








More on Current Events

Steve QJ
4 years ago
Putin's War On Reality
The dictator's playbook.
Stalin's successor, Nikita Khrushchev, delivered a speech titled "On The Cult Of Personality And Its Consequences" in 1956, three years after Stalin’s death.
It was Stalin's grave abuse of power that caused untold harm to our party.
Stalin acted not by persuasion, explanation, or patient cooperation, but by imposing his ideas and demanding absolute obedience. […]
See where Stalin's mania for greatness led? He had lost all sense of reality.
The speech, which was never made public, shook the Soviet Union and the Soviet Bloc. After Stalin's "cult of personality" was exposed as a lie, only reality remained.
As I've watched the nightmare unfold in Ukraine, I'm reminded of that question. Primarily by Putin's repeated denials.
His odd claim that Ukraine is run by drug addicts and Nazis (especially strange given that Volodymyr Zelenskyy, the Ukrainian president, is Jewish). Others attempt to portray Russia as liberators rather than occupiers. For example, he portrays Luhansk and Donetsk as plucky, newly independent states when they have been totalitarian statelets for 8 years.
Putin seemed to have lost all sense of reality.
Maybe that's why his remarks to an oligarchs' gathering stood out:
Everything is a desperate measure. They gave us no choice. We couldn't do anything about their security risks. […] They could have put the country in jeopardy.
This is almost certainly true from Putin's perspective. Even for Putin, a military invasion seems unlikely. So, what exactly is putting Russia's security in jeopardy? How could Ukraine's independence endanger Russia's existence?
The truth is the only thing that truly terrifies leaders like these.
Trump, the president of “alternative facts,” "and “fake news” praised Putin's fabricated justifications for the Ukraine invasion. Russia tightened news censorship as news of their losses came in. It's no accident that modern dictatorships like Russia (and China and North Korea) restrict citizens' access to information.
Controlling what people see, hear, and think is the simplest method. And Ukraine's recent efforts to join the European Union showed a country whose thoughts Putin couldn't control. With the Russian and Ukrainian peoples so close, he could not control their reality.
He appears to think this is a threat worth fighting NATO over.
It's easy to disown history's great dictators. By the magnitude of their harm. But the strategy they used is still in use today, albeit not to the same devastating effect.
The Kim dynasty in North Korea has ruled for 74 years, Putin has ruled Russia for 19 years (using loopholes and even rewriting the constitution).
“Politicians and diapers must be changed frequently,” said Mark Twain. "And for the same reason.”
When their egos are threatened, they sabre-rattle, as in Kim Jong-un and Donald Trump's famous spat about the size of their...ahem, “nuclear buttons”." Or Putin's threats of mutual destruction this weekend.
Most importantly, they have cult-like control over their followers.
When a leader whose power is built on lies feels he is losing control of the narrative, things like Trump's Jan. 6 meltdown and Putin's current actions in Ukraine are unavoidable.
Leaders who try to control their people's reality will have to die to keep the illusion alive.
Long version of this post available here

B Kean
3 years ago
To prove his point, Putin is prepared to add 200,000 more dead soldiers.
What does Ukraine's murderous craziness mean?

