





More on Society & Culture

Charlie Brown
3 years ago
What Happens When You Sell Your House, Never Buying It Again, Reverse the American Dream
Homeownership isn't the only life pattern.

Want to irritate people?
My party trick is to say I used to own a house but no longer do.
I no longer wish to own a home, not because I lost it or because I'm moving.
It was a long-term plan. It was more deliberate than buying a home. Many people are committed for this reason.
Poppycock.
Anyone who told me that owning a house (or striving to do so) is a must is wrong.
Because, URGH.
One pattern for life is to own a home, but there are millions of others.
You can afford to buy a home? Go, buddy.
You think you need 1,000 square feet (or more)? You think it's non-negotiable in life?
Nope.
It's insane that society forces everyone to own real estate, regardless of income, wants, requirements, or situation. As if this trade brings happiness, stability, and contentment.
Take it from someone who thought this for years: drywall isn't happy. Living your way brings contentment.
That's in real estate. It may also be renting a small apartment in a city that makes your soul sing, but you can't afford the downpayment or mortgage payments.
Living or traveling abroad is difficult when your life savings are connected to something that eats your money the moment you sign.
#vanlife, which seems like torment to me, makes some people feel alive.
I've seen co-living, vacation rental after holiday rental, living with family, and more work.
Insisting that home ownership is the only path in life is foolish and reduces alternative options.
How little we question homeownership is a disgrace.
No one challenges a homebuyer's motives. We congratulate them, then that's it.
When you offload one, you must answer every question, even if you have a loose screw.
Why do you want to sell?
Do you have any concerns about leaving the market?
Why would you want to renounce what everyone strives for?
Why would you want to abandon a beautiful place like that?
Why would you mismanage your cash in such a way?
But surely it's only temporary? RIGHT??
Incorrect questions. Buying a property requires several inquiries.
The typical American has $4500 saved up. When something goes wrong with the house (not if, it’s never if), can you actually afford the repairs?
Are you certain that you can examine a home in less than 15 minutes before committing to buying it outright and promising to pay more than twice the asking price on a 30-year 7% mortgage?
Are you certain you're ready to leave behind friends, family, and the services you depend on in order to acquire something?
Have you thought about the connotation that moving to a suburb, which more than half of Americans do, means you will be dependent on a car for the rest of your life?
Plus:
Are you sure you want to prioritize home ownership over debt, employment, travel, raising kids, and daily routines?
Homeownership entails that. This ex-homeowner says it will rule your life from the time you put the key in the door.
This isn't questioned. We don't question enough. The holy home-ownership grail was set long ago, and we don't challenge it.
Many people question after signing the deeds. 70% of homeowners had at least one regret about buying a property, including the expense.
Exactly. Tragic.
Homes are different from houses
We've been fooled into thinking home ownership will make us happy.
Some may agree. No one.
Bricks and brick hindered me from living the version of my life that made me most comfortable, happy, and steady.
I'm spending the next month in a modest apartment in southern Spain. Even though it's late November, today will be 68 degrees. My spouse and I will soon meet his visiting parents. We'll visit a Sherry store. We'll eat, nap, walk, and drink Sherry. Writing. Jerez means flamenco.
That's my home. This is such a privilege. Living a fulfilling life brings me the contentment that buying a home never did.
I'm happy and comfortable knowing I can make almost all of my days good. Rejecting home ownership is partly to blame.
I'm broke like most folks. I had to choose between home ownership and comfort. I said, I didn't find them together.
Feeling at home trumps owning brick-and-mortar every day.
The following is the reality of what it's like to turn the American Dream around.
Leaving the housing market.
Sometimes I wish I owned a home.
I miss having my own yard and bed. My kitchen, cookbooks, and pizza oven are missed.
But I rarely do.
Someone else's life plan pushed home ownership on me. I'm grateful I figured it out at 35. Many take much longer, and some never understand homeownership stinks (for them).
It's confusing. People will think you're dumb or suicidal.
If you read what I write, you'll know. You'll realize that all you've done is choose to live intentionally. Find a home beyond four walls and a picket fence.
