











More on Marketing

Rita McGrath
3 years ago
Flywheels and Funnels
Traditional sales organizations used the concept of a sales “funnel” to describe the process through which potential customers move, ending up with sales at the end. Winners today have abandoned that way of thinking in favor of building flywheels — business models in which every element reinforces every other.
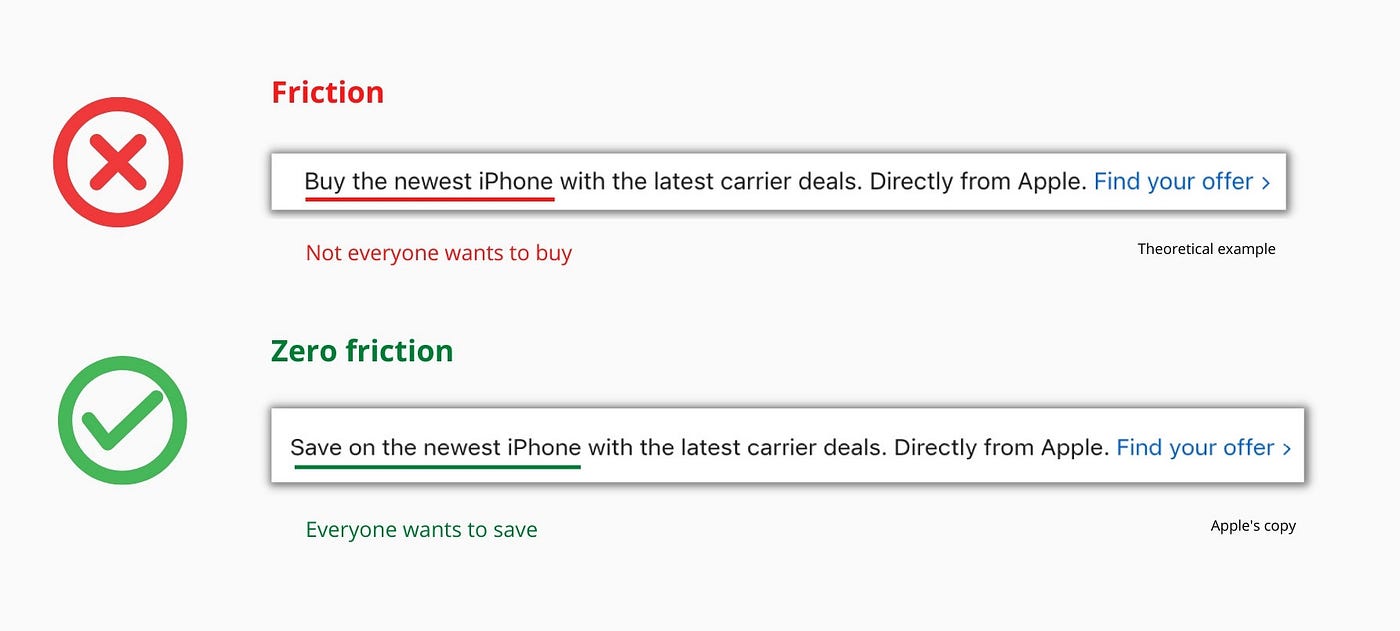
Ah, the marketing funnel…
Prospective clients go through a predictable set of experiences, students learn in business school marketing classes. It looks like this:

Understanding the funnel helps evaluate sales success indicators. Gail Goodwin, former CEO of small business direct mail provider Constant Contact, said managing the pipeline was key to escaping the sluggish SaaS ramp of death.
Like the funnel concept. To predict how well your business will do, measure how many potential clients are aware of it (awareness) and how many take the next step. If 1,000 people heard about your offering and 10% showed interest, you'd have 100 at that point. If 50% of these people made buyer-like noises, you'd know how many were, etc. It helped model buying trends.
TV, magazine, and radio advertising are pricey for B2C enterprises. Traditional B2B marketing involved armies of sales reps, which was expensive and a barrier to entry.
Cracks in the funnel model
Digital has exposed the funnel's limitations. Hubspot was born at a time when buyers and sellers had huge knowledge asymmetries, according to co-founder Brian Halligan. Those selling a product could use the buyer's lack of information to become a trusted partner.
As the world went digital, getting information and comparing offerings became faster, easier, and cheaper. Buyers didn't need a seller to move through a funnel. Interactions replaced transactions, and the relationship didn't end with a sale.
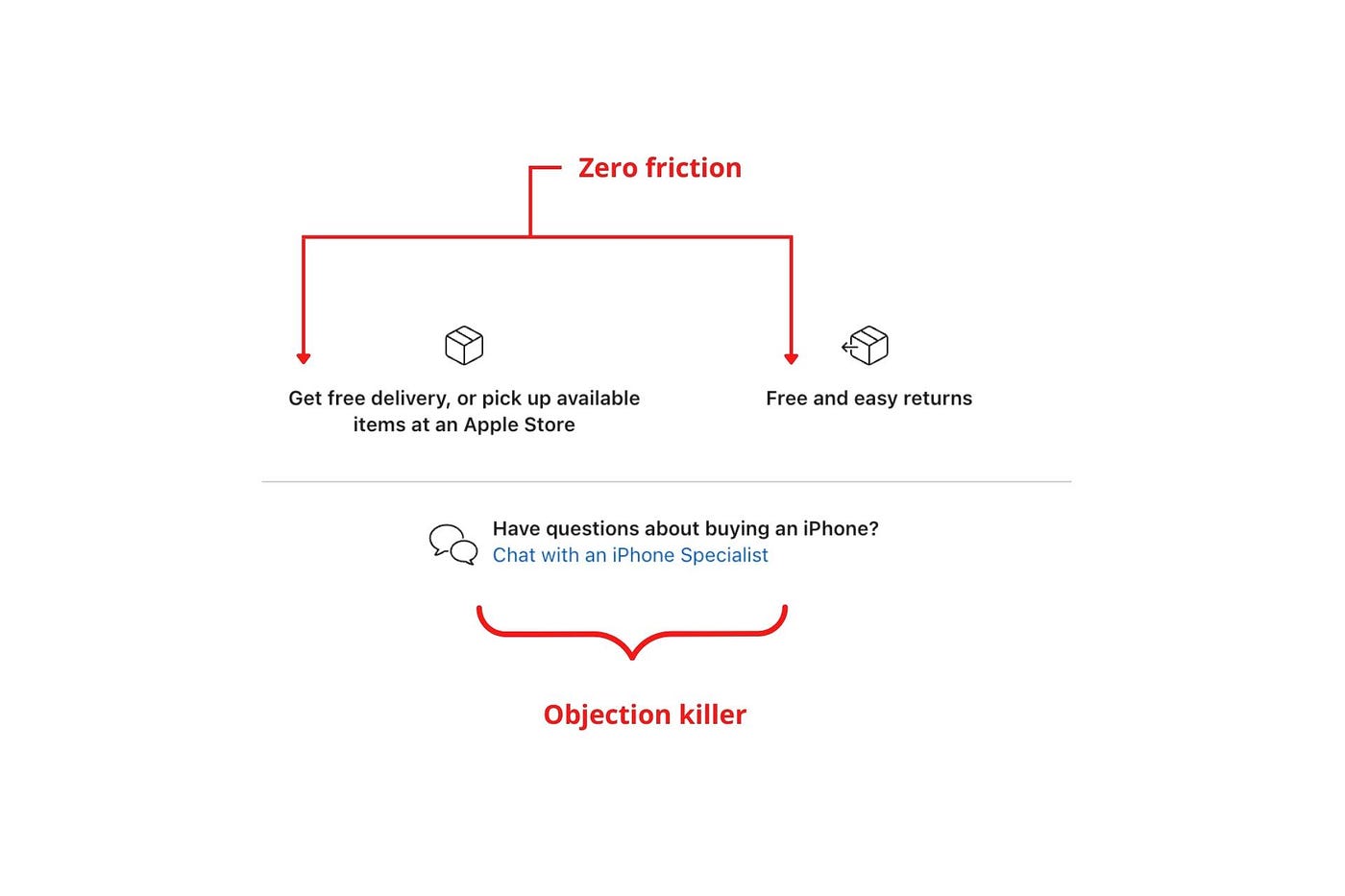
Instead, buyers and sellers interacted in a constant flow. In many modern models, the sale is midway through the process (particularly true with subscription and software-as-a-service models). Example:
You're creating a winding journey with many touch points, not a funnel (and lots of opportunities for customers to get lost).
From winding journey to flywheel
Beyond this revised view of an interactive customer journey, a company can create what Jim Collins famously called a flywheel. Imagine rolling a heavy disc on its axis. The first few times you roll it, you put in a lot of effort for a small response. The same effort yields faster turns as it gains speed. Over time, the flywheel gains momentum and turns without your help.
Modern digital organizations have created flywheel business models, in which any additional force multiplies throughout the business. The flywheel becomes a force multiplier, according to Collins.
Amazon is a famous flywheel example. Collins explained the concept to Amazon CEO Jeff Bezos at a corporate retreat in 2001. In The Everything Store, Brad Stone describes in his book The Everything Store how he immediately understood Amazon's levers.
The result (drawn on a napkin):
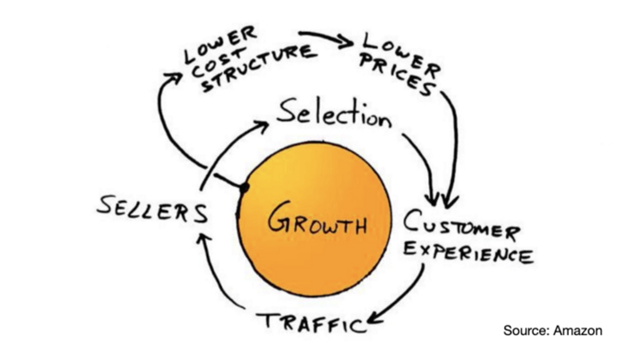
Low prices and a large selection of products attracted customers, while a focus on customer service kept them coming back, increasing traffic. Third-party sellers then increased selection. Low-cost structure supports low-price commitment. It's brilliant! Every wheel turn creates acceleration.
Where from here?
Flywheel over sales funnel! Consider these business terms.

