


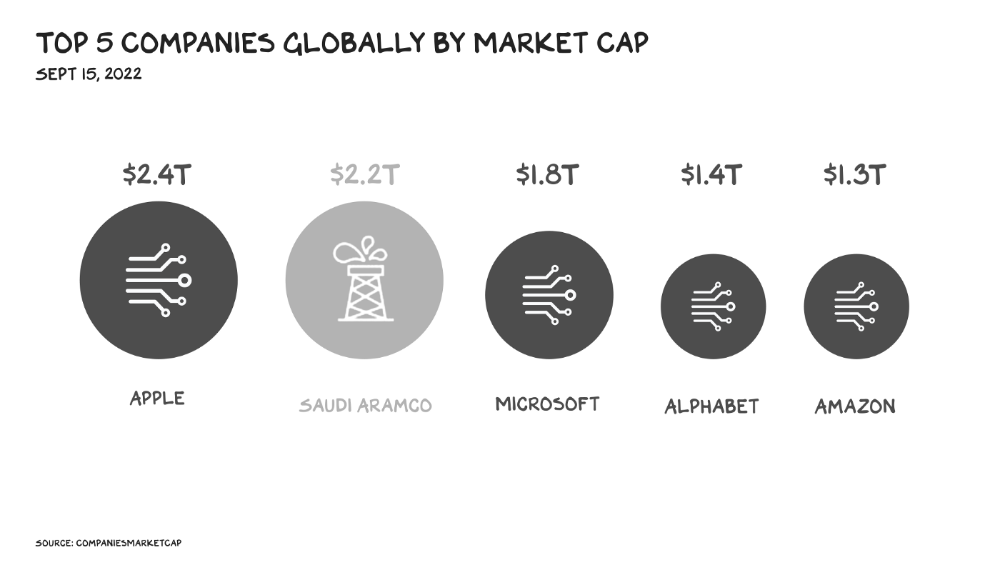
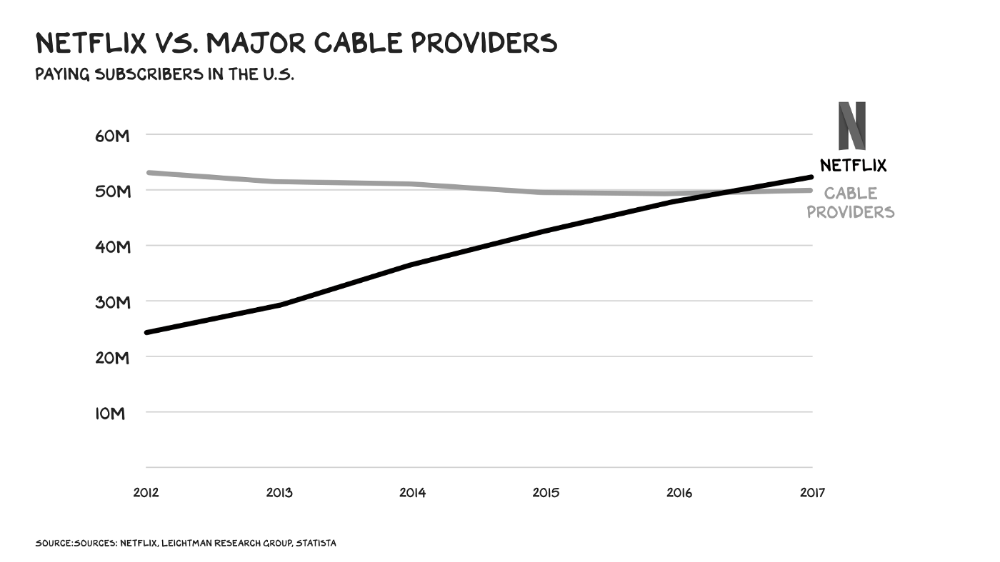
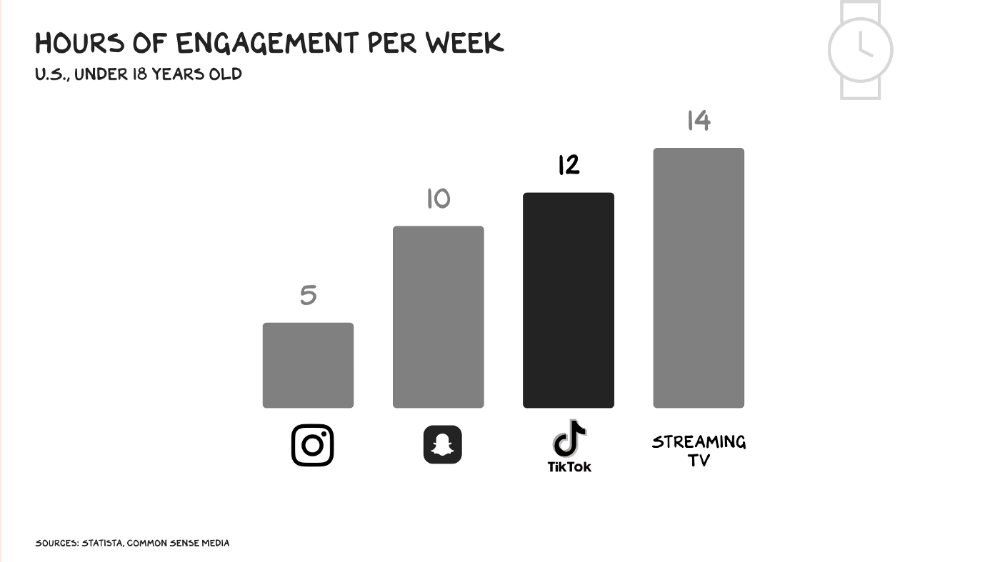
More on Society & Culture

Kyle Planck
2 months ago
The chronicles of monkeypox.
or, how I spread monkeypox and got it myself.
This story contains nsfw (not safe for wife) stuff and shouldn't be read if you're under 18 or think I'm a newborn angel. After the opening, it's broken into three sections: a chronological explanation of my disease course, my ideas, and what I plan to do next.
Your journey awaits.
As early as mid-may, I was waltzing around the lab talking about monkeypox, a rare tropical disease with an inaccurate name. Monkeys are not its primary animal reservoir. It caused an outbreak among men who have sex with men across Europe, with unprecedented levels of person-to-person transmission. European health authorities speculated that the virus spread at raves and parties and was easily transferred through intimate, mainly sexual, contact. I had already read the nejm article about the first confirmed monkeypox patient in the u.s. and shared the photos on social media so people knew what to look for. The cdc information page only included 4 photographs of monkeypox lesions that looked like they were captured on a motorola razr.
I warned my ex-boyfriend about monkeypox. Monkeypox? responded.
Mom, I'm afraid about monkeypox. What's monkeypox?
My therapist is scared about monkeypox. What's monkeypox?
Was I alone? A few science gays on Twitter didn't make me feel overreacting.
This information got my gay head turning. The incubation period for the sickness is weeks. Many of my social media contacts are traveling to Europe this summer. What is pride? Travel, parties, and sex. Many people may become infected before attending these activities. Monkeypox will affect the lgbtq+ community.
Being right always stinks. My young scientist brain was right, though. Someone who saw this coming is one of the early victims. I'll talk about my feelings publicly, and trust me, I have many concerning what's occurring.