Miss? As I said, they're not home. If it were, a pizza oven, a good mattress, and a well-stocked kitchen would bring happiness.
No.
If you can afford a house and desire one, more power to you.
There are other ways to discover home. Find calm and happiness. For fun.
For it, look deeper than your home's foundation.

The woman
3 years ago
The renowned and highest-paid Google software engineer
His story will inspire you.

“Google search went down for a few hours in 2002; Jeff Dean handled all the queries by hand and checked quality doubled.”- Jeff Dean Facts.
One of many Jeff Dean jokes, but you get the idea.
Google's top six engineers met in a war room in mid-2000. Google's crawling system, which indexed the Web, stopped working. Users could still enter queries, but results were five months old.
Google just signed a deal with Yahoo to power a ten-times-larger search engine. Tension rose. It was crucial. If they failed, the Yahoo agreement would likely fall through, risking bankruptcy for the firm. Their efforts could be lost.
A rangy, tall, energetic thirty-one-year-old man named Jeff dean was among those six brilliant engineers in the makeshift room. He had just left D. E. C. a couple of months ago and started his career in a relatively new firm Google, which was about to change the world. He rolled his chair over his colleague Sanjay and sat right next to him, cajoling his code like a movie director. The history started from there.
When you think of people who shaped the World Wide Web, you probably picture founders and CEOs like Larry Page and Sergey Brin, Marc Andreesen, Tim Berners-Lee, Bill Gates, and Mark Zuckerberg. They’re undoubtedly the brightest people on earth.
Under these giants, legions of anonymous coders work at keyboards to create the systems and products we use. These computer workers are irreplaceable.
Let's get to know him better.
It's possible you've never heard of Jeff Dean. He's American. Dean created many behind-the-scenes Google products. Jeff, co-founder and head of Google's deep learning research engineering team, is a popular technology, innovation, and AI keynote speaker.
While earning an MS and Ph.D. in computer science at the University of Washington, he was a teaching assistant, instructor, and research assistant. Dean joined the Compaq Computer Corporation Western Research Laboratory research team after graduating.
Jeff co-created ProfileMe and the Continuous Profiling Infrastructure for Digital at Compaq. He co-designed and implemented Swift, one of the fastest Java implementations. He was a senior technical staff member at mySimon Inc., retrieving and caching electronic commerce content.
Dean, a top young computer scientist, joined Google in mid-1999. He was always trying to maximize a computer's potential as a child.
An expert
His high school program for processing massive epidemiological data was 26 times faster than professionals'. Epi Info, in 13 languages, is used by the CDC. He worked on compilers as a computer science Ph.D. These apps make source code computer-readable.
Dean never wanted to work on compilers forever. He left Academia for Google, which had less than 20 employees. Dean helped found Google News and AdSense, which transformed the internet economy. He then addressed Google's biggest issue, scaling.
Growing Google faced a huge computing challenge. They developed PageRank in the late 1990s to return the most relevant search results. Google's popularity slowed machine deployment.
Dean solved problems, his specialty. He and fellow great programmer Sanjay Ghemawat created the Google File System, which distributed large data over thousands of cheap machines.
These two also created MapReduce, which let programmers handle massive data quantities on parallel machines. They could also add calculations to the search algorithm. A 2004 research article explained MapReduce, which became an industry sensation.
Several revolutionary inventions
Dean's other initiatives were also game-changers. BigTable, a petabyte-capable distributed data storage system, was based on Google File. The first global database, Spanner, stores data on millions of servers in dozens of data centers worldwide.
It underpins Gmail and AdWords. Google Translate co-founder Jeff Dean is surprising. He contributes heavily to Google News. Dean is Senior Fellow of Google Research and Health and leads Google AI.
Recognitions
The National Academy of Engineering elected Dean in 2009. He received the 2009 Association for Computing Machinery fellowship and the 2016 American Academy of Arts and Science fellowship. He received the 2007 ACM-SIGOPS Mark Weiser Award and the 2012 ACM-Infosys Foundation Award. Lists could continue.