Joseph Mavericks
3 years ago
You Don't Have to Spend $250 on TikTok Ads Because I Did
900K impressions, 8K clicks, and $$$ orders…

I recently started dropshipping. Now that I own my business and can charge it as a business expense, it feels less like money wasted if it doesn't work. I also made t-shirts to sell. I intended to open a t-shirt store and had many designs on a hard drive. I read that Tiktok advertising had a high conversion rate and low cost because they were new. According to many, the advertising' cost/efficiency ratio would plummet and become as bad as Google or Facebook Ads. Now felt like the moment to try Tiktok marketing and dropshipping. I work in marketing for a SaaS firm and have seen how poorly ads perform. I wanted to try it alone.
I set up $250 and ran advertising for a week. Before that, I made my own products, store, and marketing. In this post, I'll show you my process and results.
Setting up the store
Dropshipping is a sort of retail business in which the manufacturer ships the product directly to the client through an online platform maintained by a seller. The seller takes orders but has no stock. The manufacturer handles all orders. This no-stock concept increases profitability and flexibility.
In my situation, I used previous t-shirt designs to make my own product. I didn't want to handle order fulfillment logistics, so I looked for a way to print my designs on demand, ship them, and handle order tracking/returns automatically. So I found Printful.
I needed to connect my backend and supplier to a storefront so visitors could buy. 99% of dropshippers use Shopify, but I didn't want to master the difficult application. I wanted a one-day project. I'd previously worked with Big Cartel, so I chose them.
Big Cartel doesn't collect commissions on sales, simply a monthly flat price ($9.99 to $19.99 depending on your plan).
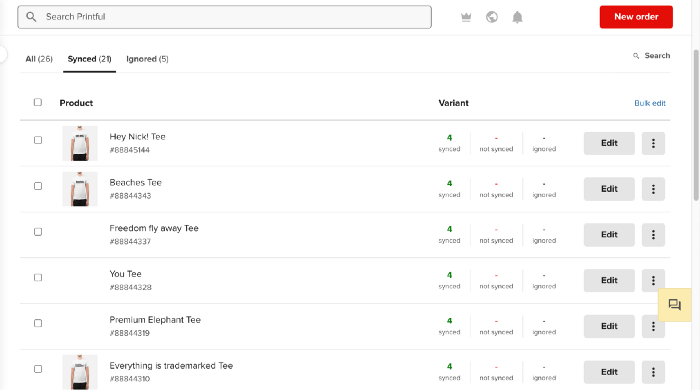
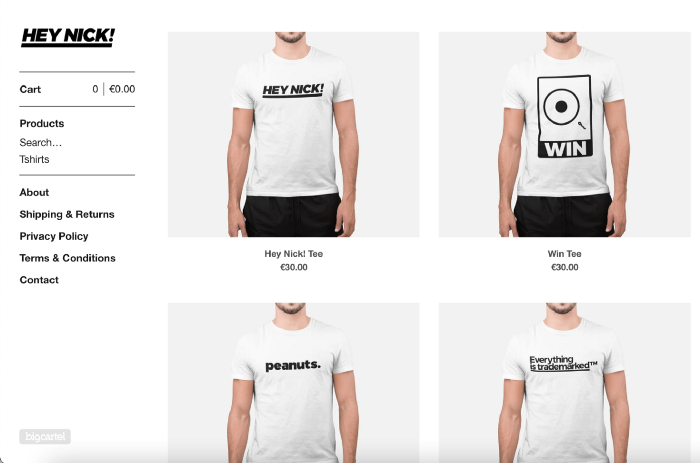
After opening a Big Cartel account, I uploaded 21 designs and product shots, then synced each product with Printful.
Developing the ads
I mocked up my designs on cool people photographs from placeit.net, a great tool for creating product visuals when you don't have a studio, camera gear, or models to wear your t-shirts.
I opened an account on the website and had advertising visuals within 2 hours.
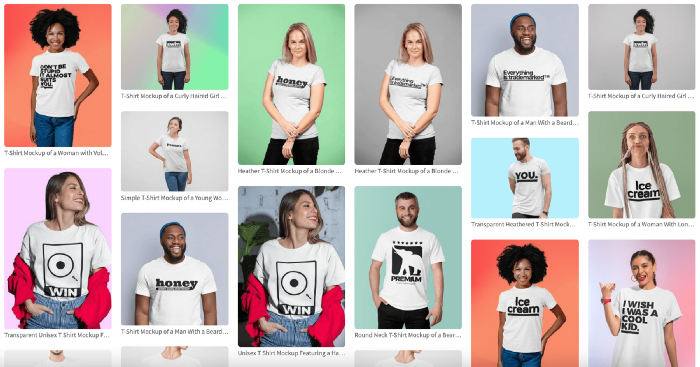
Because my designs are simple (black design on white t-shirt), I chose happy, stylish people on plain-colored backdrops. After that, I had to develop an animated slideshow.
Because I'm a graphic designer, I chose to use Adobe Premiere to create animated Tiktok advertising.
Premiere is a fancy video editing application used for more than advertisements. Premiere is used to edit movies, not social media marketing. I wanted this experiment to be quick, so I got 3 social media ad templates from motionarray.com and threw my visuals in. All the transitions and animations were pre-made in the files, so it only took a few hours to compile. The result:
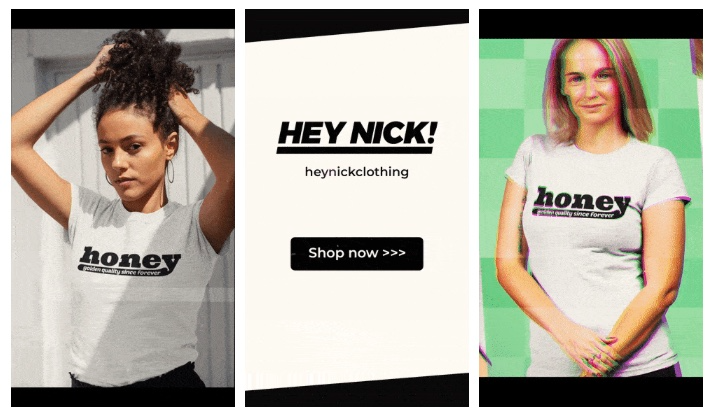
I downloaded 3 different soundtracks for the videos to determine which would convert best.
After that, I opened a Tiktok business account, uploaded my films, and inserted ad info. They went live within one hour.
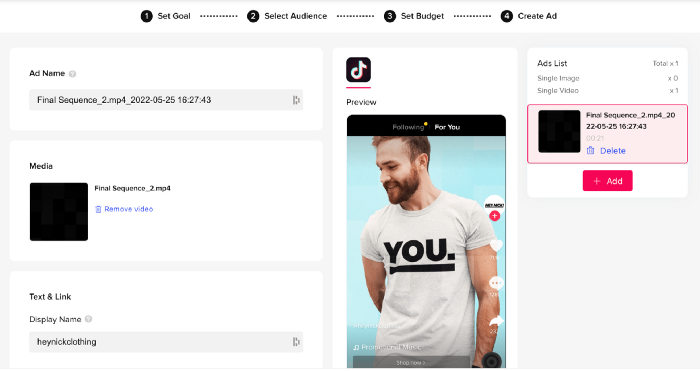
The (poor) outcomes
As a European company, I couldn't deliver ads in the US. All of my advertisements' material (title, description, and call to action) was in English, hence they continued getting rejected in Europe for countries that didn't speak English. There are a lot of them:
I lost a lot of quality traffic, but I felt that if the images were engaging, people would check out the store and buy my t-shirts. I was wrong.
51,071 impressions on Day 1. 0 orders after 411 clicks
114,053 impressions on Day 2. 1.004 clicks and no orders
Day 3: 987 clicks, 103,685 impressions, and 0 orders
101,437 impressions on Day 4. 0 orders after 963 clicks
115,053 impressions on Day 5. 1,050 clicks and no purchases
125,799 impressions on day 6. 1,184 clicks, no purchases
115,547 impressions on Day 7. 1,050 clicks and no purchases
121,456 impressions on day 8. 1,083 clicks, no purchases
47,586 impressions on Day 9. 419 Clicks. No orders
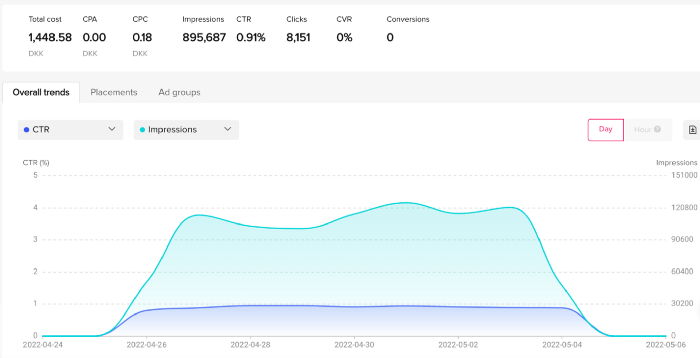
My overall conversion rate for video advertisements was 0.9%. TikTok's paid ad formats all result in strong engagement rates (ads average 3% to 12% CTR to site), therefore a 1 to 2% CTR should have been doable.
My one-week experiment yielded 8,151 ad clicks but no sales. Even if 0.1% of those clicks converted, I should have made 8 sales. Even companies with horrible web marketing would get one download or trial sign-up for every 8,151 clicks. I knew that because my advertising were in English, I had no impressions in the main EU markets (France, Spain, Italy, Germany), and that this impacted my conversion potential. I still couldn't believe my numbers.
I dug into the statistics and found that Tiktok's stats didn't match my store traffic data.
Looking more closely at the numbers
My ads were approved on April 26 but didn't appear until April 27. My store dashboard showed 440 visitors but 1,004 clicks on Tiktok. This happens often while tracking campaign results since different platforms handle comparable user activities (click, view) differently. In online marketing, residual data won't always match across tools.
My data gap was too large. Even if half of the 1,004 persons who clicked closed their browser or left before the store site loaded, I would have gained 502 visitors. The significant difference between Tiktok clicks and Big Cartel store visits made me suspicious. It happened all week:
Day 1: 440 store visits and 1004 ad clicks
Day 2: 482 store visits, 987 ad clicks
3rd day: 963 hits on ads, 452 store visits
443 store visits and 1,050 ad clicks on day 4.
Day 5: 459 store visits and 1,184 ad clicks
Day 6: 430 store visits and 1,050 ad clicks
Day 7: 409 store visits and 1,031 ad clicks
Day 8: 166 store visits and 418 ad clicks
The disparity wasn't related to residual data or data processing. The disparity between visits and clicks looked regular, but I couldn't explain it.
After the campaign concluded, I discovered all my creative assets (the videos) had a 0% CTR and a $0 expenditure in a separate dashboard. Whether it's a dashboard reporting issue or a budget allocation bug, online marketers shouldn't see this.
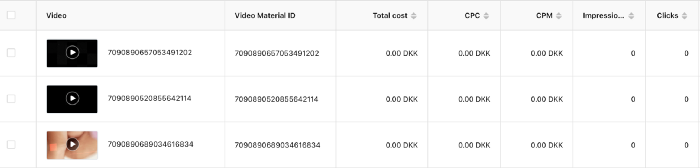
Tiktok can present any stats they want on their dashboard, just like any other platform that runs advertisements to promote content to its users. I can't verify that 895,687 individuals saw and clicked on my ad. I invested $200 for what appears to be around 900K impressions, which is an excellent ROI. No one bought a t-shirt, even an unattractive one, out of 900K people?
Would I do it again?
Nope. Whether I didn't make sales because Tiktok inflated the dashboard numbers or because I'm horrible at producing advertising and items that sell, I’ll stick to writing content and making videos. If setting up a business and ads in a few days was all it took to make money online, everyone would do it.
Video advertisements and dropshipping aren't dead. As long as the internet exists, people will click ads and buy stuff. Converting ads and selling stuff takes a lot of work, and I want to focus on other things.
I had always wanted to try dropshipping and I’m happy I did, I just won’t stick to it because that’s not something I’m interested in getting better at.
If I want to sell t-shirts again, I'll avoid Tiktok advertisements and find another route.

