


More on Entrepreneurship/Creators

cdixon
3 years ago
2000s Toys, Secrets, and Cycles
During the dot-com bust, I started my internet career. People used the internet intermittently to check email, plan travel, and do research. The average internet user spent 30 minutes online a day, compared to 7 today. To use the internet, you had to "log on" (most people still used dial-up), unlike today's always-on, high-speed mobile internet. In 2001, Amazon's market cap was $2.2B, 1/500th of what it is today. A study asked Americans if they'd adopt broadband, and most said no. They didn't see a need to speed up email, the most popular internet use. The National Academy of Sciences ranked the internet 13th among the 100 greatest inventions, below radio and phones. The internet was a cool invention, but it had limited uses and wasn't a good place to build a business.
A small but growing movement of developers and founders believed the internet could be more than a read-only medium, allowing anyone to create and publish. This is web 2. The runner up name was read-write web. (These terms were used in prominent publications and conferences.)
Web 2 concepts included letting users publish whatever they want ("user generated content" was a buzzword), social graphs, APIs and mashups (what we call composability today), and tagging over hierarchical navigation. Technical innovations occurred. A seemingly simple but important one was dynamically updating web pages without reloading. This is now how people expect web apps to work. Mobile devices that could access the web were niche (I was an avid Sidekick user).
The contrast between what smart founders and engineers discussed over dinner and on weekends and what the mainstream tech world took seriously during the week was striking. Enterprise security appliances, essentially preloaded servers with security software, were a popular trend. Many of the same people would talk about "serious" products at work, then talk about consumer internet products and web 2. It was tech's biggest news. Web 2 products were seen as toys, not real businesses. They were hobbies, not work-related.
There's a strong correlation between rich product design spaces and what smart people find interesting, which took me some time to learn and led to blog posts like "The next big thing will start out looking like a toy" Web 2's novel product design possibilities sparked dinner and weekend conversations. Imagine combining these features. What if you used this pattern elsewhere? What new product ideas are next? This excited people. "Serious stuff" like security appliances seemed more limited.
The small and passionate web 2 community also stood out. I attended the first New York Tech meetup in 2004. Everyone fit in Meetup's small conference room. Late at night, people demoed their software and chatted. I have old friends. Sometimes I get asked how I first met old friends like Fred Wilson and Alexis Ohanian. These topics didn't interest many people, especially on the east coast. We were friends. Real community. Alex Rampell, who now works with me at a16z, is someone I met in 2003 when a friend said, "Hey, I met someone else interested in consumer internet." Rare. People were focused and enthusiastic. Revolution seemed imminent. We knew a secret nobody else did.
My web 2 startup was called SiteAdvisor. When my co-founders and I started developing the idea in 2003, web security was out of control. Phishing and spyware were common on Internet Explorer PCs. SiteAdvisor was designed to warn users about security threats like phishing and spyware, and then, using web 2 concepts like user-generated reviews, add more subjective judgments (similar to what TrustPilot seems to do today). This staged approach was common at the time; I called it "Come for the tool, stay for the network." We built APIs, encouraged mashups, and did SEO marketing.
Yahoo's 2005 acquisitions of Flickr and Delicious boosted web 2 in 2005. By today's standards, the amounts were small, around $30M each, but it was a signal. Web 2 was assumed to be a fun hobby, a way to build cool stuff, but not a business. Yahoo was a savvy company that said it would make web 2 a priority.
As I recall, that's when web 2 started becoming mainstream tech. Early web 2 founders transitioned successfully. Other entrepreneurs built on the early enthusiasts' work. Competition shifted from ideation to execution. You had to decide if you wanted to be an idealistic indie bar band or a pragmatic stadium band.
Web 2 was booming in 2007 Facebook passed 10M users, Twitter grew and got VC funding, and Google bought YouTube. The 2008 financial crisis tested entrepreneurs' resolve. Smart people predicted another great depression as tech funding dried up.
Many people struggled during the recession. 2008-2011 was a golden age for startups. By 2009, talented founders were flooding Apple's iPhone app store. Mobile apps were booming. Uber, Venmo, Snap, and Instagram were all founded between 2009 and 2011. Social media (which had replaced web 2), cloud computing (which enabled apps to scale server side), and smartphones converged. Even if social, cloud, and mobile improve linearly, the combination could improve exponentially.
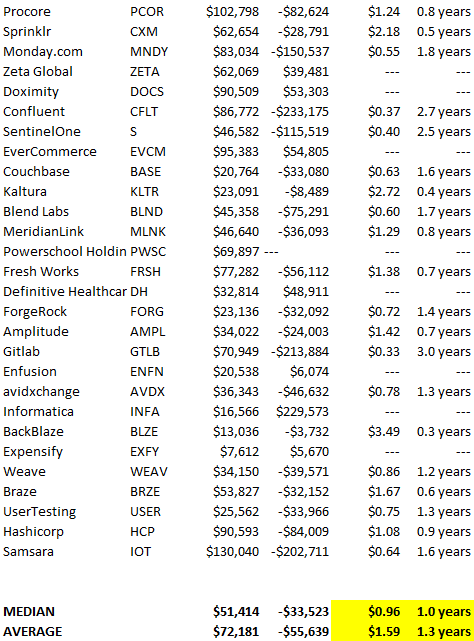
This chart shows how I view product and financial cycles. Product and financial cycles evolve separately. The Nasdaq index is a proxy for the financial sentiment. Financial sentiment wildly fluctuates.
Next row shows iconic startup or product years. Bottom-row product cycles dictate timing. Product cycles are more predictable than financial cycles because they follow internal logic. In the incubation phase, enthusiasts build products for other enthusiasts on nights and weekends. When the right mix of technology, talent, and community knowledge arrives, products go mainstream. (I show the biggest tech cycles in the chart, but smaller ones happen, like web 2 in the 2000s and fintech and SaaS in the 2010s.)
Tech has changed since the 2000s. Few tech giants dominate the internet, exerting economic and cultural influence. In the 2000s, web 2 was ignored or dismissed as trivial. Entrenched interests respond aggressively to new movements that could threaten them. Creative patterns from the 2000s continue today, driven by enthusiasts who see possibilities where others don't. Know where to look. Crypto and web 3 are where I'd start.
Today's negative financial sentiment reminds me of 2008. If we face a prolonged downturn, we can learn from 2008 by preserving capital and focusing on the long term. Keep an eye on the product cycle. Smart people are interested in things with product potential. This becomes true. Toys become necessities. Hobbies become mainstream. Optimists build the future, not cynics.
Full article is available here

Nik Nicholas
3 years ago
A simple go-to-market formula

“Poor distribution, not poor goods, is the main reason for failure” — Peter Thiel.
Here's an easy way to conceptualize "go-to-market" for your distribution plan.
One equation captures the concept:
Distribution = Ecosystem Participants + Incentives
Draw your customers' ecosystem. Set aside your goods and consider your consumer's environment. Who do they deal with daily?
First, list each participant. You want an exhaustive list, but here are some broad categories.
In-person media services
Websites
Events\Networks
Financial education and banking
Shops
Staff
Advertisers
Twitter influencers
Draw influence arrows. Who's affected? I'm not just talking about Instagram selfie-posters. Who has access to your consumer and could promote your product if motivated?
The thicker the arrow, the stronger the relationship. Include more "influencers" if needed. Customer ecosystems are complex.
3. Incentivize ecosystem players. “Show me the incentive and I will show you the result.“, says Warren Buffet's business partner Charlie Munger.
Strong distribution strategies encourage others to promote your product to your target market by incentivizing the most prominent players. Incentives can be financial or non-financial.
Financial rewards
Usually, there's money. If you pay Facebook, they'll run your ad. Salespeople close deals for commission. Giving customers bonus credits will encourage referrals.
Most businesses underuse non-financial incentives.
Non-cash incentives
Motivate key influencers without spending money to expand quickly and cheaply. What can you give a client-connector for free?
Here are some ideas:
Are there any other features or services available?
Titles or status? Tinder paid college "ambassadors" for parties to promote its dating service.
Can I get early/free access? Facebook gave a select group of developers "exclusive" early access to their AR platform.
Are you a good host? Pharell performed at YPlan's New York launch party.
Distribution? Apple's iPod earphones are white so others can see them.
Have an interesting story? PR rewards journalists by giving them a compelling story to boost page views.
Prioritize distribution.
More time spent on distribution means more room in your product design and business plan. Once you've identified the key players in your customer's ecosystem, talk to them.
Money isn't your only resource. Creative non-monetary incentives may be more effective and scalable. Give people something useful and easy to deliver.

