


Why I Love Azuki
Azuki Banner (www.azuki.com)
Disclaimer: This is my personal viewpoint. I'm not on the Azuki team. Please keep in mind that I am merely a fan, community member, and holder. Please do your own research and pardon my grammar. Thanks!
Azuki has changed my view of NFTs.
When I first entered the NFT world, I had no idea what to expect. I liked the idea. So I invested in some projects, fought for whitelists, and discovered some cool NFTs projects (shout-out to CATC). I lost more money than I earned at one point, but I hadn't invested excessively (only put in what you can afford to lose). Despite my losses, I kept looking. I almost waited for the “ah-ha” moment. A NFT project that changed my perspective on NFTs. What makes an NFT project more than a work of art?
Answer: Azuki.
The Art
The Azuki art drew me in as an anime fan. It looked like something out of an anime, and I'd never seen it before in NFT.
The project was still new. The first two animated teasers were released with little fanfare, but I was impressed with their quality. You can find them on Instagram or in their earlier Tweets.
The teasers hinted that this project could be big and that the team could deliver. It was amazing to see Shao cut the Azuki posters with her katana. Especially at the end when she sheaths her sword and the music cues. Then the live action video of the young boy arranging the Azuki posters seemed movie-like. I felt like I was entering the Azuki story, brand, and dope theme.
The team did not disappoint with the Azuki NFTs. The level of detail in the art is stunning. There were Azukis of all genders, skin and hair types, and more. These 10,000 Azukis have so much representation that almost anyone can find something that resonates. Rather than me rambling on, I suggest you visit the Azuki gallery
The Team
If the art is meant to draw you in and be the project's face, the team makes it more. The NFT would be a JPEG without a good team leader. Not that community isn't important, but no community would rally around a bad team.
Because I've been rugged before, I'm very focused on the team when considering a project. While many project teams are anonymous, I try to find ones that are doxxed (public) or at least appear to be established. Unlike Azuki, where most of the Azuki team is anonymous, Steamboy is public. He is (or was) Overwatch's character art director and co-creator of Azuki. I felt reassured and could trust the project after seeing someone from a major game series on the team.
Then I tried to learn as much as I could about the team. Following everyone on Twitter, reading their tweets, and listening to recorded AMAs. I was impressed by the team's professionalism and dedication to their vision for Azuki, led by ZZZAGABOND.
I believe the phrase “actions speak louder than words” applies to Azuki. I can think of a few examples of what the Azuki team has done, but my favorite is ERC721A.
With ERC721A, Azuki has created a new algorithm that allows minting multiple NFTs for essentially the same cost as minting one NFT.
I was ecstatic when the dev team announced it. This fascinates me as a self-taught developer. Azuki released a product that saves people money, improves the NFT space, and is open source. It showed their love for Azuki and the NFT community.
The Community
Community, community, community. It's almost a chant in the NFT space now. A community, like a team, can make or break a project. We are the project's consumers, shareholders, core, and lifeblood. The team builds the house, and we fill it. We stay for the community.
When I first entered the Azuki Discord, I was surprised by the calm atmosphere. There was no news about the project. No release date, no whitelisting requirements. No grinding or spamming either. People just wanted to hangout, get to know each other, and talk. It was nice. So the team could pick genuine people for their mintlist (aka whitelist).
But nothing fundamental has changed since the release. It has remained an authentic, fun, and helpful community. I'm constantly logging into Discord to chat with others or follow conversations. I see the community's openness to newcomers. Everyone respects each other (barring a few bad apples) and the variety of people passing through is fascinating. This human connection and interaction is what I enjoy about this place. Being a part of a group that supports a cause.
Finally, I want to thank the amazing Azuki mod team and the kissaten channel for their contributions.
The Brand
So, what sets Azuki apart from other projects? They are shaping a brand or identity. The Azuki website, I believe, best captures their vision. (This is me gushing over the site.)
If you go to the website, turn on the dope playlist in the bottom left. The playlist features a mix of Asian and non-Asian hip-hop and rap artists, with some lo-fi thrown in. The songs on the playlist change, but I think you get the vibe Azuki embodies just by turning on the music.
The Garden is our next stop where we are introduced to Azuki.
A brand.
We're creating a new brand together.
A metaverse brand. By the people.
A collection of 10,000 avatars that grant Garden membership. It starts with exclusive streetwear collabs, NFT drops, live events, and more. Azuki allows for a new media genre that the world has yet to discover. Let's build together an Azuki, your metaverse identity.
The Garden is a magical internet corner where art, community, and culture collide. The boundaries between the physical and digital worlds are blurring.
Try a Red Bean.
The text begins with Azuki's intention in the space. It's a community-made metaverse brand. Then it goes into more detail about Azuki's plans. Initiation of a story or journey. "Would you like to take the red bean and jump down the rabbit hole with us?" I love the Matrix red pill or blue pill play they used. (Azuki in Japanese means red bean.)
Morpheus, the rebel leader, offers Neo the choice of a red or blue pill in The Matrix. “You take the blue pill... After the story, you go back to bed and believe whatever you want. Your red pill... Let me show you how deep the rabbit hole goes.” Aware that the red pill will free him from the enslaving control of the machine-generated dream world and allow him to escape into the real world, he takes it. However, living the “truth of reality” is harsher and more difficult.
It's intriguing and draws you in. Taking the red bean causes what? Where am I going? I think they did well in piqueing a newcomer's interest.
Not convinced by the Garden? Read the Manifesto. It reinforces Azuki's role.
Here comes a new wave…
And surfing here is different.
Breaking down barriers.
Building open communities.
Creating magic internet money with our friends.
To those who don’t get it, we tell them: gm.
They’ll come around eventually.
Here’s to the ones with the courage to jump down a peculiar rabbit hole.
One that pulls you away from a world that’s created by many and owned by few…
To a world that’s created by more and owned by all.
From The Garden come the human beans that sprout into your family.
We rise together.
We build together.
We grow together.
Ready to take the red bean?
Not to mention the Mindmap, it sets Azuki apart from other projects and overused Roadmaps. I like how the team recognizes that the NFT space is not linear. So many of us are still trying to figure it out. It is Azuki's vision to adapt to changing environments while maintaining their values. I admire their commitment to long-term growth.
Conclusion
To be honest, I have no idea what the future holds. Azuki is still new and could fail. But I'm a long-term Azuki fan. I don't care about quick gains. The future looks bright for Azuki. I believe in the team's output. I love being an Azuki.
Thank you! IKUZO!
Full post here

