




More on Technology

Frank Andrade
3 years ago
I discovered a bug that allowed me to use ChatGPT to successfully web scrape. Here's how it operates.
This method scrapes websites with ChatGPT (demo with Amazon and Twitter)

In a recent article, I demonstrated how to scrape websites using ChatGPT prompts like scrape website X using Python.
But that doesn’t always work.
After scraping dozens of websites with ChatGPT, I realized that simple prompts rarely work for web scraping.
Using ChatGPT and basic HTML, we can scrape any website.
First things first, use ChatGPT's advanced version (Playground)
ChatGPT Playground's enhanced version is needed to scrape websites quickly. It generates code faster and has less constraints.
Here’s how it looks.
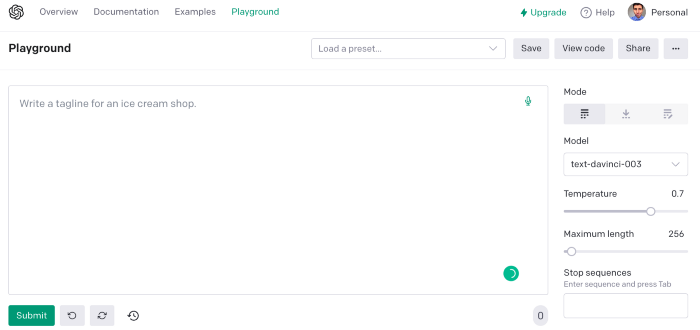
The classic ChatGPT display just allows you to type a prompt. Playground is more customizable and generates code faster than the basic version.
No more delays or restrictions.
In this tutorial, we'll write prompts underneath Playground.
How to Use ChatGPT to Scrape Any Website
To show you how to utilize ChatGPT to scrape any website, we'll use subslikescript, which lists movies.
Later in this post, I'll show you how to scrape Amazon and Twitter, but let's start easy.
If we try a basic prompt like “scrape the movie titles on this website: https://subslikescript.com/movies” it won’t scrape anything. Here’s when we need some HTML knowledge to build the right prompt for ChatGPT.Let's scrape the above movie titles. First, check the webpage. Right-click any element and choose Inspect.
Then see below.
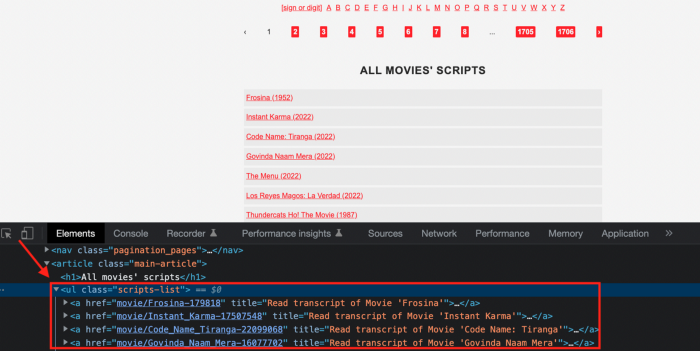
We identify the element to scrape (those in the red box). The data elements are ul, a, and scripts-list.
Here's the prompt for movie titles.
Scrape this website: https://subslikescript.com/movies with Python and Beautiful Soup. Locate the element with tag “ul” and class “scripts-list”. Scrape all the “a” elements inside. Get the text attribute and print it.
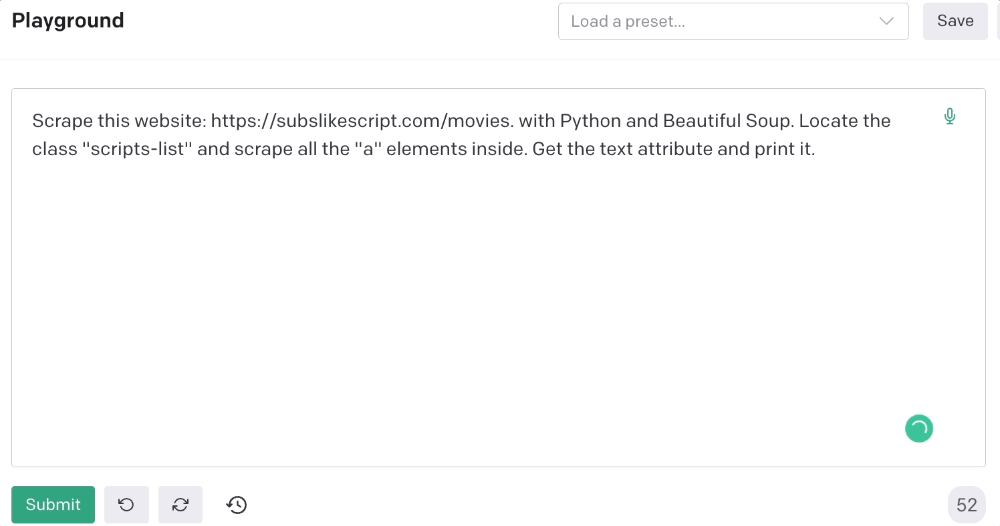
Code generated:
import requests
from bs4 import BeautifulSoup
page = requests.get('https://subslikescript.com/movies/')
soup = BeautifulSoup(page.content, 'html.parser')
scripts_list = soup.find(class_="scripts-list")
all_a_elements = scripts_list.find_all('a')
for element in all_a_elements:
print(element.get_text())It extracts movie titles successfully.
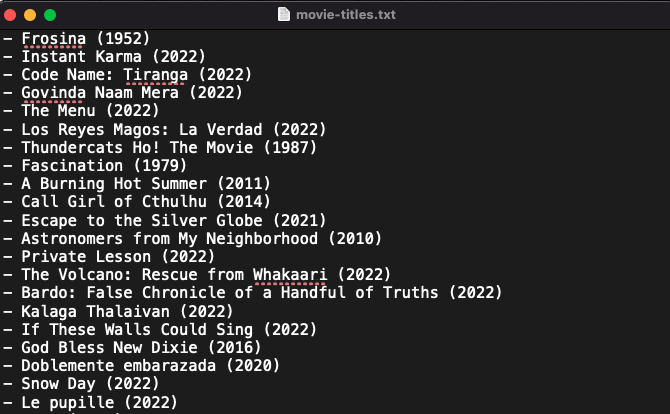
Let's scrape Amazon and Twitter.
ChatGPT's Amazon scraping
Consider scraping Amazon for self-help books. First, copy the Amazon link for self-help books.
