


Blockchain to solve growing privacy challenges
Most online activity is now public. Businesses collect, store, and use our personal data to improve sales and services.
In 2014, Uber executives and employees were accused of spying on customers using tools like maps. Another incident raised concerns about the use of ‘FaceApp'. The app was created by a small Russian company, and the photos can be used in unexpected ways. The Cambridge Analytica scandal exposed serious privacy issues. The whole incident raised questions about how governments and businesses should handle data. Modern technologies and practices also make it easier to link data to people.
As a result, governments and regulators have taken steps to protect user data. The General Data Protection Regulation (GDPR) was introduced by the EU to address data privacy issues. The law governs how businesses collect and process user data. The Data Protection Bill in India and the General Data Protection Law in Brazil are similar.
Despite the impact these regulations have made on data practices, a lot of distance is yet to cover.
Blockchain's solution
Blockchain may be able to address growing data privacy concerns. The technology protects our personal data by providing security and anonymity. The blockchain uses random strings of numbers called public and private keys to maintain privacy. These keys allow a person to be identified without revealing their identity. Blockchain may be able to ensure data privacy and security in this way. Let's dig deeper.
Financial transactions
Online payments require third-party services like PayPal or Google Pay. Using blockchain can eliminate the need to trust third parties. Users can send payments between peers using their public and private keys without providing personal information to a third-party application. Blockchain will also secure financial data.
Healthcare data
Blockchain technology can give patients more control over their data. There are benefits to doing so. Once the data is recorded on the ledger, patients can keep it secure and only allow authorized access. They can also only give the healthcare provider part of the information needed.
The major challenge
We tried to figure out how blockchain could help solve the growing data privacy issues. However, using blockchain to address privacy concerns has significant drawbacks. Blockchain is not designed for data privacy. A ‘distributed' ledger will be used to store the data. Another issue is the immutability of blockchain. Data entered into the ledger cannot be changed or deleted. It will be impossible to remove personal data from the ledger even if desired.
MIT's Enigma Project aims to solve this. Enigma's ‘Secret Network' allows nodes to process data without seeing it. Decentralized applications can use Secret Network to use encrypted data without revealing it.
Another startup, Oasis Labs, uses blockchain to address data privacy issues. They are working on a system that will allow businesses to protect their customers' data.
Conclusion
Blockchain technology is already being used. Several governments use blockchain to eliminate centralized servers and improve data security. In this information age, it is vital to safeguard our data. How blockchain can help us in this matter is still unknown as the world explores the technology.
More on Web3 & Crypto

Ben
3 years ago
The Real Value of Carbon Credit (Climate Coin Investment)
Disclaimer : This is not financial advice for any investment.

TL;DR
You might not have realized it, but as we move toward net zero carbon emissions, the globe is already at war.
According to the Paris Agreement of COP26, 64% of nations have already declared net zero, and the issue of carbon reduction has already become so important for businesses that it affects their ability to survive. Furthermore, the time when carbon emission standards will be defined and controlled on an individual basis is becoming closer.
Since 2017, the market for carbon credits has experienced extraordinary expansion as a result of widespread talks about carbon credits. The carbon credit market is predicted to expand much more once net zero is implemented and carbon emission rules inevitably tighten.