Sam Hickmann
4 years ago
+1 💪
More on NFTs & Art

nft now
4 years ago
Instagram NFTs Are Here… How does this affect artists?
Instagram (IG) is officially joining NFT. With the debut of new in-app NFT functionalities, influential producers can interact with blockchain tech on the social media platform.
Meta unveiled intentions for an Instagram NFT marketplace in March, but these latest capabilities focus more on content sharing than commerce. And why shouldn’t they? IG's entry into the NFT market is overdue, given that Twitter and Discord are NFT hotspots.
The NFT marketplace/Web3 social media race has continued to expand, with the expected Coinbase NFT Beta now live and blazing a trail through the NFT ecosystem.
IG's focus is on visual art. It's unlike any NFT marketplace or platform. IG NFTs and artists: what's the deal? Let’s take a look.
What are Instagram’s NFT features anyways?
As said, not everyone has Instagram's new features. 16 artists, NFT makers, and collectors can now post NFTs on IG by integrating third-party digital wallets (like Rainbow or MetaMask) in-app. IG doesn't charge to publish or share digital collectibles.
NFTs displayed on the app have a "shimmer" aesthetic effect. NFT posts also have a "digital collectable" badge that lists metadata such as the creator and/or owner, the platform it was created on, a brief description, and a blockchain identification.
Meta's social media NFTs have launched on Instagram, but the company is also preparing to roll out digital collectibles on Facebook, with more on the way for IG. Currently, only Ethereum and Polygon are supported, but Flow and Solana will be added soon.
How will artists use these new features?
Artists are publishing NFTs they developed or own on IG by linking third-party digital wallets. These features have no NFT trading aspects built-in, but are aimed to let authors share NFTs with IG audiences.
Creators, like IG-native aerial/street photographer Natalie Amrossi (@misshattan), are discovering novel uses for IG NFTs.
Amrossi chose to not only upload his own NFTs but also encourage other artists in the field. "That's the beauty of connecting your wallet and sharing NFTs. It's not just what you make, but also what you accumulate."
Amrossi has been producing and posting Instagram art for years. With IG's NFT features, she can understand Instagram's importance in supporting artists.
Web2 offered Amrossi the tools to become an artist and make a life. "Before 'influencer' existed, I was just making art. Instagram helped me reach so many individuals and brands, giving me a living.
Even artists without millions of viewers are encouraged to share NFTs on IG. Wilson, a relatively new name in the NFT space, seems to have already gone above and beyond the scope of these new IG features. By releasing "Losing My Mind" via IG NFT posts, she has evaded the lack of IG NFT commerce by using her network to market her multi-piece collection.
"'Losing My Mind' is a long-running photo series. Wilson was preparing to release it as NFTs before IG approached him, so it was a perfect match.
Wilson says the series is about Black feminine figures and media depiction. Respectable effort, given POC artists have been underrepresented in NFT so far.
“Over the past year, I've had mental health concerns that made my emotions so severe it was impossible to function in daily life, therefore that prompted this photo series. Every Wednesday and Friday for three weeks, I'll release a new Meta photo for sale.
Wilson hopes these new IG capabilities will help develop a connection between the NFT community and other internet subcultures that thrive on Instagram.
“NFTs can look scary as an outsider, but seeing them on your daily IG feed makes it less foreign,” adds Wilson. I think Instagram might become a hub for NFT aficionados, making them more accessible to artists and collectors.
What does it all mean for the NFT space?
Meta's NFT and metaverse activities will continue to impact Instagram's NFT ecosystem. Many think it will be for the better, as IG NFT frauds are another problem hurting the NFT industry.
IG's new NFT features seem similar to Twitter's PFP NFT verifications, but Instagram's tools should help cut down on scams as users can now verify the creation and ownership of whole NFT collections included in IG posts.
Given the number of visual artists and NFT creators on IG, it might become another hub for NFT fans, as Wilson noted. If this happens, it raises questions about Instagram success. Will artists be incentivized to distribute NFTs? Or will those with a large fanbase dominate?
Elise Swopes (@swopes) believes these new features should benefit smaller artists. Swopes was one of the first profiles placed to Instagram's original suggested user list in 2012.
Swopes says she wants IG to be a magnet for discovery and understands the value of NFT artists and producers.
"I'd love to see IG become a focus of discovery for everyone, not just the Beeples and Apes and PFPs. That's terrific for them, but [IG NFT features] are more about using new technology to promote emerging artists, Swopes added.
“Especially music artists. It's everywhere. Dancers, writers, painters, sculptors, musicians. My element isn't just for digital artists; it can be anything. I'm delighted to witness people's creativity."
Swopes, Wilson, and Amrossi all believe IG's new features can help smaller artists. It remains to be seen how these new features will effect the NFT ecosystem once unlocked for the rest of the IG NFT community, but we will likely see more social media NFT integrations in the months and years ahead.
Read the full article here

