


Plagiarism on OpenSea: humans and computers
OpenSea, a non-fungible token (NFT) marketplace, is fighting plagiarism. A new “two-pronged” approach will aim to root out and remove copies of authentic NFTs and changes to its blue tick verified badge system will seek to enhance customer confidence.
According to a blog post, the anti-plagiarism system will use algorithmic detection of “copymints” with human reviewers to keep it in check.
Last year, NFT collectors were duped into buying flipped images of the popular BAYC collection, according to The Verge. The largest NFT marketplace had to remove its delay pay minting service due to an influx of copymints.
80% of NFTs removed by the platform were minted using its lazy minting service, which kept the digital asset off-chain until the first purchase.
NFTs copied from popular collections are opportunistic money-grabs. Right-click, save, and mint the jacked JPEGs that are then flogged as an authentic NFT.
The anti-plagiarism system will scour OpenSea's collections for flipped and rotated images, as well as other undescribed permutations. The lack of detail here may be a deterrent to scammers, or it may reflect the new system's current rudimentary nature.
Thus, human detectors will be needed to verify images flagged by the detection system and help train it to work independently.
“Our long-term goal with this system is two-fold: first, to eliminate all existing copymints on OpenSea, and second, to help prevent new copymints from appearing,” it said.
“We've already started delisting identified copymint collections, and we'll continue to do so over the coming weeks.”
It works for Twitter, why not OpenSea
OpenSea is also changing account verification. Early adopters will be invited to apply for verification if their NFT stack is worth $100 or more. OpenSea plans to give the blue checkmark to people who are active on Twitter and Discord.
This is just the beginning. We are committed to a future where authentic creators can be verified, keeping scammers out.
Also, collections with a lot of hype and sales will get a blue checkmark. For example, a new NFT collection sold by the verified BAYC account will have a blue badge to verify its legitimacy.
New requests will be responded to within seven days, according to OpenSea.
These programs and products help protect creators and collectors while ensuring our community can confidently navigate the world of NFTs.
By elevating authentic content and removing plagiarism, these changes improve trust in the NFT ecosystem, according to OpenSea.
OpenSea is indeed catching up with the digital art economy. Last August, DevianArt upgraded its AI image recognition system to find stolen tokenized art on marketplaces like OpenSea.
It scans all uploaded art and compares it to “public blockchain events” like Ethereum NFTs to detect stolen art.
More on NFTs & Art

Jayden Levitt
3 years ago
Starbucks' NFT Project recently defeated its rivals.
The same way Amazon killed bookstores. You just can’t see it yet.

