









More on Personal Growth

Entreprogrammer
3 years ago
The Steve Jobs Formula: A Guide to Everything
A must-read for everyone

Jobs is well-known. You probably know the tall, thin guy who wore the same clothing every day. His influence is unavoidable. In fewer than 40 years, Jobs' innovations have impacted computers, movies, cellphones, music, and communication.
Steve Jobs may be more imaginative than the typical person, but if we can use some of his ingenuity, ambition, and good traits, we'll be successful. This essay explains how to follow his guidance and success secrets.
1. Repetition is necessary for success.
Be patient and diligent to master something. Practice makes perfect. This is why older workers are often more skilled.
When should you repeat a task? When you're confident and excited to share your product. It's when to stop tweaking and repeating.
Jobs stated he'd make the crowd sh** their pants with an iChat demo.
Use this in your daily life.
Start with the end in mind. You can put it in writing and be as detailed as you like with your plan's schedule and metrics. For instance, you have a goal of selling three coffee makers in a week.
Break it down, break the goal down into particular tasks you must complete, and then repeat those tasks. To sell your coffee maker, you might need to make 50 phone calls.
Be mindful of the amount of work necessary to produce the desired results. Continue doing this until you are happy with your product.
2. Acquire the ability to add and subtract.
How did Picasso invent cubism? Pablo Picasso was influenced by stylised, non-naturalistic African masks that depict a human figure.
Artists create. Constantly seeking inspiration. They think creatively about random objects. Jobs said creativity is linking things. Creative people feel terrible when asked how they achieved something unique because they didn't do it all. They saw innovation. They had mastered connecting and synthesizing experiences.
Use this in your daily life.
On your phone, there is a note-taking app. Ideas for what you desire to learn should be written down. It may be learning a new language, calligraphy, or anything else that inspires or intrigues you.
Note any ideas you have, quotations, or any information that strikes you as important.
Spend time with smart individuals, that is the most important thing. Jim Rohn, a well-known motivational speaker, has observed that we are the average of the five people with whom we spend the most time.
Learning alone won't get you very far. You need to put what you've learnt into practice. If you don't use your knowledge and skills, they are useless.
3. Develop the ability to refuse.
Steve Jobs deleted thousands of items when he created Apple's design ethic. Saying no to distractions meant upsetting customers and partners.
John Sculley, the former CEO of Apple, said something like this. According to Sculley, Steve’s methodology differs from others as he always believed that the most critical decisions are things you choose not to do.
Use this in your daily life.
Never be afraid to say "no," "I won't," or "I don't want to." Keep it simple. This method works well in some situations.
Give a different option. For instance, X might be interested even if I won't be able to achieve it.
Control your top priority. Before saying yes to anything, make sure your work schedule and priority list are up to date.
4. Follow your passion
“Follow your passion” is the worst advice people can give you. Steve Jobs didn't start Apple because he suddenly loved computers. He wanted to help others attain their maximum potential.
Great things take a lot of work, so quitting makes sense if you're not passionate. Jobs learned from history that successful people were passionate about their work and persisted through challenges.
Use this in your daily life.
Stay away from your passion. Allow it to develop daily. Keep working at your 9-5-hour job while carefully gauging your level of desire and endurance. Less risk exists.
The truth is that if you decide to work on a project by yourself rather than in a group, it will take you years to complete it instead of a week. Instead, network with others who have interests in common.
Prepare a fallback strategy in case things go wrong.
Success, this small two-syllable word eventually gives your life meaning, a perspective. What is success? For most, it's achieving their ambitions. However, there's a catch. Successful people aren't always happy.
Furthermore, where do people’s goals and achievements end? It’s a never-ending process. Success is a journey, not a destination. We wish you not to lose your way on this journey.
Matthew Royse
3 years ago
Ten words and phrases to avoid in presentations
Don't say this in public!