Abhimanyu Bhargava
3 years ago
VeeFriends Series 2: The Biggest NFT Opportunity Ever
VeeFriends is one NFT project I'm sure will last.

I believe in blockchain technology and JPEGs, aka NFTs. NFTs aren't JPEGs. It's not as it seems.
Gary Vaynerchuk is leading the pack with his new NFT project VeeFriends, I wrote a year ago. I was spot-on. It's the most innovative project I've seen.
Since its minting in May 2021, it has given its holders enormous value, most notably the first edition of VeeCon, a multi-day superconference featuring iconic and emerging leaders in NFTs and Popular Culture. First-of-its-kind NFT-ticketed Web3 conference to build friendships, share ideas, and learn together.
VeeFriends holders got free VeeCon NFT tickets. Attendees heard iconic keynote speeches, innovative talks, panels, and Q&A sessions.
It was a unique conference that most of us, including me, are looking forward to in 2023. The lineup was epic, and it allowed many to network in new ways. Really memorable learning. Here are a couple of gratitude posts from the attendees.
VeeFriends Series 2
This article explains VeeFriends if you're still confused.
GaryVee's hand-drawn doodles have evolved into wonderful characters. The characters' poses and backgrounds bring the VeeFriends IP to life.

Yes, this is the second edition of VeeFriends, and at current prices, it's one of the best NFT opportunities in years. If you have the funds and risk appetite to invest in NFTs, VeeFriends Series 2 is worth every penny. Even if you can't invest, learn from their journey.
1. Art Is the Start
Many critics say VeeFriends artwork is below average and not by GaryVee. Art is often the key to future success.
Let's look at one of the first Mickey Mouse drawings. No one would have guessed that this would become one of the most beloved animated short film characters. In Walt Before Mickey, Walt Disney's original mouse Mortimer was less refined.
First came a mouse...

These sketches evolved into Steamboat Willie, Disney's first animated short film.

Fred Moore redesigned the character artwork into what we saw in cartoons as kids. Mickey Mouse's history is here.

Looking at how different cartoon characters have evolved and gained popularity over decades, I believe Series 2 characters like Self-Aware Hare, Kind Kudu, and Patient Pig can do the same.

GaryVee captures this journey on the blockchain and lets early supporters become part of history. Time will tell if it rivals Disney, Pokemon, or Star Wars. Gary has been vocal about this vision.
2. VeeFriends is Intellectual Property for the Coming Generations
Most of us grew up watching cartoons, playing with toys, cards, and video games. Our interactions with fictional characters and the stories we hear shape us.
GaryVee is slowly curating an experience for the next generation with animated videos, card games, merchandise, toys, and more.
VeeFriends UNO, a collaboration with Mattel Creations, features 17 VeeFriends characters.
VeeFriends and Zerocool recently released Trading Cards featuring all 268 Series 1 characters and 15 new ones. Another way to build VeeFriends' collectibles brand.

