



More on Personal Growth

Tim Denning
3 years ago
Read These Books on Personal Finance to Boost Your Net Worth
And retire sooner.

Books can make you filthy rich.
If you apply what you learn. In 2011, I was broke and had broken dreams.
Someone suggested I read finance books. One Up On Wall Street was his first recommendation.
Finance books were my crack.
I've read every money book since then. Some are good, but most stink.
These books will make you rich.
The Almanack of Naval Ravikant by Eric Jorgenson
This isn't a cliche book.
This book was inspired by a How to Get Rich tweet thread.
It’s one of the best tweets I’ve ever read.
Naval thinks differently. He nukes ordinary ideas. I've never heard better money advice.
Eric Jorgenson wrote a book about this tweet thread with Navals permission. A must-read, easy-to-digest book.
Best quote
Seek wealth, not money or status. Wealth is having assets that earn while you sleep. Money is how we transfer time and wealth. Status is your place in the social hierarchy — Naval
Morgan Housel's The Psychology of Money
Many finance books advise investing like a dunce.
They almost all peddle the buy an index fund BS. Different book.
It's about money-making psychology. Because any fool can get rich and drunk on their ego. Few can consistently make money.
Each chapter is short. A single-page chapter breaks all book publishing rules.
Best quote
Spending money to show people how much money you have is the fastest way to have less money — Morgan Housel
J.L. Collins' The Simple Path to Wealth
Most of the best money books were written by bloggers.
JL Collins blogs. This easy-to-read book was written for his daughter.
This book popularized the phrase F You Money. With enough money in your bank account and investment portfolio, you can say F You more.
A bad boss is an example. You can leave instead of enduring his wrath.
You can then sit at home and look for another job while financially secure. JL says its mind-freedom is powerful.
Best phrasing
You own the things you own and they in turn own you — J.L. Collins
Tony Robbins' Unshakeable
I like Tony. This book makes me sweaty.
Tony interviews the world's top financiers. He interviews people who rarely do so.
This book taught me all-weather portfolio. It's a way to invest in different asset classes in good, bad, recession, or depression times.
Look at it:
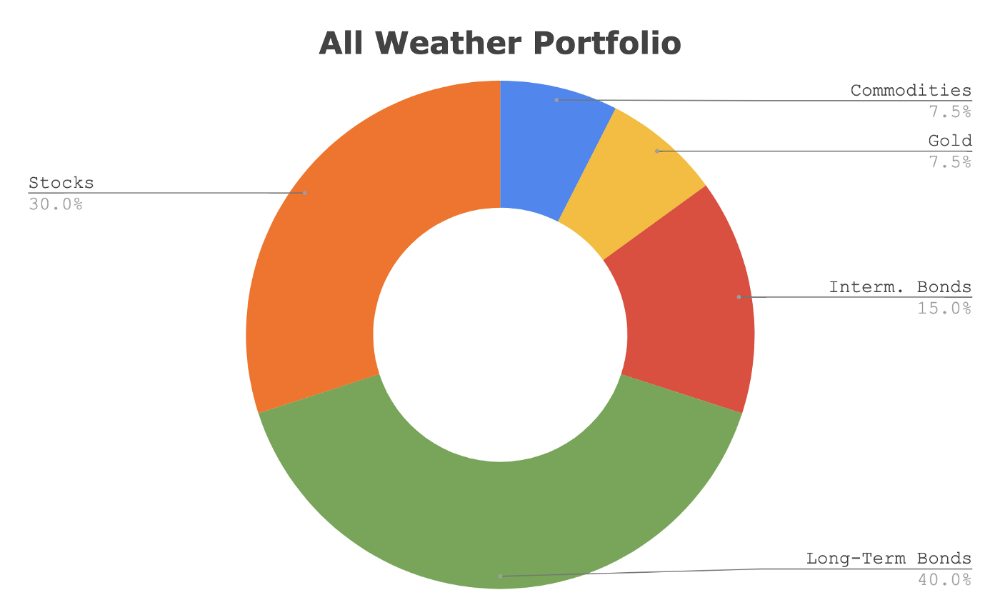
Investing isn’t about buying one big winner — that’s gambling. It’s about investing in a diversified portfolio of assets.
