




More on Entrepreneurship/Creators

Grace Huang
3 years ago
I sold 100 copies of my book when I had anticipated selling none.
After a decade in large tech, I know how software engineers were interviewed. I've seen outstanding engineers fail interviews because their responses were too vague.
So I wrote Nail A Coding Interview: Six-Step Mental Framework. Give candidates a mental framework for coding questions; help organizations better prepare candidates so they can calibrate traits.
Recently, I sold more than 100 books, something I never expected.
In this essay, I'll describe my publication journey, which included self-doubt and little triumphs. I hope this helps if you want to publish.
It was originally a Medium post.
How did I know to develop a coding interview book? Years ago, I posted on Medium.
Six steps to ace a coding interview Inhale. blog.devgenius.io
This story got a lot of attention and still gets a lot of daily traffic. It indicates this domain's value.
Converted the Medium article into an ebook
The Medium post contains strong bullet points, but it is missing the “flesh”. How to use these strategies in coding interviews, for example. I filled in the blanks and made a book.
I made the book cover for free. It's tidy.
Shared the article with my close friends on my social network WeChat.
I shared the book on Wechat's Friend Circle (朋友圈) after publishing it on Gumroad. Many friends enjoyed my post. It definitely triggered endorphins.
In Friend Circle, I presented a 100% off voucher. No one downloaded the book. Endorphins made my heart sink.
Several days later, my Apple Watch received a Gumroad notification. A friend downloaded it. I majored in finance, he subsequently said. My brother-in-law can get it? He downloaded it to cheer me up.
I liked him, but was disappointed that he didn't read it.
The Tipping Point: Reddit's Free Giving
I trusted the book. It's based on years of interviewing. I felt it might help job-hunting college students. If nobody wants it, it can still have value.
I posted the book's link on /r/leetcode. I told them to DM me for a free promo code.
Momentum shifted everything. Gumroad notifications kept coming when I was out with family. Following orders.
As promised, I sent DMs a promo code. Some consumers ordered without asking for a promo code. Some readers finished the book and posted reviews.
My book was finally on track.
A 5-Star Review, plus More
A reader afterwards DMed me and inquired if I had another book on system design interviewing. I said that was a good idea, but I didn't have one. If you write one, I'll be your first reader.
Later, I asked for a book review. Yes, but how? That's when I learned readers' reviews weren't easy. I built up an email pipeline to solicit customer reviews. Since then, I've gained credibility through ratings.
Learnings
I wouldn't have gotten 100 if I gave up when none of my pals downloaded. Here are some lessons.
Your friends are your allies, but they are not your clients.
Be present where your clients are
Request ratings and testimonials
gain credibility gradually
I did it, so can you. Follow me on Twitter @imgracehuang for my publishing and entrepreneurship adventure.

Rachel Greenberg
3 years ago
The Unsettling Fact VC-Backed Entrepreneurs Don't Want You to Know
What they'll do is scarier.

My acquaintance recently joined a VC-funded startup. Money, equity, and upside possibilities were nice, but he had a nagging dread.
They just secured a $40M round and are hiring like crazy to prepare for their IPO in two years. All signals pointed to this startup's (a B2B IT business in a stable industry) success, and its equity-holding workers wouldn't pass that up.
Five months after starting the work, my friend struggled with leaving. We might overlook the awful culture and long hours at the proper price. This price plus the company's fate and survival abilities sent my friend departing in an unpleasant unplanned resignation before jumping on yet another sinking ship.
This affects founders. This affects VC-backed companies (and all businesses). This affects anyone starting, buying, or running a business.
Here's the under-the-table approach that's draining VC capital, leaving staff terrified (or jobless), founders rattled, and investors upset. How to recognize, solve, and avoid it
The unsettling reality behind door #1
You can't raise money off just your looks, right? If "looks" means your founding team's expertise, then maybe. In my friend's case, the founding team's strong qualifications and track records won over investors before talking figures.
They're hardly the only startup to raise money without a profitable customer acquisition strategy. Another firm raised money for an expensive sleep product because it's eco-friendly. They were off to the races with a few keywords and key players.
Both companies, along with numerous others, elected to invest on product development first. Company A employed all the tech, then courted half their market (they’re a tech marketplace that connects two parties). Company B spent millions on R&D to create a palatable product, then flooded the world with marketing.
My friend is on Company B's financial team, and he's seen where they've gone wrong. It's terrible.
Company A (tech market): Growing? Not quite. To achieve the ambitious expansion they (and their investors) demand, they've poured much of their little capital into salespeople: Cold-calling commission and salary salesmen. Is it working? Considering attrition and companies' dwindling capital, I don't think so.
Company B (green sleep) has been hiring, digital marketing, and opening new stores like crazy. Growing expenses should result in growing revenues and a favorable return on investment; if you grow too rapidly, you may neglect to check that ROI.
Once Company A cut headcount and Company B declared “going concerned”, my friend realized both startups had the same ailment and didn't recognize it.
I shouldn't have to ask a friend to verify a company's cash reserves and profitability to spot a financial problem. It happened anyhow.
The frightening part isn't that investors were willing to invest millions without product-market fit, CAC, or LTV estimates. That's alarming, but not as scary as the fact that startups aren't understanding the problem until VC rounds have dried up.
When they question consultants if their company will be around in 6 months. It’s a red flag. How will they stretch $20M through a 2-year recession with a $3M/month burn rate and no profitability? Alarms go off.
Who's in danger?
In a word, everyone who raised money without a profitable client acquisition strategy or enough resources to ride out dry spells.
Money mismanagement and poor priorities affect every industry (like sinking all your capital into your product, team, or tech, at the expense of probing what customer acquisition really takes and looks like).