Part 1 is the specifics.
Wednesday nights are never smart but always entertaining. I didn't wake up until noon on june 23 and saw gay twitter blazing. Without warning, the nyc department of health announced a pop-up monkeypox immunization station in chelsea. Some days would be 11am-7pm. Walk-ins were welcome, however appointments were preferred. I tried to arrange an appointment after rubbing my eyes, but they were all taken. I got out of bed, washed my face, brushed my teeth, and put on short shorts because I wanted to get a walk-in dose and show off my legs. I got a 20-oz. cold brew on the way to the train and texted a chelsea-based acquaintance for help.
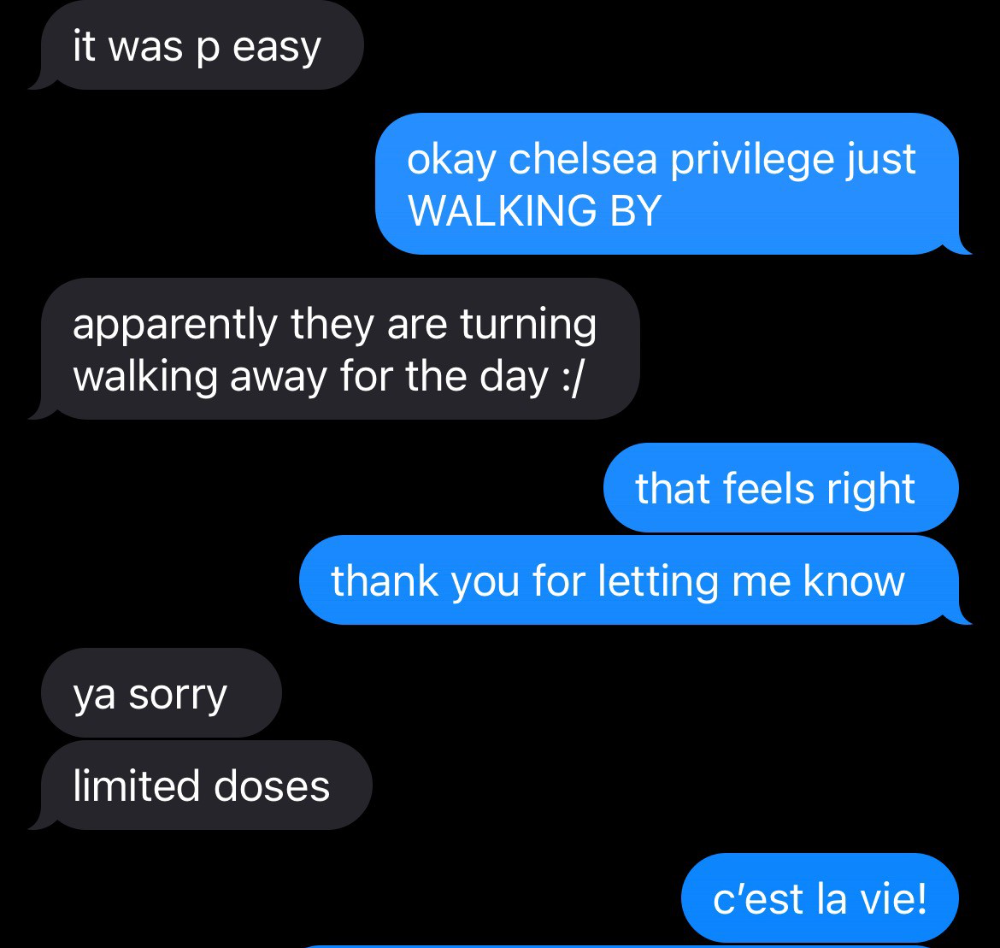
Clinic closed at 2pm. No more doses. Hundreds queued up. The government initially gave them only 1,000 dosages. For a city with 500,000 LGBT people, c'mon. What more could I do? I was upset by how things were handled. The evidence speaks for itself.
I decided to seek an appointment when additional doses were available and continued my weekend. I was celebrating nyc pride with pals. Fun! sex! *
On tuesday after that, I felt a little burn. This wasn't surprising because I'd been sexually active throughout the weekend, so I got a sti panel the next day. I expected to get results in a few days, take antibiotics, and move on.
Emerging germs had other intentions. Wednesday night, I felt sore, and thursday morning, I had a blazing temperature and had sweat through my bedding. I had fever, chills, and body-wide aches and pains for three days. I reached 102 degrees. I believed I had covid over pride weekend, but I tested negative for three days straight.
STDs don't induce fevers or other systemic symptoms. If lymphogranuloma venereum advances, it can cause flu-like symptoms and swollen lymph nodes. I was suspicious and desperate for answers, so I researched monkeypox on the cdc website (for healthcare professionals). Much of what I saw on screen about monkeypox prodrome matched my symptoms. Multiple-day fever, headache, muscle aches, chills, tiredness, enlarged lymph nodes. Pox were lacking.
I told my doctor my concerns pre-medically. I'm occasionally annoying.
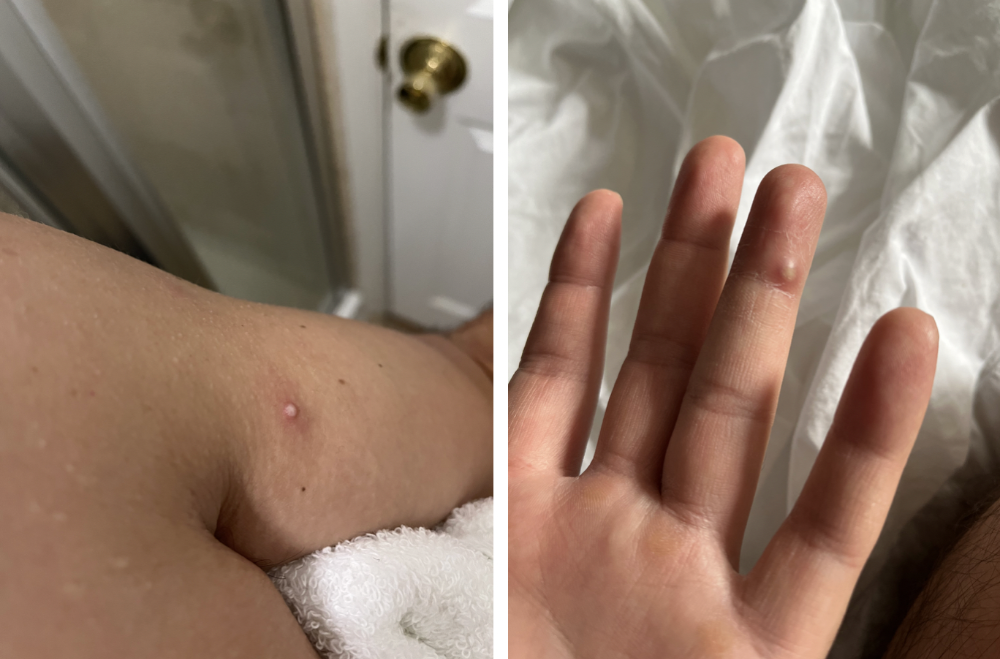
On saturday night, my fever broke and I felt better. Still burning, I was optimistic till sunday, when I woke up with five red splotches on my arms and fingertips.
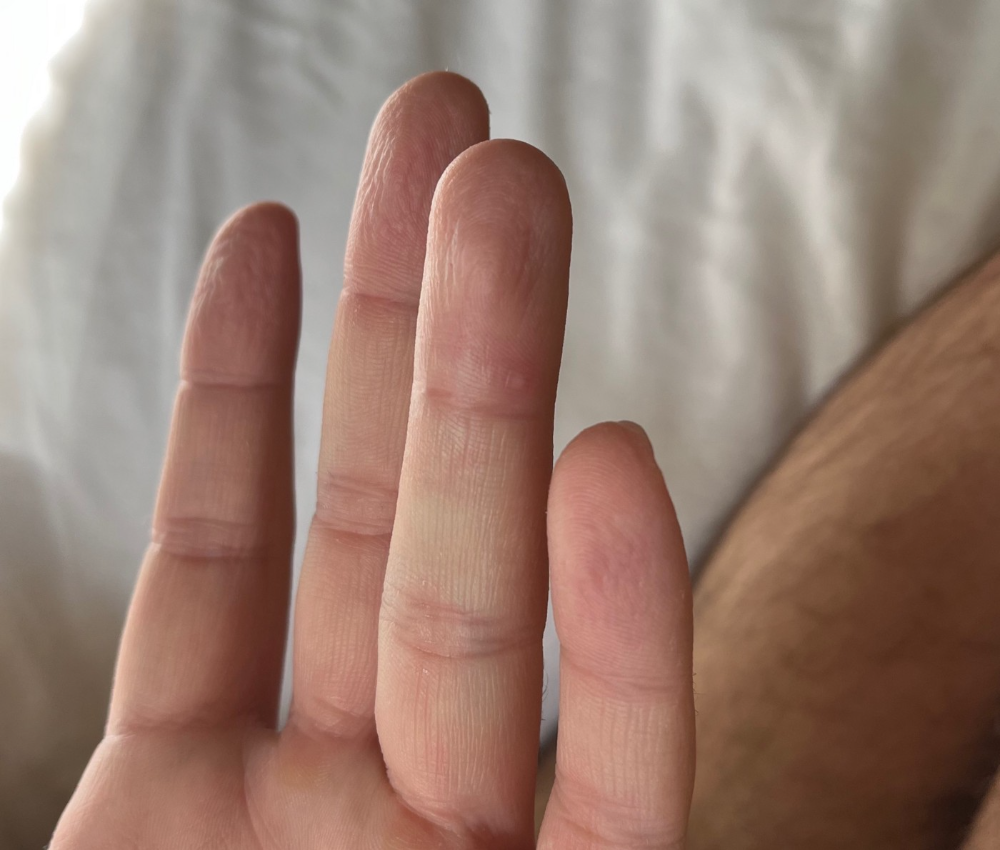
As spots formed, burning became pain. I observed as spots developed on my body throughout the day. I had more than a dozen by the end of the day, and the early spots were pustular. I had monkeypox, as feared.