Navdeep Yadav
3 years ago
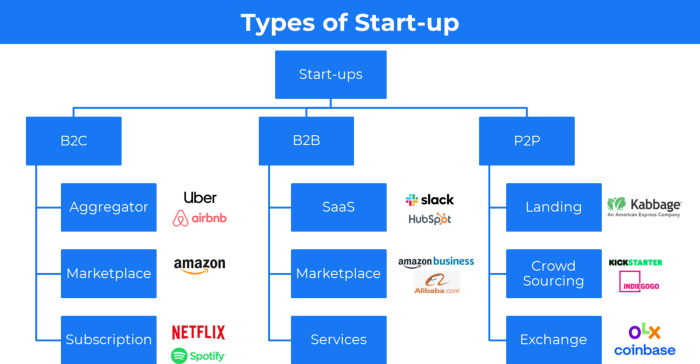
31 startup company models (with examples)
Many people find the internet's various business models bewildering.
This article summarizes 31 startup e-books.
1. Using the freemium business model (free plus premium),
The freemium business model offers basic software, games, or services for free and charges for enhancements.
Examples include Slack, iCloud, and Google Drive
Provide a rudimentary, free version of your product or service to users.
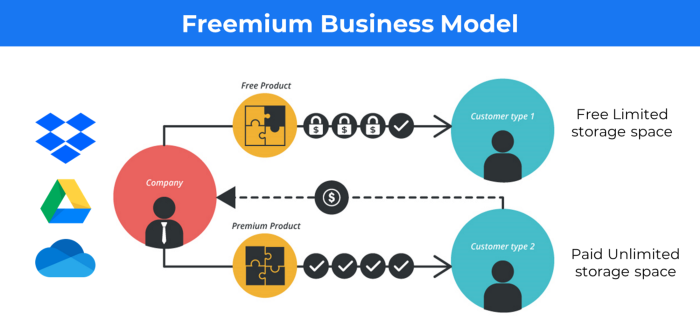
Google Drive and Dropbox offer 15GB and 2GB of free space but charge for more.
Freemium business model details (Click here)
2. The Business Model of Subscription
Subscription business models sell a product or service for recurring monthly or yearly revenue.
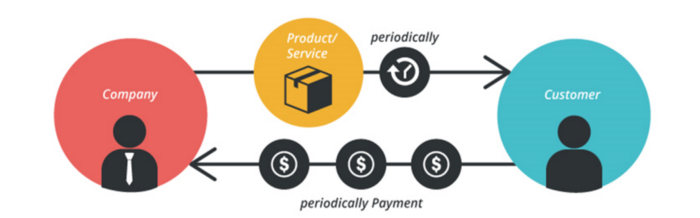
Examples: Tinder, Netflix, Shopify, etc
It's the next step to Freemium if a customer wants to pay monthly for premium features.
Subscription Business Model (Click here)
3. A market-based business strategy
It's an e-commerce site or app where third-party sellers sell products or services.
Examples are Amazon and Fiverr.
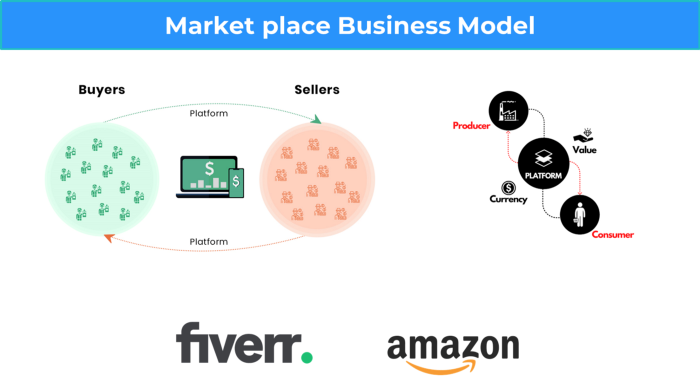
On Amazon's marketplace, a third-party vendor sells a product.
Freelancers on Fiverr offer specialized skills like graphic design.
Marketplace's business concept is explained.
4. Business plans using aggregates
In the aggregator business model, the service is branded.
Uber, Airbnb, and other examples
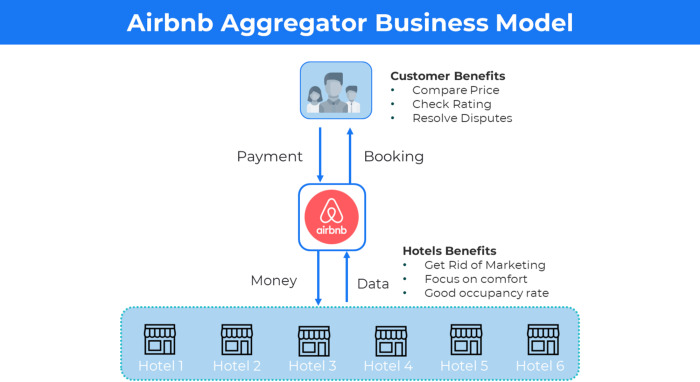
Marketplace and Aggregator business models differ.

