Why Is Blockchain So Popular?
What is Bitcoin?
The blockchain is a shared, immutable ledger that helps businesses record transactions and track assets. The blockchain can track tangible assets like cars, houses, and land. Tangible assets like intellectual property can also be tracked on the blockchain.
Imagine a blockchain as a distributed database split among computer nodes. A blockchain stores data in blocks. When a block is full, it is closed and linked to the next. As a result, all subsequent information is compiled into a new block that will be added to the chain once it is filled.
The blockchain is designed so that adding a transaction requires consensus. That means a majority of network nodes must approve a transaction. No single authority can control transactions on the blockchain. The network nodes use cryptographic keys and passwords to validate each other's transactions.
Blockchain History
The blockchain was not as popular in 1991 when Stuart Haber and W. Scott Stornetta worked on it. The blocks were designed to prevent tampering with document timestamps. Stuart Haber and W. Scott Stornetta improved their work in 1992 by using Merkle trees to increase efficiency and collect more documents on a single block.
In 2004, he developed Reusable Proof of Work. This system allows users to verify token transfers in real time. Satoshi Nakamoto invented distributed blockchains in 2008. He improved the blockchain design so that new blocks could be added to the chain without being signed by trusted parties.
Satoshi Nakomoto mined the first Bitcoin block in 2009, earning 50 Bitcoins. Then, in 2013, Vitalik Buterin stated that Bitcoin needed a scripting language for building decentralized applications. He then created Ethereum, a new blockchain-based platform for decentralized apps. Since the Ethereum launch in 2015, different blockchain platforms have been launched: from Hyperledger by Linux Foundation, EOS.IO by block.one, IOTA, NEO and Monero dash blockchain. The block chain industry is still growing, and so are the businesses built on them.
Blockchain Components
The Blockchain is made up of many parts:
1. Node: The node is split into two parts: full and partial. The full node has the authority to validate, accept, or reject any transaction. Partial nodes or lightweight nodes only keep the transaction's hash value. It doesn't keep a full copy of the blockchain, so it has limited storage and processing power.
2. Ledger: A public database of information. A ledger can be public, decentralized, or distributed. Anyone on the blockchain can access the public ledger and add data to it. It allows each node to participate in every transaction. The distributed ledger copies the database to all nodes. A group of nodes can verify transactions or add data blocks to the blockchain.
3. Wallet: A blockchain wallet allows users to send, receive, store, and exchange digital assets, as well as monitor and manage their value. Wallets come in two flavors: hardware and software. Online or offline wallets exist. Online or hot wallets are used when online. Without an internet connection, offline wallets like paper and hardware wallets can store private keys and sign transactions. Wallets generally secure transactions with a private key and wallet address.
4. Nonce: A nonce is a short term for a "number used once''. It describes a unique random number. Nonces are frequently generated to modify cryptographic results. A nonce is a number that changes over time and is used to prevent value reuse. To prevent document reproduction, it can be a timestamp. A cryptographic hash function can also use it to vary input. Nonces can be used for authentication, hashing, or even electronic signatures.
5. Hash: A hash is a mathematical function that converts inputs of arbitrary length to outputs of fixed length. That is, regardless of file size, the hash will remain unique. A hash cannot generate input from hashed output, but it can identify a file. Hashes can be used to verify message integrity and authenticate data. Cryptographic hash functions add security to standard hash functions, making it difficult to decipher message contents or track senders.
Blockchain: Pros and Cons
The blockchain provides a trustworthy, secure, and trackable platform for business transactions quickly and affordably. The blockchain reduces paperwork, documentation errors, and the need for third parties to verify transactions.
Blockchain security relies on a system of unaltered transaction records with end-to-end encryption, reducing fraud and unauthorized activity. The blockchain also helps verify the authenticity of items like farm food, medicines, and even employee certification. The ability to control data gives users a level of privacy that no other platform can match.
