


The InSight lander from NASA has recorded the greatest tremor ever felt on Mars.
The magnitude 5 earthquake was responsible for the discharge of energy that was 10 times greater than the previous record holder.
Any Martians who happen to be reading this should quickly learn how to duck and cover.
NASA's Jet Propulsion Laboratory in Pasadena, California, reported that on May 4, the planet Mars was shaken by an earthquake of around magnitude 5, making it the greatest Marsquake ever detected to this point. The shaking persisted for more than six hours and unleashed more than ten times as much energy as the earthquake that had previously held the record for strongest.
The event was captured on record by the InSight lander, which is operated by the United States Space Agency and has been researching the innards of Mars ever since it touched down on the planet in 2018 (SN: 11/26/18). The epicenter of the earthquake was probably located in the vicinity of Cerberus Fossae, which is located more than 1,000 kilometers away from the lander.
The surface of Cerberus Fossae is notorious for being broken up and experiencing periodic rockfalls. According to geophysicist Philippe Lognonné, who is the lead investigator of the Seismic Experiment for Interior Structure, the seismometer that is onboard the InSight lander, it is reasonable to assume that the ground is moving in that area. "This is an old crater from a volcanic eruption."
Marsquakes, which are similar to earthquakes in that they give information about the interior structure of our planet, can be utilized to investigate what lies beneath the surface of Mars (SN: 7/22/21). And according to Lognonné, who works at the Institut de Physique du Globe in Paris, there is a great deal that can be gleaned from analyzing this massive earthquake. Because the quality of the signal is so high, we will be able to focus on the specifics.
More on Science

Will Lockett
3 years ago
The Unlocking Of The Ultimate Clean Energy

The company seeking 24/7 ultra-powerful solar electricity.
We're rushing to adopt low-carbon energy to prevent a self-made doomsday. We're using solar, wind, and wave energy. These low-carbon sources aren't perfect. They consume large areas of land, causing habitat loss. They don't produce power reliably, necessitating large grid-level batteries, an environmental nightmare. We can and must do better than fossil fuels. Longi, one of the world's top solar panel producers, is creating a low-carbon energy source. Solar-powered spacecraft. But how does it work? Why is it so environmentally harmonious? And how can Longi unlock it?
Space-based solar makes sense. Satellites above Medium Earth Orbit (MEO) enjoy 24/7 daylight. Outer space has no atmosphere or ozone layer to block the Sun's high-energy UV radiation. Solar panels can create more energy in space than on Earth due to these two factors. Solar panels in orbit can create 40 times more power than those on Earth, according to estimates.
How can we utilize this immense power? Launch a geostationary satellite with solar panels, then beam power to Earth. Such a technology could be our most eco-friendly energy source. (Better than fusion power!) How?
Solar panels create more energy in space, as I've said. Solar panel manufacture and grid batteries emit the most carbon. This indicates that a space-solar farm's carbon footprint (which doesn't need a battery because it's a constant power source) might be over 40 times smaller than a terrestrial one. Combine that with carbon-neutral launch vehicles like Starship, and you have a low-carbon power source. Solar power has one of the lowest emissions per kWh at 6g/kWh, so space-based solar could approach net-zero emissions.
Space solar is versatile because it doesn't require enormous infrastructure. A space-solar farm could power New York and Dallas with the same efficiency, without cables. The satellite will transmit power to a nearby terminal. This allows an energy system to evolve and adapt as the society it powers changes. Building and maintaining infrastructure can be carbon-intensive, thus less infrastructure means less emissions.
Space-based solar doesn't destroy habitats, either. Solar and wind power can be engineered to reduce habitat loss, but they still harm ecosystems, which must be restored. Space solar requires almost no land, therefore it's easier on Mother Nature.
Space solar power could be the ultimate energy source. So why haven’t we done it yet?
Well, for two reasons: the cost of launch and the efficiency of wireless energy transmission.
Advances in rocket construction and reusable rocket technology have lowered orbital launch costs. In the early 2000s, the Space Shuttle cost $60,000 per kg launched into LEO, but a SpaceX Falcon 9 costs only $3,205. 95% drop! Even at these low prices, launching a space-based solar farm is commercially questionable.
Energy transmission efficiency is half of its commercial viability. Space-based solar farms must be in geostationary orbit to get 24/7 daylight, 22,300 miles above Earth's surface. It's a long way to wirelessly transmit energy. Most laser and microwave systems are below 20% efficient.
Space-based solar power is uneconomical due to low efficiency and high deployment costs.
Longi wants to create this ultimate power. But how?
They'll send solar panels into space to develop space-based solar power that can be beamed to Earth. This mission will help them design solar panels tough enough for space while remaining efficient.