This isn't about tech, real estate, or recession-proof luxury products. Fast, cheap, easy money flows into flashy-looking teams with buzzwords, trending industries, and attractive credentials.
If these companies can't show progress or get a profitable CAC, they can't raise more money. They die if they can't raise more money (or slash headcount and find shoestring budget solutions until they solve the real problem).
The kiss of death (and how to avoid it)
If you're running a startup and think raising VC is the answer, pause and evaluate. Do you need the money now?
I'm not saying VC is terrible or has no role. Founders have used it as a Band-Aid for larger, pervasive problems. Venture cash isn't a crutch for recruiting consumers profitably; it's rocket fuel to get you what and who you need.
Pay-to-play isn't a way to throw money at the wall and hope for a return. Pay-to-play works until you run out of money, and if you haven't mastered client acquisition, your cash will diminish quickly.
How can you avoid this bottomless pit? Tips:
Understand your burn rate
Keep an eye on your growth or profitability.
Analyze each and every marketing channel and initiative.
Make lucrative customer acquisition strategies and satisfied customers your top two priorities. not brand-new products. not stellar hires. avoid the fundraising rollercoaster to save time. If you succeed in these two tasks, investors will approach you with their thirsty offers rather than the other way around, and your cash reserves won't diminish as a result.
Not as much as your grandfather
My family friend always justified expensive, impractical expenditures by saying it was only monopoly money. In business, startups, and especially with money from investors expecting a return, that's not true.
More founders could understand that there isn't always another round if they viewed VC money as their own limited pool. When the well runs dry, you must refill it or save the day.
Venture financing isn't your grandpa's money. A discerning investor has entrusted you with dry powder in the hope that you'll use it wisely, strategically, and thoughtfully. Use it well.

Alex Mathers
3 years ago
400 articles later, nobody bothered to read them.
Writing for readers:
14 years of daily writing.
I post practically everything on social media. I authored hundreds of articles, thousands of tweets, and numerous volumes to almost no one.
Tens of thousands of readers regularly praise me.
I despised writing. I'm stuck now.
I've learned what readers like and what doesn't.
Here are some essential guidelines for writing with impact:
Readers won't understand your work if you can't.
Though obvious, this slipped me up. Share your truths.
Stories engage human brains.
Showing the journey of a person from worm to butterfly inspires the human spirit.
Overthinking hinders powerful writing.
The best ideas come from inner understanding in between thoughts.
Avoid writing to find it. Write.
Writing a masterpiece isn't motivating.
Write for five minutes to simplify. Step-by-step, entertaining, easy steps.
Good writing requires a willingness to make mistakes.
So write loads of garbage that you can edit into a good piece.
Courageous writing.
A courageous story will move readers. Personal experience is best.
Go where few dare.
Templates, outlines, and boundaries help.
Limitations enhance writing.
Excellent writing is straightforward and readable, removing all the unnecessary fat.
Use five words instead of nine.
Use ordinary words instead of uncommon ones.
Readers desire relatability.
Too much perfection will turn it off.
Write to solve an issue if you can't think of anything to write.
Instead, read to inspire. Best authors read.
Every tweet, thread, and novel must have a central idea.
What's its point?
This can make writing confusing.
️ Don't direct your reader.
Readers quit reading. Demonstrate, describe, and relate.
Even if no one responds, have fun. If you hate writing it, the reader will too.
You might also like

Alexandra Walker-Jones
3 years ago
These are the 15 foods you should eat daily and why.
Research on preventing disease, extending life, and caring for your body from the inside out

Grapefruit and pomegranates aren't on the list, so ignore that. Mostly, I enjoyed the visual, but those fruits are healthful, too.
15 (or 17 if you consider the photo) different foods a day sounds like a lot. If you're not used to it — it is.
These lists don't aim for perfection. Instead, use this article and the science below to eat more of these foods. If you can eat 5 foods one day and 5 the next, you're doing well. This list should be customized to your requirements and preferences.
“Every time you eat or drink, you are either feeding disease or fighting it” -Heather Morgan.
The 15 Foods That You Should Consume Daily and Why:
1. Dark/Red Berries
(blueberries, blackberries, acai, goji, cherries, strawberries, raspberries)
The 2010 Global Burden of Disease Study is the greatest definitive analysis of death and disease risk factors in history. They found the primary cause of both death, disability, and disease inside the United States was diet.
Not eating enough fruit, and specifically berries, was one of the best predictors of disease (1).
What's special about berries? It's their color! Berries have the most antioxidants of any fruit, second only to spices. The American Cancer Society found that those who ate the most berries were less likely to die of cardiovascular disease.
2. Beans
Soybeans, black beans, kidney beans, lentils, split peas, chickpeas.
Beans are one of the most important predictors of survival in older people, according to global research (2).
For every 20 grams (2 tablespoons) of beans consumed daily, the risk of death is reduced by 8%.
Soybeans and soy foods are high in phytoestrogen, which reduces breast and prostate cancer risks. Phytoestrogen blocks the receptors' access to true estrogen, mitigating the effects of weight gain, dairy (high in estrogen), and hormonal fluctuations (3).
3. Nuts
(almonds, walnuts, pecans, pistachios, Brazil nuts, cashews, hazelnuts, macadamia nuts)
Eating a handful of nuts every day reduces the risk of chronic diseases like heart disease and diabetes. Nuts also reduce oxidation, blood sugar, and LDL (bad) cholesterol, improving arterial function (4).
Despite their high-fat content, studies have linked daily nut consumption to a slimmer waistline and a lower risk of obesity (5).
