


Expulsion of ten million Ukrainians
According to recent data from two UN agencies, ten million Ukrainians have been displaced.
The International Organization for Migration (IOM) estimates nearly 6.5 million Ukrainians have relocated. Most have fled the war zones around Kyiv and eastern Ukraine, including Dnipro, Zhaporizhzhia, and Kharkiv. Most IDPs have fled to western and central Ukraine.
Since Russia invaded on Feb. 24, 3.6 million people have crossed the border to seek refuge in neighboring countries, according to the latest UN data. While most refugees have fled to Poland and Romania, many have entered Russia.
Internally displaced figures are IOM estimates as of March 19, based on 2,000 telephone interviews with Ukrainians aged 18 and older conducted between March 9-16. The UNHCR compiled the figures for refugees to neighboring countries on March 21 based on official border crossing data and its own estimates. The UNHCR's top-line total is lower than the country totals because Romania and Moldova totals include people crossing between the two countries.
Sources: IOM, UNHCR
According to IOM estimates based on telephone interviews with a representative sample of internally displaced Ukrainians, over 53% of those displaced are women, and over 60% of displaced households have children.
More on Current Events

Cory Doctorow
3 years ago
The downfall of the Big Four accounting companies is just one (more) controversy away.
Economic mutual destruction.

Multibillion-dollar corporations never bothered with an independent audit, and they all lied about their balance sheets.
It's easy to forget that the Big Four accounting firms are lousy fraud enablers. Just because they sign off on your books doesn't mean you're not a hoax waiting to erupt.
This is *crazy* Capitalism depends on independent auditors. Rich folks need to know their financial advisers aren't lying. Rich folks usually succeed.
No accounting. EY, KPMG, PWC, and Deloitte make more money consulting firms than signing off on their accounts.
The Big Four sign off on phony books because failing to make friends with unscrupulous corporations may cost them consulting contracts.
The Big Four are the only firms big enough to oversee bankruptcy when they sign off on fraudulent books, as they did for Carillion in 2018. All four profited from Carillion's bankruptcy.
The Big Four are corrupt without any consequences for misconduct. Who can forget when KPMG's top management was fined millions for helping auditors cheat on ethics exams?
Consulting and auditing conflict. Consultants help a firm cover its evil activities, such as tax fraud or wage theft, whereas auditors add clarity to a company's finances. The Big Four make more money from cooking books than from uncooking them, thus they are constantly embroiled in scandals.
If a major scandal breaks, it may bring down the entire sector and substantial parts of the economy. Jim Peterson explains system risk for The Dig.
The Big Four are voluntary private partnerships where accountants invest their time, reputations, and money. If a controversy threatens the business, partners who depart may avoid scandal and financial disaster.
When disaster looms, each partner should bolt for the door, even if a disciplined stay-and-hold posture could weather the storm. This happened to Arthur Andersen during Enron's collapse, and a 2006 EU report recognized the risk to other corporations.
Each partner at a huge firm knows how much dirty laundry they've buried in the company's garden, and they have well-founded suspicions about what other partners have buried, too. When someone digs, everyone runs.
If a firm confronts substantial litigation damages or enforcement penalties, it could trigger the collapse of one of the Big Four. That would be bad news for the firm's clients, who would have trouble finding another big auditor.
Most of the world's auditing capacity is concentrated in four enormous, brittle, opaque, compromised organizations. If one of them goes bankrupt, the other three won't be able to take on its clients.
Peterson: Another collapse would strand many of the world's large public businesses, leaving them unable to obtain audit views for their securities listings and regulatory compliance.
Count Down: The Past, Present, and Uncertain Future of the Big Four Accounting Firms is in its second edition.
https://www.emerald.com/insight/publication/doi/10.1108/9781787147003

Johnny Harris
4 years ago
The REAL Reason Putin is Invading Ukraine [video with transcript]
Transcript:
[Reporter] The Russian invasion of Ukraine.
Momentum is building for a war between Ukraine and Russia.
[Reporter] Tensions between Russia and the West
are growing rapidly.
[Reporter] President Biden considering deploying
thousands of troops to Eastern Europe.
There are now 100,000 troops
on the Eastern border of Ukraine.
Russia is setting up field hospitals on this border.
Like this is what preparation for war looks like.
A legitimate war.
Ukrainian troops are watching and waiting,
saying they are preparing for a fight.
The U.S. has ordered the families of embassy staff
to leave Ukraine.
Britain has sent all of their nonessential staff home.
And now the U.S. is sending tons of weapons and munitions
to Ukraine's army.
And we're even considering deploying
our own troops to the region.
I mean, this thing is heating up.
Meanwhile, Russia and the West have been in Geneva
and Brussels trying to talk it out,
and sort of getting nowhere.
