

:max_bytes(150000):strip_icc():gifv():format(webp)/reiff_headshot-5bfc2a60c9e77c00519a70bd.jpg)
Howey Test and Cryptocurrencies: 'Every ICO Is a Security'
What Is the Howey Test?
To determine whether a transaction qualifies as a "investment contract" and thus qualifies as a security, the Howey Test refers to the U.S. Supreme Court cass: the Securities Act of 1933 and the Securities Exchange Act of 1934. According to the Howey Test, an investment contract exists when "money is invested in a common enterprise with a reasonable expectation of profits from others' efforts."
The test applies to any contract, scheme, or transaction. The Howey Test helps investors and project backers understand blockchain and digital currency projects. ICOs and certain cryptocurrencies may be found to be "investment contracts" under the test.
Understanding the Howey Test
The Howey Test comes from the 1946 Supreme Court case SEC v. W.J. Howey Co. The Howey Company sold citrus groves to Florida buyers who leased them back to Howey. The company would maintain the groves and sell the fruit for the owners. Both parties benefited. Most buyers had no farming experience and were not required to farm the land.
The SEC intervened because Howey failed to register the transactions. The court ruled that the leaseback agreements were investment contracts.
This established four criteria for determining an investment contract. Investing contract:
- An investment of money
- n a common enterprise
- With the expectation of profit
- To be derived from the efforts of others
In the case of Howey, the buyers saw the transactions as valuable because others provided the labor and expertise. An income stream was obtained by only investing capital. As a result of the Howey Test, the transaction had to be registered with the SEC.
Howey Test and Cryptocurrencies
Bitcoin is notoriously difficult to categorize. Decentralized, they evade regulation in many ways. Regardless, the SEC is looking into digital assets and determining when their sale qualifies as an investment contract.
The SEC claims that selling digital assets meets the "investment of money" test because fiat money or other digital assets are being exchanged. Like the "common enterprise" test.
Whether a digital asset qualifies as an investment contract depends on whether there is a "expectation of profit from others' efforts."
For example, buyers of digital assets may be relying on others' efforts if they expect the project's backers to build and maintain the digital network, rather than a dispersed community of unaffiliated users. Also, if the project's backers create scarcity by burning tokens, the test is met. Another way the "efforts of others" test is met is if the project's backers continue to act in a managerial role.
These are just a few examples given by the SEC. If a project's success is dependent on ongoing support from backers, the buyer of the digital asset is likely relying on "others' efforts."
Special Considerations
If the SEC determines a cryptocurrency token is a security, many issues arise. It means the SEC can decide whether a token can be sold to US investors and forces the project to register.
In 2017, the SEC ruled that selling DAO tokens for Ether violated federal securities laws. Instead of enforcing securities laws, the SEC issued a warning to the cryptocurrency industry.
Due to the Howey Test, most ICOs today are likely inaccessible to US investors. After a year of ICOs, then-SEC Chair Jay Clayton declared them all securities.
SEC Chairman Gensler Agrees With Predecessor: 'Every ICO Is a Security'
Howey Test FAQs
How Do You Determine If Something Is a Security?
The Howey Test determines whether certain transactions are "investment contracts." Securities are transactions that qualify as "investment contracts" under the Securities Act of 1933 and the Securities Exchange Act of 1934.
The Howey Test looks for a "investment of money in a common enterprise with a reasonable expectation of profits from others' efforts." If so, the Securities Act of 1933 and the Securities Exchange Act of 1934 require disclosure and registration.
Why Is Bitcoin Not a Security?
Former SEC Chair Jay Clayton clarified in June 2018 that bitcoin is not a security: "Cryptocurrencies: Replace the dollar, euro, and yen with bitcoin. That type of currency is not a security," said Clayton.
Bitcoin, which has never sought public funding to develop its technology, fails the SEC's Howey Test. However, according to Clayton, ICO tokens are securities.
A Security Defined by the SEC
In the public and private markets, securities are fungible and tradeable financial instruments. The SEC regulates public securities sales.
