, do it. Delegate if it's urgent but not necessary. If it's important but not urgent, reschedule it; otherwise, drop it. I integrated the tool with Trello to manage my daily tasks. Since 2007, I've done this.

James Clear's article mentions Eisenhower Box.
Essentialism rules
Greg McKeown's book Essentialism introduced me to disciplined pursuit of less. I once wrote about this. I wasn't sure what my career's real opportunities and distractions were. A non-essentialist thinks everything is essential; you want to be everything to everyone, and your life lacks satisfaction. Poor time management starts it all. Reading and applying this book will change your life.

Essential vs non-essential
Life Calendar
Most of us make corporate calendars. Peter Njonjo, founder of Twiga Foods, said he manages time by putting life activities in his core calendars. It includes family retreats, weddings, and other events. He joked that his wife always complained to him to avoid becoming a calendar item. It's key. "Time Masters" manages life's four burners, not just work and corporate life. There's no "work-life balance"; it's life.

Health, Family, Work, and Friends.
The Brutal No
In a culture where people want to look good, saying "NO" to a favor request seems rude. In reality, the crime is breaking a promise. "Time Masters" have mastered "NO". More "YES" means less time, and more "NO" means more time for tasks and priorities. Brutal No doesn't mean being mean to your coworkers; it means explaining kindly and professionally that you have other priorities.
To-Do vs. MITs
Most people are productive with a routine to-do list. You can't be effective by just checking boxes on a To-do list. When was the last time you completed all of your daily tasks? Never. You must replace the to-do list with Most Important Tasks (MITs). MITs allow you to focus on the most important tasks on your list. You feel progress and accomplishment when you finish these tasks. MITs don't include ad-hoc emails, meetings, etc.
Journal Mapped
Most people don't journal or plan their day in the developing South. I've learned to plan my day in my journal over time. I have multiple sections on one page: MITs (things I want to accomplish that day), Other Activities (stuff I can postpone), Life (health, faith, and family issues), and Pop-Ups (things that just pop up). I leave the next page blank for notes. I reflected on the blocks to identify areas to improve the next day. You will have bad days, but at least you'll realize it was due to poor time management.
Buy time/delegate
Time or money? When you make enough money, you lose time to make more. The smart buy "Time." I resisted buying other people's time for years. I regret not hiring an assistant sooner. Learn to buy time from others and pay for time-consuming tasks. Sometimes you think you're saving money by doing things yourself, but you're actually losing money.
This post is a summary. See the full post here.

Jenn Leach
3 years ago
This clever Instagram marketing technique increased my sales to $30,000 per month.
No Paid Ads Required

I had an online store. After a year of running the company alongside my 9-to-5, I made enough to resign.
That day was amazing.
This Instagram marketing plan helped the store succeed.
How did I increase my sales to five figures a month without using any paid advertising?
I used customer event marketing.
I'm not sure this term exists. I invented it to describe what I was doing.
Instagram word-of-mouth, fan engagement, and interaction drove sales.
If a customer liked or disliked a product, the buzz would drive attention to the store.
I used customer-based events to increase engagement and store sales.
Success!
Here are the weekly Instagram customer events I coordinated while running my business:
Be the Buyer Days
Flash sales
Mystery boxes
Be the Buyer Days: How do they work?
Be the Buyer Days are exactly that.
You choose a day to share stock selections with social media followers.
This is an easy approach to engaging customers and getting fans enthusiastic about new releases.
First, pick a handful of items you’re considering ordering. I’d usually pick around 3 for Be the Buyer Day.
Then I'd poll the crowd on Instagram to vote on their favorites.
This was before Instagram stories, polls, and all the other cool features Instagram offers today. I think using these tools now would make this event even better.
I'd ask customers their favorite back then.
The growing comments excited customers.
Then I'd declare the winner, acquire the products, and start selling it.
How do flash sales work?
I mostly ran flash sales.
You choose a limited number of itemsdd for a few-hour sale.
We wanted most sales to result in sold-out items.