The message is very clear.
Should Russia take further aggressive actions
against Ukraine the costs will be severe
and the consequences serious.
It's a scary, grim momentum that is unpredictable.
And the chances of miscalculation
and escalation are growing.
I want to explain what's going on here,
but I want to show you that this isn't just
typical geopolitical behavior.
Stuff that can just be explained on the map.
Instead, to understand why 100,000 troops are camped out
on Ukraine's Eastern border, ready for war,
you have to understand Russia
and how it's been cut down over the ages
from the Slavic empire that dominated this whole region
to then the Soviet Union,
which was defeated in the nineties.
And what you really have to understand here
is how that history is transposed
onto the brain of one man.
This guy, Vladimir Putin.
This is a story about regional domination
and struggles between big powers,
but really it's the story about
what Vladimir Putin really wants.
[Reporter] Russian troops moving swiftly
to take control of military bases in Crimea.
[Reporter] Russia has amassed more than 100,000 troops
and a lot of military hardware
at the border with Ukraine.
Let's dive back in.
Okay. Let's get up to speed on what's happening here.
And I'm just going to quickly give you the highlight version
of like the news that's happening,
because I want to get into the juicy part,
which is like why, the roots of all of this.
So let's go.
A few months ago, Russia started sending
more and more troops to this border.
It's this massive border between Ukraine and Russia.
They said they were doing a military exercise,
but the rest of the world was like,
"Yeah, we totally believe you Russia. Pshaw."
This was right before this big meeting
where North American and European countries
were coming together to talk about a lot
of different things, like these countries often do
in these diplomatic summits.
But soon, because of Russia's aggressive behavior
coming in and setting up 100,000 troops
on the border with Ukraine,
the entire summit turned into a whole, "WTF Russia,
what are you doing on the border of Ukraine," meeting.
Before the meeting Putin comes out and says,
"Listen, I have some demands for the West."
And everyone's like, "Okay, Russia, what are your demands?
You know, we have like, COVID19 right now.
And like, that's like surging.
So like, we don't need your like,
bluster about what your demands are."
And Putin's like, "No, here's my list of demands."
Putin's demands for the summit were this:
number one, that NATO, which is this big military alliance
between U.S., Canada, and Europe stop expanding,
meaning they don't let any new members in, okay.
So, Russia is like, "No more new members to your, like,
cool military club that I don't like.
You can't have any more members."
Number two, that NATO withdraw all of their troops
from anywhere in Eastern Europe.
Basically Putin is saying,
"I can veto any military cooperation
or troops going between countries
that have to do with Eastern Europe,
the place that used to be the Soviet Union."
Okay, and number three, Putin demands that America vow
not to protect its allies in Eastern Europe
with nuclear weapons.
"LOL," said all of the other countries,
"You're literally nuts, Vladimir Putin.
Like these are the most ridiculous demands, ever."
But there he is, Putin, with these demands.
These very, very aggressive demands.
And he sort of is implying that if his demands aren't met,
he's going to invade Ukraine.
I mean, it doesn't work like this.
This is not how international relations work.
You don't just show up and say like,
"I'm not gonna allow other countries to join your alliance
because it makes me feel uncomfortable."
But what I love about this list of demands
from Vladimir Putin for this summit
is that it gives us a clue
on what Vladimir Putin really wants.
What he's after here.
You read them closely and you can grasp his intentions.
But to grasp those intentions
you have to understand what NATO is.
and what Russia and Ukraine used to be.
(dramatic music)
Okay, so a while back I made this video
about why Russia is so damn big,
where I explain how modern day Russia started here in Kiev,
which is actually modern day Ukraine.
In other words, modern day Russia, as we know it,
has its original roots in Ukraine.
These places grew up together
and they eventually became a part
of the same mega empire called the Soviet Union.
They were deeply intertwined,
not just in their history and their culture,
but also in their economy and their politics.
So it's after World War II,
it's like the '50s, '60s, '70s, and NATO was formed,
the North Atlantic Treaty Organization.
This was a military alliance between all of these countries,
that was meant to sort of deter the Soviet Union
from expanding and taking over the world.
But as we all know, the Soviet Union,
which was Russia and all of these other countries,
collapsed in 1991.
And all of these Soviet republics,
including Ukraine, became independent,
meaning they were not now a part
of one big block of countries anymore.
But just because the border's all split up,
it doesn't mean that these cultural ties actually broke.
Like for example, the Soviet leader at the time
of the collapse of the Soviet Union, this guy, Gorbachev,
he was the son of a Ukrainian mother and a Russian father.
Like he grew up with his mother singing him
Ukrainian folk songs.
In his mind, Ukraine and Russia were like one thing.