4. Flaxseed
(milled flaxseed)
2013 research found that ground flaxseed had one of the strongest anti-hypertensive effects of any food. A few tablespoons (added to a smoothie or baked goods) lowered blood pressure and stroke risk 23 times more than daily aerobic exercise (6).
Flax shouldn't replace exercise, but its nutritional punch is worth adding to your diet.
5. Other seeds
(chia seeds, hemp seeds, pumpkin seeds, sesame seeds, fennel seeds)
Seeds are high in fiber and omega-3 fats and can be added to most dishes without being noticed.
When eaten with or after a meal, chia seeds moderate blood sugar and reduce inflammatory chemicals in the blood (7). Overall, a great daily addition.
6. Dates
Dates are one of the world's highest sugar foods, with 80% sugar by weight. Pure cake frosting is 60%, maple syrup is 66%, and cotton-candy jelly beans are 70%.
Despite their high sugar content, dates have a low glycemic index, meaning they don't affect blood sugar levels dramatically. They also improve triglyceride and antioxidant stress levels (8).
Dates are a great source of energy and contain high levels of dietary fiber and polyphenols, making 3-10 dates a great way to fight disease, support gut health with prebiotics, and satisfy a sweet tooth (9).
7. Cruciferous Veggies
(broccoli, Brussel sprouts, horseradish, kale, cauliflower, cabbage, boy choy, arugula, radishes, turnip greens)
Cruciferous vegetables contain an active ingredient that makes them disease-fighting powerhouses. Sulforaphane protects our brain, eyesight, against free radicals and environmental hazards, and treats and prevents cancer (10).
Unless you eat raw cruciferous vegetables daily, you won't get enough sulforaphane (and thus, its protective nutritional benefits). Cooking destroys the enzyme needed to create this super-compound.
If you chop broccoli, cauliflower, or turnip greens and let them sit for 45 minutes before cooking them, the enzyme will have had enough time to work its sulforaphane magic, allowing the vegetables to retain the same nutritional value as if eaten raw. Crazy, right? For more on this, see What Chopping Your Vegetables Has to Do with Fighting Cancer.
8. Whole grains
(barley, brown rice, quinoa, oats, millet, popcorn, whole-wheat pasta, wild rice)
Whole-grains are one of the healthiest ways to consume your daily carbs and help maintain healthy gut flora.
This happens when fibre is broken down in the colon and starts a chain reaction, releasing beneficial substances into the bloodstream and reducing the risk of Type 2 Diabetes and inflammation (11).
9. Spices
(turmeric, cumin, cinnamon, ginger, saffron, cloves, cardamom, chili powder, nutmeg, coriander)
7% of a person's cells will have DNA damage. This damage is caused by tiny breaks in our DNA caused by factors like free-radical exposure.
Free radicals cause mutations that damage lipids, proteins, and DNA, increasing the risk of disease and cancer. Free radicals are unavoidable because they result from cellular metabolism, but they can be avoided by consuming anti-oxidant and detoxifying foods.
Including spices and herbs like rosemary or ginger in our diet may cut DNA damage by 25%. Yes, this damage can be improved through diet. Turmeric worked better at a lower dose (just a pinch, daily). For maximum free-radical fighting (and anti-inflammatory) effectiveness, use 1.5 tablespoons of similar spices (12).
10. Leafy greens
(spinach, collard greens, lettuce, other salad greens, swiss chard)
Studies show that people who eat more leafy greens perform better on cognitive tests and slow brain aging by a year or two (13).
As we age, blood flow to the brain drops due to a decrease in nitric oxide, which prevents blood vessels from dilatation. Daily consumption of nitrate-rich vegetables like spinach and swiss chard may prevent dementia and Alzheimer's.
11. Fermented foods
(sauerkraut, tempeh, kombucha, plant-based kefir)
Miso, kimchi, and sauerkraut contain probiotics that support gut microbiome.
Probiotics balance the good and bad bacteria in our bodies and offer other benefits. Fermenting fruits and vegetables increases their antioxidant and vitamin content, preventing disease in multiple ways (14).
12. Sea vegetables
(seaweed, nori, dulse flakes)
A population study found that eating one sheet of nori seaweed per day may cut breast cancer risk by more than half (15).
Seaweed and sea vegetables may help moderate estrogen levels in the metabolism, reducing cancer and disease risk.
Sea vegetables make up 30% of the world's edible plants and contain unique phytonutrients. A teaspoon of these super sea-foods on your dinner will help fight disease from the inside out.
13. Water
I'm less concerned about whether you consider water food than whether you drink enough. If this list were ranked by what single item led to the best health outcomes, water would be first.
Research shows that people who drink 5 or more glasses of water per day have a 50% lower risk of dying from heart disease than those who drink 2 or less (16).
Drinking enough water boosts energy, improves skin, mental health, and digestion, and reduces the risk of various health issues, including obesity.
14. Tea
All tea consumption is linked to a lower risk of stroke, heart disease, and early death, with green tea leading for antioxidant content and immediate health benefits.
Green tea leaves may also be able to interfere with each stage of cancer formation, from the growth of the first mutated cell to the spread and progression of cancer in the body. Green tea is a quick and easy way to support your long-term and short-term health (17).
15. Supplemental B12 vitamin
B12, or cobalamin, is a vitamin responsible for cell metabolism. Not getting enough B12 can have serious consequences.
Historically, eating vegetables from untreated soil helped humans maintain their vitamin B12 levels. Due to modern sanitization, our farming soil lacks B12.
B12 is often cited as a problem only for vegetarians and vegans (as animals we eat are given B12 supplements before slaughter), but recent studies have found that plant-based eaters have lower B12 deficiency rates than any other diet (18).
Article Sources:

Jack Shepherd
3 years ago
A Dog's Guide to Every Type of Zoom Call Participant
Are you one of these Zoom dogs?