Longi is a Chinese company, and China's space program and universities are developing space-based solar power and seeking commercial partners. Xidian University has built a 98%-efficient microwave-based wireless energy transmission system for space-based solar power. The Long March 5B is China's super-cheap (but not carbon-offset) launch vehicle.
Longi fills the gap. They have the commercial know-how and ability to build solar satellites and terrestrial terminals at scale. Universities and the Chinese government have transmission technology and low-cost launch vehicles to launch this technology.
It may take a decade to develop and refine this energy solution. This could spark a clean energy revolution. Once operational, Longi and the Chinese government could offer the world a flexible, environmentally friendly, rapidly deployable energy source.
Should the world adopt this technology and let China control its energy? I'm not very political, so you decide. This seems to be the beginning of tapping into this planet-saving energy source. Forget fusion reactors. Carbon-neutral energy is coming soon.

Tomas Pueyo
3 years ago
Soon, a Starship Will Transform Humanity
SpaceX's Starship.

Launched last week.
Four minutes in:
SpaceX will succeed. When it does, its massiveness will matter.
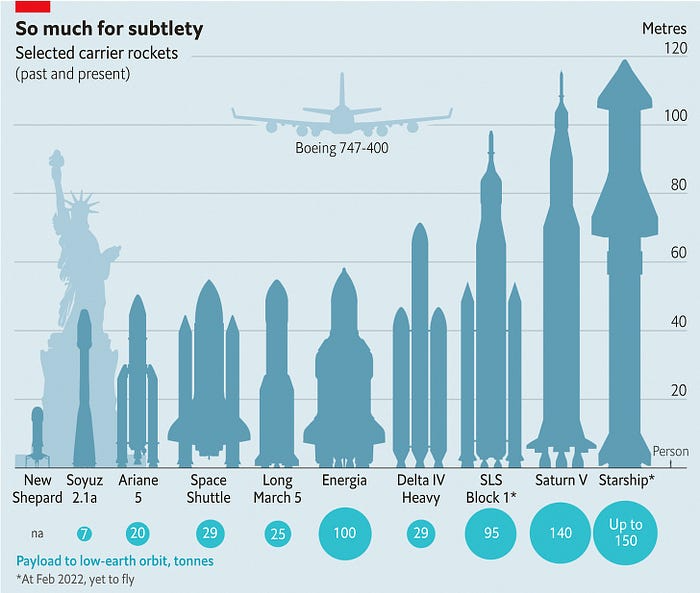
Its payload will revolutionize space economics.
Civilization will shift.
We don't yet understand how this will affect space and Earth culture. Grab it.
The Cost of Space Transportation Has Decreased Exponentially
Space launches have increased dramatically in recent years.
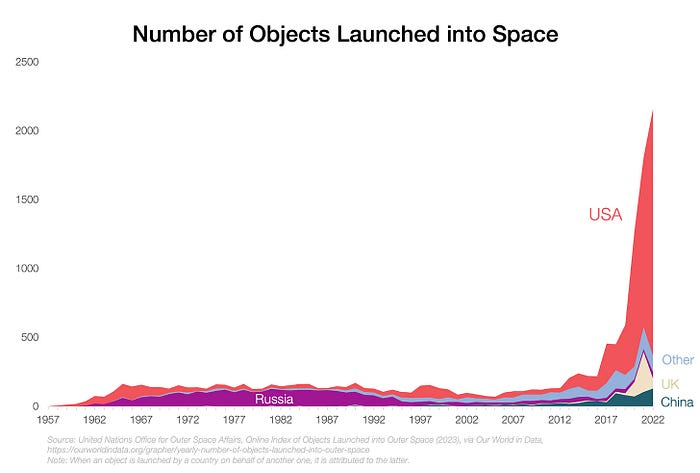
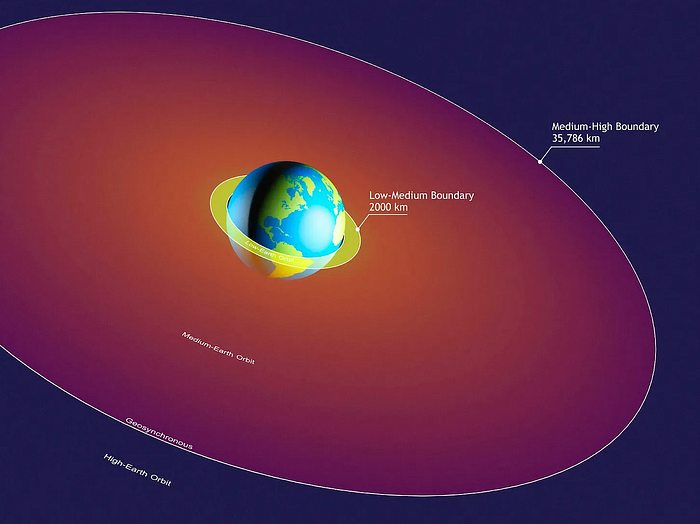
We mostly send items to LEO, the green area below:
SpaceX's reusable rockets can send these things to LEO. Each may launch dozens of payloads into space.
