



More on Web3 & Crypto

Sam Bourgi
4 years ago
DAOs are legal entities in Marshall Islands.
The Pacific island state recognizes decentralized autonomous organizations.
The Republic of the Marshall Islands has recognized decentralized autonomous organizations (DAOs) as legal entities, giving collectively owned and managed blockchain projects global recognition.
The Marshall Islands' amended the Non-Profit Entities Act 2021 that now recognizes DAOs, which are blockchain-based entities governed by self-organizing communities. Incorporating Admiralty LLC, the island country's first DAO, was made possible thanks to the amendement. MIDAO Directory Services Inc., a domestic organization established to assist DAOs in the Marshall Islands, assisted in the incorporation.
The new law currently allows any DAO to register and operate in the Marshall Islands.
“This is a unique moment to lead,” said Bobby Muller, former Marshall Islands chief secretary and co-founder of MIDAO. He believes DAOs will help create “more efficient and less hierarchical” organizations.
A global hub for DAOs, the Marshall Islands hopes to become a global hub for DAO registration, domicile, use cases, and mass adoption. He added:
"This includes low-cost incorporation, a supportive government with internationally recognized courts, and a technologically open environment."
According to the World Bank, the Marshall Islands is an independent island state in the Pacific Ocean near the Equator. To create a blockchain-based cryptocurrency that would be legal tender alongside the US dollar, the island state has been actively exploring use cases for digital assets since at least 2018.
In February 2018, the Marshall Islands approved the creation of a new cryptocurrency, Sovereign (SOV). As expected, the IMF has criticized the plan, citing concerns that a digital sovereign currency would jeopardize the state's financial stability. They have also criticized El Salvador, the first country to recognize Bitcoin (BTC) as legal tender.
Marshall Islands senator David Paul said the DAO legislation does not pose the same issues as a government-backed cryptocurrency. “A sovereign digital currency is financial and raises concerns about money laundering,” . This is more about giving DAOs legal recognition to make their case to regulators, investors, and consumers.