So there was a major reluctance to accept Ukraine
as a separate thing from Russia.
In so many ways, they are one.
There was another Russian at the time
who did not accept this new division.
This young intelligence officer, Vladimir Putin,
who was starting to rise up in the ranks
of postSoviet Russia.
There's this amazing quote from 2005
where Putin is giving this stateoftheunionlike address,
where Putin declares the collapse of the Soviet Union,
quote, "The greatest catastrophe of the 20th century.
And as for the Russian people, it became a genuine tragedy.
Tens of millions of fellow citizens and countrymen
found themselves beyond the fringes of Russian territory."
Do you see how he frames this?
The Soviet Union were all one people in his mind.
And after it collapsed, all of these people
who are a part of the motherland were now outside
of the fringes or the boundaries of Russian territory.
First off, fact check.
Greatest catastrophe of the 20th century?
Like, do you remember what else happened
in the 20th century, Vladimir?
(ominous music)
Putin's worry about the collapse of this one people
starts to get way worse when the West, his enemy,
starts showing up to his neighborhood
to all these exSoviet countries that are now independent.
The West starts selling their ideology
of democracy and capitalism and inviting them
to join their military alliance called NATO.
And guess what?
These countries are totally buying it.
All these exSoviet countries are now joining NATO.
And some of them, the EU.
And Putin is hating this.
He's like not only did the Soviet Union divide
and all of these people are now outside
of the Russia motherland,
but now they're being persuaded by the West
to join their military alliance.
This is terrible news.
Over the years, this continues to happen,
while Putin himself starts to chip away
at Russian institutions, making them weaker and weaker.
He's silencing his rivals
and he's consolidating power in himself.
(triumphant music)
And in the past few years,
he's effectively silenced anyone who can challenge him;
any institution, any court,
or any political rival have all been silenced.
It's been decades since the Soviet Union fell,
but as Putin gains more power,
he still sees the region through the lens
of the old Cold War, Soviet, Slavic empire view.
He sees this region as one big block
that has been torn apart by outside forces.
"The greatest catastrophe of the 20th century."
And the worst situation of all of these,
according to Putin, is Ukraine,
which was like the gem of the Soviet Union.
There was tons of cultural heritage.
Again, Russia sort of started in Ukraine,
not to mention it was a very populous
and industrious, resourcerich place.
And over the years Ukraine has been drifting west.
It hasn't joined NATO yet, but more and more,
it's been electing proWestern presidents.
It's been flirting with membership in NATO.
It's becoming less and less attached
to the Russian heritage that Putin so adores.
And more than half of Ukrainians say
that they'd be down to join the EU.
64% of them say that it would be cool joining NATO.
But Putin can't handle this. He is in total denial.
Like an exboyfriend who handle his exgirlfriend
starting to date someone else,
Putin can't let Ukraine go.
He won't let go.
So for the past decade,
he's been trying to keep the West out
and bring Ukraine back into the motherland of Russia.
This usually takes the form of Putin sending
secret soldiers from Russia into Ukraine
to help the people in Ukraine who want to like separate
from Ukraine and join Russia.
It also takes the form of, oh yeah,
stealing entire parts of Ukraine for Russia.
Russian troops moving swiftly to take control
of military bases in Crimea.
Like in 2014, Putin just did this.
To what America is officially calling
a Russian invasion of Ukraine.
He went down and just snatched this bit of Ukraine
and folded it into Russia.
So you're starting to see what's going on here.
Putin's life's work is to salvage what he calls
the greatest catastrophe of the 20th century,
the division and the separation
of the Soviet republics from Russia.
So let's get to present day. It's 2022.
Putin is at it again.
And honestly, if you really want to understand
the mind of Vladimir Putin and his whole view on this,
you have to read this.
"On the History of Unity of Russians and Ukrainians,"
by Vladimir Putin.
A blog post that kind of sounds
like a ninth grade history essay.
In this essay, Vladimir Putin argues
that Russia and Ukraine are one people.
He calls them essentially the same historical
and spiritual space.
Kind of beautiful writing, honestly.
Anyway, he argues that the division
between the two countries is due to quote,
"a deliberate effort by those forces
that have always sought to undermine our unity."
And that the formula they use, these outside forces,
is a classic one: divide and rule.
And then he launches into this super indepth,
like 10page argument, as to every single historical beat
of Ukraine and Russia's history
to make this argument that like,
this is one people and the division is totally because
of outside powers, i.e. the West.
Okay, but listen, there's this moment
at the end of the post,
that actually kind of hit me in a big way.
He says this, "Just have a look at Austria and Germany,
or the U.S. and Canada, how they live next to each other.
Close in ethnic composition, culture,
and in fact, sharing one language,
they remain sovereign states with their own interests,
with their own foreign policy.
