




More on Technology
James Brockbank
2 years ago
Canonical URLs for Beginners
Canonicalization and canonical URLs are essential for SEO, and improper implementation can negatively impact your site's performance.
Canonical tags were introduced in 2009 to help webmasters with duplicate or similar content on multiple URLs.
To use canonical tags properly, you must understand their purpose, operation, and implementation.
Canonical URLs and Tags
Canonical tags tell search engines that a certain URL is a page's master copy. They specify a page's canonical URL. Webmasters can avoid duplicate content by linking to the "canonical" or "preferred" version of a page.
How are canonical tags and URLs different? Can these be specified differently?
Tags
Canonical tags are found in an HTML page's head></head> section.
<link rel="canonical" href="https://www.website.com/page/" />These can be self-referencing or reference another page's URL to consolidate signals.
Canonical tags and URLs are often used interchangeably, which is incorrect.
The rel="canonical" tag is the most common way to set canonical URLs, but it's not the only way.
Canonical URLs
What's a canonical link? Canonical link is the'master' URL for duplicate pages.
In Google's own words:
A canonical URL is the page Google thinks is most representative of duplicate pages on your site.
— Google Search Console Help
You can indicate your preferred canonical URL. For various reasons, Google may choose a different page than you.
When set correctly, the canonical URL is usually your specified URL.
Canonical URLs determine which page will be shown in search results (unless a duplicate is explicitly better for a user, like a mobile version).
Canonical URLs can be on different domains.
Other ways to specify canonical URLs
Canonical tags are the most common way to specify a canonical URL.
You can also set canonicals by:
Setting the HTTP header rel=canonical.
All pages listed in a sitemap are suggested as canonicals, but Google decides which pages are duplicates.
Redirects 301.
Google recommends these methods, but they aren't all appropriate for every situation, as we'll see below. Each has its own recommended uses.
Setting canonical URLs isn't required; if you don't, Google will use other signals to determine the best page version.
To control how your site appears in search engines and to avoid duplicate content issues, you should use canonicalization effectively.
Why Duplicate Content Exists
Before we discuss why you should use canonical URLs and how to specify them in popular CMSs, we must first explain why duplicate content exists. Nobody intentionally duplicates website content.
Content management systems create multiple URLs when you launch a page, have indexable versions of your site, or use dynamic URLs.
Assume the following URLs display the same content to a user:
A search engine sees eight duplicate pages, not one.
URLs #1 and #2: the CMS saves product URLs with and without the category name.
#3, #4, and #5 result from the site being accessible via HTTP, HTTPS, www, and non-www.
#6 is a subdomain mobile-friendly URL.
URL #7 lacks URL #2's trailing slash.
URL #8 uses a capital "A" instead of a lowercase one.
Duplicate content may also exist in URLs like:
https://www.website.com
https://www.website.com/index.php
Duplicate content is easy to create.
Canonical URLs help search engines identify different page variations as a single URL on many sites.
SEO Canonical URLs
Canonical URLs help you manage duplicate content that could affect site performance.
Canonical URLs are a technical SEO focus area for many reasons.
Specify URL for search results
When you set a canonical URL, you tell Google which page version to display.
Which would you click?
https://www.domain.com/page-1/
https://www.domain.com/index.php?id=2
First, probably.
Canonicals tell search engines which URL to rank.
Consolidate link signals on similar pages
When you have duplicate or nearly identical pages on your site, the URLs may get external links.
Canonical URLs consolidate multiple pages' link signals into a single URL.
This helps your site rank because signals from multiple URLs are consolidated into one.
Syndication management
Content is often syndicated to reach new audiences.
Canonical URLs consolidate ranking signals to prevent duplicate pages from ranking and ensure the original content ranks.
Avoid Googlebot duplicate page crawling
Canonical URLs ensure that Googlebot crawls your new pages rather than duplicated versions of the same one across mobile and desktop versions, for example.
Crawl budgets aren't an issue for most sites unless they have 100,000+ pages.
How to Correctly Implement the rel=canonical Tag
Using the header tag rel="canonical" is the most common way to specify canonical URLs.