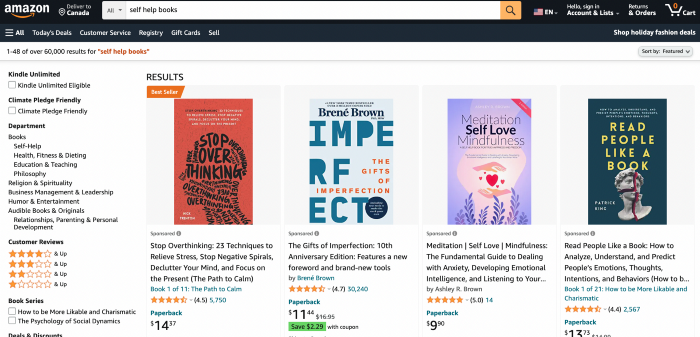
Here’s the link I got. Location-dependent connection. Use my link to replicate my results.
Now we'll check book titles. Here's our element.
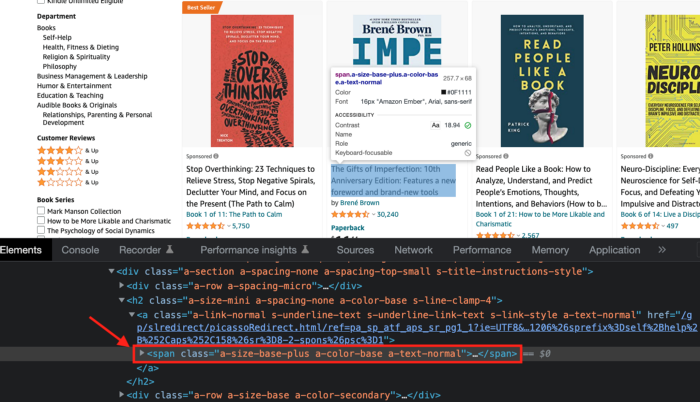
If we want to extract the book titles, we need to use the tag name span, class attribute name and a-size-base-plus a-color-base a-text-normalattribute value.
This time I'll use Selenium. I'll add Selenium-specific commands like wait 5 seconds and generate an XPath.
Scrape this website https://www.amazon.com/s?k=self+help+books&sprefix=self+help+%2Caps%2C158&ref=nb_sb_ss_ts-doa-p_2_10 with Python and Selenium.
Wait 5 seconds and locate all the elements with the following xpath: “span” tag, “class” attribute name, and “a-size-base-plus a-color-base a-text-normal” attribute value. Get the text attribute and print them.
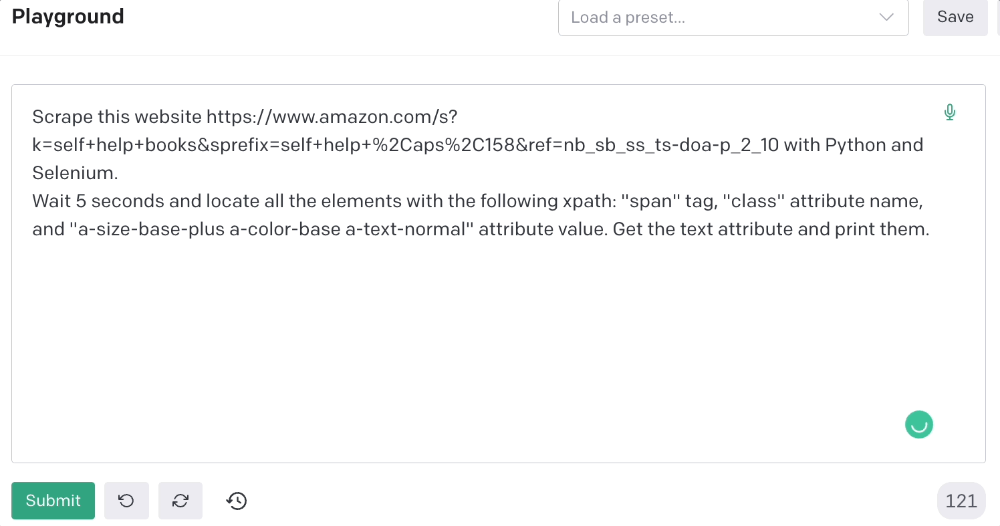
Code generated: (I only had to manually add the path where my chromedriver is located).
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
#initialize webdriver
driver = webdriver.Chrome('<add path of your chromedriver>')
#navigate to the website
driver.get("https://www.amazon.com/s?k=self+help+books&sprefix=self+help+%2Caps%2C158&ref=nb_sb_ss_ts-doa-p_2_10")
#wait 5 seconds to let the page load
sleep(5)
#locate all the elements with the following xpath
elements = driver.find_elements(By.XPATH, '//span[@class="a-size-base-plus a-color-base a-text-normal"]')
#get the text attribute of each element and print it
for element in elements:
print(element.text)
#close the webdriver
driver.close()It pulls Amazon book titles.

Utilizing ChatGPT to scrape Twitter
Say you wish to scrape ChatGPT tweets. Search Twitter for ChatGPT and copy the URL.
Here’s the link I got. We must check every tweet. Here's our element.
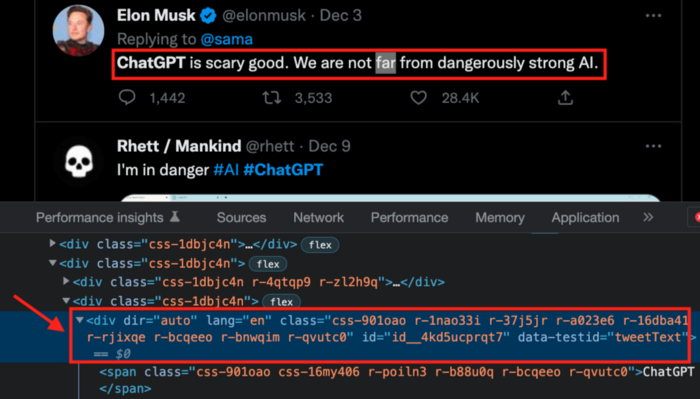
To extract a tweet, use the div tag and lang attribute.
Again, Selenium.
Scrape this website: https://twitter.com/search?q=chatgpt&src=typed_query using Python, Selenium and chromedriver.
Maximize the window, wait 15 seconds and locate all the elements that have the following XPath: “div” tag, attribute name “lang”. Print the text inside these elements.