Fourth of July weekend limited my options. I'm well-connected in my school's infectious disease academic community, so I texted a coworker for advice. He agreed it was likely monkeypox and scheduled me for testing on tuesday.
nyc health could only perform 10 monkeypox tests every day. Before doctors could take swabs and send them in, each test had to be approved by the department. Some commercial labs can now perform monkeypox testing, but the backlog is huge. I still don't have a positive orthopoxvirus test five days after my test. *My 12-day-old case may not be included in the official monkeypox tally. This outbreak is far wider than we first thought, therefore I'm attempting to spread the information and help contain it.
*Update, 7/11: I have orthopoxvirus.
I spent all day in the bathtub because of the agony. Warm lavender epsom salts helped me feel better. I can't stand lavender anymore. I brought my laptop into the bathroom and viewed everything everywhere at once (2022). If my ex and I hadn't recently broken up, I wouldn't have monkeypox. All of these things made me cry, and I sat in the bathtub on the 4th of July sobbing. I thought, Is this it? I felt like Bridesmaids' Kristen Wiig (2011). I'm a flop. From here, things can only improve.
Later that night, I wore a mask and went to my roof to see the fireworks. Even though I don't like fireworks, there was something wonderful about them this year: the colors, how they illuminated the black surfaces around me, and their transient beauty. Joyful moments rarely linger long in our life. We must enjoy them now.

Several roofs away, my neighbors gathered. Happy 4th! I heard a woman yell. Why is this godforsaken country so happy? Instead of being rude, I replied. I didn't tell them I had monkeypox. I thought that would kill the mood.
By the time I went to the hospital the next day to get my lesions swabbed, wearing long sleeves, pants, and a mask, they looked like this:
I had 30 lesions on my arms, hands, stomach, back, legs, buttcheeks, face, scalp, and right eyebrow. I had some in my mouth, gums, and throat. Current medical thought is that lesions on mucous membranes cause discomfort in sensitive places. Internal lesions are a new feature of this outbreak of monkeypox. Despite being unattractive, the other sores weren't unpleasant or bothersome.
I had a bacterial sti with the pox. Who knows if that would've created symptoms (often it doesn't), but different infections can happen at once. My care team remembered that having a sti doesn't exclude out monkeypox. doxycycline rocks!
The coworker who introduced me to testing also offered me his home. We share a restroom, and monkeypox can be spread through surfaces. (Being a dna virus gives it environmental hardiness that rna viruses like sars-cov-2 lack.) I disinfected our bathroom after every usage, but I was apprehensive. My friend's place has a guest room and second bathroom, so no cross-contamination. It was the ideal monkeypox isolation environment, so I accepted his offer and am writing this piece there. I don't know what I would have done without his hospitality and attention.
The next day, I started tecovirimat, or tpoxx, for 14 days. Smallpox has been eradicated worldwide since the 1980s but remains a bioterrorism concern. Tecovirimat has a unique, orthopoxvirus-specific method of action, which reduces side effects to headache and nausea. It hasn't been used in many people, therefore the cdc is encouraging patients who take it for monkeypox to track their disease and symptoms.
Tpoxx's oral absorption requires a fatty meal. The hospital ordered me to take the medication after a 600-calorie, 25-gram-fat meal every 12 hours. The coordinator joked, "Don't diet for the next two weeks." I wanted to get peanut butter delivered, but jif is recalling their supply due to salmonella. Please give pathogens a break. I got almond butter.
Tpoxx study enrollment was documented. After signing consent documents, my lesions were photographed and measured during a complete physical exam. I got bloodwork to assess my health. My medication delivery was precise; every step must be accounted for. I got a two-week supply and started taking it that night. I rewarded myself with McDonald's. I'd been hungry for a week. I was also prescribed ketorolac (aka toradol), a stronger ibuprofen, for my discomfort.
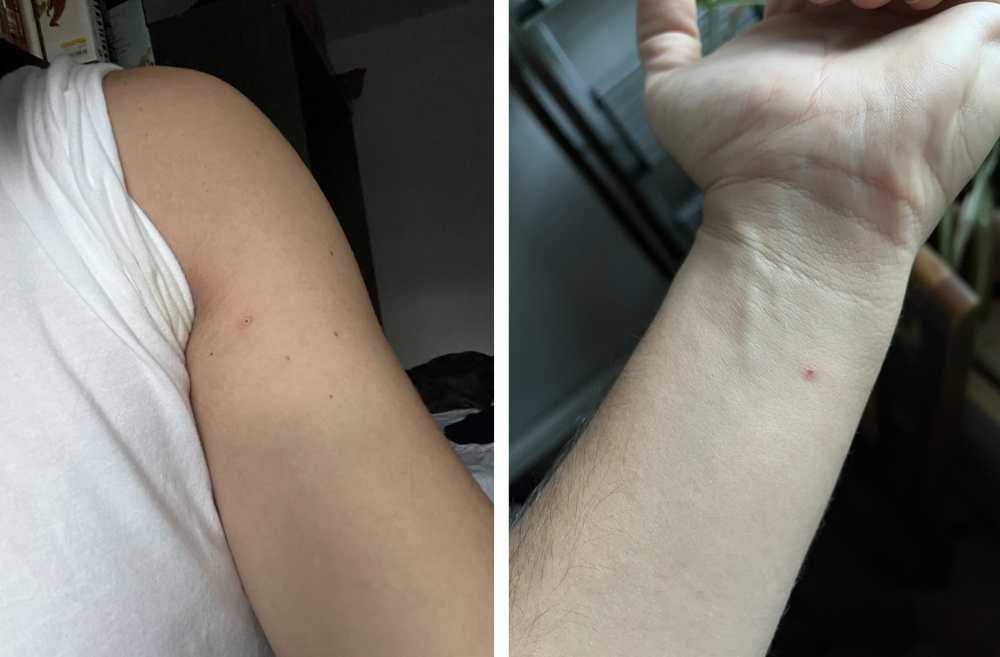
I thought tpoxx was a wonder medicine by day two of treatment. Early lesions looked like this.
however, They vanished. The three largest lesions on my back flattened and practically disappeared into my skin. Some pustular lesions were diminishing. Tpoxx+toradol has helped me sleep, focus, and feel human again. I'm down to twice-daily baths and feeling hungrier than ever in this illness. On day five of tpoxx, some of the lesions look like this:
I have a ways to go. We must believe I'll be contagious until the last of my patches scabs over, falls off, and sprouts new skin. There's no way to tell. After a week and a half of tremendous pain and psychological stress, any news is good news. I'm grateful for my slow but steady development.
Part 2 of the rant.
Being close to yet not in the medical world is interesting. It lets me know a lot about it without being persuaded by my involvement. Doctors identify and treat patients using a tool called differential diagnosis.
A doctor interviews a patient to learn about them and their symptoms. More is better. Doctors may ask, "Have you traveled recently?" sex life? Have pets? preferred streaming service? (No, really. (Hbomax is right.) After the inquisition, the doctor will complete a body exam ranging from looking in your eyes, ears, and throat to a thorough physical.
After collecting data, the doctor makes a mental (or physical) inventory of all the conceivable illnesses that could cause or explain the patient's symptoms. Differential diagnosis list. After establishing the differential, the clinician can eliminate options. The doctor will usually conduct nucleic acid tests on swab samples or bloodwork to learn more. This helps eliminate conditions from the differential or boosts a condition's likelihood. In an ideal circumstance, the doctor can eliminate all but one reason of your symptoms, leaving your formal diagnosis. Once diagnosed, treatment can begin. yay! Love medicine.
My symptoms two weeks ago did not suggest monkeypox. Fever, pains, weariness, and swollen lymph nodes are caused by several things. My scandalous symptoms weren't linked to common ones. My instance shows the importance of diversity and representation in healthcare. My doctor isn't gay, but he provides culturally sensitive care. I'd heard about monkeypox as a gay man in New York. I was hyper-aware of it and had heard of friends of friends who had contracted it the week before, even though the official case count in the US was 40. My physicians weren't concerned, but I was. How would it appear on his mental differential if it wasn't on his radar? Mental differential rhymes! I'll trademark it to prevent theft. differential!
I was in a rare position to recognize my condition and advocate for myself. I study infections. I'd spent months researching monkeypox. I work at a university where I rub shoulders with some of the country's greatest doctors. I'm a gay dude who follows nyc queer social networks online. All of these variables positioned me to think, "Maybe this is monkeypox," and to explain why.
This outbreak is another example of privilege at work. The brokenness of our healthcare system is once again exposed by the inequities produced by the vaccination rollout and the existence of people like myself who can pull strings owing to their line of work. I can't cure this situation on my own, but I can be a strong voice demanding the government do a better job addressing the outbreak and giving resources and advice to everyone I can.
lgbtqia+ community members' support has always impressed me in new york. The queer community has watched out for me and supported me in ways I never dreamed were possible.
Queer individuals are there for each other when societal structures fail. People went to the internet on the first day of the vaccine rollout to share appointment information and the vaccine clinic's message. Twitter timelines were more effective than marketing campaigns. Contrary to widespread anti-vaccine sentiment, the LGBT community was eager to protect themselves. Smallpox vaccination? sure. gimme. whether I'm safe. I credit the community's sex positivity. Many people are used to talking about STDs, so there's a reduced barrier to saying, "I think I have something, you should be on the watch too," and taking steps to protect our health.
Once I got monkeypox, I posted on Twitter and Instagram. Besides fueling my main character syndrome, I felt like I wasn't alone. My dc-based friend had monkeypox within hours. He told me about his experience and gave me ideas for managing the discomfort. I can't imagine life without him.
My buddy and colleague organized my medical care and let me remain in his home. His and his husband's friendliness and attention made a world of difference in my recovery. All of my friends and family who helped me, whether by venmo, doordash, or moral support, made me feel cared about. I don't deserve the amazing people in my life.
Finally, I think of everyone who commented on my social media posts regarding my trip. Friends from all sectors of my life and all sexualities have written me well wishes and complimented me for my vulnerability, but I feel the most gravitas from fellow lgbtq+ persons. They're learning to spot. They're learning where to go ill. They're learning self-advocacy. I'm another link in our network of caretaking. I've been cared for, therefore I want to do the same. Community and knowledge are powerful.
You're probably wondering where the diatribe is. You may believe he's gushing about his loved ones, and you'd be right. I say that just because the queer community can take care of itself doesn't mean we should.
Even when caused by the same pathogen, comparing health crises is risky. Aids is unlike covid-19 or monkeypox, yet all were caused by poorly understood viruses. The lgbtq+ community has a history of self-medicating. Queer people (and their supporters) have led the charge to protect themselves throughout history when the government refused. Surreal to experience this in real time.
First, vaccination access is a government failure. The strategic national stockpile contains tens of thousands of doses of jynneos, the newest fda-approved smallpox vaccine, and millions of doses of acam2000, an older vaccine for immunocompetent populations. Despite being a monkeypox hotspot and international crossroads, new york has only received 7,000 doses of the jynneos vaccine. Vaccine appointments are booked within minutes. It's showing Hunger Games, which bothers me.
Second, I think the government failed to recognize the severity of the european monkeypox outbreak. We saw abroad reports in may, but the first vaccines weren't available until june. Why was I a 26-year-old pharmacology grad student, able to see a monkeypox problem in europe but not the u.s. public health agency? Or was there too much bureaucracy and politicking, delaying action?
Lack of testing infrastructure for a known virus with vaccinations and therapies is appalling. More testing would have helped understand the problem's breadth. Many homosexual guys, including myself, didn't behave like monkeypox was a significant threat because there were only a dozen instances across the country. Our underestimating of the issue, spurred by a story of few infections, was huge.
Public health officials' response to infectious diseases frustrates me. A wait-and-see approach to infectious diseases is unsatisfactory. Before a sick person is recognized, they've exposed and maybe contaminated numerous others. Vaccinating susceptible populations before a disease becomes entrenched prevents disease. CDC might operate this way. When it was easier, they didn't control or prevent monkeypox. We'll learn when. Sometimes I fear never. Emerging viral infections are a menace in the era of climate change and globalization, and I fear our government will repeat the same mistakes. I don't work at the cdc, thus I have no idea what they do. As a scientist, a homosexual guy, and a citizen of this country, I feel confident declaring that the cdc has not done enough about monkeypox. Will they do enough about monkeypox? The strategic national stockpile can respond to a bioterrorism disaster in 12 hours. I'm skeptical following this outbreak.
It's simple to criticize the cdc, but they're not to blame. Underfunding public health services, especially the cdc, is another way our government fails to safeguard its citizens. I may gripe about the vaccination rollout all I want, but local health departments are doing their best with limited resources. They may not have enough workers to keep up with demand and run a contact-tracing program. Since my orthopoxvirus test is still negative, the doh hasn't asked about my close contacts. By then, my illness will be two weeks old, too long to do anything productive. Not their fault. They're functioning in a broken system that's underfunded for the work it does.
*Update, 7/11: I have orthopoxvirus.
Monkeypox is slow, so i've had time to contemplate. Now that I'm better, I'm angry. furious and sad I want to help. I wish to spare others my pain. This was preventable and solvable, I hope. HOW?
Third, the duty.
Family, especially selected family, helps each other. So many people have helped me throughout this difficult time. How can I give back? I have ideas.
1. Education. I've already started doing this by writing incredibly detailed posts on Instagram about my physical sickness and my thoughts on the entire scandal. via tweets. by producing this essay. I'll keep doing it even if people start to resent me! It's crucial! On my Instagram profile (@kyleplanckton), you may discover a story highlight with links to all of my bizarre yet educational posts.