Jon Brosio
3 years ago
You can learn more about marketing from these 8 copywriting frameworks than from a college education.
Email, landing pages, and digital content

Today's most significant skill:
Copywriting.
Unfortunately, most people don't know how to write successful copy because they weren't taught in school.
I've been obsessed with copywriting for two years. I've read 15 books, completed 3 courses, and studied internet's best digital entrepreneurs.
Here are 8 copywriting frameworks that educate more than a four-year degree.
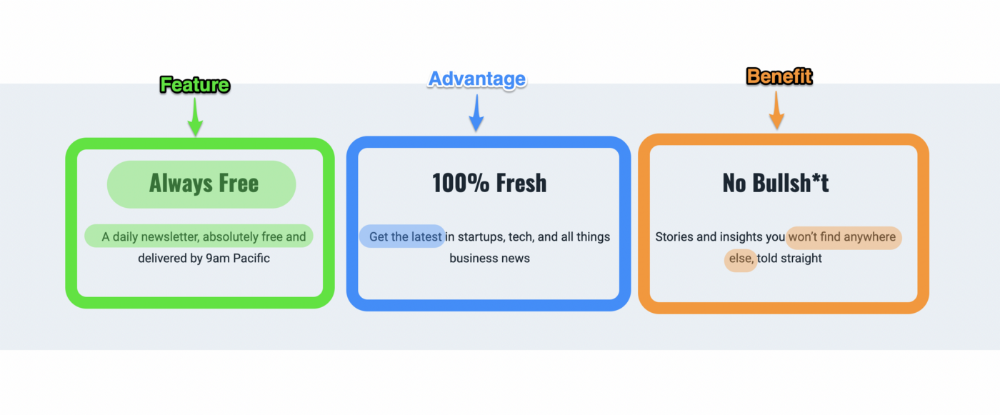
1. Feature — Advantage — Benefit (F.A.B)
This is the most basic copywriting foundation. Email marketing, landing page copy, and digital video ads can use it.
F.A.B says:
How it works (feature)
which is helpful (advantage)
What's at stake (benefit)
The Hustle uses this framework on their landing page to convince people to sign up:
2. P. A. S. T. O. R.
This framework is for longer-form copywriting. PASTOR uses stories to engage with prospects. It explains why people should buy this offer.
PASTOR means:
Problem
Amplify
Story
Testimonial
Offer
Response
Dan Koe's landing page is a great example. It shows PASTOR frame-by-frame.

3. Before — After — Bridge
Before-after-bridge is a copywriting framework that draws attention and shows value quickly.
This framework highlights:
where you are
where you want to be
how to get there
Works great for: Email threads/landing pages
Zain Kahn utilizes this framework to write viral threads.

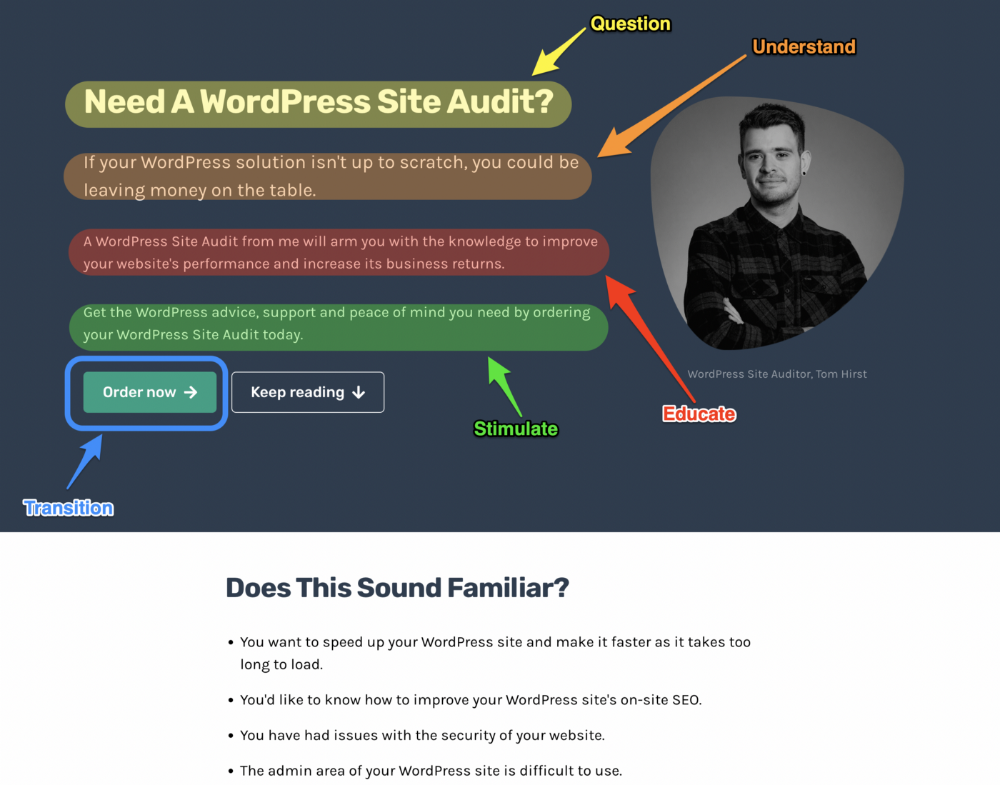
4. Q.U.E.S.T
QUEST is about empathetic writing. You know their issues, obstacles, and headaches. This allows coverups.
QUEST:
Qualifies
Understands
Educates
Stimulates
Transitions
Tom Hirst's landing page uses the QUEST framework.
5. The 4P’s model
The 4P’s approach pushes your prospect to action. It educates and persuades quickly.
4Ps:
The problem the visitor is dealing with
The promise that will help them
The proof the promise works
A push towards action
Mark Manson is a bestselling author, digital creator, and pop-philosopher. He's also a great copywriter, and his membership offer uses the 4P’s framework.