Adding tags and HTML code may seem daunting if you're not a developer, but most CMS platforms allow canonicals out-of-the-box.
These URLs each have one product.
How to Correctly Implement a rel="canonical" HTTP Header
A rel="canonical" HTTP header can replace canonical tags.
This is how to implement a canonical URL for PDFs or non-HTML documents.
You can specify a canonical URL in your site's.htaccess file using the code below.
<Files "file-to-canonicalize.pdf"> Header add Link "< http://www.website.com/canonical-page/>; rel=\"canonical\"" </Files>301 redirects for canonical URLs
Google says 301 redirects can specify canonical URLs.
Only the canonical URL will exist if you use 301 redirects. This will redirect duplicates.
This is the best way to fix duplicate content across:
HTTPS and HTTP
Non-WWW and WWW
Trailing-Slash and Non-Trailing Slash URLs
On a single page, you should use canonical tags unless you can confidently delete and redirect the page.
Sitemaps' canonical URLs
Google assumes sitemap URLs are canonical, so don't include non-canonical URLs.
This does not guarantee canonical URLs, but is a best practice for sitemaps.
Best-practice Canonical Tag
Once you understand a few simple best practices for canonical tags, spotting and cleaning up duplicate content becomes much easier.
Always include:
One canonical URL per page
If you specify multiple canonical URLs per page, they will likely be ignored.
Correct Domain Protocol
If your site uses HTTPS, use this as the canonical URL. It's easy to reference the wrong protocol, so check for it to catch it early.
Trailing slash or non-trailing slash URLs
Be sure to include trailing slashes in your canonical URL if your site uses them.
Specify URLs other than WWW
Search engines see non-WWW and WWW URLs as duplicate pages, so use the correct one.
Absolute URLs
To ensure proper interpretation, canonical tags should use absolute URLs.
So use:
<link rel="canonical" href="https://www.website.com/page-a/" />And not:
<link rel="canonical" href="/page-a/" />If not canonicalizing, use self-referential canonical URLs.
When a page isn't canonicalizing to another URL, use self-referencing canonical URLs.
Canonical tags refer to themselves here.
Common Canonical Tags Mistakes
Here are some common canonical tag mistakes.
301 Canonicalization
Set the canonical URL as the redirect target, not a redirected URL.
Incorrect Domain Canonicalization
If your site uses HTTPS, don't set canonical URLs to HTTP.
Irrelevant Canonicalization
Canonicalize URLs to duplicate or near-identical content only.
SEOs sometimes try to pass link signals via canonical tags from unrelated content to increase rank. This isn't how canonicalization should be used and should be avoided.
Multiple Canonical URLs
Only use one canonical tag or URL per page; otherwise, they may all be ignored.
When overriding defaults in some CMSs, you may accidentally include two canonical tags in your page's <head>.
Pagination vs. Canonicalization
Incorrect pagination can cause duplicate content. Canonicalizing URLs to the first page isn't always the best solution.
Canonicalize to a 'view all' page.
How to Audit Canonical Tags (and Fix Issues)
Audit your site's canonical tags to find canonicalization issues.
SEMrush Site Audit can help. You'll find canonical tag checks in your website's site audit report.
Let's examine these issues and their solutions.
No Canonical Tag on AMP
Site Audit will flag AMP pages without canonical tags.
Canonicalization between AMP and non-AMP pages is important.
Add a rel="canonical" tag to each AMP page's head>.
No HTTPS redirect or canonical from HTTP homepage
Duplicate content issues will be flagged in the Site Audit if your site is accessible via HTTPS and HTTP.
You can fix this by 301 redirecting or adding a canonical tag to HTTP pages that references HTTPS.
Broken canonical links
Broken canonical links won't be considered canonical URLs.
This error could mean your canonical links point to non-existent pages, complicating crawling and indexing.
Update broken canonical links to the correct URLs.
Multiple canonical URLs
This error occurs when a page has multiple canonical URLs.
Remove duplicate tags and leave one.
Canonicalization is a key SEO concept, and using it incorrectly can hurt your site's performance.