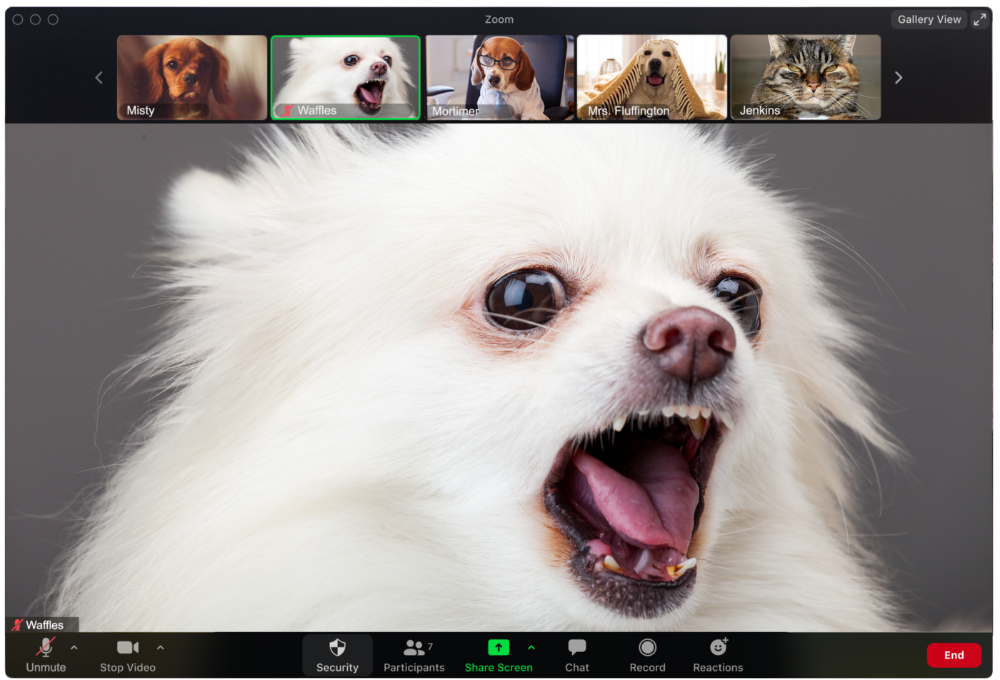
The Person Who Is Apparently Always on Mute
Waffles thinks he can overpower the mute button by shouting loudly.
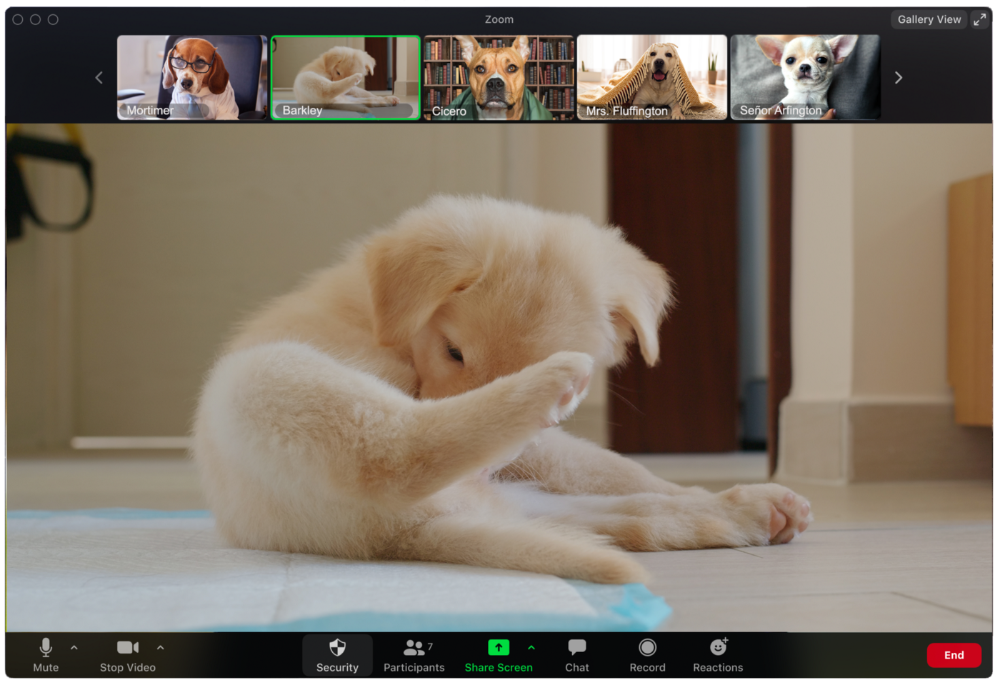
The person who believed their camera to be off
Barkley's used to remote work, but he hasn't mastered the "Stop Video" button. Everyone is affected.
Who is driving for some reason, exactly?
Why is Pumpkin always late? Who knows? Shouldn't she be driving? If you could hear her over the freeway, she'd answer these questions.
