


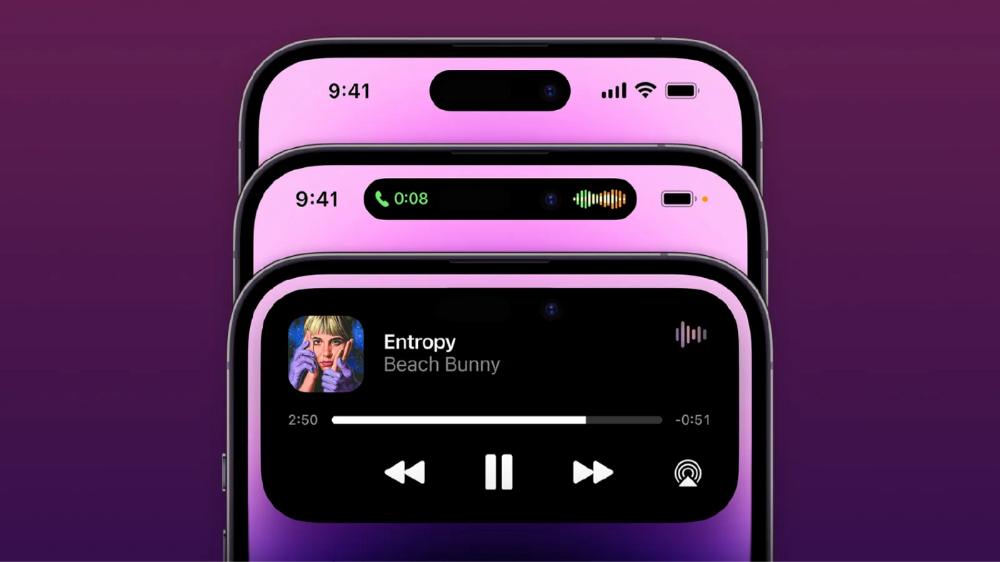



More on Technology

Nikhil Vemu
3 years ago
7 Mac Tips You Never Knew You Needed
Unleash the power of the Option key ⌥

#1 Open a link in the Private tab first.
Previously, if I needed to open a Safari link in a private window, I would:
copied the URL with the right click command,
choose File > New Private Window to open a private window, and
clicked return after pasting the URL.
I've found a more straightforward way.
Right-clicking a link shows this, right?
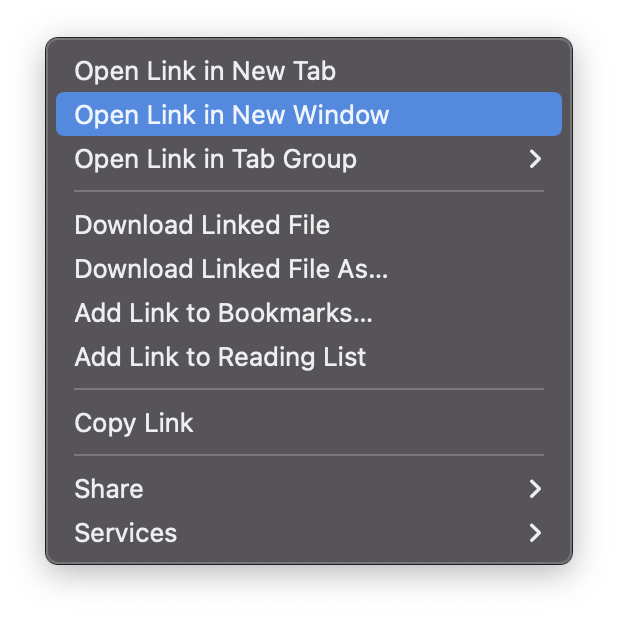
Hold option (⌥) for:
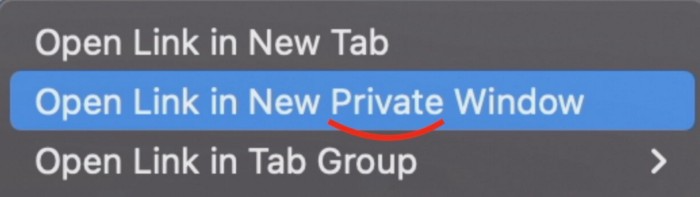
Click Open Link in New Private Window while holding.
Finished!
#2. Instead of searching for specific characters, try this
You may use unicode for business or school. Most people Google them when they need them.
That is lengthy!
You can type some special characters just by pressing ⌥ and a key.
For instance
• ⌥+2 -> ™ (Trademark)
• ⌥+0 -> ° (Degree)
• ⌥+G -> © (Copyright)
• ⌥+= -> ≠ (Not equal to)
• ⌥+< -> ≤ (Less than or equal to)
• ⌥+> -> ≥ (Greater then or equal to)
• ⌥+/ -> ÷ (Different symbol for division)#3 Activate Do Not Disturb silently.
Do Not Disturb when sharing my screen is awkward for me (because people may think Im trying to hide some secret notifications).
Here's another method.
Hold ⌥ and click on Time (at the extreme right on the menu-bar).