Shultz globalized coffee. Before Starbucks, coffee sucked.
All accounts say 1970s coffee was awful.
Starbucks had three stores selling ground Indonesian coffee in the 1980s.
What a show!
A year after joining the company at 29, Shultz traveled to Italy for R&D.
He noticed the coffee shops' sense of theater and community and realized Starbucks was in the wrong business.
Integrating coffee and destination created a sense of community in the store.
Brilliant!
He told Starbucks' founders about his experience.
They disapproved.
For two years.
Shultz left and opened an Italian coffee shop chain like any good entrepreneur.
Starbucks ran into financial trouble, so the founders offered to sell to Shultz.
Shultz bought Starbucks in 1987 for $3.8 million, including six stores and a payment plan.
Starbucks is worth $100.79Billion, per Google Finance.
26,500 times Shultz's initial investment
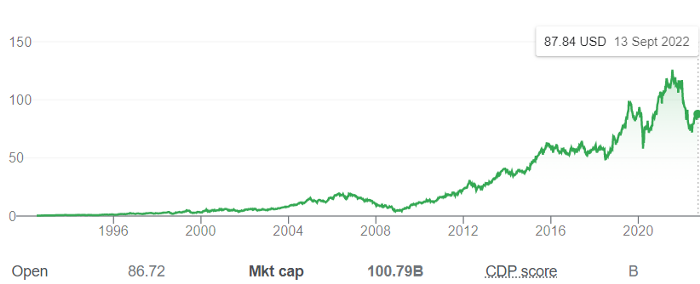
Starbucks is releasing its own NFT Platform under Shultz and his early Vision.
This year, Starbucks Odyssey launches. The new digital experience combines a Loyalty Rewards program with NFT.
The side chain Polygon-based platform doesn't require a Crypto Wallet. Customers can earn and buy digital assets to unlock incentives and experiences.
They've removed all friction, making it more immersive and convenient than a coffee shop.
Brilliant!
NFTs are the access coupon to their digital community, but they don't highlight the technology.
They prioritize consumer experience by adding non-technical users to Web3. Their collectables are called journey stamps, not NFTs.
No mention of bundled gas fees.
Brady Brewer, Starbucks' CMO, said;
“It happens to be built on blockchain and web3 technologies, but the customer — to be honest — may very well not even know that what they’re doing is interacting with blockchain technology. It’s just the enabler,”
Rewards members will log into a web app using their loyalty program credentials to access Starbucks Odyssey. They won't know about blockchain transactions.
Starbucks has just dealt its rivals a devastating blow.
It generates more than ten times the revenue of its closest competitor Costa Coffee.
The coffee giant is booming.
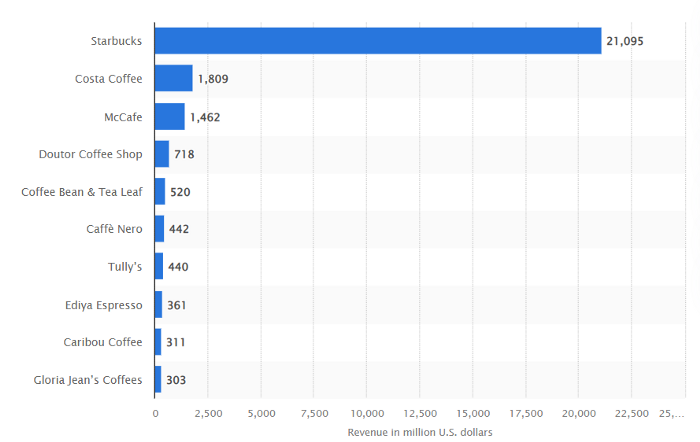
Starbucks is ahead of its competitors. No wonder.
They have an innovative, adaptable leadership team.
Starbucks' DNA challenges the narrative, especially when others reject their ideas.
I’m off for a cappuccino.

1eth1da
4 years ago
6 Rules to build a successful NFT Community in 2022

Too much NFT, Discord, and shitposting.
How do you choose?
How do you recruit more members to join your NFT project?
In 2021, a successful NFT project required:
Monkey/ape artwork
Twitter and Discord bot-filled
Roadmap overpromise
Goal was quick cash.
2022 and the years after will change that.
These are 6 Rules for a Strong NFT Community in 2022:
THINK LONG TERM
This relates to roadmap planning. Hype and dumb luck may drive NFT projects (ahem, goblins) but rarely will your project soar.
Instead, consider sustainability.
Plan your roadmap based on your team's abilities.
Do what you're already doing, but with NFTs, make it bigger and better.
You shouldn't copy a project's roadmap just because it was profitable.
This will lead to over-promising, team burnout, and an RUG NFT project.
OFFER VALUE
Building a great community starts with giving.
Why are musicians popular?
Because they offer entertainment for everyone, a random person becomes a fan, and more fans become a cult.
That's how you should approach your community.
TEAM UP
A great team helps.
An NFT project could have 3 or 2 people.
Credibility trumps team size.
Make sure your team can answer community questions, resolve issues, and constantly attend to them.
Don't overwork and burn out.
Your community will be able to recognize that you are trying too hard and give up on the project.
BUILD A GREAT PRODUCT
Bored Ape Yacht Club altered the NFT space.
Cryptopunks transformed NFTs.
Many others did, including Okay Bears.
What made them that way?
Because they answered a key question.
What is my NFT supposed to be?
Before planning art, this question must be answered.
NFTs can't be just jpegs.
What does it represent?
Is it a Metaverse-ready project?
What blockchain are you going to be using and why?
Set some ground rules for yourself. This helps your project's direction.
These questions will help you and your team set a direction for blockchain, NFT, and Web3 technology.
EDUCATE ON WEB3
The more the team learns about Web3 technology, the more they can offer their community.
Think tokens, metaverse, cross-chain interoperability and more.
BUILD A GREAT COMMUNITY
Several projects mistreat their communities.
They treat their community like "customers" and try to sell them NFT.
Providing Whitelists and giveaways aren't your only community-building options.
Think bigger.
Consider them family and friends, not wallets.
Consider them fans.
These are some tips to start your NFT project.