At Veecon, all the characters were collectible toys. Something will soon emerge.
Kids and adults alike enjoy the YouTube channel's animated shorts and VeeFriends Tunes. Here's a song by the holder's Optimistic Otter-loving daughter.
This VeeFriends story is only the beginning. I'm looking forward to animated short film series, coloring books, streetwear, candy, toys, physical collectibles, and other forms of VeeFriends IP.
3. Veefriends will always provide utilities
Smart contracts can be updated at any time and authenticated on a ledger.
VeeFriends Series 2 gives no promise of any utility whatsoever. GaryVee released no project roadmap. In the first few months after launch, many owners of specific characters or scenes received utilities.
Every benefit or perk you receive helps promote the VeeFriends brand.
Recent partnerships are listed below.
MaryRuth's Multivitamin Gummies
Productive Puffin holders from VeeFriends x Primitive
Pickleball Scene & Clown Holders Only

Pickleball & Competitive Clown Exclusive experience, anteater multivitamin gummies, and Puffin x Primitive merch
Considering the price of NFTs, it may not seem like much. It's just the beginning; you never know what the future holds. No other NFT project offers such diverse, ongoing benefits.
4. Garyvee's team is ready
Gary Vaynerchuk's team and record are undisputed. He's a serial entrepreneur and the Chairman & CEO of VaynerX, which includes VaynerMedia, VaynerCommerce, One37pm, and The Sasha Group.
Gary founded VaynerSports, Resy, and Empathy Wines. He's a Candy Digital Board Member, VCR Group Co-Founder, ArtOfficial Co-Founder, and VeeFriends Creator & CEO. Gary was recently named one of Fortune's Top 50 NFT Influencers.

Gary Vayenerchuk aka GaryVee
Gary documents his daily life as a CEO on social media, which has 34 million followers and 272 million monthly views. GaryVee Audio Experience is a top podcast. He's a five-time New York Times best-seller and sought-after speaker.
Gary can observe consumer behavior to predict trends. He understood these trends early and pioneered them.
1997 — Realized e-potential commerce's and started winelibrary.com. In five years, he grew his father's wine business from $3M to $60M.
2006 — Realized content marketing's potential and started Wine Library on YouTube. TV
2009 — Estimated social media's potential (Web2) and invested in Facebook, Twitter, and Tumblr.
2014: Ethereum and Bitcoin investments
2021 — Believed in NFTs and Web3 enough to launch VeeFriends
GaryVee isn't all of VeeFriends. Andy Krainak, Dave DeRosa, Adam Ripps, Tyler Dowdle, and others work tirelessly to make VeeFriends a success.
GaryVee has said he'll let other businesses fail but not VeeFriends. We're just beginning his 40-year vision.
I have more confidence than ever in a company with a strong foundation and team.
5. Humans die, but characters live forever
What if GaryVee dies or can't work?
A writer's books can immortalize them. As long as their books exist, their words are immortal. Socrates, Hemingway, Aristotle, Twain, Fitzgerald, and others have become immortal.
Everyone knows Vincent Van Gogh's The Starry Night.
We all love reading and watching Peter Parker, Thor, or Jessica Jones. Their behavior inspires us. Stan Lee's message and stories live on despite his death.
GaryVee represents VeeFriends. Creating characters to communicate ensures that the message reaches even those who don't listen.
Gary wants his values and messages to be omnipresent in 268 characters. Messengers die, but their messages live on.
Gary envisions VeeFriends creating timeless stories and experiences. Ten years from now, maybe every kid will sing Patient Pig.
6. I love the intent.
Gary planned to create Workplace Warriors three years ago when he began designing Patient Panda, Accountable Ant, and Empathy elephant. The project stalled. When NFTs came along, he knew.
Gary wanted to create characters with traits he values, such as accountability, empathy, patience, kindness, and self-awareness. He wants future generations to find these traits cool. He hopes one or more of his characters will become pop culture icons.
These emotional skills aren't taught in schools or colleges, but they're crucial for business and life success. I love that someone is teaching this at scale.
In the end, intent matters.
Humans Are Collectors
Buy and collect things to communicate. Since the 1700s. Medieval people formed communities around hidden metals and stones. Many people still collect stamps and coins, and luxury and fashion are multi-trillion dollar industries. We're collectors.
The early 2020s NFTs will be remembered in the future. VeeFriends will define a cultural and technological shift in this era. VeeFriends Series 1 is the original hand-drawn art, but it's expensive. VeeFriends Series 2 is a once-in-a-lifetime opportunity at $1,000.
If you are new to NFTs, check out How to Buy a Non Fungible Token (NFT) For Beginners
This is a non-commercial article. Not financial or legal advice. Information isn't always accurate. Before making important financial decisions, consult a pro or do your own research.
This post is a summary. Read the full article here

Jake Prins
3 years ago
What are NFTs 2.0 and what issues are they meant to address?
New standards help NFTs reach their full potential.