Want to wow your audience? Want to deliver a successful presentation? Do you want practical takeaways from your presentation?
Then avoid these phrases.
Public speaking is difficult. People fear public speaking, according to research.
"Public speaking is people's biggest fear, according to studies. Number two is death. "Sounds right?" — Comedian Jerry Seinfeld
Yes, public speaking is scary. These words and phrases will make your presentation harder.
Using unnecessary words can weaken your message.
You may have prepared well for your presentation and feel confident. During your presentation, you may freeze up. You may blank or forget.
Effective delivery is even more important than skillful public speaking.
Here are 10 presentation pitfalls.
1. I or Me
Presentations are about the audience, not you. Replace "I or me" with "you, we, or us." Focus on your audience. Reward them with expertise and intriguing views about your issue.
Serve your audience actionable items during your presentation, and you'll do well. Your audience will have a harder time listening and engaging if you're self-centered.
2. Sorry if/for
Your presentation is fine. These phrases make you sound insecure and unprepared. Don't pressure the audience to tell you not to apologize. Your audience should focus on your presentation and essential messages.
3. Excuse the Eye Chart, or This slide's busy
Why add this slide if you're utilizing these phrases? If you don't like this slide, change it before presenting. After the presentation, extra data can be provided.
Don't apologize for unclear slides. Hide or delete a broken PowerPoint slide. If so, divide your message into multiple slides or remove the "business" slide.
4. Sorry I'm Nervous
Some think expressing yourself will win over the audience. Nerves are horrible. Even public speakers are nervous.
Nerves aren't noticeable. What's the point? Let the audience judge your nervousness. Please don't make this obvious.
5. I'm not a speaker or I've never done this before.
These phrases destroy credibility. People won't listen and will check their phones or computers.
Why present if you use these phrases?
Good speakers aren't necessarily public speakers. Be confident in what you say. When you're confident, many people will like your presentation.
6. Our Key Differentiators Are
Overused term. It's widely utilized. This seems "salesy," and your "important differentiators" are probably like a competitor's.
This statement has been diluted; say, "what makes us different is..."
7. Next Slide
Many slides or stories? Your presentation needs transitions. They help your viewers understand your argument.
You didn't transition well when you said "next slide." Think about organic transitions.
8. I Didn’t Have Enough Time, or I’m Running Out of Time
The phrase "I didn't have enough time" implies that you didn't care about your presentation. This shows the viewers you rushed and didn't care.
Saying "I'm out of time" shows poor time management. It means you didn't rehearse enough and plan your time well.
9. I've been asked to speak on
This phrase is used to emphasize your importance. This phrase conveys conceit.
When you say this sentence, you tell others you're intelligent, skilled, and appealing. Don't utilize this term; focus on your topic.
10. Moving On, or All I Have
These phrases don't consider your transitions or presentation's end. People recall a presentation's beginning and end.
How you end your discussion affects how people remember it. You must end your presentation strongly and use natural transitions.
Conclusion
10 phrases to avoid in a presentation. I or me, sorry if or sorry for, pardon the Eye Chart or this busy slide, forgive me if I appear worried, or I'm really nervous, and I'm not good at public speaking, I'm not a speaker, or I've never done this before.
Please don't use these phrases: next slide, I didn't have enough time, I've been asked to speak about, or that's all I have.
We shouldn't make public speaking more difficult than it is. We shouldn't exacerbate a difficult issue. Better public speakers avoid these words and phrases.
“Remember not only to say the right thing in the right place, but far more difficult still, to leave unsaid the wrong thing at the tempting moment.” — Benjamin Franklin, Founding Father
This is a summary. See the original post here.

Hudson Rennie
3 years ago
My Work at a $1.2 Billion Startup That Failed
Sometimes doing everything correctly isn't enough.