Max Parasol
4 years ago
Are DAOs the future or just a passing fad?
How do you DAO? Can DAOs scale?
DAO: Decentralized Autonomous. Organization.
“The whole phrase is a misnomer. They're not decentralized, autonomous, or organizations,” says Monsterplay blockchain consultant David Freuden.
As part of the DAO initiative, Freuden coauthored a 51-page report in May 2020. “We need DAOs,” he says. “‘Shareholder first' is a 1980s/90s concept. Profits became the focus, not products.”
His predictions for DAOs have come true nearly two years later. DAOs had over 1.6 million participants by the end of 2021, up from 13,000 at the start of the year. Wyoming, in the US, will recognize DAOs and the Marshall Islands in 2021. Australia may follow that example in 2022.
But what is a DAO?
Members buy (or are rewarded with) governance tokens to vote on how the DAO operates and spends its money. “DeFi spawned DAOs as an investment vehicle. So a DAO is tokenomics,” says Freuden.
DAOs are usually built around a promise or a social cause, but they still want to make money. “If you can't explain why, the DAO will fail,” he says. “A co-op without tokenomics is not a DAO.”
Operating system DAOs, protocol DAOs, investment DAOs, grant DAOs, service DAOs, social DAOs, collector DAOs, and media DAOs are now available.
Freuden liked the idea of people rallying around a good cause. Speculators and builders make up the crypto world, so it needs a DAO for them.
,Speculators and builders, or both, have mismatched expectations, causing endless, but sometimes creative friction.
Organisms that boost output
Launching a DAO with an original product such as a cryptocurrency, an IT protocol or a VC-like investment fund like FlamingoDAO is common. DAOs enable distributed open-source contributions without borders. The goal is vital. Sometimes, after a product is launched, DAOs emerge, leaving the company to eventually transition to a DAO, as Uniswap did.
Doing things together is a DAO. So it's a way to reward a distributed workforce. DAOs are essentially productivity coordination organisms.
“Those who work for the DAO make permissionless contributions and benefit from fragmented employment,” argues Freuden. DAOs are, first and foremost, a new form of cooperation.
DAO? Distributed not decentralized
In decentralized autonomous organizations, words have multiple meanings. DAOs can emphasize one aspect over another. Autonomy is a trade-off for decentralization.
DAOstack CEO Matan Field says a DAO is a distributed governance system. Power is shared. However, there are two ways to understand a DAO's decentralized nature. This clarifies the various DAO definitions.
A decentralized infrastructure allows a DAO to be decentralized. It could be created on a public permissionless blockchain to prevent a takeover.
As opposed to a company run by executives or shareholders, a DAO is distributed. Its leadership does not wield power
Option two is clearly distributed.
But not all of this is “automated.”
Think quorum, not robot.
DAOs can be autonomous in the sense that smart contracts are self-enforcing and self-executing. So every blockchain transaction is a simplified smart contract.
Dao landscape
The DAO landscape is evolving.
Consider how Ethereum's smart contracts work. They are more like self-executing computer code, which Vitalik Buterin calls “persistent scripts”.
However, a DAO is self-enforcing once its members agree on its rules. As such, a DAO is “automated upon approval by the governance committee.” This distinguishes them from traditional organizations whose rules must be interpreted and applied.
Why a DAO? They move fast
A DAO can quickly adapt to local conditions as a governance mechanism. It's a collaborative decision-making tool.
Like UkraineDAO, created in response to Putin's invasion of Ukraine by Ukrainian expat Alona Shevchenko, Nadya Tolokonnikova, Trippy Labs, and PleasrDAO. The DAO sought to support Ukrainian charities by selling Ukrainian flag NFTs. With a single mission, a DAO can quickly raise funds for a country accepting crypto where banks are distrusted.
This could be a watershed moment for DAOs.
ConstitutionDAO was another clever use case for DAOs for Freuden. In a failed but “beautiful experiment in a single-purpose DAO,” ConstitutionDAO tried to buy a copy of the US Constitution from a Sotheby's auction. In November 2021, ConstitutionDAO raised $47 million from 19,000 people, but a hedge fund manager outbid them.
Contributions were returned or lost if transactional gas fees were too high. The ConstitutionDAO, as a “beautiful experiment,” proved exceptionally fast at organizing and crowdsourcing funds for a specific purpose.
We may soon be applauding UkraineDAO's geopolitical success in support of the DAO concept.
Some of the best use cases for DAOs today, according to Adam Miller, founder of DAOplatform.io and MIDAO Directory Services, involve DAO structures.
That is, a “flat community is vital.” Prototyping by the crowd is a good example. To succeed, members must be enthusiastic about DAOs as an alternative to starting a company. Because DAOs require some hierarchy, he agrees that "distributed is a better acronym."
Miller sees DAOs as a “new way of organizing people and resources.” He started DAOplatform.io, a DAO tooling advisery that is currently transitioning to a DAO due to the “woeful tech options for running a DAO,” which he says mainly comprises of just “multisig admin keys and a voting system.” So today he's advising on DAO tech stacks.
Miller identifies three key elements.
Tokenization is a common method and tool. Second, governance mechanisms connected to the DAO's treasury. Lastly, community.”
How a DAO works...
