






More on Personal Growth

Jari Roomer
3 years ago
Successful people have this one skill.
Without self-control, you'll waste time chasing dopamine fixes.
I found a powerful quote in Tony Robbins' Awaken The Giant Within:
“Most of the challenges that we have in our personal lives come from a short-term focus” — Tony Robbins
Most people are short-term oriented, but highly successful people are long-term oriented.
Successful people act in line with their long-term goals and values, while the rest are distracted by short-term pleasures and dopamine fixes.
Instant gratification wrecks lives
Instant pleasure is fleeting. Quickly fading effects leave you craving more stimulation.
Before you know it, you're in a cycle of quick fixes. This explains binging on food, social media, and Netflix.
These things cause a dopamine spike, which is entertaining. This dopamine spike crashes quickly, leaving you craving more stimulation.
It's fine to watch TV or play video games occasionally. Problems arise when brain impulses aren't controlled. You waste hours chasing dopamine fixes.
Instant gratification becomes problematic when it interferes with long-term goals, happiness, and life fulfillment.
Most rewarding things require delay
Life's greatest rewards require patience and delayed gratification. They must be earned through patience, consistency, and effort.
Ex:
A fit, healthy body
A deep connection with your spouse
A thriving career/business
A healthy financial situation
These are some of life's most rewarding things, but they take work and patience. They all require the ability to delay gratification.
To have a healthy bank account, you must save (and invest) a large portion of your monthly income. This means no new tech or clothes.
If you want a fit, healthy body, you must eat better and exercise three times a week. So no fast food and Netflix.
It's a battle between what you want now and what you want most.
Successful people choose what they want most over what they want now. It's a major difference.
Instant vs. delayed gratification
Most people subconsciously prefer instant rewards over future rewards, even if the future rewards are more significant.
We humans aren't logical. Emotions and instincts drive us. So we act against our goals and values.
Fortunately, instant gratification bias can be overridden. This is a modern superpower. Effective methods include:
#1: Train your brain to handle overstimulation
Training your brain to function without constant stimulation is a powerful change. Boredom can lead to long-term rewards.
Unlike impulsive shopping, saving money is boring. Having lots of cash is amazing.
Compared to video games, deep work is boring. A successful online business is rewarding.
Reading books is boring compared to scrolling through funny videos on social media. Knowledge is invaluable.
You can't do these things if your brain is overstimulated. Your impulses will control you. To reduce overstimulation addiction, try:
Daily meditation (10 minutes is enough)
Daily study/work for 90 minutes (no distractions allowed)
First hour of the day without phone, social media, and Netflix
Nature walks, journaling, reading, sports, etc.
#2: Make Important Activities Less Intimidating
Instant gratification helps us cope with stress. Starting a book or business can be intimidating. Video games and social media offer a quick escape in such situations.
Make intimidating tasks less so. Break them down into small tasks. Start a new business/side-hustle by:
Get domain name
Design website
Write out a business plan
Research competition/peers
Approach first potential client
Instead of one big mountain, divide it into smaller sub-tasks. This makes a task easier and less intimidating.
#3: Plan ahead for important activities
Distractions will invade unplanned time. Your time is dictated by your impulses, which are usually Netflix, social media, fast food, and video games. It wants quick rewards and dopamine fixes.
Plan your days and be proactive with your time. Studies show that scheduling activities makes you 3x more likely to do them.
To achieve big goals, you must plan. Don't gamble.
Want to get fit? Schedule next week's workouts. Want a side-job? Schedule your work time.

Akshad Singi
3 years ago
Four obnoxious one-minute habits that help me save more than 30 hours each week
These four, when combined, destroy procrastination.