Once you understand how it works, what it does, and how to find and fix issues, you can use it effectively to remove duplicate content from your site.
Canonicalization SEO Myths

Jussi Luukkonen, MBA
1 year ago
Is Apple Secretly Building A Disruptive Tsunami?
A TECHNICAL THOUGHT
The IT giant is seeding the digital Great Renaissance.

Recently, technology has been dull.
We're still fascinated by processing speeds. Wearables are no longer an engineer's dream.
Apple has been quiet and avoided huge announcements. Slowness speaks something. Everything in the spaceship HQ seems to be turning slowly, unlike competitors around buzzwords.
Is this a sign of the impending storm?
Metas stock has fallen while Google milks dumb people. Microsoft steals money from corporations and annexes platforms like Linkedin.
Just surface bubbles?
Is Apple, one of the technology continents, pushing against all others to create a paradigm shift?
The fundamental human right to privacy
Apple's unusual remarks emphasize privacy. They incorporate it into their business models and judgments.
Apple believes privacy is a human right. There are no compromises.
This makes it hard for other participants to gain Apple's ecosystem's efficiencies.
Other players without hardware platforms lose.
Apple delivers new kidneys without rejection, unlike other software vendors. Nothing compromises your privacy.
Corporate citizenship will become more popular.
Apples have full coffers. They've started using that flow to better communities, which is great.
Apple's $2.5B home investment is one example. Google and Facebook are building or proposing to build workforce housing.
Apple's funding helps marginalized populations in more than 25 California counties, not just Apple employees.
Is this a trend, and does Apple keep giving back? Hope so.
I'm not cynical enough to suspect these investments have malicious motives.
The last frontier is the environment.
Climate change is a battle-to-win.
Long-term winners will be companies that protect the environment, turning climate change dystopia into sustainable growth.
Apple has been quietly changing its supply chain to be carbon-neutral by 2030.
“Apple is dedicated to protecting the planet we all share with solutions that are supporting the communities where we work.” Lisa Jackson, Apple’s vice president of environment.
Apple's $4.7 billion Green Bond investment will produce 1.2 gigawatts of green energy for the corporation and US communities. Apple invests $2.2 billion in Europe's green energy. In the Philippines, Thailand, Nigeria, Vietnam, Colombia, Israel, and South Africa, solar installations are helping communities obtain sustainable energy.
Apple is already carbon neutral today for its global corporate operations, and this new commitment means that by 2030, every Apple device sold will have net zero climate impact. -Apple.
Apple invests in green energy and forests to reduce its paper footprint in China and the US. Apple and the Conservation Fund are safeguarding 36,000 acres of US working forest, according to GreenBiz.
Apple's packaging paper is recycled or from sustainably managed forests.
What matters is the scale.
$1 billion is a rounding error for Apple.
These small investments originate from a tree with deep, spreading roots.
Apple's genes are anchored in building the finest products possible to improve consumers' lives.
I felt it when I switched to my iPhone while waiting for a train and had to pack my Macbook. iOS 16 dictation makes writing more enjoyable. Small change boosts productivity. Smooth transition from laptop to small screen and dictation.
Apples' tiny, well-planned steps have great growth potential for all consumers in everything they do.
There is clearly disruption, but it doesn't have to be violent
Digital channels, methods, and technologies have globalized human consciousness. One person's responsibility affects many.
Apple gives us tools to be privately connected. These technologies foster creativity, innovation, fulfillment, and safety.
Apple has invented a mountain of technologies, services, and channels to assist us adapt to the good future or combat evil forces who cynically aim to control us and ruin the environment and communities. Apple has quietly disrupted sectors for decades.
Google, Microsoft, and Meta, among others, should ride this wave. It's a tsunami, but it doesn't have to be devastating if we care, share, and cooperate with political decision-makers and community leaders worldwide.
A fresh Renaissance
Renaissance geniuses Michelangelo and Da Vinci. Different but seeing something no one else could yet see. Both were talented in many areas and could discover art in science and science in art.
These geniuses exemplified a period that changed humanity for the better. They created, used, and applied new, valuable things. It lives on.