The Supreme Court defined a security offering in SEC v. W.J. Howey Co. In its judgment, the court defines a security using four criteria:
- An investment contract's existence
- The formation of a common enterprise
- The issuer's profit promise
- Third-party promotion of the offering
Read original post.
More on Web3 & Crypto

Ajay Shrestha
3 years ago
Bitcoin's technical innovation: addressing the issue of the Byzantine generals
The 2008 Bitcoin white paper solves the classic computer science consensus problem.
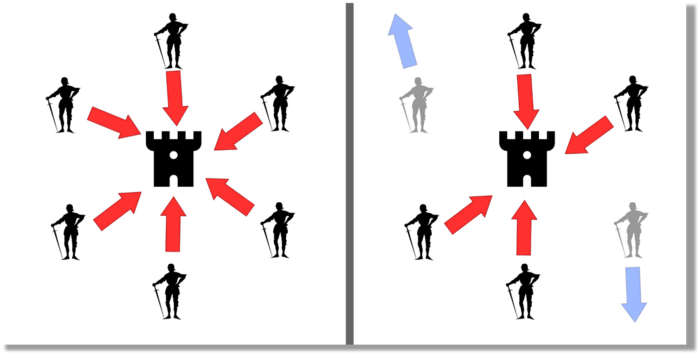
Issue Statement
The Byzantine Generals Problem (BGP) is called after an allegory in which several generals must collaborate and attack a city at the same time to win (figure 1-left). Any general who retreats at the last minute loses the fight (figure 1-right). Thus, precise messengers and no rogue generals are essential. This is difficult without a trusted central authority.
In their 1982 publication, Leslie Lamport, Robert Shostak, and Marshall Please termed this topic the Byzantine Generals Problem to simplify distributed computer systems.
Consensus in a distributed computer network is the issue. Reaching a consensus on which systems work (and stay in the network) and which don't makes maintaining a network tough (i.e., needs to be removed from network). Challenges include unreliable communication routes between systems and mis-reporting systems.
Solving BGP can let us construct machine learning solutions without single points of failure or trusted central entities. One server hosts model parameters while numerous workers train the model. This study describes fault-tolerant Distributed Byzantine Machine Learning.
Bitcoin invented a mechanism for a distributed network of nodes to agree on which transactions should go into the distributed ledger (blockchain) without a trusted central body. It solved BGP implementation. Satoshi Nakamoto, the pseudonymous bitcoin creator, solved the challenge by cleverly combining cryptography and consensus mechanisms.
Disclaimer
This is not financial advice. It discusses a unique computer science solution.
Bitcoin
Bitcoin's white paper begins:
“A purely peer-to-peer version of electronic cash would allow online payments to be sent directly from one party to another without going through a financial institution.” Source: https://www.ussc.gov/sites/default/files/pdf/training/annual-national-training-seminar/2018/Emerging_Tech_Bitcoin_Crypto.pdf
Bitcoin's main parts:
The open-source and versioned bitcoin software that governs how nodes, miners, and the bitcoin token operate.
The native kind of token, known as a bitcoin token, may be created by mining (up to 21 million can be created), and it can be transferred between wallet addresses in the bitcoin network.
Distributed Ledger, which contains exact copies of the database (or "blockchain") containing each transaction since the first one in January 2009.
distributed network of nodes (computers) running the distributed ledger replica together with the bitcoin software. They broadcast the transactions to other peer nodes after validating and accepting them.
Proof of work (PoW) is a cryptographic requirement that must be met in order for a miner to be granted permission to add a new block of transactions to the blockchain of the cryptocurrency bitcoin. It takes the form of a valid hash digest. In order to produce new blocks on average every 10 minutes, Bitcoin features a built-in difficulty adjustment function that modifies the valid hash requirement (length of nonce). PoW requires a lot of energy since it must continually generate new hashes at random until it satisfies the criteria.
The competing parties known as miners carry out continuous computing processing to address recurrent cryptography issues. Transaction fees and some freshly minted (mined) bitcoin are the rewards they receive. The amount of hashes produced each second—or hash rate—is a measure of mining capacity.
