



More on Entrepreneurship/Creators

Andy Raskin
3 years ago
I've Never Seen a Sales Deck This Good

It’s Zuora’s, and it’s brilliant. Here’s why.
My friend Tim got a sales position at a Series-C software company that garnered $60 million from A-list investors. He's one of the best salespeople I know, yet he emailed me after starting to struggle.
Tim has a few modest clients. “Big companies ignore my pitch”. Tim said.
I love helping teams write the strategic story that drives sales, marketing, and fundraising. Tim and I had lunch at Amber India on Market Street to evaluate his deck.
After a feast, I asked Tim when prospects tune out.
He said, “several slides in”.
Intent on maximizing dining ROI, Tim went back to the buffet for seconds. When he returned, I pulled out my laptop and launched into a Powerpoint presentation.
“What’s this?” Tim asked.
“This,” I said, “is the greatest sales deck I have ever seen.”
Five Essentials of a Great Sales Narrative
I showed Tim a sales slide from IPO-bound Zuora, which sells a SaaS platform for subscription billing. Zuora supports recurring payments (e.g. enterprise software).
Ex-Zuora salesman gave me the deck, saying it helped him close his largest business. (I don't know anyone who works at Zuora.) After reading this, a few Zuora employees contacted me.)
Tim abandoned his naan in a pool of goat curry and took notes while we discussed the Zuora deck.
We remarked how well the deck led prospects through five elements:
(The ex-Zuora salesperson begged me not to release the Zuora deck publicly.) All of the images below originate from Zuora's website and SlideShare channel.)
#1. Name a Significant Change in the World
Don't start a sales presentation with mentioning your product, headquarters, investors, clients, or yourself.
Name the world shift that raises enormous stakes and urgency for your prospect.
Every Zuora sales deck begins with this slide:

Zuora coined the term subscription economy to describe a new market where purchasers prefer regular service payments over outright purchases. Zuora then shows a slide with the change's history.

Most pitch recommendation advises starting with the problem. When you claim a problem, you put prospects on the defensive. They may be unaware of or uncomfortable admitting the situation.
When you highlight a global trend, prospects open up about how it affects them, worries them, and where they see opportunity. You capture their interest. Robert McKee says:
…what attracts human attention is change. …if the temperature around you changes, if the phone rings — that gets your attention. The way in which a story begins is a starting event that creates a moment of change.
#2. Show There’ll Be Winners and Losers
Loss aversion affects all prospects. They avoid a loss by sticking with the status quo rather than risking a gain by changing.
To fight loss aversion, show how the change will create winners and losers. You must show both
that if the prospect can adjust to the modification you mentioned, the outcome will probably be quite favorable; and
That failing to do so is likely to have an unacceptable negative impact on the prospect's future
Zuora shows a mass extinction among Fortune 500 firms.

…and then showing how the “winners” have shifted from product ownership to subscription services. Those include upstarts…

…as well as rejuvenated incumbents:

To illustrate, Zuora asks:

Winners utilize Zuora's subscription service models.
#3. Tease the Promised Land
It's tempting to get into product or service details now. Resist that urge.
Prospects won't understand why product/service details are crucial if you introduce them too soon, therefore they'll tune out.
Instead, providing a teaser image of the happily-ever-after your product/service will assist the prospect reach.
Your Promised Land should be appealing and hard to achieve without support. Otherwise, why does your company exist?
Zuora shows this Promised Land slide after explaining that the subscription economy will have winners and losers.

Not your product or service, but a new future state.
(I asked my friend Tim to describe his Promised Land, and he answered, "You’ll have the most innovative platform for ____." Nope: the Promised Land isn't possessing your technology, but living with it.)
Your Promised Land helps prospects market your solution to coworkers after your sales meeting. Your coworkers will wonder what you do without you. Your prospects are more likely to provide a persuasive answer with a captivating Promised Land.
#4. Present Features as “Mystic Gifts” for Overcoming Difficulties on the Road to the Promised Land
Successful sales decks follow the same format as epic films and fairy tales. Obi Wan gives Luke a lightsaber to help him destroy the Empire. You're Gandalf, helping Frodo destroy the ring. Your prospect is Cinderella, and you're her fairy godmother.
Position your product or service's skills as mystical gifts to aid your main character (prospect) achieve the Promised Land.