Best phrasing
The best opportunities come in times of maximum pessimism — Tony Robbins
Ben Graham's The Intelligent Investor
This book helped me distinguish between a spectator and an investor.
Spectators are those who shout that crypto, NFTs, or XYZ platform will die.
Tourists. They want attention and to say "I told you so." They make short-term and long-term predictions like fortunetellers. LOL. Idiots.
Benjamin Graham teaches smart investing. You'll buy a long-term asset. To be confident in recessions, use dollar-cost averaging.
Best phrasing
Those who do not remember the past are condemned to repeat it. — Benjamin Graham
The Napoleon Hill book Think and Grow Rich
This classic book introduced positive thinking to modern self-help.
Lazy pessimists can't become rich. No way.
Napoleon said, "Thoughts create reality."
No surprise that he discusses obsession and focus in this book. They are the fastest ways to make more money to invest in time and wealth-protecting assets.
Best phrasing
The starting point of all achievement is DESIRE. Keep this constantly in mind. Weak desire brings weak results, just as a small fire makes a small amount of heat — Napoleon Hill
Ramit Sethi's book I Will Teach You To Be Rich
This book is mostly good. The part about credit cards is trash.
Avoid credit card temptations. I don't care about their airline points.
This book teaches you to master money basics (that many people mess up) then automate it so your monkey brain doesn't ruin your financial future.
The book includes great negotiation tactics to help you make more money in less time.
Best quote
The 85 Percent Solution: Getting started is more important than becoming an expert — Ramit Sethi
David Bach's The Automatic Millionaire
You've probably met a six- or seven-figure earner who's broke. All their money goes to useless things like cars.
Money isn't as essential as what you do with it. David teaches how to automate your earnings for more money.
Compounding works once investing is automated. So you get rich.
His strategy eliminates luck and (almost) guarantees millionaire status.
Best phrasing
Every time you earn one dollar, make sure to pay yourself first — David Bach
Thomas J. Stanley's The Millionaire Next Door
Thomas defies the definition of rich.
He spends much of the book highlighting millionaire traits he's studied.
Rich people are quiet, so you wouldn't know they're wealthy. They don't earn much money or drive a BMW.
Thomas will give you the math to get started.
Best phrasing
I am not impressed with what people own. But I’m impressed with what they achieve. I’m proud to be a physician. Always strive to be the best in your field…. Don’t chase money. If you are the best in your field, money will find you. — Thomas J. Stanley
by Bill Perkins "Die With Zero"
Let’s end with one last book.
Bill's book angered many people. He says we spend too much time saving for retirement and die rich. That bank money is lost time.
Your grandkids could use the money. When children inherit money, they become lazy, entitled a-holes.
Bill wants us to spend our money on life-enhancing experiences. Stop saving money like monopoly monkeys.
Best phrasing
You should be focusing on maximizing your life enjoyment rather than on maximizing your wealth. Those are two very different goals. Money is just a means to an end: Having money helps you to achieve the more important goal of enjoying your life. But trying to maximize money actually gets in the way of achieving the more important goal — Bill Perkins

Alex Mathers
3 years ago Draft
12 practices of the zenith individuals I know
Calmness is a vital life skill.
It aids communication. It boosts creativity and performance.
I've studied calm people's habits for years. Commonalities:
Have learned to laugh at themselves.
Those who have something to protect can’t help but make it a very serious business, which drains the energy out of the room.
They are fixated on positive pursuits like making cool things, building a strong physique, and having fun with others rather than on depressing influences like the news and gossip.
Every day, spend at least 20 minutes moving, whether it's walking, yoga, or lifting weights.
Discover ways to take pleasure in life's challenges.