Hello! Ben here from Nonce Classic. Nonce Classic has recently confirmed the tremendous growth potential of the carbon credit market in the midst of a major trend towards the global goal of net zero (carbon emissions caused by humans — carbon reduction by humans = 0 ). Moreover, we too believed that the questions and issues the carbon credit market suffered from the last 30–40yrs could be perfectly answered through crypto technology and that is why we have added a carbon credit crypto project to the Nonce Classic portfolio. There have been many teams out there that have tried to solve environmental problems through crypto but very few that have measurable experience working in the carbon credit scene. Thus we have put in our efforts to find projects that are not crypto projects created for the sake of issuing tokens but projects that pragmatically use crypto technology to combat climate change by solving problems of the current carbon credit market. In that process, we came to hear of Climate Coin, a veritable carbon credit crypto project, and us Nonce Classic as an accelerator, have begun contributing to its growth and invested in its tokens. Starting with this article, we plan to publish a series of articles explaining why the carbon credit market is bullish, why we invested in Climate Coin, and what kind of project Climate Coin is specifically. In this first article let us understand the carbon credit market and look into its growth potential! Let’s begin :)
The Unavoidable Entry of the Net Zero Era
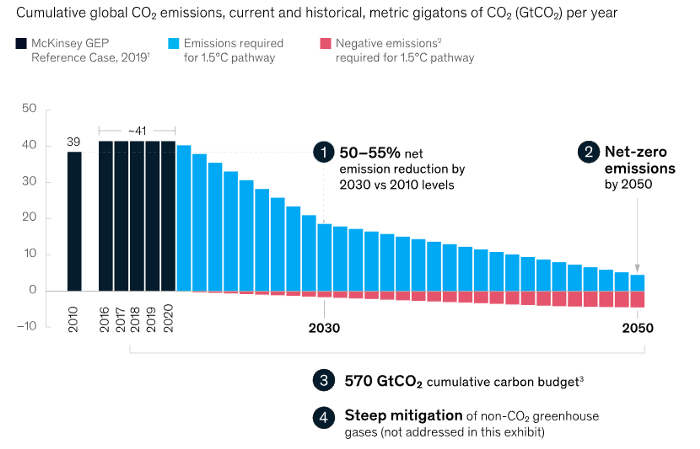
Net zero means... Human carbon emissions are balanced by carbon reduction efforts. A non-environmentalist may find it hard to accept that net zero is attainable by 2050. Global cooperation to save the earth is happening faster than we imagine.
In the Paris Agreement of COP26, concluded in Glasgow, UK on Oct. 31, 2021, nations pledged to reduce worldwide yearly greenhouse gas emissions by more than 50% by 2030 and attain net zero by 2050. Governments throughout the world have pledged net zero at the national level and are holding each other accountable by submitting Nationally Determined Contributions (NDC) every five years to assess implementation. 127 of 198 nations have declared net zero.
Each country's 1.5-degree reduction plans have led to carbon reduction obligations for companies. In places with the strictest environmental regulations, like the EU, companies often face bankruptcy because the cost of buying carbon credits to meet their carbon allowances exceeds their operating profits. In this day and age, minimizing carbon emissions and securing carbon credits are crucial.
Recent SEC actions on climate change may increase companies' concerns about reducing emissions. The SEC required all U.S. stock market companies to disclose their annual greenhouse gas emissions and climate change impact on March 21, 2022. The SEC prepared the proposed regulation through in-depth analysis and stakeholder input since last year. Three out of four SEC members agreed that it should pass without major changes. If the regulation passes, it will affect not only US companies, but also countless companies around the world, directly or indirectly.
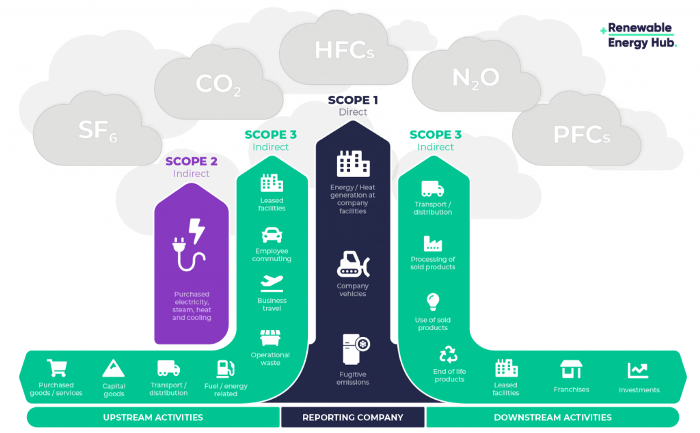
Even companies not listed on the U.S. stock market will be affected and, in most cases, required to disclose emissions. Companies listed on the U.S. stock market with significant greenhouse gas emissions or specific targets are subject to stricter emission standards (Scope 3) and disclosure obligations, which will magnify investigations into all related companies. Greenhouse gas emissions can be calculated three ways. Scope 1 measures carbon emissions from a company's facilities and transportation. Scope 2 measures carbon emissions from energy purchases. Scope 3 covers all indirect emissions from a company's value chains.
