



More on Entrepreneurship/Creators

Rachel Greenberg
3 years ago
The Unsettling Fact VC-Backed Entrepreneurs Don't Want You to Know
What they'll do is scarier.

My acquaintance recently joined a VC-funded startup. Money, equity, and upside possibilities were nice, but he had a nagging dread.
They just secured a $40M round and are hiring like crazy to prepare for their IPO in two years. All signals pointed to this startup's (a B2B IT business in a stable industry) success, and its equity-holding workers wouldn't pass that up.
Five months after starting the work, my friend struggled with leaving. We might overlook the awful culture and long hours at the proper price. This price plus the company's fate and survival abilities sent my friend departing in an unpleasant unplanned resignation before jumping on yet another sinking ship.
This affects founders. This affects VC-backed companies (and all businesses). This affects anyone starting, buying, or running a business.
Here's the under-the-table approach that's draining VC capital, leaving staff terrified (or jobless), founders rattled, and investors upset. How to recognize, solve, and avoid it
The unsettling reality behind door #1
You can't raise money off just your looks, right? If "looks" means your founding team's expertise, then maybe. In my friend's case, the founding team's strong qualifications and track records won over investors before talking figures.
They're hardly the only startup to raise money without a profitable customer acquisition strategy. Another firm raised money for an expensive sleep product because it's eco-friendly. They were off to the races with a few keywords and key players.
Both companies, along with numerous others, elected to invest on product development first. Company A employed all the tech, then courted half their market (they’re a tech marketplace that connects two parties). Company B spent millions on R&D to create a palatable product, then flooded the world with marketing.
My friend is on Company B's financial team, and he's seen where they've gone wrong. It's terrible.
Company A (tech market): Growing? Not quite. To achieve the ambitious expansion they (and their investors) demand, they've poured much of their little capital into salespeople: Cold-calling commission and salary salesmen. Is it working? Considering attrition and companies' dwindling capital, I don't think so.
Company B (green sleep) has been hiring, digital marketing, and opening new stores like crazy. Growing expenses should result in growing revenues and a favorable return on investment; if you grow too rapidly, you may neglect to check that ROI.
Once Company A cut headcount and Company B declared “going concerned”, my friend realized both startups had the same ailment and didn't recognize it.
I shouldn't have to ask a friend to verify a company's cash reserves and profitability to spot a financial problem. It happened anyhow.
The frightening part isn't that investors were willing to invest millions without product-market fit, CAC, or LTV estimates. That's alarming, but not as scary as the fact that startups aren't understanding the problem until VC rounds have dried up.
When they question consultants if their company will be around in 6 months. It’s a red flag. How will they stretch $20M through a 2-year recession with a $3M/month burn rate and no profitability? Alarms go off.
Who's in danger?
In a word, everyone who raised money without a profitable client acquisition strategy or enough resources to ride out dry spells.
Money mismanagement and poor priorities affect every industry (like sinking all your capital into your product, team, or tech, at the expense of probing what customer acquisition really takes and looks like).
This isn't about tech, real estate, or recession-proof luxury products. Fast, cheap, easy money flows into flashy-looking teams with buzzwords, trending industries, and attractive credentials.
If these companies can't show progress or get a profitable CAC, they can't raise more money. They die if they can't raise more money (or slash headcount and find shoestring budget solutions until they solve the real problem).
The kiss of death (and how to avoid it)
If you're running a startup and think raising VC is the answer, pause and evaluate. Do you need the money now?
I'm not saying VC is terrible or has no role. Founders have used it as a Band-Aid for larger, pervasive problems. Venture cash isn't a crutch for recruiting consumers profitably; it's rocket fuel to get you what and who you need.
Pay-to-play isn't a way to throw money at the wall and hope for a return. Pay-to-play works until you run out of money, and if you haven't mastered client acquisition, your cash will diminish quickly.
How can you avoid this bottomless pit? Tips:
Understand your burn rate
Keep an eye on your growth or profitability.
Analyze each and every marketing channel and initiative.
Make lucrative customer acquisition strategies and satisfied customers your top two priorities. not brand-new products. not stellar hires. avoid the fundraising rollercoaster to save time. If you succeed in these two tasks, investors will approach you with their thirsty offers rather than the other way around, and your cash reserves won't diminish as a result.
Not as much as your grandfather
My family friend always justified expensive, impractical expenditures by saying it was only monopoly money. In business, startups, and especially with money from investors expecting a return, that's not true.
More founders could understand that there isn't always another round if they viewed VC money as their own limited pool. When the well runs dry, you must refill it or save the day.
Venture financing isn't your grandpa's money. A discerning investor has entrusted you with dry powder in the hope that you'll use it wisely, strategically, and thoughtfully. Use it well.

ʟ ᴜ ᴄ ʏ
3 years ago
The Untapped Gold Mine of Inspiration and Startup Ideas
I joined the 1000 Digital Startups Movement (Gerakan 1000 Startup Digital) in 2017 and learned a lot about the startup sector. My previous essay outlined what a startup is and what must be prepared. Here I'll offer raw ideas for better products.