2. Resources. I've forwarded the contact information for my institution's infectious diseases clinic to several folks who will hopefully be able to get tpoxx under the expanded use policy. Through my social networks, I've learned of similar institutions. I've also shared crowdsourced resources about symptom relief and vaccine appointment availability on social media. DM me or see my Instagram highlight for more.
3. Community action. During my illness, my friends' willingness to aid me has meant the most. It was nice to know I had folks on my side. One of my pals (thanks, kenny) snagged me a mcgriddle this morning when seamless canceled my order. This scenario has me thinking about methods to help people with monkeypox isolation. A two-week isolation period is financially damaging for many hourly workers. Certain governments required paid sick leave for covid-19 to allow employees to recover and prevent spread. No comparable program exists for monkeypox, and none seems to be planned shortly.
I want to aid monkeypox patients in severe financial conditions. I'm willing to pick up and bring groceries or fund meals/expenses for sick neighbors. I've seen several GoFundMe accounts, but I wish there was a centralized mechanism to link those in need with those who can help. Please contact me if you have expertise with mutual aid organizations. I hope we can start this shortly.
4. lobbying. Personal narratives are powerful. My narrative is only one, but I think it's compelling. Over the next day or so, i'll write to local, state, and federal officials about monkeypox. I wanted a vaccine but couldn't acquire one, and I feel tpoxx helped my disease. As a pharmacologist-in-training, I believe collecting data on a novel medicine is important, and there are ethical problems when making a drug with limited patient data broadly available. Many folks I know can't receive tpoxx due of red tape and a lack of contacts. People shouldn't have to go to an ivy league hospital to obtain the greatest care. Based on my experience and other people's tales, I believe tpoxx can drastically lessen monkeypox patients' pain and potentially curb transmission chains if administered early enough. This outbreak is manageable. It's not too late if we use all the instruments we have (diagnostic, vaccine, treatment).
*UPDATE 7/15: I submitted the following letter to Chuck Schumer and Kirsten Gillibrand. I've addressed identical letters to local, state, and federal officials, including the CDC and HHS.



