


Elon Musk’s Rich Life Is a Nightmare
I'm sure you haven't read about Elon's other side.
Elon divorced badly.
Nobody's surprised.
Imagine you're a parent. Someone isn't home year-round. What's next?
That’s what happened to YOLO Elon.
He can do anything. He can intervene in wars, shoot his mouth off, bang anyone he wants, avoid tax, make cool tech, buy anything his ego desires, and live anywhere exotic.
Few know his billionaire backstory. I'll tell you so you don't worship his lifestyle. It’s a cult.
Only his career succeeds. His life is a nightmare otherwise.
Psychopaths' schedule
Elon has said he works 120-hour weeks.
As he told the reporter about his job, he choked up, which was unusual for him.
His crazy workload and lack of sleep forced him to scold innocent Wall Street analysts. Later, he apologized.
In the same interview, he admits he hadn't taken more than a week off since 2001, when he was bedridden with malaria. Elon stays home after a near-death experience.
He's rarely outside.
Elon says he sometimes works 3 or 4 days straight.
He admits his crazy work schedule has cost him time with his kids and friends.
Elon's a slave
Elon's birthday description made him emotional.
Elon worked his entire birthday.
"No friends, nothing," he said, stuttering.
His brother's wedding in Catalonia was 48 hours after his birthday. That meant flying there from Tesla's factory prison.
He arrived two hours before the big moment, barely enough time to eat and change, let alone see his brother.
Elon had to leave after the bouquet was tossed to a crowd of billionaire lovers. He missed his brother's first dance with his wife.
Shocking.
He went straight to Tesla's prison.
The looming health crisis
Elon was asked if overworking affected his health.
Not great. Friends are worried.
Now you know why Elon tweets dumb things. Working so hard has probably caused him mental health issues.
Mental illness removed my reality filter. You do stupid things because you're tired.
Astronauts pelted Elon
Elon's overwork isn't the first time his life has made him emotional.
When asked about Neil Armstrong and Gene Cernan criticizing his SpaceX missions, he got emotional. Elon's heroes.
They're why he started the company, and they mocked his work. In another interview, we see how Elon’s business obsession has knifed him in the heart.
Once you have a company, you must feed, nurse, and care for it, even if it destroys you.
"Yep," Elon says, tearing up.
In the same interview, he's asked how Tesla survived the 2008 recession. Elon stopped the interview because he was crying. When Tesla and SpaceX filed for bankruptcy in 2008, he nearly had a nervous breakdown. He called them his "children."
All the time, he's risking everything.
Jack Raines explains best:
Too much money makes you a slave to your net worth.
Elon's emotions are admirable. It's one of the few times he seems human, not like an alien Cyborg.
Stop idealizing Elon's lifestyle
Building a side business that becomes a billion-dollar unicorn startup is a nightmare.
"Billionaire" means financially wealthy but otherwise broke. A rich life includes more than business and money.
This post is a summary. Read full article here
More on Entrepreneurship/Creators

Jenn Leach
3 years ago
I created a faceless TikTok account. Six months later.
Follower count, earnings, and more