Now, DND is activated (secretly!). To turn it off, do it again.
Note: This works only for DND focus.#4. Resize a window starting from its center
Although this is rarely useful, it is still a hidden trick.
When you resize a window, the opposite edge or corner is used as the pivot, right?
However, if you want to resize it with its center as the pivot, hold while doing so.
#5. Yes, Cut-Paste is available on Macs as well (though it is slightly different).
I call it copy-move rather than cut-paste. This is how it works.
Carry it out.
Choose a file (by clicking on it), then copy it (⌘+C).
Go to a new location on your Mac. Do you use ⌘+V to paste it? However, to move it, press ⌘+⌥+V.
This removes the file from its original location and copies it here. And it works exactly like cut-and-paste on Windows.
#6. Instantly expand all folders
Set your Mac's folders to List view.
Assume you have one folder with multiple subfolders, each of which contains multiple files. And you wanted to look at every single file that was over there.
How would you do?
You're used to clicking the ⌄ glyph near the folder and each subfolder to expand them all, right? Instead, hold down ⌥ while clicking ⌄ on the parent folder.
This is what happens next.
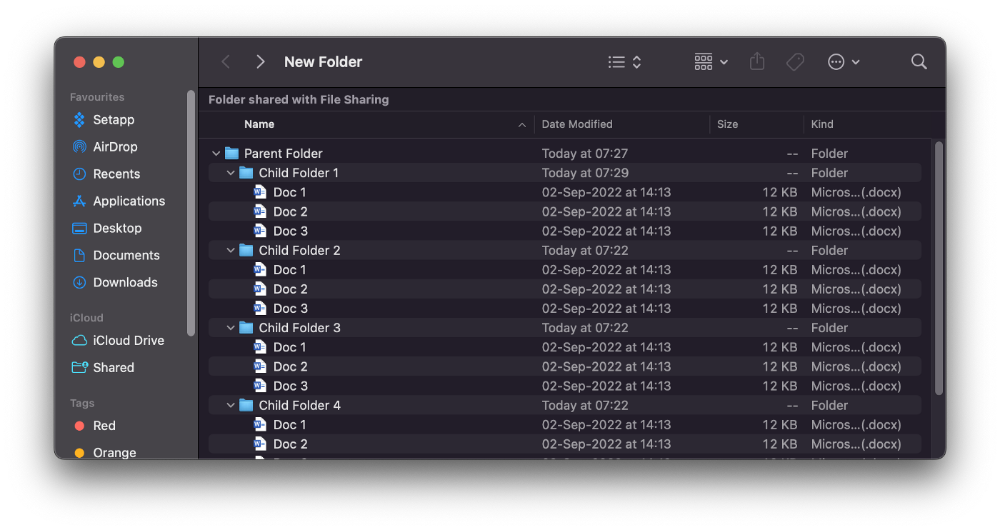
Everything expands.
View/Copy a file's path as an added bonus
If you want to see the path of a file in Finder, select it and hold ⌥, and you'll see it at the bottom for a moment.
To copy its path, right-click on the folder and hold down ⌥ to see this
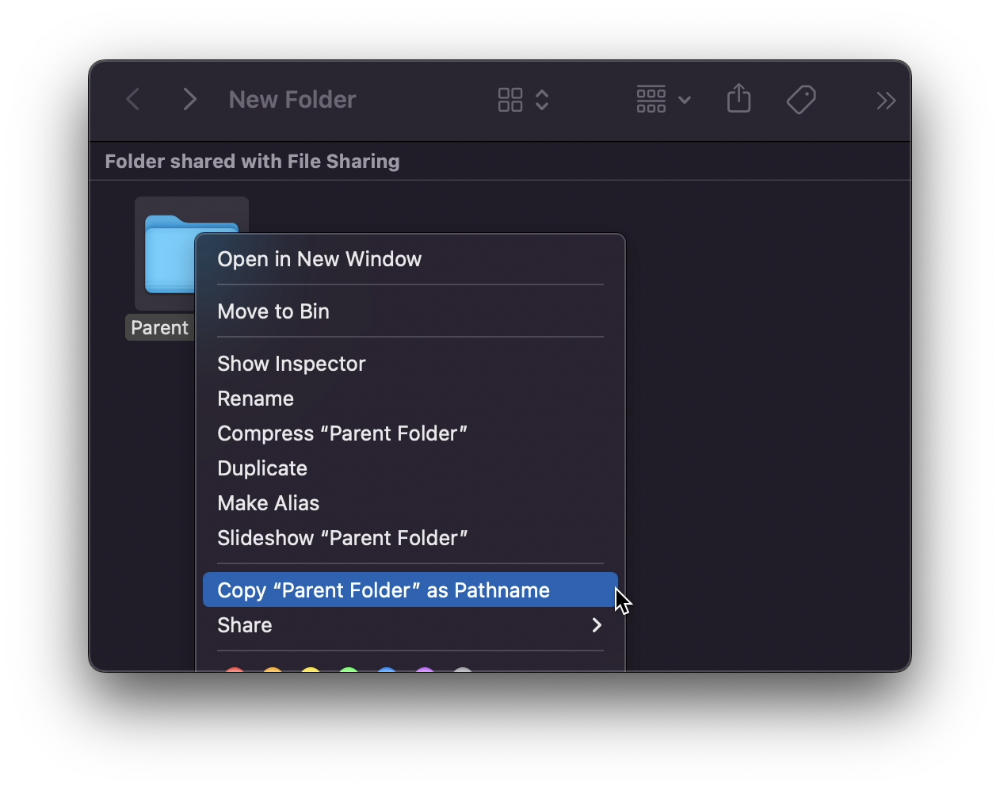
Click on Copy <"folder name"> as Pathname to do it.
#7 "Save As"
I was irritated by the lack of "Save As" in Pages when I first got a Mac (after 15 years of being a Windows guy).
It was necessary for me to save the file as a new file, in a different location, with a different name, or both.
Unfortunately, I couldn't do it on a Mac.
However, I recently discovered that it appears when you hold ⌥ when in the File menu.
Yay!

