


The InSight lander from NASA has recorded the greatest tremor ever felt on Mars.
The magnitude 5 earthquake was responsible for the discharge of energy that was 10 times greater than the previous record holder.
Any Martians who happen to be reading this should quickly learn how to duck and cover.
NASA's Jet Propulsion Laboratory in Pasadena, California, reported that on May 4, the planet Mars was shaken by an earthquake of around magnitude 5, making it the greatest Marsquake ever detected to this point. The shaking persisted for more than six hours and unleashed more than ten times as much energy as the earthquake that had previously held the record for strongest.
The event was captured on record by the InSight lander, which is operated by the United States Space Agency and has been researching the innards of Mars ever since it touched down on the planet in 2018 (SN: 11/26/18). The epicenter of the earthquake was probably located in the vicinity of Cerberus Fossae, which is located more than 1,000 kilometers away from the lander.
The surface of Cerberus Fossae is notorious for being broken up and experiencing periodic rockfalls. According to geophysicist Philippe Lognonné, who is the lead investigator of the Seismic Experiment for Interior Structure, the seismometer that is onboard the InSight lander, it is reasonable to assume that the ground is moving in that area. "This is an old crater from a volcanic eruption."
Marsquakes, which are similar to earthquakes in that they give information about the interior structure of our planet, can be utilized to investigate what lies beneath the surface of Mars (SN: 7/22/21). And according to Lognonné, who works at the Institut de Physique du Globe in Paris, there is a great deal that can be gleaned from analyzing this massive earthquake. Because the quality of the signal is so high, we will be able to focus on the specifics.
More on Science
Daniel Clery
3 years ago
Twisted device investigates fusion alternatives
German stellarator revamped to run longer, hotter, compete with tokamaks

Tokamaks have dominated the search for fusion energy for decades. Just as ITER, the world's largest and most expensive tokamak, nears completion in southern France, a smaller, twistier testbed will start up in Germany.
If the 16-meter-wide stellarator can match or outperform similar-size tokamaks, fusion experts may rethink their future. Stellarators can keep their superhot gases stable enough to fuse nuclei and produce energy. They can theoretically run forever, but tokamaks must pause to reset their magnet coils.
The €1 billion German machine, Wendelstein 7-X (W7-X), is already getting "tokamak-like performance" in short runs, claims plasma physicist David Gates, preventing particles and heat from escaping the superhot gas. If W7-X can go long, "it will be ahead," he says. "Stellarators excel" Eindhoven University of Technology theorist Josefine Proll says, "Stellarators are back in the game." A few of startup companies, including one that Gates is leaving Princeton Plasma Physics Laboratory, are developing their own stellarators.
W7-X has been running at the Max Planck Institute for Plasma Physics (IPP) in Greifswald, Germany, since 2015, albeit only at low power and for brief runs. W7-X's developers took it down and replaced all inner walls and fittings with water-cooled equivalents, allowing for longer, hotter runs. The team reported at a W7-X board meeting last week that the revised plasma vessel has no leaks. It's expected to restart later this month to show if it can get plasma to fusion-igniting conditions.

Wendelstein 7-X's water-cooled inner surface allows for longer runs.
HOSAN/IPP
Both stellarators and tokamaks create magnetic gas cages hot enough to melt metal. Microwaves or particle beams heat. Extreme temperatures create a plasma, a seething mix of separated nuclei and electrons, and cause the nuclei to fuse, releasing energy. A fusion power plant would use deuterium and tritium, which react quickly. Non-energy-generating research machines like W7-X avoid tritium and use hydrogen or deuterium instead.
Tokamaks and stellarators use electromagnetic coils to create plasma-confining magnetic fields. A greater field near the hole causes plasma to drift to the reactor's wall.
Tokamaks control drift by circulating plasma around a ring. Streaming creates a magnetic field that twists and stabilizes ionized plasma. Stellarators employ magnetic coils to twist, not plasma. Once plasma physicists got powerful enough supercomputers, they could optimize stellarator magnets to improve plasma confinement.
W7-X is the first large, optimized stellarator with 50 6- ton superconducting coils. Its construction began in the mid-1990s and cost roughly twice the €550 million originally budgeted.
The wait hasn't disappointed researchers. W7-X director Thomas Klinger: "The machine operated immediately." "It's a friendly machine." It did everything we asked." Tokamaks are prone to "instabilities" (plasma bulging or wobbling) or strong "disruptions," sometimes associated to halted plasma flow. IPP theorist Sophia Henneberg believes stellarators don't employ plasma current, which "removes an entire branch" of instabilities.
In early stellarators, the magnetic field geometry drove slower particles to follow banana-shaped orbits until they collided with other particles and leaked energy. Gates believes W7-X's ability to suppress this effect implies its optimization works.
W7-X loses heat through different forms of turbulence, which push particles toward the wall. Theorists have only lately mastered simulating turbulence. W7-X's forthcoming campaign will test simulations and turbulence-fighting techniques.
A stellarator can run constantly, unlike a tokamak, which pulses. W7-X has run 100 seconds—long by tokamak standards—at low power. The device's uncooled microwave and particle heating systems only produced 11.5 megawatts. The update doubles heating power. High temperature, high plasma density, and extensive runs will test stellarators' fusion power potential. Klinger wants to heat ions to 50 million degrees Celsius for 100 seconds. That would make W7-X "a world-class machine," he argues. The team will push for 30 minutes. "We'll move step-by-step," he says.
W7-X's success has inspired VCs to finance entrepreneurs creating commercial stellarators. Startups must simplify magnet production.
Princeton Stellarators, created by Gates and colleagues this year, has $3 million to build a prototype reactor without W7-X's twisted magnet coils. Instead, it will use a mosaic of 1000 HTS square coils on the plasma vessel's outside. By adjusting each coil's magnetic field, operators can change the applied field's form. Gates: "It moves coil complexity to the control system." The company intends to construct a reactor that can fuse cheap, abundant deuterium to produce neutrons for radioisotopes. If successful, the company will build a reactor.
Renaissance Fusion, situated in Grenoble, France, raised €16 million and wants to coat plasma vessel segments in HTS. Using a laser, engineers will burn off superconductor tracks to carve magnet coils. They want to build a meter-long test segment in 2 years and a full prototype by 2027.
Type One Energy in Madison, Wisconsin, won DOE money to bend HTS cables for stellarator magnets. The business carved twisting grooves in metal with computer-controlled etching equipment to coil cables. David Anderson of the University of Wisconsin, Madison, claims advanced manufacturing technology enables the stellarator.
Anderson said W7-X's next phase will boost stellarator work. “Half-hour discharges are steady-state,” he says. “This is a big deal.”