I created my 7th TikTok account six months ago. TikTok's great. I've developed accounts for Amazon products, content creators/brand deals education, website flipping, and more.
Introverted or shy people use faceless TikTok accounts.
Maybe they don't want millions of people to see their face online, or they want to remain anonymous so relatives and friends can't locate them.
Going faceless on TikTok can help you grow a following, communicate your message, and make money online.
Here are 6 steps I took to turn my Tik Tok account into a $60,000/year side gig.
From nothing to $60K in 6 months
It's clickbait, but it’s true. Here’s what I did to get here.
Quick context:
I've used social media before. I've spent years as a social creator and brand.
I've built Instagram, TikTok, and YouTube accounts to nearly 100K.
How I did it
First, select a niche.
If you can focus on one genre on TikTok, you'll have a better chance of success, however lifestyle creators do well too.
Niching down is easier, in my opinion.
Examples:
Travel
Food
Kids
Earning cash
Finance
You can narrow these niches if you like.
During the pandemic, a travel blogger focused on Texas-only tourism and gained 1 million subscribers.
Couponing might be a finance specialization.
One of my finance TikTok accounts gives credit tips and grants and has 23K followers.
Tons of ways you can get more specific.
Consider how you'll monetize your TikTok account. I saw many enormous TikTok accounts that lose money.
Why?
They can't monetize their niche. Not impossible to commercialize, but tough enough to inhibit action.
First, determine your goal.
In this first step, consider what your end goal is.
Are you trying to promote your digital products or social media management services?
You want brand deals or e-commerce sales.
This will affect your TikTok specialty.
This is the first step to a TikTok side gig.
Step 2: Pick a content style
Next, you want to decide on your content style.
Do you do voiceover and screenshots?
You'll demonstrate a product?
Will you faceless vlog?
Step 3: Look at the competition
Find anonymous accounts and analyze what content works, where they thrive, what their audience wants, etc.
This can help you make better content.
Like the skyscraper method for TikTok.
Step 4: Create a content strategy.
Your content plan is where you sit down and decide:
How many videos will you produce each day or each week?
Which links will you highlight in your biography?
What amount of time can you commit to this project?
You may schedule when to post videos on a calendar. Make videos.
5. Create videos.
No video gear needed.
Using a phone is OK, and I think it's preferable than posting drafts from a computer or phone.
TikTok prefers genuine material.
Use their app, tools, filters, and music to make videos.
And imperfection is preferable. Tik okers like to see videos made in a bedroom, not a film studio.
Make sense?
When making videos, remember this.
I personally use my phone and tablet.
Step 6: Monetize
Lastly, it’s time to monetize How will you make money? You decided this in step 1.
Time to act!
For brand agreements
Include your email in the bio.
Share several sites and use a beacons link in your bio.
Make cold calls to your favorite companies to get them to join you in a TikTok campaign.
For e-commerce
Include a link to your store's or a product's page in your bio.
For client work
Include your email in the bio.
Use a beacons link to showcase your personal website, portfolio, and other resources.
For affiliate marketing
Include affiliate product links in your bio.
Join the Amazon Influencer program and provide a link to your storefront in your bio.
$60,000 per year from Tik Tok?
Yes, and some creators make much more.
Tori Dunlap (herfirst100K) makes $100,000/month on TikTok.
My TikTok adventure took 6 months, but by month 2 I was making $1,000/month (or $12K/year).
By year's end, I want this account to earn $100K/year.
Imagine if my 7 TikTok accounts made $100K/year.
7 Tik Tok accounts X $100K/yr = $700,000/year

DC Palter
3 years ago
Is Venture Capital a Good Fit for Your Startup?
5 VC investment criteria