A sneaky question may arrive in your mind: How much does this big brain earn? Well, most believe he is one of the highest-paid employees at Google. According to a survey, he is paid $3 million a year.
He makes espresso and chats with a small group of Googlers most mornings. Dean steams milk, another grinds, and another brews espresso. They discuss families and technology while making coffee. He thinks this little collaboration and idea-sharing keeps Google going.
“Some of us have been working together for more than 15 years,” Dean said. “We estimate that we’ve collectively made more than 20,000 cappuccinos together.”
We all know great developers and software engineers. It may inspire many.

Mike Meyer
3 years ago
Reality Distortion
Old power paradigm blocks new planetary paradigm

The difference between our reality and the media's reality is like a tale of two worlds. The greatest and worst of times, really.
Expanding information demands complex skills and understanding to separate important information from ignorance and crap. And that's just the start of determining the source's aim.
Trust who? We see people trust liars in public and then be destroyed by their decisions. Mistakes may be devastating.
Many give up and don't trust anyone. Reality is a choice, though. Same risks.
We must separate our needs and wants from reality. Needs and wants have rules. Greed and selfishness create an unlivable planet.
Culturally, we know this, but we ignore it as foolish. Selfish and greedy people obtain what they want, while others suffer.
We invade, plunder, rape, and burn. We establish civilizations by institutionalizing an exploitable underclass and denying its existence. These cultural lies promote greed and selfishness despite their destructiveness.
Controlling parts of society institutionalize these lies as fact. Many of each age are willing to gamble on greed because they were taught to see greed and selfishness as principles justified by prosperity.
Our cultural understanding recognizes the long-term benefits of collaboration and sharing. This older understanding generates an increasing tension between greedy people and those who see its planetary effects.
Survival requires distinguishing between global and regional realities. Simple, yet many can't do it. This is the first time human greed has had a global impact.
In the past, conflict stories focused on regional winners and losers. Losers lose, winners win, etc. Powerful people see potential decades of nuclear devastation as local, overblown, and not personally dangerous.
Mutually Assured Destruction (MAD) was a human choice that required people to acquiesce to irrational devastation. This prevented nuclear destruction. Most would refuse.
A dangerous “solution” relies on nuclear trigger-pullers not acting irrationally. Since then, we've collected case studies of sane people performing crazy things in experiments. We've been lucky, but the climate apocalypse could be different.
Climate disaster requires only continuing current behavior. These actions already cause global harm, but that's not a threat. These activities must be viewed differently.
Once grasped, denying planetary facts is hard to accept. Deniers can't think beyond regional power. Seeing planet-scale is unusual.
Decades of indoctrination defining any planetary perspective as un-American implies communal planetary assets are for plundering. The old paradigm limits any other view.
In the same way, the new paradigm sees the old regional power paradigm as a threat to planetary civilization and lifeforms. Insane!
While MAD relied on leaders not acting stupidly to trigger a nuclear holocaust, the delayed climatic holocaust needs correcting centuries of lunacy. We must stop allowing craziness in global leadership.
Nothing in our acknowledged past provides a paradigm for such. Only primitive people have failed to reach our level of sophistication.
Before European colonization, certain North American cultures built sophisticated regional nations but abandoned them owing to authoritarian cruelty and destruction. They were overrun by societies that saw no wrong in perpetual exploitation. David Graeber's The Dawn of Everything is an example of historical rediscovery, which is now crucial.
From the new paradigm's perspective, the old paradigm is irrational, yet it's too easy to see those in it as ignorant or malicious, if not both. These people are both, but the collapsing paradigm they promote is older or more ingrained than we think.
We can't shift that paradigm's view of a dead world. We must eliminate this mindset from our nations' leadership. No other way will preserve the earth.
Change is occurring. As always with tremendous transition, younger people are building the new paradigm.
The old paradigm's disintegration is insane. The ability to detect errors and abandon their sources is more important than age. This is gaining recognition.