DANIEL CLERY
3 years ago
Can space-based solar power solve Earth's energy problems?
Better technology and lower launch costs revive science-fiction tech.
Airbus engineers showed off sustainable energy's future in Munich last month. They captured sunlight with solar panels, turned it into microwaves, and beamed it into an airplane hangar, where it lighted a city model. The test delivered 2 kW across 36 meters, but it posed a serious question: Should we send enormous satellites to capture solar energy in space? In orbit, free of clouds and nighttime, they could create power 24/7 and send it to Earth.
Airbus engineer Jean-Dominique Coste calls it an engineering problem. “But it’s never been done at [large] scale.”
Proponents of space solar power say the demand for green energy, cheaper space access, and improved technology might change that. Once someone invests commercially, it will grow. Former NASA researcher John Mankins says it might be a trillion-dollar industry.
Myriad uncertainties remain, including whether beaming gigawatts of power to Earth can be done efficiently and without burning birds or people. Concept papers are being replaced with ground and space testing. The European Space Agency (ESA), which supported the Munich demo, will propose ground tests to member nations next month. The U.K. government offered £6 million to evaluate innovations this year. Chinese, Japanese, South Korean, and U.S. agencies are working. NASA policy analyst Nikolai Joseph, author of an upcoming assessment, thinks the conversation's tone has altered. What formerly appeared unattainable may now be a matter of "bringing it all together"
NASA studied space solar power during the mid-1970s fuel crunch. A projected space demonstration trip using 1970s technology would have cost $1 trillion. According to Mankins, the idea is taboo in the agency.
Space and solar power technology have evolved. Photovoltaic (PV) solar cell efficiency has increased 25% over the past decade, Jones claims. Telecoms use microwave transmitters and receivers. Robots designed to repair and refuel spacecraft might create solar panels.
Falling launch costs have boosted the idea. A solar power satellite large enough to replace a nuclear or coal plant would require hundreds of launches. ESA scientist Sanjay Vijendran: "It would require a massive construction complex in orbit."
SpaceX has made the idea more plausible. A SpaceX Falcon 9 rocket costs $2600 per kilogram, less than 5% of what the Space Shuttle did, and the company promised $10 per kilogram for its giant Starship, slated to launch this year. Jones: "It changes the equation." "Economics rules"
Mass production reduces space hardware costs. Satellites are one-offs made with pricey space-rated parts. Mars rover Perseverance cost $2 million per kilogram. SpaceX's Starlink satellites cost less than $1000 per kilogram. This strategy may work for massive space buildings consisting of many identical low-cost components, Mankins has long contended. Low-cost launches and "hypermodularity" make space solar power economical, he claims.
Better engineering can improve economics. Coste says Airbus's Munich trial was 5% efficient, comparing solar input to electricity production. When the Sun shines, ground-based solar arrays perform better. Studies show space solar might compete with existing energy sources on price if it reaches 20% efficiency.
Lighter parts reduce costs. "Sandwich panels" with PV cells on one side, electronics in the middle, and a microwave transmitter on the other could help. Thousands of them build a solar satellite without heavy wiring to move power. In 2020, a team from the U.S. Naval Research Laboratory (NRL) flew on the Air Force's X-37B space plane.
NRL project head Paul Jaffe said the satellite is still providing data. The panel converts solar power into microwaves at 8% efficiency, but not to Earth. The Air Force expects to test a beaming sandwich panel next year. MIT will launch its prototype panel with SpaceX in December.
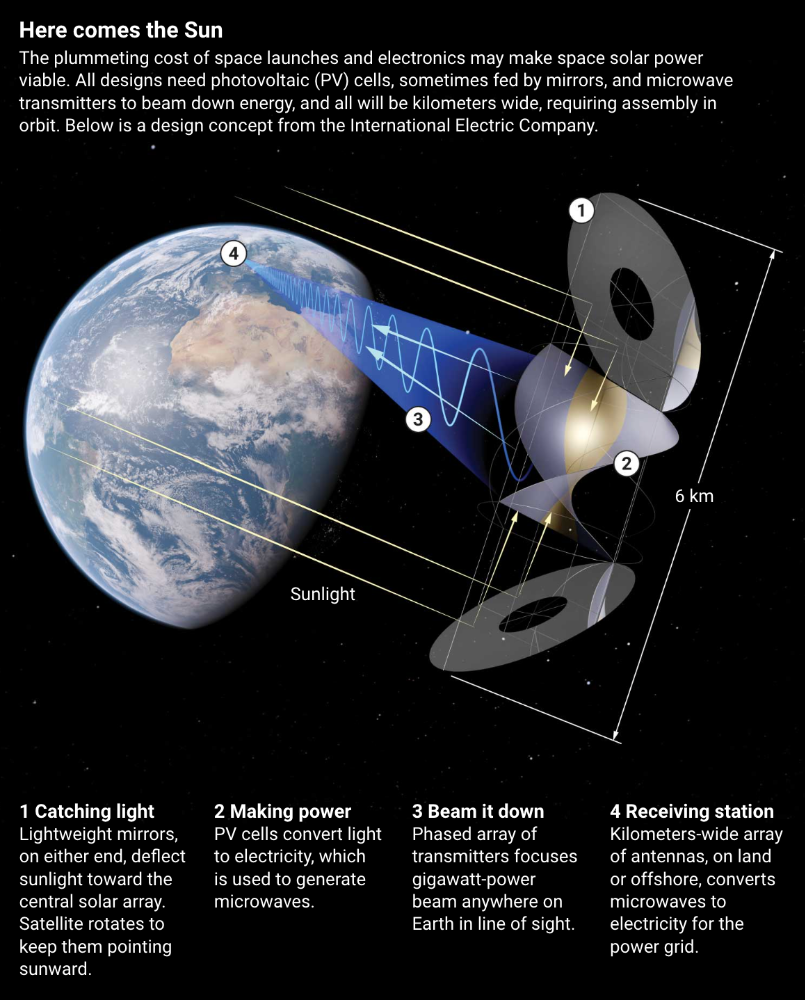
As a satellite orbits, the PV side of sandwich panels sometimes faces away from the Sun since the microwave side must always face Earth. To maintain 24-hour power, a satellite needs mirrors to keep that side illuminated and focus light on the PV. In a 2012 NASA study by Mankins, a bowl-shaped device with thousands of thin-film mirrors focuses light onto the PV array.
International Electric Company's Ian Cash has a new strategy. His proposed satellite uses enormous, fixed mirrors to redirect light onto a PV and microwave array while the structure spins (see graphic, above). 1 billion minuscule perpendicular antennas act as a "phased array" to electronically guide the beam toward Earth, regardless of the satellite's orientation. This design, argues Cash, is "the most competitive economically"
If a space-based power plant ever flies, its power must be delivered securely and efficiently. Jaffe's team at NRL just beamed 1.6 kW over 1 km, and teams in Japan, China, and South Korea have comparable attempts. Transmitters and receivers lose half their input power. Vijendran says space solar beaming needs 75% efficiency, "preferably 90%."
Beaming gigawatts through the atmosphere demands testing. Most designs aim to produce a beam kilometers wide so every ship, plane, human, or bird that strays into it only receives a tiny—hopefully harmless—portion of the 2-gigawatt transmission. Receiving antennas are cheap to build but require a lot of land, adds Jones. You could grow crops under them or place them offshore.
Europe's public agencies currently prioritize space solar power. Jones: "There's a devotion you don't see in the U.S." ESA commissioned two solar cost/benefit studies last year. Vijendran claims it might match ground-based renewables' cost. Even at a higher price, equivalent to nuclear, its 24/7 availability would make it competitive.
ESA will urge member states in November to fund a technical assessment. If the news is good, the agency will plan for 2025. With €15 billion to €20 billion, ESA may launch a megawatt-scale demonstration facility by 2030 and a gigawatt-scale facility by 2040. "Moonshot"

Tomas Pueyo
2 years ago
Soon, a Starship Will Transform Humanity
SpaceX's Starship.