Code generated: (again, I had to add the path where my chromedriver is located)
from selenium import webdriver
import time
driver = webdriver.Chrome("/Users/frankandrade/Downloads/chromedriver")
driver.maximize_window()
driver.get("https://twitter.com/search?q=chatgpt&src=typed_query")
time.sleep(15)
elements = driver.find_elements_by_xpath("//div[@lang]")
for element in elements:
print(element.text)
driver.quit()You'll get the first 2 or 3 tweets from a search. To scrape additional tweets, click X times.
Congratulations! You scraped websites without coding by using ChatGPT.

Asha Barbaschow
4 years ago
Apple WWDC 2022 Announcements
WWDC 2022 began early Tuesday morning. WWDC brought a ton of new features (which went for just shy of two hours).
With so many announcements, we thought we'd compile them. And now...
WWDC?
WWDC is Apple's developer conference. This includes iOS, macOS, watchOS, and iPadOS (all of its iPads). It's where Apple announces new features for developers to use. It's also where Apple previews new software.
Virtual WWDC runs June 6-10. You can rewatch the stream on Apple's website.
WWDC 2022 news:
Completely everything. Really. iOS 16 first.
iOS 16.
iOS 16 is a major iPhone update. iOS 16 adds the ability to customize the Lock Screen's color/theme. And widgets. It also organizes notifications and pairs Lock Screen with Focus themes. Edit or recall recently sent messages, recover recently deleted messages, and mark conversations as unread. Apple gives us yet another reason to stay in its walled garden with iMessage.
New iOS includes family sharing. Parents can set up a child's account with parental controls to restrict apps, movies, books, and music. iOS 16 lets large families and friend pods share iCloud photos. Up to six people can contribute photos to a separate iCloud library.
Live Text is getting creepier. Users can interact with text in any video frame. Touch and hold an image's subject to remove it from its background and place it in apps like messages. Dictation offers a new on-device voice-and-touch experience. Siri can run app shortcuts without setup in iOS 16. Apple also unveiled a new iOS 16 feature to help people break up with abusive partners who track their locations or read their messages. Safety Check.
Apple Pay Later allows iPhone users to buy products and pay for them later. iOS 16 pushes Mail. Users can schedule emails and cancel delivery before it reaches a recipient's inbox (be quick!). Mail now detects if you forgot an attachment, as Gmail has for years. iOS 16's Maps app gets "Multi-Stop Routing," .
Apple News also gets an iOS 16 update. Apple News adds My Sports. With iOS 16, the Apple Watch's Fitness app is also coming to iOS and the iPhone, using motion-sensing tech to track metrics and performance (as long as an athlete is wearing or carrying the device on their person).
iOS 16 includes accessibility updates like Door Detection.
watchOS9
Many of Apple's software updates are designed to take advantage of the larger screens in recent models, but they also improve health and fitness tracking.
The most obvious reason to upgrade watchOS every year is to get new watch faces from Apple. WatchOS 9 will add four new faces.
Runners' workout metrics improve.
Apple quickly realized that fitness tracking would be the Apple Watch's main feature, even though it's been the killer app for wearables since their debut. For watchOS 9, the Apple Watch will use its accelerometer and gyroscope to track a runner's form, stride length, and ground contact time. It also introduces the ability to specify heart rate zones, distance, and time intervals, with vibrating haptic feedback and voice alerts.
The Apple Watch's Fitness app is coming to iOS and the iPhone, using the smartphone's motion-sensing tech to track metrics and performance (as long as an athlete is wearing or carrying the device on their person).
We'll get sleep tracking, medication reminders, and drug interaction alerts. Your watch can create calendar events. A new Week view shows what meetings or responsibilities stand between you and the weekend.
iPadOS16
WWDC 2022 introduced iPad updates. iPadOS 16 is similar to iOS for the iPhone, but has features for larger screens and tablet accessories. The software update gives it many iPhone-like features.
iPadOS 16's Home app, like iOS 16, will have a new design language. iPad users who want to blame it on the rain finally have a Weather app. iPadOS 16 will have iCloud's Shared Photo Library, Live Text and Visual Look Up upgrades, and FaceTime Handoff, so you can switch between devices during a call.
Apple highlighted iPadOS 16's multitasking at WWDC 2022. iPad's Stage Manager sounds like a community theater app. It's a powerful multitasking tool for tablets and brings them closer to emulating laptops. Apple's iPadOS 16 supports multi-user collaboration. You can share content from Files, Keynote, Numbers, Pages, Notes, Reminders, Safari, and other third-party apps in Apple Messages.
M2-chip
WWDC 2022 revealed Apple's M2 chip. Apple has started the next generation of Apple Silicon for the Mac with M2. Apple says this device improves M1's performance.
M2's second-generation 5nm chip has 25% more transistors than M1's. 100GB/s memory bandwidth (50 per cent more than M1). M2 has 24GB of unified memory, up from 16GB but less than some ultraportable PCs' 32GB. The M2 chip has 10% better multi-core CPU performance than the M2, and it's nearly twice as fast as the latest 10-core PC laptop chip at the same power level (CPU performance is 18 per cent greater than M1).
New MacBooks
Apple introduced the M2-powered MacBook Air. Apple's entry-level laptop has a larger display, a new processor, new colors, and a notch.
M2 also powers the 13-inch MacBook Pro. The 13-inch MacBook Pro has 24GB of unified memory and 50% more memory bandwidth. New MacBook Pro batteries last 20 hours. As I type on the 2021 MacBook Pro, I can only imagine how much power the M2 will add.
macOS 13.0 (or, macOS Ventura)
macOS Ventura will take full advantage of M2 with new features like Stage Manager and Continuity Camera and Handoff for FaceTime. Safari, Mail, Messages, Spotlight, and more get updates in macOS Ventura.
Apple hasn't run out of California landmarks to name its OS after yet. macOS 13 will be called Ventura when it's released in a few months, but it's more than a name change and new wallpapers.
Stage Manager organizes windows
Stage Manager is a new macOS tool that organizes open windows and applications so they're still visible while focusing on a specific task. The main app sits in the middle of the desktop, while other apps and documents are organized and piled up to the side.
Improved Searching
Spotlight is one of macOS's least appreciated features, but with Ventura, it's becoming even more useful. Live Text lets you extract text from Spotlight results without leaving the window, including images from the photo library and the web.
Mail lets you schedule or unsend emails.
We've all sent an email we regret, whether it contained regrettable words or was sent at the wrong time. In macOS Ventura, Mail users can cancel or reschedule a message after sending it. Mail will now intelligently determine if a person was forgotten from a CC list or if a promised attachment wasn't included. Procrastinators can set a reminder to read a message later.