In 2020, I could fix my life.
After failing to start a business, I owed $40,000 and had no work.
A $1.2 billion startup on the cusp of going public pulled me up.
Ironically, it was getting ready for an epic fall — with the world watching.
Life sometimes helps. Without a base, even the strongest fall. A corporation that did everything right failed 3 months after going public.
First-row view.
Apple is the creator of Adore.
Out of respect, I've altered the company and employees' names in this account, despite their failure.
Although being a publicly traded company, it may become obvious.
We’ll call it “Adore” — a revolutionary concept in retail shopping.
Two Apple execs established Adore in 2014 with a focus on people-first purchasing.
Jon and Tim:
The concept for the stylish Apple retail locations you see today was developed by retail expert Jon Swanson, who collaborated closely with Steve Jobs.
Tim Cruiter is a graphic designer who produced the recognizable bouncing lamp video that appears at the start of every Pixar film.
The dynamic duo realized their vision.
“What if you could combine the convenience of online shopping with the confidence of the conventional brick-and-mortar store experience.”
Adore's mobile store concept combined traditional retail with online shopping.
Adore brought joy to 70+ cities and 4 countries over 7 years, including the US, Canada, and the UK.
Being employed on the ground floor, with world dominance and IPO on the horizon, was exciting.
I started as an Adore Expert.
I delivered cell phones, helped consumers set them up, and sold add-ons.
As the company grew, I became a Virtual Learning Facilitator and trained new employees across North America using Zoom.
In this capacity, I gained corporate insider knowledge. I worked with the creative team and Jon and Tim.
It's where I saw company foundation fissures. Despite appearances, investors were concerned.
The business strategy was ground-breaking.
Even after seeing my employee stocks fall from a home down payment to $0 (when Adore filed for bankruptcy), it's hard to pinpoint what went wrong.
Solid business model, well-executed.
Jon and Tim's chase for public funding ended in glory.
Here’s the business model in a nutshell:
Buying cell phones is cumbersome. You have two choices:
Online purchase: not knowing what plan you require or how to operate your device.
Enter a store, which can be troublesome and stressful.
Apple, AT&T, and Rogers offered Adore as a free delivery add-on. Customers could:
Have their phone delivered by UPS or Canada Post in 1-2 weeks.
Alternately, arrange for a person to visit them the same day (or sometimes even the same hour) to assist them set up their phone and demonstrate how to use it (transferring contacts, switching the SIM card, etc.).
Each Adore Expert brought a van with extra devices and accessories to customers.
Happy customers.
Here’s how Adore and its partners made money:
Adores partners appreciated sending Experts to consumers' homes since they improved customer satisfaction, average sale, and gadget returns.
**Telecom enterprises have low customer satisfaction. The average NPS is 30/100. Adore's global NPS was 80.
Adore made money by:
a set cost for each delivery
commission on sold warranties and extras
Consumer product applications seemed infinite.
A proprietary scheduling system (“The Adore App”), allowed for same-day, even same-hour deliveries.
It differentiates Adore.
They treated staff generously by:
Options on stock
health advantages
sales enticements
high rates per hour
Four-day workweeks were set by experts.
Being hired early felt like joining Uber, Netflix, or Tesla. We hoped the company's stocks would rise.
Exciting times.
I smiled as I greeted more than 1,000 new staff.
I spent a decade in retail before joining Adore. I needed a change.
After a leap of faith, I needed a lifeline. So, I applied for retail sales jobs in the spring of 2019.
The universe typically offers you what you want after you accept what you need. I needed a job to settle my debt and reach $0 again.
And the universe listened.
After being hired as an Adore Expert, I became a Virtual Learning Facilitator. Enough said.
After weeks of economic damage from the pandemic.
This employment let me work from home during the pandemic. It taught me excellent business skills.
I was active in brainstorming, onboarding new personnel, and expanding communication as we grew.
This job gave me vital skills and a regular paycheck during the pandemic.
It wasn’t until January of 2022 that I left on my own accord to try to work for myself again — this time, it’s going much better.
Adore was perfect. We valued:
Connection
Discovery
Empathy
Everything we did centered on compassion, and we held frequent Justice Calls to discuss diversity and work culture.
The last day of onboarding typically ended in tears as employees felt like they'd found a home, as I had.
Like all nice things, the wonderful vibes ended.
First indication of distress
My first day at the workplace was great.
Fun, intuitive, and they wanted creative individuals, not salesman.
While sales were important, the company's vision was more important.
“To deliver joy through life-changing mobile retail experiences.”
Thorough, forward-thinking training. We had a module on intuition. It gave us role ownership.
We were flown cross-country for training, gave feedback, and felt like we made a difference. Multiple contacts responded immediately and enthusiastically.
The atmosphere was genuine.
Making money was secondary, though. Incredible service was a priority.
Jon and Tim answered new hires' questions during Zoom calls during onboarding. CEOs seldom meet new hires this way, but they seemed to enjoy it.
All appeared well.
But in late 2021, things started changing.
Adore's leadership changed after its IPO. From basic values to sales maximization. We lost communication and were forced to fend for ourselves.
Removed the training wheels.
It got tougher to gain instructions from those above me, and new employees told me their roles weren't as advertised.
External money-focused managers were hired.
Instead of creative types, we hired salespeople.
With a new focus on numbers, Adore's uniqueness began to crumble.
Via Zoom, hundreds of workers were let go.
So.
Early in 2022, mass Zoom firings were trending. A CEO firing 900 workers over Zoom went viral.
Adore was special to me, but it became a headline.
30 June 2022, Vice Motherboard published Watch as Adore's CEO Fires Hundreds.
It described a leaked video of Jon Swanson laying off all staff in Canada and the UK.
They called it a “notice of redundancy”.
The corporation couldn't pay its employees.
I loved Adore's underlying ideals, among other things. We called clients Adorers and sold solutions, not add-ons.
But, like anything, a company is only as strong as its weakest link. And obviously, the people-first focus wasn’t making enough money.
There were signs. The expansion was presumably a race against time and money.
Adore finally declared bankruptcy.
Adore declared bankruptcy 3 months after going public. It happened in waves, like any large-scale fall.
Initial key players to leave were
Then, communication deteriorated.
Lastly, the corporate culture disintegrated.
6 months after leaving Adore, I received a letter in the mail from a Law firm — it was about my stocks.
Adore filed Chapter 11. I had to sue to collect my worthless investments.
I hoped those stocks will be valuable someday. Nope. Nope.
Sad, I sighed.
$1.2 billion firm gone.
I left the workplace 3 months before starting a writing business. Despite being mediocre, I'm doing fine.
I got up as Adore fell.
Finally, can we scale kindness?
I trust my gut. Changes at Adore made me leave before it sank.
Adores' unceremonious slide from a top startup to bankruptcy is astonishing to me.
The company did everything perfectly, in my opinion.
first to market,
provided excellent service
paid their staff handsomely.
was responsible and attentive to criticism
The company wasn't led by an egotistical eccentric. The crew had centuries of cumulative space experience.
I'm optimistic about the future of work culture, but is compassion scalable?
You might also like

Modern Eremite
3 years ago
The complete, easy-to-understand guide to bitcoin

Introduction
Markets rely on knowledge.
The internet provided practically endless knowledge and wisdom. Humanity has never seen such leverage. Technology's progress drives us to adapt to a changing world, changing our routines and behaviors.
In a digital age, people may struggle to live in the analogue world of their upbringing. Can those who can't adapt change their lives? I won't answer. We should teach those who are willing to learn, nevertheless. Unravel the modern world's riddles and give them wisdom.
Adapt or die . Accept the future or remain behind.
This essay will help you comprehend Bitcoin better than most market participants and the general public. Let's dig into Bitcoin.
Join me.