Launched last week.
Four minutes in:
SpaceX will succeed. When it does, its massiveness will matter.
Its payload will revolutionize space economics.
Civilization will shift.
We don't yet understand how this will affect space and Earth culture. Grab it.
The Cost of Space Transportation Has Decreased Exponentially
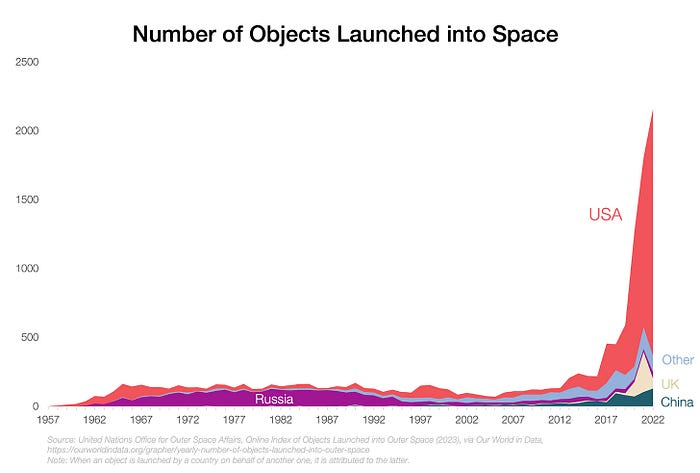
Space launches have increased dramatically in recent years.
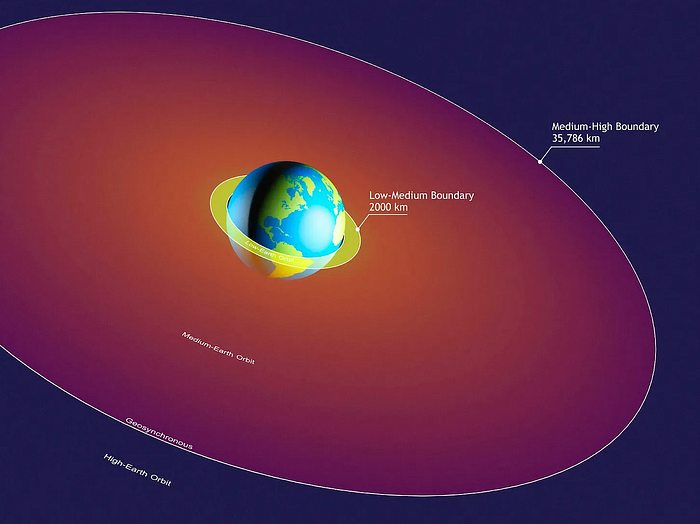
We mostly send items to LEO, the green area below:
SpaceX's reusable rockets can send these things to LEO. Each may launch dozens of payloads into space.
With all these launches, we're sending more than simply things to space. Volume and mass. Since the 1980s, launching a kilogram of payload to LEO has become cheaper:
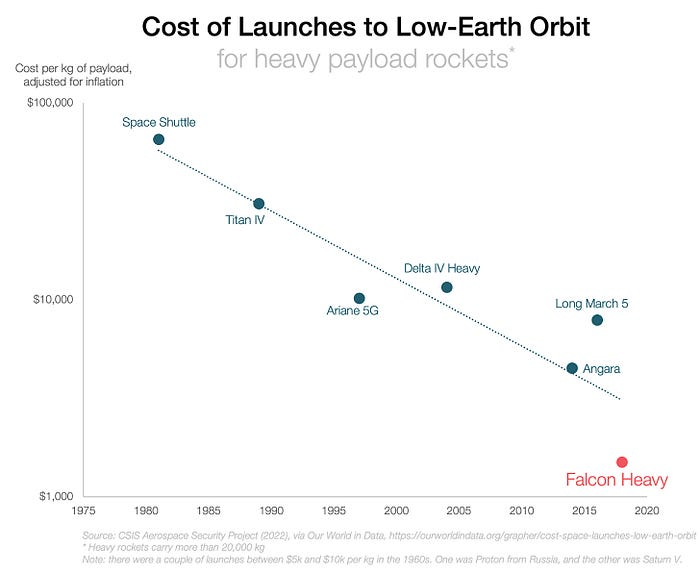
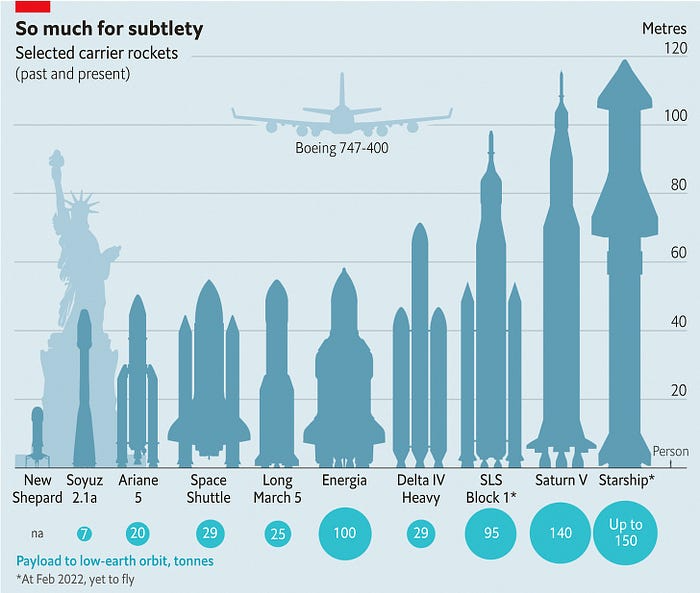
One kilogram in a large rocket cost over $75,000 in the 1980s. Carrying one astronaut cost nearly $5M! Falcon Heavy's $1,500/kg price is 50 times lower. SpaceX's larger, reusable rockets are amazing.
SpaceX's Starship rocket will continue. It can carry over 100 tons to LEO, 50% more than the current Falcon heavy. Thousands of launches per year. Elon Musk predicts Falcon Heavy's $1,500/kg cost will plummet to $100 in 23 years.
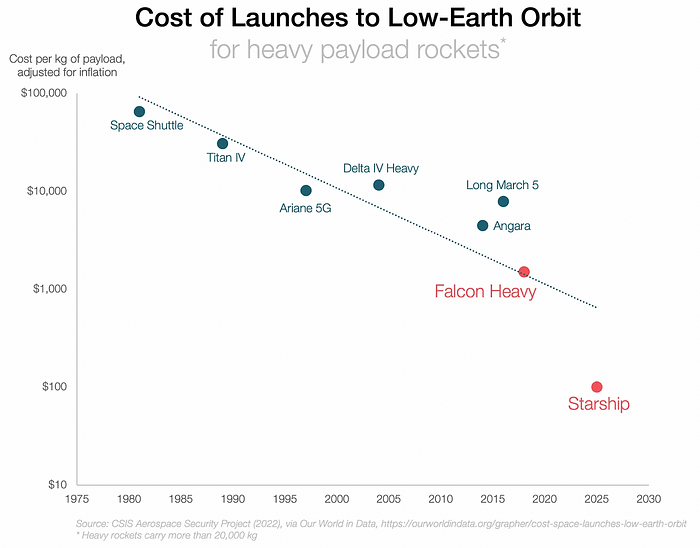
In context:
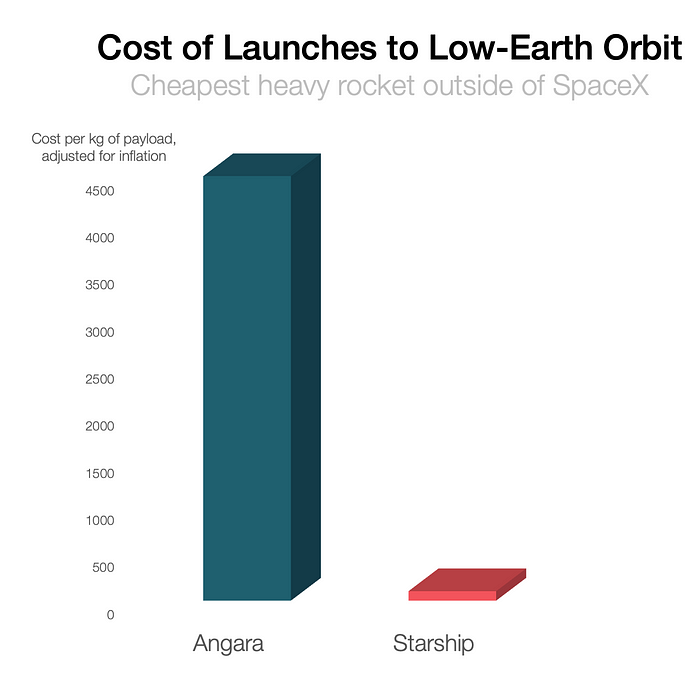
People underestimate this.
2. The Benefits of Affordable Transportation
Compare Earth's transportation costs:
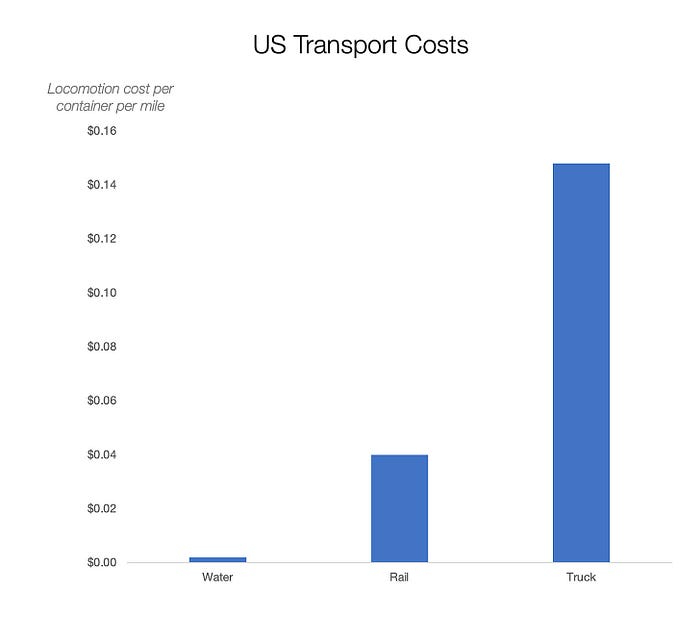
It's no surprise that the US and Northern Europe are the wealthiest and have the most navigable interior waterways.
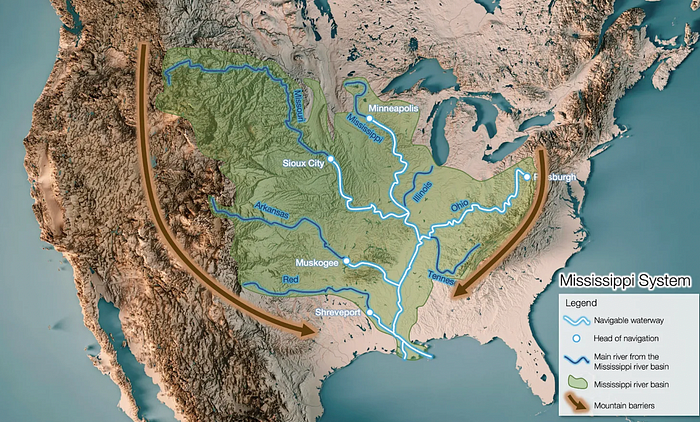
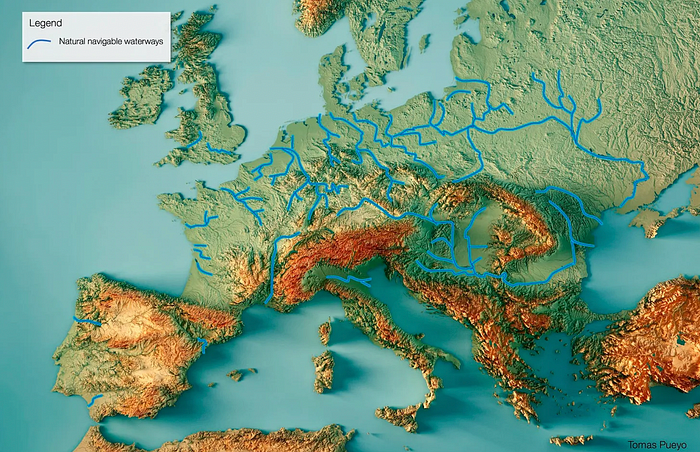
So what? since sea transportation is cheaper than land. Inland waterways are even better than sea transportation since weather is less of an issue, currents can be controlled, and rivers serve two banks instead of one for coastal transportation.
In France, because population density follows river systems, rivers are valuable. Cheap transportation brought people and money to rivers, especially their confluences.
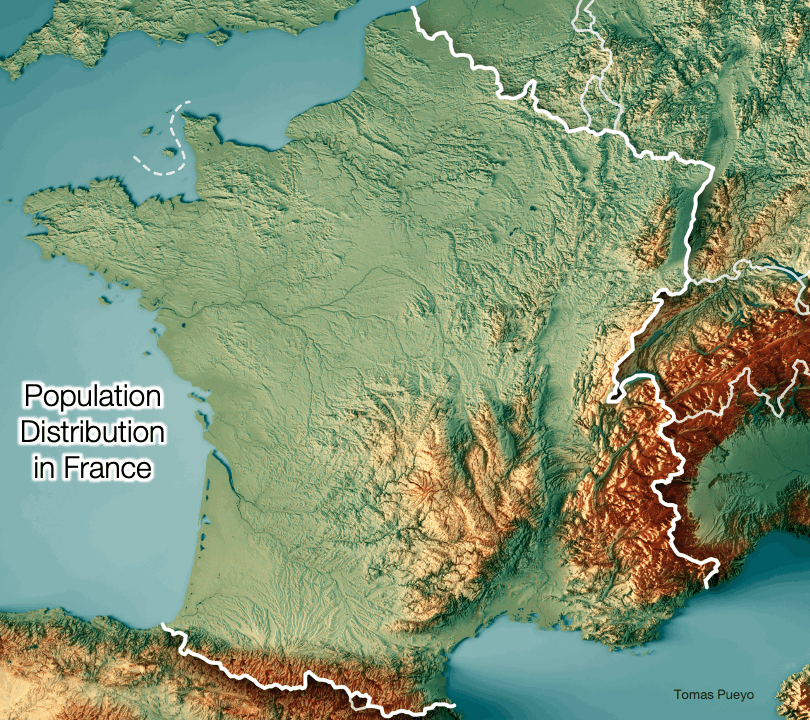
How come? Why were humans surrounding rivers?
Imagine selling meat for $10 per kilogram. Transporting one kg one kilometer costs $1. Your margin decreases $1 each kilometer. You can only ship 10 kilometers. For example, you can only trade with four cities:
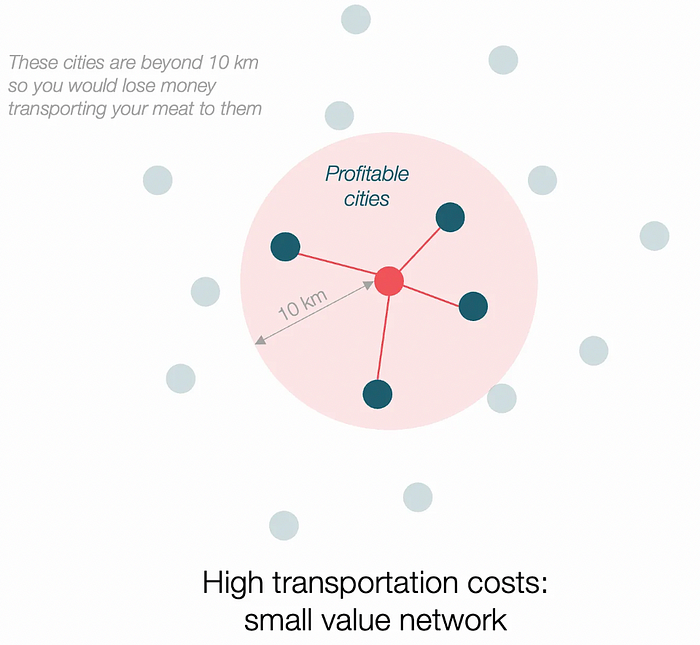