Zuora's client record slide is shown above. Without context, even the most technical prospect would be bored.
Positioned in the context of shifting from an “old” to a “new world”, it's the foundation for a compelling conversation with prospects—technical and otherwise—about why traditional solutions can't reach the Promised Land.
#5. Show Proof That You Can Make the Story True.
In this sense, you're promising possibilities that if they follow you, they'll reach the Promised Land.
The journey to the Promised Land is by definition rocky, so prospects are right to be cautious. The final part of the pitch is proof that you can make the story come true.
The most convincing proof is a success story about how you assisted someone comparable to the prospect. Zuora's sales people use a deck of customer success stories, but this one gets the essence.

I particularly appreciate this one from an NCR exec (a Zuora customer), which relates more strongly to Zuora's Promised Land:

Not enough successful customers? Product demos are the next best evidence, but features should always be presented in the context of helping a prospect achieve the Promised Land.
The best sales narrative is one that is told by everyone.
Success rarely comes from a fantastic deck alone. To be effective, salespeople need an organization-wide story about change, Promised Land, and Magic Gifts.
Zuora exemplifies this. If you hear a Zuora executive, including CEO Tien Tzuo, talk, you'll likely hear about the subscription economy and its winners and losers. This is the theme of the company's marketing communications, campaigns, and vision statement.

According to the ex-Zuora salesperson, company-wide story alignment made him successful.
The Zuora marketing folks ran campaigns and branding around this shift to the subscription economy, and [CEO] Tien [Tzuo] talked it up all the time. All of that was like air cover for my in-person sales ground attack. By the time I arrived, prospects were already convinced they had to act. It was the closest thing I’ve ever experienced to sales nirvana.
The largest deal ever
Tim contacted me three weeks after our lunch to tell me that prospects at large organizations were responding well to his new deck, which we modeled on Zuora's framework. First, prospects revealed their obstacles more quickly. The new pitch engages CFOs and other top gatekeepers better, he said.
A week later, Tim emailed that he'd signed his company's biggest agreement.
Next week, we’re headed back to Amber India to celebrate.