You're not rushed. You waste it on busywork.
You'll accept this eventually.
In 2022, the daily average usage of a user on social media is 2.5 hours.
By 2020, 6 billion hours of video were watched each month by Netflix's customers, who used the service an average of 3.2 hours per day.
When we see these numbers, we think "Wow!" People squander so much time as though they don't contribute. True. These are yours. Likewise.
We don't lack time; we just waste it. Once you realize this, you can change your habits to save time. This article explains. If you adopt ALL 4 of these simple behaviors, you'll see amazing benefits.
Time-blocking
Cal Newport's time-blocking trick takes a minute but improves your day's clarity.
Divide the next day into 30-minute (or 5-minute, if you're Elon Musk) segments and assign responsibilities. As seen.
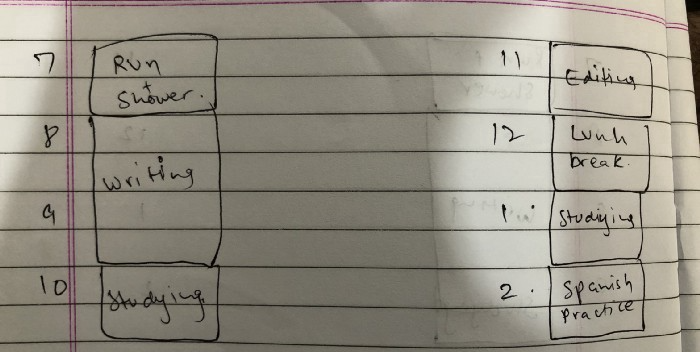
Here's why:
The procrastination that results from attempting to determine when to begin working is eliminated. Procrastination is a given if you choose when to begin working in real-time. Even if you may assume you'll start working in five minutes, it won't take you long to realize that five minutes have turned into an hour. But if you've already determined to start working at 2:00 the next day, your odds of procrastinating are greatly decreased, if not eliminated altogether.
You'll also see that you have a lot of time in a day when you plan your day out on paper and assign chores to each hour. Doing this daily will permanently eliminate the lack of time mindset.
5-4-3-2-1: Have breakfast with the frog!
“If it’s your job to eat a frog, it’s best to do it first thing in the morning. And If it’s your job to eat two frogs, it’s best to eat the biggest one first.”
Eating the frog means accomplishing the day's most difficult chore. It's better to schedule it first thing in the morning when time-blocking the night before. Why?
The day's most difficult task is also the one that causes the most postponement. Because of the stress it causes, the later you schedule it, the more time you risk wasting by procrastinating.
However, if you do it right away in the morning, you'll feel good all day. This is the reason it was set for the morning.
Mel Robbins' 5-second rule can help. Start counting backward 54321 and force yourself to start at 1. If you acquire the urge to work on a goal, you must act within 5 seconds or your brain will destroy it. If you're scheduled to eat your frog at 9, eat it at 8:59. Start working.
Micro-visualisation
You've heard of visualizing to enhance the future. Visualizing a bright future won't do much if you're not prepared to focus on the now and develop the necessary habits. Alexander said:
People don’t decide their futures. They decide their habits and their habits decide their future.
I visualize the next day's schedule every morning. My day looks like this
“I’ll start writing an article at 7:30 AM. Then, I’ll get dressed up and reach the medicine outpatient department by 9:30 AM. After my duty is over, I’ll have lunch at 2 PM, followed by a nap at 3 PM. Then, I’ll go to the gym at 4…”
etc.
This reinforces the day you planned the night before. This makes following your plan easy.
Set the timer.
It's the best iPhone productivity app. A timer is incredible for increasing productivity.
Set a timer for an hour or 40 minutes before starting work. Your call. I don't believe in techniques like the Pomodoro because I can focus for varied amounts of time depending on the time of day, how fatigued I am, and how cognitively demanding the activity is.
I work with a timer. A timer keeps you focused and prevents distractions. Your mind stays concentrated because of the timer. Timers generate accountability.
To pee, I'll pause my timer. When I sit down, I'll continue. Same goes for bottle refills. To use Twitter, I must pause the timer. This creates accountability and focuses work.
Connecting everything
If you do all 4, you won't be disappointed. Here's how:
Plan out your day's schedule the night before.
Next, envision in your mind's eye the same timetable in the morning.
Speak aloud 54321 when it's time to work: Eat the frog! In the morning, devour the largest frog.
Then set a timer to ensure that you remain focused on the task at hand.

The woman
3 years ago
The best lesson from Sundar Pichai is that success and stress don't mix.
His regular regimen teaches stress management.