If instead, your cost of transportation is half, what happens? It costs you $0.5 per km. You now have higher margins with each city you traded with. More importantly, you can reach 20-km markets.
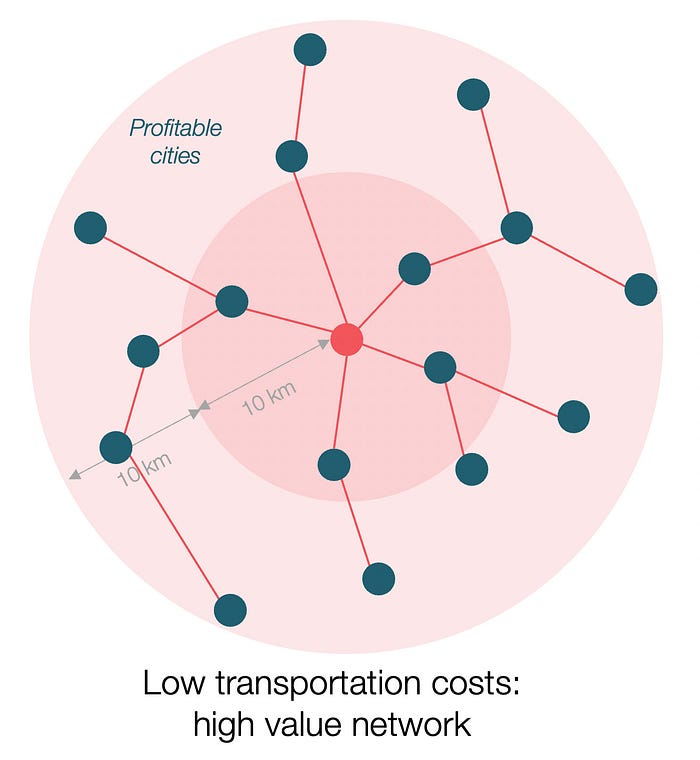
However, 2x distance 4x surface! You can now trade with sixteen cities instead of four! Metcalfe's law states that a network's value increases with its nodes squared. Since now sixteen cities can connect to yours. Each city now has sixteen connections! They get affluent and can afford more meat.
Rivers lower travel costs, connecting many cities, which can trade more, get wealthy, and buy more.
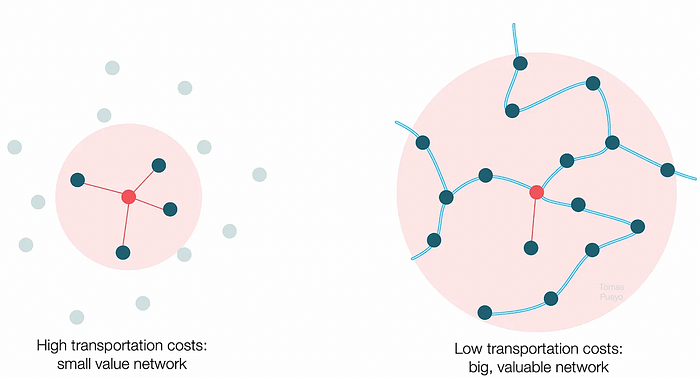
The right network is worth at least an order of magnitude more than the left! The cheaper the transport, the more trade at a lower cost, the more income generated, the more that wealth can be reinvested in better canals, bridges, and roads, and the wealth grows even more.
Throughout history. Rome was established around cheap Mediterranean transit and preoccupied with cutting overland transportation costs with their famous roadways. Communications restricted their empire.
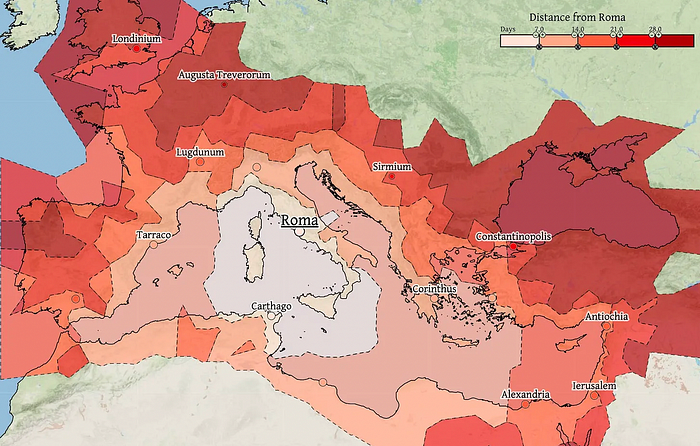
The Egyptians lived around the Nile, the Vikings around the North Sea, early Japan around the Seto Inland Sea, and China started canals in the 5th century BC.
Transportation costs shaped empires.Starship is lowering new-world transit expenses. What's possible?
3. Change Organizations, Change Companies, Change the World
Starship is a conveyor belt to LEO. A new world of opportunity opens up as transportation prices drop 100x in a decade.
Satellite engineers have spent decades shedding milligrams. Weight influenced every decision: pricing structure, volumes to be sent, material selections, power sources, thermal protection, guiding, navigation, and control software. Weight was everything in the mission. To pack as much science into every millimeter, NASA missions had to be miniaturized. Engineers were indoctrinated against mass.
No way.
Starship is not constrained by any space mission, robotic or crewed.
Starship obliterates the mass constraint and every last vestige of cultural baggage it has gouged into the minds of spacecraft designers. A dollar spent on mass optimization no longer buys a dollar saved on launch cost. It buys nothing. It is time to raise the scope of our ambition and think much bigger. — Casey Handmer, Starship is still not understood
A Tesla Roadster in space makes more sense.