Grace Huang
3 years ago
I sold 100 copies of my book when I had anticipated selling none.
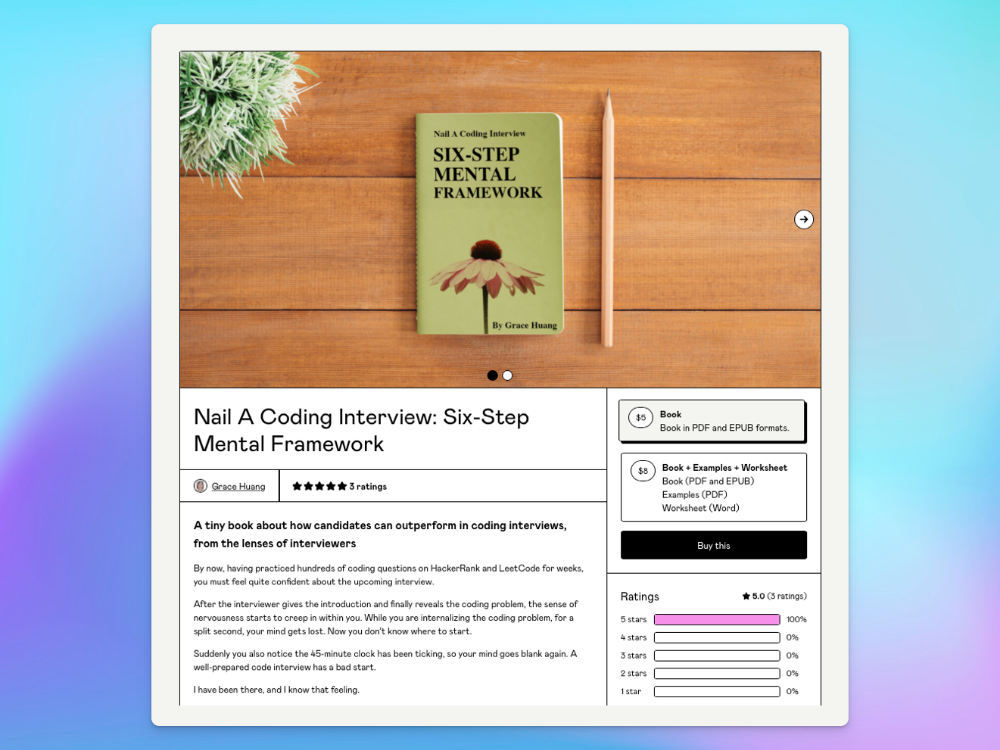
After a decade in large tech, I know how software engineers were interviewed. I've seen outstanding engineers fail interviews because their responses were too vague.
So I wrote Nail A Coding Interview: Six-Step Mental Framework. Give candidates a mental framework for coding questions; help organizations better prepare candidates so they can calibrate traits.
Recently, I sold more than 100 books, something I never expected.
In this essay, I'll describe my publication journey, which included self-doubt and little triumphs. I hope this helps if you want to publish.
It was originally a Medium post.
How did I know to develop a coding interview book? Years ago, I posted on Medium.
Six steps to ace a coding interview Inhale. blog.devgenius.io
This story got a lot of attention and still gets a lot of daily traffic. It indicates this domain's value.
Converted the Medium article into an ebook
The Medium post contains strong bullet points, but it is missing the “flesh”. How to use these strategies in coding interviews, for example. I filled in the blanks and made a book.
I made the book cover for free. It's tidy.
Shared the article with my close friends on my social network WeChat.
I shared the book on Wechat's Friend Circle (朋友圈) after publishing it on Gumroad. Many friends enjoyed my post. It definitely triggered endorphins.
In Friend Circle, I presented a 100% off voucher. No one downloaded the book. Endorphins made my heart sink.
Several days later, my Apple Watch received a Gumroad notification. A friend downloaded it. I majored in finance, he subsequently said. My brother-in-law can get it? He downloaded it to cheer me up.
I liked him, but was disappointed that he didn't read it.
The Tipping Point: Reddit's Free Giving
I trusted the book. It's based on years of interviewing. I felt it might help job-hunting college students. If nobody wants it, it can still have value.
I posted the book's link on /r/leetcode. I told them to DM me for a free promo code.
Momentum shifted everything. Gumroad notifications kept coming when I was out with family. Following orders.
As promised, I sent DMs a promo code. Some consumers ordered without asking for a promo code. Some readers finished the book and posted reviews.
My book was finally on track.
A 5-Star Review, plus More
A reader afterwards DMed me and inquired if I had another book on system design interviewing. I said that was a good idea, but I didn't have one. If you write one, I'll be your first reader.
Later, I asked for a book review. Yes, but how? That's when I learned readers' reviews weren't easy. I built up an email pipeline to solicit customer reviews. Since then, I've gained credibility through ratings.
Learnings
I wouldn't have gotten 100 if I gave up when none of my pals downloaded. Here are some lessons.
Your friends are your allies, but they are not your clients.
Be present where your clients are
Request ratings and testimonials
gain credibility gradually
I did it, so can you. Follow me on Twitter @imgracehuang for my publishing and entrepreneurship adventure.
Maddie Wang
3 years ago
Easiest and fastest way to test your startup idea!

Here's the fastest way to validate company concepts.
I squandered a year after dropping out of Stanford designing a product nobody wanted.
But today, I’m at 100k!
Differences:
I was designing a consumer product when I dropped out.
I coded MVP, got 1k users, and got YC interview.
Nice, huh?
WRONG!
Still coding and getting users 12 months later
WOULD PEOPLE PAY FOR IT? was the riskiest assumption I hadn't tested.
When asked why I didn't verify payment, I said,
Not-ready products. Now, nobody cares. The website needs work. Include this. Increase usage…
I feared people would say no.
After 1 year of pushing it off, my team told me they were really worried about the Business Model. Then I asked my audience if they'd buy my product.
So?
No, overwhelmingly.
I felt like I wasted a year building a product no one would buy.
Founders Cafe was the opposite.
Before building anything, I requested payment.
40 founders were interviewed.
Then we emailed Stanford, YC, and other top founders, asking them to join our community.
BOOM! 10/12 paid!
Without building anything, in 1 day I validated my startup's riskiest assumption. NOT 1 year.
Asking people to pay is one of the scariest things.
I understand.
I asked Stanford queer women to pay before joining my gay sorority.
I was afraid I'd turn them off or no one would pay.
Gay women, like those founders, were in such excruciating pain that they were willing to pay me upfront to help.
You can ask for payment (before you build) to see if people have the burning pain. Then they'll pay!
Examples from Founders Cafe members:
😮 Using a fake landing page, a college dropout tested a product. Paying! He built it and made $3m!
😮 YC solo founder faked a Powerpoint demo. 5 Enterprise paid LOIs. $1.5m raised, built, and in YC!
😮 A Harvard founder can convert Figma to React. 1 day, 10 customers. Built a tool to automate Figma -> React after manually fulfilling requests. 1m+
Bad example:
😭 Stanford Dropout Spends 1 Year Building Product Without Payment Validation
Some people build for a year and then get paying customers.
What I'm sharing is my experience and what Founders Cafe members have told me about validating startup ideas.
Don't waste a year like I did.
After my first startup failed, I planned to re-enroll at Stanford/work at Facebook.
After people paid, I quit for good.
I've hit $100k!
Hope this inspires you to request upfront payment! It'll change your life
You might also like

