



More on Technology

Ossiana Tepfenhart
3 years ago
Has anyone noticed what an absolute shitshow LinkedIn is?
After viewing its insanity, I had to leave this platform.

I joined LinkedIn recently. That's how I aim to increase my readership and gain recognition. LinkedIn's premise appealed to me: a Facebook-like platform for professional networking.
I don't use Facebook since it's full of propaganda. It seems like a professional, apolitical space, right?
I expected people to:
be more formal and respectful than on Facebook.
Talk about the inclusiveness of the workplace. Studies consistently demonstrate that inclusive, progressive workplaces outperform those that adhere to established practices.
Talk about business in their industry. Yep. I wanted to read articles with advice on how to write better and reach a wider audience.
Oh, sh*t. I hadn't anticipated that.

After posting and reading about inclusivity and pro-choice, I was startled by how many professionals acted unprofessionally. I've seen:
Men have approached me in the DMs in a really aggressive manner. Yikes. huge yikes Not at all professional.
I've heard pro-choice women referred to as infant killers by many people. If I were the CEO of a company and I witnessed one of my employees acting that poorly, I would immediately fire them.
Many posts are anti-LGBTQIA+, as I've noticed. a lot, like, a lot. Some are subtly stating that the world doesn't need to know, while others are openly making fun of transgender persons like myself.
Several medical professionals were posting explicitly racist comments. Even if you are as white as a sheet like me, you should be alarmed by this. Who's to guarantee a patient who is black won't unintentionally die?
I won't even get into how many men in STEM I observed pushing for the exclusion of women from their fields. I shouldn't be surprised considering the majority of those men I've encountered have a passionate dislike for women, but goddamn, dude.
Many people appear entirely too at ease displaying their bigotry on their professional profiles.

As a white female, I'm always shocked by people's open hostility. Professional environments are very important.
I don't know if this is still true (people seem too politicized to care), but if I heard many of these statements in person, I'd suppose they feel ashamed. Really.
Are you not ashamed of being so mean? Are you so weak that competing with others terrifies you? Isn't this embarrassing?
LinkedIn isn't great at censoring offensive comments. These people aren't getting warnings. So they were safe while others were unsafe.
The CEO in me would want to know if I had placed a bigot on my staff.

I always wondered if people's employers knew about their online behavior. If they know how horrible they appear, they don't care.
As a manager, I was picky about hiring. Obviously. In most industries, it costs $1,000 or more to hire a full-time employee, so be sure it pays off.
Companies that embrace diversity and tolerance (and are intolerant of intolerance) are more profitable, likely to recruit top personnel, and successful.
People avoid businesses that alienate them. That's why I don't eat at Chic-Fil-A and why folks avoid MyPillow. Being inclusive is good business.
CEOs are harmed by online bigots. Image is an issue. If you're a business owner, you can fire staff who don't help you.
On the one hand, I'm delighted it makes it simpler to identify those with whom not to do business.

Don’t get me wrong. I'm glad I know who to avoid when hiring, getting references, or searching for a job. When people are bad, it saves me time.
What's up with professionalism?
Really. I need to know. I've crossed the boundary between acceptable and unacceptable behavior, but never on a professional platform. I got in trouble for not wearing bras even though it's not part of my gender expression.
If I behaved like that at my last two office jobs, my supervisors would have fired me immediately. Some of the behavior I've seen is so outrageous, I can't believe these people have employment. Some are even leaders.
Like…how? Is hatred now normalized?
Please pay attention whether you're seeking for a job or even simply a side gig.

Do not add to the tragedy that LinkedIn comments can be, or at least don't make uninformed comments. Even if you weren't banned, the site may still bite you.
Recruiters can and do look at your activity. Your writing goes on your résumé. The wrong comment might lose you a job.
Recruiters and CEOs might reject candidates whose principles contradict with their corporate culture. Bigotry will get you banned from many companies, especially if others report you.
If you want a high-paying job, avoid being a LinkedIn asshole. People care even if you think no one does. Before speaking, ponder. Is this how you want to be perceived?
Better advice:
If your politics might turn off an employer, stop posting about them online and ask yourself why you hold such objectionable ideas.