But this does not prevent them
from the closest integration or allied relations.
They have very conditional, transparent borders.
And when crossing them citizens feel at home.
They create families, study, work, do business.
Incidentally, so do millions of those born in Ukraine
who now live in Russia.
We see them as our own close people."
I mean, listen, like,
I'm not in support of what Putin is doing,
but like that, it's like a pretty solid like analogy.
If China suddenly showed up and started like
coaxing Canada into being a part of its alliance,
I would be a little bit like, "What's going on here?"
That's what Putin feels.
And so I kind of get what he means there.
There's a deep heritage and connection between these people.
And he's seen that falter and dissolve
and he doesn't like it.
He clearly genuinely feels a brotherhood
and this deep heritage connection
with the people of Ukraine.
Okay, okay, okay, okay. Putin, I get it.
Your essay is compelling there at the end.
You're clearly very smart and wellread.
But this does not justify what you've been up to. Okay?
It doesn't justify sending 100,000 troops to the border
or sending cyber soldiers to sabotage
the Ukrainian government, or annexing territory,
fueling a conflict that has killed
tens of thousands of people in Eastern Ukraine.
No. Okay.
No matter how much affection you feel for Ukrainian heritage
and its connection to Russia, this is not okay.
Again, it's like the boyfriend
who genuinely loves his girlfriend.
They had a great relationship,
but they broke up and she's free to see whomever she wants.
But Putin is not ready to let go.
[Man In Blue Shirt] What the hell's wrong with you?
I love you, Jessica.
What the hell is wrong with you?
Dude, don't fucking touch me.
I love you. Worldstar!
What is wrong with you? Just stop!
Putin has constructed his own reality here.
One in which Ukraine is actually being controlled
by shadowy Western forces
who are holding the people of Ukraine hostage.
And if that he invades, it will be a swift victory
because Ukrainians will accept him with open arms.
The great liberator.
(triumphant music)
Like, this guy's a total romantic.
He's a history buff and a romantic.
And he has a hill to die on here.
And it is liberating the people
who have been taken from the Russian motherland.
Kind of like the abusive boyfriend, who's like,
"She actually really loves me,
but it's her annoying friends
who were planting all these ideas in her head.
That's why she broke up with me."
And it's like, "No, dude, she's over you."
[Man In Blue Shirt] What the hell is wrong with you?
I love you, Jessica.
I mean, maybe this video should be called
Putin is just like your abusive exboyfriend.
[Man In Blue Shirt] What the hell is wrong with you?
I love you, Jessica!
Worldstar! What's wrong with you?
Okay. So where does this leave us?
It's 2022, Putin is showing up to these meetings in Europe
to tell them where he stands.
He says, "NATO, you cannot expand anymore. No new members.
And you need to withdraw all your troops
from Eastern Europe, my neighborhood."
He knows these demands will never be accepted
because they're ludicrous.
But what he's doing is showing a false effort to say,
"Well, we tried to negotiate with the West,
but they didn't want to."
Hence giving a little bit more justification
to a Russian invasion.
So will Russia invade? Is there war coming?
Maybe; it's impossible to know
because it's all inside of the head of this guy.
But, if I were to make the best argument
that war is not coming tomorrow,
I would look at a few things.
Number one, war in Ukraine would be incredibly costly
for Vladimir Putin.
Russia has a far superior army to Ukraine's,
but still, Ukraine has a very good army
that is supported by the West
and would give Putin a pretty bad bloody nose
in any invasion.
Controlling territory in Ukraine would be very hard.
Ukraine is a giant country.
They would fight back and it would be very hard
to actually conquer and take over territory.
Another major point here is that if Russia invades Ukraine,
this gives NATO new purpose.
If you remember, NATO was created because of the Cold War,
because the Soviet Union was big and nuclear powered.
Once the Soviet Union fell,
NATO sort of has been looking for a new purpose
over the past couple of decades.
If Russia invades Ukraine,
NATO suddenly has a brand new purpose to unite
and to invest in becoming more powerful than ever.
Putin knows that.
And it would be very bad news for him if that happened.
But most importantly, perhaps the easiest clue
for me to believe that war isn't coming tomorrow
is the Russian propaganda machine
is not preparing the Russian people for an invasion.
In 2014, when Russia was about to invade
and take over Crimea, this part of Ukraine,
there was a barrage of state propaganda
that prepared the Russian people
that this was a justified attack.
So when it happened, it wasn't a surprise
and it felt very normal.
That isn't happening right now in Russia.
At least for now. It may start happening tomorrow.
But for now, I think Putin is showing up to the border,
flexing his muscles and showing the West that he is earnest.
I'm not sure that he's going to invade tomorrow,
but he very well could.