Apple is a digital genius orchard. Wozniak and Jobs offered us fertile ground for the digital renaissance. We'll build on their legacy.
We may put our seeds there and see them bloom despite corporate greed and political ignorance.
I think the coming tsunami will illuminate our planet like the Renaissance.

Shalitha Suranga
1 year ago
The Top 5 Mathematical Concepts Every Programmer Needs to Know
Using math to write efficient code in any language

Programmers design, build, test, and maintain software. Employ cases and personal preferences determine the programming languages we use throughout development. Mobile app developers use JavaScript or Dart. Some programmers design performance-first software in C/C++.
A generic source code includes language-specific grammar, pre-implemented function calls, mathematical operators, and control statements. Some mathematical principles assist us enhance our programming and problem-solving skills.
We all use basic mathematical concepts like formulas and relational operators (aka comparison operators) in programming in our daily lives. Beyond these mathematical syntaxes, we'll see discrete math topics. This narrative explains key math topics programmers must know. Master these ideas to produce clean and efficient software code.
Expressions in mathematics and built-in mathematical functions
A source code can only contain a mathematical algorithm or prebuilt API functions. We develop source code between these two ends. If you create code to fetch JSON data from a RESTful service, you'll invoke an HTTP client and won't conduct any math. If you write a function to compute the circle's area, you conduct the math there.
When your source code gets more mathematical, you'll need to use mathematical functions. Every programming language has a math module and syntactical operators. Good programmers always consider code readability, so we should learn to write readable mathematical expressions.
Linux utilizes clear math expressions.
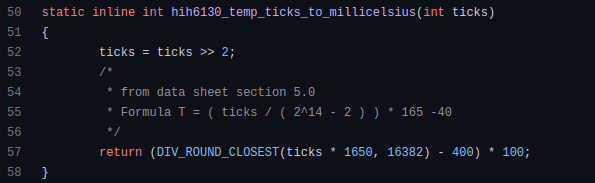
Inbuilt max and min functions can minimize verbose if statements.
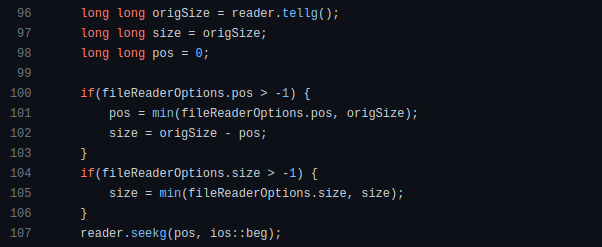
How can we compute the number of pages needed to display known data? In such instances, the ceil function is often utilized.
import math as m
results = 102
items_per_page = 10
pages = m.ceil(results / items_per_page)
print(pages)Learn to write clear, concise math expressions.
Combinatorics in Algorithm Design
Combinatorics theory counts, selects, and arranges numbers or objects. First, consider these programming-related questions. Four-digit PIN security? what options exist? What if the PIN has a prefix? How to locate all decimal number pairs?
Combinatorics questions. Software engineering jobs often require counting items. Combinatorics counts elements without counting them one by one or through other verbose approaches, therefore it enables us to offer minimum and efficient solutions to real-world situations. Combinatorics helps us make reliable decision tests without missing edge cases. Write a program to see if three inputs form a triangle. This is a question I commonly ask in software engineering interviews.
Graph theory is a subfield of combinatorics. Graph theory is used in computerized road maps and social media apps.
Logarithms and Geometry Understanding
Geometry studies shapes, angles, and sizes. Cartesian geometry involves representing geometric objects in multidimensional planes. Geometry is useful for programming. Cartesian geometry is useful for vector graphics, game development, and low-level computer graphics. We can simply work with 2D and 3D arrays as plane axes.
GetWindowRect is a Windows GUI SDK geometric object.
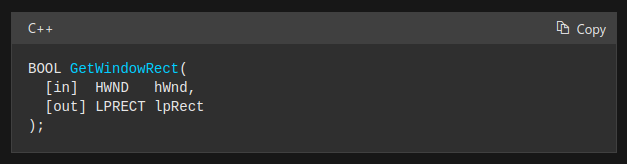
High-level GUI SDKs and libraries use geometric notions like coordinates, dimensions, and forms, therefore knowing geometry speeds up work with computer graphics APIs.