In 1995, an Indian graduate visited the US. He obtained a scholarship to Stanford after graduating from IIT with a silver medal. First flight. His ticket cost a year's income. His head was full.
Pichai Sundararajan is his full name. He became Google's CEO and a world leader. Mr. Pichai transformed technology and inspired millions to dream big.
This article reveals his daily schedule.
Mornings
While many of us dread Mondays, Mr. Pichai uses the day to contemplate.
A typical Indian morning. He awakens between 6:30 and 7 a.m. He avoids working out in the mornings.
Mr. Pichai oversees the internet, but he reads a real newspaper every morning.
Pichai mentioned that he usually enjoys a quiet breakfast during which he reads the news to get a good sense of what’s happening in the world. Pichai often has an omelet for breakfast and reads while doing so. The native of Chennai, India, continues to enjoy his daily cup of tea, which he describes as being “very English.”
Pichai starts his day. BuzzFeed's Mat Honan called the CEO Banana Republic dad.
Overthinking in the morning is a bad idea. It's crucial to clear our brains and give ourselves time in the morning before we hit traffic.
Mr. Pichai's morning ritual shows how to stay calm. Wharton Business School found that those who start the day calmly tend to stay that way. It's worth doing regularly.
And he didn't forget his roots.
Afternoons
He has a busy work schedule, as you can imagine. Running one of the world's largest firm takes time, energy, and effort. He prioritizes his work. Monitoring corporate performance and guaranteeing worker efficiency.
Sundar Pichai spends 7-8 hours a day to improve Google. He's noted for changing the company's culture. He wants to boost employee job satisfaction and performance.
His work won him recognition within the company.
Pichai received a 96% approval rating from Glassdoor users in 2017.
Mr. Pichai stresses work satisfaction. Each day is a new canvas for him to find ways to enrich people's job and personal lives.
His work offers countless lessons. According to several profiles and press sources, the Google CEO is a savvy negotiator. Mr. Pichai's success came from his strong personality, work ethic, discipline, simplicity, and hard labor.
Evenings
His evenings are spent with family after a busy day. Sundar Pichai's professional and personal lives are balanced. Sundar Pichai is a night owl who re-energizes about 9 p.m.
However, he claims to be most productive after 10 p.m., and he thinks doing a lot of work at that time is really useful. But he ensures he sleeps for around 7–8 hours every day. He enjoys long walks with his dog and enjoys watching NSDR on YouTube. It helps him in relaxing and sleep better.
His regular routine teaches us what? Work wisely, not hard, discipline, vision, etc. His stress management is key. Leading one of the world's largest firm with 85,000 employees is scary.
The pressure to achieve may ruin a day. Overworked employees are more likely to make mistakes or be angry with coworkers, according to the Family Work Institute. They can't handle daily problems, making the house more stressful than the office.
Walking your dog, having fun with friends, and having hobbies are as vital as your office.
You might also like

Will Lockett
2 years ago
There Is A New EV King in Town

McMurtry Spéirling outperforms Tesla in speed and efficiency.
EVs were ridiculously slow for decades. However, the 2008 Tesla Roadster revealed that EVs might go extraordinarily fast. The Tesla Model S Plaid and Rimac Nevera are the fastest-accelerating road vehicles, despite combustion-engined road cars dominating the course. A little-known firm beat Tesla and Rimac in the 0-60 race, beat F1 vehicles on a circuit, and boasts a 350-mile driving range. The McMurtry Spéirling is completely insane.
Mat Watson of CarWow, a YouTube megastar, was recently handed a Spéirling and access to Silverstone Circuit (view video above). Mat ran a quarter-mile on Silverstone straight with former F1 driver Max Chilton. The little pocket-rocket automobile touched 100 mph in 2.7 seconds, completed the quarter mile in 7.97 seconds, and hit 0-60 in 1.4 seconds. When looking at autos quickly, 0-60 times can seem near. The Tesla Model S Plaid does 0-60 in 1.99 seconds, which is comparable to the Spéirling. Despite the meager statistics, the Spéirling is nearly 30% faster than Plaid!
My vintage VW Golf 1.4s has an 8.8-second 0-60 time, whereas a BMW Z4 3.0i is 30% faster (with a 0-60 time of 6 seconds). I tried to beat a Z4 off the lights in my Golf, but the Beamer flew away. If they challenge the Spéirling in a Model S Plaid, they'll feel as I did. Fast!
Insane quarter-mile drag time. Its road car record is 7.97 seconds. A Dodge Demon, meant to run extremely fast quarter miles, finishes so in 9.65 seconds, approximately 20% slower. The Rimac Nevera's 8.582-second quarter-mile record was miles behind drag racing. This run hampered the Spéirling. Because it was employing gearing that limited its top speed to 150 mph, it reached there in a little over 5 seconds without accelerating for most of the quarter mile! McMurtry can easily change the gearing, making the Spéirling run quicker.
McMurtry did this how? First, the Spéirling is a tiny single-seater EV with a 60 kWh battery pack, making it one of the lightest EVs ever. The 1,000-hp Spéirling has more than one horsepower per kg. The Nevera has 0.84 horsepower per kg and the Plaid 0.44.
However, you cannot simply construct a car light and power it. Instead of accelerating, it would spin. This makes the Spéirling a fan car. Its huge fans create massive downforce. These fans provide the Spéirling 2 tonnes of downforce while stationary, so you could park it on the ceiling. Its fast 0-60 time comes from its downforce, which lets it deliver all that power without wheel spin.
It also possesses complete downforce at all speeds, allowing it to tackle turns faster than even race vehicles. Spéirlings overcame VW IDRs and F1 cars to set the Goodwood Hill Climb record (read more here). The Spéirling is a dragstrip winner and track dominator, unlike the Plaid and Nevera.
The Spéirling is astonishing for a single-seater. Fan-generated downforce is more efficient than wings and splitters. It also means the vehicle has very minimal drag without the fan. The Spéirling can go 350 miles per charge (WLTP) or 20-30 minutes at full speed on a track despite its 60 kWh battery pack. The G-forces would hurt your neck before the battery died if you drove around a track for longer. The Spéirling can charge at over 200 kW in about 30 minutes. Thus, driving to track days, having fun, and returning is possible. Unlike other high-performance EVs.
Tesla, Rimac, or Lucid will struggle to defeat the Spéirling. They would need to build a fan automobile because adding power to their current vehicle would make it uncontrollable. The EV and automobile industries now have a new, untouchable performance king.
Monroe Mayfield
2 years ago
CES 2023: A Third Look At Upcoming Trends
Las Vegas hosted CES 2023. This third and last look at CES 2023 previews upcoming consumer electronics trends that will be crucial for market share.