It went beyond bad PR. It told the industry: Did you care about every microgram? No more. My rockets are big enough to send a Tesla without noticing. Industry watchers should have noticed.
Most didn’t. Artemis is a global mission to send astronauts to the Moon and build a base. Artemis uses disposable Space Launch System rockets. Instead of sending two or three dinky 10-ton crew habitats over the next decade, Starship might deliver 100x as much cargo and create a base for 1,000 astronauts in a year or two. Why not? Because Artemis remains in a pre-Starship paradigm where each kilogram costs a million dollars and we must aggressively descope our objective.

Space agencies can deliver 100x more payload to space for the same budget with 100x lower costs and 100x higher transportation volumes. How can space economy saturate this new supply?
Before Starship, NASA supplied heavy equipment for Moon base construction. After Starship, Caterpillar and Deere may space-qualify their products with little alterations. Instead than waiting decades for NASA engineers to catch up, we could send people to build a space outpost with John Deere equipment in a few years.
History is littered with the wreckage of former industrial titans that underestimated the impact of new technology and overestimated their ability to adapt: Blockbuster, Motorola, Kodak, Nokia, RIM, Xerox, Yahoo, IBM, Atari, Sears, Hitachi, Polaroid, Toshiba, HP, Palm, Sony, PanAm, Sega, Netscape, Compaq, GM… — Casey Handmer, Starship is still not understood
Everyone saw it coming, but senior management failed to realize that adaption would involve moving beyond their established business practice. Others will if they don't.
4. The Starship Possibilities
It's Starlink.