How does exponentiation's inverse function work? Logarithm is exponentiation's inverse function. Logarithm helps programmers find efficient algorithms and solve calculations. Writing efficient code involves finding algorithms with logarithmic temporal complexity. Programmers prefer binary search (O(log n)) over linear search (O(n)). Git source specifies O(log n):
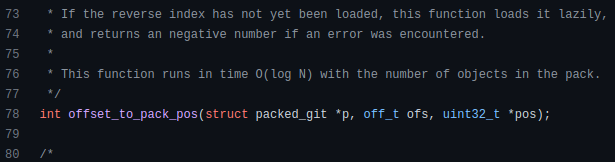
Logarithms aid with programming math. Metas Watchman uses a logarithmic utility function to find the next power of two.
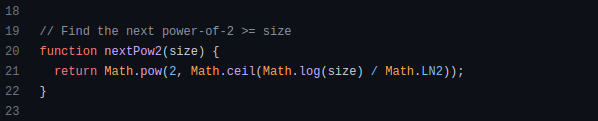
Employing Mathematical Data Structures
Programmers must know data structures to develop clean, efficient code. Stack, queue, and hashmap are computer science basics. Sets and graphs are discrete arithmetic data structures. Most computer languages include a set structure to hold distinct data entries. In most computer languages, graphs can be represented using neighboring lists or objects.
Using sets as deduped lists is powerful because set implementations allow iterators. Instead of a list (or array), store WebSocket connections in a set.
Most interviewers ask graph theory questions, yet current software engineers don't practice algorithms. Graph theory challenges become obligatory in IT firm interviews.
Recognizing Applications of Recursion
A function in programming isolates input(s) and output(s) (s). Programming functions may have originated from mathematical function theories. Programming and math functions are different but similar. Both function types accept input and return value.
Recursion involves calling the same function inside another function. In its implementation, you'll call the Fibonacci sequence. Recursion solves divide-and-conquer software engineering difficulties and avoids code repetition. I recently built the following recursive Dart code to render a Flutter multi-depth expanding list UI:
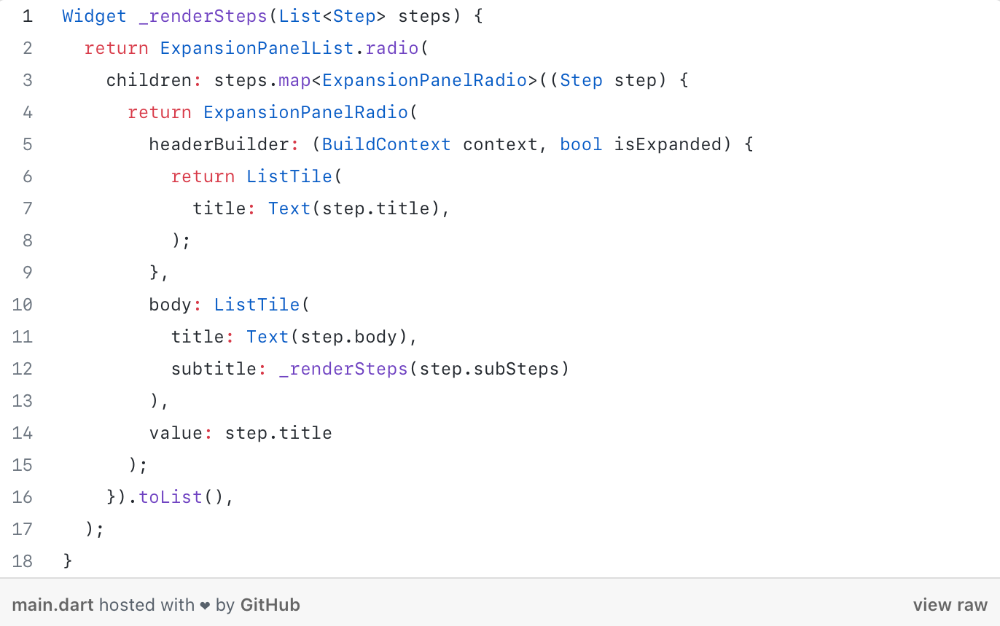
Recursion is not the natural linear way to solve problems, hence thinking recursively is difficult. Everything becomes clear when a mathematical function definition includes a base case and recursive call.