The breakdown of the previous paradigm is not due to senile leadership, but to systemic problems that the current, conservative leadership cannot recognize.
Stop following the old paradigm.
You might also like

Jared A. Brock
4 years ago
Here is the actual reason why Russia invaded Ukraine
Democracy's demise
Our Ukrainian brothers and sisters are being attacked by a far superior force.
It's the biggest invasion since WWII.
43.3 million peaceful Ukrainians awoke this morning to tanks, mortars, and missiles. Russia is already 15 miles away.
America and the West will not deploy troops.
They're sanctioning. Except railways. And luxuries. And energy. Diamonds. Their dependence on Russian energy exports means they won't even cut Russia off from SWIFT.
Ukraine is desperate enough to hand out guns on the street.
France, Austria, Turkey, and the EU are considering military aid, but Ukraine will fall without America or NATO.
The Russian goal is likely to encircle Kyiv and topple Zelenskyy's government. A proxy power will be reinstated once Russia has total control.
“Western security services believe Putin intends to overthrow the government and install a puppet regime,” says Financial Times foreign affairs commentator Gideon Rachman. This “decapitation” strategy includes municipalities. Ukrainian officials are being targeted for arrest or death.”
Also, Putin has never lost a war.
Why is Russia attacking Ukraine?
Putin, like a snowflake college student, “feels unsafe.”
Why?
Because Ukraine is full of “Nazi ideas.”
Putin claims he has felt threatened by Ukraine since the country's pro-Putin leader was ousted and replaced by a popular Jewish comedian.
Hee hee
He fears a full-scale enemy on his doorstep if Ukraine joins NATO. But he refuses to see it both ways. NATO has never invaded Russia, but Russia has always stolen land from its neighbors. Can you blame them for joining a mutual defense alliance when a real threat exists?
Nations that feel threatened can join NATO. That doesn't justify an attack by Russia. It allows them to defend themselves. But NATO isn't attacking Moscow. They aren't.
Russian President Putin's "special operation" aims to de-Nazify the Jewish-led nation.
To keep Crimea and the other two regions he has already stolen, he wants Ukraine undefended by NATO.
(Warlords have fought for control of the strategically important Crimea for over 2,000 years.)
Putin wants to own all of Ukraine.
Why?
The Black Sea is his goal.
Ports bring money and power, and Ukraine pipelines transport Russian energy products.
Putin wants their wheat, too — with 70% crop coverage, Ukraine would be their southern breadbasket, and Russia has no qualms about starving millions of Ukrainians to death to feed its people.
In the end, it's all about greed and power.
Putin wants to own everything Russia has ever owned. This year he turns 70, and he wants to be remembered like his hero Peter the Great.
In order to get it, he's willing to kill thousands of Ukrainians
Art imitates life
This story began when a Jewish TV comedian portrayed a teacher elected President after ranting about corruption.
Servant of the People, the hit sitcom, is now the leading centrist political party.
Right, President Zelenskyy won the hearts and minds of Ukrainians by imagining a fairer world.
A fair fight is something dictators, corporatists, monopolists, and warlords despise.
Now Zelenskyy and his people will die, allowing one of history's most corrupt leaders to amass even more power.
The poor always lose
Meanwhile, the West will impose economic sanctions on Russia.
China is likely to step in to help Russia — or at least the wealthy.
The poor and working class in Russia will suffer greatly if there is a hard crash or long-term depression.
Putin's friends will continue to drink champagne and eat caviar.
Russia cutting off oil, gas, and fertilizer could cause more inflation and possibly a recession if it cuts off supplies to the West. This causes more suffering and hardship for the Western poor and working class.
Why? a billionaire sociopath gets his dirt.
Yes, Russia is simply copying America. Some of us think all war is morally wrong, regardless of who does it.
But let's not kid ourselves right now.
The markets rallied after the biggest invasion in Europe since WWII.
Investors hope Ukraine collapses and Russian oil flows.
Unbridled capitalists value lifeless.
What we can do about Ukraine
When the Russian army invaded eastern Finland, my wife's grandmother fled as a child. 80 years later, Russia still has Karelia.