NFTs lack interoperability and functionality. They have great potential but are mostly speculative. To maximize NFTs, we need flexible smart contracts.
Current requirements are too restrictive.
Most NFTs are based on ERC-721, which makes exchanging them easy. CryptoKitties, a popular online game, used the 2017 standard to demonstrate NFTs' potential.
This simple standard includes a base URI and incremental IDs for tokens. Add the tokenID to the base URI to get the token's metadata.
This let creators collect NFTs. Many NFT projects store metadata on IPFS, a distributed storage network, but others use Google Drive. NFT buyers often don't realize that if the creators delete or move the files, their NFT is just a pointer.
This isn't the standard's biggest issue. There's no way to validate NFT projects.
Creators are one of the most important aspects of art, but nothing is stored on-chain.
ERC-721 contracts only have a name and symbol.
Most of the data on OpenSea's collection pages isn't from the NFT's smart contract. It was added through a platform input field, so it's in the marketplace's database. Other websites may have different NFT information.
In five years, your NFT will be just a name, symbol, and ID.
Your NFT doesn't mention its creators. Although the smart contract has a public key, it doesn't reveal who created it.
The NFT's creators and their reputation are crucial to its value. Think digital fashion and big brands working with well-known designers when more professionals use NFTs. Don't you want them in your NFT?
Would paintings be as valuable if their artists were unknown? Would you believe it's real?
Buying directly from an on-chain artist would reduce scams. Current standards don't allow this data.
Most creator profiles live on centralized marketplaces and could disappear. Current platforms have outpaced underlying standards. The industry's standards are lagging.
For NFTs to grow beyond pointers to a monkey picture file, we may need to use new Web3-based standards.
Introducing NFTs 2.0
Fabian Vogelsteller, creator of ERC-20, developed new web3 standards. He proposed LSP7 Digital Asset and LSP8 Identifiable Digital Asset, also called NFT 2.0.
NFT and token metadata inputs are extendable. Changes to on-chain metadata inputs allow NFTs to evolve. Instead of public keys, the contract can have Universal Profile addresses attached. These profiles show creators' faces and reputations. NFTs can notify asset receivers, automating smart contracts.
LSP7 and LSP8 use ERC725Y. Using a generic data key-value store gives contracts much-needed features:
The asset can be customized and made to stand out more by allowing for unlimited data attachment.
Recognizing changes to the metadata
using a hash reference for metadata rather than a URL reference
This base will allow more metadata customization and upgradeability. These guidelines are:
Genuine and Verifiable Now, the creation of an NFT by a specific Universal Profile can be confirmed by smart contracts.
Dynamic NFTs can update Flexible & Updatable Metadata, allowing certain things to evolve over time.
Protected metadata Now, secure metadata that is readable by smart contracts can be added indefinitely.
Better NFTS prevent the locking of NFTs by only being sent to Universal Profiles or a smart contract that can interact with them.
Summary
NFTS standards lack standardization and powering features, limiting the industry.
ERC-721 is the most popular NFT standard, but it only represents incremental tokenIDs without metadata or asset representation. No standard sender-receiver interaction or security measures ensure safe asset transfers.
NFT 2.0 refers to the new LSP7-DigitalAsset and LSP8-IdentifiableDigitalAsset standards.
They have new standards for flexible metadata, secure transfers, asset representation, and interactive transfer.
With NFTs 2.0 and Universal Profiles, creators could build on-chain reputations.
NFTs 2.0 could bring the industry's needed innovation if it wants to move beyond trading profile pictures for speculation.
You might also like

Niharikaa Kaur Sodhi
3 years ago
The Only Paid Resources I Turn to as a Solopreneur

4 Pricey Tools That Are Valuable
I pay based on ROI (return on investment).
If a $20/month tool or $500 online course doubles my return, I'm in.
Investing helps me build wealth.
Canva Pro
I initially refused to pay.
My course content needed updating a few months ago. My Google Docs text looked cleaner and more professional in Canva.
I've used it to:
product cover pages
eBook covers
Product page infographics
See my Google Sheets vs. Canva product page graph.
Google Sheets vs Canva
Yesterday, I used it to make a LinkedIn video thumbnail. It took less than 5 minutes and improved my video.