Definitely start with ICT. Qualcomm CEO Cristiano Amon spoke to CNBC from Las Vegas on China's crackdown and the company's automated driving systems for electric vehicles (EV). The business showed a concept car and its latest Snapdragon processor designs, which offer expanded digital interactions through SalesForce-partnered CRM platforms.
Electrification is reviving Michigan's automobile industry. Michigan Local News reports that $14 billion in EV and battery manufacturing investments will benefit the state. The report also revealed that the Strategic Outreach and Attraction Reserve (SOAR) fund had generated roughly $1 billion for the state's automotive sector.
Ars Technica is great for technology, society, and the future. After CES 2023, Jonathan M. Gitlin published How many electric car chargers are enough? Read about EV charging network issues and infrastructure spending. Politics aside, rapid technological advances enable EV charging network expansion in American cities and abroad.
Finally, the UNEP's The Future of Electric Vehicles and Material Resources: A Foresight Brief. Understanding how lithium-ion batteries will affect EV sales is crucial. Climate change affects EVs in various ways, but electrification and mining trends stand out because more EVs demand more energy-intensive metals and rare earths. Areas & Producers has been publishing my electrification and mining trends articles. Follow me if you wish to write for the publication.
The Weekend Brief (TWB) will routinely cover tech, industrials, and global commodities in global markets, including stock markets. Read more about the future of key areas and critical producers of the global economy in Areas & Producers.

Andy Walker
3 years ago
Why personal ambition and poor leadership caused Google layoffs