Amazon and Fiverr link merchants and customers and take a 10-20% revenue split.
Uber and Airbnb-style aggregator Join these businesses and provide their products.
5. The pay-as-you-go concept of business
This is a consumption-based pricing system. Cloud companies use it.
Example: Amazon Web Service and Google Cloud Platform (GCP) (AWS)
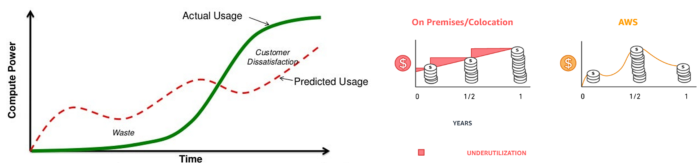
AWS, an Amazon subsidiary, offers over 200 pay-as-you-go cloud services.
“In short, the more you use the more you pay”
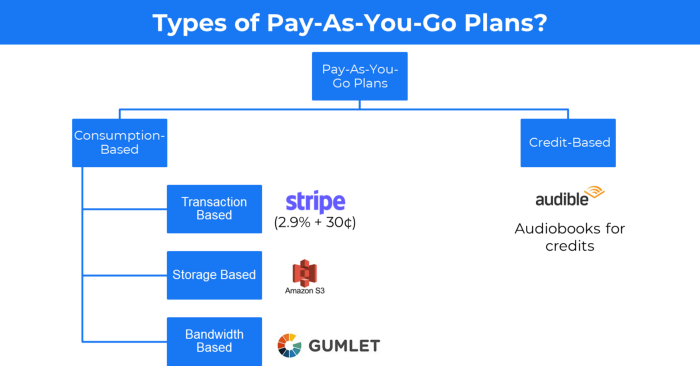
When it's difficult to divide clients into pricing levels, pay-as-you is employed.
6. The business model known as fee-for-service (FFS)
FFS charges fixed and variable fees for each successful payment.
For instance, PayU, Paypal, and Stripe
Stripe charges 2.9% + 30 per payment.
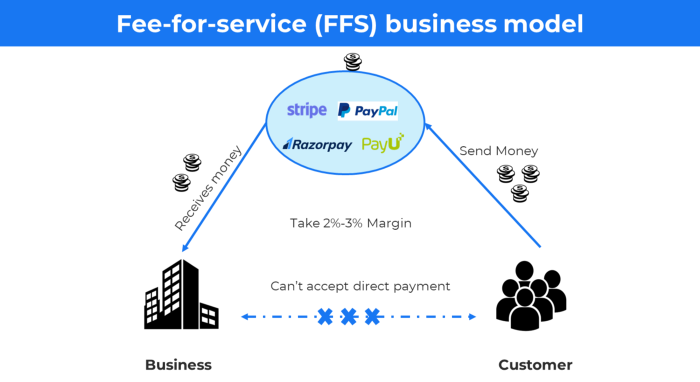
These firms offer a payment gateway to take consumer payments and deposit them to a business account.
Fintech business model
7. EdTech business strategy
In edtech, you generate money by selling material or teaching as a service.
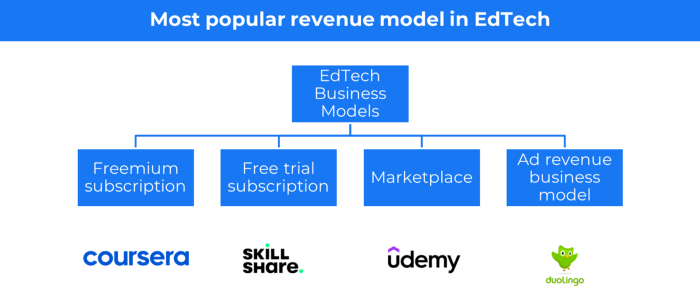
edtech business models
Freemium When course content is free but certification isn't, e.g. Coursera
FREE TRIAL SkillShare offers free trials followed by monthly or annual subscriptions.
Self-serving marketplace approach where you pick what to learn.
Ad-revenue model The company makes money by showing adverts to its huge user base.
Lock-in business strategy
Lock in prevents customers from switching to a competitor's brand or offering.
It uses switching costs or effort to transmit (soft lock-in), improved brand experience, or incentives.
Apple, SAP, and other examples
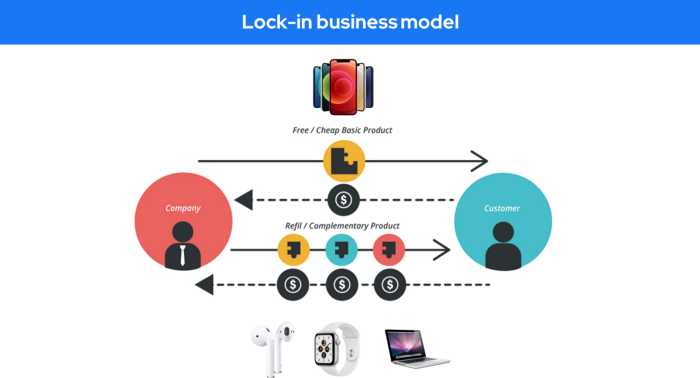
Apple offers an iPhone and then locks you in with extra hardware (Watch, Airpod) and platform services (Apple Store, Apple Music, cloud, etc.).
9. Business Model for API Licensing
APIs let third-party apps communicate with your service.
Uber and Airbnb use Google Maps APIs for app navigation.
Examples are Google Map APIs (Map), Sendgrid (Email), and Twilio (SMS).
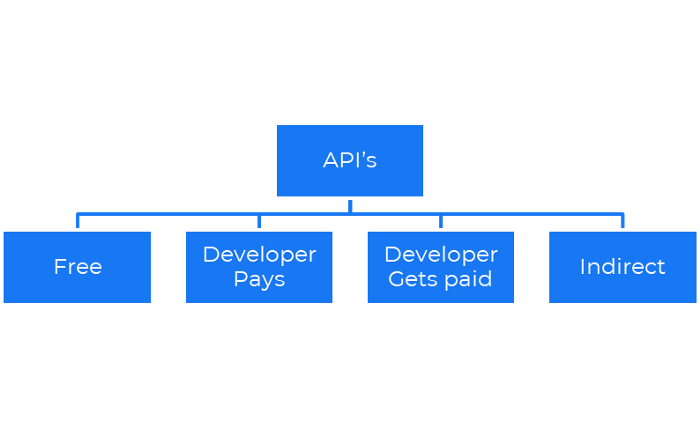
Business models for APIs
Free: The simplest API-driven business model that enables unrestricted API access for app developers. Google Translate and Facebook are two examples.
Developer Pays: Under this arrangement, service providers such as AWS, Twilio, Github, Stripe, and others must be paid by application developers.
The developer receives payment: These are the compensated content producers or developers who distribute the APIs utilizing their work. For example, Amazon affiliate programs
10. Open-source enterprise
Open-source software can be inspected, modified, and improved by anybody.
For instance, use Firefox, Java, or Android.
Google paid Mozilla $435,702 million to be their primary search engine in 2018.
Open-source software profits in six ways.
Paid assistance The Project Manager can charge for customization because he is quite knowledgeable about the codebase.
A full database solution is available as a Software as a Service (MongoDB Atlas), but there is a fee for the monitoring tool.
Open-core design R studio is a better GUI substitute for open-source applications.
sponsors of GitHub Sponsorships benefit the developers in full.
demands for paid features Earn Money By Developing Open Source Add-Ons for Current Products
Open-source business model
11. The business model for data
If the software or algorithm collects client data to improve or monetize the system.
Open AI GPT3 gets smarter with use.
Foursquare allows users to exchange check-in locations.
Later, they compiled large datasets to enable retailers like Starbucks launch new outlets.
12. Business Model Using Blockchain
Blockchain is a distributed ledger technology that allows firms to deploy smart contracts without a central authority.
Examples include Alchemy, Solana, and Ethereum.
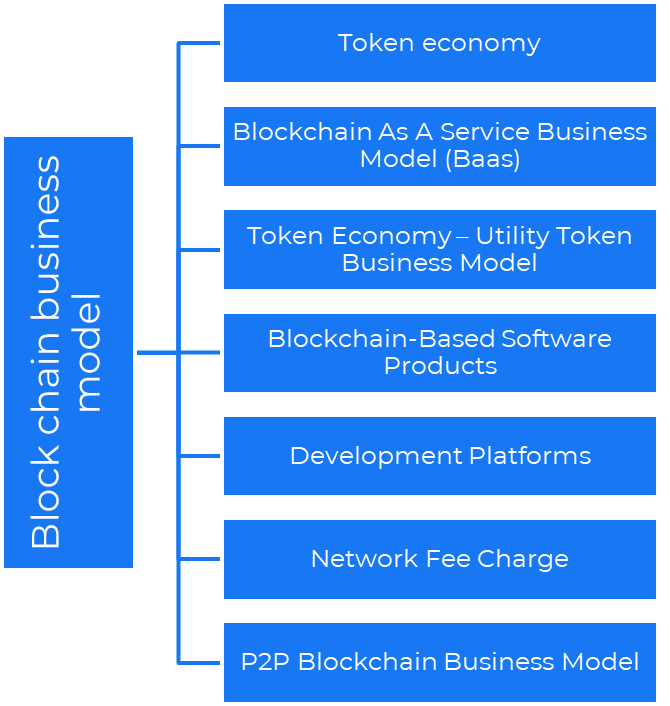
Business models using blockchain
Economy of tokens or utility When a business uses a token business model, it issues some kind of token as one of the ways to compensate token holders or miners. For instance, Solana and Ethereum
Bitcoin Cash P2P Business Model Peer-to-peer (P2P) blockchain technology permits direct communication between end users. as in IPFS
Enterprise Blockchain as a Service (Baas) BaaS focuses on offering ecosystem services similar to those offered by Amazon (AWS) and Microsoft (Azure) in the web 3 sector. Example: Ethereum Blockchain as a Service with Bitcoin (EBaaS).
Blockchain-Based Aggregators With AWS for blockchain, you can use that service by making an API call to your preferred blockchain. As an illustration, Alchemy offers nodes for many blockchains.
13. The free-enterprise model
In the freeterprise business model, free professional accounts are led into the funnel by the free product and later become B2B/enterprise accounts.
For instance, Slack and Zoom
Freeterprise companies flourish through collaboration.
Start with a free professional account to build an enterprise.
14. Business plan for razor blades
It's employed in hardware where one piece is sold at a loss and profits are made through refills or add-ons.
Gillet razor & blades, coffee machine & beans, HP printer & cartridge, etc.
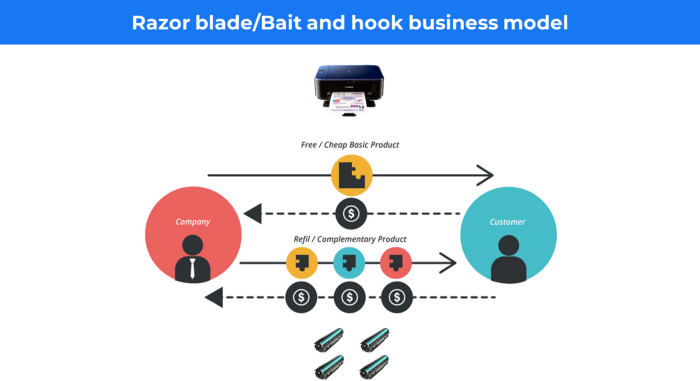
Sony sells the Playstation console at a loss but makes up for it by selling games and charging for online services.
Advantages of the Razor-Razorblade Method
lowers the risk a customer will try a product. enables buyers to test the goods and services without having to pay a high initial investment.
The product's ongoing revenue stream has the potential to generate sales that much outweigh the original investments.
Razor blade business model
15. The business model of direct-to-consumer (D2C)
In D2C, the company sells directly to the end consumer through its website using a third-party logistic partner.
Examples include GymShark and Kylie Cosmetics.
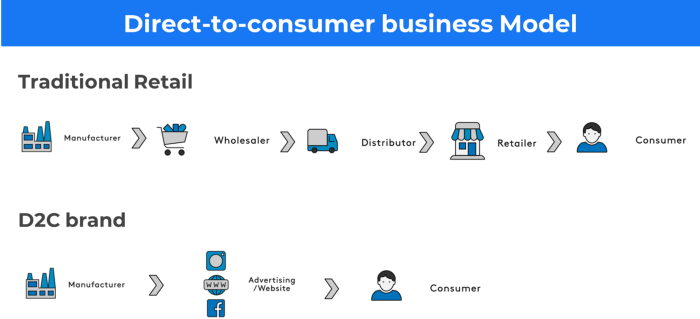
D2C brands can only expand via websites, marketplaces (Amazon, eBay), etc.
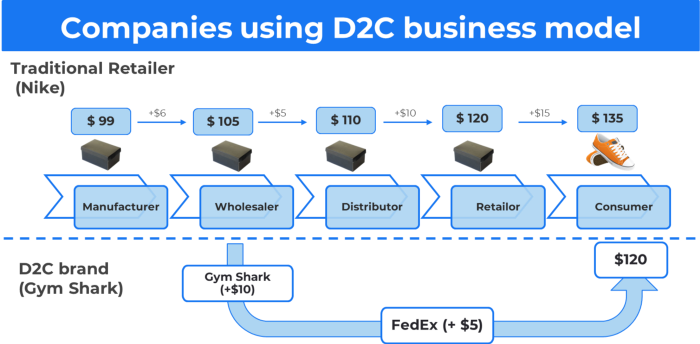
D2C benefits
Lower reliance on middlemen = greater profitability
You now have access to more precise demographic and geographic customer data.
Additional space for product testing
Increased customisation throughout your entire product line-Inventory Less
16. Business model: White Label vs. Private Label
Private label/White label products are made by a contract or third-party manufacturer.
Most amazon electronics are made in china and white-labeled.
Amazon supplements and electronics.
Contract manufacturers handle everything after brands select product quantities on design labels.
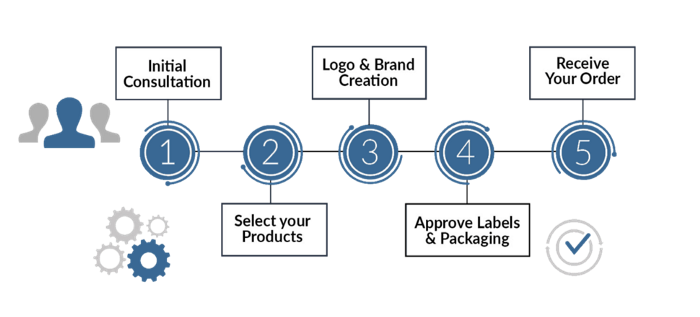
17. The franchise model
The franchisee uses the franchisor's trademark, branding, and business strategy (company).
For instance, KFC, Domino's, etc.
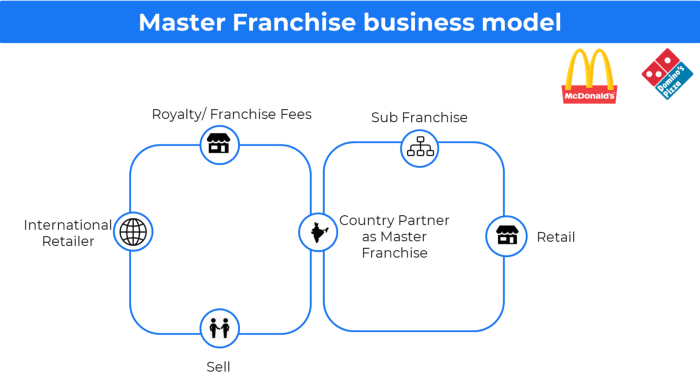
Subway, Domino, Burger King, etc. use this business strategy.