In the case of Bitcoin, the blockchain can only handle seven transactions per second. Unlike Hyperledger and Visa, which can handle ten thousand transactions per second. Also, each participant node must verify and approve transactions, slowing down exchanges and limiting scalability.
The blockchain requires a lot of energy to run. In addition, the blockchain is not a hugely distributable system and it is destructible. The security of the block chain can be compromised by hackers; it is not completely foolproof. Also, since blockchain entries are immutable, data cannot be removed. The blockchain's high energy consumption and limited scalability reduce its efficiency.
Why Is Blockchain So Popular?
The blockchain is a technology giant. In 2018, 90% of US and European banks began exploring blockchain's potential. In 2021, 24% of companies are expected to invest $5 million to $10 million in blockchain. By the end of 2024, it is expected that corporations will spend $20 billion annually on blockchain technical services.
Blockchain is used in cryptocurrency, medical records storage, identity verification, election voting, security, agriculture, business, and many other fields. The blockchain offers a more secure, decentralized, and less corrupt system of making global payments, which cryptocurrency enthusiasts love. Users who want to save time and energy prefer it because it is faster and less bureaucratic than banking and healthcare systems.
Most organizations have jumped on the blockchain bandwagon, and for good reason: the blockchain industry has never had more potential. The launch of IBM's Blockchain Wire, Paystack, Aza Finance and Bloom are visible proof of the wonders that the blockchain has done. The blockchain's cryptocurrency segment may not be as popular in the future as the blockchain's other segments, as evidenced by the various industries where it is used. The blockchain is here to stay, and it will be discussed for a long time, not just in tech, but in many industries.
Read original post here
More on Web3 & Crypto

CyberPunkMetalHead
3 years ago
I talked to ChatGPT about the adoption of cryptocurrencies.

OpenAI's ChatGPT is an amazing AI-powered chatbot. It can write poetry, fiction, and marketing ideas. I was impressed how well ChatGPT followed the interview, albeit there were a few classics “I’m afraid I can’t do that”.
Full interview below.
Me: I'm your interviewer. We'll discuss crypto. Thanks for being interviewed. What do you think about cryptocurrency?
CGPT: Cryptocurrency is an innovative technology that could transform money and financial activities. It might boost the efficiency and security of financial institutions and let consumers deal directly without banks. Cryptocurrency is still a new and untested technology with many unknowns and hurdles before it can be broadly accepted.
Me: Over 22,000 cryptocurrencies exist, and many have little use. We need how much cryptocurrencies?
CGPT: The appropriate quantity will rely on a multitude of factors, including each cryptocurrency's use cases, adoption rate, and market rivalry. Only a few cryptocurrencies will likely receive widespread adoption and be successful. Many existing cryptocurrencies may not survive since they can't deliver new or valued solutions or compete with more established cryptocurrencies.
Me: Will cryptocurrencies grow? What's next for worldwide adoption?
CGPT: It's hard to forecast the future of cryptocurrencies because the acceptance of new technologies is unpredictable. I believe cryptocurrencies will expand and acquire popularity in the future years. Regulatory ambiguity, security concerns, and scalability issues must be overcome for this to happen. Cryptocurrency companies and organizations must engage together with governments and authorities to address these obstacles and establish a growth-friendly climate. Continued innovation and improvement of the technology, including public education and awareness, will drive acceptance.
Me: Do bear markets affect bitcoin adoption?
CGPT: On the one hand, a bear market might induce uncertainty and hesitation among potential consumers. Bear markets can present opportunities for long-term investors who can acquire cryptocurrencies at cheaper prices and are more likely to hang onto their assets. A bear market can also test the tenacity and power of the underlying technology and community, which can boost long-term confidence and adoption. A bear market might have profound and nuanced effects on bitcoin adoption.
Me: What are some likely outcomes if Bitcoin reaches $100,000 by next year?