SpaceX invented affordable cargo space and grasped its implications first. How can we use all this inexpensive cargo nobody knows how to use?
Satellite communications seemed like the best way to capitalize on it. They tried. Starlink, designed by SpaceX, provides fast, dependable Internet worldwide. Beaming information down is often cheaper than cable. Already profitable.
Starlink is one use for all this cheap cargo space. Many more. The longer firms ignore the opportunity, the more SpaceX will acquire.
What are these chances?
Satellite imagery is outdated and lacks detail. We can improve greatly. Synthetic aperture radar can take beautiful shots like this:

Have you ever used Google Maps and thought, "I want to see this in more detail"? What if I could view Earth live? What if we could livestream an infrared image of Earth?

We could launch hundreds of satellites with such mind-blowing visual precision of the Earth that we would dramatically improve the accuracy of our meteorological models; our agriculture; where crime is happening; where poachers are operating in the savannah; climate change; and who is moving military personnel where. Is that useful?
What if we could see Earth in real time? That affects businesses? That changes society?
You might also like
Isobel Asher Hamilton
3 years ago
$181 million in bitcoin buried in a dump. $11 million to get them back

James Howells lost 8,000 bitcoins. He has $11 million to get them back.
His life altered when he threw out an iPhone-sized hard drive.
Howells, from the city of Newport in southern Wales, had two identical laptop hard drives squirreled away in a drawer in 2013. One was blank; the other had 8,000 bitcoins, currently worth around $181 million.
He wanted to toss out the blank one, but the drive containing the Bitcoin went to the dump.
He's determined to reclaim his 2009 stash.
Howells, 36, wants to arrange a high-tech treasure hunt for bitcoins. He can't enter the landfill.

Newport's city council has rebuffed Howells' requests to dig for his hard drive for almost a decade, stating it would be expensive and environmentally destructive.
I got an early look at his $11 million idea to search 110,000 tons of trash. He expects submitting it to the council would convince it to let him recover the hard disk.
110,000 tons of trash, 1 hard drive
Finding a hard disk among heaps of trash may seem Herculean.
Former IT worker Howells claims it's possible with human sorters, robot dogs, and an AI-powered computer taught to find hard drives on a conveyor belt.
His idea has two versions, depending on how much of the landfill he can search.
His most elaborate solution would take three years and cost $11 million to sort 100,000 metric tons of waste. Scaled-down version costs $6 million and takes 18 months.
He's created a team of eight professionals in AI-powered sorting, landfill excavation, garbage management, and data extraction, including one who recovered Columbia's black box data.
The specialists and their companies would be paid a bonus if they successfully recovered the bitcoin stash.
Howells: "We're trying to commercialize this project."
Howells claimed rubbish would be dug up by machines and sorted near the landfill.
Human pickers and a Max-AI machine would sort it. The machine resembles a scanner on a conveyor belt.
Remi Le Grand of Max-AI told us it will train AI to recognize Howells-like hard drives. A robot arm would select candidates.
Howells has added security charges to his scheme because he fears people would steal the hard drive.
He's budgeted for 24-hour CCTV cameras and two robotic "Spot" canines from Boston Dynamics that would patrol at night and look for his hard drive by day.
Howells said his crew met in May at the Celtic Manor Resort outside Newport for a pitch rehearsal.
Richard Hammond's narrative swings from banal to epic.
Richard Hammond filmed the meeting and created a YouTube documentary on Howells.
Hammond said of Howells' squad, "They're committed and believe in him and the idea."
Hammond: "It goes from banal to gigantic." "If I were in his position, I wouldn't have the strength to answer the door."
Howells said trash would be cleaned and repurposed after excavation. Reburying the rest.
"We won't pollute," he declared. "We aim to make everything better."