Many people pick a franchise because opening a restaurant is risky.
18. Ad-based business model
Social media and search engine giants exploit search and interest data to deliver adverts.
Google, Meta, TikTok, and Snapchat are some examples.
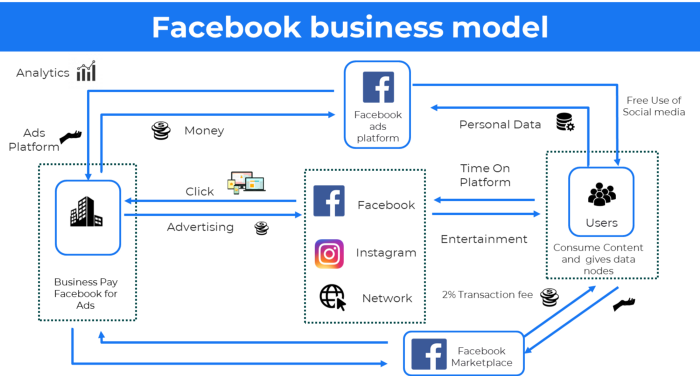
Users don't pay for the service or product given, e.g. Google users don't pay for searches.
In exchange, they collected data and hyper-personalized adverts to maximize revenue.
19. Business plan for octopuses
Each business unit functions separately but is connected to the main body.
Instance: Oyo

OYO is Asia's Airbnb, operating hotels, co-working, co-living, and vacation houses.
20, Transactional business model, number
Sales to customers produce revenue.
E-commerce sites and online purchases employ SSL.
Goli is an ex-GymShark.
21. The peer-to-peer (P2P) business model
In P2P, two people buy and sell goods and services without a third party or platform.
Consider OLX.
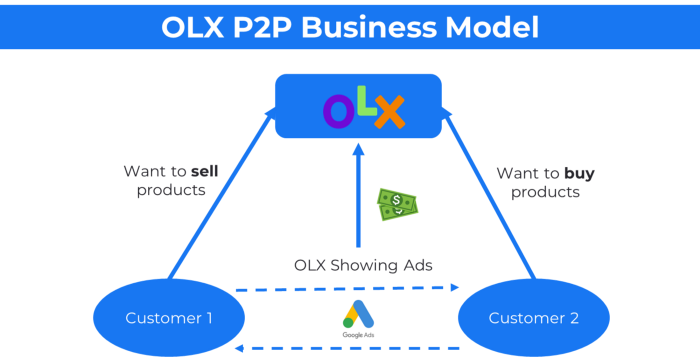
22. P2P lending as a manner of operation
In P2P lending, one private individual (P2P Lender) lends/invests or borrows money from another (P2P Borrower).
Instance: Kabbage
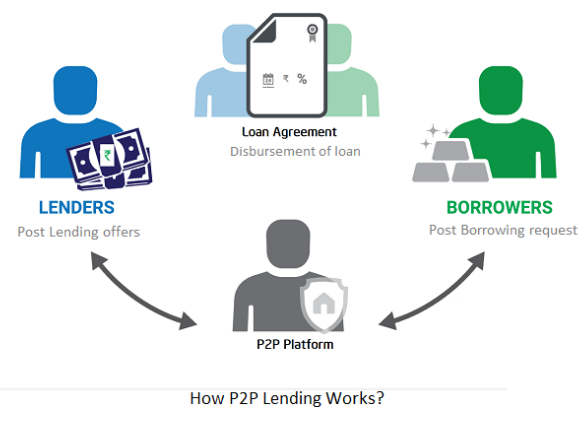
Social lending lets people lend and borrow money directly from each other without an intermediary financial institution.
23. A business model for brokers
Brokerages charge a commission or fee for their services.
Examples include eBay, Coinbase, and Robinhood.
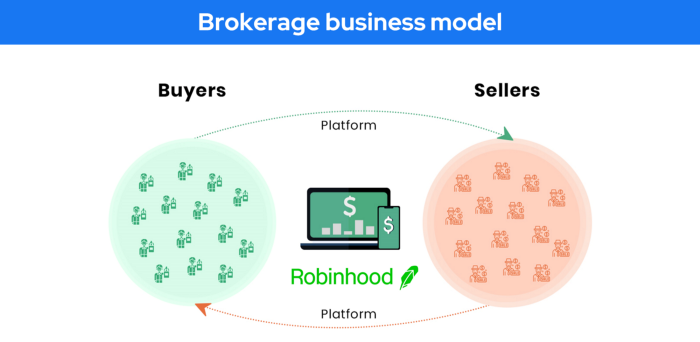
Brokerage businesses are common in Real estate, finance, and online and operate on this model.

Buy/sell similar models Examples include financial brokers, insurance brokers, and others who match purchase and sell transactions and charge a commission.
These brokers charge an advertiser a fee based on the date, place, size, or type of an advertisement. This is known as the classified-advertiser model. For instance, Craiglist
24. Drop shipping as an industry
Dropshipping allows stores to sell things without holding physical inventories.
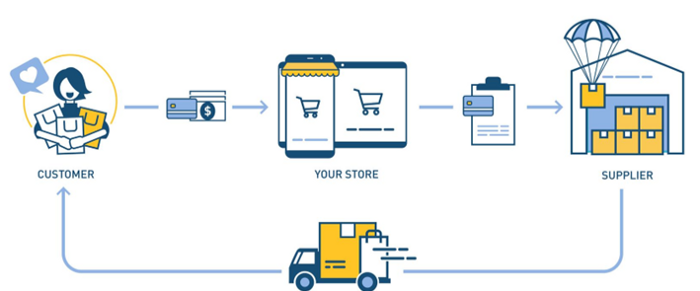
When a customer orders, use a third-party supplier and logistic partners.
Retailer product portfolio and customer experience Fulfiller The consumer places the order.
Dropshipping advantages
Less money is needed (Low overhead-No Inventory or warehousing)
Simple to start (costs under $100)
flexible work environment
New product testing is simpler
25. Business Model for Space as a Service
It's centered on a shared economy that lets millennials live or work in communal areas without ownership or lease.
Consider WeWork and Airbnb.
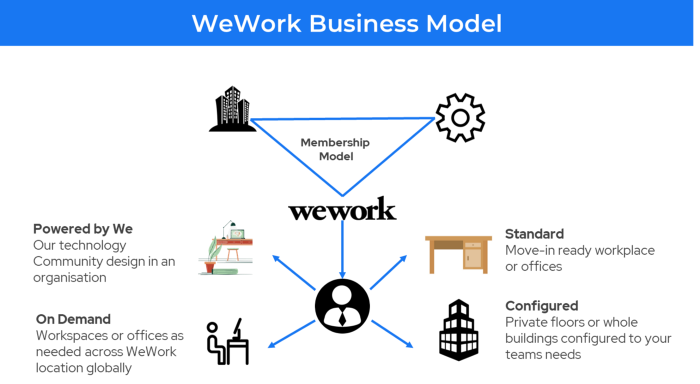
WeWork helps businesses with real estate, legal compliance, maintenance, and repair.
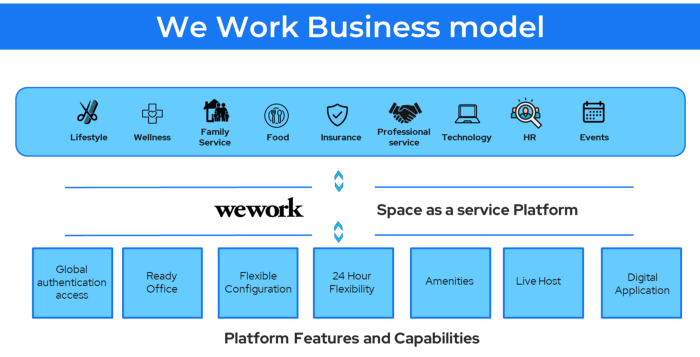
26. The business model for third-party logistics (3PL)
In 3PL, a business outsources product delivery, warehousing, and fulfillment to an external logistics company.
Examples include Ship Bob, Amazon Fulfillment, and more.