They can be more than glorified Discord groups if they have a clear mission. This mission is a mix of financial speculation and utopianism. The spectrum is vast.
The founder of Dash left the cryptocurrency project in 2017. It's the story of a prophet without an heir. So creating a global tokenized evangelical missionary community via a DAO made sense.
Evan Duffield, a “libertarian/anarchist” visionary, forked Bitcoin in January 2014 to make it instant and essentially free. He went away for a while, and DASH became a DAO.
200,000 US retailers, including Walmart and Barnes & Noble, now accept Dash as payment. This payment system works like a gift card.
Arden Goldstein, Dash's head of crypto, DAO, and blockchain marketing, claims Dash is the “first successful DAO.” It was founded in 2016 and disbanded after a hack, an Ethereum hard fork and much controversy. But what are the success metrics?
Crypto success is measured differently, says Goldstein. To achieve common goals, people must participate or be motivated in a healthy DAO. People are motivated to complete tasks in a successful DAO. And, crucially, when tasks get completed.
“Yes or no, 1 or 0, voting is not a new idea. The challenge is getting people to continue to participate and keep building a community.” A DAO motivates volunteers: Nothing keeps people from building. The DAO “philosophy is old news. You need skin in the game to play.”
MasterNodes must stake 1000 Dash. Those members are rewarded with DASH for marketing (and other tasks). It uses an outsourced team to onboard new users globally.
Joining a DAO is part of the fun of meeting crazy or “very active” people on Discord. No one gets fired (usually). If your work is noticed, you may be offered a full-time job.
DAO community members worldwide are rewarded for brand building. Dash is also a great product for developing countries with high inflation and undemocratic governments. The countries with the most Dash DAO members are Russia, Brazil, Venezuela, India, China, France, Italy, and the Philippines.
Grassroots activism makes this DAO work. A DAO is local. Venezuelans can't access Dash.org, so DAO members help them use a VPN. DAO members are investors, fervent evangelicals, and local product experts.
Every month, proposals and grant applications are voted on via the Dash platform. However, the DAO may decide not to fund you. For example, the DAO once hired a PR firm, but the community complained about the lack of press coverage. This raises a great question: How are real-world contractual obligations met by a DAO?
Does the DASH DAO work?
“I see the DAO defund projects I thought were valuable,” Goldstein says. Despite working full-time, I must submit a funding proposal. “Much faster than other companies I've worked on,” he says.
Dash DAO is a headless beast. Ryan Taylor is the CEO of the company overseeing the DASH Core Group project.
The issue is that “we don't know who has the most tokens [...] because we don't know who our customers are.” As a result, “the loudest voices usually don't have the most MasterNodes and aren't the most invested.”
Goldstein, the only female in the DAO, says she worked hard. “I was proud of the DAO when I made the logo pink for a day and got great support from the men.” This has yet to entice a major influx of female DAO members.
Many obstacles stand in the way of utopian dreams.
Governance problems remain
And what about major token holders behaving badly?
In early February, a heated crypto Twitter debate raged on about inclusion, diversity, and cancel culture in relation to decentralized projects. In this case, the question was how a DAO addresses alleged inappropriate behavior.
In a corporation, misconduct can result in termination. In a DAO, founders usually hold a large number of tokens and the keys to the blockchain (multisignature) or otherwise.
Brantly Millegan, the director of operations of Ethereum Name Service (ENS), made disparaging remarks about the LGBTQ community and other controversial topics. The screenshotted comments were made in 2016 and brought to the ENS board's attention in early 2022.
His contract with ENS has expired. But what of his large DAO governance token holdings?
Members of the DAO proposed a motion to remove Millegan from the DAO. His “delegated” votes net 370,000. He was and is the DAO's largest delegate.
What if he had refused to accept the DAO's decision?
Freuden says the answer is not so simple.
“Can a DAO kick someone out who built the project?”
The original mission “should be dissolved” if it no longer exists. “Does a DAO fail and return the money? They must r eturn the money with interest if the marriage fails.”
Before an IPO, VCs might try to remove a problematic CEO.
While DAOs use treasury as a governance mechanism, it is usually controlled (at least initially) by the original project creators. Or, in the case of Uniswap, the venture capital firm a16z has so much voting power that it has delegated it to student-run blockchain organizations.
So, can DAOs really work at scale? How to evolve voting paradigms beyond token holdings?
The whale token holder issue has some solutions. Multiple tokens, such as a utility token on top of a governance token, and quadratic voting for whales, are now common. Other safeguards include multisignature blockchain keys and decision time locks that allow for any automated decision to be made. The structure of each DAO will depend on the assets at stake.
In reality, voter turnout is often a bigger issue.
Is DAO governance scalable?
Many DAOs have low participation. Due to a lack of understanding of technology, apathy, or busy lives. “The bigger the DAO, the fewer voters who vote,” says Freuden.