Ascension
Bitcoin.org was registered in August 2008. Bitcoin whitepaper was published on 31 October 2008. The document intrigued and motivated people around the world, including technical engineers and sovereignty seekers. Since then, Bitcoin's whitepaper has been read and researched to comprehend its essential concept.
I recommend reading the whitepaper yourself. You'll be able to say you read the Bitcoin whitepaper instead of simply Googling "what is Bitcoin" and reading the fundamental definition without knowing the revolution's scope. The article links to Bitcoin's whitepaper. To avoid being overwhelmed by the whitepaper, read the following article first.
Bitcoin isn't the first peer-to-peer digital currency. Hashcash or Bit Gold were once popular cryptocurrencies. These two Bitcoin precursors failed to gain traction and produce the network effect needed for general adoption. After many struggles, Bitcoin emerged as the most successful cryptocurrency, leading the way for others.
Satoshi Nakamoto, an active bitcointalk.org user, created Bitcoin. Satoshi's identity remains unknown. Satoshi's last bitcointalk.org login was 12 December 2010. Since then, he's officially disappeared. Thus, conspiracies and riddles surround Bitcoin's creators. I've heard many various theories, some insane and others well-thought-out.
It's not about who created it; it's about knowing its potential. Since its start, Satoshi's legacy has changed the world and will continue to.
Block-by-block blockchain
Bitcoin is a distributed ledger. What's the meaning?
Everyone can view all blockchain transactions, but no one can undo or delete them.
Imagine you and your friends routinely eat out, but only one pays. You're careful with money and what others owe you. How can everyone access the info without it being changed?

You'll keep a notebook of your evening's transactions. Everyone will take a page home. If one of you changed the page's data, the group would notice and reject it. The majority will establish consensus and offer official facts.
Miners add a new Bitcoin block to the main blockchain every 10 minutes. The appended block contains miner-verified transactions. Now that the next block has been added, the network will receive the next set of user transactions.
Bitcoin Proof of Work—prove you earned it
Any firm needs hardworking personnel to expand and serve clients. Bitcoin isn't that different.
Bitcoin's Proof of Work consensus system needs individuals to validate and create new blocks and check for malicious actors. I'll discuss Bitcoin's blockchain consensus method.
Proof of Work helps Bitcoin reach network consensus. The network is checked and safeguarded by CPU, GPU, or ASIC Bitcoin-mining machines (Application-Specific Integrated Circuit).
Every 10 minutes, miners are rewarded in Bitcoin for securing and verifying the network. It's unlikely you'll finish the block. Miners build pools to increase their chances of winning by combining their processing power.
In the early days of Bitcoin, individual mining systems were more popular due to high maintenance costs and larger earnings prospects. Over time, people created larger and larger Bitcoin mining facilities that required a lot of space and sophisticated cooling systems to keep machines from overheating.
Proof of Work is a vital part of the Bitcoin network, as network security requires the processing power of devices purchased with fiat currency. Miners must invest in mining facilities, which creates a new business branch, mining facilities ownership. Bitcoin mining is a topic for a future article.
More mining, less reward
Bitcoin is usually scarce.
Why is it rare? It all comes down to 21,000,000 Bitcoins.
Were all Bitcoins mined? Nope. Bitcoin's supply grows until it hits 21 million coins. Initially, 50BTC each block was mined, and each block took 10 minutes. Around 2140, the last Bitcoin will be mined.
But 50BTC every 10 minutes does not give me the year 2140. Indeed careful reader. So important is Bitcoin's halving process.
What is halving?
The block reward is halved every 210,000 blocks, which takes around 4 years. The initial payout was 50BTC per block and has been decreased to 25BTC after 210,000 blocks. First halving occurred on November 28, 2012, when 10,500,000 BTC (50%) had been mined. As of April 2022, the block reward is 6.25BTC and will be lowered to 3.125BTC by 19 March 2024.
The halving method is tied to Bitcoin's hashrate. Here's what "hashrate" means.
What if we increased the number of miners and hashrate they provide to produce a block every 10 minutes? Wouldn't we manufacture blocks faster?

Every 10 minutes, blocks are generated with little asymmetry. Due to the built-in adaptive difficulty algorithm, the overall hashrate does not affect block production time. With increased hashrate, it's harder to construct a block. We can estimate when the next halving will occur because 10 minutes per block is fixed.
Building with nodes and blocks
For someone new to crypto, the unusual terms and words may be overwhelming. You'll also find everyday words that are easy to guess or have a vague idea of what they mean, how they work, and what they do. Consider blockchain technology.
Nodes and blocks: Think about that for a moment. What is your first idea?
The blockchain is a chain of validated blocks added to the main chain. What's a "block"? What's inside?
The block is another page in the blockchain book that has been filled with transaction information and accepted by the majority.
We won't go into detail about what each block includes and how it's built, as long as you understand its purpose.
What about nodes?
Nodes, along with miners, verify the blockchain's state independently. But why?
To create a full blockchain node, you must download the whole Bitcoin blockchain and check every transaction against Bitcoin's consensus criteria.
What's Bitcoin's size?
In April 2022, the Bitcoin blockchain was 389.72GB.
Bitcoin's blockchain has miners and node runners.
Let's revisit the US gold rush. Miners mine gold with their own power (physical and monetary resources) and are rewarded with gold (Bitcoin). All become richer with more gold, and so does the country.
Nodes are like sheriffs, ensuring everything is done according to consensus rules and that there are no rogue miners or network users.
Lost and held bitcoin
Does the Bitcoin exchange price match each coin's price? How many coins remain after 21,000,000? 21 million or less?
Common reason suggests a 21 million-coin supply.
What if I lost 1BTC from a cold wallet?
What if I saved 1000BTC on paper in 2010 and it was damaged?
What if I mined Bitcoin in 2010 and lost the keys?
Satoshi Nakamoto's coins? Since then, those coins haven't moved.
How many BTC are truly in circulation?
Many people are trying to answer this question, and you may discover a variety of studies and individual research on the topic. Be cautious of the findings because they can't be evaluated and the statistics are hazy guesses.
On the other hand, we have long-term investors who won't sell their Bitcoin or will sell little amounts to cover mining or living needs.
The price of Bitcoin is determined by supply and demand on exchanges using liquid BTC. How many BTC are left after subtracting lost and non-custodial BTC?
We have significantly less Bitcoin in circulation than you think, thus the price may not reflect demand if we knew the exact quantity of coins available.
True HODLers and diamond-hand investors won't sell you their coins, no matter the market.
What's UTXO?
Unspent (U) Transaction (TX) Output (O)