Cryptography, decentralization, and the proof-of-work consensus method are Bitcoin's most unique features.
Bitcoin uses encryption
Bitcoin employs this established cryptography.
Hashing
digital signatures based on asymmetric encryption
Hashing (SHA-256) (SHA-256)
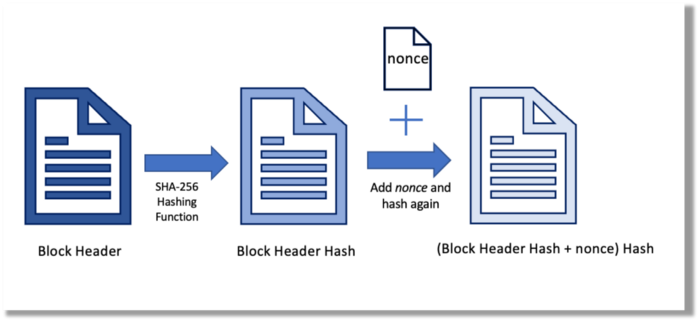
Hashing converts unique plaintext data into a digest. Creating the plaintext from the digest is impossible. Bitcoin miners generate new hashes using SHA-256 to win block rewards.
A new hash is created from the current block header and a variable value called nonce. To achieve the required hash, mining involves altering the nonce and re-hashing.
The block header contains the previous block hash and a Merkle root, which contains hashes of all transactions in the block. Thus, a chain of blocks with increasing hashes links back to the first block. Hashing protects new transactions and makes the bitcoin blockchain immutable. After a transaction block is mined, it becomes hard to fabricate even a little entry.
Asymmetric Cryptography Digital Signatures
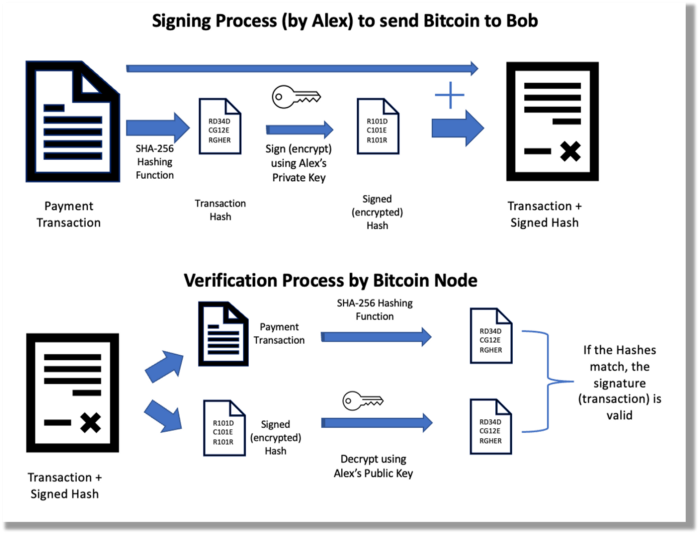
Asymmetric cryptography (public-key encryption) requires each side to have a secret and public key. Public keys (wallet addresses) can be shared with the transaction party, but private keys should not. A message (e.g., bitcoin payment record) can only be signed by the owner (sender) with the private key, but any node or anybody with access to the public key (visible in the blockchain) can verify it. Alex will submit a digitally signed transaction with a desired amount of bitcoin addressed to Bob's wallet to a node to send bitcoin to Bob. Alex alone has the secret keys to authorize that amount. Alex's blockchain public key allows anyone to verify the transaction.
Solution
Now, apply bitcoin to BGP. BGP generals resemble bitcoin nodes. The generals' consensus is like bitcoin nodes' blockchain block selection. Bitcoin software on all nodes can:
Check transactions (i.e., validate digital signatures)
2. Accept and propagate just the first miner to receive the valid hash and verify it accomplished the task. The only way to guess the proper hash is to brute force it by repeatedly producing one with the fixed/current block header and a fresh nonce value.