CGPT: If Bitcoin saw rapid growth, it would undoubtedly have repercussions for the cryptocurrency market and economy. Possible scenarios include increased public interest and awareness of cryptocurrency, a surge in demand for Bitcoin and other cryptocurrencies, and a growth in the cryptocurrency industry's market value. By shifting their focus and cash to the cryptocurrency market, investors and traders may also affect other asset classes, such as traditional equities and commodities. Governments and financial organizations may focus more on the cryptocurrency sector as they try to grasp Bitcoin's rapid rise.
Me: Will other countries accept crypto as currency?
CGPT: It's hard to say if additional governments will adopt cryptocurrencies as legal tender. Some countries have recognized the promise of bitcoin and are exploring its use, while others are cautious. Adoption of bitcoin as legal cash may vary by country, based on financial infrastructure, rules, and political atmosphere. As cryptocurrency technology evolves and becomes more accepted, more governments may embrace it as legal tender.
Me: Final question: will the recent cryptocurrency hacks affect long term adoption?
CGPT: Hacks might tarnish cryptocurrency's reputation and public faith in its security, the technology underpinning it is continually improving. Many cryptocurrency projects have developed strong security mechanisms to prevent hacks and other dangers, and these safeguards will undoubtedly improve over time. The decentralized nature of cryptocurrency makes it more resistant to attacks. Hacks and other security breaches are a concern, but they may not affect cryptocurrency adoption.

Faisal Khan
3 years ago
4 typical methods of crypto market manipulation

Market fraud
Due to its decentralized and fragmented character, the crypto market has integrity difficulties.
Cryptocurrencies are an immature sector, therefore market manipulation becomes a bigger issue. Many research have attempted to uncover these abuses. CryptoCompare's newest one highlights some of the industry's most typical scams.
Why are these concerns so common in the crypto market? First, even the largest centralized exchanges remain unregulated due to industry immaturity. A low-liquidity market segment makes an attack more harmful. Finally, market surveillance solutions not implemented reduce transparency.