The Mystique
3 years ago
Four Shocking Dark Web Incidents that Should Make You Avoid It
Dark Web activity? Is it as horrible as they say?

We peruse our phones for hours. Internet has improved our worldview.
However, the world's harshest realities remain buried on the internet and unattainable by everyone.
Browsers cannot access the Dark Web. Browse it with high-security authentication and exclusive access. There are compelling reasons to avoid the dark web at all costs.
1. The Dark Web and I

Darius wrote My Dark Web Story on reddit two years ago. The user claimed to have shared his dark web experience. DaRealEddyYT wanted to surf the dark web after hearing several stories.
He curiously downloaded Tor Browser, which provides anonymity and security.
In the Dark Room, bound
As Darius logged in, a text popped up: “Want a surprise? Click on this link.”
The link opened to a room with a chair. Only one light source illuminated the room. The chair held a female tied.
As the screen read "Let the game begin," a man entered the room and was paid in bitcoins to torment the girl.
The man dragged and tortured the woman.
A danger to safety
Leaving so soon, Darius, disgusted Darius tried to leave the stream. The anonymous user then sent Darius his personal information, including his address, which frightened him because he didn't know Tor was insecure.
After deleting the app, his phone camera was compromised.
He also stated that he left his residence and returned to find it unlocked and a letter saying, Thought we wouldn't find you? Reddit never updated the story.
The story may have been a fake, but a much scarier true story about the dark side of the internet exists.
2. The Silk Road Market

The dark web is restricted for a reason. The dark web has everything illicit imaginable. It's awful central.
The dark web has everything, from organ sales to drug trafficking to money laundering to human trafficking. Illegal drugs, pirated software, credit card, bank, and personal information can be found in seconds.
The dark web has reserved websites like Google. The Silk Road Website, which operated from 2011 to 2013, was a leading digital black market.
The FBI grew obsessed with site founder and processor Ross William Ulbricht.
The site became a criminal organization as money laundering and black enterprises increased. Bitcoin was utilized for credit card payment.
The FBI was close to arresting the site's administrator. Ross was detained after the agency closed Silk Road in 2013.
Two years later, in 2015, he was convicted and sentenced to two consecutive life terms and forty years. He appealed in 2016 but was denied, thus he is currently serving time.
The hefty sentence was for more than running a black marketing site. He was also convicted of murder-for-hire, earning about $730,000 in a short time.
3. Person-buying auctions

Bidding on individuals is another weird internet activity. After a Milan photo shoot, 20-year-old British model Chloe Ayling was kidnapped.
An ad agency in Milan made a bogus offer to shoot with the mother of a two-year-old boy. Four men gave her anesthetic and put her in a duffel bag when she arrived.
She was held captive for several days, and her images and $300,000 price were posted on the dark web. Black Death Trafficking Group kidnapped her to sell her for sex.
She was told two black death foot warriors abducted her. The captors released her when they found she was a mother because mothers were less desirable to sex slave buyers.
In July 2018, Lukasz Pawel Herba was arrested and sentenced to 16 years and nine months in prison. Being a young mother saved Chloe from creepy bidding.
However, it exceeds expectations of how many more would be in such danger daily without their knowledge.
4. Organ sales

Many are unaware of dark web organ sales. Patients who cannot acquire organs often turn to dark web brokers.
Brokers handle all transactions between donors and customers.
Bitcoins are used for dark web transactions, and the Tor server permits personal data on the web.
The WHO reports approximately 10,000 unlawful organ transplants annually. The black web sells kidneys, hearts, even eyes.
To protect our lives and privacy, we should manage our curiosity and never look up dangerous stuff.
While it's fascinating and appealing to know what's going on in the world we don't know about, it's best to prioritize our well-being because one never knows how bad it might get.
Sources

Amelia Winger-Bearskin
3 years ago
Reasons Why AI-Generated Images Remind Me of Nightmares
AI images are like funhouse mirrors.
Google's AI Blog introduced the puppy-slug in the summer of 2015.