Thus, PoW and a dispersed network of nodes that accept blocks from miners that solve the unfalsifiable cryptographic challenge solve consensus.
Suppose:
Unreliable nodes
Unreliable miners
Bitcoin accepts the longest chain if rogue nodes cause divergence in accepted blocks. Thus, rogue nodes must outnumber honest nodes in accepting/forming the longer chain for invalid transactions to reach the blockchain. As of November 2022, 7000 coordinated rogue nodes are needed to takeover the bitcoin network.
Dishonest miners could also try to insert blocks with falsified transactions (double spend, reverse, censor, etc.) into the chain. This requires over 50% (51% attack) of miners (total computational power) to outguess the hash and attack the network. Mining hash rate exceeds 200 million (source). Rewards and transaction fees encourage miners to cooperate rather than attack. Quantum computers may become a threat.
Visit my Quantum Computing post.
Quantum computers—what are they? Quantum computers will have a big influence. towardsdatascience.com
Nodes have more power than miners since they can validate transactions and reject fake blocks. Thus, the network is secure if honest nodes are the majority.
Summary
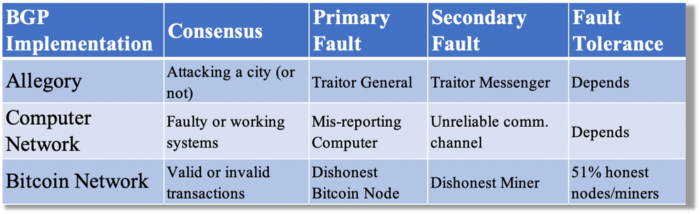
Table 1 compares three Byzantine Generals Problem implementations.
Bitcoin white paper and implementation solved the consensus challenge of distributed systems without central governance. It solved the illusive Byzantine Generals Problem.
Resources
Resources
Source-code for Bitcoin Core Software — https://github.com/bitcoin/bitcoin
Bitcoin white paper — https://bitcoin.org/bitcoin.pdf
https://www.microsoft.com/en-us/research/publication/byzantine-generals-problem/
https://www.microsoft.com/en-us/research/uploads/prod/2016/12/The-Byzantine-Generals-Problem.pdf
Genuinely Distributed Byzantine Machine Learning, El-Mahdi El-Mhamdi et al., 2020. ACM, New York, NY, https://doi.org/10.1145/3382734.3405695

rekt
4 years ago
LCX is the latest CEX to have suffered a private key exploit.
The attack began around 10:30 PM +UTC on January 8th.
Peckshield spotted it first, then an official announcement came shortly after.
We’ve said it before; if established companies holding millions of dollars of users’ funds can’t manage their own hot wallet security, what purpose do they serve?
The Unique Selling Proposition (USP) of centralised finance grows smaller by the day.
The official incident report states that 7.94M USD were stolen in total, and that deposits and withdrawals to the platform have been paused.
LCX hot wallet: 0x4631018f63d5e31680fb53c11c9e1b11f1503e6f
Hacker’s wallet: 0x165402279f2c081c54b00f0e08812f3fd4560a05
Stolen funds:
- 162.68 ETH (502,671 USD)
- 3,437,783.23 USDC (3,437,783 USD)
- 761,236.94 EURe (864,840 USD)
- 101,249.71 SAND Token (485,995 USD)
- 1,847.65 LINK (48,557 USD)
- 17,251,192.30 LCX Token (2,466,558 USD)
- 669.00 QNT (115,609 USD)
- 4,819.74 ENJ (10,890 USD)
- 4.76 MKR (9,885 USD)
**~$1M worth of $LCX remains in the address, along with 611k EURe which has been frozen by Monerium.
The rest, a total of 1891 ETH (~$6M) was sent to Tornado Cash.**
Why can’t they keep private keys private?
Is it really that difficult for a traditional corporate structure to maintain good practice?
CeFi hacks leave us with little to say - we can only go on what the team chooses to tell us.
Next time, they can write this article themselves.
See below for a template.