I hope to join RESPND-MI, an LGBTQ+ community-led assessment of monkeypox symptoms and networks in NYC. Visit their website to learn more and give to this community-based charity.
How I got monkeypox is a mystery. I received it through a pride physical interaction, but i'm not sure which one. This outbreak will expand unless leaders act quickly. Until then, I'll keep educating and connecting people to care in my neighborhood.
Despite my misgivings, I see some optimism. Health department social media efforts are underway. During the outbreak, the CDC provided nonjudgmental suggestions for safer social and sexual activity. There's additional information regarding the disease course online, including how to request tpoxx for sufferers. These materials can help people advocate for themselves if they're sick. Importantly, homosexual guys are listening when they discuss about monkeypox online and irl. Learners They're serious.
The government has a terrible track record with lgtbq+ health issues, and they're not off to a good start this time. I hope this time will be better. If I can aid even one individual, I'll do so.
Thanks for reading, supporting me, and spreading awareness about the 2022 monkeypox outbreak. My dms are accessible if you want info, resources, queries, or to chat.
y'all well
kyle

Katharine Valentino
4 months ago
A Gun-toting Teacher Is Like a Cook With Rat Poison
Pink or blue AR-15s?
A teacher teaches; a gun kills. Killing isn't teaching. Killing is opposite of teaching.
Without 27 school shootings this year, we wouldn't be talking about arming teachers. Gun makers, distributors, and the NRA cause most school shootings. Gun makers, distributors, and the NRA wouldn't be huge business if weapons weren't profitable.
Guns, ammo, body armor, holsters, concealed carriers, bore sights, cleaner kits, spare magazines and speed loaders, gun safes, and ear protection are sold. And more guns.
And lots more profit.
Guns aren't bread. You eat a loaf of bread in a week or so and then must buy more. Bread makers will make money. Winchester 94.30–30 1899 Lever Action Rifle from 1894 still kills. (For safety, I won't link to the ad.) Gun makers don't object if you collect antique weapons, but they need you to buy the latest, in-style killing machine. The youngster who killed 19 students and 2 teachers at Robb Elementary School in Uvalde, Texas, used an AR-15. Better yet, two.
Salvador Ramos, the Robb Elementary shooter, is a "killing influencer" He pushes consumers to buy items, which benefits manufacturers and distributors. Like every previous AR-15 influencer, he profits Colt, the rifle's manufacturer, and 52,779 gun dealers in the U.S. Ramos and other AR-15 influences make us fear for our safety and our children's. Fearing for our safety, we acquire 20 million firearms a year and live in a gun culture.
So now at school, we want to arm teachers.
Consider. Which of your teachers would you have preferred in body armor with a gun drawn?
Miss Summers? Remember her bringing daisies from her yard to second grade? She handed each student a beautiful flower. Miss Summers loved everyone, even those with AR-15s. She can't shoot.
Frasier? Mr. Frasier turned a youngster over down to explain "invert." Mr. Frasier's hands shook when he wasn't flipping fifth-graders and fractions. He may have shot wrong.
Mrs. Barkley barked in high school English class when anyone started an essay with "But." Mrs. Barkley dubbed Abie a "Jewboy" and gave him terrible grades. Arming Miss Barkley is like poisoning the chef.
Think back. Do you remember a teacher with a gun? No. Arming teachers so the gun industry can make more money is the craziest idea ever.
Or maybe you agree with Ted Cruz, the gun lobby-bought senator, that more guns reduce gun violence. After the next school shooting, you'll undoubtedly talk about arming teachers and pupils. Colt will likely develop a backpack-sized, lighter version of its popular killing machine in pink and blue for kids and boys. The MAR-15? (M for mini).
This post is a summary. Read the full one here.