Tim Soulo
4 years ago
Here is why 90.63% of Pages Get No Traffic From Google.
The web adds millions or billions of pages per day.
How much Google traffic does this content get?
In 2017, we studied 2 million randomly-published pages to answer this question. Only 5.7% of them ranked in Google's top 10 search results within a year of being published.
94.3 percent of roughly two million pages got no Google traffic.
Two million pages is a small sample compared to the entire web. We did another study.
We analyzed over a billion pages to see how many get organic search traffic and why.
How many pages get search traffic?
90% of pages in our index get no Google traffic, and 5.2% get ten visits or less.
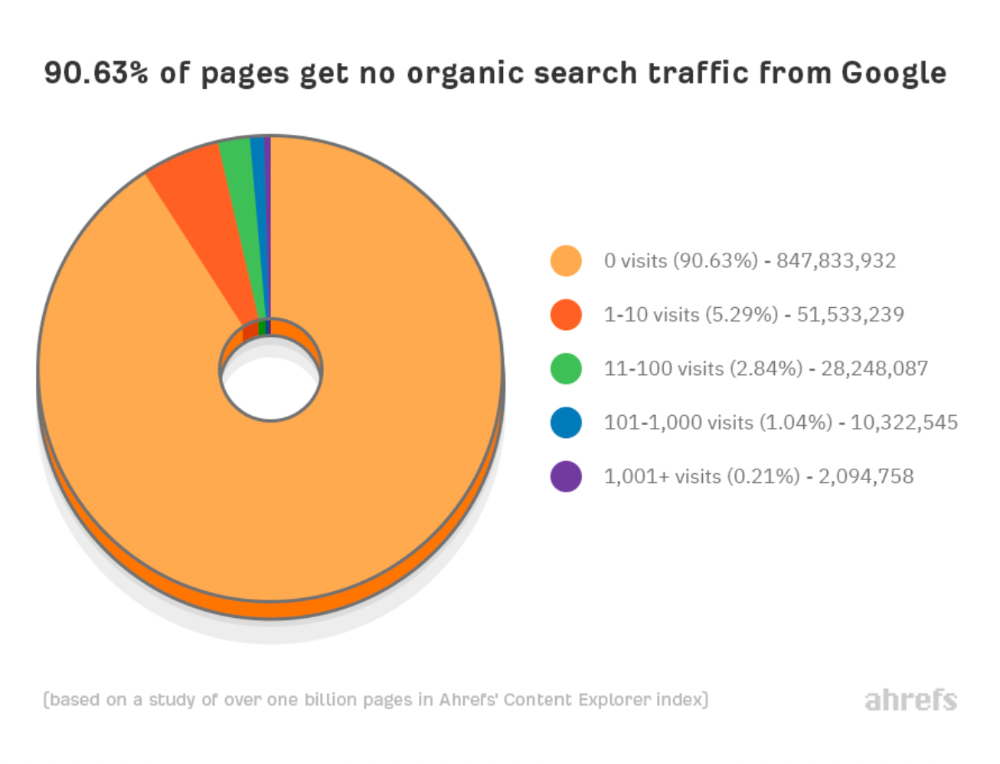
90% of google pages get no organic traffic
How can you join the minority that gets Google organic search traffic?
There are hundreds of SEO problems that can hurt your Google rankings. If we only consider common scenarios, there are only four.
Reason #1: No backlinks
I hate to repeat what most SEO articles say, but it's true:
Backlinks boost Google rankings.
Google's "top 3 ranking factors" include them.
Why don't we divide our studied pages by the number of referring domains?
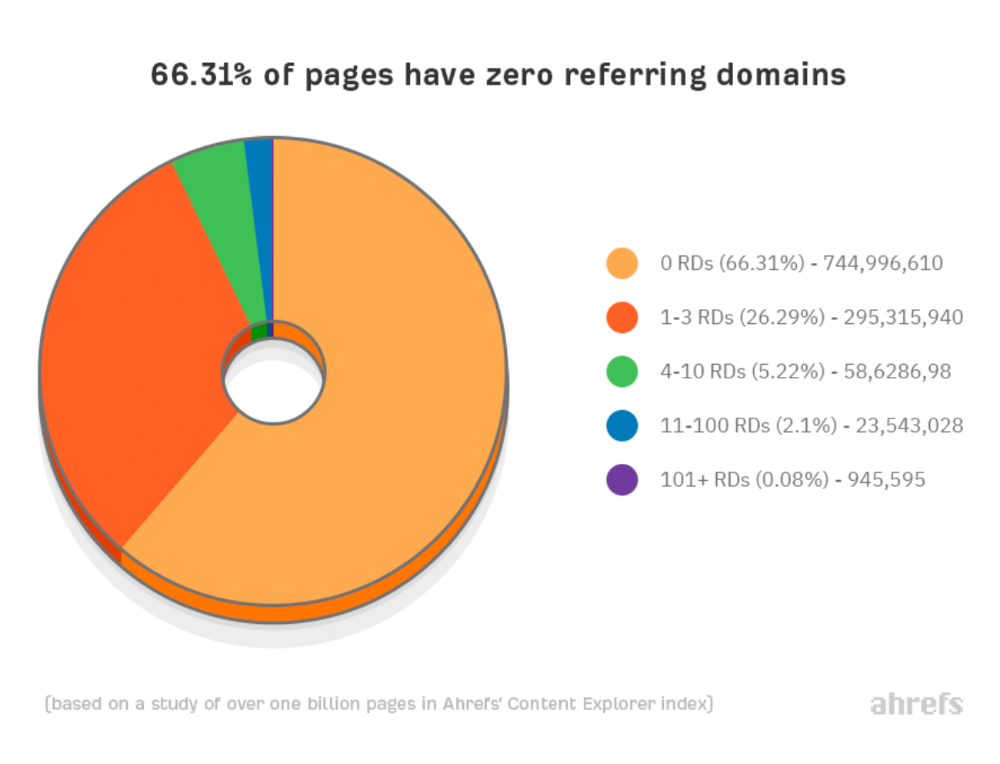
66.31 percent of pages have no backlinks, and 26.29 percent have three or fewer.
Did you notice the trend already?
Most pages lack search traffic and backlinks.
But are these the same pages?
Let's compare monthly organic search traffic to backlinks from unique websites (referring domains):
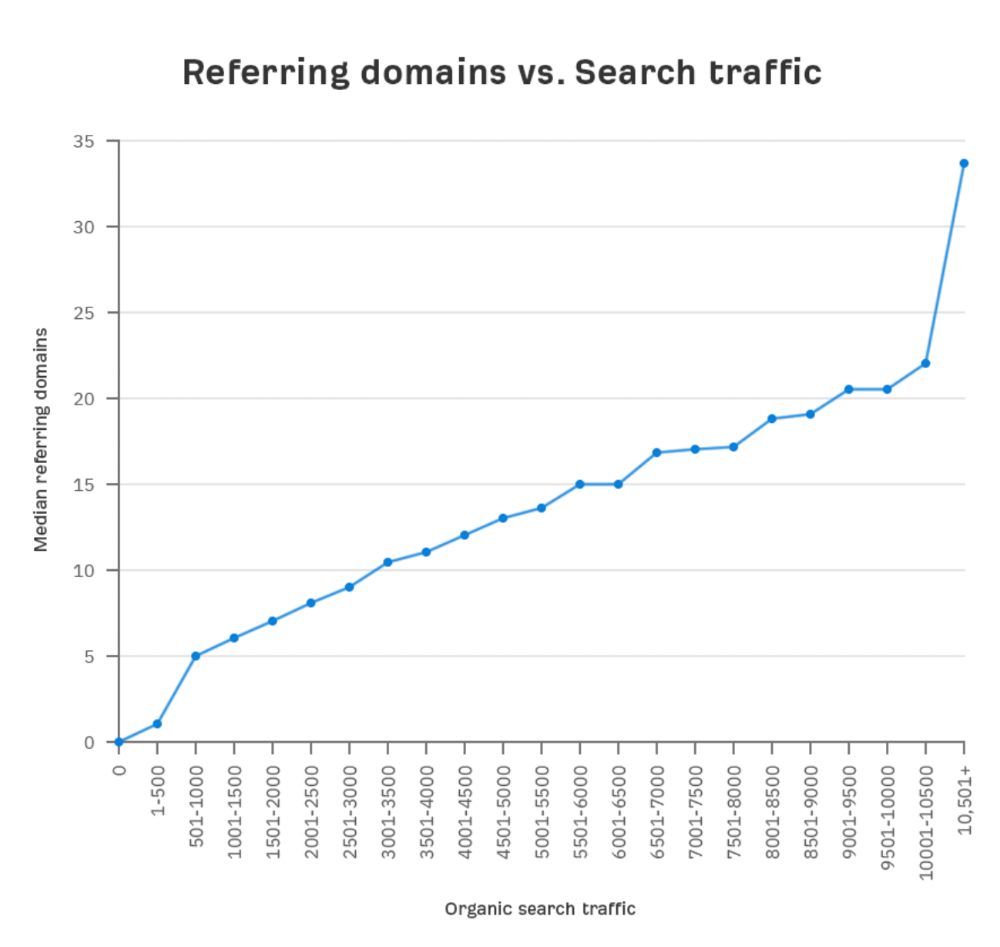
More backlinks equals more Google organic traffic.
Referring domains and keyword rankings are correlated.
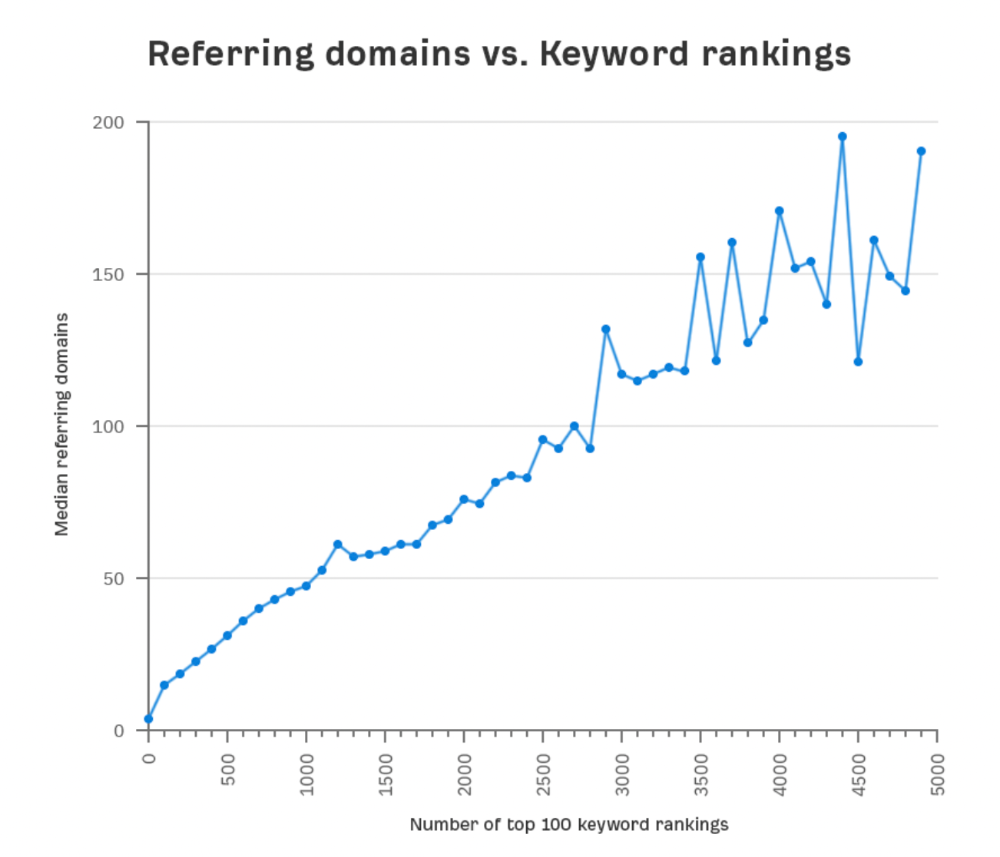
It's important to note that correlation does not imply causation, and none of these graphs prove backlinks boost Google rankings. Most SEO professionals agree that it's nearly impossible to rank on the first page without backlinks.
You'll need high-quality backlinks to rank in Google and get search traffic.
Is organic traffic possible without links?
Here are the numbers:
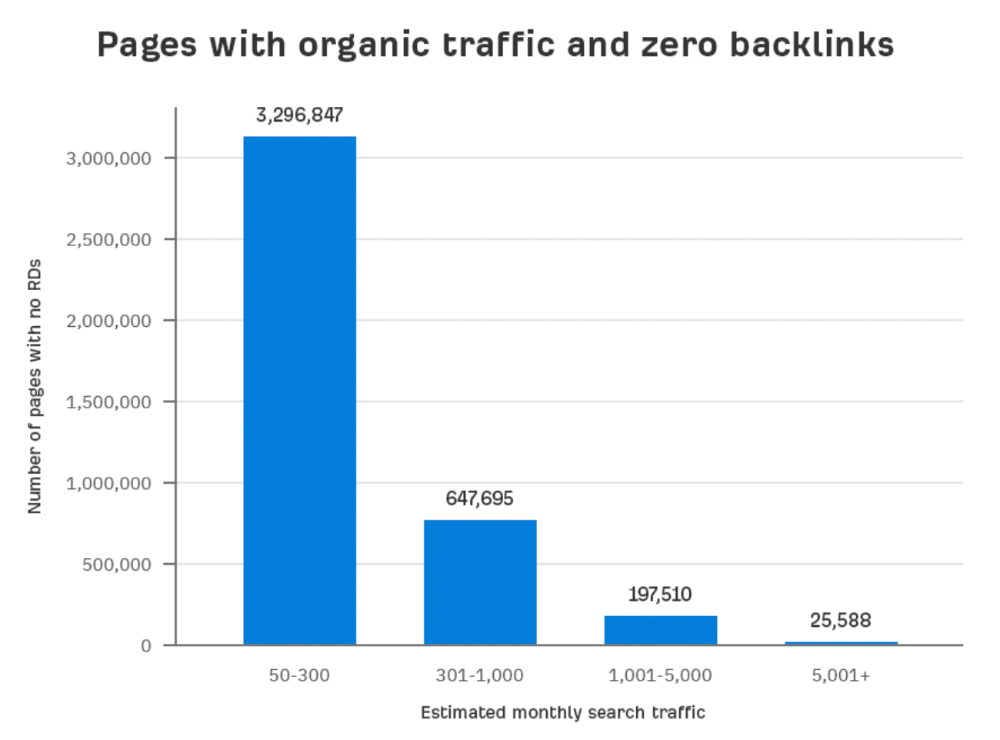
Four million pages get organic search traffic without backlinks. Only one in 20 pages without backlinks has traffic, which is 5% of our sample.
Most get 300 or fewer organic visits per month.
What happens if we exclude high-Domain-Rating pages?
The numbers worsen. Less than 4% of our sample (1.4 million pages) receive organic traffic. Only 320,000 get over 300 monthly organic visits, or 0.1% of our sample.
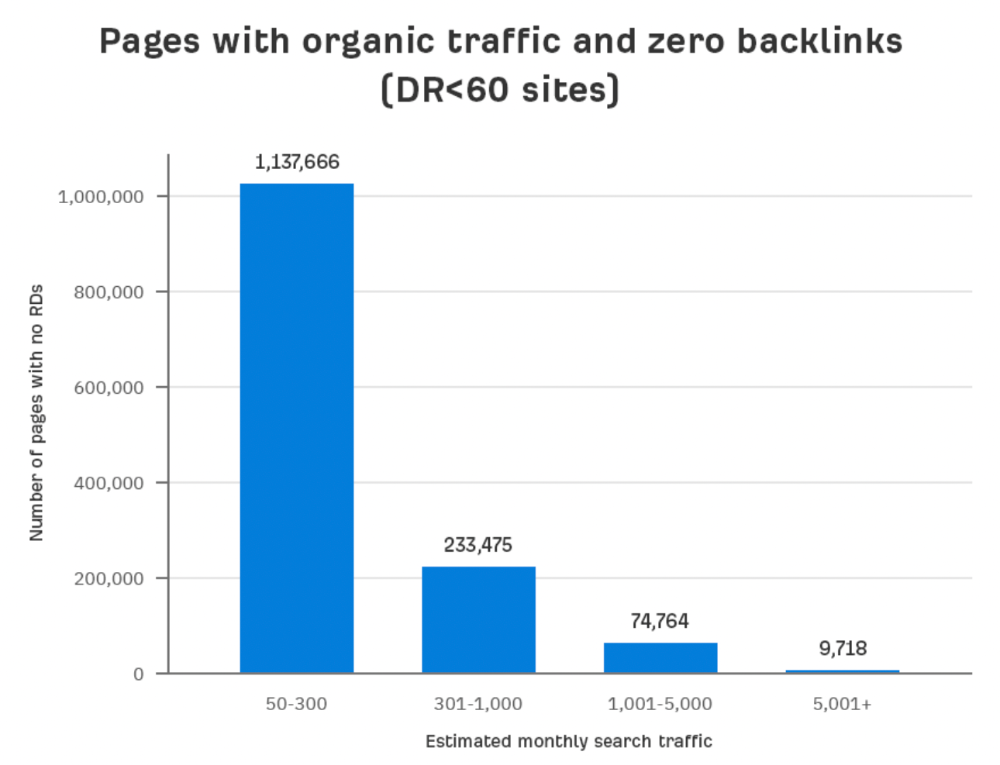
This suggests high-authority pages without backlinks are more likely to get organic traffic than low-authority pages.
Internal links likely pass PageRank to new pages.
Two other reasons:
Our crawler's blocked. Most shady SEOs block backlinks from us. This prevents competitors from seeing (and reporting) PBNs.
They choose low-competition subjects. Low-volume queries are less competitive, requiring fewer backlinks to rank.
If the idea of getting search traffic without building backlinks excites you, learn about Keyword Difficulty and how to find keywords/topics with decent traffic potential and low competition.
Reason #2: The page has no long-term traffic potential.
Some pages with many backlinks get no Google traffic.
Why? I filtered Content Explorer for pages with no organic search traffic and divided them into four buckets by linking domains.
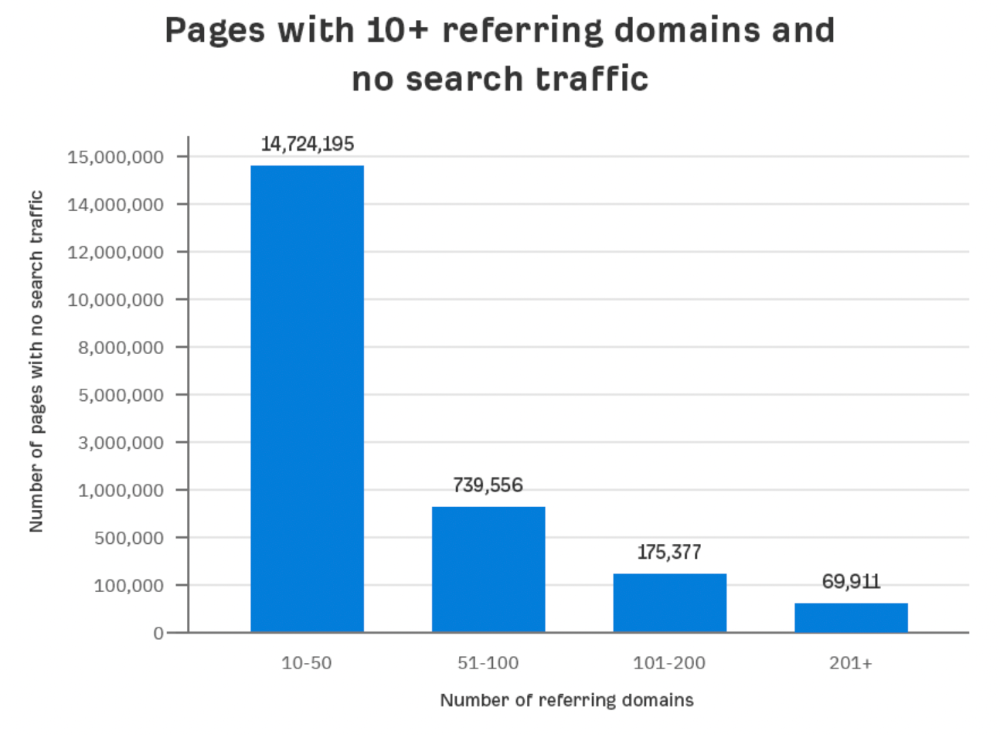
Almost 70k pages have backlinks from over 200 domains, but no search traffic.
By manually reviewing these (and other) pages, I noticed two general trends that explain why they get no traffic:
They overdid "shady link building" and got penalized by Google;
They're not targeting a Google-searched topic.
I won't elaborate on point one because I hope you don't engage in "shady link building"
#2 is self-explanatory:
If nobody searches for what you write, you won't get search traffic.
Consider one of our blog posts' metrics:

No organic traffic despite 337 backlinks from 132 sites.
The page is about "organic traffic research," which nobody searches for.
News articles often have this. They get many links from around the web but little Google traffic.
People can't search for things they don't know about, and most don't care about old events and don't search for them.
Note:
Some news articles rank in the "Top stories" block for relevant, high-volume search queries, generating short-term organic search traffic.
The Guardian's top "Donald Trump" story:
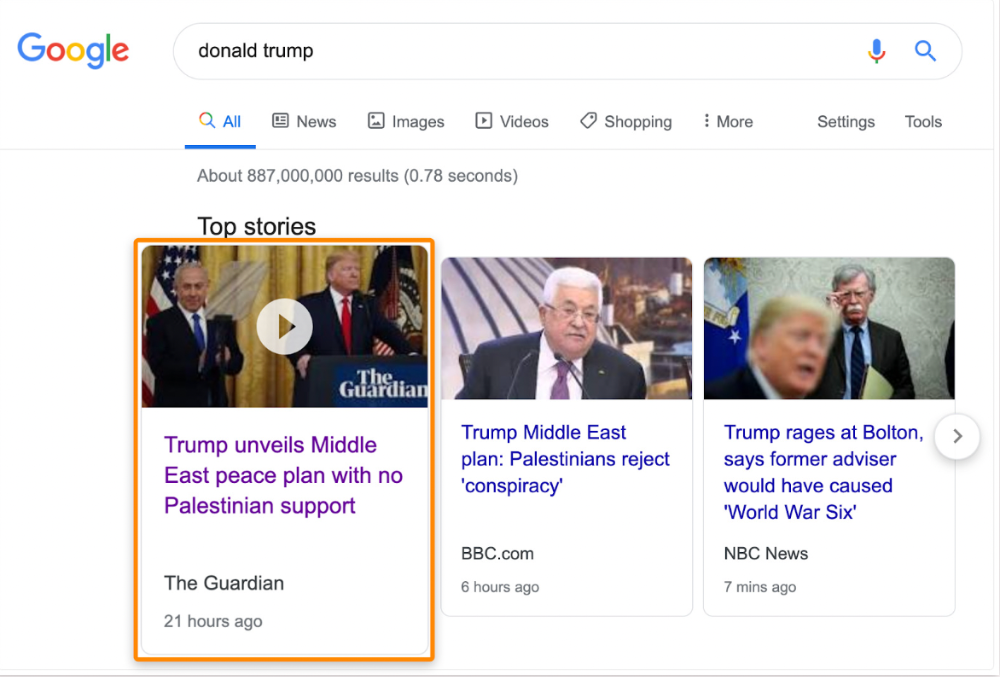
Ahrefs caught on quickly:
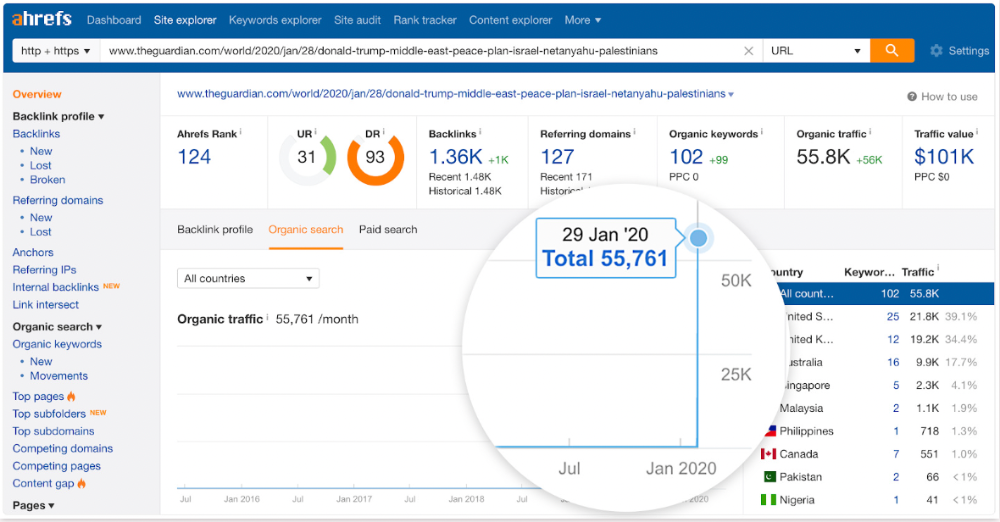
"Donald Trump" gets 5.6M monthly searches, so this page got a lot of "Top stories" traffic.
I bet traffic has dropped if you check now.
One of the quickest and most effective SEO wins is:
Find your website's pages with the most referring domains;
Do keyword research to re-optimize them for relevant topics with good search traffic potential.
Bryan Harris shared this "quick SEO win" during a course interview:
He suggested using Ahrefs' Site Explorer's "Best by links" report to find your site's most-linked pages and analyzing their search traffic. This finds pages with lots of links but little organic search traffic.
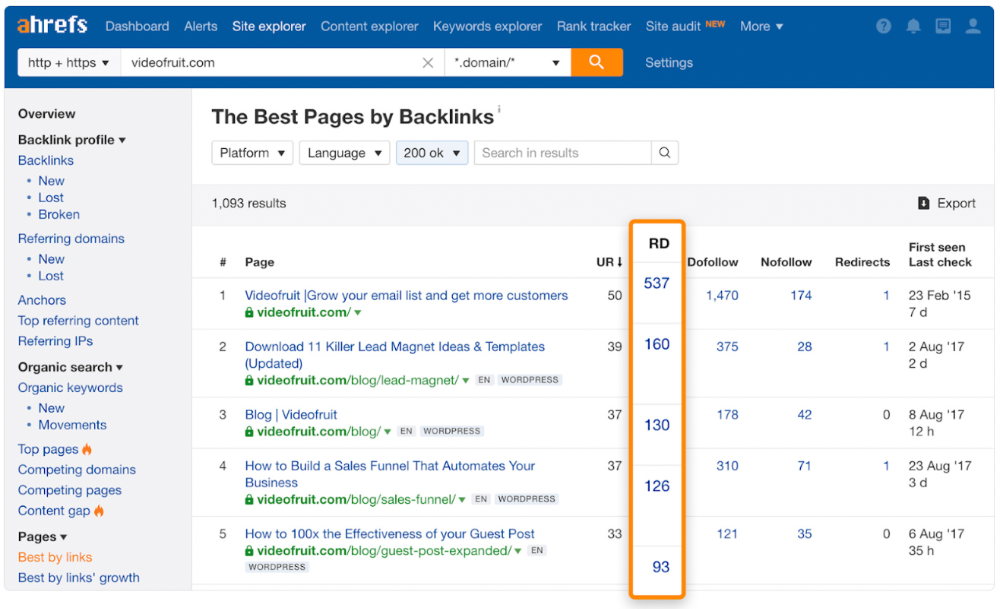
We see:
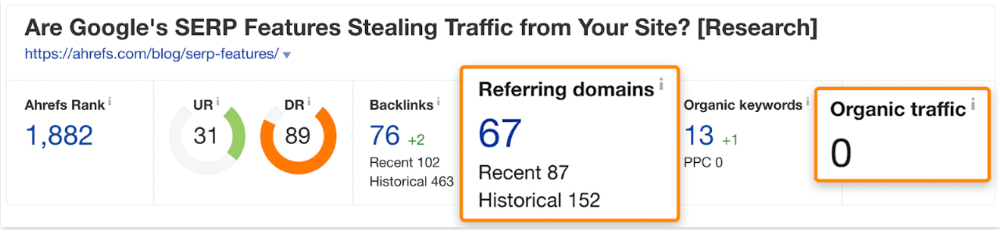
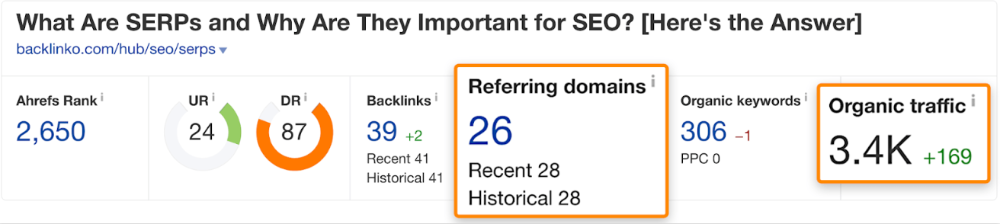
The guide has 67 backlinks but no organic traffic.
We could fix this by re-optimizing the page for "SERP"
A similar guide with 26 backlinks gets 3,400 monthly organic visits, so we should easily increase our traffic.
Don't do this with all low-traffic pages with backlinks. Choose your battles wisely; some pages shouldn't be ranked.
Reason #3: Search intent isn't met
Google returns the most relevant search results.
That's why blog posts with recommendations rank highest for "best yoga mat."
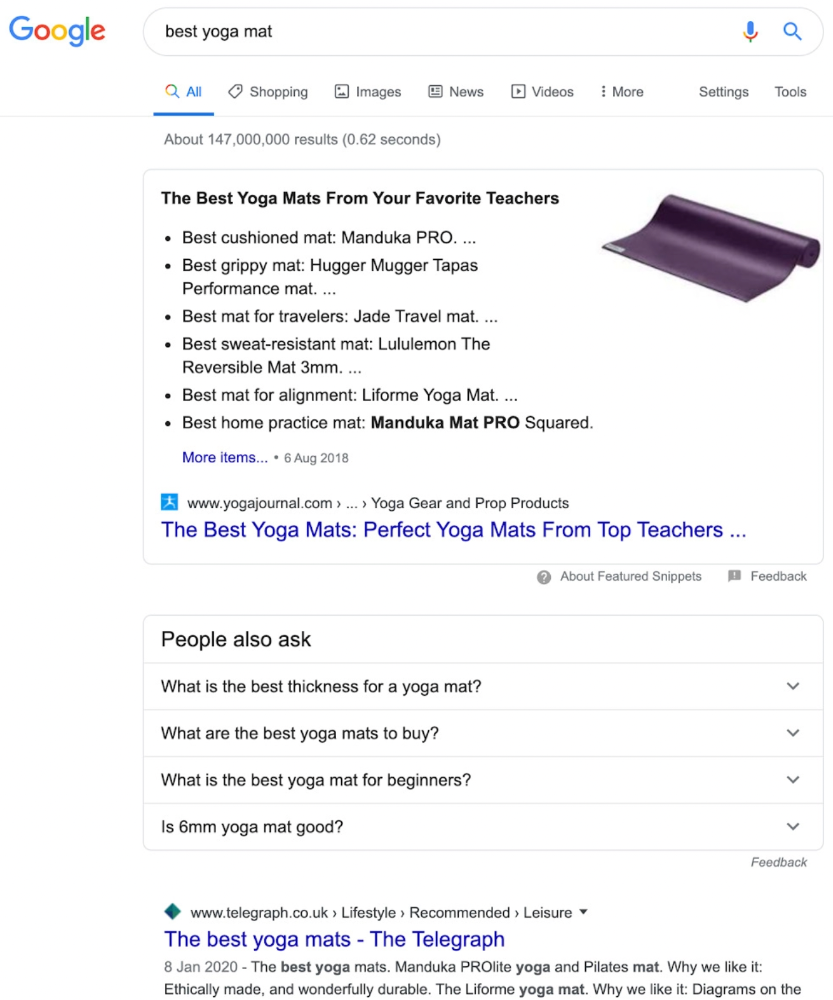
Google knows that most searchers aren't buying.
It's also why this yoga mats page doesn't rank, despite having seven times more backlinks than the top 10 pages:
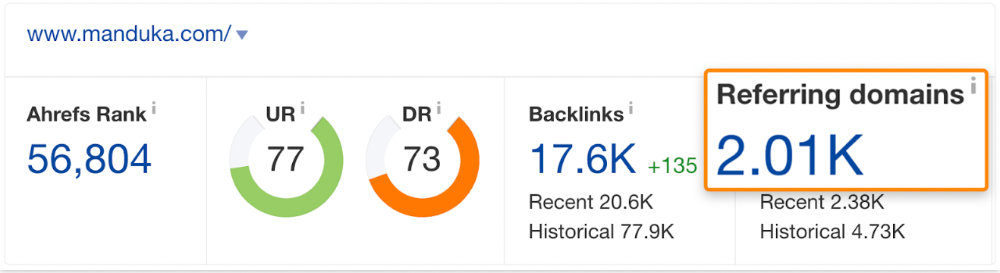
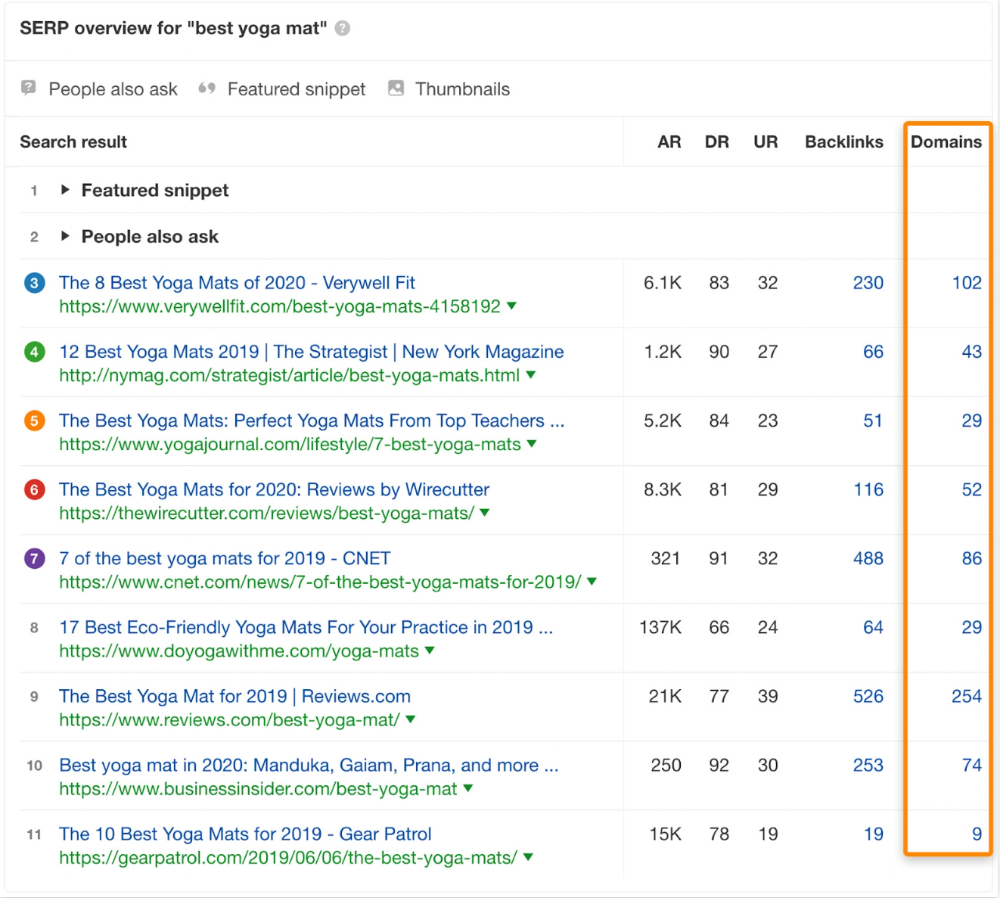
The page ranks for thousands of other keywords and gets tens of thousands of monthly organic visits. Not being the "best yoga mat" isn't a big deal.
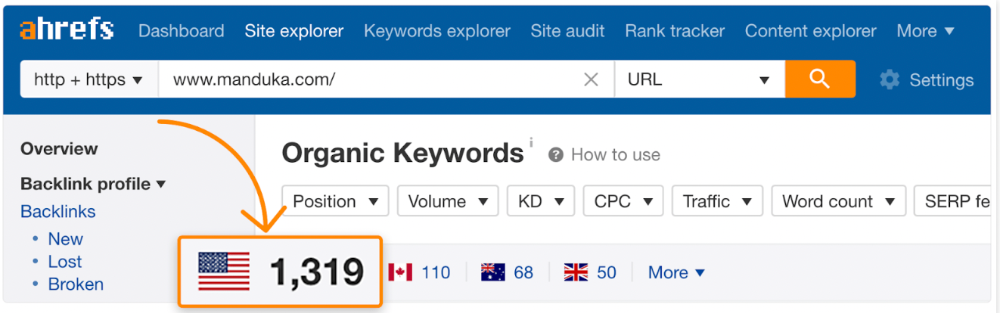
If you have pages with lots of backlinks but no organic traffic, re-optimizing them for search intent can be a quick SEO win.
It was originally a boring landing page describing our product's benefits and offering a 7-day trial.
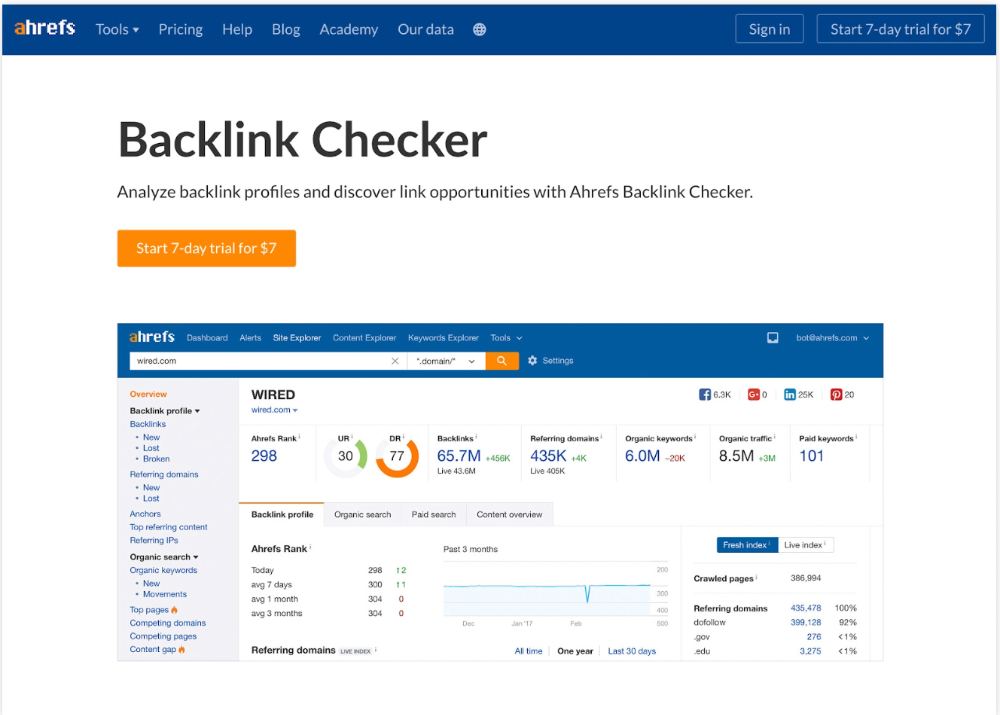
We realized the problem after analyzing search intent.
People wanted a free tool, not a landing page.
In September 2018, we published a free tool at the same URL. Organic traffic and rankings skyrocketed.
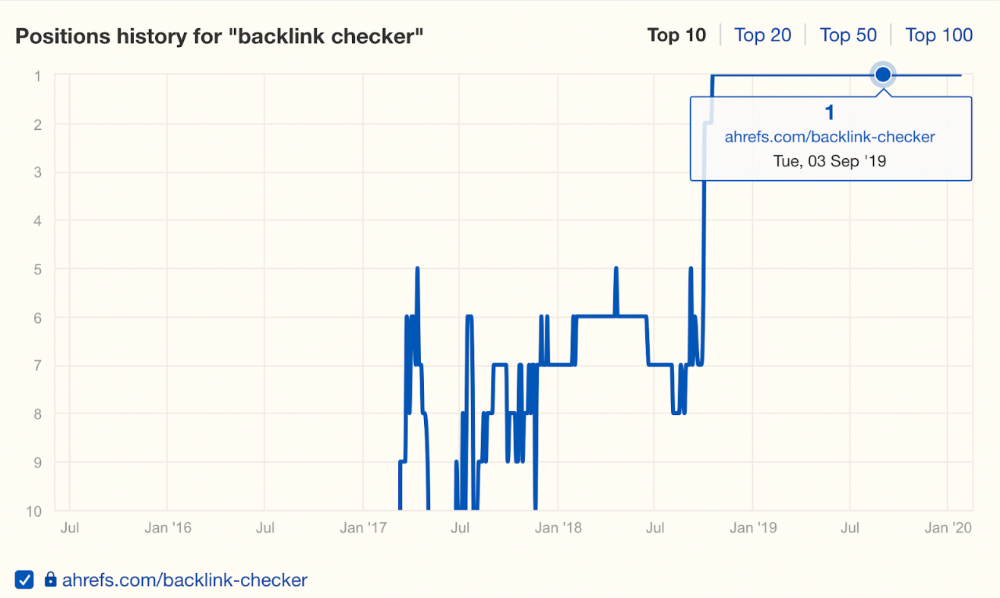
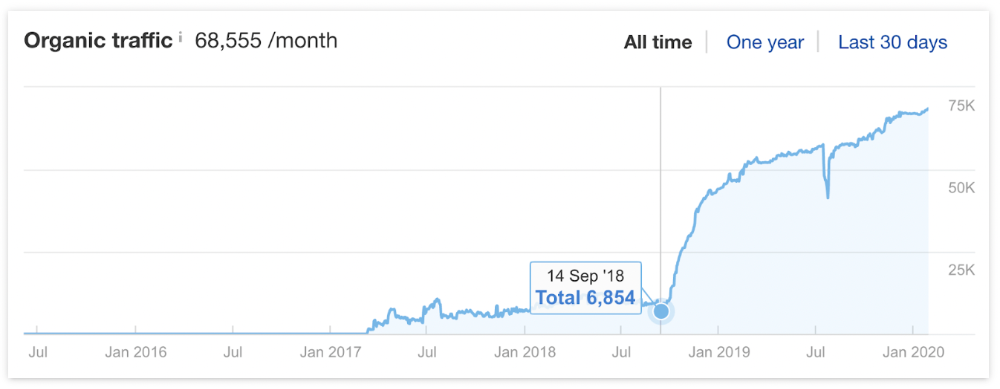
Reason #4: Unindexed page
Google can’t rank pages that aren’t indexed.
If you think this is the case, search Google for site:[url]. You should see at least one result; otherwise, it’s not indexed.
A rogue noindex meta tag is usually to blame. This tells search engines not to index a URL.
Rogue canonicals, redirects, and robots.txt blocks prevent indexing.
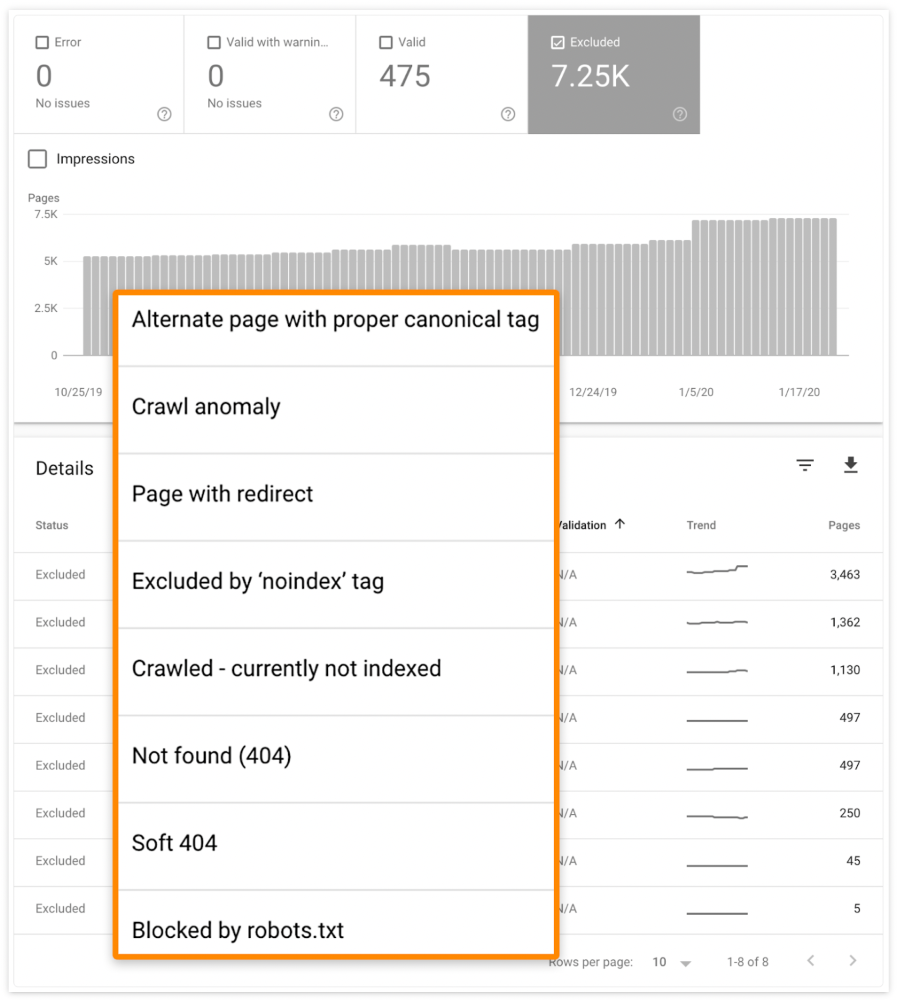
Check the "Excluded" tab in Google Search Console's "Coverage" report to see excluded pages.
Google doesn't index broken pages, even with backlinks.
Surprisingly common.
In Ahrefs' Site Explorer, the Best by Links report for a popular content marketing blog shows many broken pages.
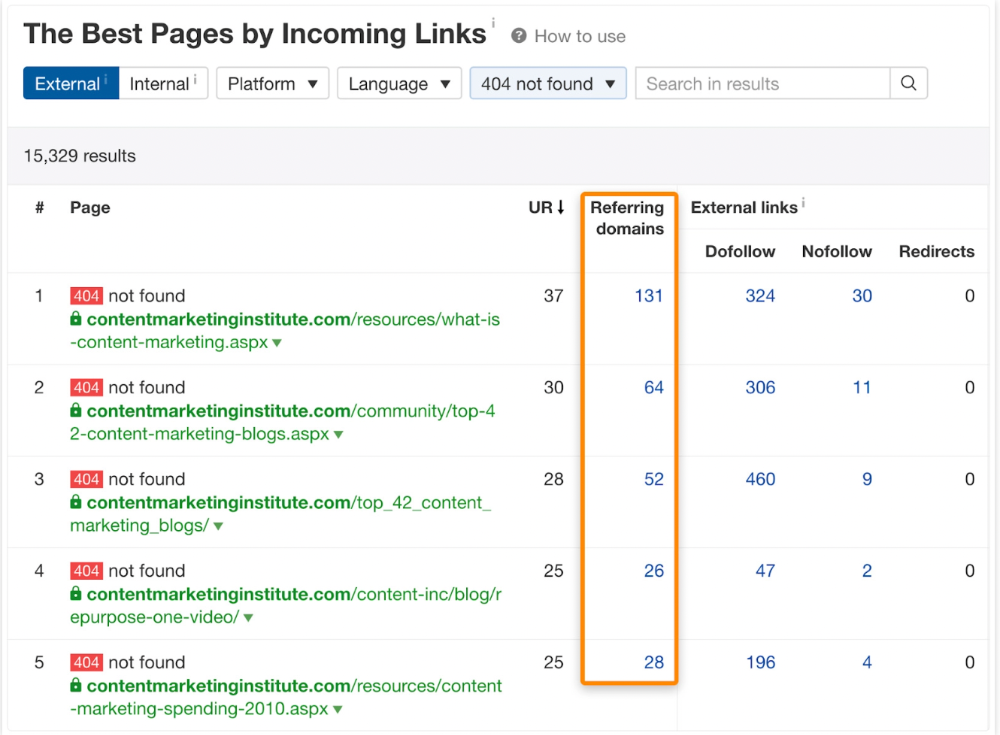
One dead page has 131 backlinks:
According to the URL, the page defined content marketing. —a keyword with a monthly search volume of 5,900 in the US.
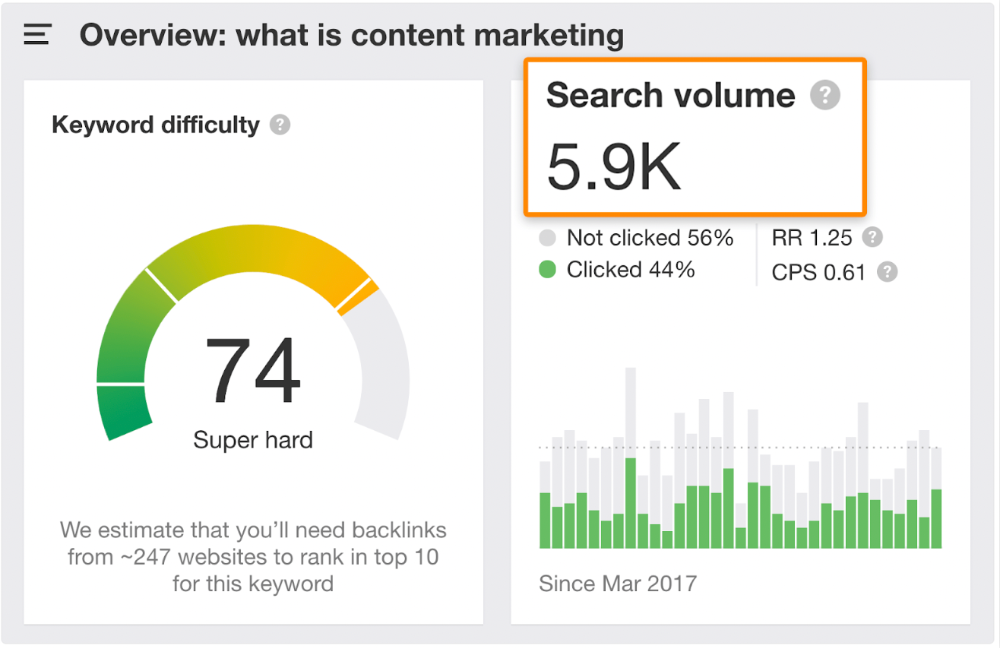
Luckily, another page ranks for this keyword. Not a huge loss.
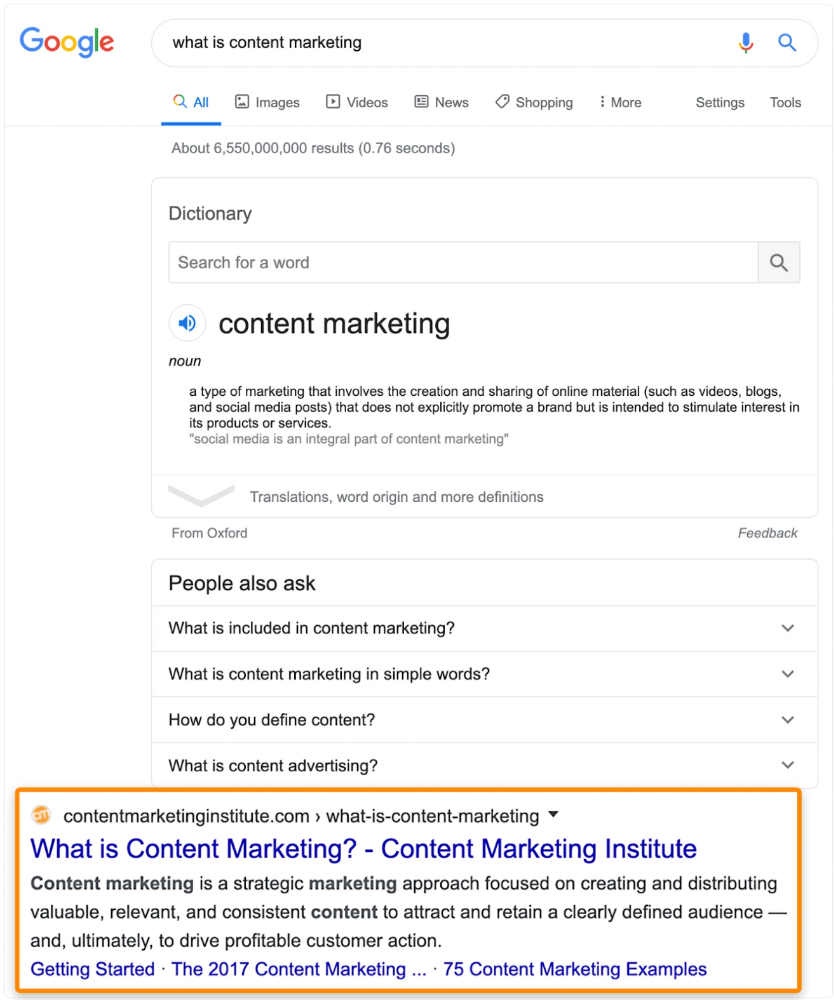
At least redirect the dead page's backlinks to a working page on the same topic. This may increase long-tail keyword traffic.
This post is a summary. See the original post here