Dylan Smyth
4 years ago
10 Ways to Make Money Online in 2022
As a tech-savvy person (and software engineer) or just a casual technology user, I'm sure you've had this same question countless times: How do I make money online? and how do I make money with my PC/Mac?
You're in luck! Today, I will list the top 5 easiest ways to make money online. Maybe a top ten in the future? Top 5 tips for 2022.
1. Using the gig economy
There are many websites on the internet that allow you to earn extra money using skills and equipment that you already own.
I'm referring to the gig economy. It's a great way to earn a steady passive income from the comfort of your own home. For some sites, premium subscriptions are available to increase sales and access features like bidding on more proposals.
Some of these are:
- Freelancer
- Upwork
- Fiverr (⭐ my personal favorite)
- TaskRabbit
2. Mineprize
MINEPRIZE is a great way to make money online. What's more, You need not do anything! You earn money by lending your idle CPU power to MINEPRIZE.
To register with MINEPRIZE, all you need is an email address and a password. Let MINEPRIZE use your resources, and watch the money roll in! You can earn up to $100 per month by letting your computer calculate. That's insane.
3. Writing
“O Romeo, Romeo, why art thou Romeo?” Okay, I admit that not all writing is Shakespearean. To be a copywriter, you'll need to be fluent in English. Thankfully, we don't have to use typewriters anymore.
Writing is a skill that can earn you a lot of money (claps for the rhyme).
Here are a few ways you can make money typing on your fancy keyboard:
Self-publish a book
Write scripts for video creators
Write for social media
Book-checking
Content marketing help
What a list within a list!
4. Coding
Yes, kids. You've probably coded before if you understand
You've probably coded before if you understand
print("hello world");
Computational thinking (or coding) is one of the most lucrative ways to earn extra money, or even as a main source of income.
Of course, there are hardcode coders (like me) who write everything line by line, binary di — okay, that last part is a bit exaggerated.
But you can also make money by writing websites or apps or creating low code or no code platforms.
But you can also make money by writing websites or apps or creating low code or no code platforms.
Some low-code platforms
Sheet : spreadsheets to apps :
Loading... We'll install your new app... No-Code Your team can create apps and automate tasks. Agile…
www.appsheet.com
Low-code platform | Business app creator - Zoho Creator
Work is going digital, and businesses of all sizes must adapt quickly. Zoho Creator is a...
www.zoho.com
Sell your data with TrueSource. NO CODE NEEDED
Upload data, configure your product, and earn in minutes.
www.truesource.io
Cool, huh?
5. Created Content
If we use the internet correctly, we can gain unfathomable wealth and extra money. But this one is a bit more difficult. Unlike some of the other items on this list, it takes a lot of time up front.
I'm referring to sites like YouTube and Medium. It's a great way to earn money both passively and actively. With the likes of Jake- and Logan Paul, PewDiePie (a.k.a. Felix Kjellberg) and others, it's never too late to become a millionaire on YouTube. YouTubers are always rising to the top with great content.
6. NFTs and Cryptocurrency
It is now possible to amass large sums of money by buying and selling digital assets on NFTs and cryptocurrency exchanges. Binance's Initial Game Offer rewards early investors who produce the best results.
One awesome game sold a piece of its plot for US$7.2 million! It's Axie Infinity. It's free and available on Google Play and Apple Store.
7. Affiliate Marketing
Affiliate marketing is a form of advertising where businesses pay others (like bloggers) to promote their goods and services. Here's an example. I write a blog (like this one) and post an affiliate link to an item I recommend buying — say, a camera — and if you buy the camera, I get a commission!
These programs pay well:
- Elementor
- AWeber
- Sendinblue
- ConvertKit\sLeadpages
- GetResponse
- SEMRush\sFiverr
- Pabbly
8. Start a blog
Now, if you're a writer or just really passionate about something or a niche, blogging could potentially monetize that passion!
Create a blog about anything you can think of. It's okay to start right here on Medium, as I did.
9. Dropshipping
And I mean that in the best possible way — drop shopping is ridiculously easy to set up, but difficult to maintain for some.
Luckily, Shopify has made setting up an online store a breeze. Drop-shipping from Alibaba and DHGate is quite common. You've got a winner if you can find a local distributor willing to let you drop ship their product!
10. Set up an Online Course
If you have a skill and can articulate it, online education is for you.
Skillshare, Pluralsight, and Coursera have all made inroads in recent years, upskilling people with courses that YOU can create and earn from.
That's it for today! Please share if you liked this post. If not, well —

Glorin Santhosh
3 years ago
In his final days, Steve Jobs sent an email to himself. What It Said Was This
An email capturing Steve Jobs's philosophy.