I reviewed 200 startup business concepts last week. Brainache.
The enterprises sold various goods and services. The concepts were achingly similar: give us money, we'll produce a product, then get more to expand. No different from daily plans and pitches.
Most of those 200 plans sounded plausible. But 10% looked venture-worthy. 90% of startups need alternatives to venture finance.
With the success of VC-backed businesses and the growth of venture funds, a common misperception is that investors would fund any decent company idea. Finding investors that believe in the firm and founders is the key to funding.
Incorrect. Venture capital needs investing in certain enterprises. If your startup doesn't match the model, as most early-stage startups don't, you can revise your business plan or locate another source of capital.
Before spending six months pitching angels and VCs, make sure your startup fits these criteria.
Likely to generate $100 million in sales
First, I check the income predictions in a pitch deck. If it doesn't display $100M, don't bother.
The math doesn't work for venture financing in smaller businesses.
Say a fund invests $1 million in a startup valued at $5 million that is later acquired for $20 million. That's a win everyone should celebrate. Most VCs don't care.
Consider a $100M fund. The fund must reach $360M in 7 years with a 20% return. Only 20-30 investments are possible. 90% of the investments will fail, hence the 23 winners must return $100M-$200M apiece. $15M isn't worth the work.
Angel investors and tiny funds use the same ideas as venture funds, but their smaller scale affects the calculations. If a company can support its growth through exit on less than $2M in angel financing, it must have $25M in revenues before large companies will consider acquiring it.
Aiming for Hypergrowth
A startup's size isn't enough. It must expand fast.
Developing a great business takes time. Complex technology must be constructed and tested, a nationwide expansion must be built, or production procedures must go from lab to pilot to factories. These can be enormous, world-changing corporations, but venture investment is difficult.
The normal 10-year venture fund life. Investments are made during first 3–4 years.. 610 years pass between investment and fund dissolution. Funds need their investments to exit within 5 years, 7 at the most, therefore add a safety margin.
Longer exit times reduce ROI. A 2-fold return in a year is excellent. Loss at 2x in 7 years.
Lastly, VCs must prove success to raise their next capital. The 2nd fund is raised from 1st fund portfolio increases. Third fund is raised using 1st fund's cash return. Fund managers must raise new money quickly to keep their jobs.
Branding or technology that is protected
No big firm will buy a startup at a high price if they can produce a competing product for less. Their development teams, consumer base, and sales and marketing channels are large. Who needs you?
Patents, specialist knowledge, or brand name are the only answers. The acquirer buys this, not the thing.
I've heard of several promising startups. It's not a decent investment if there's no exit strategy.
A company that installs EV charging stations in apartments and shopping areas is an example. It's profitable, repeatable, and big. A terrific company. Not a startup.
This building company's operations aren't secret. No technology to protect, no special information competitors can't figure out, no go-to brand name. Despite the immense possibilities, a large construction company would be better off starting their own.
Most venture businesses build products, not services. Services can be profitable but hard to safeguard.
Probable purchase at high multiple
Once a software business proves its value, acquiring it is easy. Pharma and medtech firms have given up on their own research and instead acquire startups after regulatory permission. Many startups, especially in specialized areas, have this weakness.
That doesn't mean any lucrative $25M-plus business won't be acquired. In many businesses, the venture model requires a high exit premium.
A startup invents a new glue. 3M, BASF, Henkel, and others may buy them. Adding more adhesive to their catalogs won't boost commerce. They won't compete to buy the business. They'll only buy a startup at a profitable price. The acquisition price represents a moderate EBITDA multiple.
The company's $100M revenue presumably yields $10m in profits (assuming they’ve reached profitability at all). A $30M-$50M transaction is likely. Not terrible, but not what venture investors want after investing $25M to create a plant and develop the business.
Private equity buys profitable companies for a moderate profit multiple. It's a good exit for entrepreneurs, but not for investors seeking 10x or more what PE firms pay. If a startup offers private equity as an exit, the conversation is over.
Constructed for purchase
The startup wants a high-multiple exit. Unless the company targets $1B in revenue and does an IPO, exit means acquisition.
If they're constructing the business for acquisition or themselves, founders must decide.
If you want an indefinitely-running business, I applaud you. We need more long-term founders. Most successful organizations are founded around consumer demands, not venture capital's urge to grow fast and exit. Not venture funding.
if you don't match the venture model, what to do
VC funds moonshots. The 10% that succeed are extraordinary. Not every firm is a rocketship, and launching the wrong startup into space, even with money, will explode.
But just because your startup won't make $100M in 5 years doesn't mean it's a bad business. Most successful companies don't follow this model. It's not venture capital-friendly.
Although venture capital gets the most attention due to a few spectacular triumphs (and disasters), it's not the only or even most typical option to fund a firm.
Other ways to support your startup:
Personal and family resources, such as credit cards, second mortgages, and lines of credit
bootstrapping off of sales
government funding and honors
Private equity & project financing
collaborating with a big business
Including a business partner
Before pitching angels and VCs, be sure your startup qualifies. If so, include them in your pitch.

Sarah Bird
3 years ago
Memes Help This YouTube Channel Earn Over $12k Per Month
Take a look at a YouTube channel making anything up to over $12k a month from making very simple videos.
And the best part? Its replicable by anyone. Basic videos can be generated for free without design abilities.
Join me as I deconstruct the channel to estimate how much they make, how they do it, and how you can too.
What Do They Do Exactly?
Happy Land posts memes with a simple caption they wrote. So, it's new. The videos are a slideshow of meme photos with stock music.
The site posts 12 times a day.
8-10-minute videos show 10 second images. Thus, each video needs 48-60 memes.
Memes are video titles (e.g. times a boyfriend was hilarious, back to school fails, funny restaurant signs).
Some stats about the channel:
Founded on October 30, 2020
873 videos were added.
81.8k subscribers
67,244,196 views of the video
What Value Are They Adding?
Everyone can find free memes online. This channel collects similar memes into a single video so you don't have to scroll or click for more. It’s right there, you just keep watching and more will come.
By theming it, the audience is prepared for the video's content.
If you want hilarious animal memes or restaurant signs, choose the video and you'll get up to 60 memes without having to look for them. Genius!
How much money do they make?
According to www.socialblade.com, the channel earns $800-12.8k (image shown in my home currency of GBP).
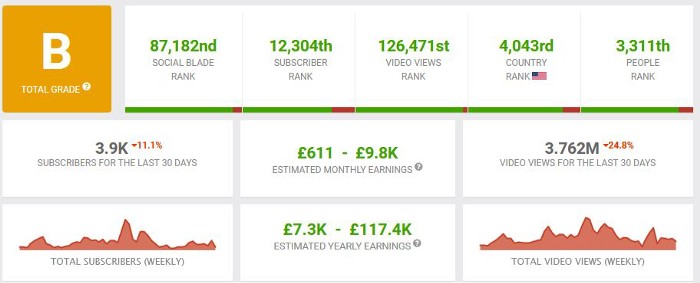
That's a crazy estimate, but it highlights the unbelievable potential of a channel that presents memes.
This channel thrives on quantity, thus putting out videos is necessary to keep the flow continuing and capture its audience's attention.
How Are the Videos Made?
Straightforward. Memes are added to a presentation without editing (so you could make this in PowerPoint or Keynote).
Each slide should include a unique image and caption. Set 10 seconds per slide.
Add music and post the video.
Finding enough memes for the material and theming is difficult, but if you enjoy memes, this is a fun job.
This case study should have shown you that you don't need expensive software or design expertise to make entertaining videos. Why not try fresh, easy-to-do ideas and see where they lead?
You might also like