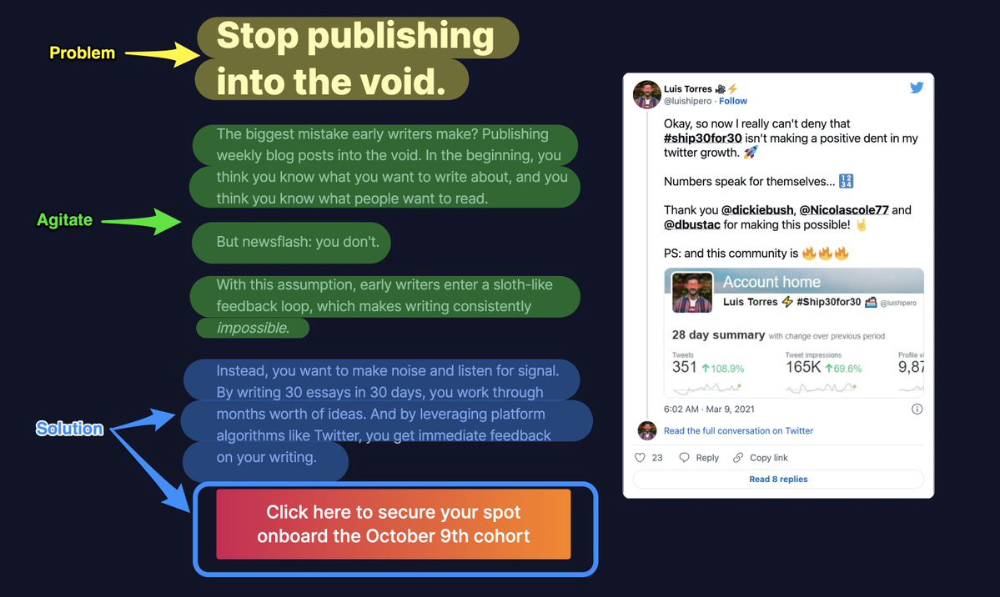
6. Problem — Agitate — Solution (P.A.S)
Up-and-coming marketers should understand problem-agitate-solution copywriting. Once you understand one structure, others are easier. It drives passion and presents a clear solution.
PAS outlines:
The issue the visitor is having
It then intensifies this issue through emotion.
finally offers an answer to that issue (the offer)
The customer's story loops. Nicolas Cole and Dickie Bush use PAS to promote Ship 30 for 30.
7. Star — Story — Solution (S.S.S)
PASTOR + PAS = star-solution-story. Like PAS, it employs stories to persuade.
S.S.S. is effective storytelling:
Star: (Person had a problem)
Story: (until they had a breakthrough)
Solution: (That created a transformation)
Ali Abdaal is a YouTuber with a great S.S.S copy.
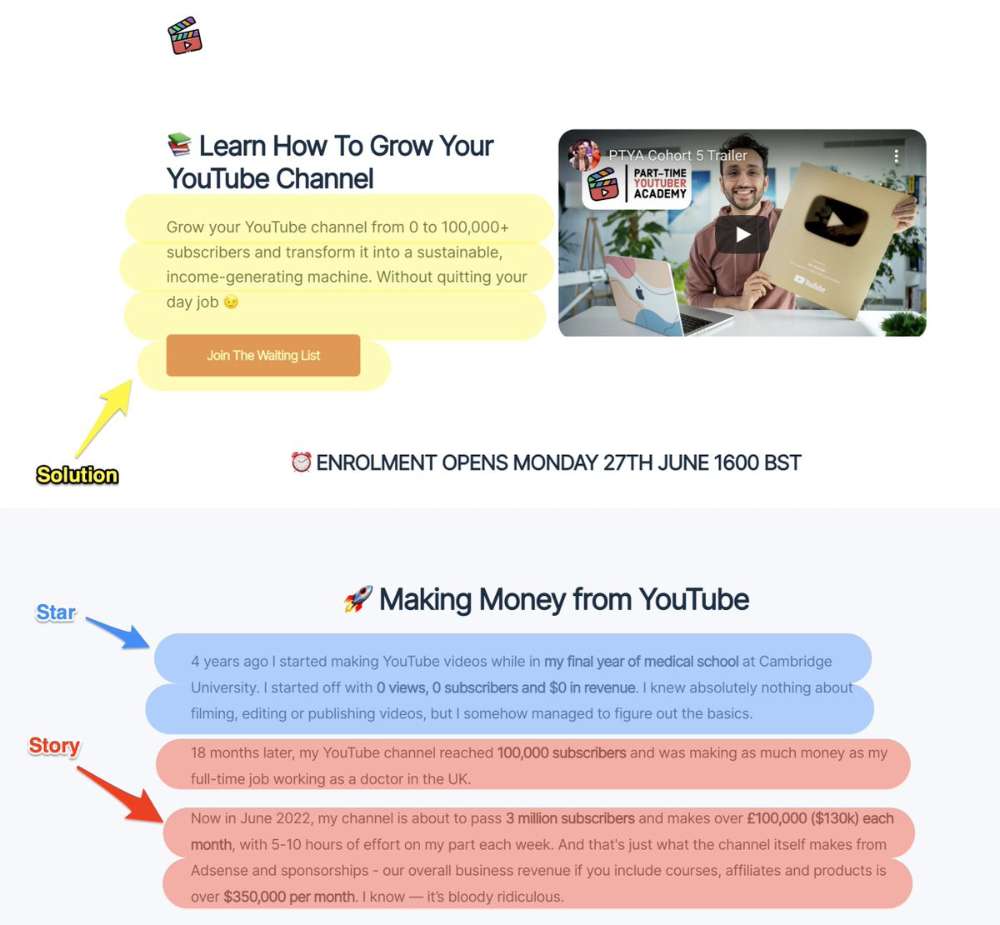
8. Attention — Interest — Desire — Action
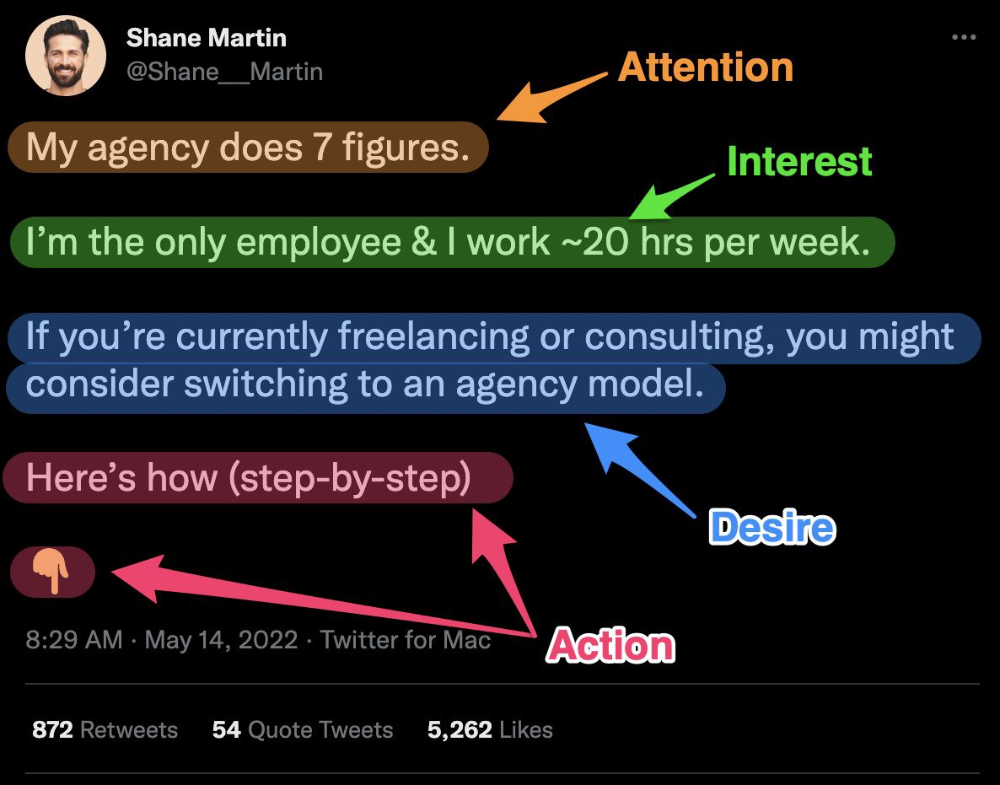
AIDA is another classic. This copywriting framework is great for fast-paced environments (think all digital content on Linkedin, Twitter, Medium, etc.).
It works with:
Page landings
writing on thread
Email
It's a good structure since it's concise, attention-grabbing, and action-oriented.
Shane Martin, Twitter's creator, uses this approach to create viral content.
TL;DR
8 copywriting frameworks that teach marketing better than a four-year degree
Feature-advantage-benefit
Before-after-bridge
Star-story-solution
P.A.S.T.O.R
Q.U.E.S.T
A.I.D.A
P.A.S
4P’s
You might also like

Navdeep Yadav
3 years ago
31 startup company models (with examples)
Many people find the internet's various business models bewildering.
This article summarizes 31 startup e-books.
1. Using the freemium business model (free plus premium),
The freemium business model offers basic software, games, or services for free and charges for enhancements.
Examples include Slack, iCloud, and Google Drive
Provide a rudimentary, free version of your product or service to users.
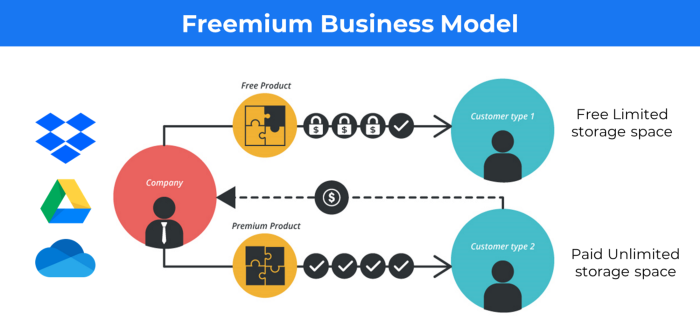
Google Drive and Dropbox offer 15GB and 2GB of free space but charge for more.
Freemium business model details (Click here)
2. The Business Model of Subscription
Subscription business models sell a product or service for recurring monthly or yearly revenue.
Examples: Tinder, Netflix, Shopify, etc
It's the next step to Freemium if a customer wants to pay monthly for premium features.
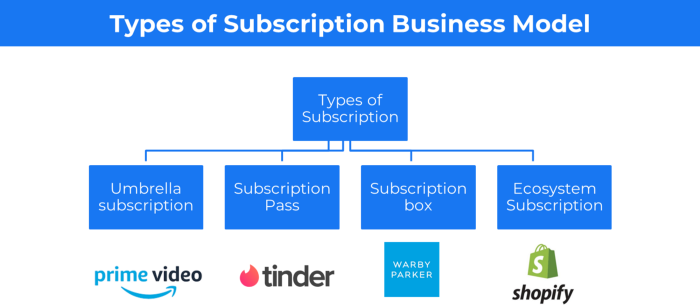
Subscription Business Model (Click here)
3. A market-based business strategy
It's an e-commerce site or app where third-party sellers sell products or services.
Examples are Amazon and Fiverr.
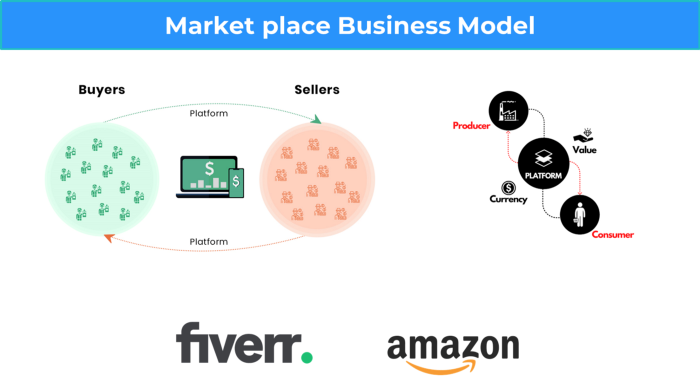
On Amazon's marketplace, a third-party vendor sells a product.
Freelancers on Fiverr offer specialized skills like graphic design.
Marketplace's business concept is explained.
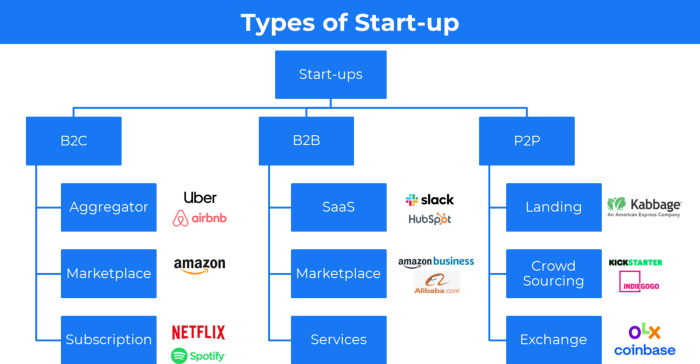
4. Business plans using aggregates
In the aggregator business model, the service is branded.
Uber, Airbnb, and other examples
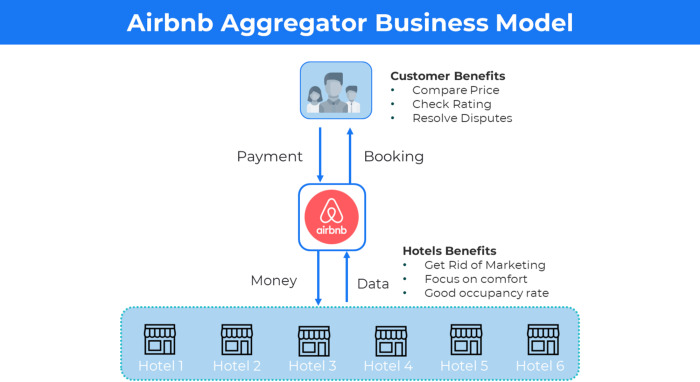
Marketplace and Aggregator business models differ.