Steve Jobs may have been the most inspired and driven entrepreneur.
He worked on projects because he wanted to leave a legacy.
Steve Jobs' final email to himself encapsulated his philosophy.
After his death from pancreatic cancer in October 2011, Laurene Powell Jobs released the email. He was 56.
Read: Steve Jobs by Walter Isaacson (#BestSeller)
The Email:
September 2010 Steve Jobs email:
“I grow little of the food I eat, and of the little I do grow, I do not breed or perfect the seeds.” “I do not make my own clothing. I speak a language I did not invent or refine,” he continued. “I did not discover the mathematics I use… I am moved by music I did not create myself.”
Jobs ended his email by reflecting on how others created everything he uses.
He wrote:
“When I needed medical attention, I was helpless to help myself survive.”

The Apple co-founder concluded by praising humanity.
“I did not invent the transistor, the microprocessor, object-oriented programming, or most of the technology I work with. I love and admire my species, living and dead, and am totally dependent on them for my life and well-being,” he concluded.
The email was made public as a part of the Steve Jobs Archive, a website that was launched in tribute to his legacy.
Steve Jobs' widow founded the internet archive. Apple CEO Tim Cook and former design leader Jony Ive were prominent guests.
Steve Jobs has always inspired because he shows how even the best can be improved.
High expectations were always there, and they were consistently met.
We miss him because he was one of the few with lifelong enthusiasm and persona.

Laura Sanders
3 years ago
Xenobots, tiny living machines, can duplicate themselves.
Strange and complex behavior of frog cell blobs
A xenobot “parent,” shaped like a hungry Pac-Man (shown in red false color), created an “offspring” xenobot (green sphere) by gathering loose frog cells in its opening.
Tiny “living machines” made of frog cells can make copies of themselves. This newly discovered renewal mechanism may help create self-renewing biological machines.
According to Kirstin Petersen, an electrical and computer engineer at Cornell University who studies groups of robots, “this is an extremely exciting breakthrough.” She says self-replicating robots are a big step toward human-free systems.
Researchers described the behavior of xenobots earlier this year (SN: 3/31/21). Small clumps of skin stem cells from frog embryos knitted themselves into small spheres and started moving. Cilia, or cellular extensions, powered the xenobots around their lab dishes.
The findings are published in the Proceedings of the National Academy of Sciences on Dec. 7. The xenobots can gather loose frog cells into spheres, which then form xenobots.
The researchers call this type of movement-induced reproduction kinematic self-replication. The study's coauthor, Douglas Blackiston of Tufts University in Medford, Massachusetts, and Harvard University, says this is typical. For example, sexual reproduction requires parental sperm and egg cells. Sometimes cells split or budded off from a parent.
“This is unique,” Blackiston says. These xenobots “find loose parts in the environment and cobble them together.” This second generation of xenobots can move like their parents, Blackiston says.
The researchers discovered that spheroid xenobots could only produce one more generation before dying out. The original xenobots' shape was predicted by an artificial intelligence program, allowing for four generations of replication.
A C shape, like an openmouthed Pac-Man, was predicted to be a more efficient progenitor. When improved xenobots were let loose in a dish, they began scooping up loose cells into their gaping “mouths,” forming more sphere-shaped bots (see image below). As many as 50 cells clumped together in the opening of a parent to form a mobile offspring. A xenobot is made up of 4,000–6,000 frog cells.
Petersen likes the Xenobots' small size. “The fact that they were able to do this at such a small scale just makes it even better,” she says. Miniature xenobots could sculpt tissues for implantation or deliver therapeutics inside the body.
Beyond the xenobots' potential jobs, the research advances an important science, says study coauthor and Tufts developmental biologist Michael Levin. The science of anticipating and controlling the outcomes of complex systems, he says.
“No one could have predicted this,” Levin says. “They regularly surprise us.” Researchers can use xenobots to test the unexpected. “This is about advancing the science of being less surprised,” Levin says.