Russia invaded Ukraine today to retake two eastern provinces.
History has taught us nothing.
Past mistakes won't fix the future.
Instead, we should try:
- Pray and/or meditate on our actions with our families.
- Stop buying Russian products (vodka, obviously, but also pay more for hydro/solar/geothermal/etc.)
- Stop wasting money on frivolous items and donate it to Ukrainian charities.
Here are 35+ places to donate.
- To protest, gather a few friends, contact the media, and shake signs in front of the Russian embassy.
- Prepare to welcome refugees.
More war won't save the planet or change hearts.
Only love can work.

Guillaume Dumortier
3 years ago
Mastering the Art of Rhetoric: A Guide to Rhetorical Devices in Successful Headlines and Titles
Unleash the power of persuasion and captivate your audience with compelling headlines.
As the old adage goes, "You never get a second chance to make a first impression."
In the world of content creation and social ads, headlines and titles play a critical role in making that first impression.
A well-crafted headline can make the difference between an article being read or ignored, a video being clicked on or bypassed, or a product being purchased or passed over.
To make an impact with your headlines, mastering the art of rhetoric is essential. In this post, we'll explore various rhetorical devices and techniques that can help you create headlines that captivate your audience and drive engagement.
tl;dr : Headline Magician will help you craft the ultimate headline titles powered by rhetoric devices
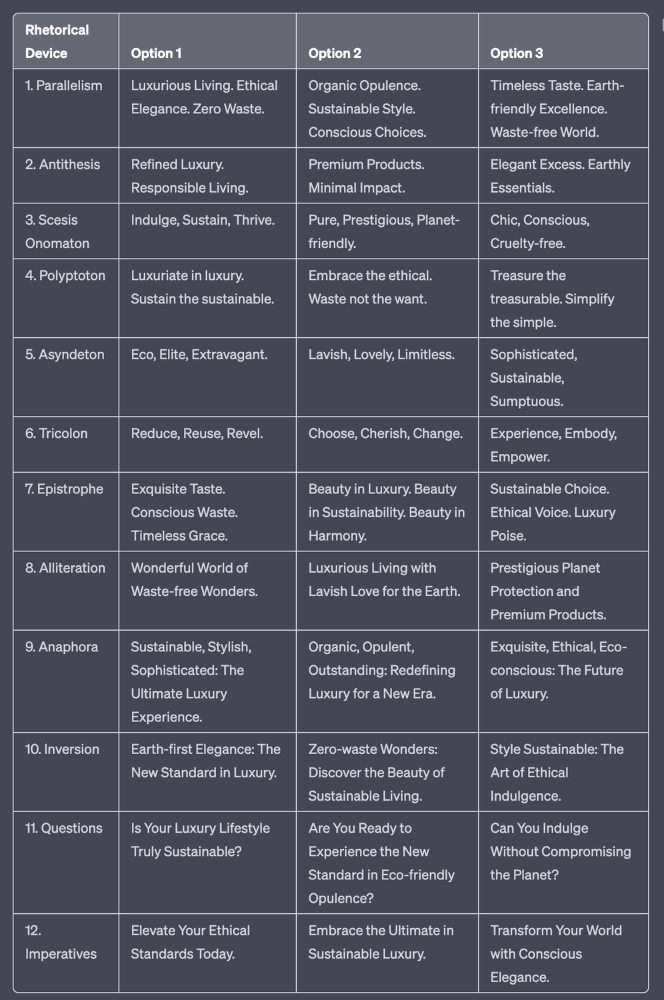
Example with a high-end luxury organic zero-waste skincare brand
✍️ The Power of Alliteration
Alliteration is the repetition of the same consonant sound at the beginning of words in close proximity. This rhetorical device lends itself well to headlines, as it creates a memorable, rhythmic quality that can catch a reader's attention.
By using alliteration, you can make your headlines more engaging and easier to remember.