After the project is finished, he hopes to develop a solar or wind farm on the dump site. The council is unlikely to accept his vision soon.
A council representative told us, "Mr. Howells can't convince us of anything." "His suggestions constitute a significant ecological danger, which we can't tolerate and are forbidden by our permit."
Will the recovered hard drive work?
The "platter" is a glass or metal disc that holds the hard drive's data. Howells estimates 80% to 90% of the data will be recoverable if the platter isn't damaged.
Phil Bridge, a data-recovery expert who consulted Howells, confirmed these numbers.

If the platter is broken, Bridge adds, data recovery is unlikely.
Bridge says he was intrigued by the proposal. "It's an intriguing case," he added. Helping him get it back and proving everyone incorrect would be a great success story.
Who'd pay?
Swiss and German venture investors Hanspeter Jaberg and Karl Wendeborn told us they would fund the project if Howells received council permission.
Jaberg: "It's a needle in a haystack and a high-risk investment."
Howells said he had no contract with potential backers but had discussed the proposal in Zoom meetings. "Until Newport City Council gives me something in writing, I can't commit," he added.
Suppose he finds the bitcoins.
Howells said he would keep 30% of the data, worth $54 million, if he could retrieve it.
A third would go to the recovery team, 30% to investors, and the remainder to local purposes, including gifting £50 ($61) in bitcoin to each of Newport's 150,000 citizens.
Howells said he opted to spend extra money on "professional firms" to help convince the council.
What if the council doesn't approve?
If Howells can't win the council's support, he'll sue, claiming its actions constitute a "illegal embargo" on the hard drive. "I've avoided that path because I didn't want to cause complications," he stated. I wanted to cooperate with Newport's council.
Howells never met with the council face-to-face. He mentioned he had a 20-minute Zoom meeting in May 2021 but thought his new business strategy would help.
He met with Jessica Morden on June 24. Morden's office confirmed meeting.
After telling the council about his proposal, he can only wait. "I've never been happier," he said. This is our most professional operation, with the best employees.
The "crypto proponent" buys bitcoin every month and sells it for cash.
Howells tries not to think about what he'd do with his part of the money if the hard disk is found functional. "Otherwise, you'll go mad," he added.
This post is a summary. Read the full article here.

Deon Ashleigh
3 years ago
You can dominate your daily productivity with these 9 little-known Google Calendar tips.
Calendars are great unpaid employees.
After using Notion to organize my next three months' goals, my days were a mess.
I grew very chaotic afterward. I was overwhelmed, unsure of what to do, and wasting time attempting to plan the day after it had started.
Imagine if our skeletons were on the outside. Doesn’t work.
The goals were too big; I needed to break them into smaller chunks. But how?
Enters Google Calendar
RescueTime’s recommendations took me seven hours to make a daily planner. This epic narrative begins with a sheet of paper and concludes with a daily calendar that helps me focus and achieve more goals. Ain’t nobody got time for “what’s next?” all day.
Onward!
Return to the Paleolithic Era
Plan in writing.
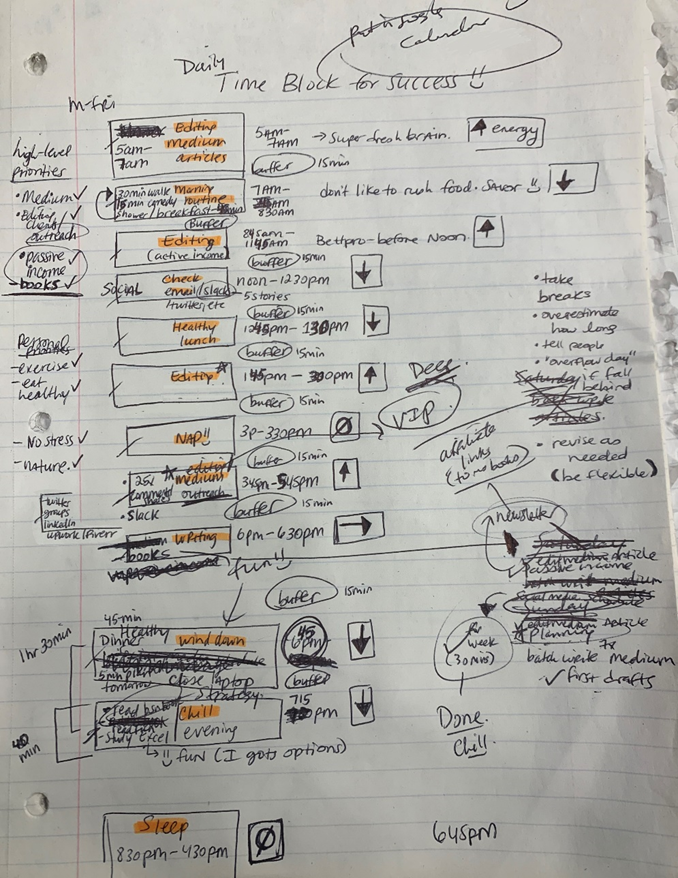
Not on the list, but it helped me plan my day. Physical writing boosts creativity and recall.
Find My Heart
i.e. prioritize
RescueTime suggested I prioritize before planning. Personal and business goals were proposed.
My top priorities are to exercise, eat healthily, spend time in nature, and avoid stress.
Priorities include writing and publishing Medium articles, conducting more freelance editing and Medium outreach, and writing/editing sci-fi books.
These eight things will help me feel accomplished every day.
Make a baby calendar.
Create daily calendar templates.
Make family, pleasure, etc. calendars.
Google Calendar instructions:
Other calendars
Press the “+” button
Create a new calendar
Create recurring events for each day
My calendar, without the template:
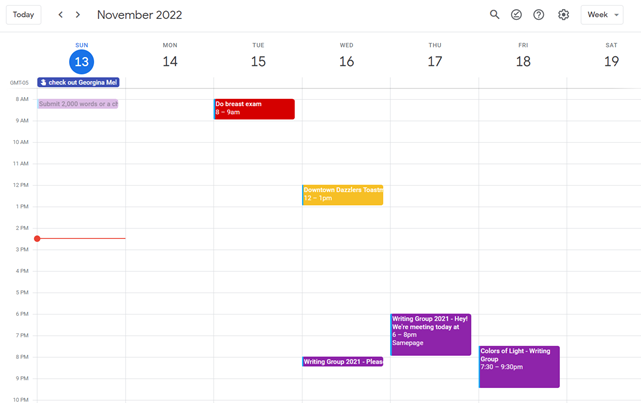
Empty, so I can fill it with vital tasks.
With the template:
My daily skeleton corresponds with my priorities. I've been overwhelmed for years because I lack daily, weekly, monthly, and yearly structure.
Google Calendars helps me reach my goals and focus my energy.
Get your colored pencils ready
Time-block color-coding.
Color labeling lets me quickly see what's happening. Maybe you are too.
Google Calendar instructions:
Determine which colors correspond to each time block.
When establishing new events, select a color.
Save
My calendar is color-coded as follows:
Yellow — passive income or other future-related activities
Red — important activities, like my monthly breast exam
Flamingo — shallow work, like emails, Twitter, etc.
Blue — all my favorite activities, like walking, watching comedy, napping, and sleeping. Oh, and eating.
Green — money-related events required for this adulting thing
Purple — writing-related stuff
Associating a time block with a color helps me stay focused. Less distractions mean faster work.
Open My Email
aka receive a daily email from Google Calendar.
Google Calendar sends a daily email feed of your calendars. I sent myself the template calendar in this email.
Google Calendar instructions:
Access settings
Select the calendar that you want to send (left side)
Go down the page to see more alerts
Under the daily agenda area, click Email.