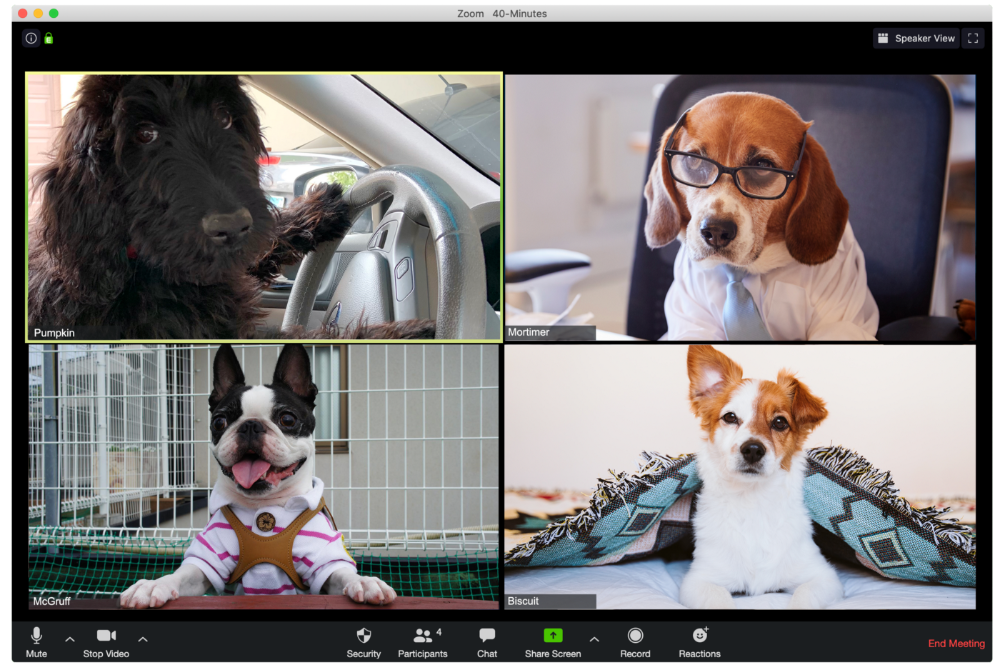
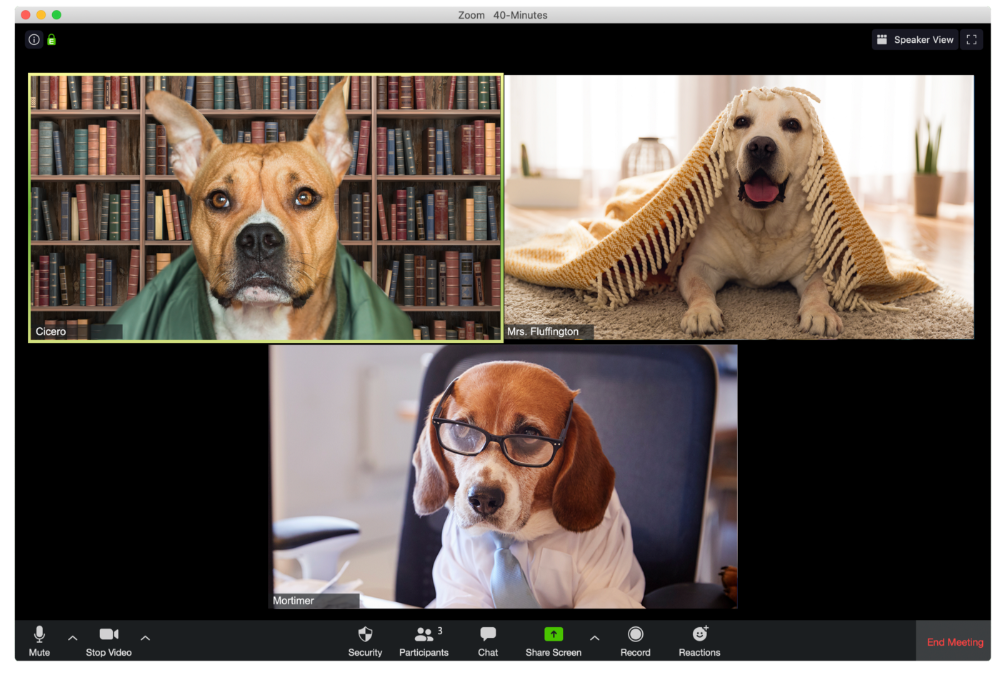
The Person With the Amazing Bookcase
Cicero likes to use SAT-words like "leverage" and "robust" in Zoom sessions, presumably from all the books he wants you to see behind him.
The Individual Who Is Unnecessarily Dressed
We hope Bandit is going somewhere beautiful after this meeting, or else he neglected the quarterly earnings report and is overcompensating to distract us.
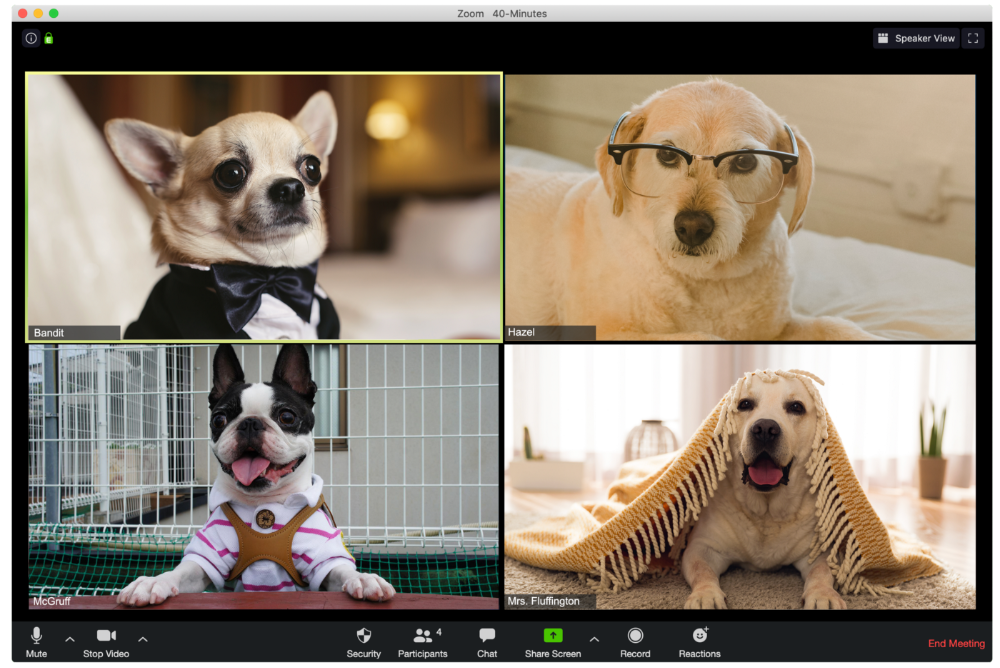
The person who works through lunch in between zoom calls
Barksworth has back-to-back meetings all day, so you can watch her eat while she talks.