Desiree Peralta
3 years ago
How to Use the 2023 Recession to Grow Your Wealth Exponentially
This season's three best money moves.

“Millionaires are made in recessions.” — Time Capital
We're in a serious downturn, whether or not we're in a recession.
97% of business owners are decreasing costs by more than 10%, and all markets are down 30%.
If you know what you're doing and analyze the markets correctly, this is your chance to become a millionaire.
In any recession, there are always excellent possibilities to seize. Real estate, crypto, stocks, enterprises, etc.
What you do with your money could influence your future riches.
This article analyzes the three key markets, their circumstances for 2023, and how to profit from them.
Ways to make money on the stock market.
If you're conservative like me, you should invest in an index fund. Most of these funds are down 10-30% of ATH:
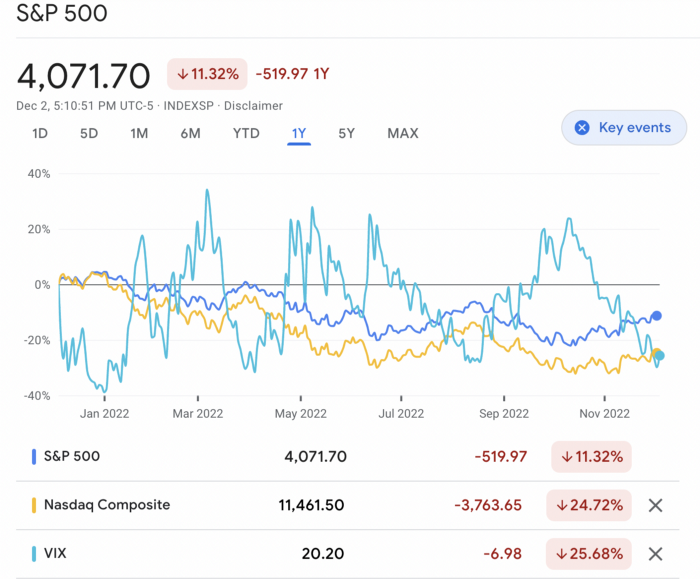
In earlier recessions, most money index funds lost 20%. After this downturn, they grew and passed the ATH in subsequent months.
Now is the greatest moment to invest in index funds to grow your money in a low-risk approach and make 20%.
If you want to be risky but wise, pick companies that will get better next year but are struggling now.
Even while we can't be 100% confident of a company's future performance, we know some are strong and will have a fantastic year.
Microsoft (down 22%), JPMorgan Chase (15.6%), Amazon (45%), and Disney (33.8%).
These firms give dividends, so you can earn passively while you wait.
So I consider that a good strategy to make wealth in the current stock market is to create two portfolios: one based on index funds to earn 10% to 20% profit when the corrections end, and the other based on individual stocks of popular and strong companies to earn 20%-30% return and dividends while you wait.
How to profit from the downturn in the real estate industry.
With rising mortgage rates, it's the worst moment to buy a home if you don't want to be eaten by banks. In the U.S., interest rates are double what they were three years ago, so buying now looks foolish.
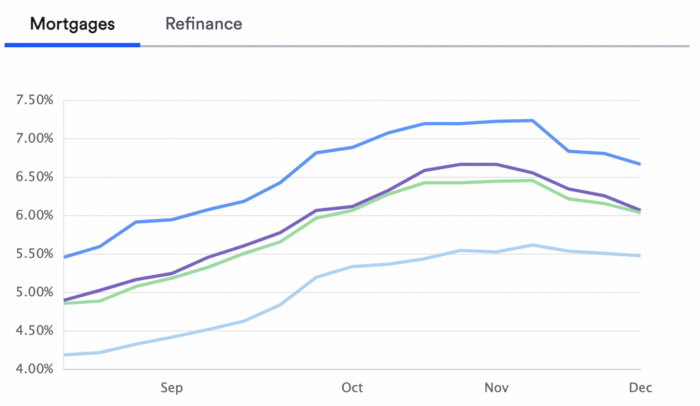
Due to these rates, property prices are falling, but that won't last long since individuals will take advantage.
According to historical data, now is the ideal moment to buy a house for the next five years and perhaps forever.
If you can buy a house, do it. You can refinance the interest at a lower rate with acceptable credit, but not the house price.
Take advantage of the housing market prices now because you won't find a decent deal when rates normalize.
How to profit from the cryptocurrency market.
This is the riskiest market to tackle right now, but it could offer the most opportunities if done appropriately.
The most powerful cryptocurrencies are down more than 60% from last year: $68,990 for BTC and $4,865 for ETH.
If you focus on those two coins, you can make 30%-60% without waiting for them to return to their ATH, and they're low enough to be a solid investment.
I don't encourage trying other altcoins because the crypto market is in crisis and you can lose everything if you're greedy.
Still, the main Cryptos are a good investment provided you store them in an external wallet and follow financial gurus' security advice.
Last thoughts
We can't anticipate a recession until it ends. We can't forecast a market or asset's lowest point, therefore waiting makes little sense.
If you want to develop your wealth, assess the money prospects on all the marketplaces and initiate long-term trades.
Many millionaires are made during recessions because they don't fear negative figures and use them to scale their money.