I mean, read the guy's blog post
and you'll realize that he is a romantic about this.
He is incredibly idealistic about the glory days
of the Slavic empires, and he wants to get it back.
So there is dangerous momentum towards war.
And the way war works is even a small little, like, fight,
can turn into the other guy
doing something bigger and crazier.
And then the other person has to respond
with something a little bit bigger.
That's called escalation.
And there's not really a ceiling
to how much that momentum can spin out of control.
That is why it's so scary when two nuclear countries
go to war with each other,
because there's kind of no ceiling.
So yeah, it's dangerous. This is scary.
I'm not sure what happens next here,
but the best we can do is keep an eye on this.
At least for now, we better understand
what Putin really wants out of all of this.
Thanks for watching.

MartinEdic
3 years ago
Russia Through the Windows: It's Very Bad
And why we must keep arming Ukraine

Russian expatriates write about horrific news from home.
Read this from Nadin Brzezinski. She's not a native English speaker, so there are grammar errors, but her tale smells true.
Terrible truth.
There's much more that reveals Russia's grim reality.
Non-leadership. Millions of missing supplies are presumably sold for profit, leaving untrained troops without food or gear. Missile attacks pause because they run out. Fake schemes to hold talks as a way of stalling while they scramble for solutions.
Street men were mobilized. Millions will be ground up to please a crazed despot. Fear, wrath, and hunger pull apart civilization.
It's the most dystopian story, but Ukraine is worse. Destruction of a society, country, and civilization. Only the invaders' corruption and incompetence save the Ukrainians.
Rochester, NY. My suburb had many Soviet-era Ukrainian refugees. Their kids were my classmates. Fifty years later, many are still my friends. I loved their food and culture. My town has 20,000 Ukrainians.
Grieving but determined. They don't quit. They won't quit. Russians are eternal enemies.
It's the Russian people's willingness to tolerate corruption, abuse, and stupidity by their leaders. They are paying. 65000 dead. Ruined economy. No freedom to speak. Americans do not appreciate that freedom as we should.
It lets me write/publish.
Russian friends are shocked. Many are here because their parents escaped Russian anti-semitism and authoritarian oppression. A Russian cultural legacy says a strongman's methods are admirable.
A legacy of a slavery history disguised as serfdom. Peasants and Princes.
Read Tolstoy. Then Anna Karenina. The main characters are princes and counts, whose leaders are incompetent idiots with wealth and power.
Peasants who die in their wars due to incompetence are nameless ciphers.
Sound familiar?
You might also like

Tim Smedley
3 years ago
When Investment in New Energy Surpassed That in Fossil Fuels (Forever)
A worldwide energy crisis might have hampered renewable energy and clean tech investment. Nope.
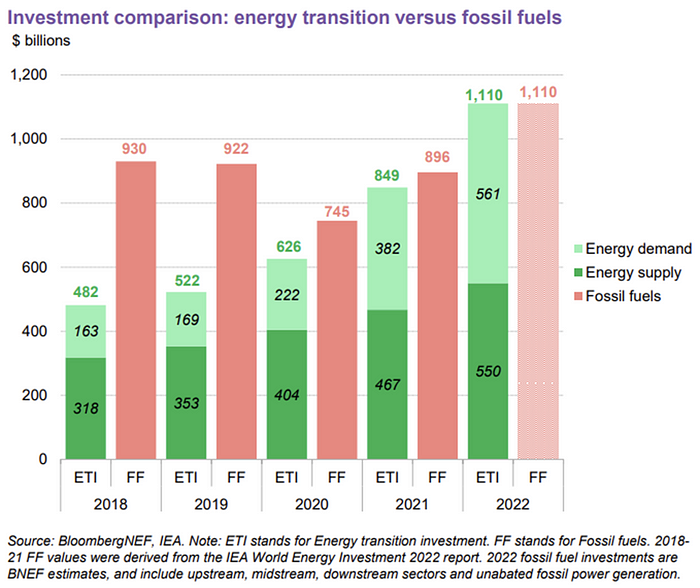
BNEF's 2023 Energy Transition Investment Trends study surprised and encouraged. Global energy transition investment reached $1 trillion for the first time ($1.11t), up 31% from 2021. From 2013, the clean energy transition has come and cannot be reversed.