When an item sells out, it contributes to the sensation of scarcity and can inspire customers to visit your store to buy a comparable product, join your email list, become a fan, etc.
We hoped they'd act quickly.
I'd hold flash deals twice a week, which generated scarcity and boosted sales.
The store had a few thousand Instagram followers when I started flash deals.
Each flash sale item would make $400 to $600.
$400 x 3= $1,200
That's $1,200 on social media!
Twice a week, you'll make roughly $10K a month from Instagram.
$1,200/day x 8 events/month=$9,600
Flash sales did great.
We held weekly flash deals and sent social media and email reminders. That’s about it!
How are mystery boxes put together?
All you do is package a box of store products and sell it as a mystery box on TikTok or retail websites.
A $100 mystery box would cost $30.
You're discounting high-value boxes.
This is a clever approach to get rid of excess inventory and makes customers happy.
It worked!
Be the Buyer Days, flash deals, and mystery boxes helped build my company without paid advertisements.
All companies can use customer event marketing. Involving customers and providing an engaging environment can boost sales.
Try it!

Sanjay Priyadarshi
3 years ago
Using Ruby code, a programmer created a $48,000,000,000 product that Elon Musk admired.
Unexpected Success

Shopify CEO and co-founder Tobias Lutke. Shopify is worth $48 billion.
World-renowned entrepreneur Tobi
Tobi never expected his first online snowboard business to become a multimillion-dollar software corporation.
Tobi founded Shopify to establish a 20-person company.
The publicly traded corporation employs over 10,000 people.
Here's Tobi Lutke's incredible story.
Elon Musk tweeted his admiration for the Shopify creator.
30-October-2019.
Musk praised Shopify founder Tobi Lutke on Twitter.
Happened:
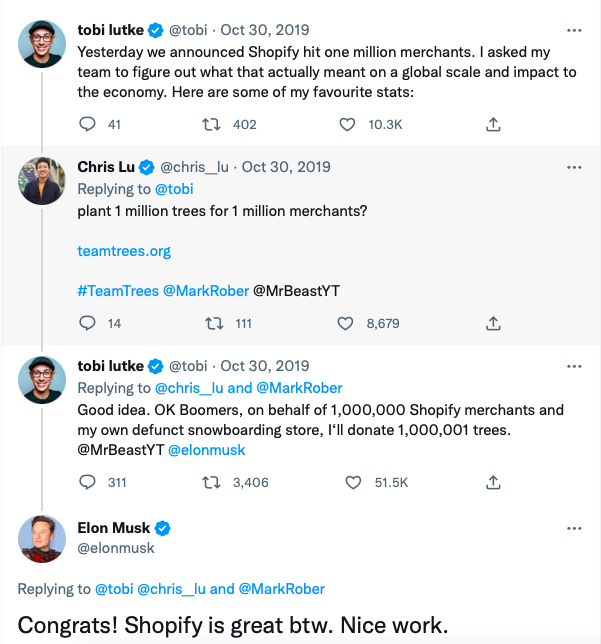
Explore this programmer's journey.
What difficulties did Tobi experience as a young child?
Germany raised Tobi.
Tobi's parents realized he was smart but had trouble learning as a toddler.
Tobi was learning disabled.
Tobi struggled with school tests.
Tobi's learning impairments were undiagnosed.
Tobi struggled to read as a dyslexic.
Tobi also found school boring.
Germany's curriculum didn't inspire Tobi's curiosity.
“The curriculum in Germany was taught like here are all the solutions you might find useful later in life, spending very little time talking about the problem…If I don’t understand the problem I’m trying to solve, it’s very hard for me to learn about a solution to a problem.”
Studying computer programming
After tenth grade, Tobi decided school wasn't for him and joined a German apprenticeship program.
This curriculum taught Tobi software engineering.
He was an apprentice in a small Siemens subsidiary team.
Tobi worked with rebellious Siemens employees.
Team members impressed Tobi.
Tobi joined the team for this reason.
Tobi was pleased to get paid to write programming all day.
His life could not have been better.
Devoted to snowboarding
Tobi loved snowboarding.