In CryptoCompare's latest exchange benchmark, 62.4% of assessed exchanges had a market surveillance system, although only 18.1% utilised an external solution. To address market integrity, this measure must improve dramatically. Before discussing the report's malpractices, note that this is not a full list of attacks and hacks.
Clean Trading
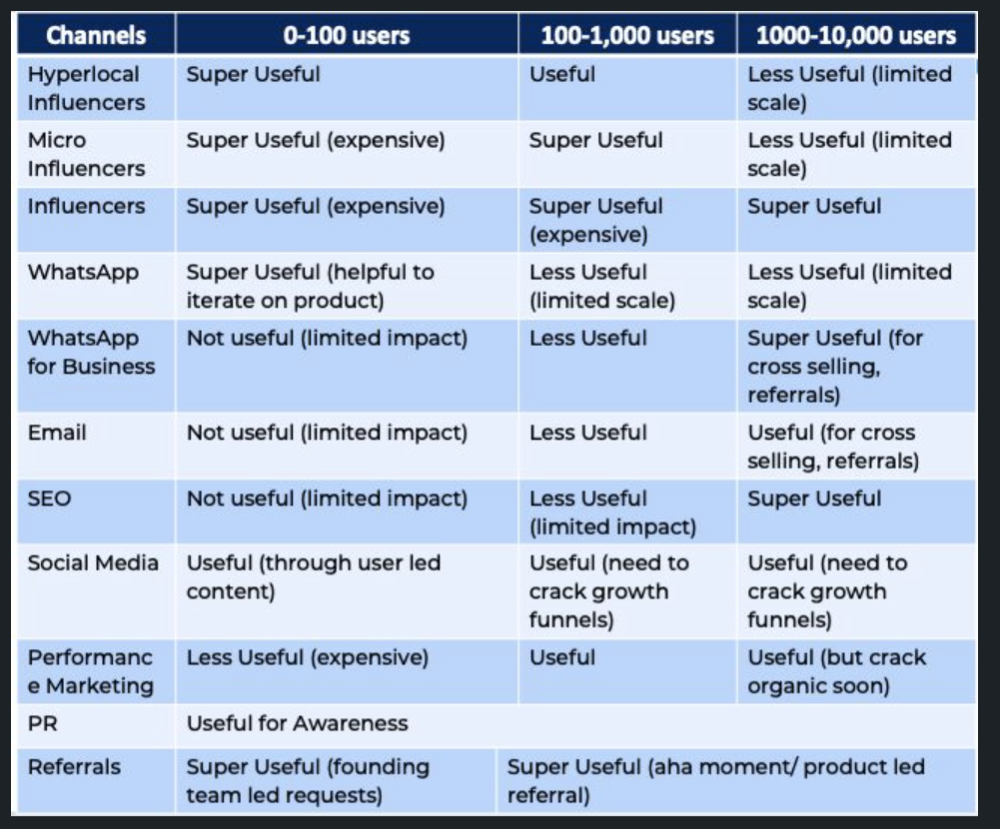
An investor buys and sells concurrently to increase the asset's price. Centralized and decentralized exchanges show this misconduct. 23 exchanges have a volume-volatility correlation < 0.1 during the previous 100 days, according to CryptoCompares. In August 2022, Exchange A reported $2.5 trillion in artificial and/or erroneous volume, up from $33.8 billion the month before.
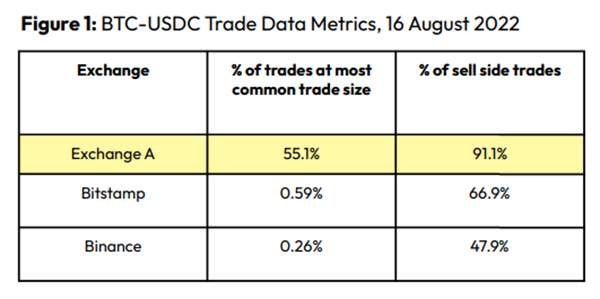
Spoofing
Criminals create and cancel fake orders before they can be filled. Since manipulators can hide in larger trading volumes, larger exchanges have more spoofing. A trader placed a 20.8 BTC ask order at $19,036 when BTC was trading at $19,043. BTC declined 0.13% to $19,018 in a minute. At 18:48, the trader canceled the ask order without filling it.
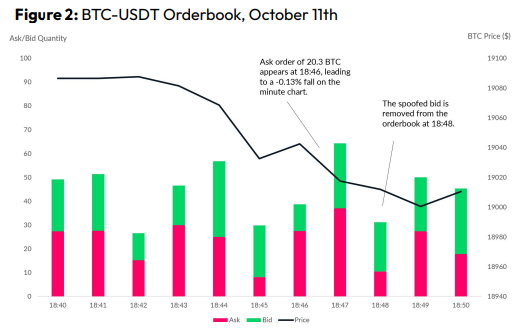
Front-Running
Most cryptocurrency front-running involves inside trading. Traditional stock markets forbid this. Since most digital asset information is public, this is harder. Retailers could utilize bots to front-run.
CryptoCompare found digital wallets of people who traded like insiders on exchange listings. The figure below shows excess cumulative anomalous returns (CAR) before a coin listing on an exchange.
Finally, LAYERING is a sequence of spoofs in which successive orders are put along a ladder of greater (layering offers) or lower (layering bids) values. The paper concludes with recommendations to mitigate market manipulation. Exchange data transparency, market surveillance, and regulatory oversight could reduce manipulative tactics.

Nitin Sharma
3 years ago
Web3 Terminology You Should Know
The easiest online explanation.

Web3 is growing. Crypto companies are growing.
Instagram, Adidas, and Stripe adopted cryptocurrency.

Bitcoin and other cryptocurrencies made web3 famous.