Shawn Mordecai
3 years ago
The Apple iPhone 14 Pill is Easier to Swallow
Is iPhone's Dynamic Island invention or a marketing ploy?
First of all, why the notch?
When Apple debuted the iPhone X with the notch, some were surprised, confused, and amused by the goof. Let the Brits keep the new meaning of top-notch.
Apple removed the bottom home button to enhance screen space. The tides couldn't overtake part of the top. This section contained sensors, a speaker, a microphone, and cameras for facial recognition. A town resisted Apple's new iPhone design.
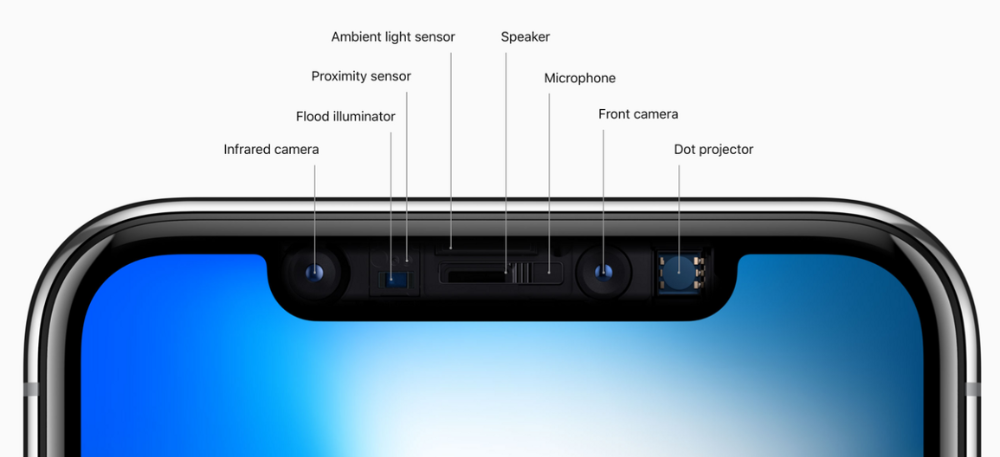
From iPhone X to 13, the notch has gotten smaller. We expected this as technology and engineering progressed, but we hated the notch. Apple approved. They attached it to their other gadgets.
Apple accepted, owned, and ran with the iPhone notch, it has become iconic (or infamous); and that’s intentional.
The Island Where Apple Is
Apple needs to separate itself, but they know how to do it well. The iPhone 14 Pro finally has us oohing and aahing. Life-changing, not just higher pixel density or longer battery.
Dynamic Island turned a visual differentiation into great usefulness, which may not be life-changing. Apple always welcomes the controversy, whether it's $700 for iMac wheels, no charging block with a new phone, or removing the headphone jack.
Apple knows its customers will be loyal, even if they're irritated. Their odd design choices often cause controversy. It's calculated that people blog, review, and criticize Apple's products. We accept what works for them.
While the competition zigs, Apple zags. Sometimes they zag too hard and smash into a wall, but we talk about it anyways, and that’s great publicity for them.
Getting Dependent on the drug
The notch became a crop. Dynamic Island's design is helpful, intuitive, elegant, and useful. It increases iPhone usability, productivity (slightly), and joy. No longer unsightly.
The medication helps with multitasking. It's a compact version of the iPhone's Live Activities lock screen function. Dynamic Island enhances apps and activities with visual effects and animations whether you engage with it or not. As you use the pill, its usefulness lessens. It lowers user notifications and consolidates them with live and permanent feeds, delivering quick app statuses. It uses the black pixels on the iPhone 14's display, which looked like a poor haircut.