Stephen Moore
3 years ago
Trading Volume on OpenSea Drops by 99% as the NFT Boom Comes to an End
Wasn't that a get-rich-quick scheme?

OpenSea processed $2.7 billion in NFT transactions in May 2021.
Fueled by a crypto bull run, rumors of unfathomable riches, and FOMO, Bored Apes, Crypto Punks, and other JPEG-format trash projects flew off the virtual shelves, snatched up by retail investors and celebrities alike.
Over a year later, those shelves are overflowing and warehouses are backlogged. Since March, I've been writing less. In May and June, the bubble was close to bursting.
Apparently, the boom has finally peaked.
This bubble has punctured, and deflation has begun. On Aug. 28, OpenSea processed $9.34 million.
From that euphoric high of $2.7 billion, $9.34 million represents a spectacular decline of 99%.
OpenSea contradicts the data. A trading platform spokeswoman stated the comparison is unfair because it compares the site's highest and lowest trading days. They're the perfect two data points to assess the drop. OpenSea chooses to use ETH volume measures, which ignore crypto's shifting price. Since January 2022, monthly ETH volume has dropped 140%, according to Dune.
Unconvincing counterargument.
Further OpenSea indicators point to declining NFT demand:
Since January 2022, daily user visits have decreased by 50%.
Daily transactions have decreased by 50% since the beginning of the year in the same manner.
Off-platform, the floor price of Bored Apes has dropped from 145 ETH to 77 ETH. (At $4,800, a reduction from $700,000 to $370,000). Google search data shows waning popular interest.
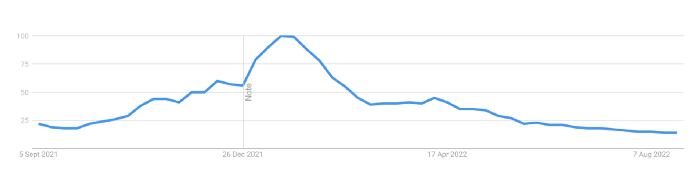
It is a trend that will soon vanish, just like laser eyes.
NFTs haven't moved since the new year. Eminem and Snoop Dogg can utilize their apes in music videos or as 3D visuals to perform at the VMAs, but the reality is that NFTs have lost their public appeal and the market is trying to regain its footing.
They've lost popularity because?
Breaking records. The technology still lacks genuine use cases a year and a half after being popular.
They're pricey prestige symbols that have made a few people rich through cunning timing or less-than-savory scams or rug pulling. Over $10.5 billion has been taken through frauds, most of which are NFT enterprises promising to be the next Bored Apes, according to Web3 is going wonderfully. As the market falls, many ordinary investors realize they purchased into a self-fulfilling ecosystem that's halted. Many NFTs are sold between owner-held accounts to boost their price, data suggests. Most projects rely on social media excitement to debut with a high price before the first owners sell and chuckle to the bank. When they don't, the initiative fails, leaving investors high and dry.
NFTs are fading like laser eyes. Most people pushing the technology don't believe in it or the future it may bring. No, they just need a Kool-Aid-drunk buyer.
Everybody wins. When your JPEGs are worth 99% less than when you bought them, you've lost.
When demand reaches zero, many will lose.
You might also like

Rick Blyth
3 years ago
Looking for a Reliable Micro SaaS Niche
Niches are rich, as the adage goes.
Micro SaaS requires a great micro-niche; otherwise, it's merely plain old SaaS with a large audience.
Instead of targeting broad markets with few identifying qualities, specialise down to a micro-niche. How would you target these users?

Better go tiny. You'll locate and engage new consumers more readily and serve them better with a customized solution.
Imagine you're a real estate lawyer looking for a case management solution. Because it's so specific to you, you'd be lured to this link:

instead of below:

Next, locate mini SaaS niches that could work for you. You're not yet looking at the problems/solutions in these areas, merely shortlisting them.
The market should be growing, not shrinking
We shouldn't design apps for a declining niche. We intend to target stable or growing niches for the next 5 to 10 years.
If it's a developing market, you may be able to claim a stake early. You must balance this strategy with safer, longer-established niches (accountancy, law, health, etc).
First Micro SaaS apps I designed were for Merch By Amazon creators, a burgeoning niche. I found this niche when searching for passive income.
Graphic designers and entrepreneurs post their art to Amazon to sell on clothes. When Amazon sells their design, they get a royalty. Since 2015, this platform and specialty have grown dramatically.
Amazon doesn't publicize the amount of creators on the platform, but it's possible to approximate by looking at Facebook groups, Reddit channels, etc.
I could see the community growing week by week, with new members joining. Merch was an up-and-coming niche, and designers made money when their designs sold. All I had to do was create tools that let designers focus on making bestselling designs.
Look at the Google Trends graph below to see how this niche has evolved and when I released my apps and resigned my job.
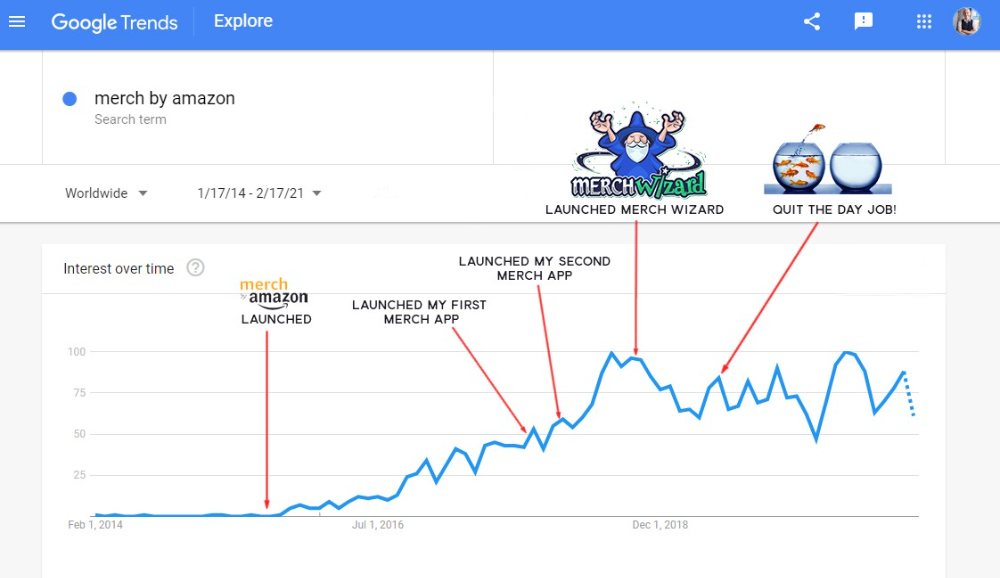
Are the users able to afford the tools?
Who's your average user? Consumer or business? Is your solution budgeted?
If they're students, you'll struggle to convince them to subscribe to your study-system app (ahead of video games and beer).
Let's imagine you designed a Shopify plugin that emails customers when a product is restocked. If your plugin just needs 5 product sales a month to justify its cost, everyone wins (just be mindful that one day Shopify could potentially re-create your plugins functionality within its core offering making your app redundant ).
Do specialized users buy tools? If so, that's comforting. If not, you'd better have a compelling value proposition for your end customer if you're the first.
This should include how much time or money your program can save or make the user.

Are you able to understand the Micro SaaS market?
Ideally, you're already familiar about the industry/niche. Maybe you're fixing a challenge from your day job or freelance work.
If not, evaluate how long it would take to learn the niche's users. Health & Fitness is easier to relate to and understand than hedge fund derivatives trading.
Competing in these complex (and profitable) fields might offer you an edge.