Examples:
"Crafting Compelling Content: A Comprehensive Course"
"Mastering the Art of Memorable Marketing"
🔁 The Appeal of Anaphora
Anaphora is the repetition of a word or phrase at the beginning of successive clauses. This rhetorical device emphasizes a particular idea or theme, making it more memorable and persuasive.
In headlines, anaphora can be used to create a sense of unity and coherence, which can draw readers in and pique their interest.
Examples:
"Create, Curate, Captivate: Your Guide to Social Media Success"
"Innovation, Inspiration, and Insight: The Future of AI"
🔄 The Intrigue of Inversion
Inversion is a rhetorical device where the normal order of words is reversed, often to create an emphasis or achieve a specific effect.
In headlines, inversion can generate curiosity and surprise, compelling readers to explore further.
Examples:
"Beneath the Surface: A Deep Dive into Ocean Conservation"
"Beyond the Stars: The Quest for Extraterrestrial Life"
⚖️ The Persuasive Power of Parallelism
Parallelism is a rhetorical device that involves using similar grammatical structures or patterns to create a sense of balance and symmetry.
In headlines, parallelism can make your message more memorable and impactful, as it creates a pleasing rhythm and flow that can resonate with readers.
Examples:
"Eat Well, Live Well, Be Well: The Ultimate Guide to Wellness"
"Learn, Lead, and Launch: A Blueprint for Entrepreneurial Success"
⏭️ The Emphasis of Ellipsis
Ellipsis is the omission of words, typically indicated by three periods (...), which suggests that there is more to the story.
In headlines, ellipses can create a sense of mystery and intrigue, enticing readers to click and discover what lies behind the headline.
Examples:
"The Secret to Success... Revealed"
"Unlocking the Power of Your Mind... A Step-by-Step Guide"
🎭 The Drama of Hyperbole
Hyperbole is a rhetorical device that involves exaggeration for emphasis or effect.
In headlines, hyperbole can grab the reader's attention by making bold, provocative claims that stand out from the competition. Be cautious with hyperbole, however, as overuse or excessive exaggeration can damage your credibility.
Examples:
"The Ultimate Guide to Mastering Any Skill in Record Time"
"Discover the Revolutionary Technique That Will Transform Your Life"
❓The Curiosity of Questions
Posing questions in your headlines can be an effective way to pique the reader's curiosity and encourage engagement.
Questions compel the reader to seek answers, making them more likely to click on your content. Additionally, questions can create a sense of connection between the content creator and the audience, fostering a sense of dialogue and discussion.
Examples:
"Are You Making These Common Mistakes in Your Marketing Strategy?"
"What's the Secret to Unlocking Your Creative Potential?"
💥 The Impact of Imperatives
Imperatives are commands or instructions that urge the reader to take action. By using imperatives in your headlines, you can create a sense of urgency and importance, making your content more compelling and actionable.
Examples:
"Master Your Time Management Skills Today"
"Transform Your Business with These Innovative Strategies"
💢 The Emotion of Exclamations
Exclamations are powerful rhetorical devices that can evoke strong emotions and convey a sense of excitement or urgency.
Including exclamations in your headlines can make them more attention-grabbing and shareable, increasing the chances of your content being read and circulated.
Examples:
"Unlock Your True Potential: Find Your Passion and Thrive!"
"Experience the Adventure of a Lifetime: Travel the World on a Budget!"
🎀 The Effectiveness of Euphemisms
Euphemisms are polite or indirect expressions used in place of harsher, more direct language.
In headlines, euphemisms can make your message more appealing and relatable, helping to soften potentially controversial or sensitive topics.
Examples:
"Navigating the Challenges of Modern Parenting"
"Redefining Success in a Fast-Paced World"
⚡Antithesis: The Power of Opposites
Antithesis involves placing two opposite words side-by-side, emphasizing their contrasts. This device can create a sense of tension and intrigue in headlines.
Examples:
"Once a day. Every day"
"Soft on skin. Kill germs"
"Mega power. Mini size."
To utilize antithesis, identify two opposing concepts related to your content and present them in a balanced manner.
🎨 Scesis Onomaton: The Art of Verbless Copy
Scesis onomaton is a rhetorical device that involves writing verbless copy, which quickens the pace and adds emphasis.