In 30 hours, the video had 39,000 views.
Here's more.
HypeFury
Hypefury rocks!
It builds my brand as I sleep. What else?
Because I'm traveling this weekend, I planned tweets for 10 days. It took me 80 minutes.
So while I travel or am absent, my content mill keeps producing.
Also I like:
I can reach hundreds of people thanks to auto-DMs. I utilize it to advertise freebies; for instance, leave an emoji remark to receive my checklist. And they automatically receive a message in their DM.
Scheduled Retweets: By appearing in a different time zone, they give my tweet a second chance.
It helps me save time and expand my following, so that's my favorite part.
It’s also super neat:
Zoom Pro
My course involves weekly and monthly calls for alumni.
Google Meet isn't great for group calls. The interface isn't great.
Zoom Pro is expensive, and the monthly payments suck, but it's necessary.
It gives my students a smooth experience.
Previously, we'd do 40-minute meetings and then reconvene.
Zoom's free edition limits group calls to 40 minutes.
This wouldn't be a good online course if I paid hundreds of dollars.
So I felt obligated to help.
YouTube Premium
My laptop has an ad blocker.
I bought an iPad recently.
When you're self-employed and work from home, the line between the two blurs. My bed is only 5 steps away!
When I read or watched videos on my laptop, I'd slide into work mode. Only option was to view on phone, which is awkward.
YouTube premium handles it. No more advertisements and I can listen on the move.
3 Expensive Tools That Aren't Valuable
Marketing strategies are sometimes aimed to make you feel you need 38474 cool features when you don’t.
Certain tools are useless.
I found it useless.
Depending on your needs. As a writer and creator, I get no return.
They could for other jobs.
Shield Analytics
It tracks LinkedIn stats, like:
follower growth
trend chart for impressions
Engagement, views, and comment stats for posts
and much more.
Middle-tier creator costs $12/month.
I got a 25% off coupon but canceled my free trial before writing this. It's not worth the discount.
Why?
LinkedIn provides free analytics. See:
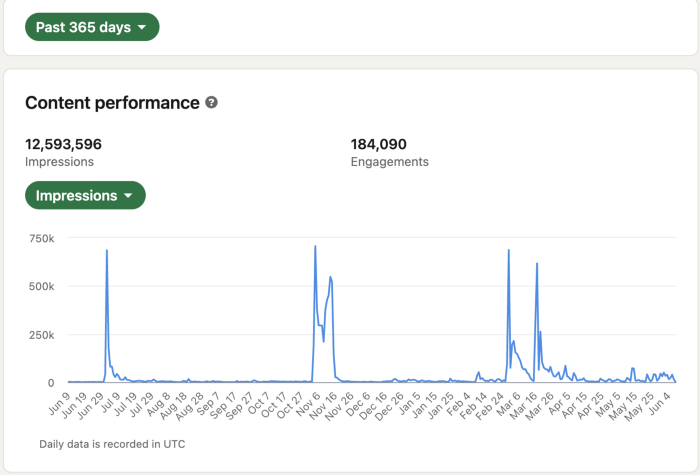
Not thorough and won't show top posts.
I don't need to see my top posts because I love experimenting with writing.
Slack Premium
Slack was my classroom. Slack provided me a premium trial during the prior cohort.
I skipped it.
Sure, voice notes are better than a big paragraph. I didn't require pro features.
Marketing methods sometimes make you think you need 38474 amazing features. Don’t fall for it.
Calendly Pro
This may be worth it if you get many calls.
I avoid calls. During my 9-5, I had too many pointless calls.
I don't need:
ability to schedule calls for 15, 30, or 60 minutes: I just distribute each link separately.
I have a Gumroad consultation page with a payment option.
follow-up emails: I hardly ever make calls, so
I just use one calendar, therefore I link to various calendars.
I'll admit, the integrations are cool. Not for me.
If you're a coach or consultant, the features may be helpful. Or book meetings.
Conclusion
Investing is spending to make money.
Use my technique — put money in tools that help you make money. This separates it from being an investment instead of an expense.
Try free versions of these tools before buying them since everyone else is.