Freuden's report cites British anthropologist Dunbar's Law, who argued that people can only maintain about 150 relationships.
"As the DAO grows in size, the individual loses influence because they perceive their voting power as being diminished or insignificant. The Ringelmann Effect and Dunbar's Rule show that as a group grows in size, members become lazier, disenfranchised, and detached.
Freuden says a DAO requires “understanding human relationships.” He believes DAOs work best as investment funds rooted in Cryptoland and small in scale. In just three weeks, SyndicateDAO enabled the creation of 450 new investment group DAOs.
Due to SEC regulations, FlamingoDAO, a famous NFT curation investment DAO, could only have 100 investors. The “LAO” is a member-directed venture capital fund and a US LLC. To comply with US securities law, they only allow 100 members with a 120ETH minimum staking contribution.
But how did FlamingoDAO make investment decisions? How often did all 70 members vote? Art and NFTs are highly speculative.
So, investment DAOs are thought to work well in a small petri dish environment. This is due to a crypto-native club's pooled capital (maximum 7% per member) and crowdsourced knowledge.
While scalability is a concern, each DAO will operate differently depending on the goal, technology stage, and personalities. Meetups and hackathons are common ways for techies to collaborate on a cause or test an idea. But somebody still organizes the hack.
Holographic consensus voting
But clever people are working on creative solutions to every problem.
Miller of DAOplatform.io cites DXdao as a successful DAO. Decentralized product and service creator DXdao runs the DAO entirely on-chain. “You earn voting rights by contributing to the community.”
DXdao, a DAOstack fork, uses holographic consensus, a voting algorithm invented by DAOstack founder Matan Field. The system lets a random or semi-random subset make group-wide decisions.
By acting as a gatekeeper for voters, DXdao's Luke Keenan explains that “a small predictions market economy emerges around the likely outcome of a proposal as tokens are staked on it.” Also, proposals that have been financially boosted have fewer requirements to be successful, increasing system efficiency.” DXdao “makes decisions by removing voting power as an economic incentive.”
Field explains that holographic consensus “does not require a quorum to render a vote valid.”
“Rather, it provides a parallel process. It is a game played (for profit) by ‘predictors' who make predictions about whether or not a vote will be approved by the voters. The voting process is valid even when the voting quorum is low if enough stake is placed on the outcome of the vote.
“In other words, a quorum is not a scalable DAO governance strategy,” Field says.
You don't need big votes on everything. If only 5% vote, fine. To move significant value or make significant changes, you need a longer voting period (say 30 days) and a higher quorum,” says Miller.
Clearly, DAOs are maturing. The emphasis is on tools like Orca and processes that delegate power to smaller sub-DAOs, committees, and working groups.
Miller also claims that “studies in psychology show that rewarding people too much for volunteering disincentivizes them.” So, rather than giving out tokens for every activity, you may want to offer symbolic rewards like POAPs or contributor levels.
“Free lunches are less rewarding. Random rewards can boost motivation.”
Culture and motivation
DAOs (and Web3 in general) can give early adopters a sense of ownership. In theory, they encourage early participation and bootstrapping before network effects.
"A double-edged sword," says Goldstein. In the developing world, they may not be fully scalable.
“There must always be a leader,” she says. “People won't volunteer if they don't want to.”
DAO members sometimes feel entitled. “They are not the boss, but they think they should be able to see my calendar or get a daily report,” Goldstein gripes. Say, “I own three MasterNodes and need to know X, Y, and Z.”
In most decentralized projects, strong community leaders are crucial to influencing culture.
Freuden says “the DAO's community builder is the cryptoland influencer.” They must “disseminate the DAO's culture, cause, and rally the troops” in English, not tech.
They must keep members happy.
So the community builder is vital. Building a community around a coin that promises riches is simple, but keeping DAO members motivated is difficult.
It's a human job. But tools like SourceCred or coordinate that measure contributions and allocate tokens are heavily marketed. Large growth funds/community funds/grant programs are common among DAOs.
The Future?
Onboarding, committed volunteers, and an iconic community builder may be all DAOs need.
It takes a DAO just one day to bring together a passionate (and sometimes obsessive) community. For organizations with a common goal, managing stakeholder expectations is critical.
A DAO's core values are community and cause, not scalable governance. “DAOs will work at scale like gaming communities, but we will have sub-DAOs everywhere like committees,” says Freuden.
So-called holographic consensuses “can handle, in principle, increasing rates of proposals by turning this tension between scale and resilience into an economical cost,” Field writes. Scalability is not guaranteed.
The DAO's key innovation is the fragmented workplace. “Voting is a subset of engagement,” says Freuden. DAO should allow for permissionless participation and engagement. DAOs allow for remote work.”
In 20 years, DAOs may be the AI-powered self-organizing concept. That seems far away now. But a new breed of productivity coordination organisms is maturing.