The pill may be a gimmick to entice customers to use more Apple products and services. Apps may promote to their users like a live billboard.
Be prepared to get a huge dose of Dynamic Island’s “pill” like you never had before with the notch. It might become so satisfying and addicting to use, that every interaction with it will become habit-forming, and you’re going to forget that it ever existed.
WARNING: A Few Potential Side Effects
Vision blurred Dynamic Island's proximity to the front-facing camera may leave behind grease that blurs photos. Before taking a selfie, wipe the camera clean.
Strained thumb To fully use Dynamic Island, extend your thumb's reach 6.7 inches beyond your typical, comfortable range.
Happiness, contentment The Dynamic Island may enhance Endorphins and Dopamine. Multitasking, interactions, animations, and haptic feedback make you want to use this function again and again.
Motion-sickness Dynamic Island's motions and effects may make some people dizzy. If you can disable animations, you can avoid motion sickness.
I'm not a doctor, therefore they aren't established adverse effects.
Does Dynamic Island Include Multiple Tasks?
Dynamic Islands is a placebo for multitasking. Apple might have compromised on iPhone multitasking. It won't make you super productive, but it's a step up.

iPhone is primarily for personal use, like watching videos, messaging friends, sending money to friends, calling friends about the money you were supposed to send them, taking 50 photos of the same leaf, investing in crypto, driving for Uber because you lost all your money investing in crypto, listening to music and hailing an Uber from a deserted crop field because while you were driving for Uber your passenger stole your car and left you stranded, so you used Apple’s new SOS satellite feature to message your friend, who still didn’t receive their money, to hail you an Uber; now you owe them more money… karma?
We won't be watching videos on iPhones while perusing 10,000-row spreadsheets anytime soon. True multitasking and productivity aren't priorities for Apple's iPhone. Apple doesn't to preserve the iPhone's experience. Like why there's no iPad calculator. Apple doesn't want iPad users to do math, but isn't essential for productivity?
Digressing.
Apple will block certain functions so you must buy and use their gadgets and services, immersing yourself in their ecosystem and dictating how to use their goods.
Dynamic Island is a poor man’s multi-task for iPhone, and that’s fine it works for most iPhone users. For substantial productivity Apple prefers you to get an iPad or a MacBook. That’s part of the reason for restrictive features on certain Apple devices, but sometimes it’s based on principles to preserve the integrity of the product, according to Apple’s definition.
Is Apple using deception?
Dynamic Island may be distracting you from a design decision. The answer is kind of. Elegant distraction
When you pull down a smartphone webpage to refresh it or minimize an app, you get seamless animations. It's not simply because it appears better; it's due to iPhone and smartphone processing speeds. Such limits reduce the system's response to your activity, slowing the experience. Designers and developers use animations and effects to distract us from the time lag (most of the time) and sometimes because it looks cooler and smoother.
Dynamic Island makes apps more useable and interactive. It shows system states visually. Turn signal audio and visual cues, voice assistance, physical and digital haptic feedbacks, heads-up displays, fuel and battery level gauges, and gear shift indicators helped us overcome vehicle design problems.
Dynamic Island is a wonderfully delightful (and temporary) solution to a design “problem” until Apple or other companies can figure out a way to sink the cameras under the smartphone screen.