James Howell
4 years ago
Which Metaverse Is Better, Decentraland or Sandbox?
The metaverse is the most commonly used term in current technology discussions. While the entire tech ecosystem awaits the metaverse's full arrival, defining it is difficult. Imagine the internet in the '80s! The metaverse is a three-dimensional virtual world where users can interact with digital solutions and each other as digital avatars.
The metaverse is a three-dimensional virtual world where users can interact with digital solutions and each other as digital avatars.
Among the metaverse hype, the Decentraland vs Sandbox debate has gained traction. Both are decentralized metaverse platforms with no central authority. So, what's the difference and which is better? Let us examine the distinctions between Decentraland and Sandbox.
2 Popular Metaverse Platforms Explained
The first step in comparing sandbox and Decentraland is to outline the definitions. Anyone keeping up with the metaverse news has heard of the two current leaders. Both have many similarities, but also many differences. Let us start with defining both platforms to see if there is a winner.
Decentraland
Decentraland, a fully immersive and engaging 3D metaverse, launched in 2017. It allows players to buy land while exploring the vast virtual universe. Decentraland offers a wide range of activities for its visitors, including games, casinos, galleries, and concerts. It is currently the longest-running metaverse project.
Decentraland began with a $24 million ICO and went public in 2020. The platform's virtual real estate parcels allow users to create a variety of experiences. MANA and LAND are two distinct tokens associated with Decentraland. MANA is the platform's native ERC-20 token, and users can burn MANA to get LAND, which is ERC-721 compliant. The MANA coin can be used to buy avatars, wearables, products, and names on Decentraland.
Sandbox
Sandbox, the next major player, began as a blockchain-based virtual world in 2011 and migrated to a 3D gaming platform in 2017. The virtual world allows users to create, play, own, and monetize their virtual experiences. Sandbox aims to empower artists, creators, and players in the blockchain community to customize the platform. Sandbox gives the ideal means for unleashing creativity in the development of the modern gaming ecosystem.
The project combines NFTs and DAOs to empower a growing community of gamers. A new play-to-earn model helps users grow as gamers and creators. The platform offers a utility token, SAND, which is required for all transactions.
What are the key points from both metaverse definitions to compare Decentraland vs sandbox?
It is ideal for individuals, businesses, and creators seeking new artistic, entertainment, and business opportunities. It is one of the rapidly growing Decentralized Autonomous Organization projects. Holders of MANA tokens also control the Decentraland domain.
Sandbox, on the other hand, is a blockchain-based virtual world that runs on the native token SAND. On the platform, users can create, sell, and buy digital assets and experiences, enabling blockchain-based gaming. Sandbox focuses on user-generated content and building an ecosystem of developers.
Sandbox vs. Decentraland
If you try to find what is better Sandbox or Decentraland, then you might struggle with only the basic definitions. Both are metaverse platforms offering immersive 3D experiences. Users can freely create, buy, sell, and trade digital assets. However, both have significant differences, especially in MANA vs SAND.
For starters, MANA has a market cap of $5,736,097,349 versus $4,528,715,461, giving Decentraland an advantage.
The MANA vs SAND pricing comparison is also noteworthy. A SAND is currently worth $3664, while a MANA is worth $2452.
The value of the native tokens and the market capitalization of the two metaverse platforms are not enough to make a choice. Let us compare Sandbox vs Decentraland based on the following factors.
Workstyle
The way Decentraland and Sandbox work is one of the main comparisons. From a distance, they both appear to work the same way. But there's a lot more to learn about both platforms' workings. Decentraland has 90,601 digital parcels of land.
Individual parcels of virtual real estate or estates with multiple parcels of land are assembled. It also has districts with similar themes and plazas, which are non-tradeable parcels owned by the community. It has three token types: MANA, LAND, and WEAR.
Sandbox has 166,464 plots of virtual land that can be grouped into estates. Estates are owned by one person, while districts are owned by two or more people. The Sandbox metaverse has four token types: SAND, GAMES, LAND, and ASSETS.
Age
The maturity of metaverse projects is also a factor in the debate. Decentraland is clearly the winner in terms of maturity. It was the first solution to create a 3D blockchain metaverse. Decentraland made the first working proof of concept public. However, Sandbox has only made an Alpha version available to the public.
Backing
The MANA vs SAND comparison would also include support for both platforms. Digital Currency Group, FBG Capital, and CoinFund are all supporters of Decentraland. It has also partnered with Polygon, the South Korean government, Cyberpunk, and Samsung.
SoftBank, a Japanese multinational conglomerate focused on investment management, is another major backer. Sandbox has the backing of one of the world's largest investment firms, as well as Slack and Uber.
Compatibility
Wallet compatibility is an important factor in comparing the two metaverse platforms. Decentraland currently has a competitive advantage. How? Both projects' marketplaces accept ERC-20 wallets. However, Decentraland has recently improved by bridging with Walletconnect. So it can let Polygon users join Decentraland.
Scalability
Because Sandbox and Decentraland use the Ethereum blockchain, scalability is an issue. Both platforms' scalability is constrained by volatile tokens and high gas fees. So, scalability issues can hinder large-scale adoption of both metaverse platforms.
Buying Land
Decentraland vs Sandbox comparisons often include virtual real estate. However, the ability to buy virtual land on both platforms defines the user experience and differentiates them. In this case, Sandbox offers better options for users to buy virtual land by combining OpenSea and Sandbox. In fact, Decentraland users can only buy from the MANA marketplace.
Innovation
The rate of development distinguishes Sandbox and Decentraland. Both platforms have been developing rapidly new features. However, Sandbox wins by adopting Polygon NFT layer 2 solutions, which consume almost 100 times less energy than Ethereum.
Collaborations
The platforms' collaborations are the key to determining "which is better Sandbox or Decentraland." Adoption of metaverse platforms like the two in question can be boosted by association with reputable brands. Among the partners are Atari, Cyberpunk, and Polygon. Rather, Sandbox has partnered with well-known brands like OpenSea, CryptoKitties, The Walking Dead, Snoop Dogg, and others.
Platform Adaptivity
Another key feature that distinguishes Sandbox and Decentraland is the ease of use. Sandbox clearly wins in terms of platform access. It allows easy access via social media, email, or a Metamask wallet. However, Decentraland requires a wallet connection.
Prospects
The future development plans also play a big role in defining Sandbox vs Decentraland. Sandbox's future development plans include bringing the platform to mobile devices. This includes consoles like PlayStation and Xbox. By the end of 2023, the platform expects to have around 5000 games.
Decentraland, on the other hand, has no set plan. In fact, the team defines the decisions that appear to have value. They plan to add celebrities, creators, and brands soon, along with NFT ads and drops.
Final Words
The comparison of Decentraland vs Sandbox provides a balanced view of both platforms. You can see how difficult it is to determine which decentralized metaverse is better now. Sandbox is still in Alpha, whereas Decentraland has a working proof of concept.
Sandbox, on the other hand, has better graphics and is backed by some big names. But both have a long way to go in the larger decentralized metaverse.