Most don't know where to start. Cryptocurrency, DeFi, etc. are investments.
Since we don't understand web3, I'll help you today.
Let’s go.
1. Web3
It is the third generation of the web, and it is built on the decentralization idea which means no one can control it.
There are static webpages that we can only read on the first generation of the web (i.e. Web 1.0).
Web 2.0 websites are interactive. Twitter, Medium, and YouTube.
Each generation controlled the website owner. Simply put, the owner can block us. However, data breaches and selling user data to other companies are issues.
They can influence the audience's mind since they have control.
Assume Twitter's CEO endorses Donald Trump. Result? Twitter would have promoted Donald Trump with tweets and graphics, enhancing his chances of winning.
We need a decentralized, uncontrollable system.
And then there’s Web3.0 to consider. As Bitcoin and Ethereum values climb, so has its popularity. Web3.0 is uncontrolled web evolution. It's good and bad.
Dapps, DeFi, and DAOs are here. It'll all be explained afterwards.
2. Cryptocurrencies:
No need to elaborate.
Bitcoin, Ethereum, Cardano, and Dogecoin are cryptocurrencies. It's digital money used for payments and other uses.
Programs must interact with cryptocurrencies.
3. Blockchain:
Blockchain facilitates bitcoin transactions, investments, and earnings.
This technology governs Web3. It underpins the web3 environment.
Let us delve much deeper.
Blockchain is simple. However, the name expresses the meaning.
Blockchain is a chain of blocks.
Let's use an image if you don't understand.
The graphic above explains blockchain. Think Blockchain. The block stores related data.
Here's more.
4. Smart contracts
Programmers and developers must write programs. Smart contracts are these blockchain apps.
That’s reasonable.
Decentralized web3.0 requires immutable smart contracts or programs.
5. NFTs
Blockchain art is NFT. Non-Fungible Tokens.
Explaining Non-Fungible Token may help.
Two sorts of tokens:
These tokens are fungible, meaning they can be changed. Think of Bitcoin or cash. The token won't change if you sell one Bitcoin and acquire another.
Non-Fungible Token: Since these tokens cannot be exchanged, they are exclusive. For instance, music, painting, and so forth.
Right now, Companies and even individuals are currently developing worthless NFTs.
The concept of NFTs is much improved when properly handled.
6. Dapp
Decentralized apps are Dapps. Instagram, Twitter, and Medium apps in the same way that there is a lot of decentralized blockchain app.
Curve, Yearn Finance, OpenSea, Axie Infinity, etc. are dapps.
7. DAOs
DAOs are member-owned and governed.
Consider it a company with a core group of contributors.
8. DeFi
We all utilize centrally regulated financial services. We fund these banks.
If you have $10,000 in your bank account, the bank can invest it and retain the majority of the profits.
We only get a penny back. Some banks offer poor returns. To secure a loan, we must trust the bank, divulge our information, and fill out lots of paperwork.
DeFi was built for such issues.
Decentralized banks are uncontrolled. Staking, liquidity, yield farming, and more can earn you money.
Web3 beginners should start with these resources.
You might also like

Pat Vieljeux
3 years ago
In 5 minutes, you can tell if a startup will succeed.
Or the “lie to me” method.

I can predict a startup's success in minutes.
Just interview its founder.
Ask "why?"
I question "why" till I sense him.
I need to feel the person I have in front of me. I need to know if he or she can deliver. Startups aren't easy. Without abilities, a brilliant idea will fail.
Good entrepreneurs have these qualities: He's a leader, determined, and resilient.
For me, they can be split in two categories.
The first entrepreneur aspires to live meaningfully. The second wants to get rich. The second is communicative. He wants to wow the crowd. He's motivated by the thought of one day sailing a boat past palm trees and sunny beaches.
What drives the first entrepreneur is evident in his speech, face, and voice. He will not speak about his product. He's (nearly) uninterested. He's not selling anything. He's not a salesman. He wants to succeed. The product is his fuel.