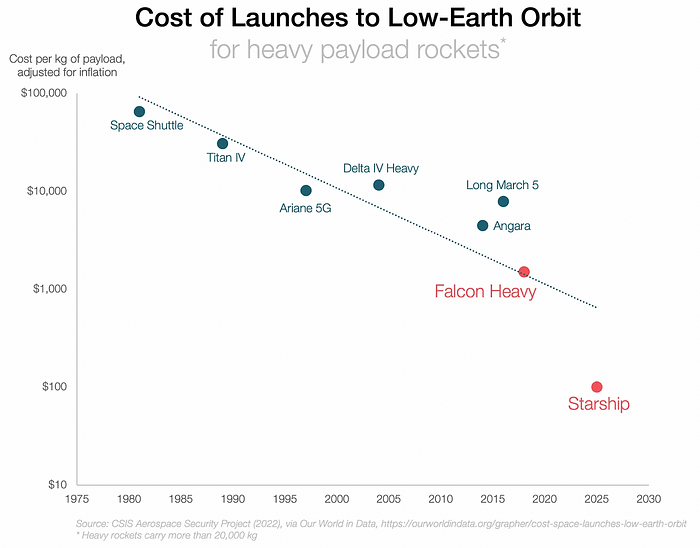
With all these launches, we're sending more than simply things to space. Volume and mass. Since the 1980s, launching a kilogram of payload to LEO has become cheaper:
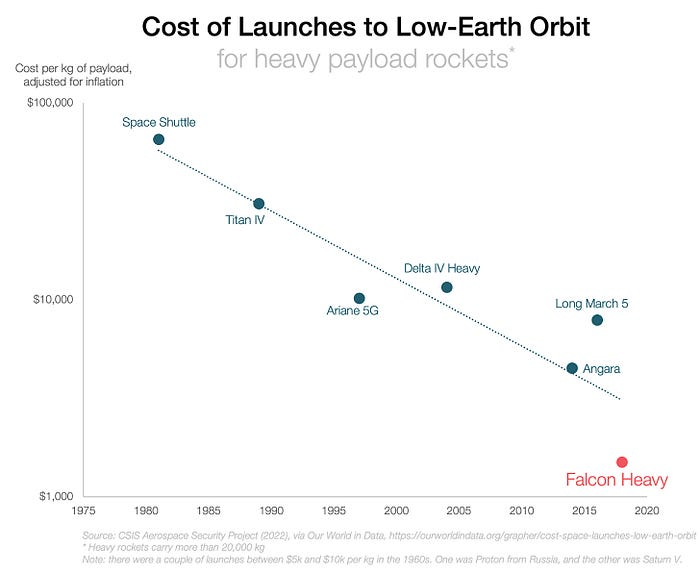
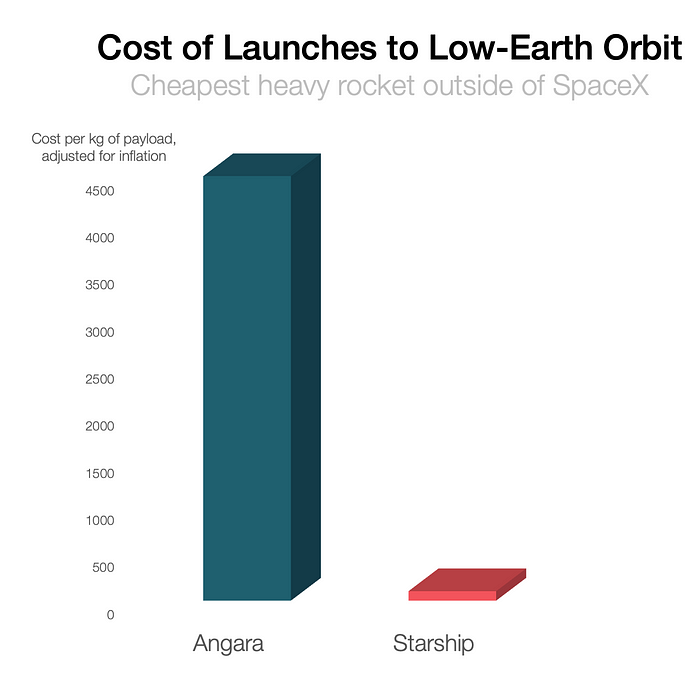
One kilogram in a large rocket cost over $75,000 in the 1980s. Carrying one astronaut cost nearly $5M! Falcon Heavy's $1,500/kg price is 50 times lower. SpaceX's larger, reusable rockets are amazing.