B2C, B2M, or B2B?
Consider your user base's demographics. Will you target businesses, consumers, or both? Let's examine the different consumer types:
B2B refers to business-to-business transactions where customers are other businesses. UpVoty, Plutio, Slingshot, Salesforce, Atlassian, and Hubspot are a few examples of SaaS, ranging from Micro SaaS to SaaS.
Business to Consumer (B2C), in which your clients are people who buy things. For instance, Duolingo, Canva, and Nomad List.
For instance, my tool KDP Wizard has a mixed user base of publishing enterprises and also entrepreneurial consumers selling low-content books on Amazon. This is a case of business to many (B2M), where your users are a mixture of businesses and consumers. There is a large SaaS called Dropbox that offers both personal and business plans.
Targeting a B2B vs. B2C niche is very different. The sales cycle differs.
A B2B sales staff must make cold calls to potential clients' companies. Long sales, legal, and contractual conversations are typically required for each business to get the go-ahead. The cost of obtaining a new customer is substantially more than it is for B2C, despite the fact that the recurring fees are significantly higher.
Since there is typically only one individual making the purchasing decision, B2C signups are virtually always self-service with reduced recurring fees. Since there is typically no outbound sales staff in B2C, acquisition costs are significantly lower than in B2B.
User Characteristics for B2B vs. B2C
Consider where your niche's users congregate if you don't already have a presence there.
B2B users frequent LinkedIn and Twitter. B2C users are on Facebook/Instagram/Reddit/Twitter, etc.
Churn is higher in B2C because consumers haven't gone through all the hoops of a B2B sale. Consumers are more unpredictable than businesses since they let their bank cards exceed limitations or don't update them when they expire.
With a B2B solution, there's a contractual arrangement and the firm will pay the subscription as long as they need it.
Depending on how you feel about the above (sales team vs. income vs. churn vs. targeting), you'll know which niches to pursue.
You ought to respect potential customers.
Would you hang out with customers?
You'll connect with users at conferences (in-person or virtual), webinars, seminars, screenshares, Facebook groups, emails, support calls, support tickets, etc.
If talking to a niche's user base makes you shudder, you're in for a tough road. Whether they're demanding or dull, avoid them if possible.
Merch users are mostly graphic designers, side hustlers, and entrepreneurs. These laid-back users embrace technologies that assist develop their Merch business.
I discovered there was only one annual conference for this specialty, held in Seattle, USA. I decided to organize a conference for UK/European Merch designers, despite never having done so before.

Hosting a conference for over 80 people was stressful, and it turned out to be much bigger than expected, with attendees from the US, Europe, and the UK.
I met many specialized users, built relationships, gained trust, and picked their brains in person. Many of the attendees were already Merch Wizard users, so hearing their feedback and ideas for future features was invaluable.
focused and specific
Instead of building for a generic, hard-to-reach market, target a specific group.
I liken it to fishing in a little, hidden pond. This small pond has only one species of fish, so you learn what bait it likes. Contrast that with trawling for hours to catch as many fish as possible, even if some aren't what you want.
In the case management scenario, it's difficult to target leads because several niches could use the app. Where do your potential customers hang out? Your generic solution: No.
It's easier to join a community of Real Estate Lawyers and see if your software can answer their pain points.
My Success with Micro SaaS
In my case, my Micro SaaS apps have been my chrome extensions. Since I launched them, they've earned me an average $10k MRR, allowing me to quit my lousy full-time job years ago.
I sold my apps after scaling them for a life-changing lump amount. Since then, I've helped unfulfilled software developers escape the 9-5 through Micro SaaS.
Whether it's a profitable side hustle or a liferaft to quit their job and become their own Micro SaaS boss.
Having built my apps to the point where I could quit my job, then scaled and sold them, I feel I can share my skills with software developers worldwide.
Read my free guide on self-funded SaaS to discover more about Micro SaaS, or download your own copy. 12 chapters cover everything from Idea to Exit.

Watch my YouTube video to learn how to construct a Micro SaaS app in 10 steps.

Nik Nicholas
4 years ago
A simple go-to-market formula

“Poor distribution, not poor goods, is the main reason for failure” — Peter Thiel.
Here's an easy way to conceptualize "go-to-market" for your distribution plan.
One equation captures the concept:
Distribution = Ecosystem Participants + Incentives
Draw your customers' ecosystem. Set aside your goods and consider your consumer's environment. Who do they deal with daily?
First, list each participant. You want an exhaustive list, but here are some broad categories.
In-person media services
Websites
Events\Networks
Financial education and banking
Shops
Staff
Advertisers
Twitter influencers
Draw influence arrows. Who's affected? I'm not just talking about Instagram selfie-posters. Who has access to your consumer and could promote your product if motivated?
The thicker the arrow, the stronger the relationship. Include more "influencers" if needed. Customer ecosystems are complex.
3. Incentivize ecosystem players. “Show me the incentive and I will show you the result.“, says Warren Buffet's business partner Charlie Munger.
Strong distribution strategies encourage others to promote your product to your target market by incentivizing the most prominent players. Incentives can be financial or non-financial.
Financial rewards
Usually, there's money. If you pay Facebook, they'll run your ad. Salespeople close deals for commission. Giving customers bonus credits will encourage referrals.
Most businesses underuse non-financial incentives.
Non-cash incentives
Motivate key influencers without spending money to expand quickly and cheaply. What can you give a client-connector for free?
Here are some ideas:
Are there any other features or services available?
Titles or status? Tinder paid college "ambassadors" for parties to promote its dating service.
Can I get early/free access? Facebook gave a select group of developers "exclusive" early access to their AR platform.
Are you a good host? Pharell performed at YPlan's New York launch party.
Distribution? Apple's iPod earphones are white so others can see them.
Have an interesting story? PR rewards journalists by giving them a compelling story to boost page views.
Prioritize distribution.
More time spent on distribution means more room in your product design and business plan. Once you've identified the key players in your customer's ecosystem, talk to them.
Money isn't your only resource. Creative non-monetary incentives may be more effective and scalable. Give people something useful and easy to deliver.