ANDREW SINGER
4 years ago
Crypto seen as the ‘future of money’ in inflation-mired countries
Crypto as the ‘future of money' in inflation-stricken nations
Citizens of devalued currencies “need” crypto. “Nice to have” in the developed world.
According to Gemini's 2022 Global State of Crypto report, cryptocurrencies “evolved from what many considered a niche investment into an established asset class” last year.
More than half of crypto owners in Brazil (51%), Hong Kong (51%), and India (54%), according to the report, bought cryptocurrency for the first time in 2021.
The study found that inflation and currency devaluation are powerful drivers of crypto adoption, especially in emerging market (EM) countries:
“Respondents in countries that have seen a 50% or greater devaluation of their currency against the USD over the last decade were more than 5 times as likely to plan to purchase crypto in the coming year.”
Between 2011 and 2021, the real lost 218 percent of its value against the dollar, and 45 percent of Brazilians surveyed by Gemini said they planned to buy crypto in 2019.
The rand (South Africa's currency) has fallen 103 percent in value over the last decade, second only to the Brazilian real, and 32 percent of South Africans expect to own crypto in the coming year. Mexico and India, the third and fourth highest devaluation countries, followed suit.
Compared to the US dollar, Hong Kong and the UK currencies have not devalued in the last decade. Meanwhile, only 5% and 8% of those surveyed in those countries expressed interest in buying crypto.
What can be concluded? Noah Perlman, COO of Gemini, sees various crypto use cases depending on one's location.
‘Need to have' investment in countries where the local currency has devalued against the dollar, whereas in the developed world it is still seen as a ‘nice to have'.
Crypto as money substitute
As an adjunct professor at New York University School of Law, Winston Ma distinguishes between an asset used as an inflation hedge and one used as a currency replacement.
Unlike gold, he believes Bitcoin (BTC) is not a “inflation hedge”. They acted more like growth stocks in 2022. “Bitcoin correlated more closely with the S&P 500 index — and Ether with the NASDAQ — than gold,” he told Cointelegraph. But in the developing world, things are different:
“Inflation may be a primary driver of cryptocurrency adoption in emerging markets like Brazil, India, and Mexico.”
According to Justin d'Anethan, institutional sales director at the Amber Group, a Singapore-based digital asset firm, early adoption was driven by countries where currency stability and/or access to proper banking services were issues. Simply put, he said, developing countries want alternatives to easily debased fiat currencies.
“The larger flows may still come from institutions and developed countries, but the actual users may come from places like Lebanon, Turkey, Venezuela, and Indonesia.”
“Inflation is one of the factors that has and continues to drive adoption of Bitcoin and other crypto assets globally,” said Sean Stein Smith, assistant professor of economics and business at Lehman College.
But it's only one factor, and different regions have different factors, says Stein Smith. As a “instantaneously accessible, traceable, and cost-effective transaction option,” investors and entrepreneurs increasingly recognize the benefits of crypto assets. Other places promote crypto adoption due to “potential capital gains and returns”.
According to the report, “legal uncertainty around cryptocurrency,” tax questions, and a general education deficit could hinder adoption in Asia Pacific and Latin America. In Africa, 56% of respondents said more educational resources were needed to explain cryptocurrencies.
Not only inflation, but empowering our youth to live better than their parents without fear of failure or allegiance to legacy financial markets or products, said Monica Singer, ConsenSys South Africa lead. Also, “the issue of cash and remittances is huge in Africa, as is the issue of social grants.”
Money's future?
The survey found that Brazil and Indonesia had the most cryptocurrency ownership. In each country, 41% of those polled said they owned crypto. Only 20% of Americans surveyed said they owned cryptocurrency.
These markets are more likely to see cryptocurrencies as the future of money. The survey found:
“The majority of respondents in Latin America (59%) and Africa (58%) say crypto is the future of money.”
Brazil (66%), Nigeria (63%), Indonesia (61%), and South Africa (57%). Europe and Australia had the fewest believers, with Denmark at 12%, Norway at 15%, and Australia at 17%.
Will the Ukraine conflict impact adoption?
The poll was taken before the war. Will the devastating conflict slow global crypto adoption growth?
With over $100 million in crypto donations directly requested by the Ukrainian government since the war began, Stein Smith says the war has certainly brought crypto into the mainstream conversation.
“This real-world demonstration of decentralized money's power could spur wider adoption, policy debate, and increased use of crypto as a medium of exchange.”
But the war may not affect all developing nations. “The Ukraine war has no impact on African demand for crypto,” Others loom larger. “Yes, inflation, but also a lack of trust in government in many African countries, and a young demographic very familiar with mobile phones and the internet.”
A major success story like Mpesa in Kenya has influenced the continent and may help accelerate crypto adoption. Creating a plan when everyone you trust fails you is directly related to the African spirit, she said.
On the other hand, Ma views the Ukraine conflict as a sort of crisis check for cryptocurrencies. For those in emerging markets, the Ukraine-Russia war has served as a “stress test” for the cryptocurrency payment rail, he told Cointelegraph.
“These emerging markets may see the greatest future gains in crypto adoption.”
Inflation and currency devaluation are persistent global concerns. In such places, Bitcoin and other cryptocurrencies are now seen as the “future of money.” Not in the developed world, but that could change with better regulation and education. Inflation and its impact on cash holdings are waking up even Western nations.
Read original post here.
You might also like