The SEC's proposed carbon emission disclosure mandate and regulations are one example of how carbon credit policies can cross borders and affect all parties. As such incidents will continue throughout the implementation of net zero, even companies that are not immediately obligated to disclose their carbon emissions must be prepared to respond to changes in carbon emission laws and policies.
Carbon reduction obligations will soon become individual. Individual consumption has increased dramatically with improved quality of life and convenience, despite national and corporate efforts to reduce carbon emissions. Since consumption is directly related to carbon emissions, increasing consumption increases carbon emissions. Countries around the world have agreed that to achieve net zero, carbon emissions must be reduced on an individual level. Solutions to individual carbon reduction are being actively discussed and studied under the term Personal Carbon Trading (PCT).
PCT is a system that allows individuals to trade carbon emission quotas in the form of carbon credits. Individuals who emit more carbon than their allotment can buy carbon credits from those who emit less. European cities with well-established carbon credit markets are preparing for net zero by conducting early carbon reduction prototype projects. The era of checking product labels for carbon footprints, choosing low-emissions transportation, and worrying about hot shower emissions is closer than we think.

The Market for Carbon Credits Is Expanding Fearfully
Compliance and voluntary carbon markets make up the carbon credit market.
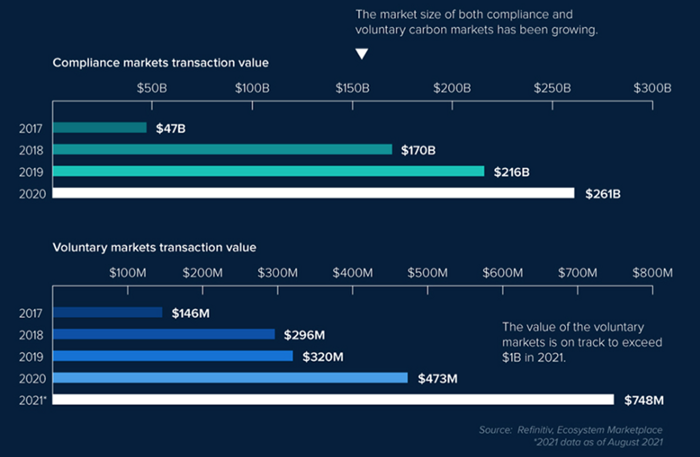
A Compliance Market enforces carbon emission allowances for actors. Companies in industries that previously emitted a lot of carbon are included in the mandatory carbon market, and each government receives carbon credits each year. If a company's emissions are less than the assigned cap and it has extra carbon credits, it can sell them to other companies that have larger emissions and require them (Cap and Trade). The annual number of free emission permits provided to companies is designed to decline, therefore companies' desire for carbon credits will increase. The compliance market's yearly trading volume will exceed $261B in 2020, five times its 2017 level.