He'll explain his decision. He'll share his motivations. His desire. And he'll use meaningful words.
Paul Ekman has shown that face expressions aren't cultural. His study influenced the American TV series "lie to me" about body language and speech.
Passionate entrepreneurs are obvious. It's palpable. Faking passion is tough. Someone who wants your favor and money will expose his actual motives through his expressions and language.
The good liar will be able to fool you for a while, but not for long if you pay attention to his body language and how he expresses himself.
And also, if you look at his business plan.
His business plan reveals his goals. Read between the lines.
Entrepreneur 1 will focus on his "why", whereas Entrepreneur 2 will focus on the "how".
Entrepreneur 1 will develop a vision-driven culture.
The second, on the other hand, will focus on his EBITDA.
Why is the culture so critical? Because it will allow entrepreneur 1 to develop a solid team that can tackle his problems and trials. His team's "why" will keep them together in tough times.
"Give me a terrific start-up team with a mediocre idea over a weak one any day." Because a great team knows when to pivot and trusts each other. Weak teams fail.” — Bernhard Schroeder
Closings thoughts
Every VC must ask Why. Entrepreneur's motivations. This "why" will create the team's culture. This culture will help the team adjust to any setback.

Hudson Rennie
3 years ago
My Work at a $1.2 Billion Startup That Failed
Sometimes doing everything correctly isn't enough.

In 2020, I could fix my life.
After failing to start a business, I owed $40,000 and had no work.
A $1.2 billion startup on the cusp of going public pulled me up.
Ironically, it was getting ready for an epic fall — with the world watching.
Life sometimes helps. Without a base, even the strongest fall. A corporation that did everything right failed 3 months after going public.
First-row view.
Apple is the creator of Adore.
Out of respect, I've altered the company and employees' names in this account, despite their failure.
Although being a publicly traded company, it may become obvious.
We’ll call it “Adore” — a revolutionary concept in retail shopping.
Two Apple execs established Adore in 2014 with a focus on people-first purchasing.
Jon and Tim:
The concept for the stylish Apple retail locations you see today was developed by retail expert Jon Swanson, who collaborated closely with Steve Jobs.
Tim Cruiter is a graphic designer who produced the recognizable bouncing lamp video that appears at the start of every Pixar film.
The dynamic duo realized their vision.
“What if you could combine the convenience of online shopping with the confidence of the conventional brick-and-mortar store experience.”
Adore's mobile store concept combined traditional retail with online shopping.
Adore brought joy to 70+ cities and 4 countries over 7 years, including the US, Canada, and the UK.
Being employed on the ground floor, with world dominance and IPO on the horizon, was exciting.
I started as an Adore Expert.
I delivered cell phones, helped consumers set them up, and sold add-ons.
As the company grew, I became a Virtual Learning Facilitator and trained new employees across North America using Zoom.
In this capacity, I gained corporate insider knowledge. I worked with the creative team and Jon and Tim.
It's where I saw company foundation fissures. Despite appearances, investors were concerned.
The business strategy was ground-breaking.
Even after seeing my employee stocks fall from a home down payment to $0 (when Adore filed for bankruptcy), it's hard to pinpoint what went wrong.
Solid business model, well-executed.
Jon and Tim's chase for public funding ended in glory.
Here’s the business model in a nutshell:
Buying cell phones is cumbersome. You have two choices:
Online purchase: not knowing what plan you require or how to operate your device.
Enter a store, which can be troublesome and stressful.
Apple, AT&T, and Rogers offered Adore as a free delivery add-on. Customers could:
Have their phone delivered by UPS or Canada Post in 1-2 weeks.
Alternately, arrange for a person to visit them the same day (or sometimes even the same hour) to assist them set up their phone and demonstrate how to use it (transferring contacts, switching the SIM card, etc.).
Each Adore Expert brought a van with extra devices and accessories to customers.
