




More on Personal Growth

James White
3 years ago
Ray Dalio suggests reading these three books in 2022.
An inspiring reading list

I'm no billionaire or hedge-fund manager. My bank account doesn't have millions. Ray Dalio's love of reading motivates me to think differently.
Here are some books recommended by Ray Dalio. Each influenced me. Hope they'll help you.
Sapiens by Yuval Noah Harari
Page Count: 512
Rating on Goodreads: 4.39
My favorite nonfiction book.
Sapiens explores human evolution. It explains how Homo Sapiens developed from hunter-gatherers to a dominant species. Amazing!
Sapiens will teach you about human history. Yuval Noah Harari has a follow-up book on human evolution.

My favorite book quotes are:
The tendency for luxuries to turn into necessities and give rise to new obligations is one of history's few unbreakable laws.
Happiness is not dependent on material wealth, physical health, or even community. Instead, it depends on how closely subjective expectations and objective circumstances align.
The romantic comparison between today's industry, which obliterates the environment, and our forefathers, who coexisted well with nature, is unfounded. Homo sapiens held the record among all organisms for eradicating the most plant and animal species even before the Industrial Revolution. The unfortunate distinction of being the most lethal species in the history of life belongs to us.
The Power Of Habit by Charles Duhigg
Page Count: 375
Rating on Goodreads: 4.13
Great book: The Power Of Habit. It illustrates why habits are everything. The book explains how healthier habits can improve your life, career, and society.
The Power of Habit rocks. It's a great book on productivity. Its suggestions helped me build healthier behaviors (and drop bad ones).
Read ASAP!

My favorite book quotes are:
Change may not occur quickly or without difficulty. However, almost any behavior may be changed with enough time and effort.
People who exercise begin to eat better and produce more at work. They are less smokers and are more patient with friends and family. They claim to feel less anxious and use their credit cards less frequently. A fundamental habit that sparks broad change is exercise.
Habits are strong but also delicate. They may develop independently of our awareness or may be purposefully created. They frequently happen without our consent, but they can be altered by changing their constituent pieces. They have a much greater influence on how we live than we realize; in fact, they are so powerful that they cause our brains to adhere to them above all else, including common sense.
Tribe Of Mentors by Tim Ferriss
Page Count: 561
Rating on Goodreads: 4.06
Unusual book structure. It's worth reading if you want to learn from successful people.
The book is Q&A-style. Tim questions everyone. Each chapter features a different person's life-changing advice. In the book, Pressfield, Willink, Grylls, and Ravikant are interviewed.
Amazing!

My favorite book quotes are:
According to one's courage, life can either get smaller or bigger.
Don't engage in actions that you are aware are immoral. The reputation you have with yourself is all that constitutes self-esteem. Always be aware.
People mistakenly believe that focusing means accepting the task at hand. However, that is in no way what it represents. It entails rejecting the numerous other worthwhile suggestions that exist. You must choose wisely. Actually, I'm just as proud of the things we haven't accomplished as I am of what I have. Saying no to 1,000 things is what innovation is.

Merve Yılmaz
3 years ago
Dopamine detox
This post is for you if you can't read or study for 5 minutes.

If you clicked this post, you may be experiencing problems focusing on tasks. A few minutes of reading may tire you. Easily distracted? Using social media and video games for hours without being sidetracked may impair your dopamine system.
When we achieve a goal, the brain secretes dopamine. It might be as simple as drinking water or as crucial as college admission. Situations vary. Various events require different amounts.
Dopamine is released when we start learning but declines over time. Social media algorithms provide new material continually, making us happy. Social media use slows down the system. We can't continue without an award. We return to social media and dopamine rewards.
Mice were given a button that released dopamine into their brains to study the hormone. The mice lost their hunger, thirst, and libido and kept pressing the button. Think this is like someone who spends all day gaming or on Instagram?
When we cause our brain to release so much dopamine, the brain tries to balance it in 2 ways:
1- Decreases dopamine production
2- Dopamine cannot reach its target.
Too many quick joys aren't enough. We'll want more joys. Drugs and alcohol are similar. Initially, a beer will get you drunk. After a while, 3-4 beers will get you drunk.
Social media is continually changing. Updates to these platforms keep us interested. When social media conditions us, we can't read a book.
Same here. I used to complete a book in a day and work longer without distraction. Now I'm addicted to Instagram. Daily, I spend 2 hours on social media. This must change. My life needs improvement. So I started the 50-day challenge.
I've compiled three dopamine-related methods.
Recommendations:
Day-long dopamine detox
First, take a day off from all your favorite things. Social media, gaming, music, junk food, fast food, smoking, alcohol, friends. Take a break.
Hanging out with friends or listening to music may seem pointless. Our minds are polluted. One day away from our pleasures can refresh us.
2. One-week dopamine detox by selecting
Choose one or more things to avoid. Social media, gaming, music, junk food, fast food, smoking, alcohol, friends. Try a week without Instagram or Twitter. I use this occasionally.
One week all together
One solid detox week. It's the hardest program. First or second options are best for dopamine detox. Time will help you.
You can walk, read, or pray during a dopamine detox. Many options exist. If you want to succeed, you must avoid instant gratification. Success after hard work is priceless.