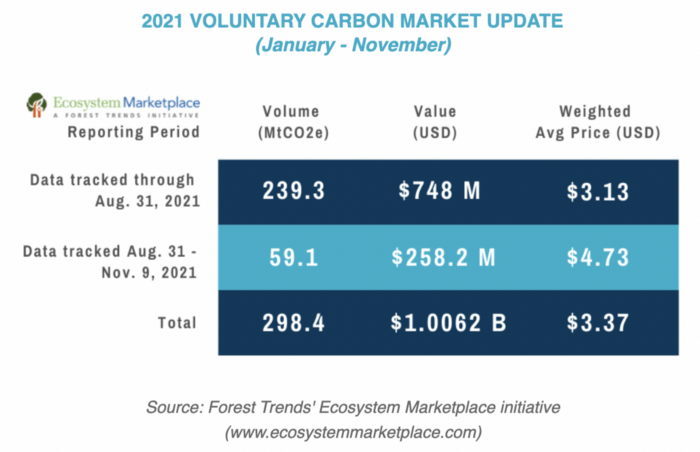
In the Voluntary Market, carbon reduction is voluntary and carbon credits are sold for personal reasons or to build market participants' eco-friendly reputations. Even if not in the compliance market, it is typical for a corporation to be obliged to offset its carbon emissions by acquiring voluntary carbon credits. When a company seeks government or company investment, it may be denied because it is not net zero. If a significant shareholder declares net zero, the companies below it must execute it. As the world moves toward ESG management, becoming an eco-friendly company is no longer a strategic choice to gain a competitive edge, but an important precaution to not fall behind. Due to this eco-friendly trend, the annual market volume of voluntary emission credits will approach $1B by November 2021. The voluntary credit market is anticipated to reach $5B to $50B by 2030. (TSCVM 2021 Report)
In conclusion
This article analyzed how net zero, a target promised by countries around the world to combat climate change, has brought governmental, corporate, and human changes. We discussed how these shifts will become more obvious as we approach net zero, and how the carbon credit market would increase exponentially in response. In the following piece, let's analyze the hurdles impeding the carbon credit market's growth, how the project we invested in tries to tackle these issues, and why we chose Climate Coin. Wait! Jim Skea, co-chair of the IPCC working group, said,
“It’s now or never, if we want to limit global warming to 1.5°C” — Jim Skea
Join nonceClassic’s community:
Telegram: https://t.me/non_stock
Youtube: https://www.youtube.com/channel/UCqeaLwkZbEfsX35xhnLU2VA
Twitter: @nonceclassic
Mail us : general@nonceclassic.org
:max_bytes(150000):strip_icc():gifv():format(webp)/reiff_headshot-5bfc2a60c9e77c00519a70bd.jpg)
Nathan Reiff
4 years ago
Howey Test and Cryptocurrencies: 'Every ICO Is a Security'
What Is the Howey Test?
To determine whether a transaction qualifies as a "investment contract" and thus qualifies as a security, the Howey Test refers to the U.S. Supreme Court cass: the Securities Act of 1933 and the Securities Exchange Act of 1934. According to the Howey Test, an investment contract exists when "money is invested in a common enterprise with a reasonable expectation of profits from others' efforts."
The test applies to any contract, scheme, or transaction. The Howey Test helps investors and project backers understand blockchain and digital currency projects. ICOs and certain cryptocurrencies may be found to be "investment contracts" under the test.
Understanding the Howey Test
The Howey Test comes from the 1946 Supreme Court case SEC v. W.J. Howey Co. The Howey Company sold citrus groves to Florida buyers who leased them back to Howey. The company would maintain the groves and sell the fruit for the owners. Both parties benefited. Most buyers had no farming experience and were not required to farm the land.
The SEC intervened because Howey failed to register the transactions. The court ruled that the leaseback agreements were investment contracts.
This established four criteria for determining an investment contract. Investing contract:
- An investment of money
- n a common enterprise
- With the expectation of profit
- To be derived from the efforts of others
In the case of Howey, the buyers saw the transactions as valuable because others provided the labor and expertise. An income stream was obtained by only investing capital. As a result of the Howey Test, the transaction had to be registered with the SEC.
Howey Test and Cryptocurrencies
Bitcoin is notoriously difficult to categorize. Decentralized, they evade regulation in many ways. Regardless, the SEC is looking into digital assets and determining when their sale qualifies as an investment contract.
The SEC claims that selling digital assets meets the "investment of money" test because fiat money or other digital assets are being exchanged. Like the "common enterprise" test.
Whether a digital asset qualifies as an investment contract depends on whether there is a "expectation of profit from others' efforts."
For example, buyers of digital assets may be relying on others' efforts if they expect the project's backers to build and maintain the digital network, rather than a dispersed community of unaffiliated users. Also, if the project's backers create scarcity by burning tokens, the test is met. Another way the "efforts of others" test is met is if the project's backers continue to act in a managerial role.
These are just a few examples given by the SEC. If a project's success is dependent on ongoing support from backers, the buyer of the digital asset is likely relying on "others' efforts."
Special Considerations
If the SEC determines a cryptocurrency token is a security, many issues arise. It means the SEC can decide whether a token can be sold to US investors and forces the project to register.