Safari adds tab sharing and password passkeys
Apple is updating Safari to make it more user-friendly... mostly. Users can share a group of tabs with friends or family, a useful feature when researching a topic with too many tabs. Passkeys will replace passwords in Safari's next version. Instead of entering random gibberish when creating a new account, macOS users can use TouchID to create an on-device passkey. Using an iPhone's camera and a QR system, Passkey syncs and works across all Apple devices and Windows computers.
Continuity adds Facetime device switching and iPhone webcam.
With macOS Ventura, iPhone users can transfer a FaceTime call from their phone to their desktop or laptop using Handoff, or vice versa if they started a call at their desk and need to continue it elsewhere. Apple finally admits its laptop and monitor webcams aren't the best. Continuity makes the iPhone a webcam. Apple demonstrated a feature where the wide-angle lens could provide a live stream of the desk below, while the standard zoom lens could focus on the speaker's face. New iPhone laptop mounts are coming.
System Preferences
System Preferences is Now System Settings and Looks Like iOS
Ventura's System Preferences has been renamed System Settings and is much more similar in appearance to iOS and iPadOS. As the iPhone and iPad are gateway devices into Apple's hardware ecosystem, new Mac users should find it easier to adjust.
This post is a summary. Read full article here

M.G. Siegler
3 years ago
G3nerative
Generative AI hype: some thoughts

The sudden surge in "generative AI" startups and projects feels like the inverse of the recent "web3" boom. Both came from hyped-up pots. But while web3 hyped idealistic tech and an easy way to make money, generative AI hypes unsettling tech and questions whether it can be used to make money.
Web3 is technology looking for problems to solve, while generative AI is technology creating almost too many solutions. Web3 has been evangelists trying to solve old problems with new technology. As Generative AI evolves, users are resolving old problems in stunning new ways.
It's a jab at web3, but it's true. Web3's hype, including crypto, was unhealthy. Always expected a tech crash and shakeout. Tech that won't look like "web3" but will enhance "web2"
But that doesn't mean AI hype is healthy. There'll be plenty of bullshit here, too. As moths to a flame, hype attracts charlatans. Again, the difference is the different starting point. People want to use it. Try it.
With the beta launch of Dall-E 2 earlier this year, a new class of consumer product took off. Midjourney followed suit (despite having to jump through the Discord server hoops). Twelve more generative art projects. Lensa, Prisma Labs' generative AI self-portrait project, may have topped the hype (a startup which has actually been going after this general space for quite a while). This week, ChatGPT went off-topic.
This has a "fake-it-till-you-make-it" vibe. We give these projects too much credit because they create easy illusions. This also unlocks new forms of creativity. And faith in new possibilities.
As a user, it's thrilling. We're just getting started. These projects are not only fun to play with, but each week brings a new breakthrough. As an investor, it's all happening so fast, with so much hype (and ethical and societal questions), that no one knows how it will turn out. Web3's demand won't be the issue. Too much demand may cause servers to melt down, sending costs soaring. Companies will try to mix rapidly evolving tech to meet user demand and create businesses. Frustratingly difficult.
Anyway, I wanted an excuse to post some Lensa selfies.

These are really weird. I recognize them as me or a version of me, but I have no memory of them being taken. It's surreal, out-of-body. Uncanny Valley.
You might also like

Aniket
3 years ago
Yahoo could have purchased Google for $1 billion
Let's see this once-dominant IT corporation crumble.

What's the capital of Kazakhstan? If you don't know the answer, you can probably find it by Googling. Google Search returned results for Nur-Sultan in 0.66 seconds.
Google is the best search engine I've ever used. Did you know another search engine ruled the Internet? I'm sure you guessed Yahoo!
Google's friendly UI and wide selection of services make it my top choice. Let's explore Yahoo's decline.
Yahoo!
YAHOO stands for Yet Another Hierarchically Organized Oracle. Jerry Yang and David Filo established Yahoo.
Yahoo is primarily a search engine and email provider. It offers News and an advertising platform. It was a popular website in 1995 that let people search the Internet directly. Yahoo began offering free email in 1997 by acquiring RocketMail.
According to a study, Yahoo used Google Search Engine technology until 2000 and then developed its own in 2004.
Yahoo! rejected buying Google for $1 billion
Larry Page and Sergey Brin, Google's founders, approached Yahoo in 1998 to sell Google for $1 billion so they could focus on their studies. Yahoo denied the offer, thinking it was overvalued at the time.
Yahoo realized its error and offered Google $3 billion in 2002, but Google demanded $5 billion since it was more valuable. Yahoo thought $5 billion was overpriced for the existing market.
In 2022, Google is worth $1.56 Trillion.
What happened to Yahoo!
Yahoo refused to buy Google, and Google's valuation rose, making a purchase unfeasible.
Yahoo started losing users when Google launched Gmail. Google's UI was far cleaner than Yahoo's.
Yahoo offered $1 billion to buy Facebook in July 2006, but Zuckerberg and the board sought $1.1 billion. Yahoo rejected, and Facebook's valuation rose, making it difficult to buy.
Yahoo was losing users daily while Google and Facebook gained many. Google and Facebook's popularity soared. Yahoo lost value daily.
Microsoft offered $45 billion to buy Yahoo in February 2008, but Yahoo declined. Microsoft increased its bid to $47 billion after Yahoo said it was too low, but Yahoo rejected it. Then Microsoft rejected Yahoo’s 10% bid increase in May 2008.
In 2015, Verizon bought Yahoo for $4.5 billion, and Apollo Global Management bought 90% of Yahoo's shares for $5 billion in May 2021. Verizon kept 10%.
Yahoo's opportunity to acquire Google and Facebook could have been a turning moment. It declined Microsoft's $45 billion deal in 2008 and was sold to Verizon for $4.5 billion in 2015. Poor decisions and lack of vision caused its downfall. Yahoo's aim wasn't obvious and it didn't stick to a single domain.
Hence, a corporation needs a clear vision and a leader who can see its future.
Liked this article? Join my tech and programming newsletter here.

TheRedKnight
4 years ago
Say goodbye to Ponzi yields - A new era of decentralized perpetual
Decentralized perpetual may be the next crypto market boom; with tons of perpetual popping up, let's look at two protocols that offer organic, non-inflationary yields.
Decentralized derivatives exchanges' market share has increased tenfold in a year, but it's still 2% of CEXs'. DEXs have a long way to go before they can compete with centralized exchanges in speed, liquidity, user experience, and composability.