Imagine taking a $100 bill to a store. After choosing a drink and munchies, you walk to the checkout to pay. The cashier takes your $100 bill and gives you $25.50 in change. It's in your wallet.
Is it simply 100$? No way.
The $25.50 in your wallet is unrelated to the $100 bill you used. Your wallet's $25.50 is just bills and coins. Your wallet may contain these coins and bills:
2x 10$ 1x 10$
1x 5$ or 3x 5$
1x 0.50$ 2x 0.25$
Any combination of coins and bills can equal $25.50. You don't care, and I'd wager you've never ever considered it.
That is UTXO. Now, I'll detail the Bitcoin blockchain and how UTXO works, as it's crucial to know what coins you have in your (hopefully) cold wallet.
You purchased 1BTC. Is it all? No. UTXOs equal 1BTC. Then send BTC to a cold wallet. Say you pay 0.001BTC and send 0.999BTC to your cold wallet. Is it the 1BTC you got before? Well, yes and no. The UTXOs are the same or comparable as before, but the blockchain address has changed. It's like if you handed someone a wallet, they removed the coins needed for a network charge, then returned the rest of the coins and notes.
UTXO is a simple concept, but it's crucial to grasp how it works to comprehend dangers like dust attacks and how coins may be tracked.
Lightning Network: fast cash
You've probably heard of "Layer 2 blockchain" projects.
What does it mean?
Layer 2 on a blockchain is an additional layer that increases the speed and quantity of transactions per minute and reduces transaction fees.
Imagine going to an obsolete bank to transfer money to another account and having to pay a charge and wait. You can transfer funds via your bank account or a mobile app without paying a fee, or the fee is low, and the cash appear nearly quickly. Layer 1 and 2 payment systems are different.
Layer 1 is not obsolete; it merely has more essential things to focus on, including providing the blockchain with new, validated blocks, whereas Layer 2 solutions strive to offer Layer 1 with previously processed and verified transactions. The primary blockchain, Bitcoin, will only receive the wallets' final state. All channel transactions until shutting and balancing are irrelevant to the main chain.
Layer 2 and the Lightning Network's goal are now clear. Most Layer 2 solutions on multiple blockchains are created as blockchains, however Lightning Network is not. Remember the following remark, as it best describes Lightning.

Lightning Network connects public and private Bitcoin wallets.
Opening a private channel with another wallet notifies just two parties. The creation and opening of a public channel tells the network that anyone can use it.
Why create a public Lightning Network channel?
Every transaction through your channel generates fees.
Money, if you don't know.
See who benefits when in doubt.
Anonymity, huh?
Bitcoin anonymity? Bitcoin's anonymity was utilized to launder money.
Well… You've heard similar stories. When you ask why or how it permits people to remain anonymous, the conversation ends as if it were just a story someone heard.
Bitcoin isn't private. Pseudonymous.
What if someone tracks your transactions and discovers your wallet address? Where is your anonymity then?

Bitcoin is like bulletproof glass storage; you can't take or change the money. If you dig and analyze the data, you can see what's inside.
Every online action leaves a trace, and traces may be tracked. People often forget this guideline.
A tool like that can help you observe what the major players, or whales, are doing with their coins when the market is uncertain. Many people spend time analyzing on-chain data. Worth it?
Ask yourself a question. What are the big players' options? Do you think they're letting you see their wallets for a small on-chain data fee?
Instead of short-term behaviors, focus on long-term trends.
More wallet transactions leave traces. Having nothing to conceal isn't a defect. Can it lead to regulating Bitcoin so every transaction is tracked like in banks today?
But wait. How can criminals pay out Bitcoin? They're doing it, aren't they?
Mixers can anonymize your coins, letting you to utilize them freely. This is not a guide on how to make your coins anonymous; it could do more harm than good if you don't know what you're doing.
Remember, being anonymous attracts greater attention.
Bitcoin isn't the only cryptocurrency we can use to buy things. Using cryptocurrency appropriately can provide usability and anonymity. Monero (XMR), Zcash (ZEC), and Litecoin (LTC) following the Mimblewimble upgrade are examples.
Summary
Congratulations! You've reached the conclusion of the article and learned about Bitcoin and cryptocurrency. You've entered the future.
You know what Bitcoin is, how its blockchain works, and why it's not anonymous. I bet you can explain Lightning Network and UTXO to your buddies.
Markets rely on knowledge. Prepare yourself for success before taking the first step. Let your expertise be your edge.
This article is a summary of this one.