Since perspective is malleable, they change their view.
Set your own needs first.
Stressed people neglect themselves and wonder why they struggle.
Prioritize self-care.
Don't ruin your life to please others.
Make something.
Calm people create more than react.
They love creating beautiful things—paintings, children, relationships, and projects.
Hold your breath, please.
If you're stressed or angry, you may be surprised how much time you spend holding your breath and tightening your belly.
Release, breathe, and relax to find calm.
Stopped rushing.
Rushing is disadvantageous.
Calm people handle life better.
Are attuned to their personal dietary needs.
They avoid junk food and eat foods that keep them healthy, happy, and calm.
Don’t take anything personally.
Stressed people control everything.
Self-conscious.
Calm people put others and their work first.
Keep their surroundings neat.
Maintaining an uplifting and clutter-free environment daily calms the mind.
Minimise negative people.
Calm people are ruthless with their boundaries and avoid negative and drama-prone people.

Jari Roomer
3 years ago
After 240 articles and 2.5M views on Medium, 9 Raw Writing Tips
Late in 2018, I published my first Medium article, but I didn't start writing seriously until 2019. Since then, I've written more than 240 articles, earned over $50,000 through Medium's Partner Program, and had over 2.5 million page views.
Write A Lot
Most people don't have the patience and persistence for this simple writing secret:
Write + Write + Write = possible success
Writing more improves your skills.
The more articles you publish, the more likely one will go viral.
If you only publish once a month, you have no views. If you publish 10 or 20 articles a month, your success odds increase 10- or 20-fold.
Tim Denning, Ayodeji Awosika, Megan Holstein, and Zulie Rane. Medium is their jam. How are these authors alike? They're productive and consistent. They're prolific.
80% is publishable
Many writers battle perfectionism.
To succeed as a writer, you must publish often. You'll never publish if you aim for perfection.
Adopt the 80 percent-is-good-enough mindset to publish more. It sounds terrible, but it'll boost your writing success.
Your work won't be perfect. Always improve. Waiting for perfection before publishing will take a long time.
Second, readers are your true critics, not you. What you consider "not perfect" may be life-changing for the reader. Don't let perfectionism hinder the reader.
Don't let perfectionism hinder the reader. ou don't want to publish mediocre articles. When the article is 80% done, publish it. Don't spend hours editing. Realize it. Get feedback. Only this will work.
Make Your Headline Irresistible
We all judge books by their covers, despite the saying. And headlines. Readers, including yourself, judge articles by their titles. We use it to decide if an article is worth reading.
Make your headlines irresistible. Want more article views? Then, whether you like it or not, write an attractive article title.
Many high-quality articles are collecting dust because of dull, vague headlines. It didn't make the reader click.
As a writer, you must do more than produce quality content. You must also make people click on your article. This is a writer's job. How to create irresistible headlines:
Curiosity makes readers click. Here's a tempting example...
Example: What Women Actually Look For in a Guy, According to a Huge Study by Luba Sigaud
Use Numbers: Click-bait lists. I mean, which article would you click first? ‘Some ways to improve your productivity’ or ’17 ways to improve your productivity.’ Which would I click?
Example: 9 Uncomfortable Truths You Should Accept Early in Life by Sinem Günel
Most headlines are dull. If you want clicks, get 'sexy'. Buzzword-ify. Invoke emotion. Trendy words.
Example: 20 Realistic Micro-Habits To Live Better Every Day by Amardeep Parmar
Concise paragraphs
Our culture lacks focus. If your headline gets a click, keep paragraphs short to keep readers' attention.
Some writers use 6–8 lines per paragraph, but I prefer 3–4. Longer paragraphs lose readers' interest.
A writer should help the reader finish an article, in my opinion. I consider it a job requirement. You can't force readers to finish an article, but you can make it 'snackable'
Help readers finish an article with concise paragraphs, interesting subheadings, exciting images, clever formatting, or bold attention grabbers.