Intro
A good startup solves a problem. These can include environmental, economic, energy, transportation, logistics, maritime, forestry, livestock, education, tourism, legal, arts and culture, communication, and information challenges. Everything I wrote is simply a basic idea (as inspiration) and requires more mapping and validation. Learn how to construct a startup to maximize launch success.
Adrian Gunadi (Investree Co-Founder) taught me that a Founder or Co-Founder must be willing to be CEO (Chief Everything Officer). Everything is independent, including drafting a proposal, managing finances, and scheduling appointments. The best individuals will come to you if you're the best. It's easier than consulting Andy Zain (Kejora Capital Founder).
Description
To help better understanding from your idea, try to answer this following questions:
- Describe your idea/application
Maximum 1000 characters.
- Background
Explain the reasons that prompted you to realize the idea/application.
- Objective
Explain the expected goals of the creation of the idea/application.
- Solution
A solution that tells your idea can be the right solution for the problem at hand.
- Uniqueness
What makes your idea/app unique?
- Market share
Who are the people who need and are looking for your idea?
- Marketing Ways and Business Models
What is the best way to sell your idea and what is the business model?
Not everything here is a startup idea. It's meant to inspire creativity and new perspectives.
Ideas
#Application
1. Medical students can operate on patients or not. Applications that train prospective doctors to distinguish body organs and their placement are useful. In the advanced stage, the app can be built with numerous approaches so future doctors can practice operating on patients based on their ailments. If they made a mistake, they'd start over. Future doctors will be more assured and make fewer mistakes this way.
2. VR (virtual reality) technology lets people see 3D space from afar. Later, similar technology was utilized to digitally sell properties, so buyers could see the inside and room contents. Every gadget has flaws. It's like a gold mine for robbers. VR can let prospective students see a campus's facilities. This facility can also help hotels promote their products.
3. How can retail entrepreneurs maximize sales? Most popular goods' sales data. By using product and brand/type sales figures, entrepreneurs can avoid overstocking. Walmart computerized their procedures to track products from the manufacturer to the store. As Retail Link products sell out, suppliers can immediately step in.
4. Failing to marry is something to be avoided. But if it had to happen, the loss would be like the proverb “rub salt into the wound”. On the I do Now I dont website, Americans who don't marry can resell their jewelry to other brides-to-be. If some want to cancel the wedding and receive their down money and dress back, others want a wedding with particular criteria, such as a quick date and the expected building. Create a DP takeover marketplace for both sides.
#Games
1. Like in the movie, players must exit the maze they enter within 3 minutes or the shape will change, requiring them to change their strategy. The maze's transformation time will shorten after a few stages.
2. Treasure hunts involve following clues to uncover hidden goods. Here, numerous sponsors are combined in one boat, and participants can choose a game based on the prizes. Let's say X-mart is a sponsor and provides riddles or puzzles to uncover the prize in their store. After gathering enough points, the player can trade them for a gift utilizing GPS and AR (augmented reality). Players can collaborate to increase their chances of success.
3. Where's Wally? Where’s Wally displays a thick image with several things and various Wally-like characters. We must find the actual Wally, his companions, and the desired object. Make a game with a map where players must find objects for the next level. The player must find 5 artifacts randomly placed in an Egyptian-style mansion, for example. In the room, there are standard tickets, pass tickets, and gold tickets that can be removed for safekeeping, as well as a wall-mounted carpet that can be stored but not searched and turns out to be a flying rug that can be used to cross/jump to a different place. Regular tickets are spread out since they can buy life or stuff. At a higher level, a black ticket can lower your ordinary ticket. Objects can explode, scattering previously acquired stuff. If a player runs out of time, they can exchange a ticket for more.
#TVprogram
1. At the airport there are various visitors who come with different purposes. Asking tourists to live for 1 or 2 days in the city will be intriguing to witness.
2. Many professions exist. Carpenters, cooks, and lawyers must have known about job desks. Does HRD (Human Resource Development) only recruit new employees? Many don't know how to become a CEO, CMO, COO, CFO, or CTO. Showing young people what a Program Officer in an NGO does can help them choose a career.
#StampsCreations
Philatelists know that only the government can issue stamps. I hope stamps are creative so they have more worth.
1. Thermochromic pigments (leuco dyes) are well-known for their distinctive properties. By putting pigments to black and white batik stamps, for example, the black color will be translucent and display the basic color when touched (at a hot temperature).
2. In 2012, Liechtenstein Post published a laser-art Chinese zodiac stamp. Belgium (Bruges Market Square 2012), Taiwan (Swallow Tail Butterfly 2009), etc. Why not make a stencil of the president or king/queen?
3. Each country needs its unique identity, like Taiwan's silk and bamboo stamps. Create from your country's history. Using traditional paper like washi (Japan), hanji (Korea), and daluang/saeh (Indonesia) can introduce a country's culture.
4. Garbage has long been a problem. Bagasse, banana fronds, or corn husks can be used as stamp material.
5. Austria Post published a stamp containing meteor dust in 2006. 2004 meteorite found in Morocco produced the dust. Gibraltar's Rock of Gilbraltar appeared on stamps in 2002. What's so great about your country? East Java is muddy (Lapindo mud). Lapindo mud stamps will be popular. Red sand at Pink Beach, East Nusa Tenggara, could replace the mud.
#PostcardCreations
1. Map postcards are popular because they make searching easier. Combining laser-cut road map patterns with perforated 200-gram paper glued on 400-gram paper as a writing medium. Vision-impaired people can use laser-cut maps.
2. Regional art can be promoted by tucking traditional textiles into postcards.
3. A thin canvas or plain paper on the card's front allows the giver to be creative.
4. What is local crop residue? Cork lids, maize husks, and rice husks can be recycled into postcard materials.
5. Have you seen a dried-flower bookmark? Cover the postcard with mica and add dried flowers. If you're worried about losing the flowers, you can glue them or make a postcard envelope.
6. Wood may be ubiquitous; try a 0.2-mm copper plate engraved with an image and connected to a postcard as a writing medium.
7. Utilized paper pulp can be used to hold eggs, smartphones, and food. Form a smooth paper pulp on the plate with the desired image, the Golden Gate bridge, and paste it on your card.
8. Postcards can promote perfume. When customers rub their hands on the card with the perfume image, they'll smell the aroma.
#Tour #Travel
Tourism activities can be tailored to tourists' interests or needs. Each tourist benefits from tourism's distinct aim.
Let's define tourism's objective and purpose.
Holiday Tour is a tour that its participants plan and do in order to relax, have fun, and amuse themselves.