Puppy-slug isn't a single image or character. "Puppy-slug" refers to Google's DeepDream's unsettling psychedelia. This tool uses convolutional neural networks to train models to recognize dataset entities. If researchers feed the model millions of dog pictures, the network will learn to recognize a dog.
DeepDream used neural networks to analyze and classify image data as well as generate its own images. DeepDream's early examples were created by training a convolutional network on dog images and asking it to add "dog-ness" to other images. The models analyzed images to find dog-like pixels and modified surrounding pixels to highlight them.
Puppy-slugs and other DeepDream images are ugly. Even when they don't trigger my trypophobia, they give me vertigo when my mind tries to reconcile familiar features and forms in unnatural, physically impossible arrangements. I feel like I've been poisoned by a forbidden mushroom or a noxious toad. I'm a Lovecraft character going mad from extradimensional exposure. They're gross!
Is this really how AIs see the world? This is possibly an even more unsettling topic that DeepDream raises than the blatant abjection of the images.
When these photographs originally circulated online, many friends were startled and scandalized. People imagined a computer's imagination would be literal, accurate, and boring. We didn't expect vivid hallucinations and organic-looking formations.
DeepDream's images didn't really show the machines' imaginations, at least not in the way that scared some people. DeepDream displays data visualizations. DeepDream reveals the "black box" of convolutional network training.
Some of these images look scary because the models don't "know" anything, at least not in the way we do.
These images are the result of advanced algorithms and calculators that compare pixel values. They can spot and reproduce trends from training data, but can't interpret it. If so, they'd know dogs have two eyes and one face per head. If machines can think creatively, they're keeping it quiet.
You could be forgiven for thinking otherwise, given OpenAI's Dall-impressive E's results. From a technological perspective, it's incredible.
Arthur C. Clarke once said, "Any sufficiently advanced technology is indistinguishable from magic." Dall-magic E's requires a lot of math, computer science, processing power, and research. OpenAI did a great job, and we should applaud them.
Dall-E and similar tools match words and phrases to image data to train generative models. Matching text to images requires sorting and defining the images. Untold millions of low-wage data entry workers, content creators optimizing images for SEO, and anyone who has used a Captcha to access a website make these decisions. These people could live and die without receiving credit for their work, even though the project wouldn't exist without them.
This technique produces images that are less like paintings and more like mirrors that reflect our own beliefs and ideals back at us, albeit via a very complex prism. Due to the limitations and biases that these models portray, we must exercise caution when viewing these images.
The issue was succinctly articulated by artist Mimi Onuoha in her piece "On Algorithmic Violence":
As we continue to see the rise of algorithms being used for civic, social, and cultural decision-making, it becomes that much more important that we name the reality that we are seeing. Not because it is exceptional, but because it is ubiquitous. Not because it creates new inequities, but because it has the power to cloak and amplify existing ones. Not because it is on the horizon, but because it is already here.
You might also like

obimy.app
3 years ago
How TikTok helped us grow to 6 million users
This resulted to obimy's new audience.