Sad NoCoiner
3 years ago
Two Key Money Principles You Should Understand But Were Never Taught

Prudence is advised. Be debt-free. Be frugal. Spend less.
This advice sounds nice, but it rarely works.
Most people never learn these two money rules. Both approaches will impact how you see personal finance.
It may safeguard you from inflation or the inability to preserve money.
Let’s dive in.
#1: Making long-term debt your ally
High-interest debt hurts consumers. Many credit cards carry 25% yearly interest (or more), so always pay on time. Otherwise, you’re losing money.
Some low-interest debt is good. Especially when buying an appreciating asset with borrowed money.
Inflation helps you.
If you borrow $800,000 at 3% interest and invest it at 7%, you'll make $32,000 (4%).
As money loses value, fixed payments get cheaper. Your assets' value and cash flow rise.
The never-in-debt crowd doesn't know this. They lose money paying off mortgages and low-interest loans early when they could have bought assets instead.
#2: How To Buy Or Build Assets To Make Inflation Irrelevant
Dozens of studies demonstrate actual wage growth is static; $2.50 in 1964 was equivalent to $22.65 now.
These reports never give solutions unless they're selling gold.
But there is one.
Assets beat inflation.
$100 invested into the S&P 500 would have an inflation-adjusted return of 17,739.30%.
Likewise, you can build assets from nothing. Doing is easy and quick. The returns can boost your income by 10% or more.
The people who obsess over inflation inadvertently make the problem worse for themselves. They wait for The Big Crash to buy assets. Or they moan about debt clocks and spending bills instead of seeking a solution.
Conclusion
Being ultra-prudent is like playing golf with a putter to avoid hitting the ball into the water. Sure, you might not slice a drive into the pond. But, you aren’t going to play well either. Or have very much fun.
Money has rules.
Avoiding debt or investment risks will limit your rewards. Long-term, being too cautious hurts your finances.
Disclaimer: This article is for entertainment purposes only. It is not financial advice, always do your own research.
You might also like