Vladimir Putin expressed his patience to Israeli Prime Minister Naftali Bennet. Thousands, even hundreds of thousands of young and middle-aged males in his country have no meaning to him.
During a meeting in March with Prime Minister Naftali Bennett of Israel, Mr. Putin admitted that the Ukrainians were tougher “than I was told,” according to two people familiar with the exchange. “This will probably be much more difficult than we thought. But the war is on their territory, not ours. We are a big country and we have patience (The Inside Story of a Catastrophe).”
Putin should explain to Russian mothers how patient he is with his invasion of Ukraine.
Putin is rich. Even while sanctions have certainly limited Putin's access to his fortune, he has access to everything in Russia. Unlimited wealth.
The Russian leader's infrastructure was designed with his whims in mind. Vladimir Putin is one of the wealthiest and most catered-to people alive. He's also all-powerful, as his lack of opposition shows. His incredible wealth and power have isolated him from average people so much that he doesn't mind turning lives upside down to prove a point.
For many, losing a Russian spouse or son is painful. Whether the soldier was a big breadwinner or unemployed, the loss of a male figure leaves many families bewildered and anxious. Putin, Russia's revered president, seems unfazed.
People who know Mr. Putin say he is ready to sacrifice untold lives and treasure for as long as it takes, and in a rare face-to-face meeting with the Americans last month the Russians wanted to deliver a stark message to President Biden: No matter how many Russian soldiers are killed or wounded on the battlefield, Russia will not give up (The Inside Story of a Catastrophe).
Imagine a country's leader publicly admitting a mistake he's made. Imagine getting Putin's undivided attention.
So, I underestimated Ukrainians. I can't allow them make me appear terrible, so I'll utilize as many drunken dopes as possible to cover up my error. They'll die fulfilled and heroic.
Russia's human resources are limited, but its willingness to cause suffering is not. How many Russian families must die before the curse is broken? If mass protests started tomorrow, Russia's authorities couldn't stop them.
When Moscovites faced down tanks in August 1991, the Gorbachev coup ended in three days. Even though few city residents showed up, everything collapsed. This wicked disaster won't require many Russians.
One NATO member is warning allies that Mr. Putin is ready to accept the deaths or injuries of as many as 300,000 Russian troops — roughly three times his estimated losses so far.
If 100,000 Russians have died in Ukraine and Putin doesn't mind another 200,000 dying, why don't these 200,000 ghosts stand up and save themselves? Putin plays the role of concerned and benevolent leader effectively, but things aren't going well for Russia.
What would 300,000 or more missing men signify for Russia's future? How many kids will have broken homes? How many families won't form, and what will the economy do?
Putin reportedly cared about his legacy. His place in Russian history Putin's invasion of Ukraine settled his legacy. He has single-handedly weakened and despaired Russia since the 1980s.
Putin will be viewed by sensible people as one of Russia's worst adversaries, but Russians will think he was fantastic despite Ukraine.
The more setbacks Mr. Putin endures on the battlefield, the more fears grow over how far he is willing to go. He has killed tens of thousands in Ukraine, leveled cities, and targeted civilians for maximum pain — obliterating hospitals, schools, and apartment buildings while cutting off power and water to millions before winter. Each time Ukrainian forces score a major blow against Russia, the bombing of their country intensifies. And Mr. Putin has repeatedly reminded the world that he can use anything at his disposal, including nuclear arms, to pursue his notion of victory.
How much death and damage will there be in Ukraine if Putin sends 200,000 more Russians to the front? It's scary, sad, and sick.
Monster.

Isaiah McCall
3 years ago
There is a new global currency emerging, but it is not bitcoin.
America should avoid BRICS

Vladimir Putin has watched videos of Muammar Gaddafi's CIA-backed demise.
Gaddafi...
Thief.
Did you know Gaddafi wanted a gold-backed dinar for Africa? Because he considered our global financial system was a Ponzi scheme, he wanted to discontinue trading oil in US dollars.
Or, Gaddafi's Libya enjoyed Africa's highest quality of living before becoming freed. Pictured:

Vladimir Putin is a nasty guy, but he had his reasons for not mentioning NATO assisting Ukraine in resisting US imperialism. Nobody tells you. Sure.
The US dollar's corruption post-2008, debasement by quantitative easing, and lack of value are key factors. BRICS will replace the dollar.
BRICS aren't bricks.
Economy-related.
Brazil, Russia, India, China, and South Africa have cooperated for 14 years to fight U.S. hegemony with a new international currency: BRICS.
BRICS is mostly comical. Now. Saudi Arabia, the second-largest oil hegemon, wants to join.
So what?
The New World Currency is BRICS
Russia was kicked out of G8 for its aggressiveness in Crimea in 2014.
It's now G7.
No biggie, said Putin, he said, and I quote, “Bon appetite.”
He was prepared. China, India, and Brazil lead the New World Order.
Together, they constitute 40% of the world's population and, according to the IMF, 50% of the world's GDP by 2030.
Here’s what the BRICS president Marcos Prado Troyjo had to say earlier this year about no longer needing the US dollar: “We have implemented the mechanism of mutual settlements in rubles and rupees, and there is no need for our countries to use the dollar in mutual settlements. And today a similar mechanism of mutual settlements in rubles and yuan is being developed by China.”
Ick. That's D.C. and NYC warmongers licking their chops for WW3 nasty.
Here's a lovely picture of BRICS to relax you:

If Saudi Arabia joins BRICS, as President Mohammed Bin Salman has expressed interest, a majority of the Middle East will have joined forces to construct a new world order not based on the US currency.
I'm not sure of the new acronym.
SBRICSS? CIRBSS? CRIBSS?
The Reason America Is Harvesting What It Sowed
BRICS began 14 years ago.
14 years ago, what occurred? Concentrate. It involved CDOs, bad subprime mortgages, and Wall Street quants crunching numbers.
2008 recession
When two nations trade, they do so in US dollars, not Euros or gold.
What happened when 2008, an avoidable crisis caused by US banks' cupidity and ignorance, what happened?
Everyone WORLDWIDE felt the pain.
Mostly due to corporate America's avarice.
This should have been a warning that China and Russia had enough of our bs. Like when France sent a battleship to America after Nixon scrapped the gold standard. The US was warned to shape up or be dethroned (or at least try).

Nixon improved in 1971. Kinda. Invented PetroDollar.
Another BS system that unfairly favors America and possibly pushed Russia, China, and Saudi Arabia into BRICS.
The PetroDollar forces oil-exporting nations to trade in US dollars and invest in US Treasury bonds. Brilliant. Genius evil.
Our misdeeds are:
In conflicts that are not its concern, the USA uses the global reserve currency as a weapon.
Targeted nations abandon the dollar, and rightfully so, as do nations that depend on them for trade in vital resources.
The dollar's position as the world's reserve currency is in jeopardy, which could have disastrous economic effects.
Although we have actually sown our own doom, we appear astonished. According to the Bible, whomever sows to appease his sinful nature will reap destruction from that nature whereas whoever sows to appease the Spirit will reap eternal life from the Spirit.
Americans, even our leaders, lack caution and delayed pleasure. When our unsustainable systems fail, we double down. Bailouts of the banks in 2008 were myopic, puerile, and another nail in America's hegemony.
America has screwed everyone.
We're unpopular.
The BRICS's future
It's happened before.
Saddam Hussein sold oil in Euros in 2000, and the US invaded Iraq a month later. The media has devalued the word conspiracy. The Iraq conspiracy.
There were no WMDs, but NYT journalists like Judy Miller drove Americans into a warmongering frenzy because Saddam would ruin the PetroDollar. Does anyone recall that this war spawned ISIS?
I think America has done good for the world. You can make a convincing case that we're many people's villain.
Learn more in Confessions of an Economic Hitman, The Devil's Chessboard, or Tyranny of the Federal Reserve. Or ignore it. That's easier.
We, America, should extend an olive branch, ask for forgiveness, and learn from our faults, as the Tao Te Ching advises. Unlikely. Our population is apathetic and stupid, and our government is corrupt.
Argentina, Iran, Egypt, and Turkey have also indicated interest in joining BRICS. They're also considering making it gold-backed, making it a new world reserve currency.
You should pay attention.
Thanks for reading!
You might also like

Web3Lunch
3 years ago
An employee of OpenSea might get a 40-year prison sentence for insider trading using NFTs.