The Person Who Is A Little Too Comfy
Hercules thinks Zoom meetings happen between sleeps. He'd appreciate everyone speaking more quietly.
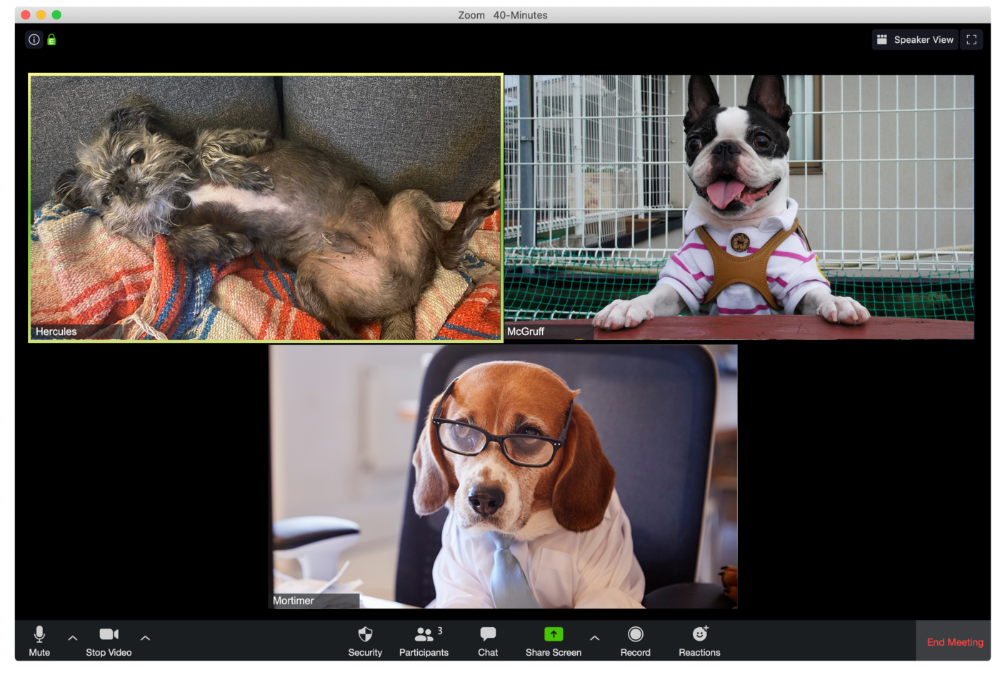
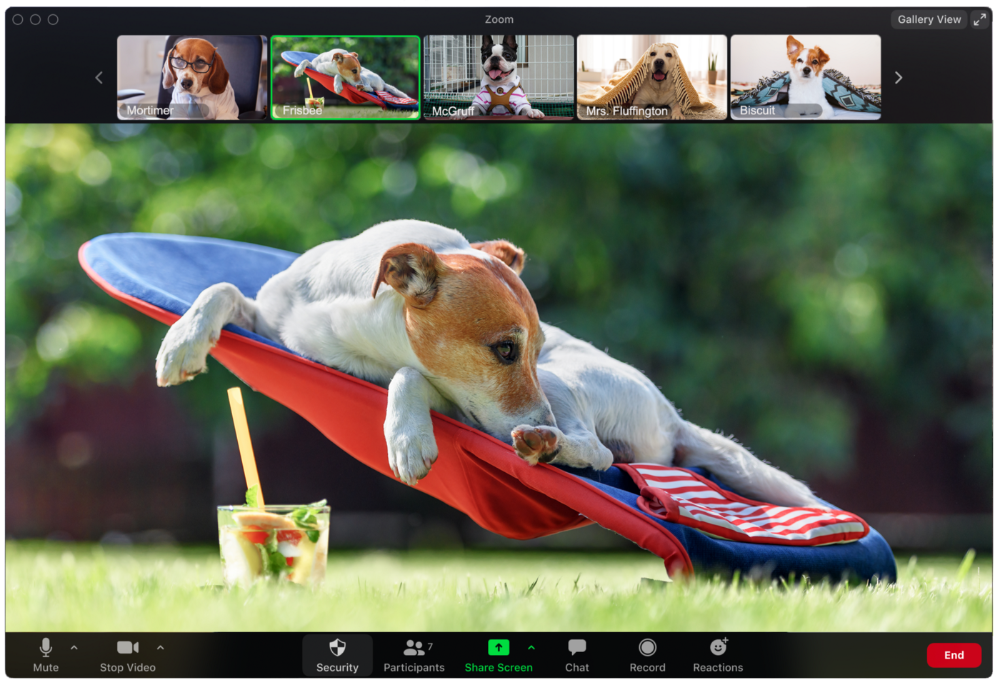
The Person Who Answered the Phone Outside
Frisbee has a gorgeous backyard and lives in a place with great weather year-round, and she wants you to think about that during the daily team huddle.