Frank Andrade
3 years ago
I discovered a bug that allowed me to use ChatGPT to successfully web scrape. Here's how it operates.
This method scrapes websites with ChatGPT (demo with Amazon and Twitter)

In a recent article, I demonstrated how to scrape websites using ChatGPT prompts like scrape website X using Python.
But that doesn’t always work.
After scraping dozens of websites with ChatGPT, I realized that simple prompts rarely work for web scraping.
Using ChatGPT and basic HTML, we can scrape any website.
First things first, use ChatGPT's advanced version (Playground)
ChatGPT Playground's enhanced version is needed to scrape websites quickly. It generates code faster and has less constraints.
Here’s how it looks.
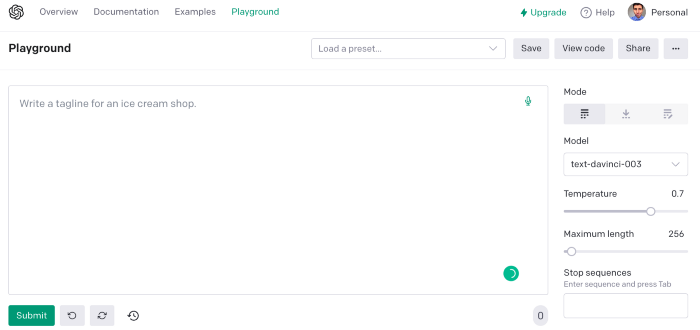
The classic ChatGPT display just allows you to type a prompt. Playground is more customizable and generates code faster than the basic version.
No more delays or restrictions.
In this tutorial, we'll write prompts underneath Playground.
How to Use ChatGPT to Scrape Any Website
To show you how to utilize ChatGPT to scrape any website, we'll use subslikescript, which lists movies.
Later in this post, I'll show you how to scrape Amazon and Twitter, but let's start easy.
If we try a basic prompt like “scrape the movie titles on this website: https://subslikescript.com/movies” it won’t scrape anything. Here’s when we need some HTML knowledge to build the right prompt for ChatGPT.Let's scrape the above movie titles. First, check the webpage. Right-click any element and choose Inspect.
Then see below.
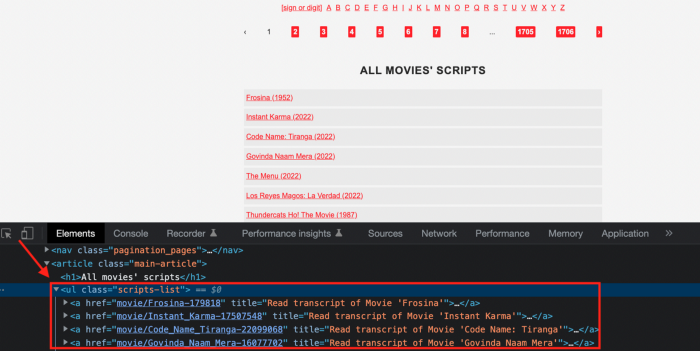
We identify the element to scrape (those in the red box). The data elements are ul, a, and scripts-list.
Here's the prompt for movie titles.
Scrape this website: https://subslikescript.com/movies with Python and Beautiful Soup. Locate the element with tag “ul” and class “scripts-list”. Scrape all the “a” elements inside. Get the text attribute and print it.
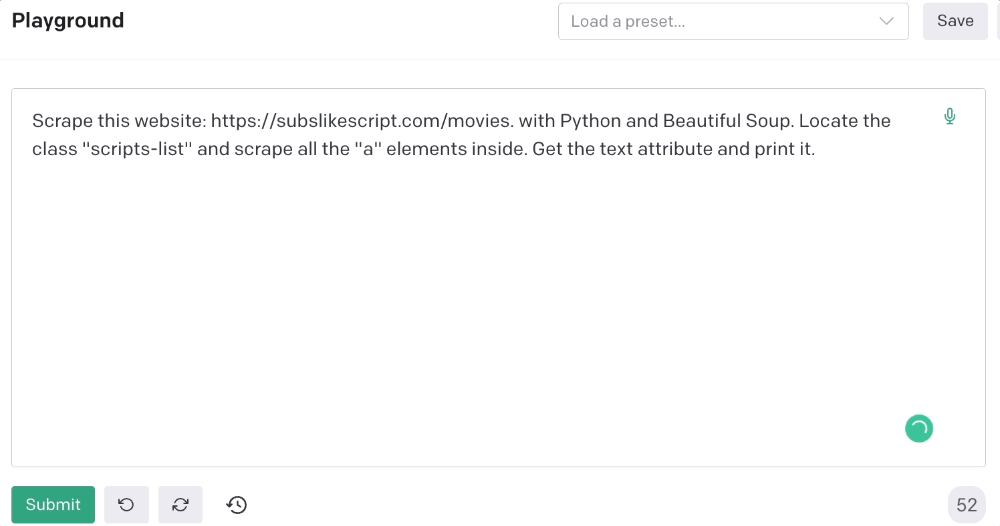
Code generated:
import requests
from bs4 import BeautifulSoup
page = requests.get('https://subslikescript.com/movies/')
soup = BeautifulSoup(page.content, 'html.parser')
scripts_list = soup.find(class_="scripts-list")
all_a_elements = scripts_list.find_all('a')
for element in all_a_elements:
print(element.get_text())It extracts movie titles successfully.
Let's scrape Amazon and Twitter.
ChatGPT's Amazon scraping
Consider scraping Amazon for self-help books. First, copy the Amazon link for self-help books.
Here’s the link I got. Location-dependent connection. Use my link to replicate my results.
Now we'll check book titles. Here's our element.
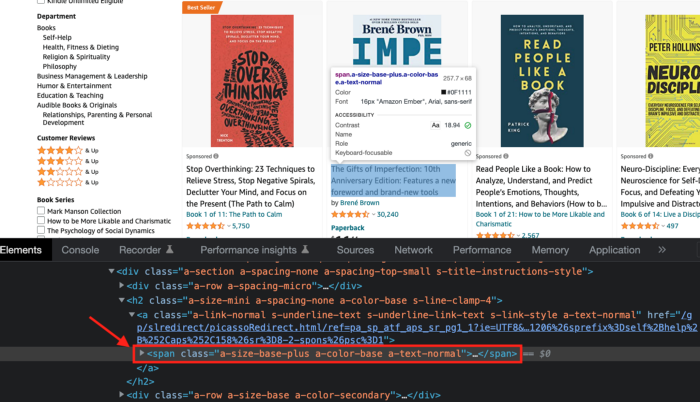
If we want to extract the book titles, we need to use the tag name span, class attribute name and a-size-base-plus a-color-base a-text-normalattribute value.
This time I'll use Selenium. I'll add Selenium-specific commands like wait 5 seconds and generate an XPath.
Scrape this website https://www.amazon.com/s?k=self+help+books&sprefix=self+help+%2Caps%2C158&ref=nb_sb_ss_ts-doa-p_2_10 with Python and Selenium.
Wait 5 seconds and locate all the elements with the following xpath: “span” tag, “class” attribute name, and “a-size-base-plus a-color-base a-text-normal” attribute value. Get the text attribute and print them.
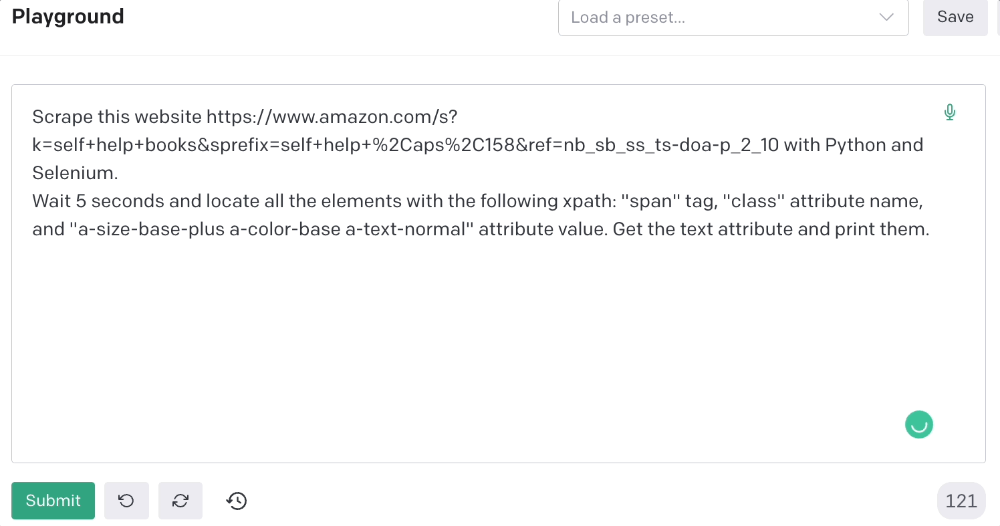
Code generated: (I only had to manually add the path where my chromedriver is located).
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
#initialize webdriver
driver = webdriver.Chrome('<add path of your chromedriver>')
#navigate to the website
driver.get("https://www.amazon.com/s?k=self+help+books&sprefix=self+help+%2Caps%2C158&ref=nb_sb_ss_ts-doa-p_2_10")
#wait 5 seconds to let the page load
sleep(5)
#locate all the elements with the following xpath
elements = driver.find_elements(By.XPATH, '//span[@class="a-size-base-plus a-color-base a-text-normal"]')
#get the text attribute of each element and print it
for element in elements:
print(element.text)
#close the webdriver
driver.close()It pulls Amazon book titles.