The space had better days. Those greenish spikes...oh wow, haven't felt that in ages. Cryptocurrencies and NFTs have lost popularity. Google agrees. Both are declining.
As seen below, crypto interest spiked in May because of the Luna fall. NFT interest is similar to early October last year.
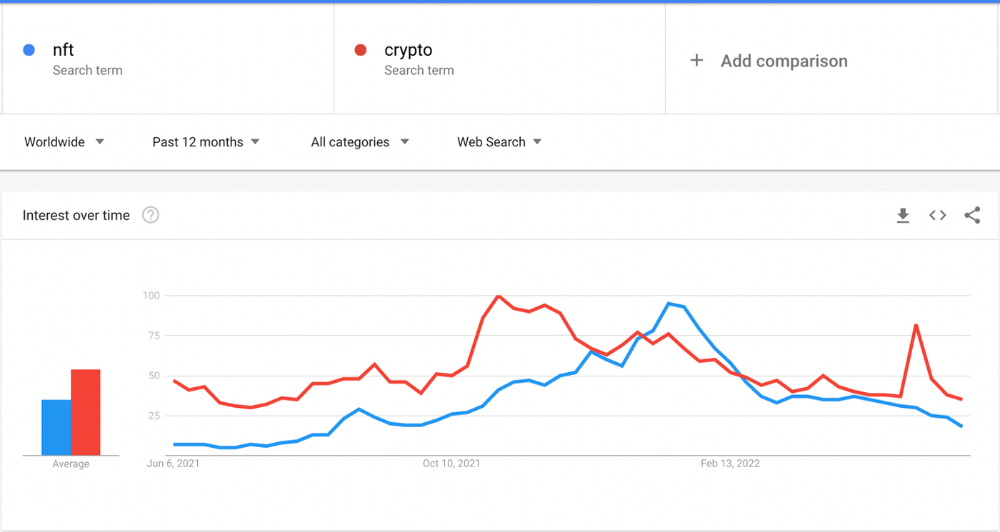
This makes me think NFTs are mostly hype and FOMO. No art or community. I've seen enough initiatives to know that communities stick around if they're profitable. Once it starts falling, they move on to the next project. The space has no long-term investments. Flip everything.
OpenSea trading volume has stayed steady for months. May's volume is 1.8 million ETH ($3.3 billion).
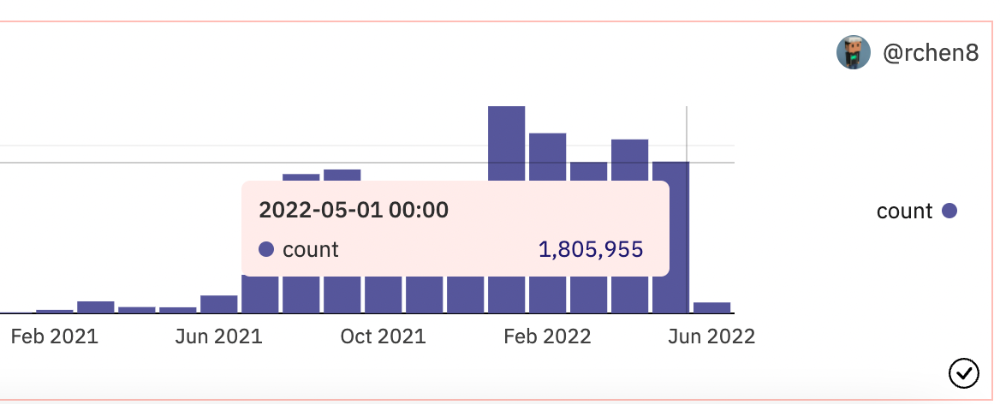
Despite this, I think NFTs and crypto will stick around. In bad markets, builders gain most.
Only 4k developers are active on Ethereum blockchain. It's low. A great chance for the space enthusiasts.
An employee of OpenSea might get a 40-year prison sentence for insider trading using NFTs.
Nathaniel Chastian, an OpenSea employee, traded on insider knowledge. He'll serve 40 years for that.
Here's what happened if you're unfamiliar.
OpenSea is a secondary NFT marketplace. Their homepage featured remarkable drops. Whatever gets featured there, NFT prices will rise 5x.
Chastian was at OpenSea. He chose forthcoming NFTs for OpenSeas' webpage.
Using anonymous digital currency wallets and OpenSea accounts, he would buy NFTs before promoting them on the homepage, showcase them, and then sell them for at least 25 times the price he paid.
From June through September 2021, this happened. Later caught, fired. He's charged with wire fraud and money laundering, each carrying a 20-year maximum penalty.
Although web3 space is all about decentralization, a step like this is welcomed since it restores faith in the area. We hope to see more similar examples soon.
Here's the press release.

Understanding smart contracts
@cantino.eth has a Twitter thread on smart contracts. Must-read. Also, he appears educated about the space, so follow him.