Work And Move On
I've learned over the years not to get too attached to my articles. Many writers report a strange phenomenon:
The articles you're most excited about usually bomb, while the ones you're not tend to do well.
This isn't always true, but I've noticed it in my own writing. My hopes for an article usually make it worse. The more objective I am, the better an article does.
Let go of a finished article. 40 or 40,000 views, whatever. Now let the article do its job. Onward. Next story. Start another project.
Disregard Haters
Online content creators will encounter haters, whether on YouTube, Instagram, or Medium. More views equal more haters. Fun, right?
As a web content creator, I learned:
Don't debate haters. Never.
It's a mistake I've made several times. It's tempting to prove haters wrong, but they'll always find a way to be 'right'. Your response is their fuel.
I smile and ignore hateful comments. I'm indifferent. I won't enter a negative environment. I have goals, money, and a life to build. "I'm not paid to argue," Drake once said.
Use Grammarly
Grammarly saves me as a non-native English speaker. You know Grammarly. It shows writing errors and makes article suggestions.
As a writer, you need Grammarly. I have a paid plan, but their free version works. It improved my writing greatly.
Put The Reader First, Not Yourself
Many writers write for themselves. They focus on themselves rather than the reader.
Ask yourself:
This article teaches what? How can they be entertained or educated?
Personal examples and experiences improve writing quality. Don't focus on yourself.
It's not about you, the content creator. Reader-focused. Putting the reader first will change things.
Extreme ownership: Stop blaming others
I remember writing a lot on Medium but not getting many views. I blamed Medium first. Poor algorithm. Poor publishing. All sucked.
Instead of looking at what I could do better, I blamed others.
When you blame others, you lose power. Owning your results gives you power.
As a content creator, you must take full responsibility. Extreme ownership means 100% responsibility for work and results.
You don’t blame others. You don't blame the economy, president, platform, founders, or audience. Instead, you look for ways to improve. Few people can do this.
Blaming is useless. Zero. Taking ownership of your work and results will help you progress. It makes you smarter, better, and stronger.
Instead of blaming others, you'll learn writing, marketing, copywriting, content creation, productivity, and other skills. Game-changer.
You might also like

joyce shen
4 years ago
Framework to Evaluate Metaverse and Web3
Everywhere we turn, there's a new metaverse or Web3 debut. Microsoft recently announced a $68.7 BILLION cash purchase of Activision.
Like AI in 2013 and blockchain in 2014, NFT growth in 2021 feels like this year's metaverse and Web3 growth. We are all bombarded with information, conflicting signals, and a sensation of FOMO.
How can we evaluate the metaverse and Web3 in a noisy, new world? My framework for evaluating upcoming technologies and themes is shown below. I hope you will also find them helpful.
Understand the “pipes” in a new space.
Whatever people say, Metaverse and Web3 will have to coexist with the current Internet. Companies who host, move, and store data over the Internet have a lot of intriguing use cases in Metaverse and Web3, whether in infrastructure, data analytics, or compliance. Hence the following point.
## Understand the apps layer and their infrastructure.
Gaming, crypto exchanges, and NFT marketplaces would not exist today if not for technology that enables rapid app creation. Yes, according to Chainalysis and other research, 30–40% of Ethereum is self-hosted, with the rest hosted by large cloud providers. For Microsoft to acquire Activision makes strategic sense. It's not only about the games, but also the infrastructure that supports them.
Follow the money
Understanding how money and wealth flow in a complex and dynamic environment helps build clarity. Unless you are exceedingly wealthy, you have limited ability to significantly engage in the Web3 economy today. Few can just buy 10 ETH and spend it in one day. You must comprehend who benefits from the process, and how that 10 ETH circulates now and possibly tomorrow. Major holders and players control supply and liquidity in any market. Today, most Web3 apps are designed to increase capital inflow so existing significant holders can utilize it to create a nascent Web3 economy. When you see a new Metaverse or Web3 application, remember how money flows.
What is the use case?