nft now
3 years ago
Instagram NFTs Are Here… How does this affect artists?
Instagram (IG) is officially joining NFT. With the debut of new in-app NFT functionalities, influential producers can interact with blockchain tech on the social media platform.
Meta unveiled intentions for an Instagram NFT marketplace in March, but these latest capabilities focus more on content sharing than commerce. And why shouldn’t they? IG's entry into the NFT market is overdue, given that Twitter and Discord are NFT hotspots.
The NFT marketplace/Web3 social media race has continued to expand, with the expected Coinbase NFT Beta now live and blazing a trail through the NFT ecosystem.
IG's focus is on visual art. It's unlike any NFT marketplace or platform. IG NFTs and artists: what's the deal? Let’s take a look.
What are Instagram’s NFT features anyways?
As said, not everyone has Instagram's new features. 16 artists, NFT makers, and collectors can now post NFTs on IG by integrating third-party digital wallets (like Rainbow or MetaMask) in-app. IG doesn't charge to publish or share digital collectibles.
NFTs displayed on the app have a "shimmer" aesthetic effect. NFT posts also have a "digital collectable" badge that lists metadata such as the creator and/or owner, the platform it was created on, a brief description, and a blockchain identification.
Meta's social media NFTs have launched on Instagram, but the company is also preparing to roll out digital collectibles on Facebook, with more on the way for IG. Currently, only Ethereum and Polygon are supported, but Flow and Solana will be added soon.
How will artists use these new features?
Artists are publishing NFTs they developed or own on IG by linking third-party digital wallets. These features have no NFT trading aspects built-in, but are aimed to let authors share NFTs with IG audiences.
Creators, like IG-native aerial/street photographer Natalie Amrossi (@misshattan), are discovering novel uses for IG NFTs.
Amrossi chose to not only upload his own NFTs but also encourage other artists in the field. "That's the beauty of connecting your wallet and sharing NFTs. It's not just what you make, but also what you accumulate."
Amrossi has been producing and posting Instagram art for years. With IG's NFT features, she can understand Instagram's importance in supporting artists.
Web2 offered Amrossi the tools to become an artist and make a life. "Before 'influencer' existed, I was just making art. Instagram helped me reach so many individuals and brands, giving me a living.
Even artists without millions of viewers are encouraged to share NFTs on IG. Wilson, a relatively new name in the NFT space, seems to have already gone above and beyond the scope of these new IG features. By releasing "Losing My Mind" via IG NFT posts, she has evaded the lack of IG NFT commerce by using her network to market her multi-piece collection.
"'Losing My Mind' is a long-running photo series. Wilson was preparing to release it as NFTs before IG approached him, so it was a perfect match.
Wilson says the series is about Black feminine figures and media depiction. Respectable effort, given POC artists have been underrepresented in NFT so far.
“Over the past year, I've had mental health concerns that made my emotions so severe it was impossible to function in daily life, therefore that prompted this photo series. Every Wednesday and Friday for three weeks, I'll release a new Meta photo for sale.
Wilson hopes these new IG capabilities will help develop a connection between the NFT community and other internet subcultures that thrive on Instagram.
“NFTs can look scary as an outsider, but seeing them on your daily IG feed makes it less foreign,” adds Wilson. I think Instagram might become a hub for NFT aficionados, making them more accessible to artists and collectors.
What does it all mean for the NFT space?
Meta's NFT and metaverse activities will continue to impact Instagram's NFT ecosystem. Many think it will be for the better, as IG NFT frauds are another problem hurting the NFT industry.
IG's new NFT features seem similar to Twitter's PFP NFT verifications, but Instagram's tools should help cut down on scams as users can now verify the creation and ownership of whole NFT collections included in IG posts.
Given the number of visual artists and NFT creators on IG, it might become another hub for NFT fans, as Wilson noted. If this happens, it raises questions about Instagram success. Will artists be incentivized to distribute NFTs? Or will those with a large fanbase dominate?
Elise Swopes (@swopes) believes these new features should benefit smaller artists. Swopes was one of the first profiles placed to Instagram's original suggested user list in 2012.
Swopes says she wants IG to be a magnet for discovery and understands the value of NFT artists and producers.
"I'd love to see IG become a focus of discovery for everyone, not just the Beeples and Apes and PFPs. That's terrific for them, but [IG NFT features] are more about using new technology to promote emerging artists, Swopes added.
“Especially music artists. It's everywhere. Dancers, writers, painters, sculptors, musicians. My element isn't just for digital artists; it can be anything. I'm delighted to witness people's creativity."