Happy customers.
Here’s how Adore and its partners made money:
Adores partners appreciated sending Experts to consumers' homes since they improved customer satisfaction, average sale, and gadget returns.
**Telecom enterprises have low customer satisfaction. The average NPS is 30/100. Adore's global NPS was 80.
Adore made money by:
a set cost for each delivery
commission on sold warranties and extras
Consumer product applications seemed infinite.
A proprietary scheduling system (“The Adore App”), allowed for same-day, even same-hour deliveries.
It differentiates Adore.
They treated staff generously by:
Options on stock
health advantages
sales enticements
high rates per hour
Four-day workweeks were set by experts.
Being hired early felt like joining Uber, Netflix, or Tesla. We hoped the company's stocks would rise.
Exciting times.
I smiled as I greeted more than 1,000 new staff.
I spent a decade in retail before joining Adore. I needed a change.
After a leap of faith, I needed a lifeline. So, I applied for retail sales jobs in the spring of 2019.
The universe typically offers you what you want after you accept what you need. I needed a job to settle my debt and reach $0 again.
And the universe listened.
After being hired as an Adore Expert, I became a Virtual Learning Facilitator. Enough said.
After weeks of economic damage from the pandemic.
This employment let me work from home during the pandemic. It taught me excellent business skills.
I was active in brainstorming, onboarding new personnel, and expanding communication as we grew.
This job gave me vital skills and a regular paycheck during the pandemic.
It wasn’t until January of 2022 that I left on my own accord to try to work for myself again — this time, it’s going much better.
Adore was perfect. We valued:
Connection
Discovery
Empathy
Everything we did centered on compassion, and we held frequent Justice Calls to discuss diversity and work culture.
The last day of onboarding typically ended in tears as employees felt like they'd found a home, as I had.
Like all nice things, the wonderful vibes ended.
First indication of distress
My first day at the workplace was great.
Fun, intuitive, and they wanted creative individuals, not salesman.
While sales were important, the company's vision was more important.
“To deliver joy through life-changing mobile retail experiences.”
Thorough, forward-thinking training. We had a module on intuition. It gave us role ownership.
We were flown cross-country for training, gave feedback, and felt like we made a difference. Multiple contacts responded immediately and enthusiastically.
The atmosphere was genuine.
Making money was secondary, though. Incredible service was a priority.
Jon and Tim answered new hires' questions during Zoom calls during onboarding. CEOs seldom meet new hires this way, but they seemed to enjoy it.
All appeared well.
But in late 2021, things started changing.
Adore's leadership changed after its IPO. From basic values to sales maximization. We lost communication and were forced to fend for ourselves.
Removed the training wheels.
It got tougher to gain instructions from those above me, and new employees told me their roles weren't as advertised.
External money-focused managers were hired.
Instead of creative types, we hired salespeople.
With a new focus on numbers, Adore's uniqueness began to crumble.
Via Zoom, hundreds of workers were let go.
So.
Early in 2022, mass Zoom firings were trending. A CEO firing 900 workers over Zoom went viral.
Adore was special to me, but it became a headline.
30 June 2022, Vice Motherboard published Watch as Adore's CEO Fires Hundreds.
It described a leaked video of Jon Swanson laying off all staff in Canada and the UK.
They called it a “notice of redundancy”.
The corporation couldn't pay its employees.
I loved Adore's underlying ideals, among other things. We called clients Adorers and sold solutions, not add-ons.
But, like anything, a company is only as strong as its weakest link. And obviously, the people-first focus wasn’t making enough money.
There were signs. The expansion was presumably a race against time and money.
Adore finally declared bankruptcy.
Adore declared bankruptcy 3 months after going public. It happened in waves, like any large-scale fall.
Initial key players to leave were
Then, communication deteriorated.
Lastly, the corporate culture disintegrated.
6 months after leaving Adore, I received a letter in the mail from a Law firm — it was about my stocks.