3PL partners warehouse, fulfill, and return inbound and outbound items for a charge.
Inbound logistics involves bringing products from suppliers to your warehouse.
Outbound logistics refers to a company's production line, warehouse, and customer.

27. The last-mile delivery paradigm as a commercial strategy
Last-mile delivery is the collection of supply chain actions that reach the end client.
Examples include Rappi, Gojek, and Postmates.
Last-mile is tied to on-demand and has a nighttime peak.
28. The use of affiliate marketing
Affiliate marketing involves promoting other companies' products and charging commissions.
Examples include Hubspot, Amazon, and Skillshare.

Your favorite youtube channel probably uses these short amazon links to get 5% of sales.
Affiliate marketing's benefits
In exchange for a success fee or commission, it enables numerous independent marketers to promote on its behalf.
Ensure system transparency by giving the influencers a specific tracking link and an online dashboard to view their profits.
Learn about the newest bargains and have access to promotional materials.
29. The business model for virtual goods
This is an in-app purchase for an intangible product.
Examples include PubG, Roblox, Candy Crush, etc.
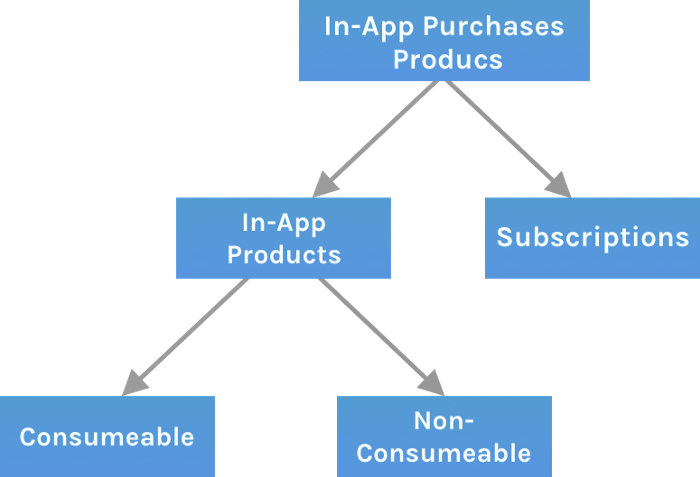
Consumables are like gaming cash that runs out. Non-consumable products provide a permanent advantage without repeated purchases.
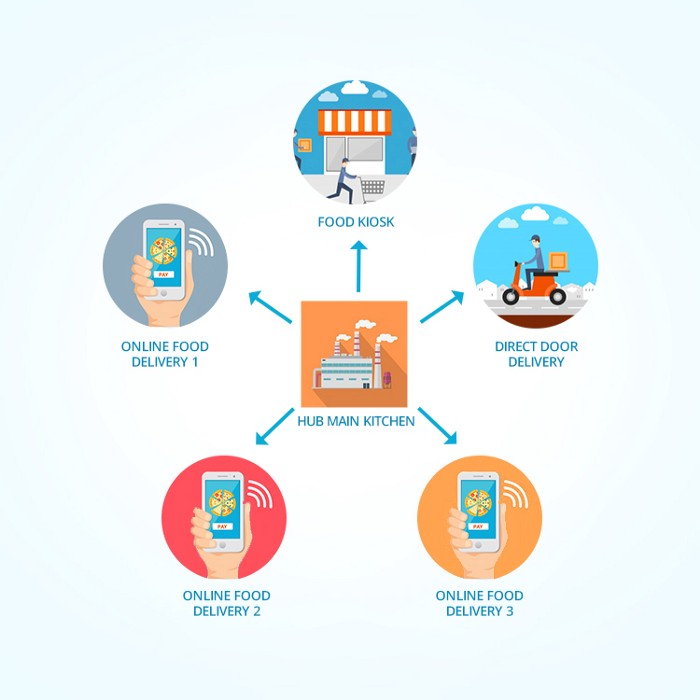
30. Business Models for Cloud Kitchens
Ghost, Dark, Black Box, etc.
Delivery-only restaurant.
These restaurants don't provide dine-in, only delivery.
For instance, NextBite and Faasos
31. Crowdsourcing as a Business Model
Crowdsourcing = Using the crowd as a platform's source.
In crowdsourcing, you get support from people around the world without hiring them.
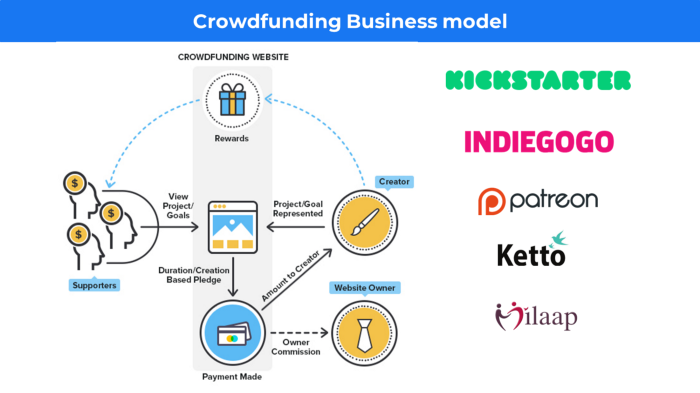
Crowdsourcing sites
Open-Source Software gives access to the software's source code so that developers can edit or enhance it. Examples include Firefox browsers and Linux operating systems.
Crowdfunding The oculus headgear would be an example of crowdfunding in essence, with no expectations.
You might also like

Jari Roomer
3 years ago
5 ways to never run out of article ideas
“Perfectionism is the enemy of the idea muscle. " — James Altucher

Writer's block is a typical explanation for low output. Success requires productivity.
In four years of writing, I've never had writer's block. And you shouldn't care.
You'll never run out of content ideas if you follow a few tactics. No, I'm not overpromising.
Take Note of Ideas
Brains are strange machines. Blank when it's time to write. Idiot. Nothing. We get the best article ideas when we're away from our workstation.
In the shower
Driving
In our dreams
Walking
During dull chats
Meditating
In the gym
No accident. The best ideas come in the shower, in nature, or while exercising.
(Your workstation is the worst place for creativity.)
The brain has time and space to link 'dots' of information during rest. It's eureka! New idea.
If you're serious about writing, capture thoughts as they come.
Immediately write down a new thought. Capture it. Don't miss it. Your future self will thank you.
As a writer, entrepreneur, or creative, letting ideas slide is bad.
I recommend using Evernote, Notion, or your device's basic note-taking tool to capture article ideas.
It doesn't matter whatever app you use as long as you collect article ideas.
When you practice 'idea-capturing' enough, you'll have an unending list of article ideas when writer's block hits.
High-Quality Content
More books, films, Medium pieces, and Youtube videos I consume, the more I'm inspired to write.
What you eat shapes who you are.
Celebrity gossip and fear-mongering news won't help your writing. It won't help you write regularly.
Instead, read expert-written books. Watch documentaries to improve your worldview. Follow amazing people online.
Develop your 'idea muscle' Daily creativity takes practice. The more you exercise your 'idea muscles,' the easier it is to generate article ideas.
I've trained my 'concept muscle' using James Altucher's exercise.
Write 10 ideas daily.
Write ten book ideas every day if you're an author. Write down 10 business ideas per day if you're an entrepreneur. Write down 10 investing ideas per day.
Write 10 article ideas per day. You become a content machine.
It doesn't state you need ten amazing ideas. You don't need 10 ideas. Ten ideas, regardless of quality.
Like at the gym, reps are what matter. With each article idea, you gain creativity. Writer's block is no match for this workout.
Quit Perfectionism
Perfectionism is bad for writers. You'll have bad articles. You'll have bad ideas. OK. It's creative.
Writing success requires prolificacy. You can't have 'perfect' articles.
“Perfectionism is the enemy of the idea muscle. Perfectionism is your brain trying to protect you from harm.” — James Altucher
Vincent van Gogh painted 900 pieces. The Starry Night is the most famous.
Thomas Edison invented 1093 things, but not all were as important as the lightbulb or the first movie camera.
Mozart composed nearly 600 compositions, but only Serenade No13 became popular.
Always do your best. Perfectionism shouldn't stop you from working. Write! Publicize. Make. Even if imperfect.
Write Your Story
Living an interesting life gives you plenty to write about. If you travel a lot, share your stories or lessons learned.
Describe your business's successes and shortcomings.
Share your experiences with difficulties or addictions.
More experiences equal more writing material.
If you stay indoors, perusing social media, you won't be inspired to write.
Have fun. Travel. Strive. Build a business. Be bold. Live a life worth writing about, and you won't run out of material.