Apple Has Returned to Being an Innovative & Exciting Company
Now Apple's products are exciting. Next, bring back real Apple events, not pre-recorded demos.
Dynamic Island integrates hardware and software. What will this new tech do? How would this affect device use? Or is it just hype?
Dynamic Island may be an insignificant improvement to the iPhone, but it sure is promising for the future of bridging the human and computer interaction gap.
You might also like

forkast
4 years ago
Three Arrows Capital collapse sends crypto tremors

Three Arrows Capital's Google search volume rose over 5,000%.
Three Arrows Capital, a Singapore-based cryptocurrency hedge fund, filed for Chapter 15 bankruptcy last Friday to protect its U.S. assets from creditors.
Three Arrows filed for bankruptcy on July 1 in New York.
Three Arrows was ordered liquidated by a British Virgin Islands court last week after defaulting on a $670 million loan from Voyager Digital. Three days later, the Singaporean government reprimanded Three Arrows for spreading misleading information and exceeding asset limits.
Three Arrows' troubles began with Terra's collapse in May, after it bought US$200 million worth of Terra's LUNA tokens in February, co-founder Kyle Davies told the Wall Street Journal. Three Arrows has failed to meet multiple margin calls since then, including from BlockFi and Genesis.
Three Arrows Capital, founded by Kyle Davies and Su Zhu in 2012, manages $10 billion in crypto assets.
Bitcoin's price fell from US$20,600 to below US$19,200 after Three Arrows' bankruptcy petition. According to CoinMarketCap, BTC is now above US$20,000.
What does it mean?
Every action causes an equal and opposite reaction, per Newton's third law. Newtonian physics won't comfort Three Arrows investors, but future investors will thank them for their overconfidence.
Regulators are taking notice of crypto's meteoric rise and subsequent fall. Historically, authorities labeled the industry "high risk" to warn traditional investors against entering it. That attitude is changing. Regulators are moving quickly to regulate crypto to protect investors and prevent broader asset market busts.
The EU has reached a landmark deal that will regulate crypto asset sales and crypto markets across the 27-member bloc. The U.S. is close behind with a similar ruling, and smaller markets are also looking to improve safeguards.
For many, regulation is the only way to ensure the crypto industry survives the current winter.