Conclusion
Every codebase uses arithmetic operators, relational operators, and expressions. To build mathematical expressions, we typically employ log, ceil, floor, min, max, etc. Combinatorics, geometry, data structures, and recursion help implement algorithms. Unless you operate in a pure mathematical domain, you may not use calculus, limits, and other complex math in daily programming (i.e., a game engine). These principles are fundamental for daily programming activities.
Master the above math fundamentals to build clean, efficient code.
You might also like

Desiree Peralta
1 year ago
Why Now Is Your Chance To Create A Millionaire Career
People don’t believe in influencers anymore; they need people like you.

Social media influencers have dominated for years. We've seen videos, images, and articles of *famous* individuals unwrapping, reviewing, and endorsing things.
This industry generates billions. This year, marketers spent $2.23 billion on Instagram, $1 million on Youtube, and $775 million on Tiktok. This marketing has helped start certain companies.
Influencers are dying, so ordinary people like us may take over this billion-dollar sector. Why?
Why influencers are perishing
Most influencers lie to their fans, especially on Instagram. Influencers' first purpose was to make their lives so flawless that others would want to buy their stuff.
In 2015, an Australian influencer with 600,000 followers went viral for revealing all her photos and everything she did to seem great before deleting her account.
“I dramatically edited the pictures, I manipulated the environements, and made my life look perfect in social media… I remember I obsessively checked the like count for a full week since uploading it, a selfie that now has close to 2,500 likes. It got 5 likes. This was when I was so hungry for social media validation … This was the reason why I quit social media: for me, personally, it consumed me. I wasn’t living in a 3D world.”
Influencers then lost credibility.
Influencers seem to live in a bubble, separate from us. Thanks to self-popularity love's and constant awareness campaigns, people find these people ridiculous.
Influencers are praised more for showing themselves as natural and common than for showing luxuries and lies.
Little by little, they are dying, making room for a new group to take advantage of this multi-million dollar business, which gives us (ordinary people) a big opportunity to grow on any content creation platform we want.
Why this is your chance to develop on any platform for creating content
In 2021, I wrote “Not everyone who talks about money is a Financial Advisor, be careful of who you take advice from,”. In it, I warned that not everyone with a large following is a reputable source of financial advice.
Other writers hated this post and said I was wrong.
People don't want Jeff Bezos or Elon Musk's counsel, they said. They prefer to hear about their neighbor's restroom problems or his closest friend's terrible business.
Real advice from regular folks.
And I found this was true when I returned to my independent YouTube channel and had more than 1000 followers after having abandoned it with fewer than 30 videos in 2021 since there were already many personal finance and travel channels and I thought mine wasn't special.
People appreciated my videos because I was a 20-something girl trying to make money online, and they believed my advice more than that of influencers with thousands of followers.
I think today is the greatest time to grow on any platform as an ordinary person. Normal individuals give honest recommendations about what works for them and look easier to make because they have the same options as us.
Nobody cares how a millionaire acquired a Lamborghini unless it's entertaining. Education works now. Real counsel from average people is replicable.
Many individuals don't appreciate how false influencers seem (unreal bodies and excessive surgery and retouching) since it makes them feel uneasy.
That's why body-positive advertisements have been so effective, but they've lost ground in places like Tiktok, where the audience wants more content from everyday people than influencers living amazing lives. More people will relate to your content if you appear genuine.
Last thoughts
Influencers are dwindling. People want more real people to give real advice and demonstrate an ordinary life.
People will enjoy anything you tell about your daily life as long as you provide value, and you can build a following rapidly if you're honest.
This is a millionaire industry that is getting more expensive and will go with what works, so stand out immediately.