He drove 5 hours to ski at his folks' house.
His friends traveled to the US to snowboard when he was older.
However, the cheap dollar conversion rate led them to Canada.
2000.
Tobi originally decided to snowboard instead than ski.
Snowboarding captivated him in Canada.
On the trip to Canada, Tobi encounters his wife.
Tobi meets his wife Fiona McKean on his first Canadian ski trip.
They maintained in touch after the trip.
Fiona moved to Germany after graduating.
Tobi was a startup coder.
Fiona found work in Germany.
Her work included editing, writing, and academics.
“We lived together for 10 months and then she told me that she need to go back for the master's program.”
With Fiona, Tobi immigrated to Canada.
Fiona invites Tobi.
Tobi agreed to move to Canada.
Programming helped Tobi move in with his girlfriend.
Tobi was an excellent programmer, therefore what he did in Germany could be done anywhere.
He worked remotely for his German employer in Canada.
Tobi struggled with remote work.
Due to poor communication.
No slack, so he used email.
Programmers had trouble emailing.
Tobi's startup was developing a browser.
After the dot-com crash, individuals left that startup.
It ended.
Tobi didn't intend to work for any major corporations.
Tobi left his startup.
He believed he had important skills for any huge corporation.
He refused to join a huge corporation.
Because of Siemens.
Tobi learned to write professional code and about himself while working at Siemens in Germany.
Siemens culture was odd.
Employees were distrustful.
Siemens' rigorous dress code implies that the corporation doesn't trust employees' attire.
It wasn't Tobi's place.
“There was so much bad with it that it just felt wrong…20-year-old Tobi would not have a career there.”
Focused only on snowboarding
Tobi lived in Ottawa with his girlfriend.
Canada is frigid in winter.
Ottawa's winters last.
Almost half a year.
Tobi wanted to do something worthwhile now.
So he snowboarded.
Tobi began snowboarding seriously.
He sought every snowboarding knowledge.
He researched the greatest snowboarding gear first.
He created big spreadsheets for snowboard-making technologies.
Tobi grew interested in selling snowboards while researching.
He intended to sell snowboards online.
He had no choice but to start his own company.
A small local company offered Tobi a job.
Interested.
He must sign papers to join the local company.
He needed a work permit when he signed the documents.
Tobi had no work permit.
He was allowed to stay in Canada while applying for permanent residency.
“I wasn’t illegal in the country, but my state didn’t give me a work permit. I talked to a lawyer and he told me it’s going to take a while until I get a permanent residency.”
Tobi's lawyer told him he cannot get a work visa without permanent residence.
His lawyer said something else intriguing.
Tobis lawyer advised him to start a business.
Tobi declined this local company's job offer because of this.
Tobi considered opening an internet store with his technical skills.
He sold snowboards online.
“I was thinking of setting up an online store software because I figured that would exist and use it as a way to sell snowboards…make money while snowboarding and hopefully have a good life.”
What brought Tobi and his co-founder together, and how did he support Tobi?
Tobi lived with his girlfriend's parents.
In Ottawa, Tobi encounters Scott Lake.
Scott was Tobis girlfriend's family friend and worked for Tobi's future employer.
Scott and Tobi snowboarded.
Tobi pitched Scott his snowboard sales software idea.
Scott liked the idea.
They planned a business together.
“I was looking after the technology and Scott was dealing with the business side…It was Scott who ended up developing relationships with vendors and doing all the business set-up.”
Issues they ran into when attempting to launch their business online
Neither could afford a long-term lease.
That prompted their online business idea.
They would open a store.
Tobi anticipated opening an internet store in a week.
Tobi seeks open-source software.
Most existing software was pricey.
Tobi and Scott couldn't afford pricey software.
“In 2004, I was sitting in front of my computer absolutely stunned realising that we hadn’t figured out how to create software for online stores.”
They required software to:
to upload snowboard images to the website.
people to look up the types of snowboards that were offered on the website. There must be a search feature in the software.
Online users transmit payments, and the merchant must receive them.
notifying vendors of the recently received order.