Simon Egersand
3 years ago
Working from home for more than two years has taught me a lot.
Since the pandemic, I've worked from home. It’s been +2 years (wow, time flies!) now, and during this time I’ve learned a lot. My 4 remote work lessons.
I work in a remote distributed team. This team setting shaped my experience and teachings.
Isolation ("I miss my coworkers")
The most obvious point. I miss going out with my coworkers for coffee, weekend chats, or just company while I work. I miss being able to go to someone's desk and ask for help. On a remote world, I must organize a meeting, share my screen, and avoid talking over each other in Zoom - sigh!
Social interaction is more vital for my health than I believed.
Online socializing stinks
My company used to come together every Friday to play Exploding Kittens, have food and beer, and bond over non-work things.
Different today. Every Friday afternoon is for fun, but it's not the same. People with screen weariness miss meetings, which makes sense. Sometimes you're too busy on Slack to enjoy yourself.
We laugh in meetings, but it's not the same as face-to-face.
Digital social activities can't replace real-world ones
Improved Work-Life Balance, if You Let It
At the outset of the pandemic, I recognized I needed to take better care of myself to survive. After not leaving my apartment for a few days and feeling miserable, I decided to walk before work every day. This turned into a passion for exercise, and today I run or go to the gym before work. I use my commute time for healthful activities.
Working from home makes it easier to keep working after hours. I sometimes forget the time and find myself writing coding at dinnertime. I said, "One more test." This is a disadvantage, therefore I keep my office schedule.
Spend your commute time properly and keep to your office schedule.
Remote Pair Programming Is Hard
As a software developer, I regularly write code. My team sometimes uses pair programming to write code collaboratively. One person writes code while another watches, comments, and asks questions. I won't list them all here.
Internet pairing is difficult. My team struggles with this. Even with Tuple, it's challenging. I lose attention when I get a notification or check my computer.
I miss a pen and paper to rapidly sketch down my thoughts for a colleague or a whiteboard for spirited talks with others. Best answers are found through experience.
Real-life pair programming beats the best remote pair programming tools.
Lessons Learned
Here are 4 lessons I've learned working remotely for 2 years.
-
Socializing is more vital to my health than I anticipated.
-
Digital social activities can't replace in-person ones.
-
Spend your commute time properly and keep your office schedule.
-
Real-life pair programming beats the best remote tools.
Conclusion
Our era is fascinating. Remote labor has existed for years, but software companies have just recently had to adapt. Companies who don't offer remote work will lose talent, in my opinion.
We're still figuring out the finest software development approaches, programming language features, and communication methods since the 1960s. I can't wait to see what advancements assist us go into remote work.
I'll certainly work remotely in the next years, so I'm interested to see what I've learnt from this post then.
This post is a summary of this one.