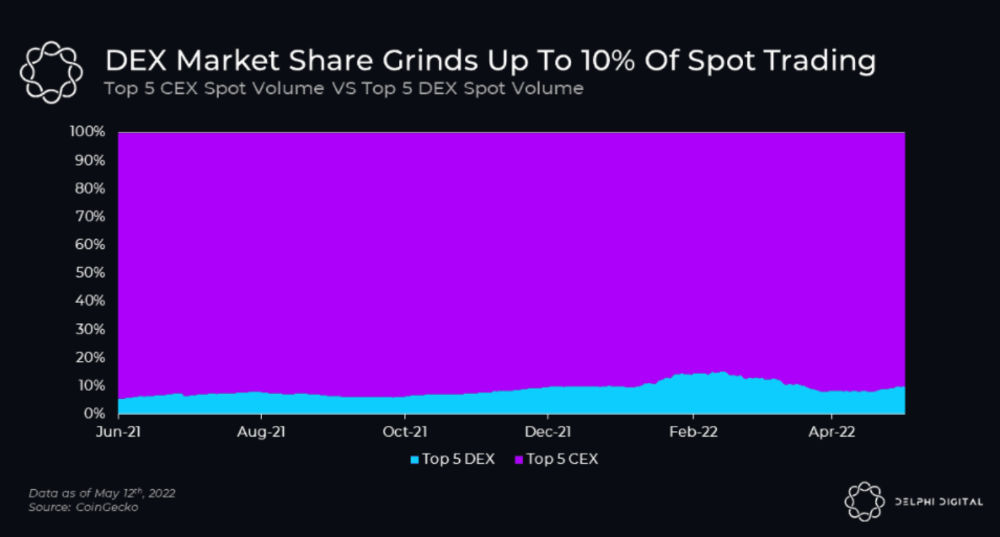
I'll cover gains.trade and GMX protocol in Polygon, Avalanche, and Arbitrum. Both protocols support leveraged perpetual crypto, stock, and Forex trading.
Why these protocols?
Decentralized GMX Gains protocol
Organic yield: path to sustainability
I've never trusted Defi's non-organic yields. Example: XYZ protocol. 20–75% of tokens may be set aside as farming rewards to provide liquidity, according to tokenomics.
Say you provide ETH-USDC liquidity. They advertise a 50% APR reward for this pair, 10% from trading fees and 40% from farming rewards. Only 10% is real, the rest is "Ponzi." The "real" reward is in protocol tokens.
Why keep this token? Governance voting or staking rewards are promoted services.
Most liquidity providers expect compensation for unused tokens. Basic psychological principles then? — Profit.
Nobody wants governance tokens. How many out of 100 care about the protocol's direction and will vote?
Staking increases your token's value. Currently, they're mostly non-liquid. If the protocol is compromised, you can't withdraw funds. Most people are sceptical of staking because of this.
"Free tokens," lack of use cases, and skepticism lead to tokens moving south. No farming reward protocols have lasted.
It may have shown strength in a bull market, but what about a bear market?
What is decentralized perpetual?
A perpetual contract is a type of futures contract that doesn't expire. So one can hold a position forever.
You can buy/sell any leveraged instruments (Long-Short) without expiration.
In centralized exchanges like Binance and coinbase, fees and revenue (liquidation) go to the exchanges, not users.
Users can provide liquidity that traders can use to leverage trade, and the revenue goes to liquidity providers.
Gains.trade and GMX protocol are perpetual trading platforms with a non-inflationary organic yield for liquidity providers.
GMX protocol
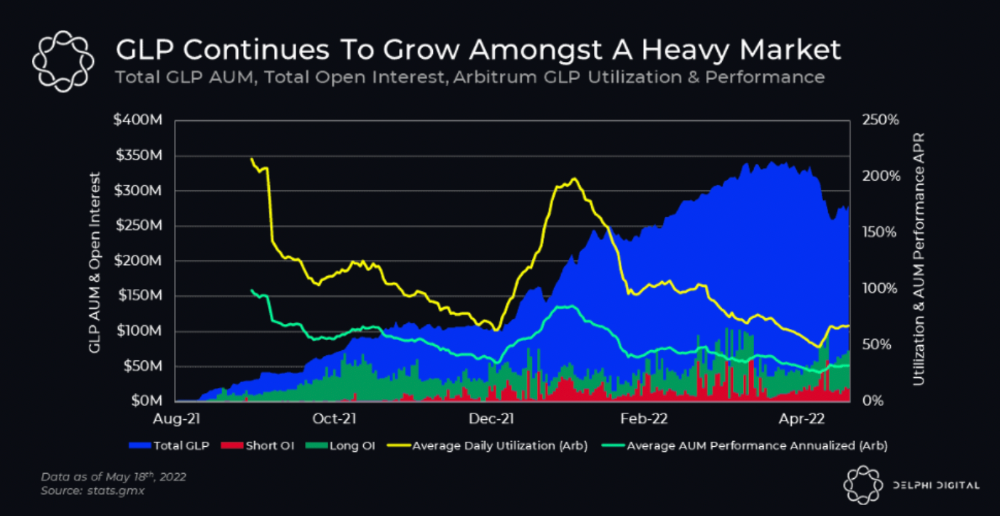
GMX is an Arbitrum and Avax protocol that rewards in ETH and Avax. GLP uses a fast oracle to borrow the "true price" from other trading venues, unlike a traditional AMM.
GLP and GMX are protocol tokens. GLP is used for leveraged trading, swapping, etc.
GLP is a basket of tokens, including ETH, BTC, AVAX, stablecoins, and UNI, LINK, and Stablecoins.