Hi! obimy's official account. Here, we'll teach app developers and marketers. In 2022, our downloads increased dramatically, so we'll share what we learned.
obimy is what we call a ‘senseger’. It's a new method to communicate digitally. Instead of text, obimy users connect through senses and moods. Feeling playful? Flirt with your partner, pat a pal, or dump water on a classmate. Each feeling is an interactive animation with vibration. It's a wordless app. App Store and Google Play have obimy.
We had 20,000 users in 2022. Two to five thousand of them opened the app monthly. Our DAU metric was 500.
We have 6 million users after 6 months. 500,000 individuals use obimy daily. obimy was the top lifestyle app this week in the U.S.
And TikTok helped.
TikTok fuels obimys' growth. It's why our app exploded. How and what did we learn? Our Head of Marketing, Anastasia Avramenko, knows.
our actions prior to TikTok
We wanted to achieve product-market fit through organic expansion. Quora, Reddit, Facebook Groups, Facebook Ads, Google Ads, Apple Search Ads, and social media activity were tested. Nothing worked. Our CPI was sometimes $4, so unit economics didn't work.
We studied our markets and made audience hypotheses. We promoted our goods and studied our audience through social media quizzes. Our target demographic was Americans in long-distance relationships. I designed quizzes like Test the Strength of Your Relationship to better understand the user base. After each quiz, we encouraged users to download the app to enhance their connection and bridge the distance.
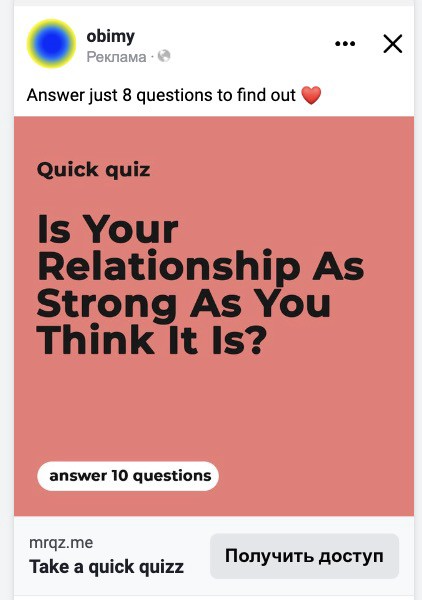
We got 1,000 responses for $50. This helped us comprehend the audience's grief and coping strategies (aka our rivals). I based action items on answers given. If you can't embrace a loved one, use obimy.
We also tried Facebook and Google ads. From the start, we knew it wouldn't work.
We were desperate to discover a free way to get more users.
Our journey to TikTok
TikTok is a great venue for emerging creators. It also helped reach people. Before obimy, my TikTok videos garnered 12 million views without sponsored promotion.
We had to act. TikTok was required.

I wasn't a TikTok user before obimy. Initially, I uploaded promotional content. Call-to-actions appear strange next to dancing challenges and my money don't jiggle jiggle. I learned TikTok. Watch TikTok for an hour was on my to-do list. What a dream job!
Our most popular movies presented the app alongside text outlining what it does. We started promoting them in Europe and the U.S. and got a 16% CTR and $1 CPI, an improvement over our previous efforts.
Somehow, we were expanding. So we came up with new hypotheses, calls to action, and content.
Four months passed, yet we saw no organic growth.
Russia attacked Ukraine.
Our app aimed to be helpful. For now, we're focusing on our Ukrainian audience. I posted sloppy TikToks illustrating how obimy can help during shelling or air raids.
In two hours, Kostia sent me our visitor count. Our servers crashed.
Initially, we had several thousand daily users. Over 200,000 users joined obimy in a week. They posted obimy videos on TikTok, drawing additional users. We've also resumed U.S. video promotion.
We gained 2,000,000 new members with less than $100 in ads, primarily in the U.S. and U.K.
TikTok helped.
The figures
We were confident we'd chosen the ideal tool for organic growth.
Over 45 million people have viewed our own videos plus a ton of user-generated content with the hashtag #obimy.
About 375 thousand people have liked all of our individual videos.
The number of downloads and the virality of videos are directly correlated.
Where are we now?
TikTok fuels our organic growth. We post 56 videos every week and pay to promote viral content.
We use UGC and influencers. We worked with Universal Music Italy on Eurovision. They offered to promote us through their million-follower TikTok influencers. We thought their followers would improve our audience, but it didn't matter. Integration didn't help us. Users that share obimy videos with their followers can reach several million views, which affects our download rate.
After the dust settled, we determined our key audience was 13-18-year-olds. They want to express themselves, but it's sometimes difficult. We're searching for methods to better engage with our users. We opened a Discord server to discuss anime and video games and gather app and content feedback.
TikTok helps us test product updates and hypotheses. Example: I once thought we might raise MAU by prompting users to add strangers as friends. Instead of asking our team to construct it, I made a TikTok urging users to share invite URLs. Users share links under every video we upload, embracing people worldwide.
Key lessons
Don't direct-sell. TikTok isn't for Instagram, Facebook, or YouTube promo videos. Conventional advertisements don't fit. Most users will swipe up and watch humorous doggos.
More product videos are better. Finally. So what?
Encourage interaction. Tagging friends in comments or making videos with the app promotes it more than any marketing spend.
Be odd and risqué. A user mistakenly sent a French kiss to their mom in one of our most popular videos.
TikTok helps test hypotheses and build your user base. It also helps develop apps. In our upcoming blog, we'll guide you through obimy's design revisions based on TikTok. Follow us on Twitter, Instagram, and TikTok.