SpaceX's Starship rocket will continue. It can carry over 100 tons to LEO, 50% more than the current Falcon heavy. Thousands of launches per year. Elon Musk predicts Falcon Heavy's $1,500/kg cost will plummet to $100 in 23 years.
In context:
People underestimate this.
2. The Benefits of Affordable Transportation
Compare Earth's transportation costs:
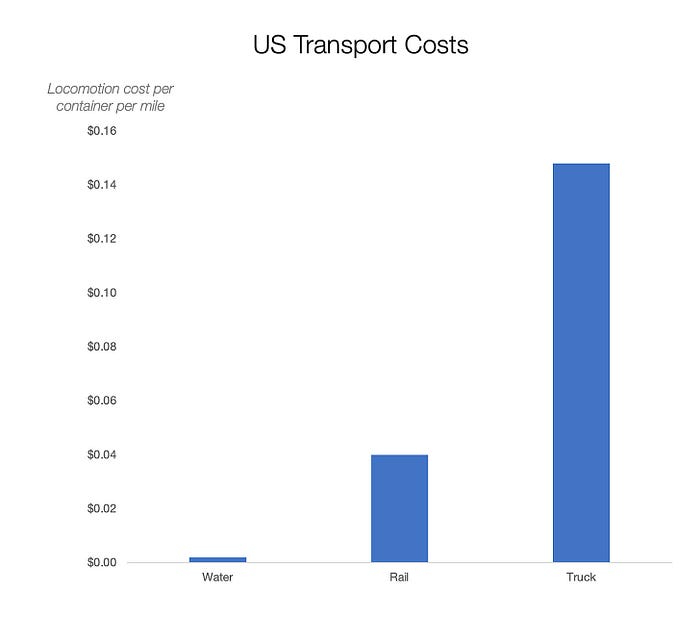
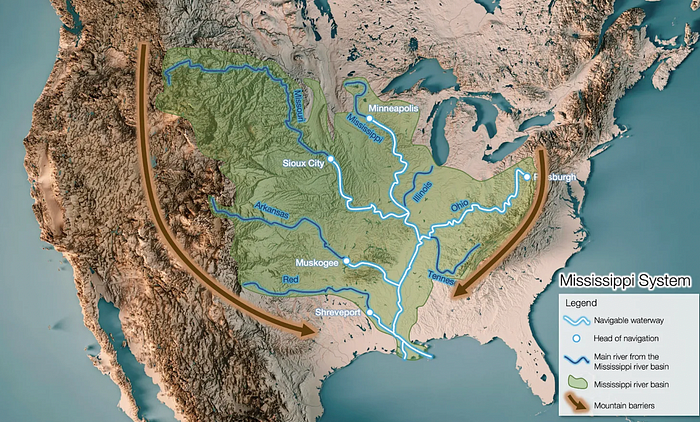
It's no surprise that the US and Northern Europe are the wealthiest and have the most navigable interior waterways.
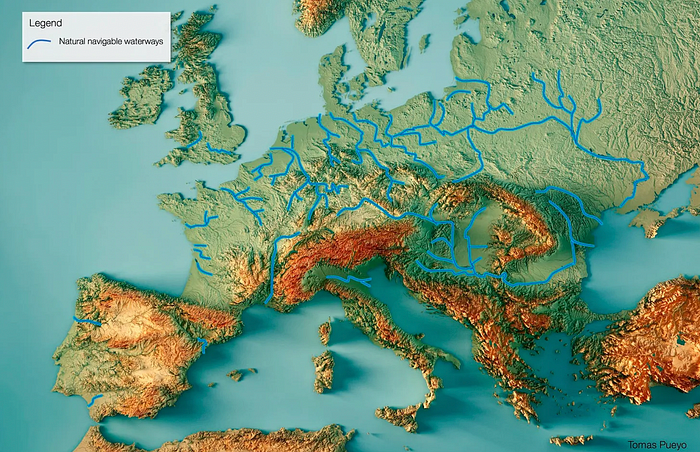
So what? since sea transportation is cheaper than land. Inland waterways are even better than sea transportation since weather is less of an issue, currents can be controlled, and rivers serve two banks instead of one for coastal transportation.
In France, because population density follows river systems, rivers are valuable. Cheap transportation brought people and money to rivers, especially their confluences.