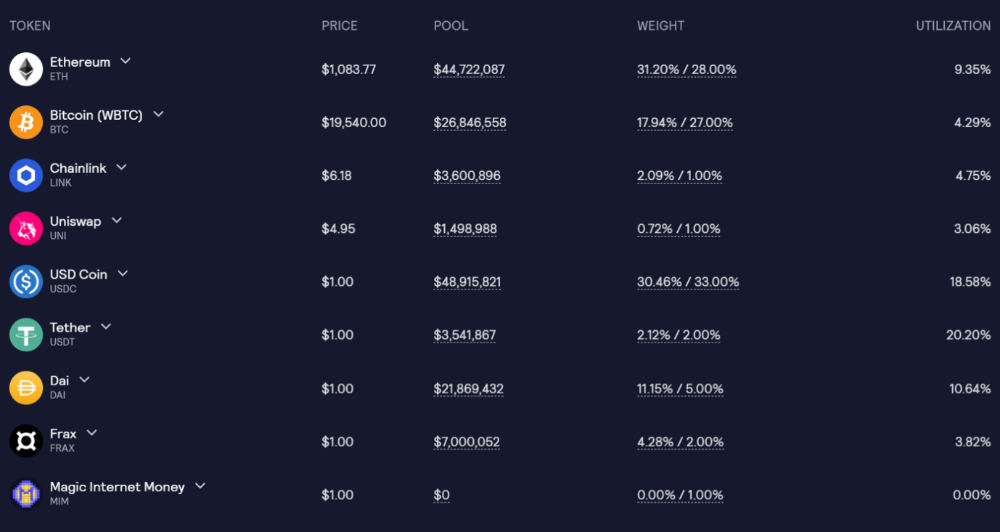
GLP composition on arbitrum
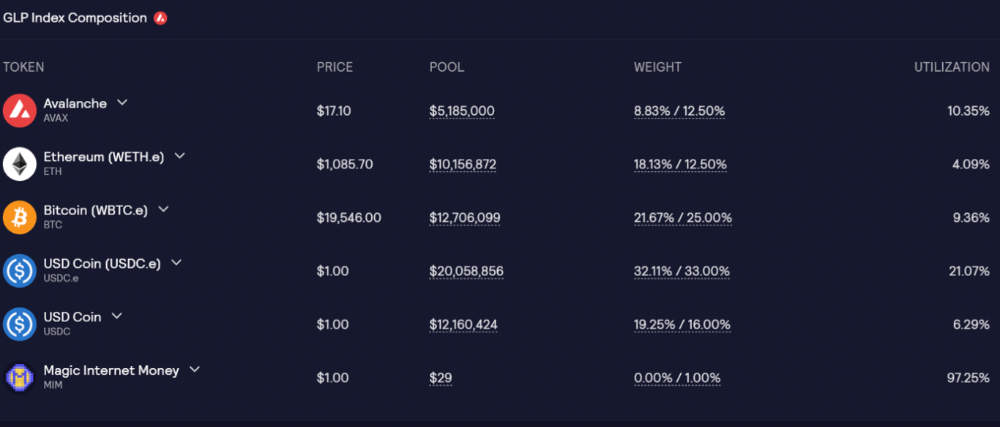
GLP composition on Avalanche
GLP token rebalances based on usage, providing liquidity without loss.
Protocol "runs" on Staking GLP. Depending on their chain, the protocol will reward users with ETH or AVAX. Current rewards are 22 percent (15.71 percent in ETH and the rest in escrowed GMX) and 21 percent (15.72 percent in AVAX and the rest in escrowed GMX). escGMX and ETH/AVAX percentages fluctuate.
Where is the yield coming from?
Swap fees, perpetual interest, and liquidations generate yield. 70% of fees go to GLP stakers, 30% to GMX. Organic yields aren't paid in inflationary farm tokens.
Escrowed GMX is vested GMX that unlocks in 365 days. To fully unlock GMX, you must farm the Escrowed GMX token for 365 days. That means less selling pressure for the GMX token.
GMX's status
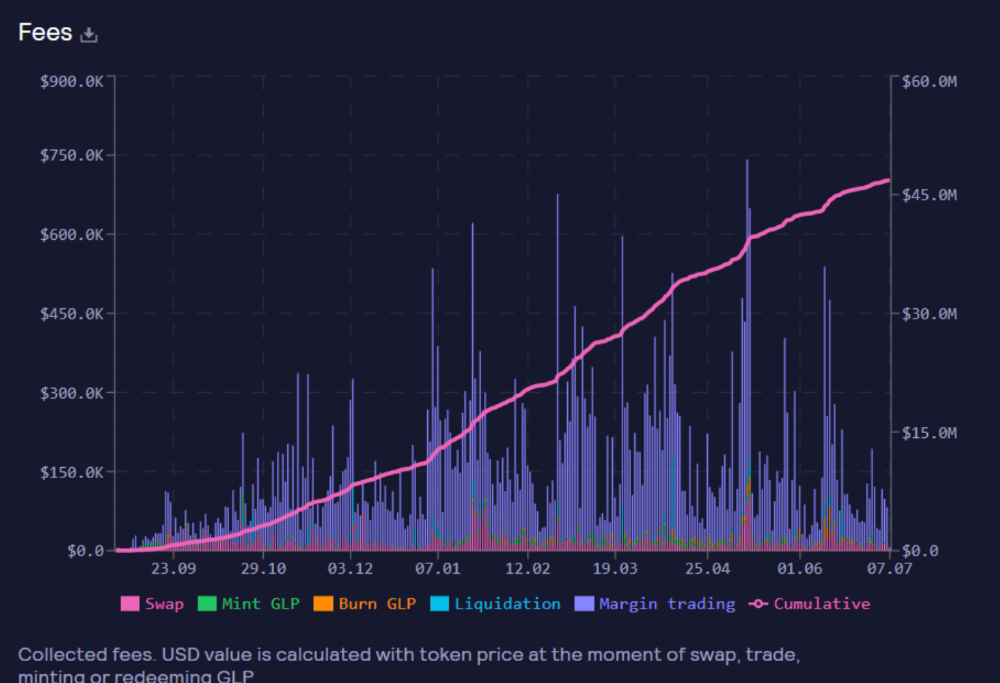
These are the fees in Arbitrum in the past 11 months by GMX.
GMX works like a casino, which increases fees. Most fees come from Margin trading, which means most traders lose money; this money goes to the casino, or GLP stakers.