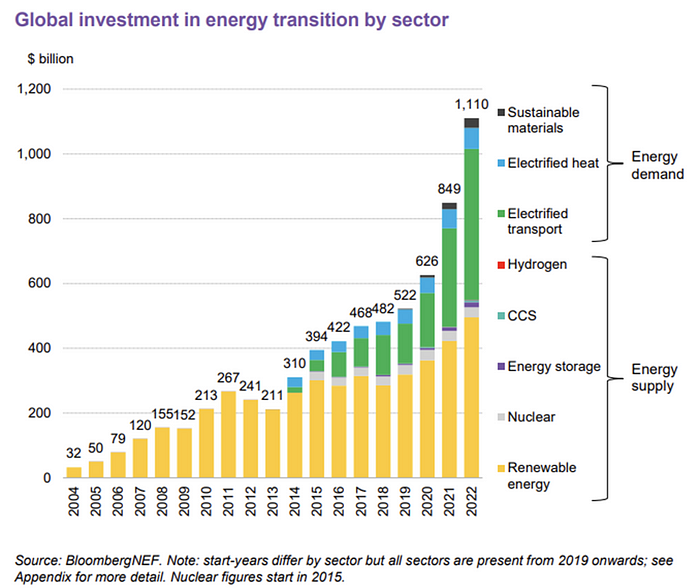
BNEF Head of Global Analysis Albert Cheung said our findings ended the energy crisis's influence on renewable energy deployment. Energy transition investment has reached a record as countries and corporations implement transition strategies. Clean energy investments will soon surpass fossil fuel investments.
The table below indicates the tripping point, which means the energy shift is occuring today.
BNEF calls money invested on clean technology including electric vehicles, heat pumps, hydrogen, and carbon capture energy transition investment. In 2022, electrified heat received $64b and energy storage $15.7b.
Nonetheless, $495b in renewables (up 17%) and $466b in electrified transport (up 54%) account for most of the investment. Hydrogen and carbon capture are tiny despite the fanfare. Hydrogen received the least funding in 2022 at $1.1 billion (0.1%).
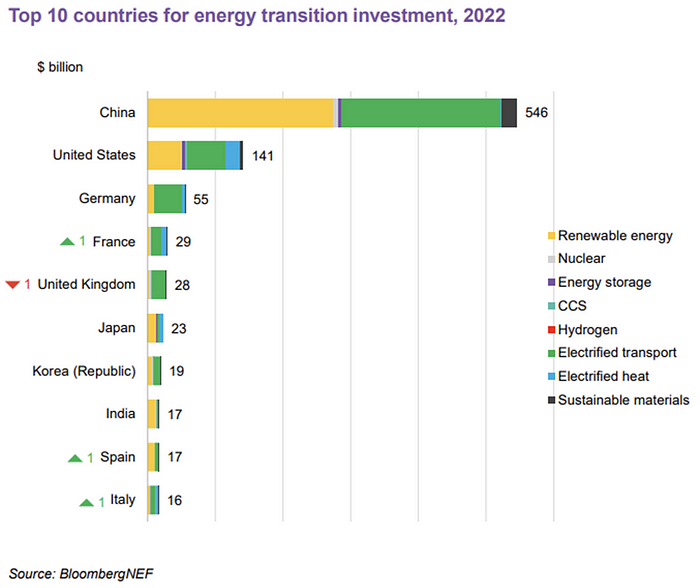
China dominates investment. China spends $546 billion on energy transition, half the global amount. Second, the US total of $141 billion in 2022 was up 11% from 2021. With $180 billion, the EU is unofficially second. China invested 91% in battery technologies.
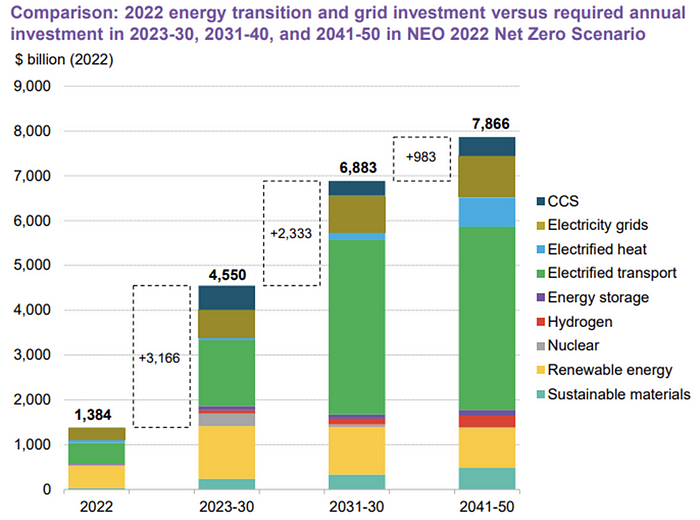
The 2022 transition tipping point is encouraging, but the BNEF research shows how far we must go to get Net Zero. Energy transition investment must average $4.55 trillion between 2023 and 2030—three times the amount spent in 2022—to reach global Net Zero. Investment must be seven times today's record to reach Net Zero by 2050.
BNEF 2023 Energy Transition Investment Trends.