Amazon and Fiverr link merchants and customers and take a 10-20% revenue split.
Uber and Airbnb-style aggregator Join these businesses and provide their products.
5. The pay-as-you-go concept of business
This is a consumption-based pricing system. Cloud companies use it.
Example: Amazon Web Service and Google Cloud Platform (GCP) (AWS)
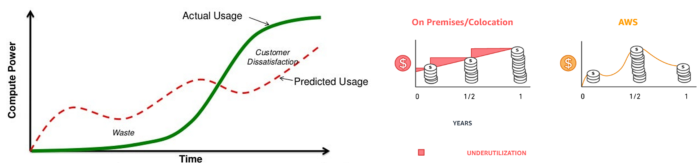
AWS, an Amazon subsidiary, offers over 200 pay-as-you-go cloud services.
“In short, the more you use the more you pay”
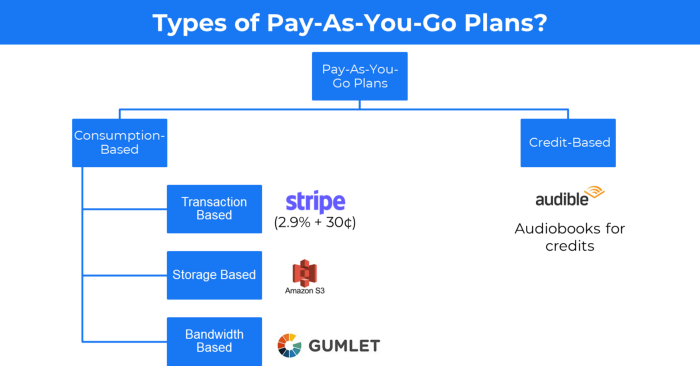
When it's difficult to divide clients into pricing levels, pay-as-you is employed.
6. The business model known as fee-for-service (FFS)
FFS charges fixed and variable fees for each successful payment.
For instance, PayU, Paypal, and Stripe
Stripe charges 2.9% + 30 per payment.
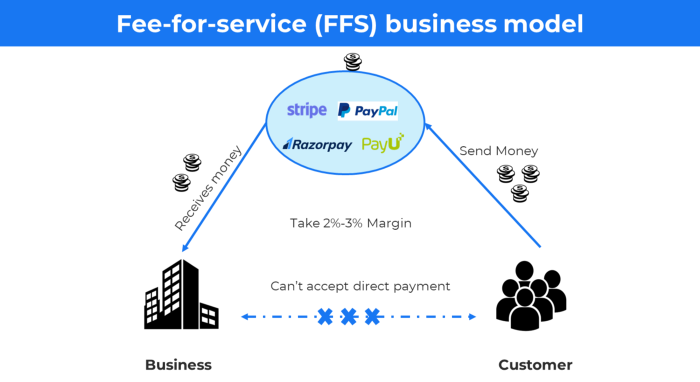
These firms offer a payment gateway to take consumer payments and deposit them to a business account.
Fintech business model
7. EdTech business strategy
In edtech, you generate money by selling material or teaching as a service.
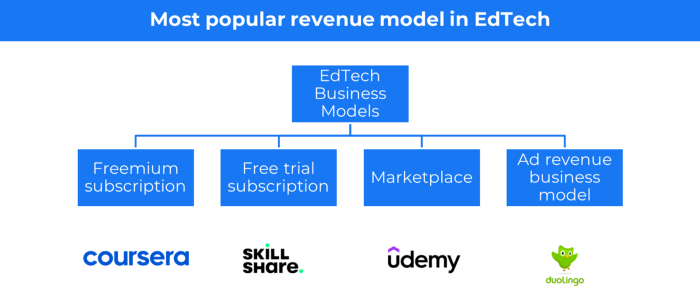
edtech business models
Freemium When course content is free but certification isn't, e.g. Coursera
FREE TRIAL SkillShare offers free trials followed by monthly or annual subscriptions.
Self-serving marketplace approach where you pick what to learn.
Ad-revenue model The company makes money by showing adverts to its huge user base.
Lock-in business strategy
Lock in prevents customers from switching to a competitor's brand or offering.
It uses switching costs or effort to transmit (soft lock-in), improved brand experience, or incentives.
Apple, SAP, and other examples
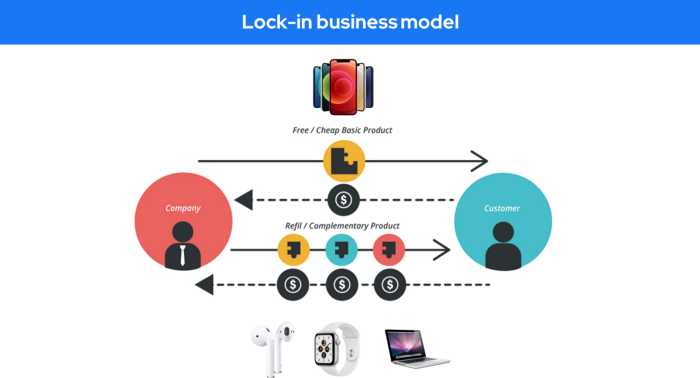
Apple offers an iPhone and then locks you in with extra hardware (Watch, Airpod) and platform services (Apple Store, Apple Music, cloud, etc.).
9. Business Model for API Licensing
APIs let third-party apps communicate with your service.
Uber and Airbnb use Google Maps APIs for app navigation.
Examples are Google Map APIs (Map), Sendgrid (Email), and Twilio (SMS).
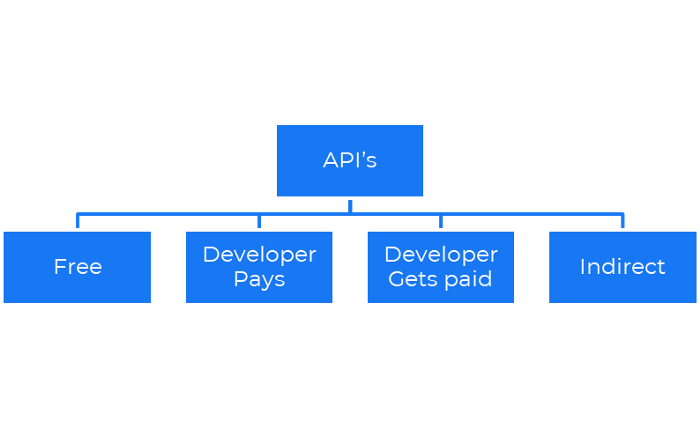
Business models for APIs
Free: The simplest API-driven business model that enables unrestricted API access for app developers. Google Translate and Facebook are two examples.
Developer Pays: Under this arrangement, service providers such as AWS, Twilio, Github, Stripe, and others must be paid by application developers.
The developer receives payment: These are the compensated content producers or developers who distribute the APIs utilizing their work. For example, Amazon affiliate programs
10. Open-source enterprise
Open-source software can be inspected, modified, and improved by anybody.
For instance, use Firefox, Java, or Android.
Google paid Mozilla $435,702 million to be their primary search engine in 2018.
Open-source software profits in six ways.
Paid assistance The Project Manager can charge for customization because he is quite knowledgeable about the codebase.
A full database solution is available as a Software as a Service (MongoDB Atlas), but there is a fee for the monitoring tool.
Open-core design R studio is a better GUI substitute for open-source applications.
sponsors of GitHub Sponsorships benefit the developers in full.
demands for paid features Earn Money By Developing Open Source Add-Ons for Current Products
Open-source business model
11. The business model for data
If the software or algorithm collects client data to improve or monetize the system.
Open AI GPT3 gets smarter with use.
Foursquare allows users to exchange check-in locations.
Later, they compiled large datasets to enable retailers like Starbucks launch new outlets.
12. Business Model Using Blockchain
Blockchain is a distributed ledger technology that allows firms to deploy smart contracts without a central authority.
Examples include Alchemy, Solana, and Ethereum.
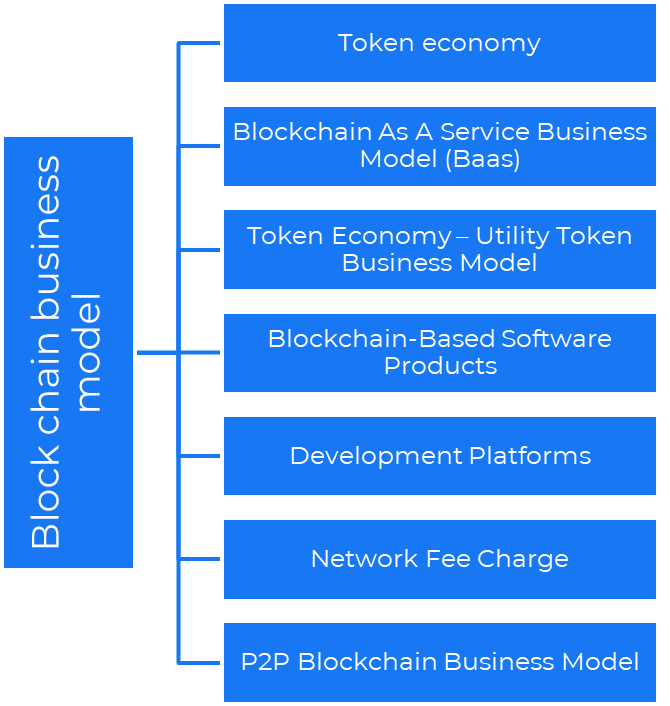
Business models using blockchain
Economy of tokens or utility When a business uses a token business model, it issues some kind of token as one of the ways to compensate token holders or miners. For instance, Solana and Ethereum
Bitcoin Cash P2P Business Model Peer-to-peer (P2P) blockchain technology permits direct communication between end users. as in IPFS
Enterprise Blockchain as a Service (Baas) BaaS focuses on offering ecosystem services similar to those offered by Amazon (AWS) and Microsoft (Azure) in the web 3 sector. Example: Ethereum Blockchain as a Service with Bitcoin (EBaaS).
Blockchain-Based Aggregators With AWS for blockchain, you can use that service by making an API call to your preferred blockchain. As an illustration, Alchemy offers nodes for many blockchains.
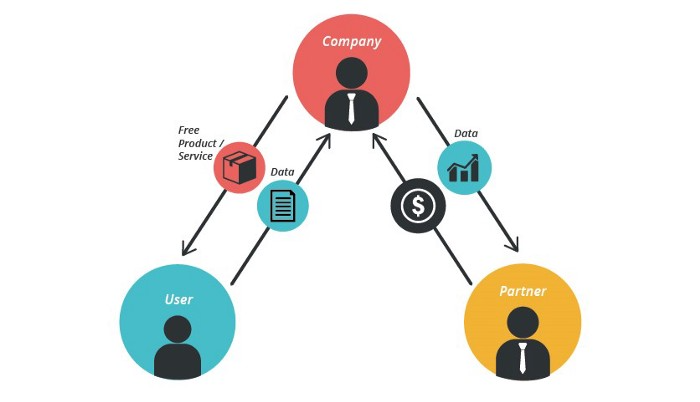
13. The free-enterprise model
In the freeterprise business model, free professional accounts are led into the funnel by the free product and later become B2B/enterprise accounts.
For instance, Slack and Zoom
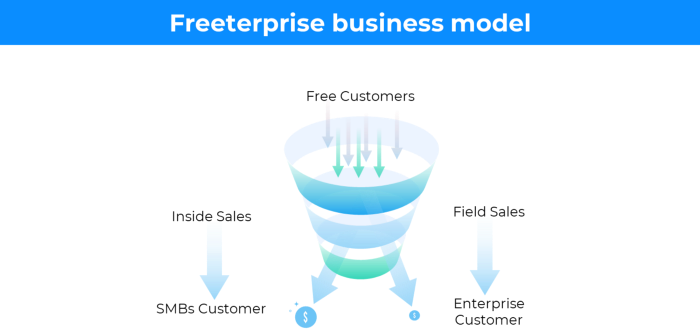
Freeterprise companies flourish through collaboration.
Start with a free professional account to build an enterprise.
14. Business plan for razor blades
It's employed in hardware where one piece is sold at a loss and profits are made through refills or add-ons.
Gillet razor & blades, coffee machine & beans, HP printer & cartridge, etc.
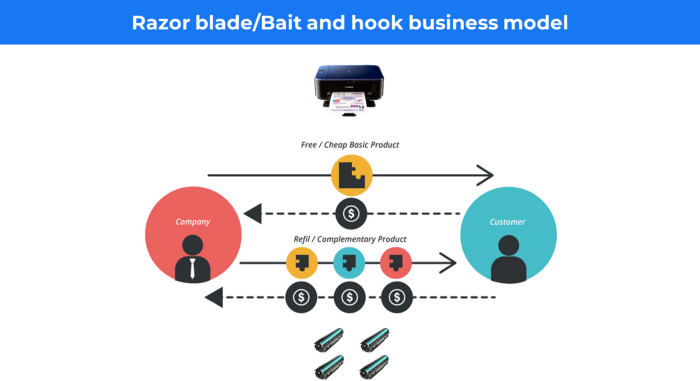
Sony sells the Playstation console at a loss but makes up for it by selling games and charging for online services.
Advantages of the Razor-Razorblade Method
lowers the risk a customer will try a product. enables buyers to test the goods and services without having to pay a high initial investment.
The product's ongoing revenue stream has the potential to generate sales that much outweigh the original investments.
Razor blade business model
15. The business model of direct-to-consumer (D2C)
In D2C, the company sells directly to the end consumer through its website using a third-party logistic partner.
Examples include GymShark and Kylie Cosmetics.
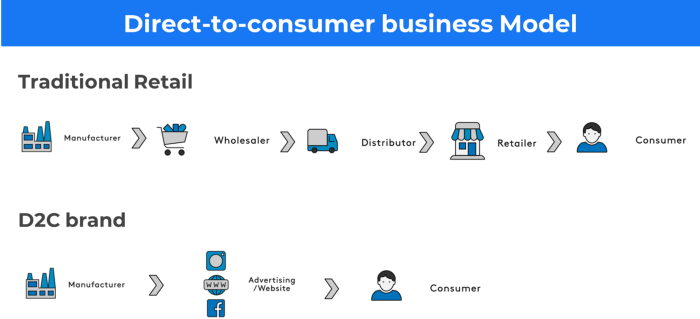
D2C brands can only expand via websites, marketplaces (Amazon, eBay), etc.
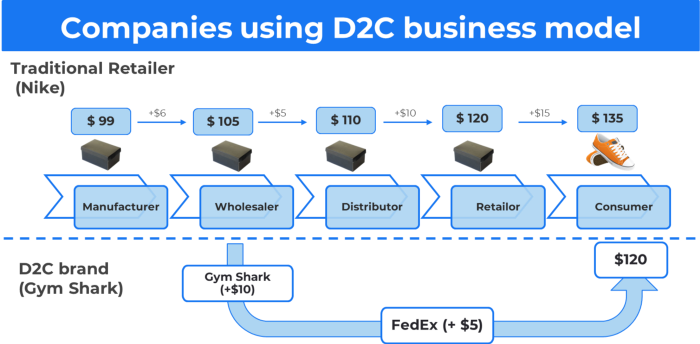
D2C benefits
Lower reliance on middlemen = greater profitability
You now have access to more precise demographic and geographic customer data.
Additional space for product testing
Increased customisation throughout your entire product line-Inventory Less
16. Business model: White Label vs. Private Label
Private label/White label products are made by a contract or third-party manufacturer.
Most amazon electronics are made in china and white-labeled.
Amazon supplements and electronics.
Contract manufacturers handle everything after brands select product quantities on design labels.
17. The franchise model
The franchisee uses the franchisor's trademark, branding, and business strategy (company).
For instance, KFC, Domino's, etc.
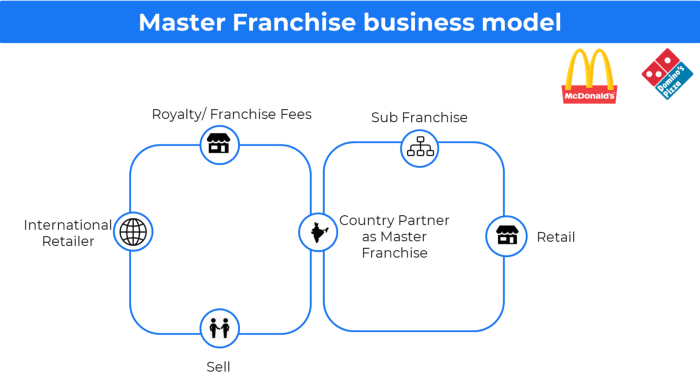
Subway, Domino, Burger King, etc. use this business strategy.