Swopes, Wilson, and Amrossi all believe IG's new features can help smaller artists. It remains to be seen how these new features will effect the NFT ecosystem once unlocked for the rest of the IG NFT community, but we will likely see more social media NFT integrations in the months and years ahead.
Read the full article here
Jamie Ducharme
3 years ago
How monkeypox spreads (and doesn't spread)
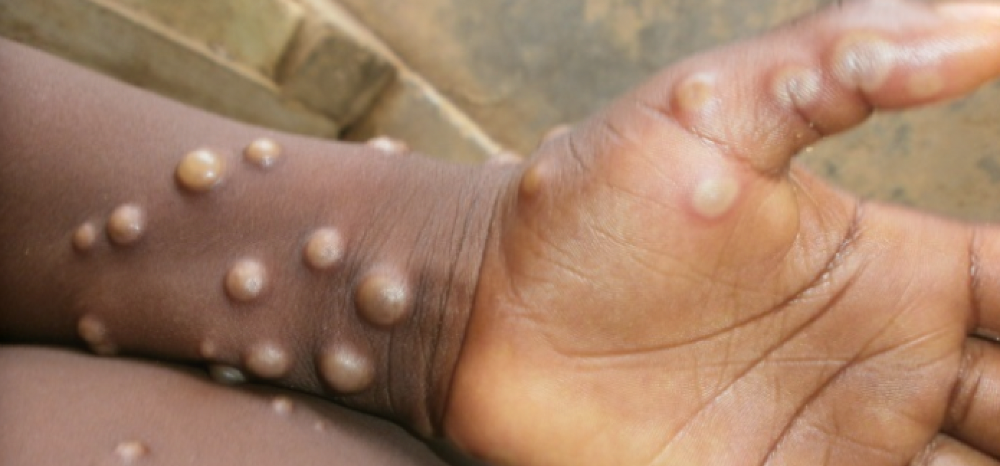
Monkeypox was rare until recently. In 2005, a research called a cluster of six monkeypox cases in the Republic of Congo "the longest reported chain to date."
That's changed. This year, over 25,000 monkeypox cases have been reported in 83 countries, indicating widespread human-to-human transmission.
What spreads monkeypox? Monkeypox transmission research is ongoing; findings may change. But science says...
Most cases were formerly animal-related.
According to the WHO, monkeypox was first diagnosed in an infant in the DRC in 1970. After that, instances were infrequent and often tied to animals. In 2003, 47 Americans contracted rabies from pet prairie dogs.
In 2017, Nigeria saw a significant outbreak. NPR reported that doctors diagnosed young guys without animal exposure who had genital sores. Nigerian researchers highlighted the idea of sexual transmission in a 2019 study, but the theory didn't catch on. “People tend to cling on to tradition, and the idea is that monkeypox is transmitted from animals to humans,” explains research co-author Dr. Dimie Ogoina.
Most monkeypox cases are sex-related.
Human-to-human transmission of monkeypox occurs, and sexual activity plays a role.
Joseph Osmundson, a clinical assistant professor of biology at NYU, says most transmission occurs in queer and gay sexual networks through sexual or personal contact.
Monkeypox spreads by skin-to-skin contact, especially with its blister-like rash, explains Ogoina. Researchers are exploring whether people can be asymptomatically contagious, but they are infectious until their rash heals and fresh skin forms, according to the CDC.
A July research in the New England Journal of Medicine reported that of more than 500 monkeypox cases in 16 countries as of June, 95% were linked to sexual activity and 98% were among males who have sex with men. WHO Director-General Tedros Adhanom Ghebreyesus encouraged males to temporarily restrict their number of male partners in July.
Is monkeypox a sexually transmitted infection (STI)?
Skin-to-skin contact can spread monkeypox, not simply sexual activities. Dr. Roy Gulick, infectious disease chief at Weill Cornell Medicine and NewYork-Presbyterian, said monkeypox is not a "typical" STI. Monkeypox isn't a STI, claims the CDC.
Most cases in the current outbreak are tied to male sexual behavior, but Osmundson thinks the virus might also spread on sports teams, in spas, or in college dorms.
Can you get monkeypox from surfaces?
Monkeypox can be spread by touching infected clothing or bedding. According to a study, a U.K. health care worker caught monkeypox in 2018 after handling ill patient's bedding.
Angela Rasmussen, a virologist at the University of Saskatchewan in Canada, believes "incidental" contact seldom distributes the virus. “You need enough virus exposure to get infected,” she says. It's conceivable after sharing a bed or towel with an infectious person, but less likely after touching a doorknob, she says.
Dr. Müge evik, a clinical lecturer in infectious diseases at the University of St. Andrews in Scotland, says there is a "spectrum" of risk connected with monkeypox. "Every exposure isn't equal," she explains. "People must know where to be cautious. Reducing [sexual] partners may be more useful than cleaning coffee shop seats.
Is monkeypox airborne?
Exposure to an infectious person's respiratory fluids can cause monkeypox, but the WHO says it needs close, continuous face-to-face contact. CDC researchers are still examining how often this happens.
Under precise laboratory conditions, scientists have shown that monkeypox can spread via aerosols, or tiny airborne particles. But there's no clear evidence that this is happening in the real world, Rasmussen adds. “This is expanding predominantly in communities of males who have sex with men, which suggests skin-to-skin contact,” she explains. If airborne transmission were frequent, she argues, we'd find more occurrences in other demographics.
In the shadow of COVID-19, people are worried about aerosolized monkeypox. Rasmussen believes the epidemiology is different. Different viruses.
Can kids get monkeypox?
More than 80 youngsters have contracted the virus thus far, mainly through household transmission. CDC says pregnant women can spread the illness to their fetus.
Among the 1970s, monkeypox predominantly affected children, but by the 2010s, it was more common in adults, according to a February study. The study's authors say routine smallpox immunization (which protects against monkeypox) halted when smallpox was eradicated. Only toddlers were born after smallpox vaccination halted decades ago. More people are vulnerable now.
Schools and daycares could become monkeypox hotspots, according to pediatric instances. Ogoina adds this hasn't happened in Nigeria's outbreaks, which is encouraging. He says, "I'm not sure if we should worry." We must be careful and seek evidence.