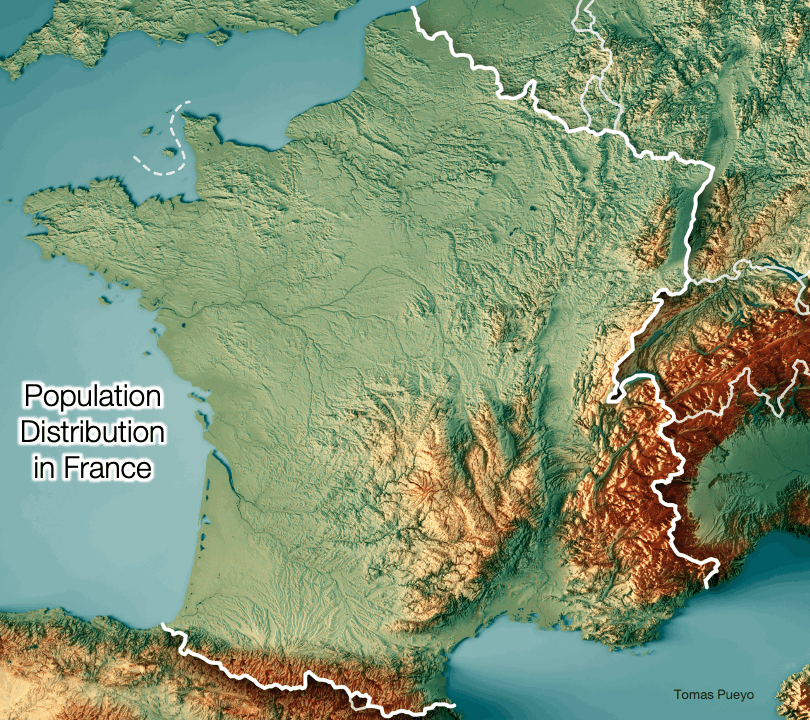
How come? Why were humans surrounding rivers?
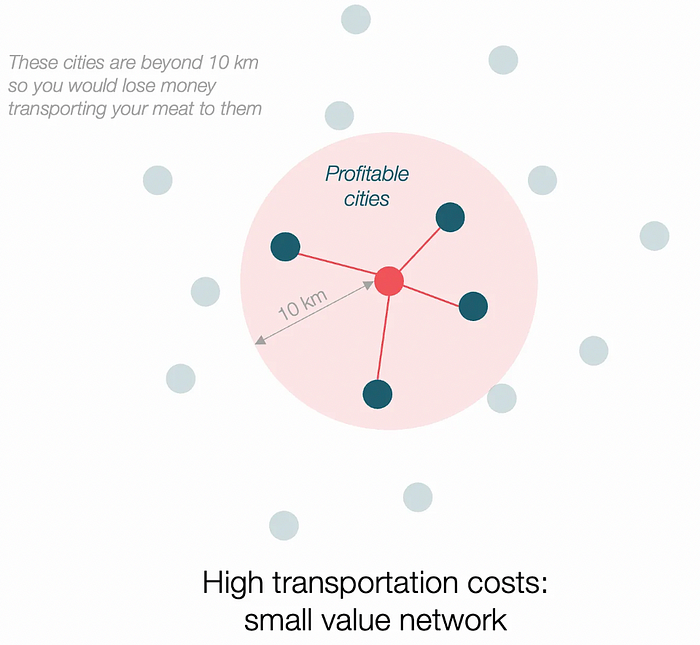
Imagine selling meat for $10 per kilogram. Transporting one kg one kilometer costs $1. Your margin decreases $1 each kilometer. You can only ship 10 kilometers. For example, you can only trade with four cities:
If instead, your cost of transportation is half, what happens? It costs you $0.5 per km. You now have higher margins with each city you traded with. More importantly, you can reach 20-km markets.
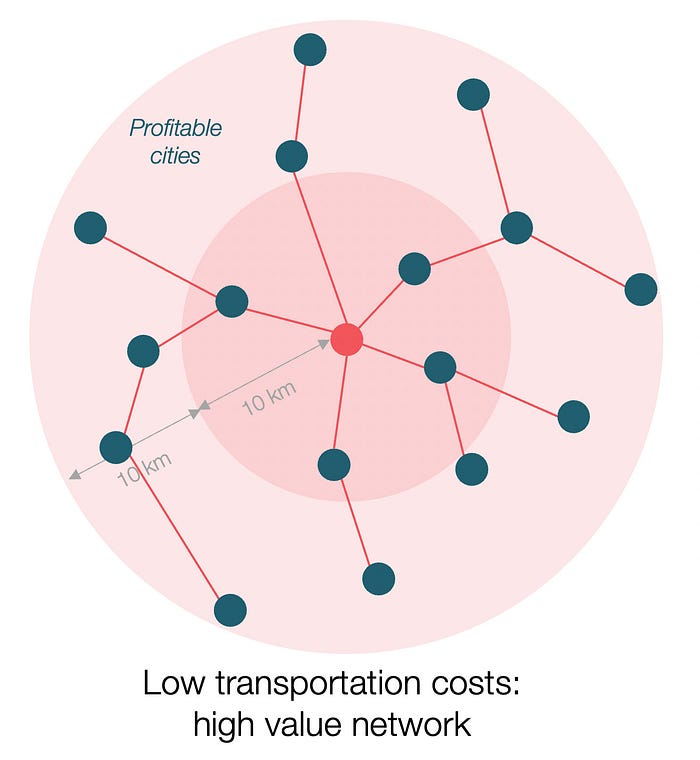
However, 2x distance 4x surface! You can now trade with sixteen cities instead of four! Metcalfe's law states that a network's value increases with its nodes squared. Since now sixteen cities can connect to yours. Each city now has sixteen connections! They get affluent and can afford more meat.