Shan Vernekar
3 years ago
How the Ethereum blockchain's transactions are carried out
Overview
Ethereum blockchain is a network of nodes that validate transactions. Any network node can be queried for blockchain data for free. To write data as a transition requires processing and writing to each network node's storage. Fee is paid in ether and is also called as gas.
We'll examine how user-initiated transactions flow across the network and into the blockchain.
Flow of transactions
A user wishes to move some ether from one external account to another. He utilizes a cryptocurrency wallet for this (like Metamask), which is a browser extension.
The user enters the desired transfer amount and the external account's address. He has the option to choose the transaction cost he is ready to pay.
Wallet makes use of this data, signs it with the user's private key, and writes it to an Ethereum node. Services such as Infura offer APIs that enable writing data to nodes. One of these services is used by Metamask. An example transaction is shown below. Notice the “to” address and value fields.
var rawTxn = {
nonce: web3.toHex(txnCount),
gasPrice: web3.toHex(100000000000),
gasLimit: web3.toHex(140000),
to: '0x633296baebc20f33ac2e1c1b105d7cd1f6a0718b',
value: web3.toHex(0),
data: '0xcc9ab24952616d6100000000000000000000000000000000000000000000000000000000'
};The transaction is written to the target Ethereum node's local TRANSACTION POOL. It informed surrounding nodes of the new transaction, and those nodes reciprocated. Eventually, this transaction is received by and written to each node's local TRANSACTION pool.
The miner who finds the following block first adds pending transactions (with a higher gas cost) from the nearby TRANSACTION POOL to the block.
The transactions written to the new block are verified by other network nodes.
A block is added to the main blockchain after there is consensus and it is determined to be genuine. The local blockchain is updated with the new node by additional nodes as well.
Block mining begins again next.
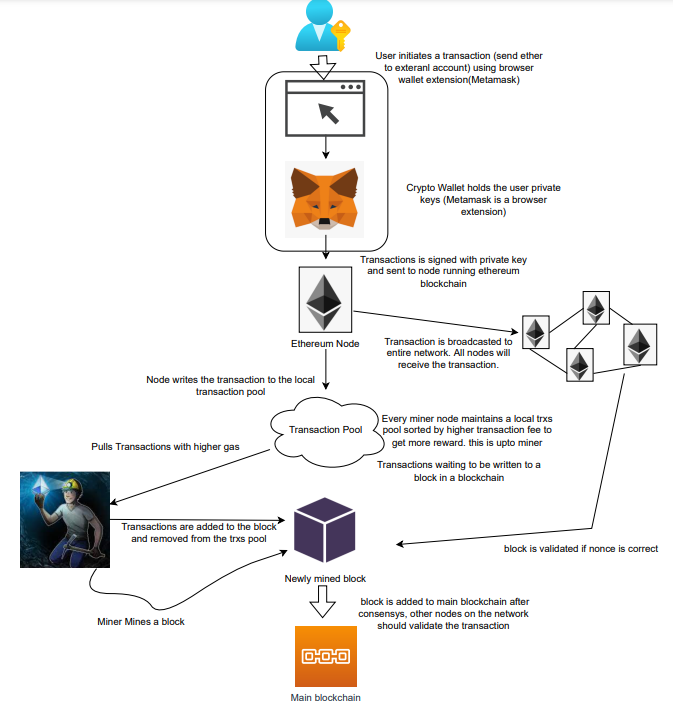
The image above shows how transactions go via the network and what's needed to submit them to the main block chain.
References
ethereum.org/transactions How Ethereum transactions function, their data structure, and how to send them via app. ethereum.org