As shown in the graph above, BNEF experts have been using their crystal balls to determine where that investment should go. CCS and hydrogen are still modest components of the picture. Interestingly, they see nuclear almost fading. Active transport advocates like me may have something to say about the massive $4b in electrified transport. If we focus on walkable 15-minute cities, we may need fewer electric automobiles. Though we need more electric trains and buses.
Albert Cheung of BNEF emphasizes the challenge. This week's figures promise short-term job creation and medium-term energy security, but more investment is needed to reach net zero in the long run.
I expect the BNEF Energy Transition Investment Trends report to show clean tech investment outpacing fossil fuels investment every year. Finally saying that is amazing. It's insufficient. The planet must maintain its electric (not gas) pedal. In response to the research, Christina Karapataki, VC at Breakthrough Energy Ventures, a clean tech investment firm, tweeted: Clean energy investment needs to average more than 3x this level, for the remainder of this decade, to get on track for BNEFs Net Zero Scenario. Go!

Charlie Brown
3 years ago
What Happens When You Sell Your House, Never Buying It Again, Reverse the American Dream
Homeownership isn't the only life pattern.

Want to irritate people?
My party trick is to say I used to own a house but no longer do.
I no longer wish to own a home, not because I lost it or because I'm moving.
It was a long-term plan. It was more deliberate than buying a home. Many people are committed for this reason.
Poppycock.
Anyone who told me that owning a house (or striving to do so) is a must is wrong.
Because, URGH.
One pattern for life is to own a home, but there are millions of others.
You can afford to buy a home? Go, buddy.
You think you need 1,000 square feet (or more)? You think it's non-negotiable in life?
Nope.
It's insane that society forces everyone to own real estate, regardless of income, wants, requirements, or situation. As if this trade brings happiness, stability, and contentment.
Take it from someone who thought this for years: drywall isn't happy. Living your way brings contentment.
That's in real estate. It may also be renting a small apartment in a city that makes your soul sing, but you can't afford the downpayment or mortgage payments.
Living or traveling abroad is difficult when your life savings are connected to something that eats your money the moment you sign.
#vanlife, which seems like torment to me, makes some people feel alive.
I've seen co-living, vacation rental after holiday rental, living with family, and more work.
Insisting that home ownership is the only path in life is foolish and reduces alternative options.
How little we question homeownership is a disgrace.
No one challenges a homebuyer's motives. We congratulate them, then that's it.
When you offload one, you must answer every question, even if you have a loose screw.
Why do you want to sell?
Do you have any concerns about leaving the market?
Why would you want to renounce what everyone strives for?
Why would you want to abandon a beautiful place like that?
Why would you mismanage your cash in such a way?
But surely it's only temporary? RIGHT??
Incorrect questions. Buying a property requires several inquiries.
The typical American has $4500 saved up. When something goes wrong with the house (not if, it’s never if), can you actually afford the repairs?
Are you certain that you can examine a home in less than 15 minutes before committing to buying it outright and promising to pay more than twice the asking price on a 30-year 7% mortgage?
Are you certain you're ready to leave behind friends, family, and the services you depend on in order to acquire something?
Have you thought about the connotation that moving to a suburb, which more than half of Americans do, means you will be dependent on a car for the rest of your life?
Plus:
Are you sure you want to prioritize home ownership over debt, employment, travel, raising kids, and daily routines?
Homeownership entails that. This ex-homeowner says it will rule your life from the time you put the key in the door.
This isn't questioned. We don't question enough. The holy home-ownership grail was set long ago, and we don't challenge it.
Many people question after signing the deeds. 70% of homeowners had at least one regret about buying a property, including the expense.
Exactly. Tragic.
Homes are different from houses
We've been fooled into thinking home ownership will make us happy.
Some may agree. No one.
Bricks and brick hindered me from living the version of my life that made me most comfortable, happy, and steady.
I'm spending the next month in a modest apartment in southern Spain. Even though it's late November, today will be 68 degrees. My spouse and I will soon meet his visiting parents. We'll visit a Sherry store. We'll eat, nap, walk, and drink Sherry. Writing. Jerez means flamenco.
That's my home. This is such a privilege. Living a fulfilling life brings me the contentment that buying a home never did.
I'm happy and comfortable knowing I can make almost all of my days good. Rejecting home ownership is partly to blame.
I'm broke like most folks. I had to choose between home ownership and comfort. I said, I didn't find them together.
Feeling at home trumps owning brick-and-mortar every day.
The following is the reality of what it's like to turn the American Dream around.
Leaving the housing market.
Sometimes I wish I owned a home.
I miss having my own yard and bed. My kitchen, cookbooks, and pizza oven are missed.
But I rarely do.
Someone else's life plan pushed home ownership on me. I'm grateful I figured it out at 35. Many take much longer, and some never understand homeownership stinks (for them).