Utilizing ChatGPT to scrape Twitter
Say you wish to scrape ChatGPT tweets. Search Twitter for ChatGPT and copy the URL.
Here’s the link I got. We must check every tweet. Here's our element.
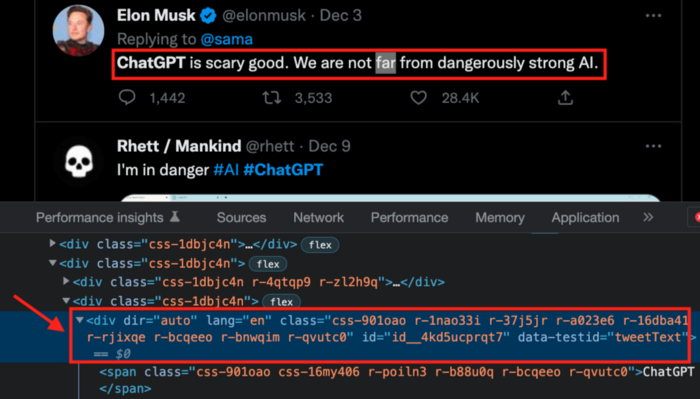
To extract a tweet, use the div tag and lang attribute.
Again, Selenium.
Scrape this website: https://twitter.com/search?q=chatgpt&src=typed_query using Python, Selenium and chromedriver.
Maximize the window, wait 15 seconds and locate all the elements that have the following XPath: “div” tag, attribute name “lang”. Print the text inside these elements.
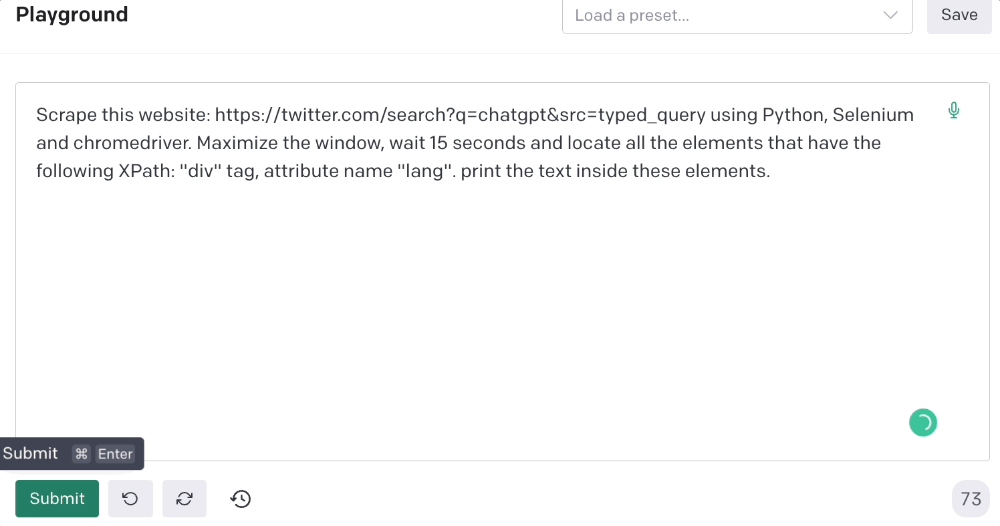
Code generated: (again, I had to add the path where my chromedriver is located)
from selenium import webdriver
import time
driver = webdriver.Chrome("/Users/frankandrade/Downloads/chromedriver")
driver.maximize_window()
driver.get("https://twitter.com/search?q=chatgpt&src=typed_query")
time.sleep(15)
elements = driver.find_elements_by_xpath("//div[@lang]")
for element in elements:
print(element.text)
driver.quit()You'll get the first 2 or 3 tweets from a search. To scrape additional tweets, click X times.
Congratulations! You scraped websites without coding by using ChatGPT.