Peter Steven Ho
3 years ago
Thank You for 21 Fantastic Years, iPod
Apple's latest revelation may shock iPod fans and former owners.

Apple discontinued the iPod touch on May 11, 2022. After 21 years, Apple killed the last surviving iPod, a device Steve Jobs believed would revolutionize the music industry.
Jobs was used to making bold predictions, but few expected Apple's digital music player to change the music industry. It did.
This chaos created new business opportunities. Spotify, YouTube, and Amazon are products of that chaotic era.
As the digital landscape changes, so do consumers, and the iPod has lost favor. I'm sure Apple realizes the importance of removing an icon. The iPod was Apple like the Mac and iPhone. I think it's bold to retire such a key Apple cornerstone. What would Jobs do?
iPod evolution across the ages
Here's an iPod family tree for all you enthusiasts.

iPod vintage (Oct 2001 to Sep 2014, 6 generations)
The original iPod had six significant upgrades since 2001. Apple announced an 80 GB ($249) and 160 GB ($349) iPod classic in 2007.
Apple updated the 80 GB model with a 120 GB device in September 2008. Apple upgraded the 120 GB model with a 160 GB variant a year later (2009). This was the last iteration, and Apple discontinued the classic in September 2014.
iPod nano (Jan 2004 to Sep 2005, 2 generations)
Apple debuted a smaller, brightly-colored iPod in 2004. The first model featured 4 GB, enough for 1,000 songs.
Apple produced a new 4 GB or 6 GB iPod mini in February 2005 and discontinued it in September when they released a better-looking iPod nano.
iTouch nano (Sep 2005 to July 2017, 7 generations)
I loved the iPod nano. It was tiny and elegant with enough tech to please most music aficionados, unless you carry around your complete music collection.

Apple owed much of the iPod nano's small form and success to solid-state flash memory. Flash memory doesn't need power because it has no moving parts. This makes the iPod nano more durable than the iPod classic and mini, which employ hard drives.
Apple manufactured seven generations of the iPod nano, improving its design, display screen, memory, battery, and software, but abandoned it in July 2017 due to dwindling demand.
Shuffle iPod (Jan 2005 to Jul 2017, 4 generations)
The iPod shuffle was entry-level. It was a simple, lightweight, tiny music player. The iPod shuffle was perfect for lengthy bike trips, runs, and hikes.

Apple sold 10 million iPod shuffles in the first year and kept making them for 12 years, through four significant modifications.
iOS device (Sep 2007 to May 2022, 7 generations)
The iPod touch's bigger touchscreen interface made it a curious addition to the iPod family. The iPod touch resembled an iPhone more than the other iPods, making them hard to tell apart.
Many were dissatisfied that Apple removed functionality from the iPod touch to avoid making it too similar to the iPhone. Seven design improvements over 15 years brought the iPod touch closer to the iPhone, but not completely.
The iPod touch uses the same iOS operating system as the iPhone, giving it access to many apps, including handheld games.
The iPod touch's long production run is due to the next generation of music-loving gamers.
What made the iPod cool
iPod revolutionized music listening. It was the first device to store and play MP3 music, allowing you to carry over 1,000 songs anywhere.
The iPod changed consumer electronics with its scroll wheel and touchscreen. Jobs valued form and function equally. He showed people that a product must look good to inspire an emotional response and ignite passion.
The elegant, tiny iPod was a tremendous sensation when it arrived for $399 in October 2001. Even at this price, it became a must-have for teens to CEOs.
It's hard to identify any technology that changed how music was downloaded and played like the iPod. Apple iPod and iTunes had 63% of the paid music download market in the fourth quarter of 2012.
The demise of the iPod was inevitable
Apple discontinuing the iPod touch after 21 years is sad. This ends a 00s music icon.
Jobs was a genius at anticipating market needs and opportunities, and Apple launched the iPod at the correct time.
Few consumer electronics items have had such a lasting impact on music lovers and the music industry as the iPod.
Smartphones and social media have contributed to the iPod's decline. Instead of moving to the music, the new generation of consumers is focused on social media. They're no longer passive content consumers; they're active content creators seeking likes and followers. Here, the smartphone has replaced the iPod.
It's hard not to feel a feeling of loss, another part of my adolescence now forgotten by the following generation.
So, if you’re lucky enough to have a working iPod, hang on to that relic and enjoy the music and the nostalgia.