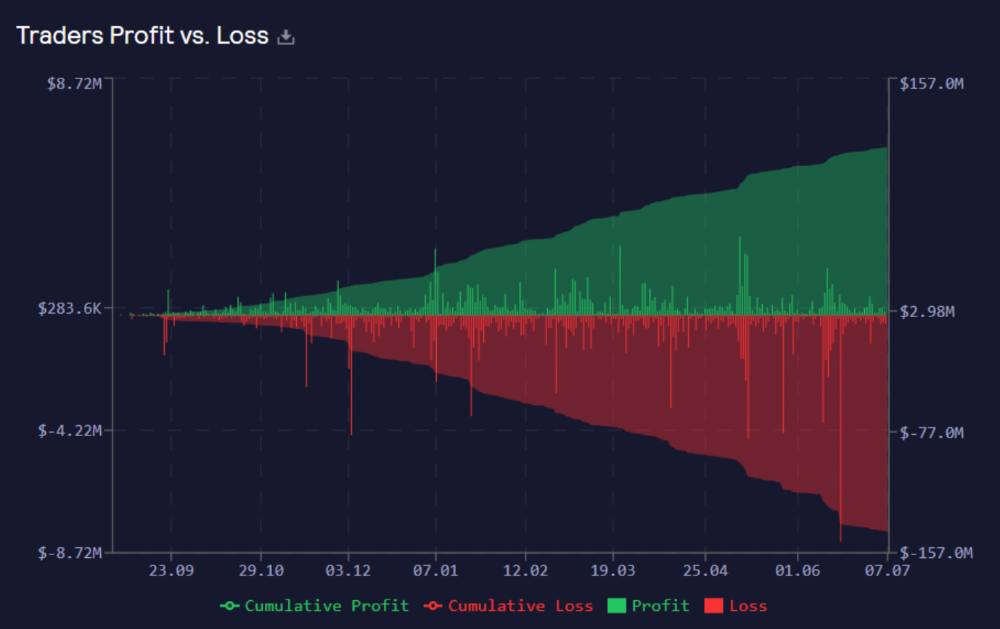
Strategies
My personal strategy is to DCA into GLP when markets hit bottom and stake it; GLP will be less volatile with extra staking rewards.
GLP YoY return vs. naked buying
Let's say I invested $10,000 in BTC, AVAX, and ETH in January.
BTC price: 47665$
ETH price: 3760$
AVAX price: $145
Current prices
BTC $21,000 (Down 56 percent )
ETH $1233 (Down 67.2 percent )
AVAX $20.36 (Down 85.95 percent )
Your $10,000 investment is now worth around $3,000.
How about GLP? My initial investment is 50% stables and 50% other assets ( Assuming the coverage ratio for stables is 50 percent at that time)
Without GLP staking yield, your value is $6500.
Let's assume the average APR for GLP staking is 23%, or $1500. So 8000$ total. It's 50% safer than holding naked assets in a bear market.
In a bull market, naked assets are preferable to GLP.
Short farming using GLP
Simple GLP short farming.
You use a stable asset as collateral to borrow AVAX. Sell it and buy GLP. Even if GLP rises, it won't rise as fast as AVAX, so we can get yields.
Let's do the maths
You deposit $10,000 USDT in Aave and borrow Avax. Say you borrow $8,000; you sell it, buy GLP, and risk 20%.
After a year, ETH, AVAX, and BTC rise 20%. GLP is $8800. $800 vanishes. 20% yields $1600. You're profitable. Shorting Avax costs $1600. (Assumptions-ETH, AVAX, BTC move the same, GLP yield is 20%. GLP has a 50:50 stablecoin/others ratio. Aave won't liquidate
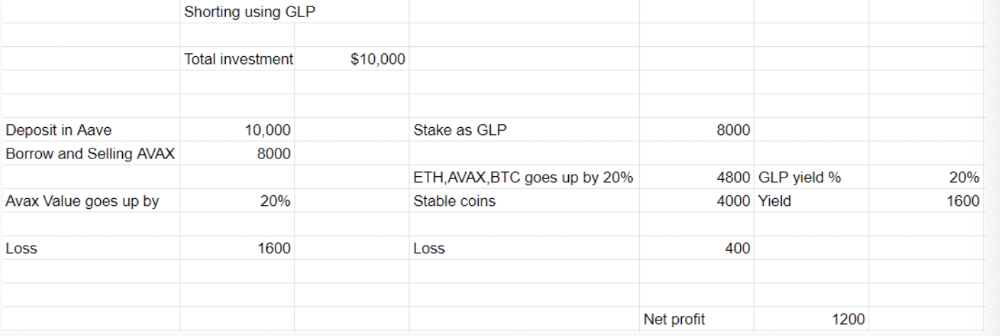
In naked Avax shorting, Avax falls 20% in a year. You'll make $1600. If you buy GLP and stake it using the sold Avax and BTC, ETH and Avax go down by 20% - your profit is 20%, but with the yield, your total gain is $2400.
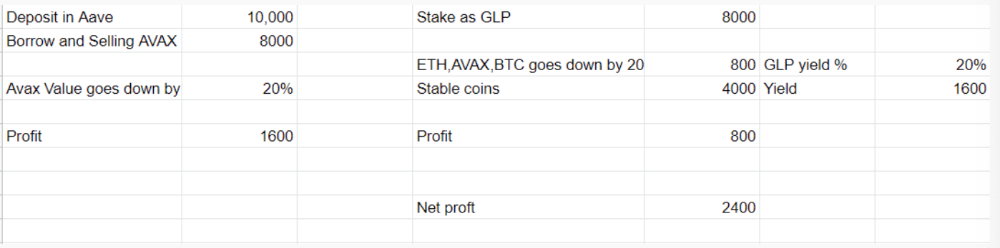
Issues with GMX
GMX's historical funding rates are always net positive, so long always pays short. This makes long-term shorts less appealing.
Oracle price discovery isn't enough. This limitation doesn't affect Bitcoin and ETH, but it affects less liquid assets. Traders can buy and sell less liquid assets at a lower price than their actual cost as long as GMX exists.
As users must provide GLP liquidity, adding more assets to GMX will be difficult. Next iteration will have synthetic assets.
Gains Protocol
Best leveraged trading platform. Smart contract-based decentralized protocol. 46 crypto pairs can be leveraged 5–150x and 10 Forex pairs 5–1000x. $10 DAI @ 150x (min collateral x leverage pos size is $1500 DAI). No funding fees, no KYC, trade DAI from your wallet, keep funds.
DAI single-sided staking and the GNS-DAI pool are important parts of Gains trading. GNS-DAI stakers get 90% of trading fees and 100% swap fees. 10 percent of trading fees go to DAI stakers, which is currently 14 percent!