Andy Raskin
3 years ago
I've Never Seen a Sales Deck This Good

It’s Zuora’s, and it’s brilliant. Here’s why.
My friend Tim got a sales position at a Series-C software company that garnered $60 million from A-list investors. He's one of the best salespeople I know, yet he emailed me after starting to struggle.
Tim has a few modest clients. “Big companies ignore my pitch”. Tim said.
I love helping teams write the strategic story that drives sales, marketing, and fundraising. Tim and I had lunch at Amber India on Market Street to evaluate his deck.
After a feast, I asked Tim when prospects tune out.
He said, “several slides in”.
Intent on maximizing dining ROI, Tim went back to the buffet for seconds. When he returned, I pulled out my laptop and launched into a Powerpoint presentation.
“What’s this?” Tim asked.
“This,” I said, “is the greatest sales deck I have ever seen.”
Five Essentials of a Great Sales Narrative
I showed Tim a sales slide from IPO-bound Zuora, which sells a SaaS platform for subscription billing. Zuora supports recurring payments (e.g. enterprise software).
Ex-Zuora salesman gave me the deck, saying it helped him close his largest business. (I don't know anyone who works at Zuora.) After reading this, a few Zuora employees contacted me.)
Tim abandoned his naan in a pool of goat curry and took notes while we discussed the Zuora deck.
We remarked how well the deck led prospects through five elements:
(The ex-Zuora salesperson begged me not to release the Zuora deck publicly.) All of the images below originate from Zuora's website and SlideShare channel.)
#1. Name a Significant Change in the World
Don't start a sales presentation with mentioning your product, headquarters, investors, clients, or yourself.
Name the world shift that raises enormous stakes and urgency for your prospect.
Every Zuora sales deck begins with this slide:

Zuora coined the term subscription economy to describe a new market where purchasers prefer regular service payments over outright purchases. Zuora then shows a slide with the change's history.

Most pitch recommendation advises starting with the problem. When you claim a problem, you put prospects on the defensive. They may be unaware of or uncomfortable admitting the situation.
When you highlight a global trend, prospects open up about how it affects them, worries them, and where they see opportunity. You capture their interest. Robert McKee says:
…what attracts human attention is change. …if the temperature around you changes, if the phone rings — that gets your attention. The way in which a story begins is a starting event that creates a moment of change.
#2. Show There’ll Be Winners and Losers
Loss aversion affects all prospects. They avoid a loss by sticking with the status quo rather than risking a gain by changing.
To fight loss aversion, show how the change will create winners and losers. You must show both
that if the prospect can adjust to the modification you mentioned, the outcome will probably be quite favorable; and
That failing to do so is likely to have an unacceptable negative impact on the prospect's future
Zuora shows a mass extinction among Fortune 500 firms.

…and then showing how the “winners” have shifted from product ownership to subscription services. Those include upstarts…

…as well as rejuvenated incumbents:

To illustrate, Zuora asks:

Winners utilize Zuora's subscription service models.
#3. Tease the Promised Land
It's tempting to get into product or service details now. Resist that urge.
Prospects won't understand why product/service details are crucial if you introduce them too soon, therefore they'll tune out.
Instead, providing a teaser image of the happily-ever-after your product/service will assist the prospect reach.
Your Promised Land should be appealing and hard to achieve without support. Otherwise, why does your company exist?
Zuora shows this Promised Land slide after explaining that the subscription economy will have winners and losers.

Not your product or service, but a new future state.
(I asked my friend Tim to describe his Promised Land, and he answered, "You’ll have the most innovative platform for ____." Nope: the Promised Land isn't possessing your technology, but living with it.)
Your Promised Land helps prospects market your solution to coworkers after your sales meeting. Your coworkers will wonder what you do without you. Your prospects are more likely to provide a persuasive answer with a captivating Promised Land.
#4. Present Features as “Mystic Gifts” for Overcoming Difficulties on the Road to the Promised Land
Successful sales decks follow the same format as epic films and fairy tales. Obi Wan gives Luke a lightsaber to help him destroy the Empire. You're Gandalf, helping Frodo destroy the ring. Your prospect is Cinderella, and you're her fairy godmother.
Position your product or service's skills as mystical gifts to aid your main character (prospect) achieve the Promised Land.

Zuora's client record slide is shown above. Without context, even the most technical prospect would be bored.
Positioned in the context of shifting from an “old” to a “new world”, it's the foundation for a compelling conversation with prospects—technical and otherwise—about why traditional solutions can't reach the Promised Land.
#5. Show Proof That You Can Make the Story True.
In this sense, you're promising possibilities that if they follow you, they'll reach the Promised Land.
The journey to the Promised Land is by definition rocky, so prospects are right to be cautious. The final part of the pitch is proof that you can make the story come true.
The most convincing proof is a success story about how you assisted someone comparable to the prospect. Zuora's sales people use a deck of customer success stories, but this one gets the essence.

I particularly appreciate this one from an NCR exec (a Zuora customer), which relates more strongly to Zuora's Promised Land:

Not enough successful customers? Product demos are the next best evidence, but features should always be presented in the context of helping a prospect achieve the Promised Land.
The best sales narrative is one that is told by everyone.
Success rarely comes from a fantastic deck alone. To be effective, salespeople need an organization-wide story about change, Promised Land, and Magic Gifts.
Zuora exemplifies this. If you hear a Zuora executive, including CEO Tien Tzuo, talk, you'll likely hear about the subscription economy and its winners and losers. This is the theme of the company's marketing communications, campaigns, and vision statement.