In 2017, the SEC ruled that selling DAO tokens for Ether violated federal securities laws. Instead of enforcing securities laws, the SEC issued a warning to the cryptocurrency industry.
Due to the Howey Test, most ICOs today are likely inaccessible to US investors. After a year of ICOs, then-SEC Chair Jay Clayton declared them all securities.
SEC Chairman Gensler Agrees With Predecessor: 'Every ICO Is a Security'
Howey Test FAQs
How Do You Determine If Something Is a Security?
The Howey Test determines whether certain transactions are "investment contracts." Securities are transactions that qualify as "investment contracts" under the Securities Act of 1933 and the Securities Exchange Act of 1934.
The Howey Test looks for a "investment of money in a common enterprise with a reasonable expectation of profits from others' efforts." If so, the Securities Act of 1933 and the Securities Exchange Act of 1934 require disclosure and registration.
Why Is Bitcoin Not a Security?
Former SEC Chair Jay Clayton clarified in June 2018 that bitcoin is not a security: "Cryptocurrencies: Replace the dollar, euro, and yen with bitcoin. That type of currency is not a security," said Clayton.
Bitcoin, which has never sought public funding to develop its technology, fails the SEC's Howey Test. However, according to Clayton, ICO tokens are securities.
A Security Defined by the SEC
In the public and private markets, securities are fungible and tradeable financial instruments. The SEC regulates public securities sales.
The Supreme Court defined a security offering in SEC v. W.J. Howey Co. In its judgment, the court defines a security using four criteria:
- An investment contract's existence
- The formation of a common enterprise
- The issuer's profit promise
- Third-party promotion of the offering
Read original post.

Chris
3 years ago
What the World's Most Intelligent Investor Recently Said About Crypto
Cryptoshit. This thing is crazy to buy.

Charlie Munger is revered and powerful in finance.
Munger, vice chairman of Berkshire Hathaway, is noted for his wit, no-nonsense attitude to investment, and ability to spot promising firms and markets.
Munger's crypto views have upset some despite his reputation as a straight shooter.
“There’s only one correct answer for intelligent people, just totally avoid all the people that are promoting it.” — Charlie Munger
The Munger Interview on CNBC (4:48 secs)
This Monday, CNBC co-anchor Rebecca Quick interviewed Munger and brought up his 2007 statement, "I'm not allowed to have an opinion on this subject until I can present the arguments against my viewpoint better than the folks who are supporting it."
Great investing and life advice!
If you can't explain the opposing reasons, you're not informed enough to have an opinion.
In today's world, it's important to grasp both sides of a debate before supporting one.
Rebecca inquired:
Does your Wall Street Journal article on banning cryptocurrency apply? If so, would you like to present the counterarguments?
Mungers reply:
I don't see any viable counterarguments. I think my opponents are idiots, hence there is no sensible argument against my position.
Consider his words.
Do you believe Munger has studied both sides?
He said, "I assume my opponents are idiots, thus there is no sensible argument against my position."
This is worrisome, especially from a guy who once encouraged studying both sides before forming an opinion.
Munger said:
National currencies have benefitted humanity more than almost anything else.
Hang on, I think we located the perpetrator.
Munger thinks crypto will replace currencies.
False.
I doubt he studied cryptocurrencies because the name is deceptive.
He misread a headline as a Dollar destroyer.
Cryptocurrencies are speculations.
Like Tesla, Amazon, Apple, Google, Microsoft, etc.
Crypto won't replace dollars.
In the interview with CNBC, Munger continued:
“I’m not proud of my country for allowing this crap, what I call the cryptoshit. It’s worthless, it’s no good, it’s crazy, it’ll do nothing but harm, it’s anti-social to allow it.” — Charlie Munger
Not entirely inaccurate.
Daily cryptos are established solely to pump and dump regular investors.
Let's get into Munger's crypto aversion.
Rat poison is bitcoin.
Munger famously dubbed Bitcoin rat poison and a speculative bubble that would implode.
Partially.
But the bubble broke. Since 2021, the market has fallen.