shivsak
3 years ago
A visual exploration of the REAL use cases for NFTs in the Future

In this essay, I studied REAL NFT use examples and their potential uses.
Knowledge of the Hype Cycle
Gartner's Hype Cycle.
It proposes 5 phases for disruptive technology.
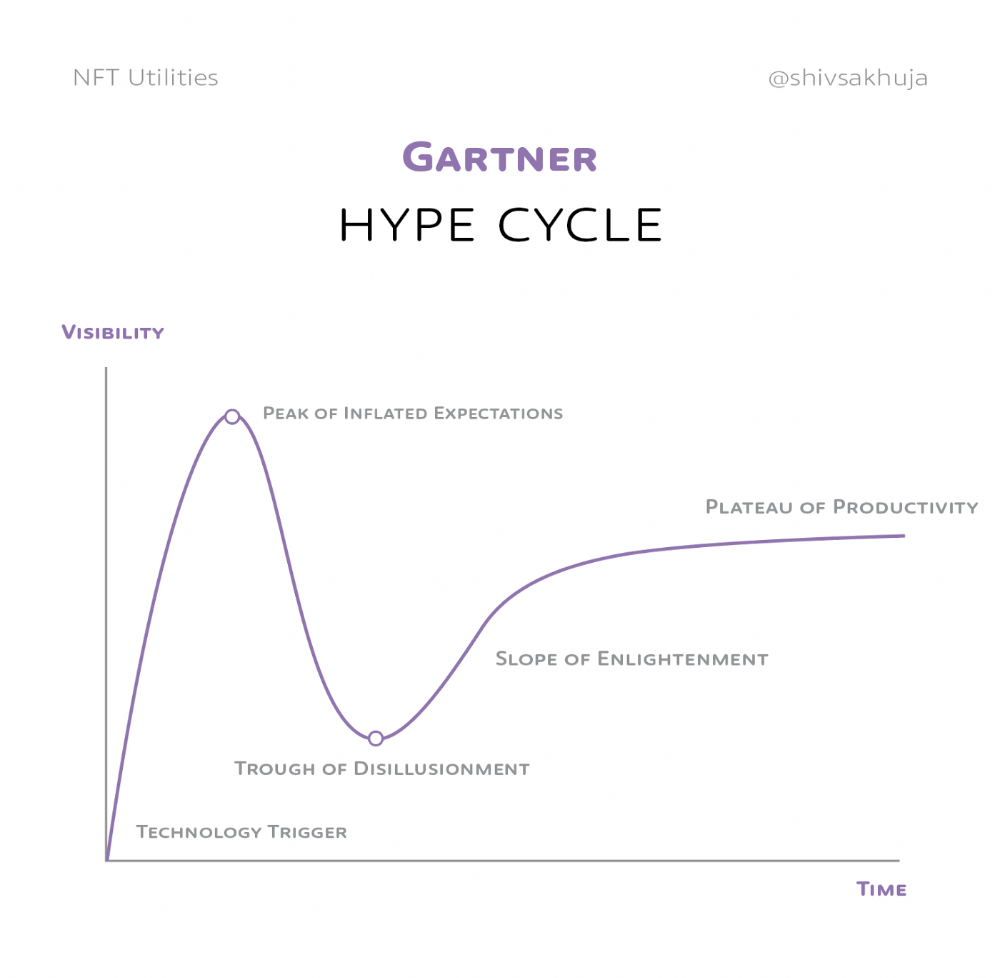
1. Technology Trigger: the emergence of potentially disruptive technology.
2. Peak of Inflated Expectations: Early publicity creates hype. (Ex: 2021 Bubble)
3. Trough of Disillusionment: Early projects fail to deliver on promises and the public loses interest. I suspect NFTs are somewhere around this trough of disillusionment now.
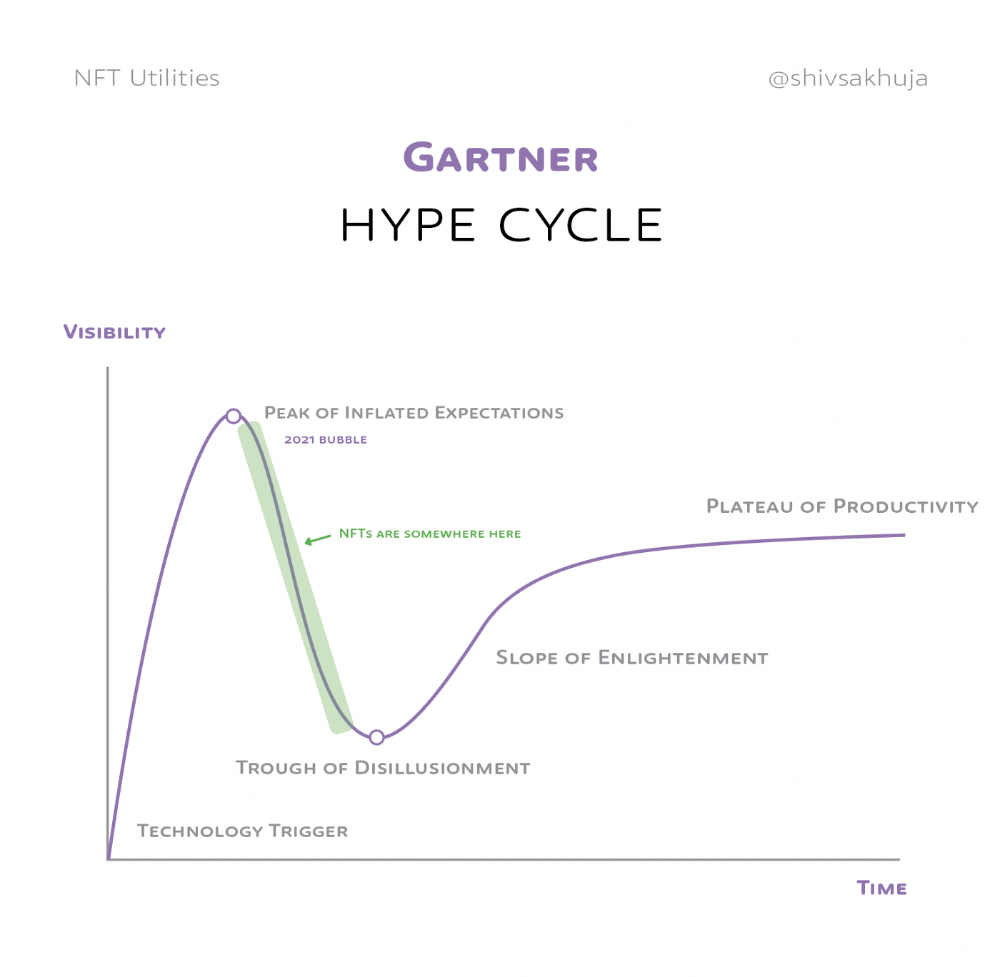
4. Enlightenment slope: The tech shows successful use cases.
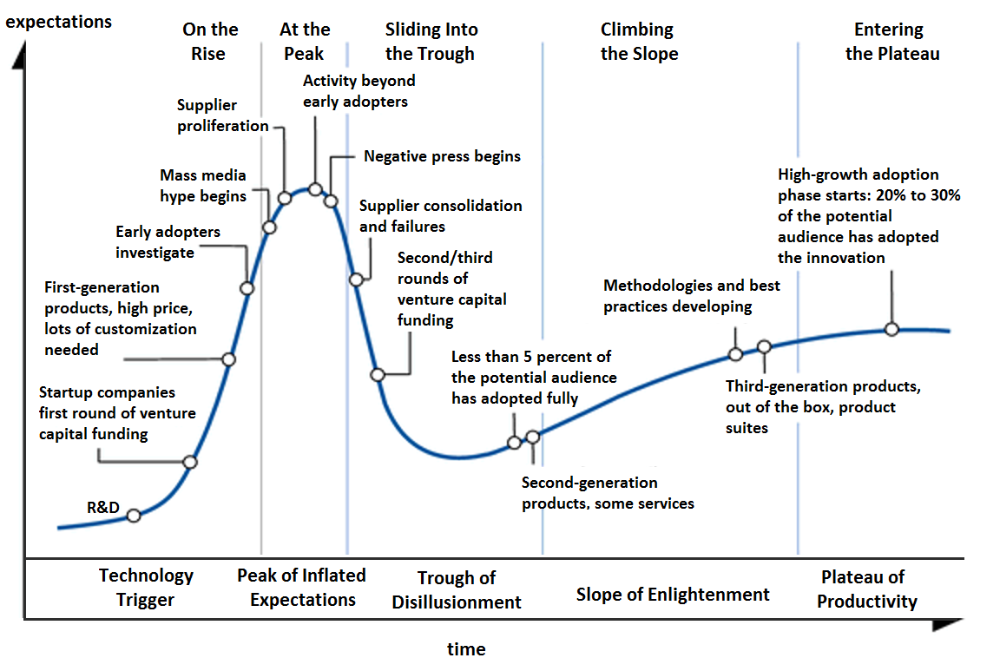
5. Plateau of Productivity: Mainstream adoption has arrived and broader market applications have proven themselves. Here’s a more detailed visual of the Gartner Hype Cycle from Wikipedia.
In the speculative NFT bubble of 2021, @beeple sold Everydays: the First 5000 Days for $69 MILLION in 2021's NFT bubble.
@nbatopshot sold millions in video collectibles.
This is when expectations peaked.
Let's examine NFTs' real-world applications.
Watch this video if you're unfamiliar with NFTs.
Online Art
Most people think NFTs are rich people buying worthless JPEGs and MP4s.
Digital artwork and collectibles are revolutionary for creators and enthusiasts.
NFT Profile Pictures
You might also have seen NFT profile pictures on Twitter.
My profile picture is an NFT I coined with @skogards factoria app, which helps me avoid bogus accounts.