According to the ex-Zuora salesperson, company-wide story alignment made him successful.
The Zuora marketing folks ran campaigns and branding around this shift to the subscription economy, and [CEO] Tien [Tzuo] talked it up all the time. All of that was like air cover for my in-person sales ground attack. By the time I arrived, prospects were already convinced they had to act. It was the closest thing I’ve ever experienced to sales nirvana.
The largest deal ever
Tim contacted me three weeks after our lunch to tell me that prospects at large organizations were responding well to his new deck, which we modeled on Zuora's framework. First, prospects revealed their obstacles more quickly. The new pitch engages CFOs and other top gatekeepers better, he said.
A week later, Tim emailed that he'd signed his company's biggest agreement.
Next week, we’re headed back to Amber India to celebrate.

Farhad Malik
3 years ago
How This Python Script Makes Me Money Every Day
Starting a passive income stream with data science and programming
My website is fresh. But how do I monetize it?
Creating a passive-income website is difficult. Advertise first. But what useful are ads without traffic?
Let’s Generate Traffic And Put Our Programming Skills To Use
SEO boosts traffic (Search Engine Optimisation). Traffic generation is complex. Keywords matter more than text, URL, photos, etc.
My Python skills helped here. I wanted to find relevant, Google-trending keywords (tags) for my topic.
First The Code
I wrote the script below here.
import re
from string import punctuation
import nltk
from nltk import TreebankWordTokenizer, sent_tokenize
from nltk.corpus import stopwords
class KeywordsGenerator:
def __init__(self, pytrends):
self._pytrends = pytrends
def generate_tags(self, file_path, top_words=30):
file_text = self._get_file_contents(file_path)
clean_text = self._remove_noise(file_text)
top_words = self._get_top_words(clean_text, top_words)
suggestions = []
for top_word in top_words:
suggestions.extend(self.get_suggestions(top_word))
suggestions.extend(top_words)
tags = self._clean_tokens(suggestions)
return ",".join(list(set(tags)))
def _remove_noise(self, text):
#1. Convert Text To Lowercase and remove numbers
lower_case_text = str.lower(text)
just_text = re.sub(r'\d+', '', lower_case_text)
#2. Tokenise Paragraphs To words
list = sent_tokenize(just_text)
tokenizer = TreebankWordTokenizer()
tokens = tokenizer.tokenize(just_text)
#3. Clean text
clean = self._clean_tokens(tokens)
return clean
def _clean_tokens(self, tokens):
clean_words = [w for w in tokens if w not in punctuation]
stopwords_to_remove = stopwords.words('english')
clean = [w for w in clean_words if w not in stopwords_to_remove and not w.isnumeric()]
return clean
def get_suggestions(self, keyword):
print(f'Searching pytrends for {keyword}')
result = []
self._pytrends.build_payload([keyword], cat=0, timeframe='today 12-m')
data = self._pytrends.related_queries()[keyword]['top']
if data is None or data.values is None:
return result
result.extend([x[0] for x in data.values.tolist()][:2])
return result
def _get_file_contents(self, file_path):
return open(file_path, "r", encoding='utf-8',errors='ignore').read()
def _get_top_words(self, words, top):
counts = dict()
for word in words:
if word in counts:
counts[word] += 1
else:
counts[word] = 1
return list({k: v for k, v in sorted(counts.items(), key=lambda item: item[1])}.keys())[:top]
if __name__ == "1__main__":
from pytrends.request import TrendReq
nltk.download('punkt')
nltk.download('stopwords')
pytrends = TrendReq(hl='en-GB', tz=360)
tags = KeywordsGenerator(pytrends)\
.generate_tags('text_file.txt')
print(tags)Then The Dependencies
This script requires:
nltk==3.7
pytrends==4.8.0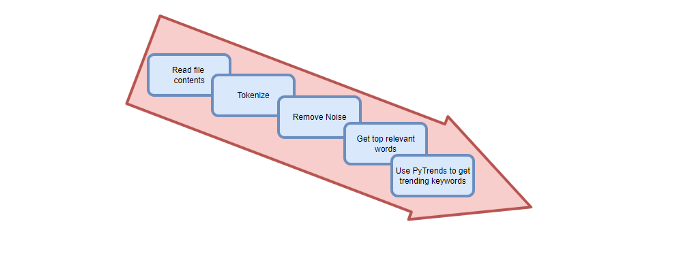
Analysis of the Script
I copy and paste my article into text file.txt, and the code returns the keywords as a comma-separated string.
To achieve this:
A class I made is called KeywordsGenerator.
This class has a function:
generate_tagsThe function
generate_tagsperforms the following tasks:
retrieves text file contents
uses NLP to clean the text by tokenizing sentences into words, removing punctuation, and other elements.
identifies the most frequent words that are relevant.
The
pytrendsAPI is then used to retrieve related phrases that are trending for each word from Google.finally adds a comma to the end of the word list.
4. I then use the keywords and paste them into the SEO area of my website.
These terms are trending on Google and relevant to my topic. My site's rankings and traffic have improved since I added new keywords. This little script puts our knowledge to work. I shared the script in case anyone faces similar issues.
I hope it helps readers sell their work.