No online selling software existed at the time.
Online credit card payments were difficult.
How did they advance the software while keeping expenses down?
Tobi and Scott needed money to start selling snowboards.
Tobi and Scott funded their firm with savings.
“We both put money into the company…I think the capital we had was around CAD 20,000(Canadian Dollars).”
Despite investing their savings.
They minimized costs.
They tried to conserve.
No office rental.
They worked in several coffee shops.
Tobi lived rent-free at his girlfriend's parents.
He installed software in coffee cafes.
How were the software issues handled?
Tobi found no online snowboard sales software.
Two choices remained:
Change your mind and try something else.
Use his programming expertise to produce something that will aid in the expansion of this company.
Tobi knew he was the sole programmer working on such a project from the start.
“I had this realisation that I’m going to be the only programmer who has ever worked on this, so I don’t have to choose something that lots of people know. I can choose just the best tool for the job…There is been this programming language called Ruby which I just absolutely loved ”
Ruby was open-source and only had Japanese documentation.
Latin is the source code.
Tobi used Ruby twice.
He assumed he could pick the tool this time.
Why not build with Ruby?
How did they find their first time operating a business?
Tobi writes applications in Ruby.
He wrote the initial software version in 2.5 months.
Tobi and Scott founded Snowdevil to sell snowboards.
Tobi coded for 16 hours a day.
His lifestyle was unhealthy.
He enjoyed pizza and coke.
“I would never recommend this to anyone, but at the time there was nothing more interesting to me in the world.”
Their initial purchase and encounter with it
Tobi worked in cafes then.
“I was working in a coffee shop at this time and I remember everything about that day…At some time, while I was writing the software, I had to type the email that the software would send to tell me about the order.”
Tobi recalls everything.
He checked the order on his laptop at the coffee shop.
Pennsylvanian ordered snowboard.
Tobi walked home and called Scott. Tobi told Scott their first order.
They loved the order.
How were people made aware about Snowdevil?
2004 was very different.
Tobi and Scott attempted simple website advertising.
Google AdWords was new.
Ad clicks cost 20 cents.
Online snowboard stores were scarce at the time.
Google ads propelled the snowdevil brand.
Snowdevil prospered.
They swiftly recouped their original investment in the snowboard business because to its high profit margin.
Tobi and Scott struggled with inventories.
“Snowboards had really good profit margins…Our biggest problem was keeping inventory and getting it back…We were out of stock all the time.”
Selling snowboards returned their investment and saved them money.
They did not appoint a business manager.
They accomplished everything alone.
Sales dipped in the spring, but something magical happened.
Spring sales plummeted.
They considered stocking different boards.
They naturally wanted to add boards and grow the business.
However, magic occurred.
Tobi coded and improved software while running Snowdevil.
He modified software constantly. He wanted speedier software.
He experimented to make the software more resilient.
Tobi received emails requesting the Snowdevil license.
They intended to create something similar.
“I didn’t stop programming, I was just like Ok now let me try things, let me make it faster and try different approaches…Increasingly I got people sending me emails and asking me If I would like to licence snowdevil to them. People wanted to start something similar.”
Software or skateboards, your choice
Scott and Tobi had to choose a hobby in 2005.
They might sell alternative boards or use software.
The software was a no-brainer from demand.
Daniel Weinand is invited to join Tobi's business.
Tobis German best friend is Daniel.
Tobi and Scott chose to use the software.
Tobi and Scott kept the software service.
Tobi called Daniel to invite him to Canada to collaborate.
Scott and Tobi had quit snowboarding until then.
How was Shopify launched, and whence did the name come from?
The three chose Shopify.
Named from two words.
First:
Shop
Final part:
Simplify
Shopify
Shopify's crew has always had one goal:
creating software that would make it simple and easy for people to launch online storefronts.
Launched Shopify after raising money for the first time.
Shopify began fundraising in 2005.
First, they borrowed from family and friends.
They needed roughly $200k to run the company efficiently.
$200k was a lot then.