Google announced 6% layoffs recently (or 12,000 people). This aligns it with most tech companies. A publicly contrite CEO explained that they had overhired during the COVID-19 pandemic boom and had to address it, but they were sorry and took full responsibility. I thought this was "bullshit" too. Meta, Amazon, Microsoft, and others must feel similarly. I spent 10 years at Google, and these things don't reflect well on the company's leaders.
All publicly listed companies have a fiduciary duty to act in the best interests of their shareholders. Dodge vs. Ford Motor Company established this (1919). Henry Ford wanted to reduce shareholder payments to offer cheaper cars and better wages. Ford stated.
My ambition is to employ still more men, to spread the benefits of this industrial system to the greatest possible number, to help them build up their lives and their homes. To do this we are putting the greatest share of our profits back in the business.
The Dodge brothers, who owned 10% of Ford, opposed this and sued Ford for the payments to start their own company. They won, preventing Ford from raising prices or salaries. If you have a vocal group of shareholders with the resources to sue you, you must prove you are acting in their best interests. Companies prioritize shareholders. Giving activist investors a stick to threaten you almost enshrines short-term profit over long-term thinking.
This underpins Google's current issues. Institutional investors who can sue Google see it as a wasteful company they can exploit. That doesn't mean you have to maximize profits (thanks to those who pointed out my ignorance of US corporate law in the comments and on HN), but it allows pressure. I feel for those navigating this. This is about unrestrained capitalism.
When Google went public, Larry Page and Sergey Brin knew the risks and worked hard to keep control. In their Founders' Letter to investors, they tried to set expectations for the company's operations.
Our long-term focus as a private company has paid off. Public companies do the same. We believe outside pressures lead companies to sacrifice long-term opportunities to meet quarterly market expectations.
The company has transformed since that letter. The company has nearly 200,000 full-time employees and a trillion-dollar market cap. Large investors have bought company stock because it has been a good long-term bet. Why are they restless now?
Other big tech companies emerged and fought for top talent. This has caused rising compensation packages. Google has also grown rapidly (roughly 22,000 people hired to the end of 2022). At $300,000 median compensation, those 22,000 people added $6.6 billion in salary overheads in 2022. Exorbitant. If the company still makes $16 billion every quarter, maybe not. Investors wonder if this value has returned.
Investors are right. Google uses people wastefully. However, by bluntly reducing headcount, they're not addressing the root causes and hurting themselves. No studies show that downsizing this way boosts productivity. There is plenty of evidence that they'll lose out because people will be risk-averse and distrust their leadership.
The company's approach also stinks. Finding out that you no longer have a job because you can’t log in anymore (sometimes in cases where someone is on call for protecting your production systems) is no way to fire anyone. Being with a narcissistic sociopath is like being abused. First, you receive praise and fancy perks for making the cut. You're fired by text and ghosted. You're told to appreciate the generous severance package. This firing will devastate managers and teams. This type of firing will take years to recover self-esteem. Senior management contributed to this. They chose the expedient answer, possibly by convincing themselves they were managing risk and taking the Macbeth approach of “If it were done when ’tis done, then ’twere well It were done quickly”.
Recap. Google's leadership did a stupid thing—mass firing—in a stupid way. How do we get rid of enough people to make investors happier? and "have 6% less people." Empathetic leaders should not emulate Elon Musk. There is no humane way to fire 12,000 people, but there are better ways. Why is Google so wasteful?
Ambition answers this. There aren't enough VP positions for a group of highly motivated, ambitious, and (increasingly) ruthless people. I’ve loitered around the edges of this world and a large part of my value was to insulate my teams from ever having to experience it. It’s like Game of Thrones played out through email and calendar and over video call.
Your company must look a certain way to be promoted to director or higher. You need the right people at the right levels under you. Long-term, growing your people will naturally happen if you're working on important things. This takes time, and you're never more than 6–18 months from a reorg that could start you over. Ambitious people also tend to be impatient. So, what do you do?
Hiring and vanity projects. To shape your company, you hire at the right levels. You value vanity metrics like active users over product utility. Your promo candidates get through by subverting the promotion process. In your quest for growth, you avoid performance managing people out. You avoid confronting toxic peers because you need their support for promotion. Your cargo cult gets you there.
Its ease makes Google wasteful. Since they don't face market forces, the employees don't see it as a business. Why would you do when the ads business is so profitable? Complacency causes senior leaders to prioritize their own interests. Empires collapse. Personal ambition often trumped doing the right thing for users, the business, or employees. Leadership's ambition over business is the root cause. Vanity metrics, mass hiring, and vague promises have promoted people to VP. Google goes above and beyond to protect senior leaders.
The decision-makers and beneficiaries are not the layoffees. Stock price increase beneficiaries. The people who will post on LinkedIn how it is about misjudging the market and how they’re so sorry and take full responsibility. While accumulating wealth, the dark room dwellers decide who stays and who goes. The billionaire investors. Google should start by addressing its bloated senior management, but — as they say — turkeys don't vote for Christmas. It should examine its wastefulness and make tough choices to fix it. A 6% cut is a blunt tool that admits you're not running your business properly. why aren’t the people running the business the ones shortly to be entering the job market?
This won't fix Google's wastefulness. The executives may never regain trust after their approach. Suppressed creativity. Business won't improve. Google will have lost its founding vision and us all. Large investors know they can force Google's CEO to yield. The rich will get richer and rationalize leaving 12,000 people behind. Cycles repeat.
It doesn’t have to be this way. In 2013, Nintendo's CEO said he wouldn't fire anyone for shareholders. Switch debuted in 2017. Nintendo's stock has increased by nearly five times, or 19% a year (including the drop most of the stock market experienced last year). Google wasted 12,000 talented people. To please rich people.