Nick Nolan
3 years ago
In five years, starting a business won't be hip.

People are slowly recognizing entrepreneurship's downside.
Growing up, entrepreneurship wasn't common. High school class of 2012 had no entrepreneurs.
Businesses were different.
They had staff and a lengthy history of achievement.
I never wanted a business. It felt unattainable. My friends didn't care.
Weird.
People desired degrees to attain good jobs at big companies.
When graduated high school:
9 out of 10 people attend college
Earn minimum wage (7%) working in a restaurant or retail establishment
Or join the military (3%)
Later, entrepreneurship became a thing.
2014-ish
I was in the military and most of my high school friends were in college, so I didn't hear anything.
Entrepreneurship soared in 2015, according to Google Trends.
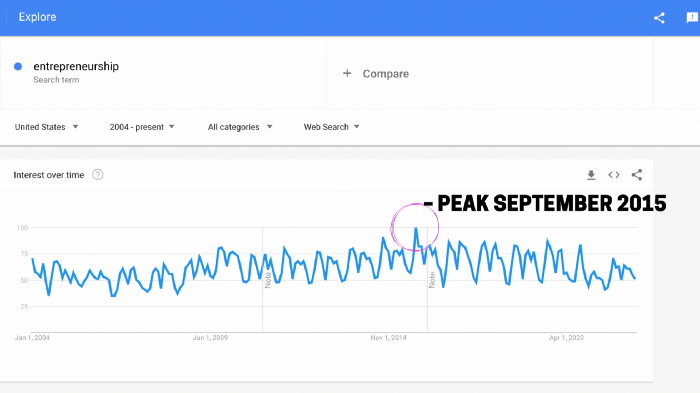
Then more individuals were interested. Entrepreneurship went from unusual to cool.
In 2015, it was easier than ever to build a website, run Facebook advertisements, and achieve organic social media reach.
There were several online business tools.
You didn't need to spend years or money figuring it out. Most entry barriers were gone.
Everyone wanted a side gig to escape the 95.
Small company applications have increased during the previous 10 years.
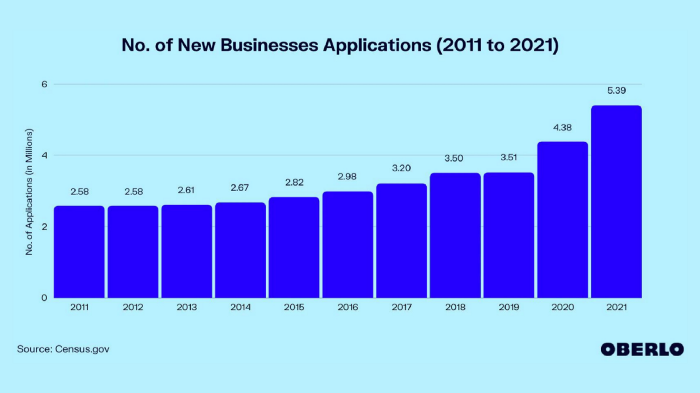
2011-2014 trend continues.
2015 adds 150,000 applications. 2016 adds 200,000. Plus 300,000 in 2017.
The graph makes it look little, but that's a considerable annual spike with no indications of stopping.
By 2021, new business apps had doubled.
Entrepreneurship will return to its early 2010s level.
I think we'll go backward in 5 years.
Entrepreneurship is half as popular as it was in 2015.
In the late 2020s and 30s, entrepreneurship will again be obscure.
Entrepreneurship's decade-long splendor is fading. People will cease escaping 9-5 and launch fewer companies.
That’s not a bad thing.
I think people have a rose-colored vision of entrepreneurship. It's fashionable. People feel that they're missing out if they're not entrepreneurial.
Reality is showing up.
People say on social media, "I knew starting a business would be hard, but not this hard."
More negative posts on entrepreneurship:

Luke adds:
Is being an entrepreneur ‘healthy’? I don’t really think so. Many like Gary V, are not role models for a well-balanced life. Despite what feel-good LinkedIn tells you the odds are against you as an entrepreneur. You have to work your face off. It’s a tough but rewarding lifestyle. So maybe let’s stop glorifying it because it takes a lot of (bleepin) work to survive a pandemic, mental health battles, and a competitive market.
Entrepreneurship is no longer a pipe dream.
It’s hard.
I went full-time in March 2020. I was done by April 2021. I had a good-paying job with perks.
When that fell through (on my start date), I had to continue my entrepreneurial path. I needed money by May 1 to pay rent.
Entrepreneurship isn't as great as many think.
Entrepreneurship is a serious business.
If you have a 9-5, the grass isn't greener here. Most people aren't telling the whole story when they post on social media or quote successful entrepreneurs.
People prefer to communicate their victories than their defeats.
Is this a bad thing?
I don’t think so.
Over the previous decade, entrepreneurship went from impossible to the finest thing ever.
It peaked in 2020-21 and is returning to reality.
Startups aren't for everyone.
If you like your job, don't quit.
Entrepreneurship won't amaze people if you quit your job.
It's irrelevant.
You're doomed.
And you'll probably make less money.
If you hate your job, quit. Change jobs and bosses. Changing jobs could net you a greater pay or better perks.
When you go solo, your paycheck and perks vanish. Did I mention you'll fail, sleep less, and stress more?
Nobody will stop you from pursuing entrepreneurship. You'll face several challenges.
Possibly.
Entrepreneurship may be romanticized for years.
Based on what I see from entrepreneurs on social media and trends, entrepreneurship is challenging and few will succeed.

Logan Rane
3 years ago
I questioned Chat-GPT for advice on the top nonfiction books. Here's What It Suggests
You have to use it.

Chat-GPT is a revolution.
All social media outlets are discussing it. How it will impact the future and different things.
True.
I've been using Chat-GPT for a few days, and it's a rare revolution. It's amazing and will only improve.
I asked Chat-GPT about the best non-fiction books. It advised this, albeit results rely on interests.
The Immortal Life of Henrietta Lacks
by Rebecca Skloot
Science, Biography
A impoverished tobacco farmer dies of cervical cancer in The Immortal Life of Henrietta Lacks. Her cell strand helped scientists treat polio and other ailments.
Rebecca Skloot discovers about Henrietta, her family, how the medical business exploited black Americans, and how her cells can live forever in a fascinating and surprising research.
You ought to read it.
if you want to discover more about the past of medicine.
if you want to discover more about American history.
Bad Blood: Secrets and Lies in a Silicon Valley Startup
by John Carreyrou
Tech, Bio
Bad Blood tells the terrifying story of how a Silicon Valley tech startup's blood-testing device placed millions of lives at risk.
John Carreyrou, a Pulitzer Prize-winning journalist, wrote this book.
Theranos and its wunderkind CEO, Elizabeth Holmes, climbed to popularity swiftly and then plummeted.
You ought to read it.
if you are a start-up employee.
specialists in medicine.
The Power of Now: A Guide to Spiritual Enlightenment
by Eckhart Tolle
Self-improvement, Spirituality
The Power of Now shows how to stop suffering and attain inner peace by focusing on the now and ignoring your mind.
The book also helps you get rid of your ego, which tries to control your ideas and actions.
If you do this, you may embrace the present, reduce discomfort, strengthen relationships, and live a better life.
You ought to read it.
if you're looking for serenity and illumination.
If you believe that you are ruining your life, stop.
if you're not happy.
The 7 Habits of Highly Effective People
by Stephen R. Covey
Profession, Success
The 7 Habits of Highly Effective People is an iconic self-help book.
This vital book offers practical guidance for personal and professional success.
This non-fiction book is one of the most popular ever.
You ought to read it.
if you want to reach your full potential.
if you want to discover how to achieve all your objectives.
if you are just beginning your journey toward personal improvement.
Sapiens: A Brief History of Humankind
by Yuval Noah Harari
Science, History
Sapiens explains how our species has evolved from our earliest ancestors to the technology age.
How did we, a species of hairless apes without tails, come to control the whole planet?
It describes the shifts that propelled Homo sapiens to the top.
You ought to read it.
if you're interested in discovering our species' past.
if you want to discover more about the origins of human society and culture.