What does the app do? If there is no clear use case with clear makers and consumers solving a real problem, then the euphoria soon fades, and the only stakeholders who remain enthused are those who have too much to lose.
Time is a major competition that is often overlooked.
We're only busier, but each day is still 24 hours. Using new apps may mean that time is lost doing other things. The user must be eager to learn. Metaverse and Web3 vs. our time? I don't think we know the answer yet (at least for working adults whose cost of time is higher).
I don't think we know the answer yet (at least for working adults whose cost of time is higher).
People and organizations need security and transparency.
For new technologies or apps to be widely used, they must be safe, transparent, and trustworthy. What does secure Metaverse and Web3 mean? This is an intriguing subject for both the business and public sectors. Cloud adoption grew in part due to improved security and data protection regulations.
The following frameworks can help analyze and understand new technologies and emerging technological topics, unless you are a significant investment fund with the financial ability to gamble on numerous initiatives and essentially form your own “index fund”.
I write on VC, startups, and leadership.
More on https://www.linkedin.com/in/joycejshen/ and https://joyceshen.substack.com/
This writing is my own opinion and does not represent investment advice.

Will Lockett
2 years ago
There Is A New EV King in Town

McMurtry Spéirling outperforms Tesla in speed and efficiency.
EVs were ridiculously slow for decades. However, the 2008 Tesla Roadster revealed that EVs might go extraordinarily fast. The Tesla Model S Plaid and Rimac Nevera are the fastest-accelerating road vehicles, despite combustion-engined road cars dominating the course. A little-known firm beat Tesla and Rimac in the 0-60 race, beat F1 vehicles on a circuit, and boasts a 350-mile driving range. The McMurtry Spéirling is completely insane.
Mat Watson of CarWow, a YouTube megastar, was recently handed a Spéirling and access to Silverstone Circuit (view video above). Mat ran a quarter-mile on Silverstone straight with former F1 driver Max Chilton. The little pocket-rocket automobile touched 100 mph in 2.7 seconds, completed the quarter mile in 7.97 seconds, and hit 0-60 in 1.4 seconds. When looking at autos quickly, 0-60 times can seem near. The Tesla Model S Plaid does 0-60 in 1.99 seconds, which is comparable to the Spéirling. Despite the meager statistics, the Spéirling is nearly 30% faster than Plaid!
My vintage VW Golf 1.4s has an 8.8-second 0-60 time, whereas a BMW Z4 3.0i is 30% faster (with a 0-60 time of 6 seconds). I tried to beat a Z4 off the lights in my Golf, but the Beamer flew away. If they challenge the Spéirling in a Model S Plaid, they'll feel as I did. Fast!
Insane quarter-mile drag time. Its road car record is 7.97 seconds. A Dodge Demon, meant to run extremely fast quarter miles, finishes so in 9.65 seconds, approximately 20% slower. The Rimac Nevera's 8.582-second quarter-mile record was miles behind drag racing. This run hampered the Spéirling. Because it was employing gearing that limited its top speed to 150 mph, it reached there in a little over 5 seconds without accelerating for most of the quarter mile! McMurtry can easily change the gearing, making the Spéirling run quicker.
McMurtry did this how? First, the Spéirling is a tiny single-seater EV with a 60 kWh battery pack, making it one of the lightest EVs ever. The 1,000-hp Spéirling has more than one horsepower per kg. The Nevera has 0.84 horsepower per kg and the Plaid 0.44.
However, you cannot simply construct a car light and power it. Instead of accelerating, it would spin. This makes the Spéirling a fan car. Its huge fans create massive downforce. These fans provide the Spéirling 2 tonnes of downforce while stationary, so you could park it on the ceiling. Its fast 0-60 time comes from its downforce, which lets it deliver all that power without wheel spin.
It also possesses complete downforce at all speeds, allowing it to tackle turns faster than even race vehicles. Spéirlings overcame VW IDRs and F1 cars to set the Goodwood Hill Climb record (read more here). The Spéirling is a dragstrip winner and track dominator, unlike the Plaid and Nevera.