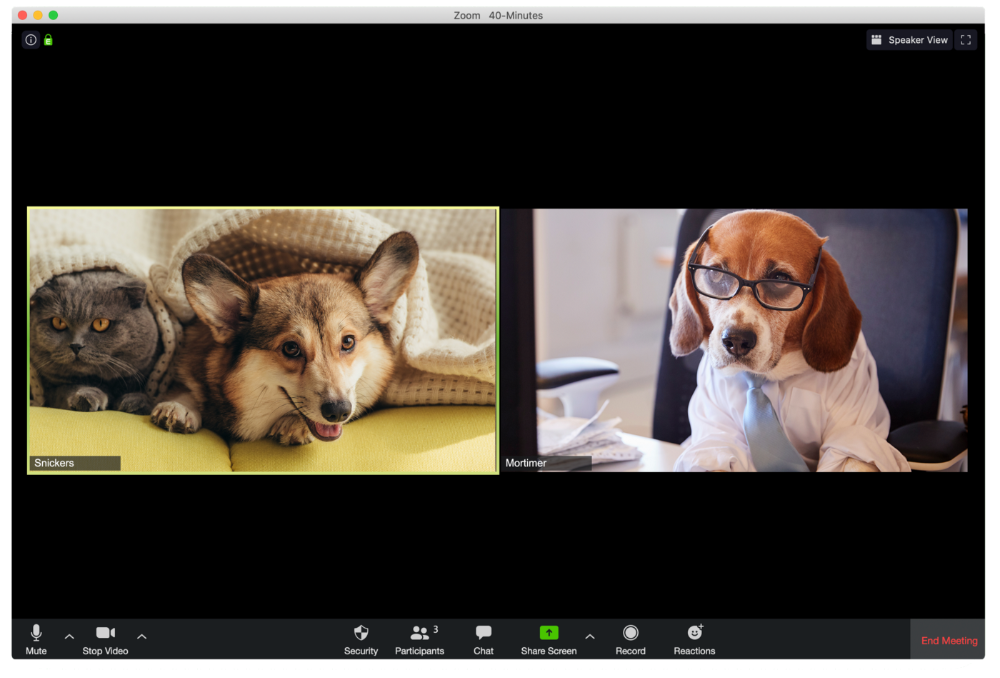
Who Wants You to Pay Attention to Their Pet
Snickers hasn't listened to you in 20 minutes unless you tell her how cute her kitten is.
One who is, for some reason, positioned incorrectly on the screen
Nelson's meetings consist primarily of attempting to figure out how he positioned his laptop so absurdly.

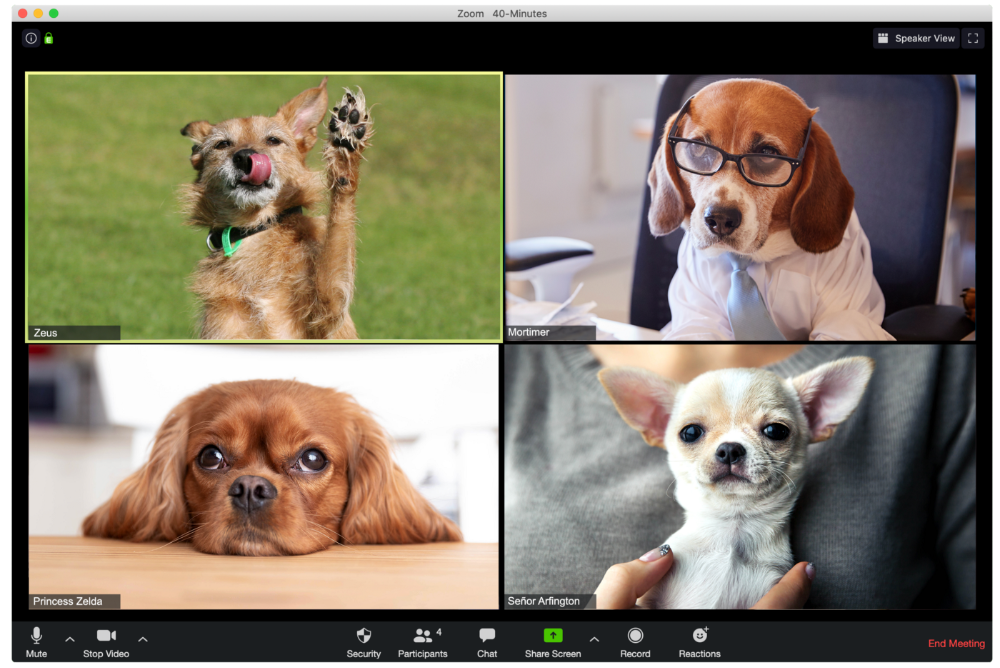
The person who says too many goodbyes
Zeus waves farewell like it's your first day of school while everyone else searches for the "Leave Meeting" button. It's nice.
He who has a poor internet connection
Ziggy's connectivity problems continue... She gives a long speech as everyone waits awkwardly to inform her they missed it.