Scam currencies and NFTs are being eliminated, which I like.
Whoa.
Why does Munger doubt crypto?
Mungers thinks cryptocurrencies has no intrinsic value.
He worries about crypto fraud and money laundering.
Both are valid issues.
Yet grouping crypto is intellectually dishonest.
Ethereum, Bitcoin, Solana, Chainlink, Flow, and Dogecoin have different purposes and values (not saying they’re all good investments).
Fraudsters who hurt innocents will be punished.
Therefore, complaining is useless.
Why not stop it? Repair rather than complain.
Regrettably, individuals today don't offer solutions.
Blind Areas for Mungers
As with everyone, Mungers' bitcoin views may be impacted by his biases and experiences.
OK.
But Munger has always advocated classic value investing and may be wary of investing in an asset outside his expertise.
Mungers' banking and insurance investments may influence his bitcoin views.
Could a coworker or acquaintance have told him crypto is bad and goes against traditional finance?
Right?
Takeaways
Do you respect Charlie Mungers?
Yes and no, like any investor or individual.
To understand Mungers' bitcoin beliefs, you must be critical.
Mungers is a successful investor, but his views about bitcoin should be considered alongside other viewpoints.
Munger’s success as an investor has made him an influencer in the space.
Influence gives power.
He controls people's thoughts.
Munger's ok. He will always be heard.
I'll do so cautiously.
You might also like

nft now
4 years ago
Instagram NFTs Are Here… How does this affect artists?
Instagram (IG) is officially joining NFT. With the debut of new in-app NFT functionalities, influential producers can interact with blockchain tech on the social media platform.
Meta unveiled intentions for an Instagram NFT marketplace in March, but these latest capabilities focus more on content sharing than commerce. And why shouldn’t they? IG's entry into the NFT market is overdue, given that Twitter and Discord are NFT hotspots.
The NFT marketplace/Web3 social media race has continued to expand, with the expected Coinbase NFT Beta now live and blazing a trail through the NFT ecosystem.
IG's focus is on visual art. It's unlike any NFT marketplace or platform. IG NFTs and artists: what's the deal? Let’s take a look.
What are Instagram’s NFT features anyways?
As said, not everyone has Instagram's new features. 16 artists, NFT makers, and collectors can now post NFTs on IG by integrating third-party digital wallets (like Rainbow or MetaMask) in-app. IG doesn't charge to publish or share digital collectibles.
NFTs displayed on the app have a "shimmer" aesthetic effect. NFT posts also have a "digital collectable" badge that lists metadata such as the creator and/or owner, the platform it was created on, a brief description, and a blockchain identification.
Meta's social media NFTs have launched on Instagram, but the company is also preparing to roll out digital collectibles on Facebook, with more on the way for IG. Currently, only Ethereum and Polygon are supported, but Flow and Solana will be added soon.
How will artists use these new features?
Artists are publishing NFTs they developed or own on IG by linking third-party digital wallets. These features have no NFT trading aspects built-in, but are aimed to let authors share NFTs with IG audiences.
Creators, like IG-native aerial/street photographer Natalie Amrossi (@misshattan), are discovering novel uses for IG NFTs.
Amrossi chose to not only upload his own NFTs but also encourage other artists in the field. "That's the beauty of connecting your wallet and sharing NFTs. It's not just what you make, but also what you accumulate."
Amrossi has been producing and posting Instagram art for years. With IG's NFT features, she can understand Instagram's importance in supporting artists.
Web2 offered Amrossi the tools to become an artist and make a life. "Before 'influencer' existed, I was just making art. Instagram helped me reach so many individuals and brands, giving me a living.
Even artists without millions of viewers are encouraged to share NFTs on IG. Wilson, a relatively new name in the NFT space, seems to have already gone above and beyond the scope of these new IG features. By releasing "Losing My Mind" via IG NFT posts, she has evaded the lack of IG NFT commerce by using her network to market her multi-piece collection.
"'Losing My Mind' is a long-running photo series. Wilson was preparing to release it as NFTs before IG approached him, so it was a perfect match.
Wilson says the series is about Black feminine figures and media depiction. Respectable effort, given POC artists have been underrepresented in NFT so far.