It's confusing. People will think you're dumb or suicidal.
If you read what I write, you'll know. You'll realize that all you've done is choose to live intentionally. Find a home beyond four walls and a picket fence.
Miss? As I said, they're not home. If it were, a pizza oven, a good mattress, and a well-stocked kitchen would bring happiness.
No.
If you can afford a house and desire one, more power to you.
There are other ways to discover home. Find calm and happiness. For fun.
For it, look deeper than your home's foundation.

Jayden Levitt
3 years ago
The country of El Salvador's Bitcoin-obsessed president lost $61.6 million.
It’s only a loss if you sell, right?

Nayib Bukele proclaimed himself “the world’s coolest dictator”.
His jokes aren't clear.
El Salvador's 43rd president self-proclaimed “CEO of El Salvador” couldn't be less presidential.
His thin jeans, aviator sunglasses, and baseball caps like a cartel lord.
He's popular, though.
Bukele won 53% of the vote by fighting violent crime and opposition party corruption.
El Salvador's 6.4 million inhabitants are riding the cryptocurrency volatility wave.
They were powerless.
Their autocratic leader, a former Yamaha Motors salesperson and Bitcoin believer, wants to help 70% unbanked locals.
He intended to give the citizens a way to save money and cut the country's $200 million remittance cost.
Transfer and deposit costs.
This makes logical sense when the president’s theatrics don’t blind you.
El Salvador's Bukele revealed plans to make bitcoin legal tender.
Remittances total $5.9 billion (23%) of the country's expenses.
Anything that reduces costs could boost the economy.
The country’s unbanked population is staggering. Here’s the data by % of people who either have a bank account (Blue) or a mobile money account (Black).
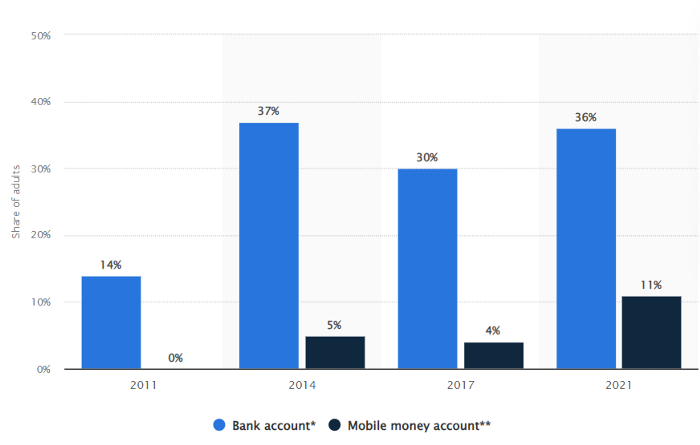
According to Bukele, 46% of the population has downloaded the Chivo Bitcoin Wallet.
In 2021, 36% of El Salvadorans had bank accounts.
Large rural countries like Kenya seem to have resolved their unbanked dilemma.
An economy surfaced where village locals would sell, trade and store network minutes and data as a store of value.
Kenyan phone networks realized unbanked people needed a safe way to accumulate wealth and have an emergency fund.
96% of Kenyans utilize M-PESA, which doesn't require a bank account.
The software involves human agents who hang out with cash and a phone.
These people are like ATMs.
You offer them cash to deposit money in your mobile money account or withdraw cash.
In a country with a faulty banking system, cash availability and a safe place to deposit it are important.
William Jack and Tavneet Suri found that M-PESA brought 194,000 Kenyan households out of poverty by making transactions cheaper and creating a safe store of value.
Mobile money, a service that allows monetary value to be stored on a mobile phone and sent to other users via text messages, has been adopted by most Kenyan households. We estimate that access to the Kenyan mobile money system M-PESA increased per capita consumption levels and lifted 194,000 households, or 2% of Kenyan households, out of poverty.
The impacts, which are more pronounced for female-headed households, appear to be driven by changes in financial behaviour — in particular, increased financial resilience and saving. Mobile money has therefore increased the efficiency of the allocation of consumption over time while allowing a more efficient allocation of labour, resulting in a meaningful reduction of poverty in Kenya.
Currently, El Salvador has 2,301 Bitcoin.
At publication, it's worth $44 million. That remains 41% of Bukele's original $105.6 million.
Unknown if the country has sold Bitcoin, but Bukeles keeps purchasing the dip.
It's still falling.

This might be a fantastic move for the impoverished country over the next five years, if they can live economically till Bitcoin's price recovers.
The evidence demonstrates that a store of value pulls individuals out of poverty, but others say Bitcoin is premature.
You may regard it as an aggressive endeavor to front run the next wave of adoption, offering El Salvador a financial upside.