Jack Shepherd
2 months ago
A Dog's Guide to Every Type of Zoom Call Participant
Are you one of these Zoom dogs?
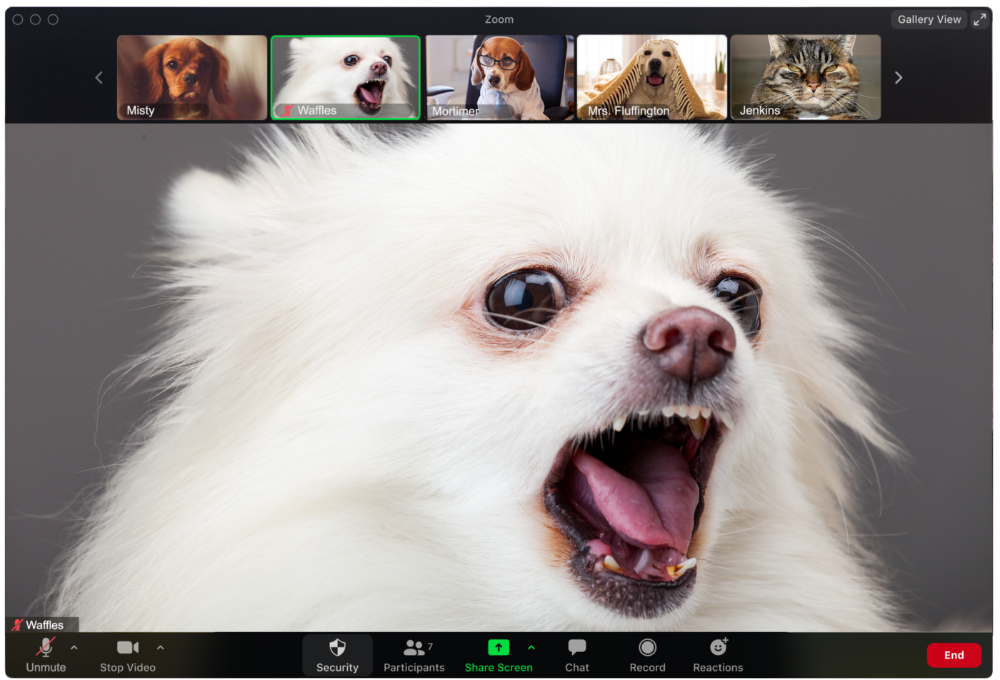
The Person Who Is Apparently Always on Mute
Waffles thinks he can overpower the mute button by shouting loudly.
The person who believed their camera to be off
Barkley's used to remote work, but he hasn't mastered the "Stop Video" button. Everyone is affected.
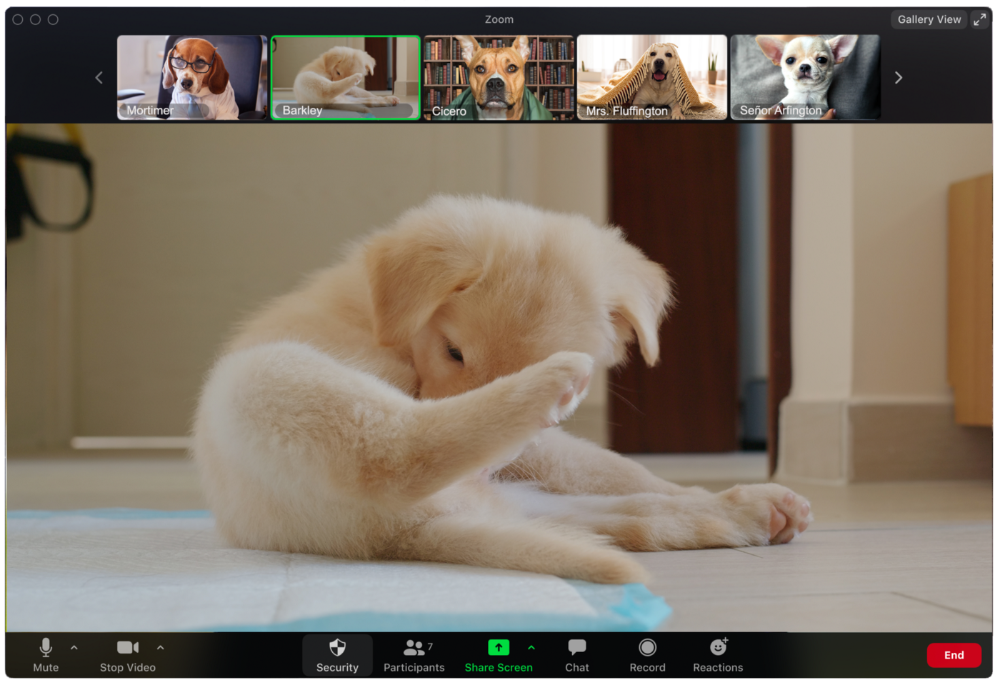
Who is driving for some reason, exactly?
Why is Pumpkin always late? Who knows? Shouldn't she be driving? If you could hear her over the freeway, she'd answer these questions.
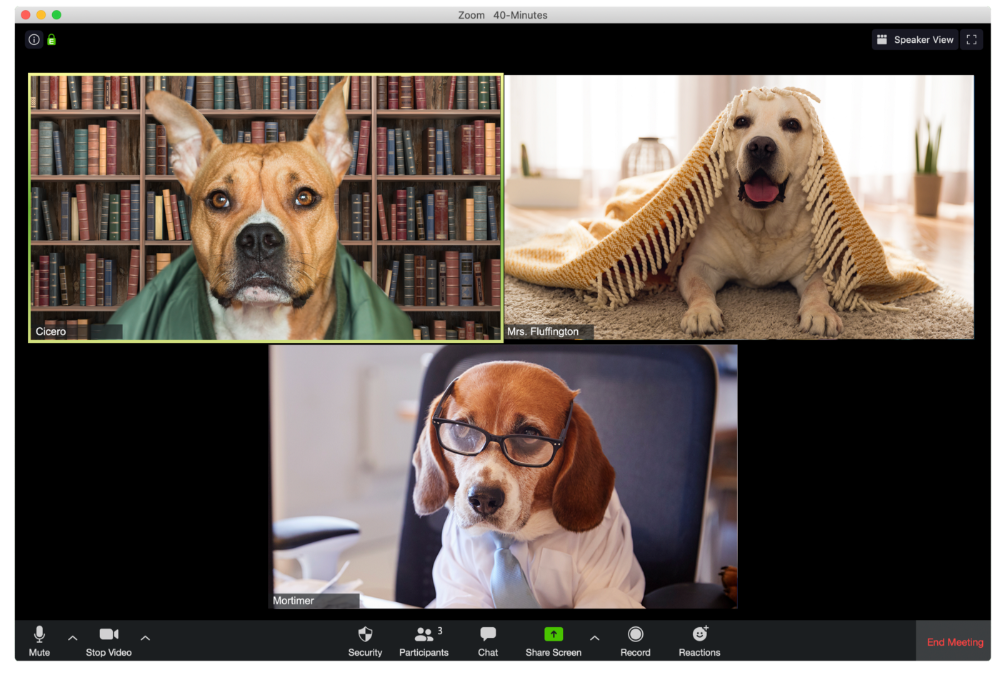
The Person With the Amazing Bookcase
Cicero likes to use SAT-words like "leverage" and "robust" in Zoom sessions, presumably from all the books he wants you to see behind him.
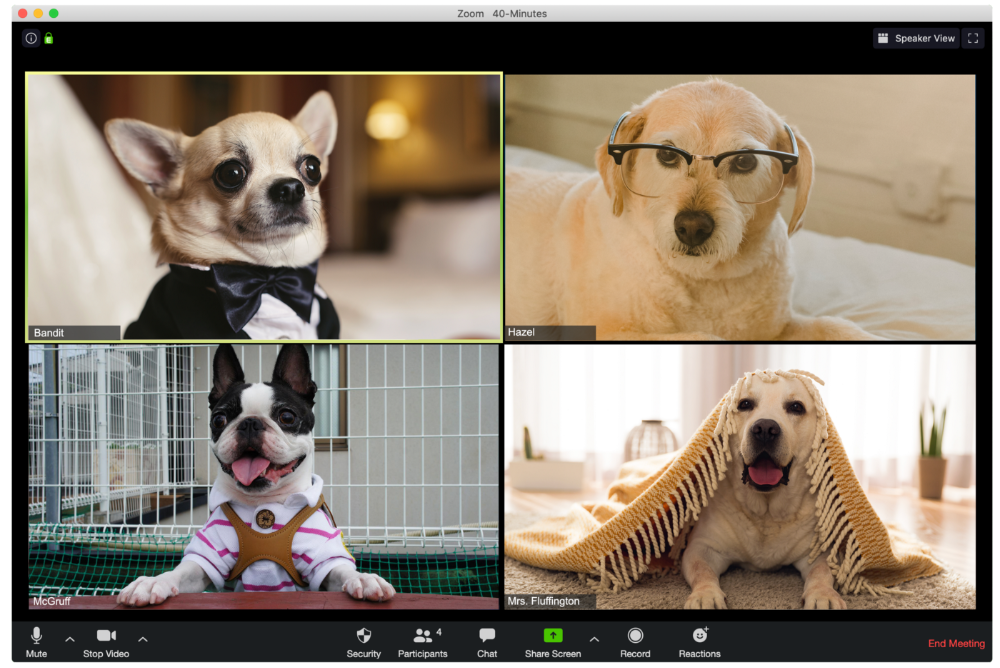
The Individual Who Is Unnecessarily Dressed
We hope Bandit is going somewhere beautiful after this meeting, or else he neglected the quarterly earnings report and is overcompensating to distract us.
The person who works through lunch in between zoom calls
Barksworth has back-to-back meetings all day, so you can watch her eat while she talks.
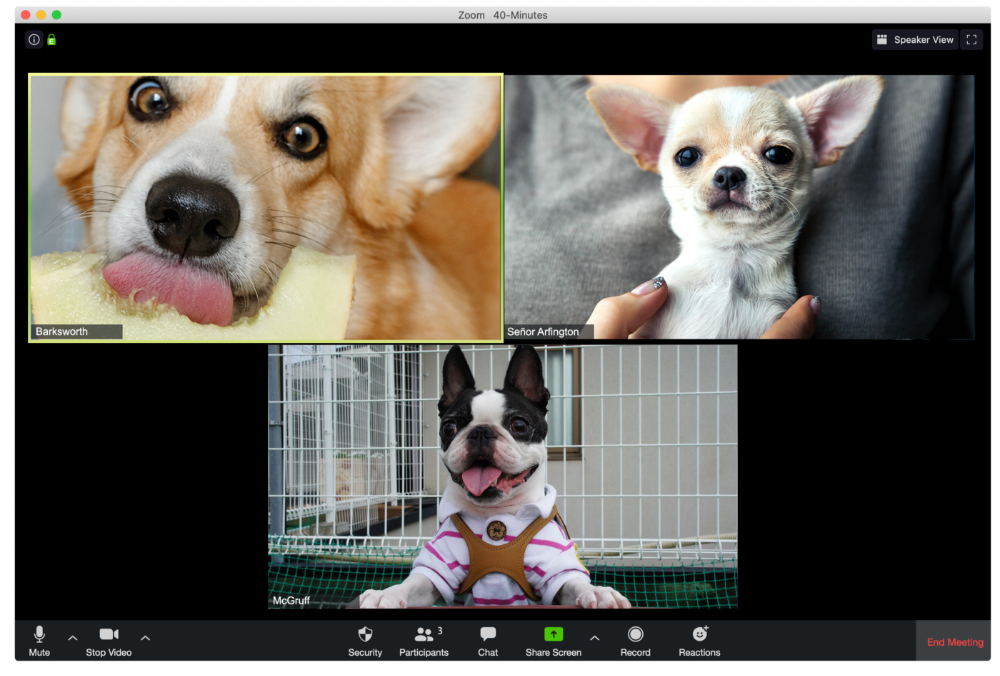
The Person Who Is A Little Too Comfy
Hercules thinks Zoom meetings happen between sleeps. He'd appreciate everyone speaking more quietly.
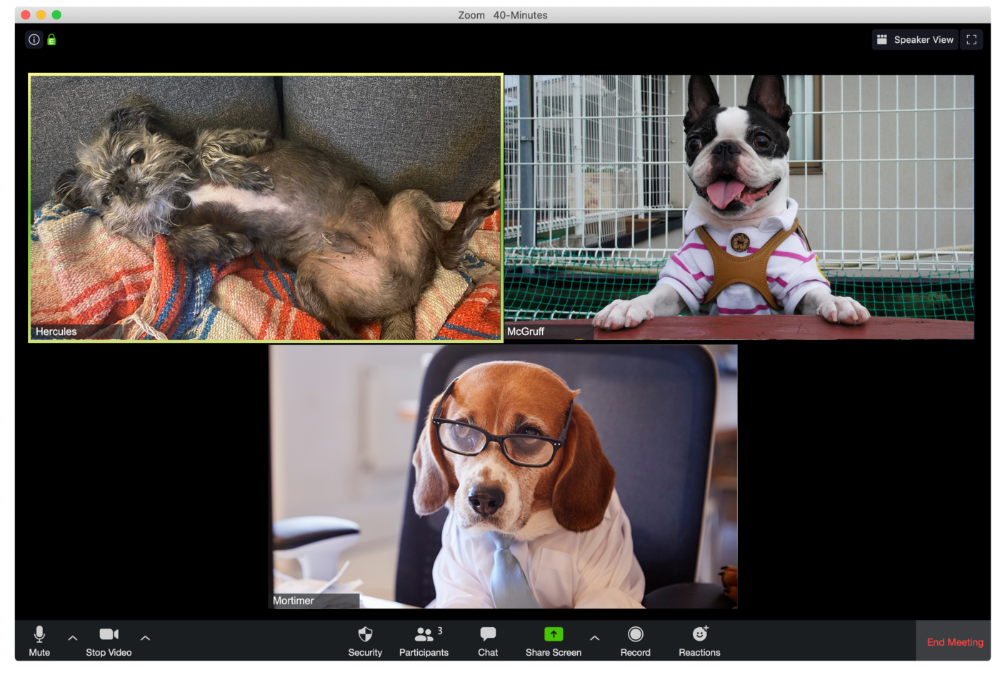
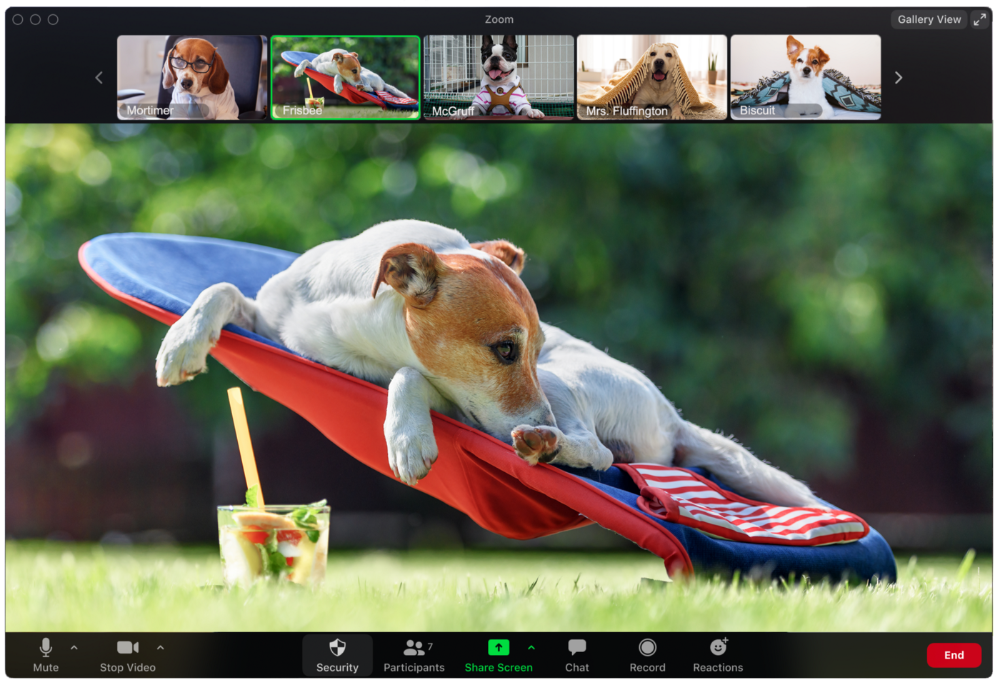
The Person Who Answered the Phone Outside
Frisbee has a gorgeous backyard and lives in a place with great weather year-round, and she wants you to think about that during the daily team huddle.
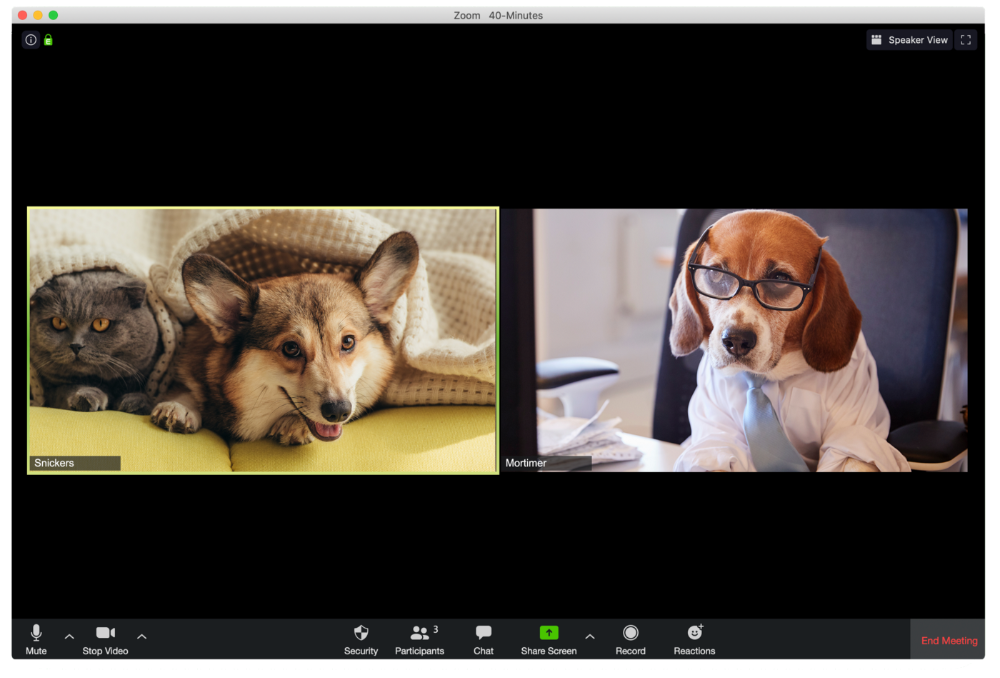
Who Wants You to Pay Attention to Their Pet
Snickers hasn't listened to you in 20 minutes unless you tell her how cute her kitten is.
One who is, for some reason, positioned incorrectly on the screen
Nelson's meetings consist primarily of attempting to figure out how he positioned his laptop so absurdly.