Sea Launch
4 years ago
A guide to NFT pre-sales and whitelists
Before we dig through NFT whitelists and pre-sales, if you know absolutely nothing about NFTs, check our NFT Glossary.
What are pre-sales and whitelists on NFTs?
An NFT pre-sale, as the name implies, allows community members or early supporters of an NFT project to mint before the public, usually via a whitelist or mint pass.
Coin collectors can use mint passes to claim NFTs during the public sale. Because the mint pass is executed by “burning” an NFT into a specific crypto wallet, the collector is not concerned about gas price spikes.
A whitelist is used to approve a crypto wallet address for an NFT pre-sale. In a similar way to an early access list, it guarantees a certain number of crypto wallets can mint one (or more) NFT.
New NFT projects can do a pre-sale without a whitelist, but whitelists are good practice to avoid gas wars and a fair shot at minting an NFT before launching in competitive NFT marketplaces like Opensea, Magic Eden, or CNFT.
Should NFT projects do pre-sales or whitelists? 👇
The reasons to do pre-sales or a whitelist for NFT creators:
Time the market and gain traction.
Pre-sale or whitelists can help NFT projects gauge interest early on.
Whitelist spots filling up quickly is usually a sign of a successful launch, though it does not guarantee NFT longevity (more on that later). Also, full whitelists create FOMO and momentum for the public sale among non-whitelisted NFT collectors.
If whitelist signups are low or slow, projects may need to work on their vision, community, or product. Or the market is in a bear cycle. In either case, it aids NFT projects in market timing.
Reward the early NFT Community members.
Pre-sale and whitelists can help NFT creators reward early supporters.
First, by splitting the minting process into two phases, early adopters get a chance to mint one or more NFTs from their collection at a discounted or even free price.
Did you know that BAYC started at 0.08 eth each? A serum that allowed you to mint a Mutant Ape has become as valuable as the original BAYC.
(2) Whitelists encourage early supporters to help build a project's community in exchange for a slot or status. If you invite 10 people to the NFT Discord community, you get a better ranking or even a whitelist spot.
Pre-sale and whitelisting have become popular ways for new projects to grow their communities and secure future buyers.
Prevent gas wars.
Most new NFTs are created on the Ethereum blockchain, which has the highest transaction fees (also known as gas) (Solana, Cardano, Polygon, Binance Smart Chain, etc).
An NFT public sale is a gas war when a large number of NFT collectors (or bots) try to mint an NFT at the same time.
Competing collectors are willing to pay higher gas fees to prioritize their transaction and out-price others when upcoming NFT projects are hyped and very popular.
Pre-sales and whitelisting prevent gas wars by breaking the minting process into smaller batches of members or season launches.
The reasons to do pre-sales or a whitelists for NFT collectors:
How do I get on an NFT whitelist?
- Popular NFT collections act as a launchpad for other new or hyped NFT collections.
Example: Interfaces NFTs gives out 100 whitelist spots to Deadfellaz NFTs holders. Both NFT projects win. Interfaces benefit from Deadfellaz's success and brand equity.
In this case, to get whitelisted NFT collectors need to hold that specific NFT that is acting like a launchpad.
- A NFT studio or collection that launches a new NFT project and rewards previous NFT holders with whitelist spots or pre-sale access.
The whitelist requires previous NFT holders or community members.
NFT Alpha Groups are closed, small, tight-knit Discord servers where members share whitelist spots or giveaways from upcoming NFTs.
The benefit of being in an alpha group is getting information about new NFTs first and getting in on pre-sale/whitelist before everyone else.
There are some entry barriers to alpha groups, but if you're active in the NFT community, you'll eventually bump into, be invited to, or form one.
- A whitelist spot is awarded to members of an NFT community who are the most active and engaged.
This participation reward is the most democratic. To get a chance, collectors must work hard and play to their strengths.
Whitelisting participation examples:
- Raffle, games and contest: NFT Community raffles, games, and contests. To get a whitelist spot, invite 10 people to X NFT Discord community.
- Fan art: To reward those who add value and grow the community by whitelisting the best fan art and/or artists is only natural.
- Giveaways: Lucky number crypto wallet giveaways promoted by an NFT community. To grow their communities and for lucky collectors, NFT projects often offer free NFT.
- Activate your voice in the NFT Discord Community. Use voice channels to get NFT teams' attention and possibly get whitelisted.
The advantage of whitelists or NFT pre-sales.
Chainalysis's NFT stats quote is the best answer:
“Whitelisting isn’t just some nominal reward — it translates to dramatically better investing results. OpenSea data shows that users who make the whitelist and later sell their newly-minted NFT gain a profit 75.7% of the time, versus just 20.8% for users who do so without being whitelisted. Not only that, but the data suggests it’s nearly impossible to achieve outsized returns on minting purchases without being whitelisted.” Full report here.
Sure, it's not all about cash. However, any NFT collector should feel secure in their investment by owning a piece of a valuable and thriving NFT project. These stats help collectors understand that getting in early on an NFT project (via whitelist or pre-sale) will yield a better and larger return.
The downsides of pre-sales & whitelists for NFT creators.
Pre-sales and whitelist can cause issues for NFT creators and collectors.
NFT flippers
NFT collectors who only want to profit from early minting (pre-sale) or low mint cost (via whitelist). To sell the NFT in a secondary market like Opensea or Solanart, flippers go after the discounted price.
For example, a 1000 Solana NFT collection allows 100 people to mint 1 Solana NFT at 0.25 SOL. The public sale price for the remaining 900 NFTs is 1 SOL. If an NFT collector sells their discounted NFT for 0.5 SOL, the secondary market floor price is below the public mint.
This may deter potential NFT collectors. Furthermore, without a cap in the pre-sale minting phase, flippers can get as many NFTs as possible to sell for a profit, dumping them in secondary markets and driving down the floor price.
Hijacking NFT sites, communities, and pre-sales phase
People try to scam the NFT team and their community by creating oddly similar but fake websites, whitelist links, or NFT's Discord channel.
Established and new NFT projects must be vigilant to always make sure their communities know which are the official links, how a whitelist or pre-sale rules and how the team will contact (or not) community members.
Another way to avoid the scams around the pre-sale phase, NFT projects opt to create a separate mint contract for the whitelisted crypto wallets and then another for the public sale phase.
Scam NFT projects
We've seen a lot of mid-mint or post-launch rug pulls, indicating that some bad NFT projects are trying to scam NFT communities and marketplaces for quick profit. What happened to Magic Eden's launchpad recently will help you understand the scam.
We discussed the benefits and drawbacks of NFT pre-sales and whitelists for both projects and collectors.
Finally, some practical tools and tips for finding new NFTs 👇
Tools & resources to find new NFT on pre-sale or to get on a whitelist:
In order to never miss an update, important pre-sale dates, or a giveaway, create a Tweetdeck or Tweeten Twitter dashboard with hyped NFT project pages, hashtags ( #NFTGiveaways , #NFTCommunity), or big NFT influencers.
Search for upcoming NFT launches that have been vetted by the marketplace and try to get whitelisted before the public launch.
Save-timing discovery platforms like sealaunch.xyz for NFT pre-sales and upcoming launches. How can we help 100x NFT collectors get projects? A project's official social media links, description, pre-sale or public sale dates, price and supply. We're also working with Dune on NFT data analysis to help NFT collectors make better decisions.
Don't invest what you can't afford to lose because a) the project may fail or become rugged. Find NFTs projects that you want to be a part of and support.
Read original post here

Glorin Santhosh
3 years ago
In his final days, Steve Jobs sent an email to himself. What It Said Was This
An email capturing Steve Jobs's philosophy.

Steve Jobs may have been the most inspired and driven entrepreneur.
He worked on projects because he wanted to leave a legacy.
Steve Jobs' final email to himself encapsulated his philosophy.
After his death from pancreatic cancer in October 2011, Laurene Powell Jobs released the email. He was 56.
Read: Steve Jobs by Walter Isaacson (#BestSeller)
The Email:
September 2010 Steve Jobs email:
“I grow little of the food I eat, and of the little I do grow, I do not breed or perfect the seeds.” “I do not make my own clothing. I speak a language I did not invent or refine,” he continued. “I did not discover the mathematics I use… I am moved by music I did not create myself.”
Jobs ended his email by reflecting on how others created everything he uses.
He wrote:
“When I needed medical attention, I was helpless to help myself survive.”

The Apple co-founder concluded by praising humanity.
“I did not invent the transistor, the microprocessor, object-oriented programming, or most of the technology I work with. I love and admire my species, living and dead, and am totally dependent on them for my life and well-being,” he concluded.
The email was made public as a part of the Steve Jobs Archive, a website that was launched in tribute to his legacy.
Steve Jobs' widow founded the internet archive. Apple CEO Tim Cook and former design leader Jony Ive were prominent guests.
Steve Jobs has always inspired because he shows how even the best can be improved.
High expectations were always there, and they were consistently met.
We miss him because he was one of the few with lifelong enthusiasm and persona.