When questioned why they require so much money. Tobi told them to trust him with their goals. The team raised seed money from family and friends.
Shopify.com has a landing page. A demo of their goal was on the landing page.
In 2006, Shopify had about 4,000 emails.
Shopify rented an Ottawa office.
“We sent a blast of emails…Some people signed up just to try it out, which was exciting.”
How things developed after Scott left the company
Shopify co-founder Scott Lake left in 2008.
Scott was CEO.
“He(Scott) realized at some point that where the software industry was going, most of the people who were the CEOs were actually the highly technical person on the founding team.”
Scott leaving the company worried Tobi.
Tobis worried about finding a new CEO.
To Tobi:
A great VC will have the network to identify the perfect CEO for your firm.
Tobi started visiting Silicon Valley to meet with venture capitalists to recruit a CEO.
Initially visiting Silicon Valley
Tobi came to Silicon Valley to start a 20-person company.
This company creates eCommerce store software.
Tobi never wanted a big corporation. He desired a fulfilling existence.
“I stayed in a hostel in the Bay Area. I had one roommate who was also a computer programmer. I bought a bicycle on Craiglist. I was there for a week, but ended up staying two and a half weeks.”
Tobi arrived unprepared.
When venture capitalists asked him business questions.
He answered few queries.
Tobi didn't comprehend VC meetings' terminology.
He wrote the terms down and looked them up.
Some were fascinated after he couldn't answer all these queries.
“I ended up getting the kind of term sheets people dream about…All the offers were conditional on moving our company to Silicon Valley.”
Canada received Tobi.
He wanted to consult his team before deciding. Shopify had five employees at the time.
2008.
A global recession greeted Tobi in Canada. The recession hurt the market.
His term sheets were useless.
The economic downturn in the world provided Shopify with a fantastic opportunity.
The global recession caused significant job losses.
Fired employees had several ideas.
They wanted online stores.
Entrepreneurship was desired. They wanted to quit work.
People took risks and tried new things during the global slump.
Shopify subscribers skyrocketed during the recession.
“In 2009, the company reached neutral cash flow for the first time…We were in a position to think about long-term investments, such as infrastructure projects.”
Then, Tobi Lutke became CEO.
How did Tobi perform as the company's CEO?
“I wasn’t good. My team was very patient with me, but I had a lot to learn…It’s a very subtle job.”
2009–2010.
Tobi limited the company's potential.
He deliberately restrained company growth.
Tobi had one costly problem:
Whether Shopify is a venture or a lifestyle business.
The company's annual revenue approached $1 million.
Tobi battled with the firm and himself despite good revenue.
His wife was supportive, but the responsibility was crushing him.
“It’s a crushing responsibility…People had families and kids…I just couldn’t believe what was going on…My father-in-law gave me money to cover the payroll and it was his life-saving.”
Throughout this trip, everyone supported Tobi.
They believed it.
$7 million in donations received
Tobi couldn't decide if this was a lifestyle or a business.
Shopify struggled with marketing then.
Later, Tobi tried 5 marketing methods.
He told himself that if any marketing method greatly increased their growth, he would call it a venture, otherwise a lifestyle.
The Shopify crew brainstormed and voted on marketing concepts.
Tested.
“Every single idea worked…We did Adwords, published a book on the concept, sponsored a podcast and all the ones we tracked worked.”
To Silicon Valley once more
Shopify marketing concepts worked once.
Tobi returned to Silicon Valley to pitch investors.
He raised $7 million, valuing Shopify at $25 million.
All investors had board seats.
“I find it very helpful…I always had a fantastic relationship with everyone who’s invested in my company…I told them straight that I am not going to pretend I know things, I want you to help me.”
Tobi developed skills via running Shopify.
Shopify had 20 employees.
Leaving his wife's parents' home
Tobi left his wife's parents in 2014.
Tobi had a child.
Shopify has 80,000 customers and 300 staff in 2013.
Public offering in 2015
Shopify investors went public in 2015.
Shopify powers 4.1 million e-Commerce sites.
Shopify stores are 65% US-based.
It is currently valued at $48 billion.