Get in Touch With Your Red Bull Wings — Naturally
aka audit your energy levels.
My daily planner has arrows. These indicate how much energy each activity requires or how much I have.
Rightward arrow denotes medium energy.
I do my Medium and professional editing in the morning because it's energy-intensive.
Niharikaa Sodhi recommends morning Medium editing.
I’m a morning person. As long as I go to bed at a reasonable time, 5 a.m. is super wild GO-TIME. It’s like the world was just born, and I marvel at its wonderfulness.
Freelance editing lets me do what I want. An afternoon snooze will help me finish on time.
Ditch Schedule View
aka focus on the weekly view.
RescueTime advocated utilizing the weekly view of Google Calendar, so I switched.
When you launch the phone app or desktop calendar, a red line shows where you are in the day.
I'll follow the red line's instructions. My digital supervisor is easy to follow.
In the image above, it's almost 3 p.m., therefore the red line implies it's time to snooze.
I won't forget this block ;).
Reduce the Lighting
aka dim previous days.
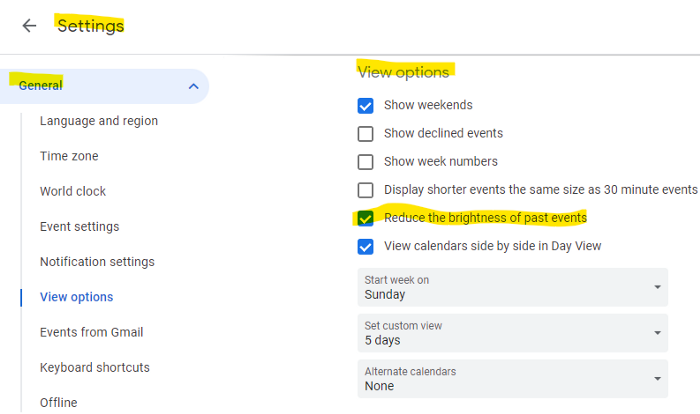
This is another Google Calendar feature I didn't know about. Once the allotted time passes, the time block dims. This keeps me present.
Google Calendar instructions:
Access settings
remaining general
To view choices, click.
Check Diminish the glare of the past.
Bonus
Two additional RescueTimes hacks:
Maintain a space between tasks
I left 15 minutes between each time block to transition smoothly. This relates to my goal of less stress. If I set strict start and end times, I'll be stressed.
With a buffer, I can breathe, stroll around, and start the following time block fresh.
Find a time is related to the buffer.
This option allows you conclude small meetings five minutes early and longer ones ten. Before the next meeting, relax or go wild.
Decide on a backup day.
This productivity technique is amazing.
Spend this excess day catching up on work. It helps reduce tension and clutter.
That's all I can say about Google Calendar's functionality.

Cody Collins
3 years ago
The direction of the economy is as follows.
What quarterly bank earnings reveal

Big banks know the economy best. Unless we’re talking about a housing crisis in 2007…
Banks are crucial to the U.S. economy. The Fed, communities, and investments exchange money.
An economy depends on money flow. Banks' views on the economy can affect their decision-making.
Most large banks released quarterly earnings and forward guidance last week. Others were pessimistic about the future.
What Makes Banks Confident
Bank of America's profit decreased 30% year-over-year, but they're optimistic about the economy. Comparatively, they're bullish.
Who banks serve affects what they see. Bank of America supports customers.
They think consumers' future is bright. They believe this for many reasons.
The average customer has decent credit, unless the system is flawed. Bank of America's new credit card and mortgage borrowers averaged 771. New-car loan and home equity borrower averages were 791 and 797.
2008's housing crisis affected people with scores below 620.
Bank of America and the economy benefit from a robust consumer. Major problems can be avoided if individuals maintain spending.
Reasons Other Banks Are Less Confident
Spending requires income. Many companies, mostly in the computer industry, have announced they will slow or freeze hiring. Layoffs are frequently an indication of poor times ahead.
BOA is positive, but investment banks are bearish.
Jamie Dimon, CEO of JPMorgan, outlined various difficulties our economy could confront.
But geopolitical tension, high inflation, waning consumer confidence, the uncertainty about how high rates have to go and the never-before-seen quantitative tightening and their effects on global liquidity, combined with the war in Ukraine and its harmful effect on global energy and food prices are very likely to have negative consequences on the global economy sometime down the road.
That's more headwinds than tailwinds.
JPMorgan, which helps with mergers and IPOs, is less enthusiastic due to these concerns. Incoming headwinds signal drying liquidity, they say. Less business will be done.
Final Reflections
I don't think we're done. Yes, stocks are up 10% from a month ago. It's a long way from old highs.
I don't think the stock market is a strong economic indicator.
Many executives foresee a 2023 recession. According to the traditional definition, we may be in a recession when Q2 GDP statistics are released next week.
Regardless of criteria, I predict the economy will have a terrible year.
Weekly layoffs are announced. Inflation persists. Will prices return to 2020 levels if inflation cools? Perhaps. Still expensive energy. Ukraine's war has global repercussions.
I predict BOA's next quarter earnings won't be as bullish about the consumer's strength.