The Spéirling is astonishing for a single-seater. Fan-generated downforce is more efficient than wings and splitters. It also means the vehicle has very minimal drag without the fan. The Spéirling can go 350 miles per charge (WLTP) or 20-30 minutes at full speed on a track despite its 60 kWh battery pack. The G-forces would hurt your neck before the battery died if you drove around a track for longer. The Spéirling can charge at over 200 kW in about 30 minutes. Thus, driving to track days, having fun, and returning is possible. Unlike other high-performance EVs.
Tesla, Rimac, or Lucid will struggle to defeat the Spéirling. They would need to build a fan automobile because adding power to their current vehicle would make it uncontrollable. The EV and automobile industries now have a new, untouchable performance king.
Alex Mathers
3 years ago
8 guidelines to help you achieve your objectives 5x fast

If you waste time every day, even though you're ambitious, you're not alone.
Many of us could use some new time-management strategies, like these:
Focus on the following three.
You're thinking about everything at once.
You're overpowered.
It's mental. We just have what's in front of us. So savor the moment's beauty.
Prioritize 1-3 things.
To be one of the most productive people you and I know, follow these steps.
Get along with boredom.
Many of us grow bored, sweat, and turn on Netflix.
We shout, "I'm rarely bored!" Look at me! I'm happy.
Shut it, Sally.
You're not making wonderful things for the world. Boredom matters.
If you can sit with it for a second, you'll get insight. Boredom? Breathe.
Go blank.
Then watch your creativity grow.
Check your MacroVision once more.
We don't know what to do with our time, which contributes to time-wasting.
Nobody does, either. Jeff Bezos won't hand-deliver that crap to you.
Daily vision checks are required.
Also:
What are 5 things you'd love to create in the next 5 years?
You're soul-searching. It's food.
Return here regularly, and you'll adore the high you get from doing valuable work.
Improve your thinking.
What's Alex's latest nonsense?
I'm talking about overcoming our own thoughts. Worrying wastes so much time.
Too many of us are assaulted by lies, myths, and insecurity.
Stop letting your worries massage you into a worried coma like a Thai woman.
Optimizing your thoughts requires accepting what you can't control.
It means letting go of unhelpful thoughts and returning to the moment.
Keep your blood sugar level.
I gave up gluten, donuts, and sweets.
This has really boosted my energy.
Blood-sugar-spiking carbs make us irritable and tired.
These day-to-day ups and downs aren't productive. It's crucial.
Know how your diet affects insulin levels. Now I have more energy and can do more without clenching my teeth.
Reduce harmful carbs to boost energy.
Create a focused setting for yourself.
When we optimize the mind, we have more energy and use our time better because we're not tense.
Changing our environment can also help us focus. Disabling alerts is one example.
Too hot makes me procrastinate and irritable.
List five items that hinder your productivity.
You may be amazed at how much you may improve by removing distractions.
Be responsible.
Accountability is a time-saver.
Creating an emotional pull to finish things.
Writing down our goals makes us accountable.
We can engage a coach or work with an accountability partner to feel horrible if we don't show up and finish on time.
‘Hey Jake, I’m going to write 1000 words every day for 30 days — you need to make sure I do.’ ‘Sure thing, Nathan, I’ll be making sure you check in daily with me.’
Tick.
You might also blog about your ambitions to show your dedication.
Now you can't hide when you promised to appear.
Acquire a liking for bravery.
Boldness changes everything.
I sometimes feel lazy and wonder why. If my food and sleep are in order, I should assess my footing.
Most of us live backward. Doubtful. Uncertain. Feelings govern us.
Backfooting isn't living. It's lame, and you'll soon melt. Live boldly now.
Be assertive.
Get disgustingly into everything. Expand.
Even if it's hard, stop being a b*tch.
Those that make Mr. Bold Bear their spirit animal benefit. Save time to maximize your effect.