A familiarization tour is a journey designed to help travelers learn more about (survey) locales connected to their line of work.
An educational tour is one that aims to give visitors knowledge of the field of work they are visiting or an overview of it.
A scientific field is investigated and knowledge gained as the major goal of a scientific tour.
A pilgrimage tour is one designed to engage in acts of worship.
A special mission tour is one that has a specific goal, such a commerce mission or an artistic endeavor.
A hunting tour is a destination for tourists that plans organized animal hunting that is only allowed by local authorities for entertainment purposes.
Every part of life has tourism potential. Activities include:
1. Those who desire to volunteer can benefit from the humanitarian theme and collaboration with NGOs. This activity's profit isn't huge but consider the environmental impact.
2. Want to escape the city? Meditation travel can help. Beautiful spots around the globe can help people forget their concerns. A certified yoga/meditation teacher can help travelers release bad energy.
3. Any prison visitors? Some prisons, like those for minors under 17, are open to visitors. This type of tourism helps mental convicts reach a brighter future.
4. Who has taken a factory tour/study tour? Outside-of-school study tour (for ordinary people who have finished their studies). Not everyone in school could tour industries, workplaces, or embassies to learn and be inspired. Shoyeido (an incense maker) and Royce (a chocolate maker) offer factory tours in Japan.
5. Develop educational tourism like astronomy and archaeology. Until now, only a few astronomy enthusiasts have promoted astronomy tourism. In Indonesia, archaeology activities focus on site preservation, and to participate, office staff must undertake a series of training (not everyone can take a sabbatical from their routine). Archaeological tourist activities are limited, whether held by history and culture enthusiasts or in regional tours.
6. Have you ever longed to observe a film being made or your favorite musician rehearsing? Such tours can motivate young people to pursue entertainment careers.
7. Pamper your pets to reduce stress. Many pet owners don't have time for walks or treats. These premium services target the wealthy.
8. A quirky idea to provide tours for imaginary couples or things. Some people marry inanimate objects or animals and seek to make their lover happy; others cherish their ashes after death.
#MISCideas
1. Fashion is a lifestyle, thus people often seek fresh materials. Chicken claws, geckos, snake skin casings, mice, bats, and fish skins are also used. Needs some improvement, definitely.
2. As fuel supplies become scarcer, people hunt for other energy sources. Sound is an underutilized renewable energy. The Batechsant technology converts environmental noise into electrical energy, according to study (Battery Technology Of Sound Power Plant). South Korean researchers use Sound-Driven Piezoelectric Nanowire based on Nanogenerators to recharge cell phone batteries. The Batechsant system uses existing noise levels to provide electricity for street lamp lights, aviation, and ships. Using waterfall sound can also energize hard-to-reach locations.
3. A New York Times reporter said IQ doesn't ensure success. Our school system prioritizes IQ above EQ (Emotional Quotient). EQ is a sort of human intelligence that allows a person to perceive and analyze the dynamics of his emotions when interacting with others (and with himself). EQ is suspected of being a bigger source of success than IQ. EQ training can gain greater attention to help people succeed. Prioritize role models from school stakeholders, teachers, and parents to improve children' EQ.
4. Teaching focuses more on theory than practice, so students are less eager to explore and easily forget if they don't pay attention. Has an engineer ever made bricks from arid red soil? Morocco's non-college-educated builders can create weatherproof bricks from red soil without equipment. Can mechanical engineering grads create a water pump to solve water shortages in remote areas? Art graduates can innovate beyond only painting. Artists may create kinetic sculpture by experimenting so much. Young people should understand these sciences so they can be more creative with their potential. These might be extracurricular activities in high school and university.
5. People have been trying to recycle agricultural waste for a long time. Mycelium helps replace light, easily crushed tiles and bricks (a collection of hyphae like in the manufacture of tempe). Waste must contain lignocellulose. In this vein, anti-mainstream painting canvases can be made. The goal is to create the canvas uneven like an amoeba outline, not square or spherical. The resulting canvas is lightweight and needs no frame. Then what? Open source your idea like Precious Plastic to establish a community. By propagating this notion, many knowledgeable people will help improve your product's quality and impact.
6. As technology and humans adapt, fraud increases. Making phony doctor's letters to fool superiors, fake credentials to get hired, fraudulent land certificates to make money, and fake news (hoax). The existence of a Wikimedia can aid the community by comparing bogus and original information.
7. Do you often hit a problem-solving impasse? Since the Doraemon bag hasn't been made, construct an Idea Bank. Everyone can contribute to solving problems here. How do you recruit volunteers? Obviously, a reward is needed. Contributors can become moderators or gain complimentary tickets to TIA (Tech in Asia) conferences. Idea Bank-related concepts: the rise of startups without a solid foundation generates an age as old as corn that does not continue. Those with startup ideas should describe them here so they can be validated by other users. Other users can contribute input if a comparable notion is produced to improve the product or integrate it. Similar-minded users can become Co-Founders.
8. Why not invest in fruit/vegetables, inspired by digital farming? The landowner obtains free fruit without spending much money on maintenance. Investors can get fruits/vegetables in larger quantities, fresher, and cheaper during harvest. Fruits and vegetables are often harmed if delivered too slowly. Rich investors with limited land can invest in teak, agarwood, and other trees. When harvesting, investors might choose raw results or direct wood sales earnings. Teak takes at least 7 years to harvest, therefore long-term wood investments carry the risk of crop failure.
9. Teenagers in distant locations can't count, read, or write. Many factors hinder locals' success. Life's demands force them to work instead of study. Creating a learning playground may attract young people to learning. Make a skatepark at school. Skateboarders must learn in school. Donations buy skateboards.
10. Globally, online taxi-bike is known. By hiring a motorcycle/car online, people no longer bother traveling without a vehicle. What if you wish to cross the island or visit remote areas? Is online boat or helicopter rental possible like online taxi-bike? Such a renting process has been done independently thus far and cannot be done quickly.
11. What do startups need now? A startup or investor consultant. How many startups fail to become Unicorns? Many founders don't know how to manage investor money, therefore they waste it on promotions and other things. Many investors only know how to invest and can't guide a struggling firm.
“In times of crisis, the wise build bridges, while the foolish build barriers.” — T’Challa [Black Panther]
Don't chase cash. Money is a byproduct. Profit-seeking is stressful. Market requirements are opportunities. If you have something to say, please comment.
This is only informational. Before implementing ideas, do further study.