“Over the past year, I've had mental health concerns that made my emotions so severe it was impossible to function in daily life, therefore that prompted this photo series. Every Wednesday and Friday for three weeks, I'll release a new Meta photo for sale.
Wilson hopes these new IG capabilities will help develop a connection between the NFT community and other internet subcultures that thrive on Instagram.
“NFTs can look scary as an outsider, but seeing them on your daily IG feed makes it less foreign,” adds Wilson. I think Instagram might become a hub for NFT aficionados, making them more accessible to artists and collectors.
What does it all mean for the NFT space?
Meta's NFT and metaverse activities will continue to impact Instagram's NFT ecosystem. Many think it will be for the better, as IG NFT frauds are another problem hurting the NFT industry.
IG's new NFT features seem similar to Twitter's PFP NFT verifications, but Instagram's tools should help cut down on scams as users can now verify the creation and ownership of whole NFT collections included in IG posts.
Given the number of visual artists and NFT creators on IG, it might become another hub for NFT fans, as Wilson noted. If this happens, it raises questions about Instagram success. Will artists be incentivized to distribute NFTs? Or will those with a large fanbase dominate?
Elise Swopes (@swopes) believes these new features should benefit smaller artists. Swopes was one of the first profiles placed to Instagram's original suggested user list in 2012.
Swopes says she wants IG to be a magnet for discovery and understands the value of NFT artists and producers.
"I'd love to see IG become a focus of discovery for everyone, not just the Beeples and Apes and PFPs. That's terrific for them, but [IG NFT features] are more about using new technology to promote emerging artists, Swopes added.
“Especially music artists. It's everywhere. Dancers, writers, painters, sculptors, musicians. My element isn't just for digital artists; it can be anything. I'm delighted to witness people's creativity."
Swopes, Wilson, and Amrossi all believe IG's new features can help smaller artists. It remains to be seen how these new features will effect the NFT ecosystem once unlocked for the rest of the IG NFT community, but we will likely see more social media NFT integrations in the months and years ahead.
Read the full article here

Aaron Dinin, PhD
3 years ago
I put my faith in a billionaire, and he destroyed my business.
How did his money blind me?

Like most fledgling entrepreneurs, I wanted a mentor. I met as many nearby folks with "entrepreneur" in their LinkedIn biographies for coffee.
These meetings taught me a lot, and I'd suggest them to any new creator. Attention! Meeting with many experienced entrepreneurs means getting contradictory advice. One entrepreneur will tell you to do X, then the next one you talk to may tell you to do Y, which are sometimes opposites. You'll have to chose which suggestion to take after the chats.
I experienced this. Same afternoon, I had two coffee meetings with experienced entrepreneurs. The first meeting was with a billionaire entrepreneur who took his company public.
I met him in a swanky hotel lobby and ordered a drink I didn't pay for. As a fledgling entrepreneur, money was scarce.
During the meeting, I demoed the software I'd built, he liked it, and we spent the hour discussing what features would make it a success. By the end of the meeting, he requested I include a killer feature we both agreed would attract buyers. The feature was complex and would require some time. The billionaire I was sipping coffee with in a beautiful hotel lobby insisted people would love it, and that got me enthusiastic.
The second meeting was with a young entrepreneur who had recently raised a small amount of investment and looked as eager to pitch me as I was to pitch him. I forgot his name. I mostly recall meeting him in a filthy coffee shop in a bad section of town and buying his pricey cappuccino. Water for me.
After his pitch, I demoed my app. When I was done, he barely noticed. He questioned my customer acquisition plan. Who was my client? What did they offer? What was my plan? Etc. No decent answers.
After our meeting, he insisted I spend more time learning my market and selling. He ignored my questions about features. Don't worry about features, he said. Customers will request features. First, find them.
Putting your faith in results over relevance
Problems plagued my afternoon. I met with two entrepreneurs who gave me differing advice about how to proceed, and I had to decide which to pursue. I couldn't decide.
Ultimately, I followed the advice of the billionaire.
Obviously.