Stephen Moore
3 years ago
Trading Volume on OpenSea Drops by 99% as the NFT Boom Comes to an End
Wasn't that a get-rich-quick scheme?

OpenSea processed $2.7 billion in NFT transactions in May 2021.
Fueled by a crypto bull run, rumors of unfathomable riches, and FOMO, Bored Apes, Crypto Punks, and other JPEG-format trash projects flew off the virtual shelves, snatched up by retail investors and celebrities alike.
Over a year later, those shelves are overflowing and warehouses are backlogged. Since March, I've been writing less. In May and June, the bubble was close to bursting.
Apparently, the boom has finally peaked.
This bubble has punctured, and deflation has begun. On Aug. 28, OpenSea processed $9.34 million.
From that euphoric high of $2.7 billion, $9.34 million represents a spectacular decline of 99%.
OpenSea contradicts the data. A trading platform spokeswoman stated the comparison is unfair because it compares the site's highest and lowest trading days. They're the perfect two data points to assess the drop. OpenSea chooses to use ETH volume measures, which ignore crypto's shifting price. Since January 2022, monthly ETH volume has dropped 140%, according to Dune.
Unconvincing counterargument.
Further OpenSea indicators point to declining NFT demand:
Since January 2022, daily user visits have decreased by 50%.
Daily transactions have decreased by 50% since the beginning of the year in the same manner.
Off-platform, the floor price of Bored Apes has dropped from 145 ETH to 77 ETH. (At $4,800, a reduction from $700,000 to $370,000). Google search data shows waning popular interest.
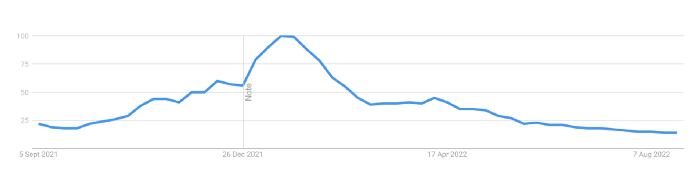
It is a trend that will soon vanish, just like laser eyes.
NFTs haven't moved since the new year. Eminem and Snoop Dogg can utilize their apes in music videos or as 3D visuals to perform at the VMAs, but the reality is that NFTs have lost their public appeal and the market is trying to regain its footing.
They've lost popularity because?
Breaking records. The technology still lacks genuine use cases a year and a half after being popular.
They're pricey prestige symbols that have made a few people rich through cunning timing or less-than-savory scams or rug pulling. Over $10.5 billion has been taken through frauds, most of which are NFT enterprises promising to be the next Bored Apes, according to Web3 is going wonderfully. As the market falls, many ordinary investors realize they purchased into a self-fulfilling ecosystem that's halted. Many NFTs are sold between owner-held accounts to boost their price, data suggests. Most projects rely on social media excitement to debut with a high price before the first owners sell and chuckle to the bank. When they don't, the initiative fails, leaving investors high and dry.
NFTs are fading like laser eyes. Most people pushing the technology don't believe in it or the future it may bring. No, they just need a Kool-Aid-drunk buyer.
Everybody wins. When your JPEGs are worth 99% less than when you bought them, you've lost.
When demand reaches zero, many will lose.