Profile pictures are a good beginning point because they're unique and clearly yours.
NFTs are a way to represent proof-of-ownership. It’s easier to prove ownership of digital assets than physical assets, which is why artwork and pfps are the first use cases.
They can do much more.
NFTs can represent anything with a unique owner and digital ownership certificate. Domains and usernames.
Usernames & Domains
@unstoppableweb, @ensdomains, @rarible sell NFT domains.

NFT domains are transferable, which is a benefit.
Godaddy and other web2 providers have difficult-to-transfer domains. Domains are often leased instead of purchased.
Tickets
NFTs can also represent concert tickets and event passes.
There's a limited number, and entry requires proof.
NFTs can eliminate the problem of forgery and make it easy to verify authenticity and ownership.

NFT tickets can be traded on the secondary market, which allows for:
marketplaces that are uniform and offer the seller and buyer security (currently, tickets are traded on inefficient markets like FB & craigslist)
unbiased pricing
Payment of royalties to the creator

4. Historical ticket ownership data implies performers can airdrop future passes, discounts, etc.
5. NFT passes can be a fandom badge.
The $30B+ online tickets business is increasing fast.
NFT-based ticketing projects:
Gaming Assets
NFTs also help in-game assets.
Imagine someone spending five years collecting a rare in-game blade, then outgrowing or quitting the game. Gamers value that collectible.

The gaming industry is expected to make $200 BILLION in revenue this year, a significant portion of which comes from in-game purchases.
Royalties on secondary market trading of gaming assets encourage gaming businesses to develop NFT-based ecosystems.
Digital assets are the start. On-chain NFTs can represent real-world assets effectively.
Real estate has a unique owner and requires ownership confirmation.
Real Estate
Tokenizing property has many benefits.
1. Can be fractionalized to increase access, liquidity
2. Can be collateralized to increase capital efficiency and access to loans backed by an on-chain asset
3. Allows investors to diversify or make bets on specific neighborhoods, towns or cities +++

I've written about this thought exercise before.
I made an animated video explaining this.
We've just explored NFTs for transferable assets. But what about non-transferrable NFTs?
SBTs are Soul-Bound Tokens. Vitalik Buterin (Ethereum co-founder) blogged about this.
NFTs are basically verifiable digital certificates.
Diplomas & Degrees
That fits Degrees & Diplomas. These shouldn't be marketable, thus they can be non-transferable SBTs.

Anyone can verify the legitimacy of on-chain credentials, degrees, abilities, and achievements.
The same goes for other awards.
For example, LinkedIn could give you a verified checkmark for your degree or skills.

Authenticity Protection
NFTs can also safeguard against counterfeiting.
Counterfeiting is the largest criminal enterprise in the world, estimated to be $2 TRILLION a year and growing.
Anti-counterfeit tech is valuable.
This is one of @ORIGYNTech's projects.

Identity
Identity theft/verification is another real-world problem NFTs can handle.
In the US, 15 million+ citizens face identity theft every year, suffering damages of over $50 billion a year.
This isn't surprising considering all you need for US identity theft is a 9-digit number handed around in emails, documents, on the phone, etc.
Identity NFTs can fix this.
NFTs are one-of-a-kind and unforgeable.
NFTs offer a universal standard.
NFTs are simple to verify.
SBTs, or non-transferrable NFTs, are tied to a particular wallet.
In the event of wallet loss or theft, NFTs may be revoked.

This could be one of the biggest use cases for NFTs.
Imagine a global identity standard that is standardized across countries, cannot be forged or stolen, is digital, easy to verify, and protects your private details.

Since your identity is more than your government ID, you may have many NFTs.
@0xPolygon and @civickey are developing on-chain identity.

Memberships
NFTs can authenticate digital and physical memberships.

Voting
NFT IDs can verify votes.
If you remember 2020, you'll know why this is an issue.
Online voting's ease can boost turnout.

Informational property
NFTs can protect IP.

This can earn creators royalties.
NFTs have 2 important properties:
Verifiability IP ownership is unambiguously stated and publicly verified.
Platforms that enable authors to receive royalties on their IP can enter the market thanks to standardization.
Content Rights

Monetization without copyrighting = more opportunities for everyone.
This works well with the music.

Spotify and Apple Music pay creators very little.
Crowdfunding
Creators can crowdfund with NFTs.
NFTs can represent future royalties for investors.
This is particularly useful for fields where people who are not in the top 1% can’t make money. (Example: Professional sports players)

Mirror.xyz allows blog-based crowdfunding.
Financial NFTs
This introduces Financial NFTs (fNFTs). Unique financial contracts abound.
Examples:
a person's collection of assets (unique portfolio)
A loan contract that has been partially repaid with a lender
temporal tokens (ex: veCRV)

Legal Agreements
Not just financial contracts.
NFT can represent any legal contract or document.

Messages & Emails
What about other agreements? Verbal agreements through emails and messages are likewise unique, but they're easily lost and fabricated.

Health Records
Medical records or prescriptions are another types of documentation that has to be verified but isn't.
Medical NFT examples:
Immunization records
Covid test outcomes
Prescriptions
health issues that may affect one's identity
Observations made via health sensors
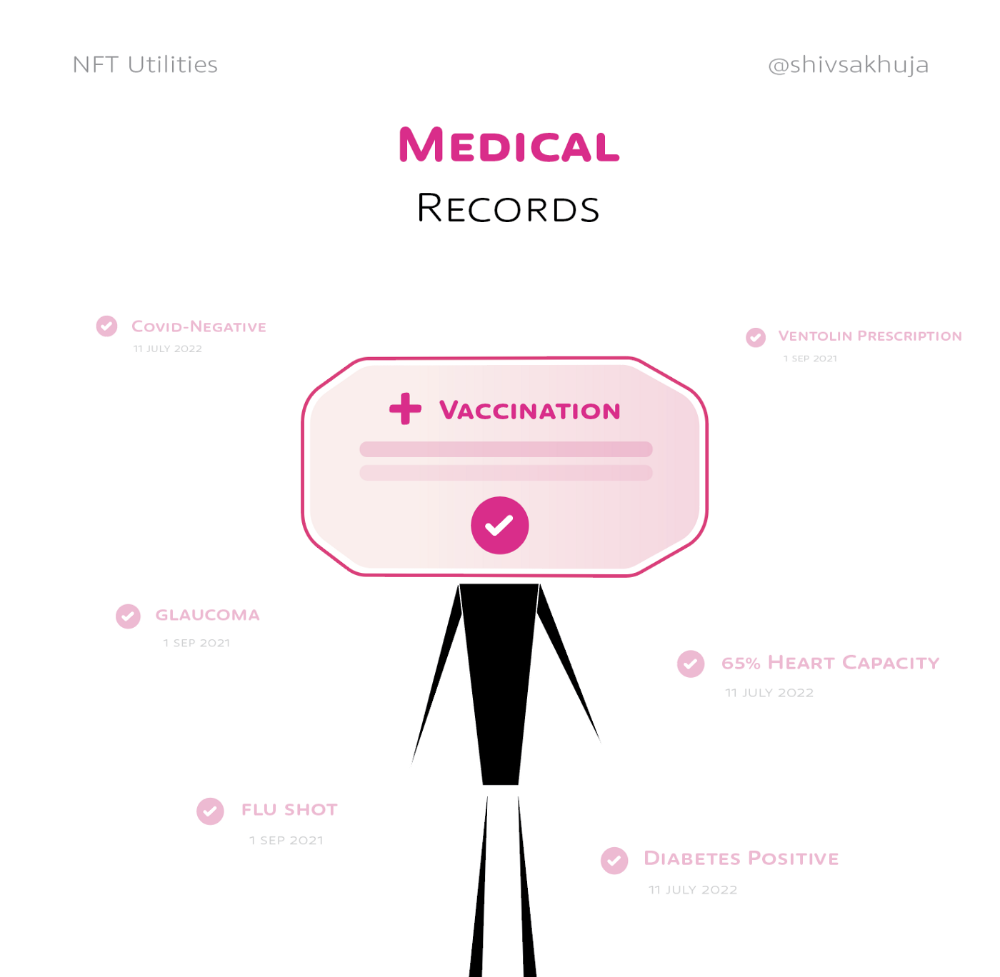
Existing systems of proof by paper / PDF have photoshop-risk.
I tried to include most use scenarios, but this is just the beginning.
NFTs have many innovative uses.
For example: @ShaanVP minted an NFT called “5 Minutes of Fame” 👇
Here are 2 Twitter threads about NFTs:
This piece of gold by @chriscantino
2. This conversation between @punk6529 and @RaoulGMI on @RealVision“The World According to @punk6529”
If you're wondering why NFTs are better than web2 databases for these use scenarios, see this Twitter thread I wrote:
If you liked this, please share it.