Adore filed Chapter 11. I had to sue to collect my worthless investments.
I hoped those stocks will be valuable someday. Nope. Nope.
Sad, I sighed.
$1.2 billion firm gone.
I left the workplace 3 months before starting a writing business. Despite being mediocre, I'm doing fine.
I got up as Adore fell.
Finally, can we scale kindness?
I trust my gut. Changes at Adore made me leave before it sank.
Adores' unceremonious slide from a top startup to bankruptcy is astonishing to me.
The company did everything perfectly, in my opinion.
first to market,
provided excellent service
paid their staff handsomely.
was responsible and attentive to criticism
The company wasn't led by an egotistical eccentric. The crew had centuries of cumulative space experience.
I'm optimistic about the future of work culture, but is compassion scalable?

SAHIL SAPRU
3 years ago
How I grew my business to a $5 million annual recurring revenue
Scaling your startup requires answering customer demands, not growth tricks.
I cofounded Freedo Rentals in 2019. I reached 50 lakh+ ARR in 6 months before quitting owing to the epidemic.
Freedo aimed to solve 2 customer pain points:
Users lacked a reliable last-mile transportation option.
The amount that Auto walas charge for unmetered services
Solution?
Effectively simple.
Build ports at high-demand spots (colleges, residential societies, metros). Electric ride-sharing can meet demand.
We had many problems scaling. I'll explain using the AARRR model.
Brand unfamiliarity or a novel product offering were the problems with awareness. Nobody knew what Freedo was or what it did.
Problem with awareness: Content and advertisements did a poor job of communicating the task at hand. The advertisements clashed with the white-collar part because they were too cheesy.
Retention Issue: We encountered issues, indicating that the product was insufficient. Problems with keyless entry, creating bills, stealing helmets, etc.
Retention/Revenue Issue: Costly compared to established rivals. Shared cars were 1/3 of our cost.
Referral Issue: Missing the opportunity to seize the AHA moment. After the ride, nobody remembered us.
Once you know where you're struggling with AARRR, iterative solutions are usually best.
Once you have nailed the AARRR model, most startups use paid channels to scale. This dependence, on paid channels, increases with scale unless you crack your organic/inbound game.
Over-index growth loops. Growth loops increase inflow and customers as you scale.
When considering growth, ask yourself:
Who is the solution's ICP (Ideal Customer Profile)? (To whom are you selling)
What are the most important messages I should convey to customers? (This is an A/B test.)
Which marketing channels ought I prioritize? (Conduct analysis based on the startup's maturity/stage.)
Choose the important metrics to monitor for your AARRR funnel (not all metrics are equal)
Identify the Flywheel effect's growth loops (inertia matters)
My biggest mistakes:
not paying attention to consumer comments or satisfaction. It is the main cause of problems with referrals, retention, and acquisition for startups. Beyond your NPS, you should consider second-order consequences.
The tasks at hand should be quite clear.
Here's my scaling equation:
Growth = A x B x C
A = Funnel top (Traffic)
B = Product Valuation (Solving a real pain point)
C = Aha! (Emotional response)
Freedo's A, B, and C created a unique offering.
Freedo’s ABC:
A — Working or Studying population in NCR
B — Electric Vehicles provide last-mile mobility as a clean and affordable solution
C — One click booking with a no-noise scooter
Final outcome:
FWe scaled Freedo to Rs. 50 lakh MRR and were growing 60% month on month till the pandemic ceased our growth story.
How we did it?
We tried ambassadors and coupons. WhatsApp was our most successful A/B test.
We grew widespread adoption through college and society WhatsApp groups. We requested users for referrals in community groups.
What worked for us won't work for others. This scale underwent many revisions.
Every firm is different, thus you must know your customers. Needs to determine which channel to prioritize and when.
Users desired a safe, time-bound means to get there.
This (not mine) growth framework helped me a lot. You should follow suit.