Example:
"7 days. 7 dollars. Full access."
To use scesis onomaton, remove verbs and focus on the essential elements of your headline.
🌟 Polyptoton: The Charm of Shared Roots
Polyptoton is the repeated use of words that share the same root, bewitching words into memorable phrases.
Examples:
"Real bread isn't made in factories. It's baked in bakeries"
"Lose your knack for losing things."
To employ polyptoton, identify words with shared roots that are relevant to your content.
✨ Asyndeton: The Elegance of Omission
Asyndeton involves the intentional omission of conjunctions, adding crispness, conviction, and elegance to your headlines.
Examples:
"You, Me, Sushi?"
"All the latte art, none of the environmental impact."
To use asyndeton, eliminate conjunctions and focus on the core message of your headline.
🔮 Tricolon: The Magic of Threes
Tricolon is a rhetorical device that uses the power of three, creating memorable and impactful headlines.
Examples:
"Show it, say it, send it"
"Eat Well, Live Well, Be Well."
To use tricolon, craft a headline with three key elements that emphasize your content's main message.
🔔 Epistrophe: The Chime of Repetition
Epistrophe involves the repetition of words or phrases at the end of successive clauses, adding a chime to your headlines.
Examples:
"Catch it. Bin it. Kill it."
"Joint friendly. Climate friendly. Family friendly."
To employ epistrophe, repeat a key phrase or word at the end of each clause.

Jenn Leach
3 years ago
This clever Instagram marketing technique increased my sales to $30,000 per month.
No Paid Ads Required

I had an online store. After a year of running the company alongside my 9-to-5, I made enough to resign.
That day was amazing.
This Instagram marketing plan helped the store succeed.
How did I increase my sales to five figures a month without using any paid advertising?
I used customer event marketing.
I'm not sure this term exists. I invented it to describe what I was doing.
Instagram word-of-mouth, fan engagement, and interaction drove sales.
If a customer liked or disliked a product, the buzz would drive attention to the store.
I used customer-based events to increase engagement and store sales.
Success!
Here are the weekly Instagram customer events I coordinated while running my business:
Be the Buyer Days
Flash sales
Mystery boxes
Be the Buyer Days: How do they work?
Be the Buyer Days are exactly that.
You choose a day to share stock selections with social media followers.
This is an easy approach to engaging customers and getting fans enthusiastic about new releases.
First, pick a handful of items you’re considering ordering. I’d usually pick around 3 for Be the Buyer Day.
Then I'd poll the crowd on Instagram to vote on their favorites.
This was before Instagram stories, polls, and all the other cool features Instagram offers today. I think using these tools now would make this event even better.
I'd ask customers their favorite back then.
The growing comments excited customers.
Then I'd declare the winner, acquire the products, and start selling it.
How do flash sales work?
I mostly ran flash sales.
You choose a limited number of itemsdd for a few-hour sale.
We wanted most sales to result in sold-out items.
When an item sells out, it contributes to the sensation of scarcity and can inspire customers to visit your store to buy a comparable product, join your email list, become a fan, etc.
We hoped they'd act quickly.
I'd hold flash deals twice a week, which generated scarcity and boosted sales.
The store had a few thousand Instagram followers when I started flash deals.
Each flash sale item would make $400 to $600.
$400 x 3= $1,200
That's $1,200 on social media!
Twice a week, you'll make roughly $10K a month from Instagram.
$1,200/day x 8 events/month=$9,600
Flash sales did great.
We held weekly flash deals and sent social media and email reminders. That’s about it!
How are mystery boxes put together?
All you do is package a box of store products and sell it as a mystery box on TikTok or retail websites.
A $100 mystery box would cost $30.
You're discounting high-value boxes.
This is a clever approach to get rid of excess inventory and makes customers happy.
It worked!
Be the Buyer Days, flash deals, and mystery boxes helped build my company without paid advertisements.
All companies can use customer event marketing. Involving customers and providing an engaging environment can boost sales.
Try it!