Jess Rifkin
4 years ago
As the world watches the Russia-Ukraine border situation, This bill would bar aid to Ukraine until the Mexican border is secured.
Although Mexico and Ukraine are thousands of miles apart, this legislation would link their responses.
Context
Ukraine was a Soviet republic until 1991. A significant proportion of the population, particularly in the east, is ethnically Russian. In February, the Russian military invaded Ukraine, intent on overthrowing its democratically elected government.
This could be the biggest European land invasion since WWII. In response, President Joe Biden sent 3,000 troops to NATO countries bordering Ukraine to help with Ukrainian refugees, with more troops possible if the situation worsened.
In July 2021, the US Border Patrol reported its highest monthly encounter total since March 2000. Some Republicans compare Biden's response to the Mexican border situation to his response to the Ukrainian border situation, though the correlation is unclear.
What the bills do
Two new Republican bills seek to link the US response to Ukraine to the situation in Mexico.
The Secure America's Borders First Act would prohibit federal funding for Ukraine until the US-Mexico border is “operationally controlled,” including a wall as promised by former President Donald Trump. (The bill even mandates a 30-foot-high wall.)
The USB (Ukraine and Southern Border) Act, introduced on February 8 by Rep. Matt Rosendale (R-MT0), would allow the US to support Ukraine, but only if the number of Armed Forces deployed there is less than the number deployed to the Mexican border. Madison Cawthorne introduced H.R. 6665 on February 9th (R-NC11).
What backers say
Supporters argue that even if the US should militarily assist Ukraine, our own domestic border situation should take precedence.
After failing to secure our own border and protect our own territorial integrity, ‘America Last' politicians on both sides of the aisle now tell us that we must do so for Ukraine. “Before rushing America into another foreign conflict over an Eastern European nation's border thousands of miles from our shores, they should first secure our southern border.”
“If Joe Biden truly cared about Americans, he would prioritize national security over international affairs,” Rep. Cawthorn said in a separate press release. The least we can do to secure our own country is send the same number of troops to the US-Mexico border to assist our border patrol agents working diligently to secure America.
What opponents say
The president has defended his Ukraine and Mexico policies, stating that both seek peace and diplomacy.
Our nations [the US and Mexico] have a long and complicated history, and we haven't always been perfect neighbors, but we have seen the power and purpose of cooperation,” Biden said in 2021. “We're safer when we work together, whether it's to manage our shared border or stop the pandemic. [In both the Obama and Biden administration], we made a commitment that we look at Mexico as an equal, not as somebody who is south of our border.”
No mistake: If Russia goes ahead with its plans, it will be responsible for a catastrophic and unnecessary war of choice. To protect our collective security, the United States and our allies are ready to defend every inch of NATO territory. We won't send troops into Ukraine, but we will continue to support the Ukrainian people... But, I repeat, Russia can choose diplomacy. It is not too late to de-escalate and return to the negotiating table.”
Odds of passage
The Secure America's Borders First Act has nine Republican sponsors. Either the House Armed Services or Foreign Affairs Committees may vote on it.
Rep. Paul Gosar, a Republican, co-sponsored the USB Act (R-AZ4). The House Armed Services Committee may vote on it.
With Republicans in control, passage is unlikely.