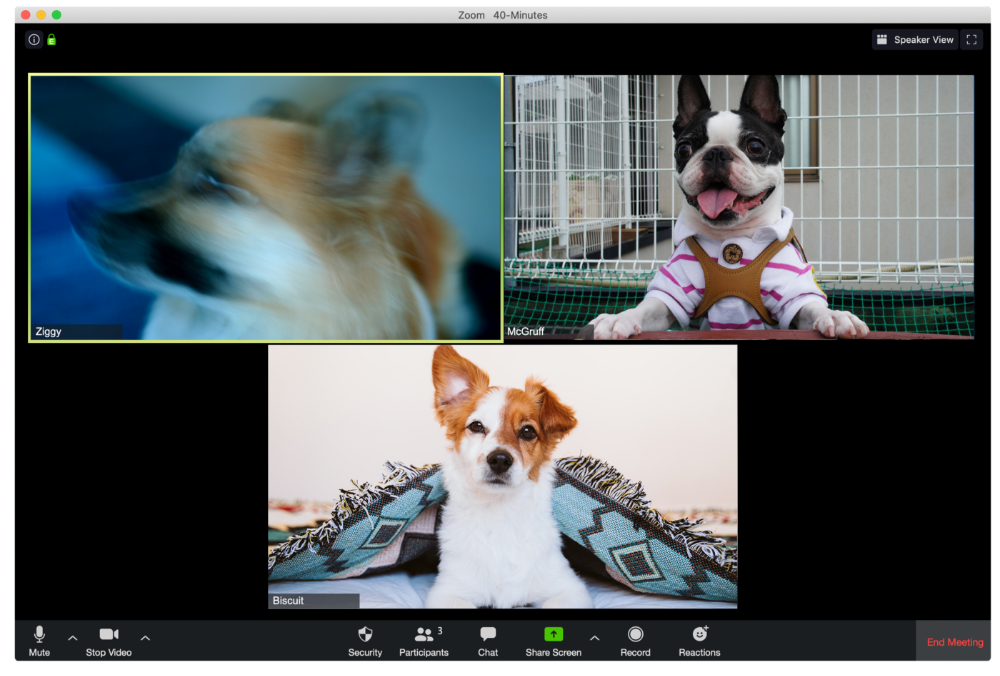
The Clearly Multitasking Person
Tinkerbell can play fetch during the monthly staff meeting if she works from home, but that's not a good idea.
The Person Using Zoom as a Makeup and Hair Mirror
If Gail and Bob knew Zoom had a "hide self view" option, they'd be distraught.

The person who feels at ease with simply leaving
Rusty bails when a Zoom conference is over. Rusty's concept is decent.

Will Lockett
3 years ago
The Unlocking Of The Ultimate Clean Energy

The company seeking 24/7 ultra-powerful solar electricity.
We're rushing to adopt low-carbon energy to prevent a self-made doomsday. We're using solar, wind, and wave energy. These low-carbon sources aren't perfect. They consume large areas of land, causing habitat loss. They don't produce power reliably, necessitating large grid-level batteries, an environmental nightmare. We can and must do better than fossil fuels. Longi, one of the world's top solar panel producers, is creating a low-carbon energy source. Solar-powered spacecraft. But how does it work? Why is it so environmentally harmonious? And how can Longi unlock it?
Space-based solar makes sense. Satellites above Medium Earth Orbit (MEO) enjoy 24/7 daylight. Outer space has no atmosphere or ozone layer to block the Sun's high-energy UV radiation. Solar panels can create more energy in space than on Earth due to these two factors. Solar panels in orbit can create 40 times more power than those on Earth, according to estimates.
How can we utilize this immense power? Launch a geostationary satellite with solar panels, then beam power to Earth. Such a technology could be our most eco-friendly energy source. (Better than fusion power!) How?
Solar panels create more energy in space, as I've said. Solar panel manufacture and grid batteries emit the most carbon. This indicates that a space-solar farm's carbon footprint (which doesn't need a battery because it's a constant power source) might be over 40 times smaller than a terrestrial one. Combine that with carbon-neutral launch vehicles like Starship, and you have a low-carbon power source. Solar power has one of the lowest emissions per kWh at 6g/kWh, so space-based solar could approach net-zero emissions.
Space solar is versatile because it doesn't require enormous infrastructure. A space-solar farm could power New York and Dallas with the same efficiency, without cables. The satellite will transmit power to a nearby terminal. This allows an energy system to evolve and adapt as the society it powers changes. Building and maintaining infrastructure can be carbon-intensive, thus less infrastructure means less emissions.
Space-based solar doesn't destroy habitats, either. Solar and wind power can be engineered to reduce habitat loss, but they still harm ecosystems, which must be restored. Space solar requires almost no land, therefore it's easier on Mother Nature.
Space solar power could be the ultimate energy source. So why haven’t we done it yet?
Well, for two reasons: the cost of launch and the efficiency of wireless energy transmission.
Advances in rocket construction and reusable rocket technology have lowered orbital launch costs. In the early 2000s, the Space Shuttle cost $60,000 per kg launched into LEO, but a SpaceX Falcon 9 costs only $3,205. 95% drop! Even at these low prices, launching a space-based solar farm is commercially questionable.
Energy transmission efficiency is half of its commercial viability. Space-based solar farms must be in geostationary orbit to get 24/7 daylight, 22,300 miles above Earth's surface. It's a long way to wirelessly transmit energy. Most laser and microwave systems are below 20% efficient.
Space-based solar power is uneconomical due to low efficiency and high deployment costs.
Longi wants to create this ultimate power. But how?
They'll send solar panels into space to develop space-based solar power that can be beamed to Earth. This mission will help them design solar panels tough enough for space while remaining efficient.
Longi is a Chinese company, and China's space program and universities are developing space-based solar power and seeking commercial partners. Xidian University has built a 98%-efficient microwave-based wireless energy transmission system for space-based solar power. The Long March 5B is China's super-cheap (but not carbon-offset) launch vehicle.
Longi fills the gap. They have the commercial know-how and ability to build solar satellites and terrestrial terminals at scale. Universities and the Chinese government have transmission technology and low-cost launch vehicles to launch this technology.
It may take a decade to develop and refine this energy solution. This could spark a clean energy revolution. Once operational, Longi and the Chinese government could offer the world a flexible, environmentally friendly, rapidly deployable energy source.
Should the world adopt this technology and let China control its energy? I'm not very political, so you decide. This seems to be the beginning of tapping into this planet-saving energy source. Forget fusion reactors. Carbon-neutral energy is coming soon.