Sammy Abdullah
1 year ago
Payouts to founders at IPO
How much do startup founders make after an IPO? We looked at 2018's major tech IPOs. Paydays aren't what founders took home at the IPO (shares are normally locked up for 6 months), but what they were worth at the IPO price on the day the firm went public. It's not cash, but it's nice. Here's the data.
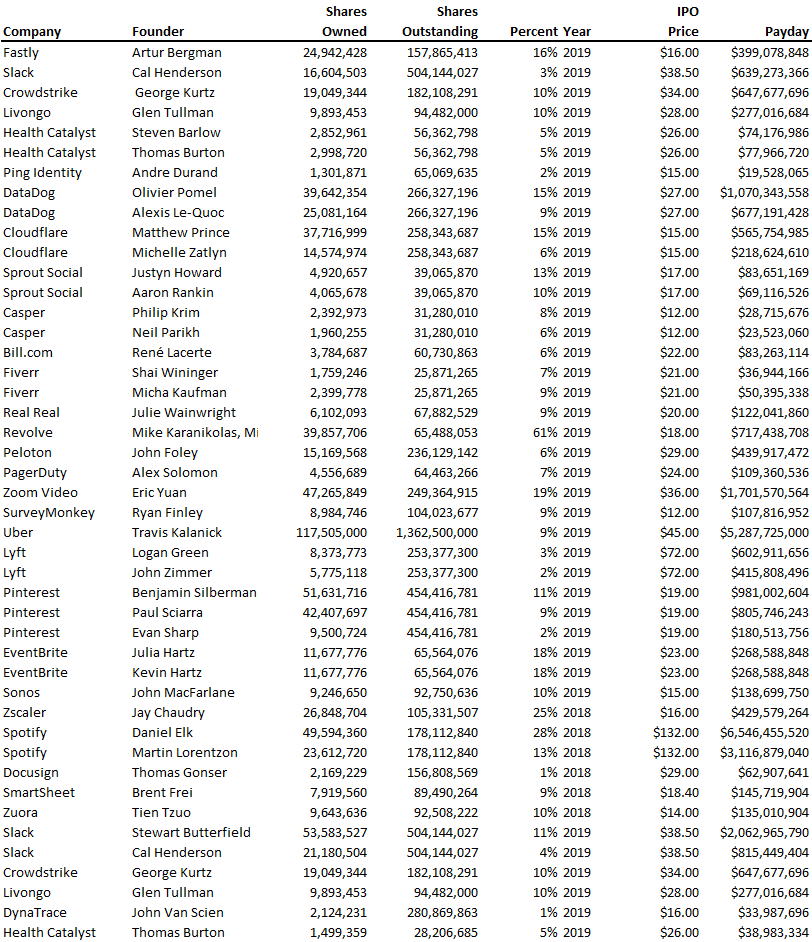
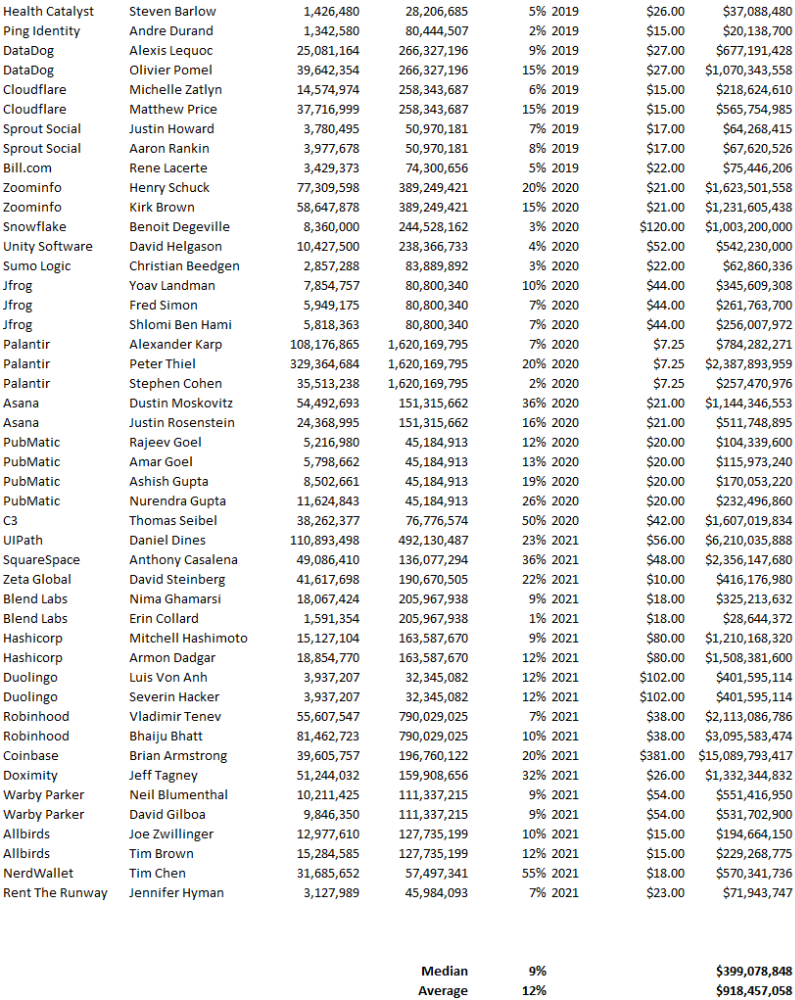
Several points are noteworthy.
Huge payoffs. Median and average pay were $399m and $918m. Average and median homeownership were 9% and 12%.
Coinbase, Uber, UI Path. Uber, Zoom, Spotify, UI Path, and Coinbase founders raised billions. Zoom's founder owned 19% and Spotify's 28% and 13%. Brian Armstrong controlled 20% of Coinbase at IPO and was worth $15bn. Preserving as much equity as possible by staying cash-efficient or raising at high valuations also helps.
The smallest was Ping. Ping's compensation was the smallest. Andre Duand owned 2% but was worth $20m at IPO. That's less than some billion-dollar paydays, but still good.
IPOs can be lucrative, as you can see. Preserving equity could be the difference between a $20mm and $15bln payday (Coinbase).

Nik Nicholas
2 years ago
A simple go-to-market formula

“Poor distribution, not poor goods, is the main reason for failure” — Peter Thiel.
Here's an easy way to conceptualize "go-to-market" for your distribution plan.
One equation captures the concept:
Distribution = Ecosystem Participants + Incentives
Draw your customers' ecosystem. Set aside your goods and consider your consumer's environment. Who do they deal with daily?
First, list each participant. You want an exhaustive list, but here are some broad categories.
In-person media services
Websites
Events\Networks
Financial education and banking
Shops
Staff
Advertisers
Twitter influencers