Rivers lower travel costs, connecting many cities, which can trade more, get wealthy, and buy more.
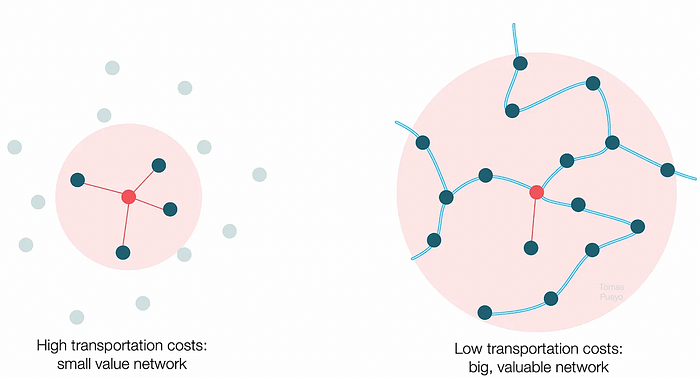
The right network is worth at least an order of magnitude more than the left! The cheaper the transport, the more trade at a lower cost, the more income generated, the more that wealth can be reinvested in better canals, bridges, and roads, and the wealth grows even more.
Throughout history. Rome was established around cheap Mediterranean transit and preoccupied with cutting overland transportation costs with their famous roadways. Communications restricted their empire.
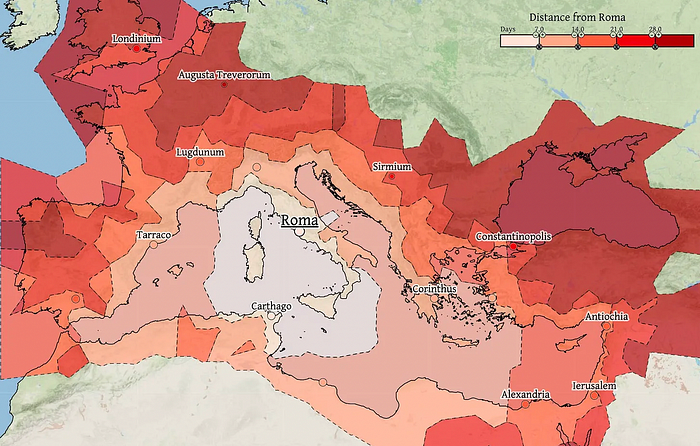
The Egyptians lived around the Nile, the Vikings around the North Sea, early Japan around the Seto Inland Sea, and China started canals in the 5th century BC.
Transportation costs shaped empires.Starship is lowering new-world transit expenses. What's possible?
3. Change Organizations, Change Companies, Change the World
Starship is a conveyor belt to LEO. A new world of opportunity opens up as transportation prices drop 100x in a decade.
Satellite engineers have spent decades shedding milligrams. Weight influenced every decision: pricing structure, volumes to be sent, material selections, power sources, thermal protection, guiding, navigation, and control software. Weight was everything in the mission. To pack as much science into every millimeter, NASA missions had to be miniaturized. Engineers were indoctrinated against mass.
No way.
Starship is not constrained by any space mission, robotic or crewed.
Starship obliterates the mass constraint and every last vestige of cultural baggage it has gouged into the minds of spacecraft designers. A dollar spent on mass optimization no longer buys a dollar saved on launch cost. It buys nothing. It is time to raise the scope of our ambition and think much bigger. — Casey Handmer, Starship is still not understood
A Tesla Roadster in space makes more sense.

It went beyond bad PR. It told the industry: Did you care about every microgram? No more. My rockets are big enough to send a Tesla without noticing. Industry watchers should have noticed.
Most didn’t. Artemis is a global mission to send astronauts to the Moon and build a base. Artemis uses disposable Space Launch System rockets. Instead of sending two or three dinky 10-ton crew habitats over the next decade, Starship might deliver 100x as much cargo and create a base for 1,000 astronauts in a year or two. Why not? Because Artemis remains in a pre-Starship paradigm where each kilogram costs a million dollars and we must aggressively descope our objective.

Space agencies can deliver 100x more payload to space for the same budget with 100x lower costs and 100x higher transportation volumes. How can space economy saturate this new supply?