SAHIL SAPRU
3 years ago
How I grew my business to a $5 million annual recurring revenue
Scaling your startup requires answering customer demands, not growth tricks.
I cofounded Freedo Rentals in 2019. I reached 50 lakh+ ARR in 6 months before quitting owing to the epidemic.
Freedo aimed to solve 2 customer pain points:
Users lacked a reliable last-mile transportation option.
The amount that Auto walas charge for unmetered services
Solution?
Effectively simple.
Build ports at high-demand spots (colleges, residential societies, metros). Electric ride-sharing can meet demand.
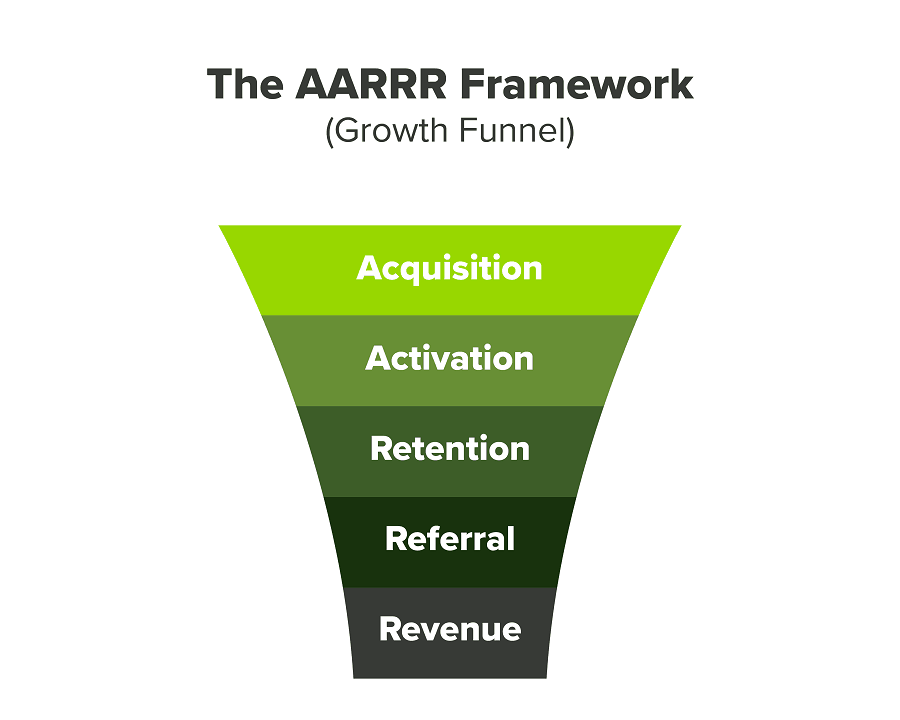
We had many problems scaling. I'll explain using the AARRR model.
Brand unfamiliarity or a novel product offering were the problems with awareness. Nobody knew what Freedo was or what it did.
Problem with awareness: Content and advertisements did a poor job of communicating the task at hand. The advertisements clashed with the white-collar part because they were too cheesy.
Retention Issue: We encountered issues, indicating that the product was insufficient. Problems with keyless entry, creating bills, stealing helmets, etc.
Retention/Revenue Issue: Costly compared to established rivals. Shared cars were 1/3 of our cost.
Referral Issue: Missing the opportunity to seize the AHA moment. After the ride, nobody remembered us.
Once you know where you're struggling with AARRR, iterative solutions are usually best.
Once you have nailed the AARRR model, most startups use paid channels to scale. This dependence, on paid channels, increases with scale unless you crack your organic/inbound game.
Over-index growth loops. Growth loops increase inflow and customers as you scale.
When considering growth, ask yourself:
Who is the solution's ICP (Ideal Customer Profile)? (To whom are you selling)
What are the most important messages I should convey to customers? (This is an A/B test.)
Which marketing channels ought I prioritize? (Conduct analysis based on the startup's maturity/stage.)
Choose the important metrics to monitor for your AARRR funnel (not all metrics are equal)
Identify the Flywheel effect's growth loops (inertia matters)
My biggest mistakes:
not paying attention to consumer comments or satisfaction. It is the main cause of problems with referrals, retention, and acquisition for startups. Beyond your NPS, you should consider second-order consequences.
The tasks at hand should be quite clear.
Here's my scaling equation:
Growth = A x B x C
A = Funnel top (Traffic)
B = Product Valuation (Solving a real pain point)
C = Aha! (Emotional response)
Freedo's A, B, and C created a unique offering.
Freedo’s ABC:
A — Working or Studying population in NCR
B — Electric Vehicles provide last-mile mobility as a clean and affordable solution
C — One click booking with a no-noise scooter
Final outcome:
FWe scaled Freedo to Rs. 50 lakh MRR and were growing 60% month on month till the pandemic ceased our growth story.
How we did it?
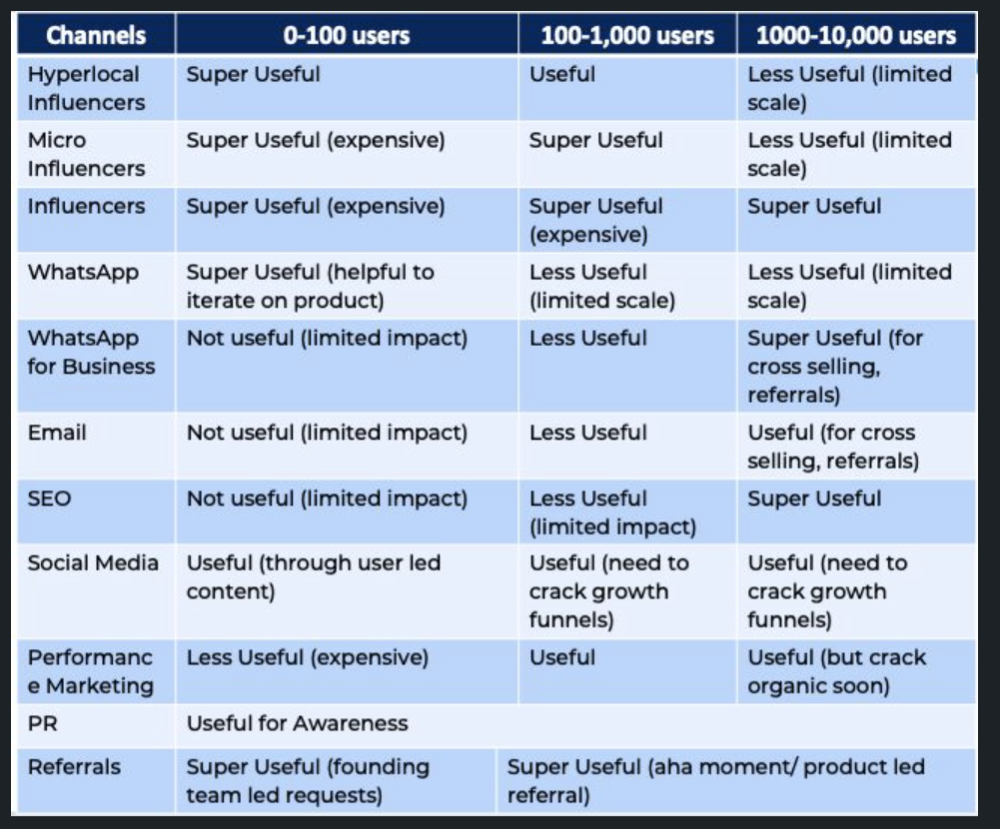
We tried ambassadors and coupons. WhatsApp was our most successful A/B test.
We grew widespread adoption through college and society WhatsApp groups. We requested users for referrals in community groups.
What worked for us won't work for others. This scale underwent many revisions.
Every firm is different, thus you must know your customers. Needs to determine which channel to prioritize and when.
Users desired a safe, time-bound means to get there.
This (not mine) growth framework helped me a lot. You should follow suit.
You might also like