MAJESTY AliNICOLE WOW!
3 years ago
YouTube's faceless videos are growing in popularity, but this is nothing new.
I've always bucked social media norms. YouTube doesn't compare. Traditional video made me zig when everyone zagged. Audio, picture personality animation, thought movies, and slide show videos are most popular and profitable.

YouTube's business is shifting. While most video experts swear by the idea that YouTube success is all about making personal and professional Face-Share-Videos, those who use YouTube for business know things are different.
In this article, I will share concepts from my mini master class Figures to Followers: Prioritizing Purposeful Profits Over Popularity on YouTube to Create the Win-Win for You, Your Audience & More and my forthcoming publication The WOWTUBE-PRENEUR FACTOR EVOLUTION: The Basics of Powerfully & Profitably Positioning Yourself as a Video Communications Authority to Broadcast Your WOW Effect as a Video Entrepreneur.
I've researched the psychology, anthropology, and anatomy of significant social media platforms as an entrepreneur and social media marketing expert. While building my YouTube empire, I've paid particular attention to what works for short, mid, and long-term success, whether it's a niche-focused, lifestyle, or multi-interest channel.
Most new, semi-new, and seasoned YouTubers feel vlog-style or live-on-camera videos are popular. Faceless, animated, music-text-based, and slideshow videos do well for businesses.
Buyer-consumer vs. content-consumer thinking is totally different when absorbing content. Profitability and popularity are closely related, however most people become popular with traditional means but not profitable.
In my experience, Faceless videos are more profitable, although it depends on the channel's style. Several professionals are now teaching in their courses that non-traditional films are making the difference in their business success and popularity.
Face-Share-Personal-Touch videos make audiences feel like they know the personality, but they're not profitable.
Most spend hours creating articles, videos, and thumbnails to seem good. That's how most YouTubers gained their success in the past, but not anymore.
Looking the part and performing a typical role in videos doesn't convert well, especially for newbie channels.
Working with video marketers and YouTubers for years, I've noticed that most struggle to be consistent with content publishing since they exclusively use formats that need extensive development. Camera and green screen set ups, shooting/filming, and editing for post productions require their time, making it less appealing to post consistently, especially if they're doing all the work themselves.
Because they won't make simple format videos or audio videos with an overlay image, they overcomplicate the procedure (even with YouTube Shorts), and they leave their channels for weeks or months. Again, they believe YouTube only allows specific types of videos. Even though this procedure isn't working, they plan to keep at it.

A successful YouTube channel needs multiple video formats to suit viewer needs, I teach. Face-Share-Personal Touch and Faceless videos are both useful.
How people engage with YouTube content has changed over the years, and the average customer is no longer interested in an all-video channel.
Face-Share-Personal-Touch videos are great
Google Live
Online training
Giving listeners a different way to access your podcast that is being broadcast on sites like Anchor, BlogTalkRadio, Spreaker, Google, Apple Store, and others Many people enjoy using a video camera to record themselves while performing the internet radio, Facebook, or Instagram Live versions of their podcasts.
Video Blog Updates
even more
Faceless videos are popular for business and benefit both entrepreneurs and audiences.
For the business owner/entrepreneur…
Less production time results in time dollar savings.
enables the business owner to demonstrate the diversity of content development
For the Audience…
The channel offers a variety of appealing content options.
The same format is not monotonous or overly repetitive for the viewers.
Below are a couple videos from YouTube guru Make Money Matt's channel, which has over 347K subscribers.
Enjoy
24 Best Niches to Make Money on YouTube Without Showing Your Face
Make Money on YouTube Without Making Videos (Free Course)
In conclusion, you have everything it takes to build your own YouTube brand and empire. Learn the rules, then adapt them to succeed.
Please reread this and the other suggested articles for optimal benefit.
I hope this helped. How has this article helped you? Follow me for more articles like this and more multi-mission expressions.