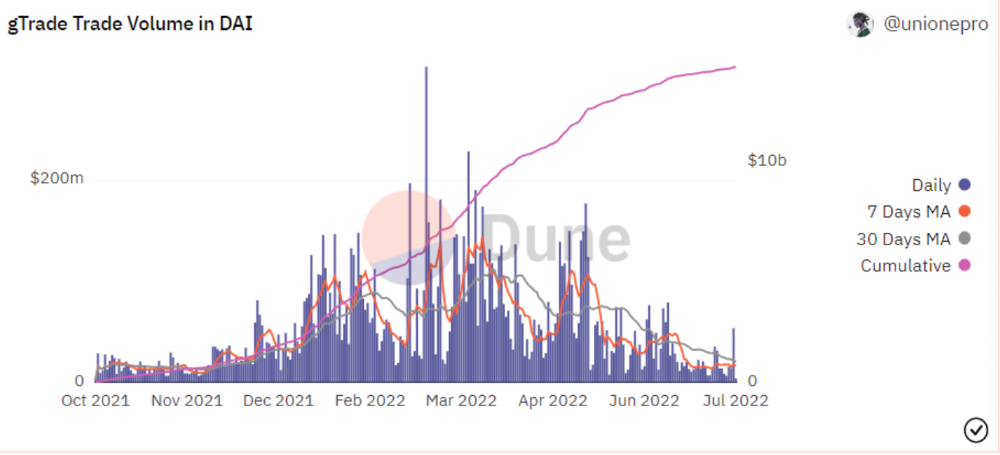
Trade volume
When a trader opens a trade, the leverage and profit are pulled from the DAI pool. If he loses, the protocol yield goes to the stakers.
If the trader's win rate is high and the DAI pool slowly depletes, the GNS token is minted and sold to refill DAI. Trader losses are used to burn GNS tokens. 25%+ of GNS is burned, making it deflationary.
Due to high leverage and volatility of crypto assets, most traders lose money and the protocol always wins, keeping GNS deflationary.
Gains uses a unique decentralized oracle for price feeds, which is better for leverage trading platforms. Let me explain.
Gains uses chainlink price oracles, not its own price feeds. Chainlink oracles only query centralized exchanges for price feeds every minute, which is unsuitable for high-precision trading.
Gains created a custom oracle that queries the eight chainlink nodes for the current price and, on average, for trade confirmation. This model eliminates every-second inquiries, which waste gas but are more efficient than chainlink's per-minute price.
This price oracle helps Gains open and close trades instantly, eliminate scam wicks, etc.
Other benefits include:
Stop-loss guarantee (open positions updated)
No scam wicks
Spot-pricing
Highest possible leverage
Fixed-spreads. During high volatility, a broker can increase the spread, which can hit your stop loss without the price moving.
Trade directly from your wallet and keep your funds.
>90% loss before liquidation (Some platforms liquidate as little as -50 percent)
KYC-free
Directly trade from wallet; keep funds safe
Further improvements
GNS-DAI liquidity providers fear the impermanent loss, so the protocol is migrating to its own liquidity and single staking GNS vaults. This allows users to stake GNS without permanent loss and obtain 90% DAI trading fees by staking. This starts in August.
Their upcoming improvements can be found here.
Gains constantly add new features and change pairs. It's an interesting protocol.
Conclusion
Next bull run, watch decentralized perpetual protocols. Effective tokenomics and non-inflationary yields may attract traders and liquidity providers. But still, there is a long way for them to develop, and I don't see them tackling the centralized exchanges any time soon until they fix their inherent problems and improve fast enough.
Read the full post here.

Shan Vernekar
3 years ago
How the Ethereum blockchain's transactions are carried out
Overview
Ethereum blockchain is a network of nodes that validate transactions. Any network node can be queried for blockchain data for free. To write data as a transition requires processing and writing to each network node's storage. Fee is paid in ether and is also called as gas.
We'll examine how user-initiated transactions flow across the network and into the blockchain.
Flow of transactions
A user wishes to move some ether from one external account to another. He utilizes a cryptocurrency wallet for this (like Metamask), which is a browser extension.
The user enters the desired transfer amount and the external account's address. He has the option to choose the transaction cost he is ready to pay.
Wallet makes use of this data, signs it with the user's private key, and writes it to an Ethereum node. Services such as Infura offer APIs that enable writing data to nodes. One of these services is used by Metamask. An example transaction is shown below. Notice the “to” address and value fields.
var rawTxn = {
nonce: web3.toHex(txnCount),
gasPrice: web3.toHex(100000000000),
gasLimit: web3.toHex(140000),
to: '0x633296baebc20f33ac2e1c1b105d7cd1f6a0718b',
value: web3.toHex(0),
data: '0xcc9ab24952616d6100000000000000000000000000000000000000000000000000000000'
};The transaction is written to the target Ethereum node's local TRANSACTION POOL. It informed surrounding nodes of the new transaction, and those nodes reciprocated. Eventually, this transaction is received by and written to each node's local TRANSACTION pool.
The miner who finds the following block first adds pending transactions (with a higher gas cost) from the nearby TRANSACTION POOL to the block.
The transactions written to the new block are verified by other network nodes.
A block is added to the main blockchain after there is consensus and it is determined to be genuine. The local blockchain is updated with the new node by additional nodes as well.
Block mining begins again next.
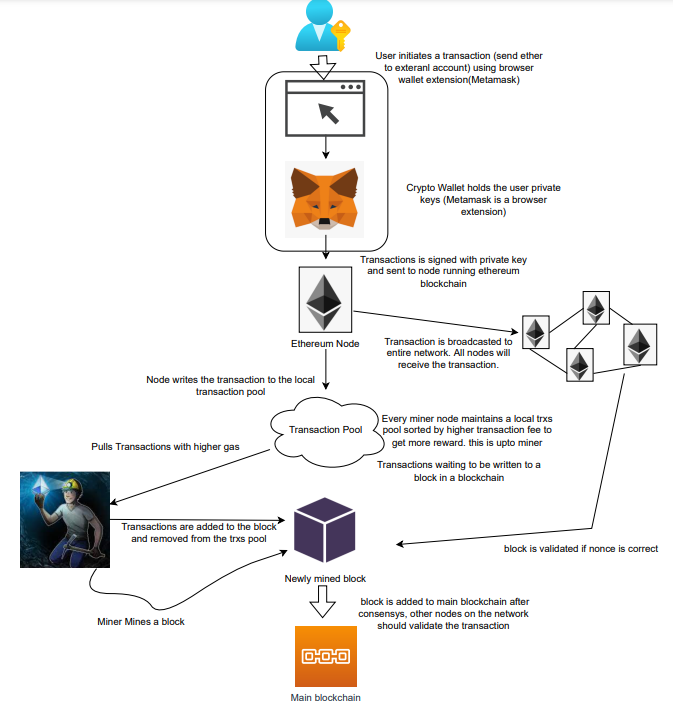
The image above shows how transactions go via the network and what's needed to submit them to the main block chain.
References
ethereum.org/transactions How Ethereum transactions function, their data structure, and how to send them via app. ethereum.org