Many people pick a franchise because opening a restaurant is risky.
18. Ad-based business model
Social media and search engine giants exploit search and interest data to deliver adverts.
Google, Meta, TikTok, and Snapchat are some examples.
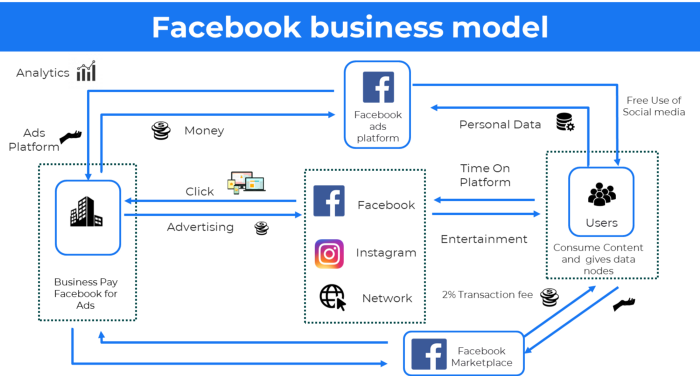
Users don't pay for the service or product given, e.g. Google users don't pay for searches.
In exchange, they collected data and hyper-personalized adverts to maximize revenue.
19. Business plan for octopuses
Each business unit functions separately but is connected to the main body.
Instance: Oyo

OYO is Asia's Airbnb, operating hotels, co-working, co-living, and vacation houses.
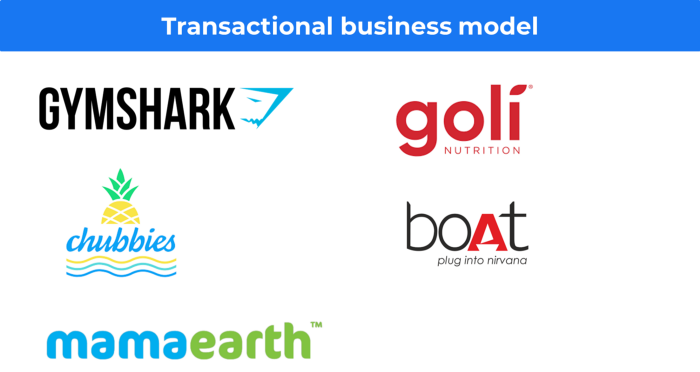
20, Transactional business model, number
Sales to customers produce revenue.
E-commerce sites and online purchases employ SSL.
Goli is an ex-GymShark.
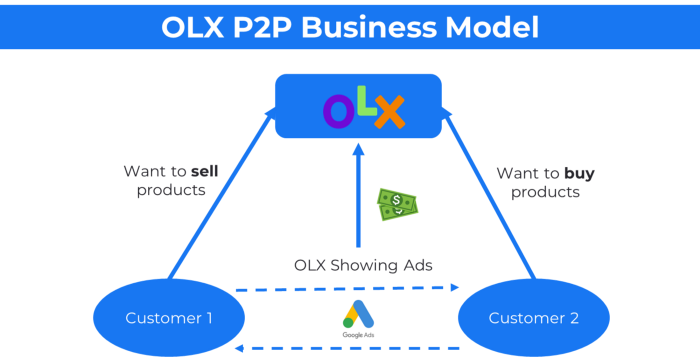
21. The peer-to-peer (P2P) business model
In P2P, two people buy and sell goods and services without a third party or platform.
Consider OLX.
22. P2P lending as a manner of operation
In P2P lending, one private individual (P2P Lender) lends/invests or borrows money from another (P2P Borrower).
Instance: Kabbage
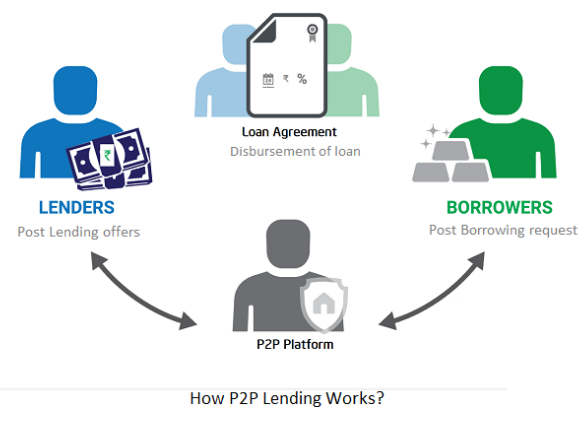
Social lending lets people lend and borrow money directly from each other without an intermediary financial institution.
23. A business model for brokers
Brokerages charge a commission or fee for their services.
Examples include eBay, Coinbase, and Robinhood.
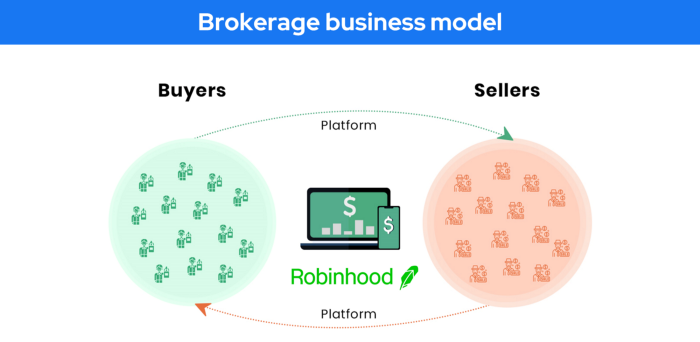
Brokerage businesses are common in Real estate, finance, and online and operate on this model.