The person who says too many goodbyes
Zeus waves farewell like it's your first day of school while everyone else searches for the "Leave Meeting" button. It's nice.
He who has a poor internet connection
Ziggy's connectivity problems continue... She gives a long speech as everyone waits awkwardly to inform her they missed it.
The Clearly Multitasking Person
Tinkerbell can play fetch during the monthly staff meeting if she works from home, but that's not a good idea.
The Person Using Zoom as a Makeup and Hair Mirror
If Gail and Bob knew Zoom had a "hide self view" option, they'd be distraught.

The person who feels at ease with simply leaving
Rusty bails when a Zoom conference is over. Rusty's concept is decent.
You might also like

nft now
5 months ago
A Guide to VeeFriends and Series 2
VeeFriends is one of the most popular and unique NFT collections. VeeFriends launched around the same time as other PFP NFTs like Bored Ape Yacht Club.
Vaynerchuk (GaryVee) took a unique approach to his large-scale project, which has influenced the NFT ecosystem. GaryVee's VeeFriends is one of the most successful NFT membership use-cases, allowing him to build a community around his creative and business passions.
What is VeeFriends?
GaryVee's NFT collection, VeeFriends, was released on May 11, 2021. VeeFriends [Mini Drops], Book Games, and a forthcoming large-scale "Series 2" collection all stem from the initial drop of 10,255 tokens.
In "Series 1," there are G.O.O. tokens (Gary Originally Owned). GaryVee reserved 1,242 NFTs (over 12% of the supply) for his own collection, so only 9,013 were available at the Series 1 launch.
Each Series 1 token represents one of 268 human traits hand-drawn by Vaynerchuk. Gary Vee's NFTs offer owners incentives.
Who made VeeFriends?
Gary Vaynerchuk, AKA GaryVee, is influential in NFT. Vaynerchuk is the chairman of New York-based communications company VaynerX. Gary Vee, CEO of VaynerMedia, VaynerSports, and bestselling author, is worth $200 million.
GaryVee went from NFT collector to creator, launching VaynerNFT to help celebrities and brands.
Vaynerchuk's influence spans the NFT ecosystem as one of its most prolific voices. He's one of the most influential NFT figures, and his VeeFriends ecosystem keeps growing.
Vaynerchuk, a trend expert, thinks NFTs will be around for the rest of his life and VeeFriends will be a landmark project.
Why use VeeFriends NFTs?
The first VeeFriends collection has sold nearly $160 million via OpenSea. GaryVee insisted that the first 10,255 VeeFriends were just the beginning.
Book Games were announced to the VeeFriends community in August 2021. Mini Drops joined VeeFriends two months later.
Book Games
GaryVee's book "Twelve and a Half: Leveraging the Emotional Ingredients for Business Success" inspired Book Games. Even prior to the announcement Vaynerchuk had mapped out the utility of the book on an NFT scale. Book Games tied his book to the VeeFriends ecosystem and solidified its place in the collection.
GaryVee says Book Games is a layer 2 NFT project with 125,000 burnable tokens. Vaynerchuk's NFT fans were incentivized to buy as many copies of his new book as possible to receive NFT rewards later.
First, a bit about “layer 2.”
Layer 2 blockchain solutions help scale applications by routing transactions away from Ethereum Mainnet (layer 1). These solutions benefit from Mainnet's decentralized security model but increase transaction speed and reduce gas fees.
Polygon (integrated into OpenSea) and Immutable X are popular Ethereum layer 2 solutions. GaryVee chose Immutable X to reduce gas costs (transaction fees). Given the large supply of Book Games tokens, this decision will likely benefit the VeeFriends community, especially if the games run forever.
What's the strategy?
The VeeFriends patriarch announced on Aug. 27, 2021, that for every 12 books ordered during the Book Games promotion, customers would receive one NFT via airdrop. After nearly 100 days, GV sold over a million copies and announced that Book Games would go gamified on Jan. 10, 2022.
Immutable X's trading options make Book Games a "game." Book Games players can trade NFTs for other NFTs, sports cards, VeeCon tickets, and other prizes. Book Games can also whitelist other VeeFirends projects, which we'll cover in Series 2.
VeeFriends Mini Drops
GaryVee launched VeeFriends Mini Drops two months after Book Games, focusing on collaboration, scarcity, and the characters' "cultural longevity."
Spooky Vees, a collection of 31 1/1 Halloween-themed VeeFriends, was released on Halloween. First-come, first-served VeeFriend owners could claim these NFTs.
Mini Drops includes Gift Goat NFTs. By holding the Gift Goat VeeFriends character, collectors will receive 18 exclusive gifts curated by GaryVee and the team. Each gifting experience includes one physical gift and one NFT out of 555, to match the 555 Gift Goat tokens.
Gift Goat holders have gotten NFTs from Danny Cole (Creature World), Isaac "Drift" Wright (Where My Vans Go), Pop Wonder, and more.
GaryVee is poised to release the largest expansion of the VeeFriends and VaynerNFT ecosystem to date with VeeFriends Series 2.
VeeCon 101
By owning VeeFriends NFTs, collectors can join the VeeFriends community and attend VeeCon in 2022. The conference is only open to VeeCon NFT ticket holders (VeeFreinds + possibly more TBA) and will feature Beeple, Steve Aoki, and even Snoop Dogg.
The VeeFreinds floor in 2022 Q1 has remained at 16 ETH ($52,000), making VeeCon unattainable for most NFT enthusiasts. Why would someone spend that much crypto on a Minneapolis "superconference" ticket? Because of Gary Vaynerchuk.
Everything to know about VeeFriends Series 2
Vaynerchuk revealed in April 2022 that the VeeFriends ecosystem will grow by 55,555 NFTs after months of teasing.
With VeeFriends Series 2, each token will cost $995 USD in ETH, allowing NFT enthusiasts to join at a lower cost. The new series will be released on multiple dates in April.
Book Games NFT holders on the Friends List (whitelist) can mint Series 2 NFTs on April 12. Book Games holders have 32,000 NFTs.
VeeFriends Series 1 NFT holders can claim Series 2 NFTs on April 12. This allotment's supply is 10,255, like Series 1's.
On April 25, the public can buy 10,000 Series 2 NFTs. Unminted Friends List NFTs will be sold on this date, so this number may change.
The VeeFriends ecosystem will add 15 new characters (220 tokens each) on April 27. One character will be released per day for 15 days, and the only way to get one is to enter a daily raffle with Book Games tokens.
Series 2 NFTs won't give owners VeeCon access, but they will offer other benefits within the VaynerNFT ecosystem. Book Games and Series 2 will get new token burn mechanics in the upcoming drop.
Visit the VeeFriends blog for the latest collection info.
Where can you buy Gary Vee’s NFTs?
Need a VeeFriend NFT? Gary Vee recommends doing "50 hours of homework" before buying. OpenSea sells VeeFriends NFTs.