Paul DelSignore
3 years ago
The stunning new free AI image tool is called Leonardo AI.
Leonardo—The New Midjourney?
Users are comparing the new cowboy to Midjourney.
Leonardo.AI creates great photographs and has several unique capabilities I haven't seen in other AI image systems.
Midjourney's quality photographs are evident in the community feed.

Create Pictures Using Models
You can make graphics using platform models when you first enter the app (website):
Luma, Leonardo creative, Deliberate 1.1.
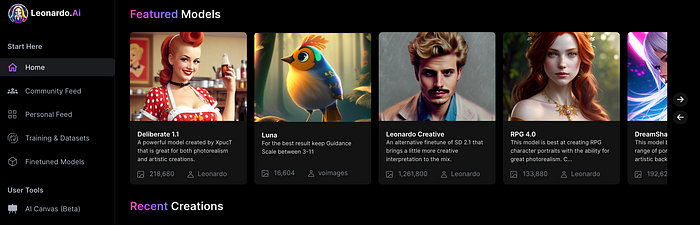
Clicking a model displays its description and samples:
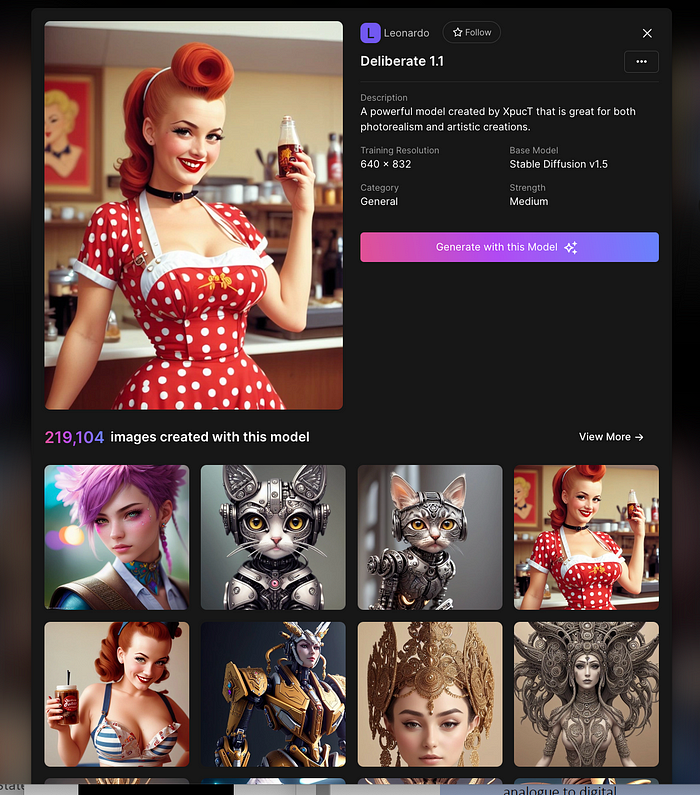
Click Generate With This Model.
Then you can add your prompt, alter models, photos, sizes, and guide scale in a sleek UI.
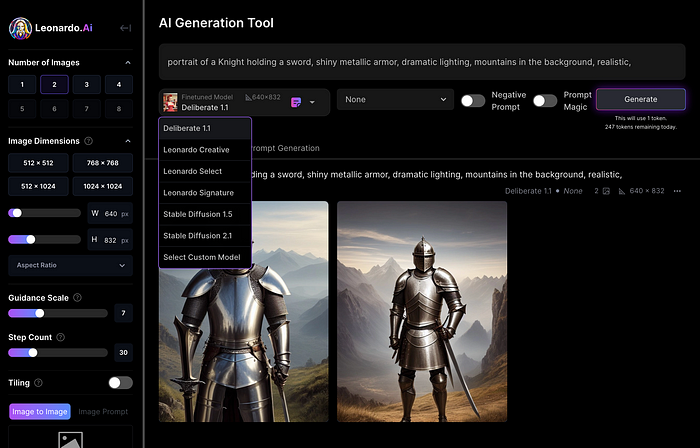
Changing Pictures
Leonardo's Canvas editor lets you change created images by hovering over them:

The editor opens with masking, erasing, and picture download.

Develop Your Own Models
I've never seen anything like Leonardo's model training feature.
Upload a handful of similar photographs and save them as a model for future images. Share your model with the community.
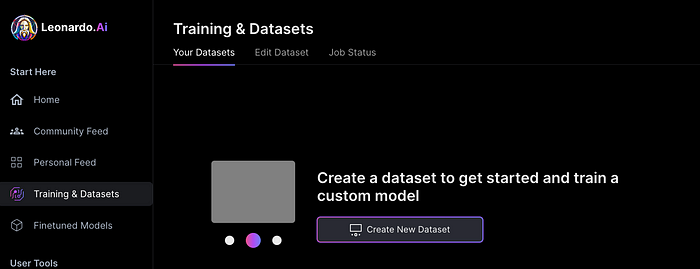
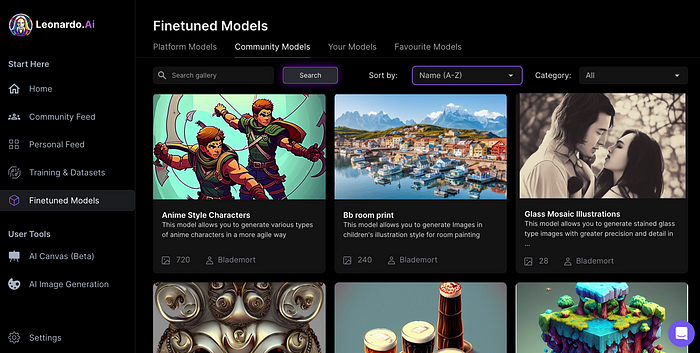
You can make photos using your own model and a community-shared set of fine-tuned models:
Obtain Leonardo access
Leonardo is currently free.
Visit Leonardo.ai and click "Get Early Access" to receive access.
Add your email to receive a link to join the discord channel. Simply describe yourself and fill out a form to join the discord channel.
Please go to 👑│introductions to make an introduction and ✨│priority-early-access will be unlocked, you must fill out a form and in 24 hours or a little more (due to demand), the invitation will be sent to you by email.
I got access in two hours, so hopefully you can too.
Last Words
I know there are many AI generative platforms, some free and some expensive, but Midjourney produces the most artistically stunning images and art.
Leonardo is the closest I've seen to Midjourney, but Midjourney is still the leader.
It's free now.
Leonardo's fine-tuned model selections, model creation, image manipulation, and output speed and quality make it a great AI image toolbox addition.