Before Starship, NASA supplied heavy equipment for Moon base construction. After Starship, Caterpillar and Deere may space-qualify their products with little alterations. Instead than waiting decades for NASA engineers to catch up, we could send people to build a space outpost with John Deere equipment in a few years.
History is littered with the wreckage of former industrial titans that underestimated the impact of new technology and overestimated their ability to adapt: Blockbuster, Motorola, Kodak, Nokia, RIM, Xerox, Yahoo, IBM, Atari, Sears, Hitachi, Polaroid, Toshiba, HP, Palm, Sony, PanAm, Sega, Netscape, Compaq, GM… — Casey Handmer, Starship is still not understood
Everyone saw it coming, but senior management failed to realize that adaption would involve moving beyond their established business practice. Others will if they don't.
4. The Starship Possibilities
It's Starlink.

SpaceX invented affordable cargo space and grasped its implications first. How can we use all this inexpensive cargo nobody knows how to use?
Satellite communications seemed like the best way to capitalize on it. They tried. Starlink, designed by SpaceX, provides fast, dependable Internet worldwide. Beaming information down is often cheaper than cable. Already profitable.
Starlink is one use for all this cheap cargo space. Many more. The longer firms ignore the opportunity, the more SpaceX will acquire.
What are these chances?
Satellite imagery is outdated and lacks detail. We can improve greatly. Synthetic aperture radar can take beautiful shots like this:

Have you ever used Google Maps and thought, "I want to see this in more detail"? What if I could view Earth live? What if we could livestream an infrared image of Earth?

We could launch hundreds of satellites with such mind-blowing visual precision of the Earth that we would dramatically improve the accuracy of our meteorological models; our agriculture; where crime is happening; where poachers are operating in the savannah; climate change; and who is moving military personnel where. Is that useful?
What if we could see Earth in real time? That affects businesses? That changes society?

Laura Sanders
4 years ago
Xenobots, tiny living machines, can duplicate themselves.
Strange and complex behavior of frog cell blobs
A xenobot “parent,” shaped like a hungry Pac-Man (shown in red false color), created an “offspring” xenobot (green sphere) by gathering loose frog cells in its opening.
Tiny “living machines” made of frog cells can make copies of themselves. This newly discovered renewal mechanism may help create self-renewing biological machines.
According to Kirstin Petersen, an electrical and computer engineer at Cornell University who studies groups of robots, “this is an extremely exciting breakthrough.” She says self-replicating robots are a big step toward human-free systems.
Researchers described the behavior of xenobots earlier this year (SN: 3/31/21). Small clumps of skin stem cells from frog embryos knitted themselves into small spheres and started moving. Cilia, or cellular extensions, powered the xenobots around their lab dishes.
The findings are published in the Proceedings of the National Academy of Sciences on Dec. 7. The xenobots can gather loose frog cells into spheres, which then form xenobots.
The researchers call this type of movement-induced reproduction kinematic self-replication. The study's coauthor, Douglas Blackiston of Tufts University in Medford, Massachusetts, and Harvard University, says this is typical. For example, sexual reproduction requires parental sperm and egg cells. Sometimes cells split or budded off from a parent.
“This is unique,” Blackiston says. These xenobots “find loose parts in the environment and cobble them together.” This second generation of xenobots can move like their parents, Blackiston says.
The researchers discovered that spheroid xenobots could only produce one more generation before dying out. The original xenobots' shape was predicted by an artificial intelligence program, allowing for four generations of replication.
A C shape, like an openmouthed Pac-Man, was predicted to be a more efficient progenitor. When improved xenobots were let loose in a dish, they began scooping up loose cells into their gaping “mouths,” forming more sphere-shaped bots (see image below). As many as 50 cells clumped together in the opening of a parent to form a mobile offspring. A xenobot is made up of 4,000–6,000 frog cells.
Petersen likes the Xenobots' small size. “The fact that they were able to do this at such a small scale just makes it even better,” she says. Miniature xenobots could sculpt tissues for implantation or deliver therapeutics inside the body.
Beyond the xenobots' potential jobs, the research advances an important science, says study coauthor and Tufts developmental biologist Michael Levin. The science of anticipating and controlling the outcomes of complex systems, he says.
“No one could have predicted this,” Levin says. “They regularly surprise us.” Researchers can use xenobots to test the unexpected. “This is about advancing the science of being less surprised,” Levin says.
You might also like

Bloomberg
4 years ago
Expulsion of ten million Ukrainians
According to recent data from two UN agencies, ten million Ukrainians have been displaced.
The International Organization for Migration (IOM) estimates nearly 6.5 million Ukrainians have relocated. Most have fled the war zones around Kyiv and eastern Ukraine, including Dnipro, Zhaporizhzhia, and Kharkiv. Most IDPs have fled to western and central Ukraine.