Sammy Abdullah
1 month ago
SaaS payback period data
It's ok and even desired to be unprofitable if you're gaining revenue at a reasonable cost and have 100%+ net dollar retention, meaning you never lose customers and expand them. To estimate the acceptable cost of new SaaS revenue, we compare new revenue to operating loss and payback period. If you pay back the customer acquisition cost in 1.5 years and never lose them (100%+ NDR), you're doing well.
To evaluate payback period, we compared new revenue to net operating loss for the last 73 SaaS companies to IPO since October 2017. (55 out of 73). Here's the data. 1/(new revenue/operating loss) equals payback period. New revenue/operating loss equals cost of new revenue.
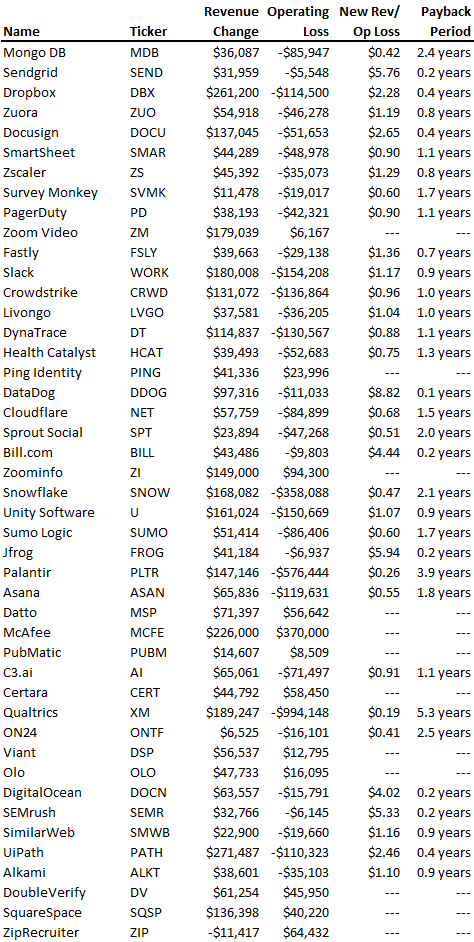
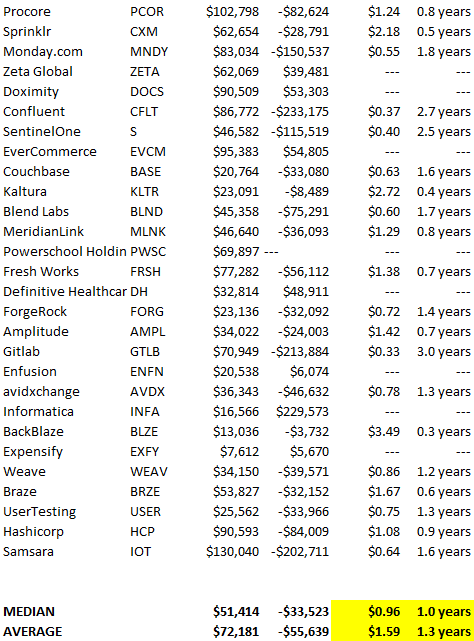
Payback averages a year. 55 SaaS companies that weren't profitable at IPO got a 1-year payback. Outstanding. If you pay for a customer in a year and never lose them (100%+ NDR), you're establishing a valuable business. The average was 1.3 years, which is within the 1.5-year range.
New revenue costs $0.96 on average. These SaaS companies lost $0.96 every $1 of new revenue last year. Again, impressive. Average new revenue per operating loss was $1.59.
Loss-in-operations definition. Operating loss revenue COGS S&M R&D G&A (technical point: be sure to use the absolute value of operating loss). It's wrong to only consider S&M costs and ignore other business costs. Operating loss and new revenue are measured over one year to eliminate seasonality.
Operating losses are desirable if you never lose a customer and have a quick payback period, especially when SaaS enterprises are valued on ARR. The payback period should be under 1.5 years, the cost of new income < $1, and net dollar retention 100%.

Camilla Dudley
2 months ago
How to gain Twitter followers: A 101 Guide

No wonder brands use Twitter to reach their audience. 53% of Twitter users buy new products first.
Twitter growth does more than make your brand look popular. It helps clients trust your business. It boosts your industry standing. It shows clients, prospects, and even competitors you mean business.
How can you naturally gain Twitter followers?
Share useful information
Post visual content
Tweet consistently
Socialize
Spread your @name everywhere.
Use existing customers
Promote followers
Share useful information
Twitter users join conversations and consume material. To build your followers, make sure your material appeals to them and gives value, whether it's sales, product lessons, or current events.
Use Twitter Analytics to learn what your audience likes.
Explore popular topics by utilizing relevant keywords and hashtags. Check out this post on how to use Twitter trends.
Post visual content
97% of Twitter users focus on images, so incorporating media can help your Tweets stand out. Visuals and videos make content more engaging and memorable.
Tweet often
Your audience should expect regular content updates. Plan your ideas and tweet during crucial seasons and events with a content calendar.
Socialize
Twitter connects people. Do more than tweet. Follow industry leaders. Retweet influencers, engage with thought leaders, and reply to mentions and customers to boost engagement.
Micro-influencers can promote your brand or items. They can help you gain new audiences' trust.
Spread your @name everywhere.
Maximize brand exposure. Add a follow button on your website, link to it in your email signature and newsletters, and promote it on business cards or menus.
Use existing customers
Emails can be used to find existing Twitter clients. Upload your email contacts and follow your customers on Twitter to start a dialogue.
Promote followers
Run a followers campaign to boost your organic growth. Followers campaigns promote your account to a particular demographic, and you only pay when someone follows you.
Consider short campaigns to enhance momentum or an always-on campaign to gain new followers.
Increasing your brand's Twitter followers takes effort and experimentation, but the payback is huge.
👋 Follow me on twitter