Buy/sell similar models Examples include financial brokers, insurance brokers, and others who match purchase and sell transactions and charge a commission.
These brokers charge an advertiser a fee based on the date, place, size, or type of an advertisement. This is known as the classified-advertiser model. For instance, Craiglist
24. Drop shipping as an industry
Dropshipping allows stores to sell things without holding physical inventories.
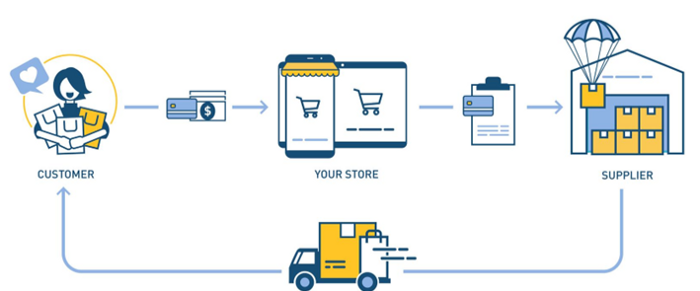
When a customer orders, use a third-party supplier and logistic partners.
Retailer product portfolio and customer experience Fulfiller The consumer places the order.
Dropshipping advantages
Less money is needed (Low overhead-No Inventory or warehousing)
Simple to start (costs under $100)
flexible work environment
New product testing is simpler
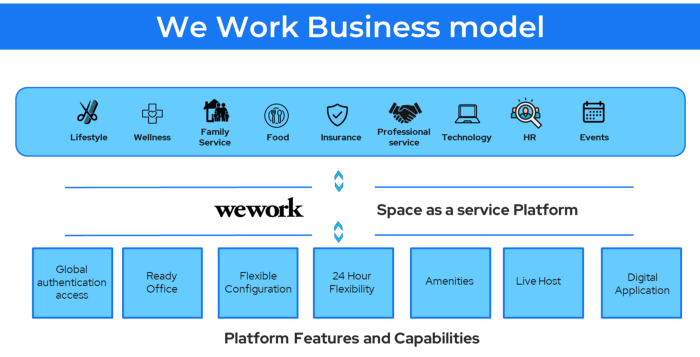
25. Business Model for Space as a Service
It's centered on a shared economy that lets millennials live or work in communal areas without ownership or lease.
Consider WeWork and Airbnb.
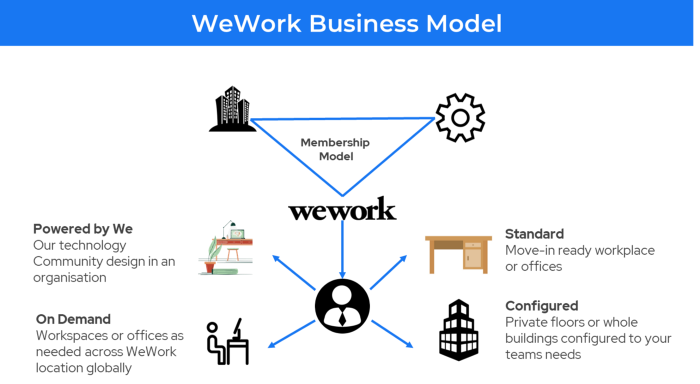
WeWork helps businesses with real estate, legal compliance, maintenance, and repair.
26. The business model for third-party logistics (3PL)
In 3PL, a business outsources product delivery, warehousing, and fulfillment to an external logistics company.
Examples include Ship Bob, Amazon Fulfillment, and more.

3PL partners warehouse, fulfill, and return inbound and outbound items for a charge.
Inbound logistics involves bringing products from suppliers to your warehouse.
Outbound logistics refers to a company's production line, warehouse, and customer.

27. The last-mile delivery paradigm as a commercial strategy
Last-mile delivery is the collection of supply chain actions that reach the end client.
Examples include Rappi, Gojek, and Postmates.
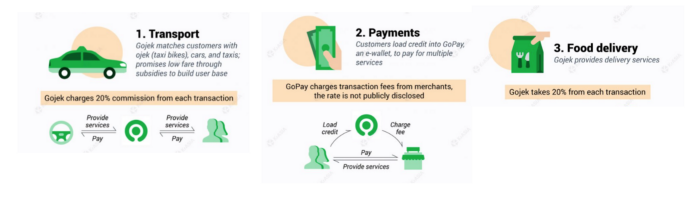
Last-mile is tied to on-demand and has a nighttime peak.
28. The use of affiliate marketing
Affiliate marketing involves promoting other companies' products and charging commissions.
Examples include Hubspot, Amazon, and Skillshare.

Your favorite youtube channel probably uses these short amazon links to get 5% of sales.
Affiliate marketing's benefits
In exchange for a success fee or commission, it enables numerous independent marketers to promote on its behalf.
Ensure system transparency by giving the influencers a specific tracking link and an online dashboard to view their profits.
Learn about the newest bargains and have access to promotional materials.
29. The business model for virtual goods
This is an in-app purchase for an intangible product.
Examples include PubG, Roblox, Candy Crush, etc.
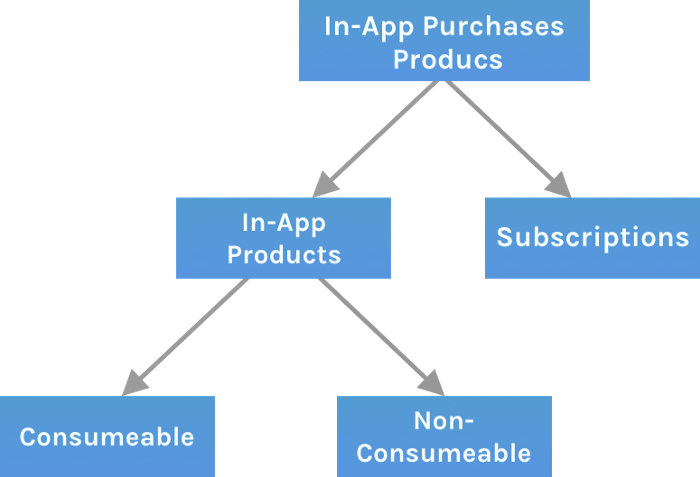
Consumables are like gaming cash that runs out. Non-consumable products provide a permanent advantage without repeated purchases.
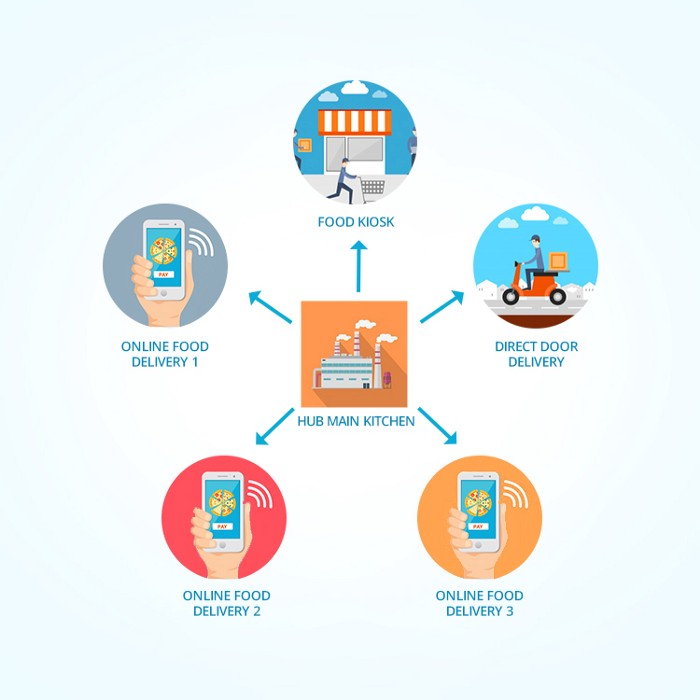
30. Business Models for Cloud Kitchens
Ghost, Dark, Black Box, etc.
Delivery-only restaurant.
These restaurants don't provide dine-in, only delivery.
For instance, NextBite and Faasos
31. Crowdsourcing as a Business Model
Crowdsourcing = Using the crowd as a platform's source.
In crowdsourcing, you get support from people around the world without hiring them.
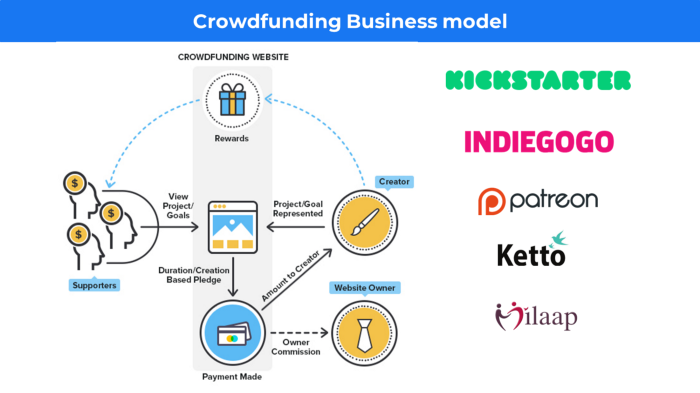
Crowdsourcing sites
Open-Source Software gives access to the software's source code so that developers can edit or enhance it. Examples include Firefox browsers and Linux operating systems.
Crowdfunding The oculus headgear would be an example of crowdfunding in essence, with no expectations.