Draw influence arrows. Who's affected? I'm not just talking about Instagram selfie-posters. Who has access to your consumer and could promote your product if motivated?
The thicker the arrow, the stronger the relationship. Include more "influencers" if needed. Customer ecosystems are complex.
3. Incentivize ecosystem players. “Show me the incentive and I will show you the result.“, says Warren Buffet's business partner Charlie Munger.
Strong distribution strategies encourage others to promote your product to your target market by incentivizing the most prominent players. Incentives can be financial or non-financial.
Financial rewards
Usually, there's money. If you pay Facebook, they'll run your ad. Salespeople close deals for commission. Giving customers bonus credits will encourage referrals.
Most businesses underuse non-financial incentives.
Non-cash incentives
Motivate key influencers without spending money to expand quickly and cheaply. What can you give a client-connector for free?
Here are some ideas:
Are there any other features or services available?
Titles or status? Tinder paid college "ambassadors" for parties to promote its dating service.
Can I get early/free access? Facebook gave a select group of developers "exclusive" early access to their AR platform.
Are you a good host? Pharell performed at YPlan's New York launch party.
Distribution? Apple's iPod earphones are white so others can see them.
Have an interesting story? PR rewards journalists by giving them a compelling story to boost page views.
Prioritize distribution.
More time spent on distribution means more room in your product design and business plan. Once you've identified the key players in your customer's ecosystem, talk to them.
Money isn't your only resource. Creative non-monetary incentives may be more effective and scalable. Give people something useful and easy to deliver.