Steve QJ
4 years ago
Putin's War On Reality
The dictator's playbook.
Stalin's successor, Nikita Khrushchev, delivered a speech titled "On The Cult Of Personality And Its Consequences" in 1956, three years after Stalin’s death.
It was Stalin's grave abuse of power that caused untold harm to our party.
Stalin acted not by persuasion, explanation, or patient cooperation, but by imposing his ideas and demanding absolute obedience. […]
See where Stalin's mania for greatness led? He had lost all sense of reality.
The speech, which was never made public, shook the Soviet Union and the Soviet Bloc. After Stalin's "cult of personality" was exposed as a lie, only reality remained.
As I've watched the nightmare unfold in Ukraine, I'm reminded of that question. Primarily by Putin's repeated denials.
His odd claim that Ukraine is run by drug addicts and Nazis (especially strange given that Volodymyr Zelenskyy, the Ukrainian president, is Jewish). Others attempt to portray Russia as liberators rather than occupiers. For example, he portrays Luhansk and Donetsk as plucky, newly independent states when they have been totalitarian statelets for 8 years.
Putin seemed to have lost all sense of reality.
Maybe that's why his remarks to an oligarchs' gathering stood out:
Everything is a desperate measure. They gave us no choice. We couldn't do anything about their security risks. […] They could have put the country in jeopardy.
This is almost certainly true from Putin's perspective. Even for Putin, a military invasion seems unlikely. So, what exactly is putting Russia's security in jeopardy? How could Ukraine's independence endanger Russia's existence?
The truth is the only thing that truly terrifies leaders like these.
Trump, the president of “alternative facts,” "and “fake news” praised Putin's fabricated justifications for the Ukraine invasion. Russia tightened news censorship as news of their losses came in. It's no accident that modern dictatorships like Russia (and China and North Korea) restrict citizens' access to information.
Controlling what people see, hear, and think is the simplest method. And Ukraine's recent efforts to join the European Union showed a country whose thoughts Putin couldn't control. With the Russian and Ukrainian peoples so close, he could not control their reality.
He appears to think this is a threat worth fighting NATO over.
It's easy to disown history's great dictators. By the magnitude of their harm. But the strategy they used is still in use today, albeit not to the same devastating effect.
The Kim dynasty in North Korea has ruled for 74 years, Putin has ruled Russia for 19 years (using loopholes and even rewriting the constitution).
“Politicians and diapers must be changed frequently,” said Mark Twain. "And for the same reason.”
When their egos are threatened, they sabre-rattle, as in Kim Jong-un and Donald Trump's famous spat about the size of their...ahem, “nuclear buttons”." Or Putin's threats of mutual destruction this weekend.
Most importantly, they have cult-like control over their followers.
When a leader whose power is built on lies feels he is losing control of the narrative, things like Trump's Jan. 6 meltdown and Putin's current actions in Ukraine are unavoidable.
Leaders who try to control their people's reality will have to die to keep the illusion alive.
Long version of this post available here

Scott Stockdale
3 years ago
A Day in the Life of Lex Fridman Can Help You Hit 6-Month Goals

The Lex Fridman podcast host has interviewed Elon Musk.
Lex is a minimalist YouTuber. His videos are sloppy. Suits are his trademark.
In a video, he shares a typical day. I've smashed my 6-month goals using its ideas.
Here's his schedule.
Morning Mantra
Not woo-woo. Lex's mantra reflects his practicality.
Four parts.
Rulebook
"I remember the game's rules," he says.
Among them:
Sleeping 6–8 hours nightly
1–3 times a day, he checks social media.
Every day, despite pain, he exercises. "I exercise uninjured body parts."
Visualize
He imagines his day. "Like Sims..."
He says three things he's grateful for and contemplates death.
"Today may be my last"
Objectives
Then he visualizes his goals. He starts big. Five-year goals.
Short-term goals follow. Lex says they're year-end goals.
Near but out of reach.
Principles
He lists his principles. Assertions. His goals.
He acknowledges his cliche beliefs. Compassion, empathy, and strength are key.
Here's my mantra routine:

Four-Hour Deep Work
Lex begins a four-hour deep work session after his mantra routine. Today's toughest.
AI is Lex's specialty. His video doesn't explain what he does.
Clearly, he works hard.
Before starting, he has water, coffee, and a bathroom break.
"During deep work sessions, I minimize breaks."
He's distraction-free. Phoneless. Silence. Nothing. Any loose ideas are typed into a Google doc for later. He wants to work.
"Just get the job done. Don’t think about it too much and feel good once it’s complete." — Lex Fridman
30-Minute Social Media & Music
After his first deep work session, Lex rewards himself.
10 minutes on social media, 20 on music. Upload content and respond to comments in 10 minutes. 20 minutes for guitar or piano.
"In the real world, I’m currently single, but in the music world, I’m in an open relationship with this beautiful guitar. Open relationship because sometimes I cheat on her with the acoustic." — Lex Fridman
Two-hour exercise
Then exercise for two hours.
Daily runs six miles. Then he chooses how far to go. Run time is an hour.
He does bodyweight exercises. Every minute for 15 minutes, do five pull-ups and ten push-ups. It's David Goggins-inspired. He aims for an hour a day.
He's hungry. Before running, he takes a salt pill for electrolytes.
He'll then take a one-minute cold shower while listening to cheesy songs. Afterward, he might eat.
Four-Hour Deep Work
Lex's second work session.
He works 8 hours a day.
Again, zero distractions.
Eating
The video's meal doesn't look appetizing, but it's healthy.
It's ground beef with vegetables. Cauliflower is his "ground-floor" veggie. "Carrots are my go-to party food."
Lex's keto diet includes 1800–2000 calories.
He drinks a "nutrient-packed" Atheltic Greens shake and takes tablets. It's:
One daily tablet of sodium.
Magnesium glycinate tablets stopped his keto headaches.
Potassium — "For electrolytes"
Fish oil: healthy joints
“So much of nutrition science is barely a science… I like to listen to my own body and do a one-person, one-subject scientific experiment to feel good.” — Lex Fridman
Four-hour shallow session
This work isn't as mentally taxing.
Lex planned to:
Finish last session's deep work (about an hour)
Adobe Premiere podcasting (about two hours).
Email-check (about an hour). Three times a day max. First, check for emergencies.
If he's sick, he may watch Netflix or YouTube documentaries or visit friends.
“The possibilities of chaos are wide open, so I can do whatever the hell I want.” — Lex Fridman
Two-hour evening reading
Nonstop work.
Lex ends the day reading academic papers for an hour. "Today I'm skimming two machine learning and neuroscience papers"
This helps him "think beyond the paper."
He reads for an hour.
“When I have a lot of energy, I just chill on the bed and read… When I’m feeling tired, I jump to the desk…” — Lex Fridman
Takeaways
Lex's day-in-the-life video is inspiring.
He has positive energy and works hard every day.
Schedule:
Mantra Routine includes rules, visualizing, goals, and principles.
Deep Work Session #1: Four hours of focus.
10 minutes social media, 20 minutes guitar or piano. "Music brings me joy"
Six-mile run, then bodyweight workout. Two hours total.
Deep Work #2: Four hours with no distractions. Google Docs stores random thoughts.
Lex supplements his keto diet.
This four-hour session is "open to chaos."
Evening reading: academic papers followed by fiction.
"I value some things in life. Work is one. The other is loving others. With those two things, life is great." — Lex Fridman