Miguel Saldana
3 years ago
Crypto Inheritance's Catch-22
Security, privacy, and a strategy!

How to manage digital assets in worst-case scenarios is a perennial crypto concern. Since blockchain and bitcoin technology is very new, this hasn't been a major issue. Many early developers are still around, and many groups created around this technology are young and feel they have a lot of life remaining. This is why inheritance and estate planning in crypto should be handled promptly. As cryptocurrency's intrinsic worth rises, many people in the ecosystem are holding on to assets that might represent generational riches. With that much value, it's crucial to have a plan. Creating a solid plan entails several challenges.
the initial hesitation in coming up with a plan
The technical obstacles to ensuring the assets' security and privacy
the passing of assets from a deceased or incompetent person
Legal experts' lack of comprehension and/or understanding of how to handle and treat cryptocurrency.
This article highlights several challenges, a possible web3-native solution, and how to learn more.

The Challenge of Inheritance:
One of the biggest hurdles to inheritance planning is starting the conversation. As humans, we don't like to think about dying. Early adopters will experience crazy gains as cryptocurrencies become more popular. Creating a plan is crucial if you wish to pass on your riches to loved ones. Without a plan, the technical and legal issues I barely mentioned above would erode value by requiring costly legal fees and/or taxes, and you could lose everything if wallets and assets are not distributed appropriately (associated with the private keys). Raising awareness of the consequences of not having a plan should motivate people to make one.

Controlling Change:
Having an inheritance plan for your digital assets is crucial, but managing the guts and bolts poses a new set of difficulties. Privacy and security provided by maintaining your own wallet provide different issues than traditional finances and assets. Traditional finance is centralized (say a stock brokerage firm). You can assign another person to handle the transfer of your assets. In crypto, asset transfer is reimagined. One may suppose future transaction management is doable, but the user must consent, creating an impossible loop.
I passed away and must send a transaction to the person I intended to deliver it to.
I have to confirm or authorize the transaction, but I'm dead.
In crypto, scheduling a future transaction wouldn't function. To transfer the wallet and its contents, we'd need the private keys and/or seed phrase. Minimizing private key exposure is crucial to protecting your crypto from hackers, social engineering, and phishing. People have lost private keys after utilizing Life Hack-type tactics to secure them. People that break and hide their keys, lose them, or make them unreadable won't help with managing and/or transferring. This will require a derived solution.

Legal Challenges and Implications
Unlike routine cryptocurrency transfers and transactions, local laws may require special considerations. Even in the traditional world, estate/inheritance taxes, how assets will be split, and who executes the will must be considered. Many lawyers aren't crypto-savvy, which complicates the matter. There will be many hoops to jump through to safeguard your crypto and traditional assets and give them to loved ones.
Knowing RUFADAA/UFADAA, depending on your state, is vital for Americans. UFADAA offers executors and trustees access to online accounts (which crypto wallets would fall into). RUFADAA was changed to limit access to the executor to protect assets. RUFADAA outlines how digital assets are administered following death and incapacity in the US.
A Succession Solution
Having a will and talking about who would get what is the first step to having a solution, but using a Dad Mans Switch is a perfect tool for such unforeseen circumstances. As long as the switch's controller has control, nothing happens. Losing control of the switch initiates a state transition.
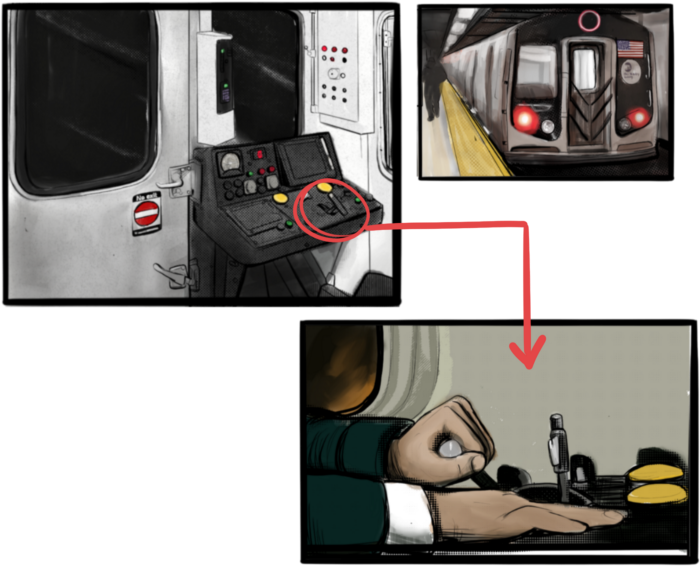
Subway or railway operations are examples. Modern control systems need the conductor to hold a switch to keep the train going. If they can't, the train stops.

Enter Sarcophagus
Sarcophagus is a decentralized dead man's switch built on Ethereum and Arweave. Sarcophagus allows actors to maintain control of their possessions even while physically unable to do so. Using a programmable dead man's switch and dual encryption, anything can be kept and passed on. This covers assets, secrets, seed phrases, and other use cases to provide authority and control back to the user and release trustworthy services from this work. Sarcophagus is built on a decentralized, transparent open source codebase. Sarcophagus is there if you're unprepared.


ANDREW SINGER
3 years ago
Crypto seen as the ‘future of money’ in inflation-mired countries
Crypto as the ‘future of money' in inflation-stricken nations
Citizens of devalued currencies “need” crypto. “Nice to have” in the developed world.
According to Gemini's 2022 Global State of Crypto report, cryptocurrencies “evolved from what many considered a niche investment into an established asset class” last year.
More than half of crypto owners in Brazil (51%), Hong Kong (51%), and India (54%), according to the report, bought cryptocurrency for the first time in 2021.
The study found that inflation and currency devaluation are powerful drivers of crypto adoption, especially in emerging market (EM) countries:
“Respondents in countries that have seen a 50% or greater devaluation of their currency against the USD over the last decade were more than 5 times as likely to plan to purchase crypto in the coming year.”
Between 2011 and 2021, the real lost 218 percent of its value against the dollar, and 45 percent of Brazilians surveyed by Gemini said they planned to buy crypto in 2019.
The rand (South Africa's currency) has fallen 103 percent in value over the last decade, second only to the Brazilian real, and 32 percent of South Africans expect to own crypto in the coming year. Mexico and India, the third and fourth highest devaluation countries, followed suit.
Compared to the US dollar, Hong Kong and the UK currencies have not devalued in the last decade. Meanwhile, only 5% and 8% of those surveyed in those countries expressed interest in buying crypto.
What can be concluded? Noah Perlman, COO of Gemini, sees various crypto use cases depending on one's location.
‘Need to have' investment in countries where the local currency has devalued against the dollar, whereas in the developed world it is still seen as a ‘nice to have'.
Crypto as money substitute
As an adjunct professor at New York University School of Law, Winston Ma distinguishes between an asset used as an inflation hedge and one used as a currency replacement.
Unlike gold, he believes Bitcoin (BTC) is not a “inflation hedge”. They acted more like growth stocks in 2022. “Bitcoin correlated more closely with the S&P 500 index — and Ether with the NASDAQ — than gold,” he told Cointelegraph. But in the developing world, things are different:
“Inflation may be a primary driver of cryptocurrency adoption in emerging markets like Brazil, India, and Mexico.”
According to Justin d'Anethan, institutional sales director at the Amber Group, a Singapore-based digital asset firm, early adoption was driven by countries where currency stability and/or access to proper banking services were issues. Simply put, he said, developing countries want alternatives to easily debased fiat currencies.
“The larger flows may still come from institutions and developed countries, but the actual users may come from places like Lebanon, Turkey, Venezuela, and Indonesia.”
“Inflation is one of the factors that has and continues to drive adoption of Bitcoin and other crypto assets globally,” said Sean Stein Smith, assistant professor of economics and business at Lehman College.
But it's only one factor, and different regions have different factors, says Stein Smith. As a “instantaneously accessible, traceable, and cost-effective transaction option,” investors and entrepreneurs increasingly recognize the benefits of crypto assets. Other places promote crypto adoption due to “potential capital gains and returns”.
According to the report, “legal uncertainty around cryptocurrency,” tax questions, and a general education deficit could hinder adoption in Asia Pacific and Latin America. In Africa, 56% of respondents said more educational resources were needed to explain cryptocurrencies.
Not only inflation, but empowering our youth to live better than their parents without fear of failure or allegiance to legacy financial markets or products, said Monica Singer, ConsenSys South Africa lead. Also, “the issue of cash and remittances is huge in Africa, as is the issue of social grants.”
Money's future?
The survey found that Brazil and Indonesia had the most cryptocurrency ownership. In each country, 41% of those polled said they owned crypto. Only 20% of Americans surveyed said they owned cryptocurrency.
These markets are more likely to see cryptocurrencies as the future of money. The survey found:
“The majority of respondents in Latin America (59%) and Africa (58%) say crypto is the future of money.”
Brazil (66%), Nigeria (63%), Indonesia (61%), and South Africa (57%). Europe and Australia had the fewest believers, with Denmark at 12%, Norway at 15%, and Australia at 17%.
Will the Ukraine conflict impact adoption?
The poll was taken before the war. Will the devastating conflict slow global crypto adoption growth?
With over $100 million in crypto donations directly requested by the Ukrainian government since the war began, Stein Smith says the war has certainly brought crypto into the mainstream conversation.
“This real-world demonstration of decentralized money's power could spur wider adoption, policy debate, and increased use of crypto as a medium of exchange.”
But the war may not affect all developing nations. “The Ukraine war has no impact on African demand for crypto,” Others loom larger. “Yes, inflation, but also a lack of trust in government in many African countries, and a young demographic very familiar with mobile phones and the internet.”
A major success story like Mpesa in Kenya has influenced the continent and may help accelerate crypto adoption. Creating a plan when everyone you trust fails you is directly related to the African spirit, she said.
On the other hand, Ma views the Ukraine conflict as a sort of crisis check for cryptocurrencies. For those in emerging markets, the Ukraine-Russia war has served as a “stress test” for the cryptocurrency payment rail, he told Cointelegraph.
“These emerging markets may see the greatest future gains in crypto adoption.”
Inflation and currency devaluation are persistent global concerns. In such places, Bitcoin and other cryptocurrencies are now seen as the “future of money.” Not in the developed world, but that could change with better regulation and education. Inflation and its impact on cash holdings are waking up even Western nations.
Read original post here.