Since Russia invaded on Feb. 24, 3.6 million people have crossed the border to seek refuge in neighboring countries, according to the latest UN data. While most refugees have fled to Poland and Romania, many have entered Russia.
Internally displaced figures are IOM estimates as of March 19, based on 2,000 telephone interviews with Ukrainians aged 18 and older conducted between March 9-16. The UNHCR compiled the figures for refugees to neighboring countries on March 21 based on official border crossing data and its own estimates. The UNHCR's top-line total is lower than the country totals because Romania and Moldova totals include people crossing between the two countries.
Sources: IOM, UNHCR
According to IOM estimates based on telephone interviews with a representative sample of internally displaced Ukrainians, over 53% of those displaced are women, and over 60% of displaced households have children.

Asher Umerie
4 years ago
What is Bionic Reading?
Senses help us navigate a complicated world. They shape our worldview - how we hear, smell, feel, and taste. People claim a sixth sense, an intuitive capacity that extends perception.
Our brain is a half-pool of grey and white matter that stores data from our senses. Brains provide us context, so zombies' obsession makes sense.
Bionic reading uses the brain's visual information and context to simplify text comprehension.
Stay with me.
What is Bionic Reading?
Bionic reading is a software application established by Swiss typographic designer Renato Casutt. The term honors the brain (bio) and technology's collaboration to better text comprehension.
The image above shows two similar paragraphs with bionic reading.
Notice anything yet?
This Twitter user did.
I did too...
Image text describes bionic reading-
New method to aid reading by using artificial fixation points. The reader focuses on the highlighted starting letters, and the brain completes the word.
How is Bionic Reading possible?
Do you remember seeing social media posts asking you to stare at a black dot for 30 seconds (or more)? You blink and see an after-image on your wall.
Our brains are skilled at identifying patterns and'seeing' familiar objects, therefore optical illusions are conceivable.
Brain and sight collaborate well. Text comprehension proves it.
Considering evolutionary patterns, humans' understanding skills may be cosmic luck.
Scientists don't know why people can read and write, but they do know what reading does to the brain.
One portion of your brain recognizes words, while another analyzes their meaning. Fixation, saccade, and linguistic transparency/opacity aid.
Let's explain some terms.
-
Fixation is how the eyes move when reading. It's where you look. If the eyes fixate less, a reader can read quicker. [Eye fixation is a physiological process](Eye fixation is a naturally occurring physiological process) impacted by the reader's vocabulary, vision span, and text familiarity.
-
Saccade - Pause and look around. That's a saccade. Rapid eye movements that alter the place of fixation, as reading text or looking around a room. They can happen willingly (when you choose) or instinctively, even when your eyes are fixed.
-
Linguistic transparency and opacity analyze how well a composite word or phrase may be deduced from its constituents.
The Bionic reading website compares these tools.
Text highlights lead the eye. Fixation, saccade, and opacity can transfer visual stimuli to text, changing typeface.
## Final Thoughts on Bionic Reading
I'm excited about how this could influence my long-term assimilation and productivity.
This technology is still in development, with prototypes working on only a few apps. Like any new tech, it will be criticized.
I'll be watching Bionic Reading closely. Comment on it!

Jeff John Roberts
4 years ago
Jack Dorsey and Jay-Z Launch 'Bitcoin Academy' in Brooklyn rapper's home
The new Bitcoin Academy will teach Jay-Marcy Z's Houses neighbors "What is Cryptocurrency."
Jay-Z grew up in Brooklyn's Marcy Houses. The rapper and Block CEO Jack Dorsey are giving back to his hometown by creating the Bitcoin Academy.
The Bitcoin Academy will offer online and in-person classes, including "What is Money?" and "What is Blockchain?"
The program will provide participants with a mobile hotspot and a small amount of Bitcoin for hands-on learning.
Students will receive dinner and two evenings of instruction until early September. The Shawn Carter Foundation will help with on-the-ground instruction.
Jay-Z and Dorsey announced the program Thursday morning. It will begin at Marcy Houses but may be expanded.
Crypto Blockchain Plug and Black Bitcoin Billionaire, which has received a grant from Block, will teach the classes.
Jay-Z, Dorsey reunite
Jay-Z and Dorsey have previously worked together to promote a Bitcoin and crypto-based future.
In 2021, Dorsey's Block (then Square) acquired the rapper's streaming music service Tidal, which they propose using for NFT distribution.
Dorsey and Jay-Z launched an endowment in 2021 to fund Bitcoin development in Africa and India.
Dorsey is funding the new Bitcoin Academy out of his own pocket (as is Jay-Z), but he's also pushed crypto-related charitable endeavors at Block, including a $5 million fund backed by corporate Bitcoin interest.
This post is a summary. Read full article here