Justin Kuepper
3 years ago
Day Trading Introduction
Historically, only large financial institutions, brokerages, and trading houses could actively trade in the stock market. With instant global news dissemination and low commissions, developments such as discount brokerages and online trading have leveled the playing—or should we say trading—field. It's never been easier for retail investors to trade like pros thanks to trading platforms like Robinhood and zero commissions.
Day trading is a lucrative career (as long as you do it properly). But it can be difficult for newbies, especially if they aren't fully prepared with a strategy. Even the most experienced day traders can lose money.
So, how does day trading work?
Day Trading Basics
Day trading is the practice of buying and selling a security on the same trading day. It occurs in all markets, but is most common in forex and stock markets. Day traders are typically well educated and well funded. For small price movements in highly liquid stocks or currencies, they use leverage and short-term trading strategies.
Day traders are tuned into short-term market events. News trading is a popular strategy. Scheduled announcements like economic data, corporate earnings, or interest rates are influenced by market psychology. Markets react when expectations are not met or exceeded, usually with large moves, which can help day traders.
Intraday trading strategies abound. Among these are:
- Scalping: This strategy seeks to profit from minor price changes throughout the day.
- Range trading: To determine buy and sell levels, range traders use support and resistance levels.
- News-based trading exploits the increased volatility around news events.
- High-frequency trading (HFT): The use of sophisticated algorithms to exploit small or short-term market inefficiencies.
A Disputed Practice
Day trading's profit potential is often debated on Wall Street. Scammers have enticed novices by promising huge returns in a short time. Sadly, the notion that trading is a get-rich-quick scheme persists. Some daytrade without knowledge. But some day traders succeed despite—or perhaps because of—the risks.
Day trading is frowned upon by many professional money managers. They claim that the reward rarely outweighs the risk. Those who day trade, however, claim there are profits to be made. Profitable day trading is possible, but it is risky and requires considerable skill. Moreover, economists and financial professionals agree that active trading strategies tend to underperform passive index strategies over time, especially when fees and taxes are factored in.
Day trading is not for everyone and is risky. It also requires a thorough understanding of how markets work and various short-term profit strategies. Though day traders' success stories often get a lot of media attention, keep in mind that most day traders are not wealthy: Many will fail, while others will barely survive. Also, while skill is important, bad luck can sink even the most experienced day trader.
Characteristics of a Day Trader
Experts in the field are typically well-established professional day traders.
They usually have extensive market knowledge. Here are some prerequisites for successful day trading.
Market knowledge and experience
Those who try to day-trade without understanding market fundamentals frequently lose. Day traders should be able to perform technical analysis and read charts. Charts can be misleading if not fully understood. Do your homework and know the ins and outs of the products you trade.
Enough capital
Day traders only use risk capital they can lose. This not only saves them money but also helps them trade without emotion. To profit from intraday price movements, a lot of capital is often required. Most day traders use high levels of leverage in margin accounts, and volatile market swings can trigger large margin calls on short notice.
Strategy
A trader needs a competitive advantage. Swing trading, arbitrage, and trading news are all common day trading strategies. They tweak these strategies until they consistently profit and limit losses.
Strategy Breakdown:
Type | Risk | Reward
Swing Trading | High | High
Arbitrage | Low | Medium
Trading News | Medium | Medium
Mergers/Acquisitions | Medium | High
Discipline
A profitable strategy is useless without discipline. Many day traders lose money because they don't meet their own criteria. “Plan the trade and trade the plan,” they say. Success requires discipline.
Day traders profit from market volatility. For a day trader, a stock's daily movement is appealing. This could be due to an earnings report, investor sentiment, or even general economic or company news.
Day traders also prefer highly liquid stocks because they can change positions without affecting the stock's price. Traders may buy a stock if the price rises. If the price falls, a trader may decide to sell short to profit.
A day trader wants to trade a stock that moves (a lot).
Day Trading for a Living
Professional day traders can be self-employed or employed by a larger institution.
Most day traders work for large firms like hedge funds and banks' proprietary trading desks. These traders benefit from direct counterparty lines, a trading desk, large capital and leverage, and expensive analytical software (among other advantages). By taking advantage of arbitrage and news events, these traders can profit from less risky day trades before individual traders react.
Individual traders often manage other people’s money or simply trade with their own. They rarely have access to a trading desk, but they frequently have strong ties to a brokerage (due to high commissions) and other resources. However, their limited scope prevents them from directly competing with institutional day traders. Not to mention more risks. Individuals typically day trade highly liquid stocks using technical analysis and swing trades, with some leverage.
Day trading necessitates access to some of the most complex financial products and services. Day traders usually need:
Access to a trading desk
Traders who work for large institutions or manage large sums of money usually use this. The trading or dealing desk provides these traders with immediate order execution, which is critical during volatile market conditions. For example, when an acquisition is announced, day traders interested in merger arbitrage can place orders before the rest of the market.
News sources
The majority of day trading opportunities come from news, so being the first to know when something significant happens is critical. It has access to multiple leading newswires, constant news coverage, and software that continuously analyzes news sources for important stories.
Analytical tools
Most day traders rely on expensive trading software. Technical traders and swing traders rely on software more than news. This software's features include:
-
Automatic pattern recognition: It can identify technical indicators like flags and channels, or more complex indicators like Elliott Wave patterns.
-
Genetic and neural applications: These programs use neural networks and genetic algorithms to improve trading systems and make more accurate price predictions.
-
Broker integration: Some of these apps even connect directly to the brokerage, allowing for instant and even automatic trade execution. This reduces trading emotion and improves execution times.
-
Backtesting: This allows traders to look at past performance of a strategy to predict future performance. Remember that past results do not always predict future results.
Together, these tools give traders a competitive advantage. It's easy to see why inexperienced traders lose money without them. A day trader's earnings potential is also affected by the market in which they trade, their capital, and their time commitment.
Day Trading Risks
Day trading can be intimidating for the average investor due to the numerous risks involved. The SEC highlights the following risks of day trading:
Because day traders typically lose money in their first months of trading and many never make profits, they should only risk money they can afford to lose.
Trading is a full-time job that is stressful and costly: Observing dozens of ticker quotes and price fluctuations to spot market trends requires intense concentration. Day traders also spend a lot on commissions, training, and computers.
Day traders heavily rely on borrowing: Day-trading strategies rely on borrowed funds to make profits, which is why many day traders lose everything and end up in debt.
Avoid easy profit promises: Avoid “hot tips” and “expert advice” from day trading newsletters and websites, and be wary of day trading educational seminars and classes.
Should You Day Trade?
As stated previously, day trading as a career can be difficult and demanding.
- First, you must be familiar with the trading world and know your risk tolerance, capital, and goals.
- Day trading also takes a lot of time. You'll need to put in a lot of time if you want to perfect your strategies and make money. Part-time or whenever isn't going to cut it. You must be fully committed.
- If you decide trading is for you, remember to start small. Concentrate on a few stocks rather than jumping into the market blindly. Enlarging your trading strategy can result in big losses.
- Finally, keep your cool and avoid trading emotionally. The more you can do that, the better. Keeping a level head allows you to stay focused and on track.
If you follow these simple rules, you may be on your way to a successful day trading career.
Is Day Trading Illegal?
Day trading is not illegal or unethical, but it is risky. Because most day-trading strategies use margin accounts, day traders risk losing more than they invest and becoming heavily in debt.
How Can Arbitrage Be Used in Day Trading?
Arbitrage is the simultaneous purchase and sale of a security in multiple markets to profit from small price differences. Because arbitrage ensures that any deviation in an asset's price from its fair value is quickly corrected, arbitrage opportunities are rare.
Why Don’t Day Traders Hold Positions Overnight?
Day traders rarely hold overnight positions for several reasons: Overnight trades require more capital because most brokers require higher margin; stocks can gap up or down on overnight news, causing big trading losses; and holding a losing position overnight in the hope of recovering some or all of the losses may be against the trader's core day-trading philosophy.
What Are Day Trader Margin Requirements?
Regulation D requires that a pattern day trader client of a broker-dealer maintain at all times $25,000 in equity in their account.
How Much Buying Power Does Day Trading Have?
Buying power is the total amount of funds an investor has available to trade securities. FINRA rules allow a pattern day trader to trade up to four times their maintenance margin excess as of the previous day's close.
The Verdict
Although controversial, day trading can be a profitable strategy. Day traders, both institutional and retail, keep the markets efficient and liquid. Though day trading is still popular among novice traders, it should be left to those with the necessary skills and resources.