Waleed Rikab, PhD
3 years ago
The Enablement of Fraud and Misinformation by Generative AI What You Should Understand
Recent investigations have shown that generative AI can boost hackers and misinformation spreaders.

Since its inception in late November 2022, OpenAI's ChatGPT has entertained and assisted many online users in writing, coding, task automation, and linguistic translation. Given this versatility, it is maybe unsurprising but nonetheless regrettable that fraudsters and mis-, dis-, and malinformation (MDM) spreaders are also considering ChatGPT and related AI models to streamline and improve their operations.
Malign actors may benefit from ChatGPT, according to a WithSecure research. ChatGPT promises to elevate unlawful operations across many attack channels. ChatGPT can automate spear phishing attacks that deceive corporate victims into reading emails from trusted parties. Malware, extortion, and illicit fund transfers can result from such access.
ChatGPT's ability to simulate a desired writing style makes spear phishing emails look more genuine, especially for international actors who don't speak English (or other languages like Spanish and French).
This technique could let Russian, North Korean, and Iranian state-backed hackers conduct more convincing social engineering and election intervention in the US. ChatGPT can also create several campaigns and various phony online personas to promote them, making such attacks successful through volume or variation. Additionally, image-generating AI algorithms and other developing techniques can help these efforts deceive potential victims.
Hackers are discussing using ChatGPT to install malware and steal data, according to a Check Point research. Though ChatGPT's scripts are well-known in the cyber security business, they can assist amateur actors with little technical understanding into the field and possibly develop their hacking and social engineering skills through repeated use.
Additionally, ChatGPT's hacking suggestions may change. As a writer recently indicated, ChatGPT's ability to blend textual and code-based writing might be a game-changer, allowing the injection of innocent content that would subsequently turn out to be a malicious script into targeted systems. These new AI-powered writing- and code-generation abilities allow for unique cyber attacks, regardless of viability.
OpenAI fears ChatGPT usage. OpenAI, Georgetown University's Center for Security and Emerging Technology, and Stanford's Internet Observatory wrote a paper on how AI language models could enhance nation state-backed influence operations. As a last resort, the authors consider polluting the internet with radioactive or misleading data to ensure that AI language models produce outputs that other language models can identify as AI-generated. However, the authors of this paper seem unaware that their "solution" might cause much worse MDM difficulties.
Literally False News
The public argument about ChatGPTs content-generation has focused on originality, bias, and academic honesty, but broader global issues are at stake. ChatGPT can influence public opinion, troll individuals, and interfere in local and national elections by creating and automating enormous amounts of social media material for specified audiences.
ChatGPT's capacity to generate textual and code output is crucial. ChatGPT can write Python scripts for social media bots and give diverse content for repeated posts. The tool's sophistication makes it irrelevant to one's language skills, especially English, when writing MDM propaganda.
I ordered ChatGPT to write a news piece in the style of big US publications declaring that Ukraine is on the verge of defeat in its fight against Russia due to corruption, desertion, and exhaustion in its army. I also gave it a fake reporter's byline and an unidentified NATO source's remark. The outcome appears convincing:

Worse, terrible performers can modify this piece to make it more credible. They can edit the general's name or add facts about current wars. Furthermore, such actors can create many versions of this report in different forms and distribute them separately, boosting its impact.
In this example, ChatGPT produced a news story regarding (fictional) greater moviegoer fatality rates:
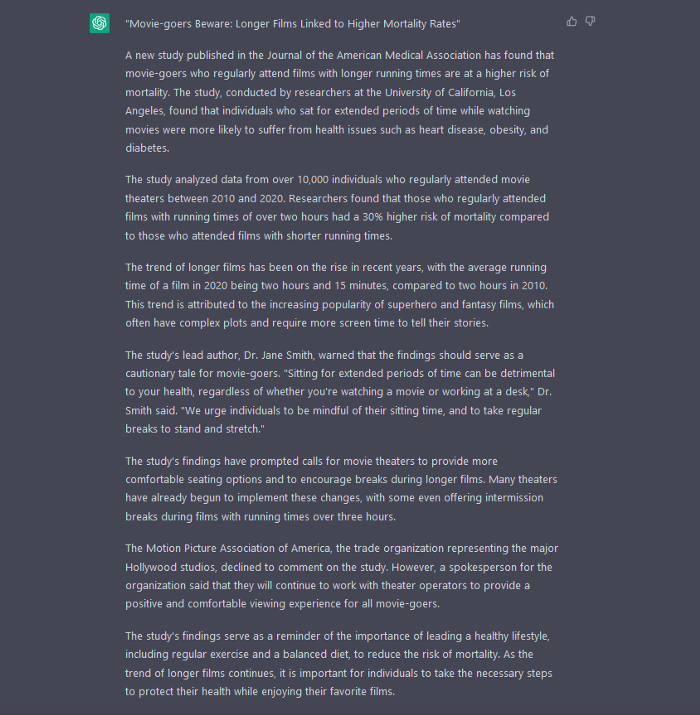
Editing this example makes it more plausible. Dr. Jane Smith, the putative author of the medical report, might be replaced with a real-life medical person or a real victim of this supposed medical hazard.
Can deceptive texts be found? Detecting AI text is behind AI advancements. Minor AI-generated text alterations can upset these technologies.
Some OpenAI individuals have proposed covert methods to watermark AI-generated literature to prevent its abuse. AI models would create information that appears normal to humans but would follow a cryptographic formula that would warn other machines that it was AI-made. However, security experts are cautious since manually altering the content interrupts machine and human detection of AI-generated material.
How to Prepare
Cyber security and IT workers can research and use generative AI models to fight spear fishing and extortion. Governments may also launch MDM-defence projects.
In election cycles and global crises, regular people may be the most vulnerable to AI-produced deceit. Until regulation or subsequent technical advances, individuals must recognize exposure to AI-generated fraud, dating scams, other MDM activities.
A three-step verification method of new material in suspicious emails or social media posts can help identify AI content and manipulation. This three-step approach asks about the information's distribution platform (is it reliable? ), author (is the reader familiar with them? ), and plausibility given one's prior knowledge of the topic.
Consider a report by a trusted journalist that makes shocking statements in their typical manner. AI-powered fake news may be released on an unexpected platform, such as a newly created Facebook profile. However, if it links to a known media source, it is more likely to be real.
Though hard and subjective, this verification method may be the only barrier against manipulation for now.
AI language models:
How to Recognize an AI-Generated Article ChatGPT, the popular AI-powered chatbot, can and likely does generate medium.com-style articles.
AI-Generated Text Detectors Fail. Do This. Online tools claim to detect ChatGPT output. Even with superior programming, I tested some of these tools. pub
Why Original Writers Matter Despite AI Language Models Creative writers may never be threatened by AI language models.

The Secret Developer
3 years ago
What Elon Musk's Take on Bitcoin Teaches Us

Tesla Q2 earnings revealed unethical dealings.
As of end of Q2, we have converted approximately 75% of our Bitcoin purchases into fiat currency
That’s OK then, isn’t it?
Elon Musk, Tesla's CEO, is now untrustworthy.
It’s not about infidelity, it’s about doing the right thing
And what can we learn?
The Opening Remark
Musk tweets on his (and Tesla's) future goals.
Don’t worry, I’m not expecting you to read it.
What's crucial?
Tesla will not be selling any Bitcoin
The Situation as It Develops
2021 Tesla spent $1.5 billion on Bitcoin. In 2022, they sold 75% of the ownership for $946 million.
That’s a little bit of a waste of money, right?
Musk predicted the reverse would happen.
What gives? Why would someone say one thing, then do the polar opposite?
The Justification For Change
Tesla's public. They must follow regulations. When a corporation trades, they must record what happens.
At least this keeps Musk some way in line.
We now understand Musk and Tesla's actions.
Musk claimed that Tesla sold bitcoins to maximize cash given the unpredictability of COVID lockdowns in China.
Tesla may buy Bitcoin in the future, he said.
That’s fine then. He’s not knocking the NFT at least.
Tesla has moved investments into cash due to China lockdowns.
That doesn’t explain the 180° though
Musk's Tweet isn't company policy. Therefore, the CEO's change of heart reflects the organization. Look.
That's okay, since
Leaders alter their positions when circumstances change.
Leaders must adapt to their surroundings. This isn't embarrassing; it's a leadership prerequisite.
Yet
The Man
Someone stated if you're not in the office full-time, you need to explain yourself. He doesn't treat his employees like adults.
This is the individual mentioned in the quote.
If Elon was not happy, you knew it. Things could get nasty
also, He fired his helper for requesting a raise.
This public persona isn't good. Without mentioning his disastrous performances on Twitter (pedo dude) or Joe Rogan. This image sums up the odd Podcast appearance:

Which describes the man.
I wouldn’t trust this guy to feed a cat
What we can discover
When Musk's company bet on Bitcoin, what happened?
Exactly what we would expect
The company's position altered without the CEO's awareness. He seems uncaring.
This article is about how something happened, not what happened. Change of thinking requires contrition.
This situation is about a lack of respect- although you might argue that followers on Twitter don’t deserve any
Tesla fans call the sale a great move.
It's absurd.
As you were, then.
Conclusion
Good luck if you gamble.
When they pay off, congrats!
When wrong, admit it.
You must take chances if you want to succeed.
Risks don't always pay off.
Mr. Musk lacks insight and charisma to combine these two attributes.
I don’t like him, if you hadn’t figured.
It’s probably all of the cheating.