Who wouldn’t? That was the guy who clearly knew more.
A few months later, I constructed the feature the billionaire said people would line up for.
The new feature was unpopular. I couldn't even get the billionaire to answer an email showing him what I'd done. He disappeared.
Within a few months, I shut down the company, wasting all the time and effort I'd invested into constructing the killer feature the billionaire said I required.
Would follow the struggling entrepreneur's advice have saved my company? It would have saved me time in retrospect. Potential consumers would have told me they didn't want what I was producing, and I could have shut down the company sooner or built something they did want. Both outcomes would have been better.
Now I know, but not then. I favored achievement above relevance.
Success vs. relevance
The millionaire gave me advice on building a large, successful public firm. A successful public firm is different from a startup. Priorities change in the last phase of business building, which few entrepreneurs reach. He gave wonderful advice to founders trying to double their stock values in two years, but it wasn't beneficial for me.
The other failing entrepreneur had relevant, recent experience. He'd recently been in my shoes. We still had lots of problems. He may not have achieved huge success, but he had valuable advice on how to pass the closest hurdle.
The money blinded me at the moment. Not alone So much of company success is defined by money valuations, fundraising, exits, etc., so entrepreneurs easily fall into this trap. Money chatter obscures the value of knowledge.
Don't base startup advice on a person's income. Focus on what and when the person has learned. Relevance to you and your goals is more important than a person's accomplishments when considering advice.

Muthinja
3 years ago
Why don't you relaunch my startup projects?
Open to ideas or acquisitions
Failure is an unavoidable aspect of life, yet many recoil at the word.

I've worked on unrelated startup projects. This is a list of products I developed (often as the tech lead or co-founder) and why they failed to launch.
Chess Bet (Betting)
As a chess player who plays 5 games a day and has an ELO rating of 2100, I tried to design a chess engine to rival stockfish and Houdini.
While constructing my chess engine, my cofounder asked me about building a p2p chess betting app. Chess Bet. There couldn't be a better time.
Two people in different locations could play a staked game. The winner got 90% of the bet and we got 10%. The business strategy was clear, but our mini-launch was unusual.
People started employing the same cheat engines I mentioned, causing user churn and defaming our product.
It was the first programming problem I couldn't solve after building a cheat detection system based on player move strengths and prior games. Chess.com, the most famous online chess software, still suffers from this.
We decided to pivot because we needed an expensive betting license.
We relaunched as Chess MVP after deciding to focus on chess learning. A platform for teachers to create chess puzzles and teach content. Several chess students used our product, but the target market was too tiny.
We chose to quit rather than persevere or pivot.
BodaCare (Insure Tech)
‘BodaBoda’ in Swahili means Motorcycle. My Dad approached me in 2019 (when I was working for a health tech business) about establishing an Insurtech/fintech solution for motorbike riders to pay for insurance using SNPL.
We teamed up with an underwriter to market motorcycle insurance. Once they had enough premiums, they'd get an insurance sticker in the mail. We made it better by splitting the cover in two, making it more reasonable for motorcyclists struggling with lump-sum premiums.
Lack of capital and changing customer behavior forced us to close, with 100 motorcyclists paying 0.5 USD every day. Our unit econ didn't make sense, and CAC and retention capital only dug us deeper.
Circle (Social Networking)
Having learned from both product failures, I began to understand what worked and what didn't. While reading through Instagram, an idea struck me.
Suppose social media weren't virtual.
Imagine meeting someone on your way home. Like-minded person
People were excited about social occasions after covid restrictions were eased. Anything to escape. I just built a university student-popular experiences startup. Again, there couldn't be a better time.
I started the Android app. I launched it on Google Beta and oh my! 200 people joined in two days.
It works by signaling if people are in a given place and allowing users to IM in hopes of meeting up in near real-time. Playstore couldn't deploy the app despite its success in beta for unknown reasons. I appealed unsuccessfully.
My infrastructure quickly lost users because I lacked funding.
In conclusion
This essay contains many failures, some of which might have been avoided and others not, but they were crucial learning points in my startup path.
If you liked any idea, I have the source code on Github.
Happy reading until then!