Mike Meyer
3 years ago
Reality Distortion
Old power paradigm blocks new planetary paradigm

The difference between our reality and the media's reality is like a tale of two worlds. The greatest and worst of times, really.
Expanding information demands complex skills and understanding to separate important information from ignorance and crap. And that's just the start of determining the source's aim.
Trust who? We see people trust liars in public and then be destroyed by their decisions. Mistakes may be devastating.
Many give up and don't trust anyone. Reality is a choice, though. Same risks.
We must separate our needs and wants from reality. Needs and wants have rules. Greed and selfishness create an unlivable planet.
Culturally, we know this, but we ignore it as foolish. Selfish and greedy people obtain what they want, while others suffer.
We invade, plunder, rape, and burn. We establish civilizations by institutionalizing an exploitable underclass and denying its existence. These cultural lies promote greed and selfishness despite their destructiveness.
Controlling parts of society institutionalize these lies as fact. Many of each age are willing to gamble on greed because they were taught to see greed and selfishness as principles justified by prosperity.
Our cultural understanding recognizes the long-term benefits of collaboration and sharing. This older understanding generates an increasing tension between greedy people and those who see its planetary effects.
Survival requires distinguishing between global and regional realities. Simple, yet many can't do it. This is the first time human greed has had a global impact.
In the past, conflict stories focused on regional winners and losers. Losers lose, winners win, etc. Powerful people see potential decades of nuclear devastation as local, overblown, and not personally dangerous.
Mutually Assured Destruction (MAD) was a human choice that required people to acquiesce to irrational devastation. This prevented nuclear destruction. Most would refuse.
A dangerous “solution” relies on nuclear trigger-pullers not acting irrationally. Since then, we've collected case studies of sane people performing crazy things in experiments. We've been lucky, but the climate apocalypse could be different.
Climate disaster requires only continuing current behavior. These actions already cause global harm, but that's not a threat. These activities must be viewed differently.
Once grasped, denying planetary facts is hard to accept. Deniers can't think beyond regional power. Seeing planet-scale is unusual.
Decades of indoctrination defining any planetary perspective as un-American implies communal planetary assets are for plundering. The old paradigm limits any other view.
In the same way, the new paradigm sees the old regional power paradigm as a threat to planetary civilization and lifeforms. Insane!
While MAD relied on leaders not acting stupidly to trigger a nuclear holocaust, the delayed climatic holocaust needs correcting centuries of lunacy. We must stop allowing craziness in global leadership.
Nothing in our acknowledged past provides a paradigm for such. Only primitive people have failed to reach our level of sophistication.
Before European colonization, certain North American cultures built sophisticated regional nations but abandoned them owing to authoritarian cruelty and destruction. They were overrun by societies that saw no wrong in perpetual exploitation. David Graeber's The Dawn of Everything is an example of historical rediscovery, which is now crucial.
From the new paradigm's perspective, the old paradigm is irrational, yet it's too easy to see those in it as ignorant or malicious, if not both. These people are both, but the collapsing paradigm they promote is older or more ingrained than we think.
We can't shift that paradigm's view of a dead world. We must eliminate this mindset from our nations' leadership. No other way will preserve the earth.
Change is occurring. As always with tremendous transition, younger people are building the new paradigm.
The old paradigm's disintegration is insane. The ability to detect errors and abandon their sources is more important than age. This is gaining recognition.
The breakdown of the previous paradigm is not due to senile leadership, but to systemic problems that the current, conservative leadership cannot recognize.
Stop following the old paradigm.