Caleb Naysmith
3 years ago Draft
A Myth: Decentralization
It’s simply not conceivable, or at least not credible.

One of the most touted selling points of Crypto has always been this grandiose idea of decentralization. Bitcoin first arose in 2009 after the housing crisis and subsequent crash that came with it. It aimed to solve this supposed issue of centralization. Nobody “owns” Bitcoin in theory, so the idea then goes that it won’t be subject to the same downfalls that led to the 2008 crash or similarly speculative events that led to the 2008 disaster. The issue is the banks, not the human nature associated with the greedy individuals running them.
Subsequent blockchains have attempted to fix many of the issues of Bitcoin by increasing capacity, decreasing the costs and processing times associated with Bitcoin, and expanding what can be done with their blockchains. Since nobody owns Bitcoin, it hasn’t really been able to be expanded on. You have people like Vitalk Buterin, however, that actively work on Ethereum though.
The leap from Bitcoin to Ethereum was a massive leap toward centralization, and the trend has only gotten worse. In fact, crypto has since become almost exclusively centralized in recent years.
Decentralization is only good in theory
It’s a good idea. In fact, it’s a wonderful idea. However, like other utopian societies, individuals misjudge human nature and greed. In a perfect world, decentralization would certainly be a wonderful idea because sure, people may function as their own banks, move payments immediately, remain anonymous, and so on. However, underneath this are a couple issues:
You can already send money instantaneously today.
They are not decentralized.
Decentralization is a bad idea.
Being your own bank is a stupid move.
Let’s break these down. Some are quite simple, but lets have a look.
Sending money right away
One thing with crypto is the idea that you can send payments instantly. This has pretty much been entirely solved in current times. You can transmit significant sums of money instantly for a nominal cost and it’s instantaneously cleared. Venmo was launched in 2009 and has since increased to prominence, and currently is on most people's phones. I can directly send ANY amount of money quickly from my bank to another person's Venmo account.
Comparing that with ETH and Bitcoin, Venmo wins all around. I can send money to someone for free instantly in dollars and the only fee paid is optional depending on when you want it.
Both Bitcoin and Ethereum are subject to demand. If the blockchains have a lot of people trying to process transactions fee’s go up, and the time that it takes to receive your crypto takes longer. When Ethereum gets bad, people have reported spending several thousand of dollars on just 1 transaction.
These transactions take place via “miners” bundling and confirming transactions, then recording them on the blockchain to confirm that the transaction did indeed happen. They charge fees to do this and are also paid in Bitcoin/ETH. When a transaction is confirmed, it's then sent to the other users wallet. This within itself is subject to lots of controversy because each transaction needs to be confirmed 6 times, this takes massive amounts of power, and most of the power is wasted because this is an adversarial system in which the person that mines the transaction gets paid, and everyone else is out of luck. Also, these could theoretically be subject to a “51% attack” in which anyone with over 51% of the mining hash rate could effectively control all of the transactions, and reverse transactions while keeping the BTC resulting in “double spending”.
There are tons of other issues with this, but essentially it means: They rely on these third parties to confirm the transactions. Without people confirming these transactions, Bitcoin stalls completely, and if anyone becomes too dominant they can effectively control bitcoin.
Not to mention, these transactions are in Bitcoin and ETH, not dollars. So, you need to convert them to dollars still, and that's several more transactions, and likely to take several days anyway as the centralized exchange needs to send you the money by traditional methods.
They are not distributed
That takes me to the following point. This isn’t decentralized, at all. Bitcoin is the closest it gets because Satoshi basically closed it to new upgrades, although its still subject to:
Whales
Miners
It’s vital to realize that these are often the same folks. While whales aren’t centralized entities typically, they can considerably effect the price and outcome of Bitcoin. If the largest wallets holding as much as 1 million BTC were to sell, it’d effectively collapse the price perhaps beyond repair. However, Bitcoin can and is pretty much controlled by the miners. Further, Bitcoin is more like an oligarchy than decentralized. It’s been effectively used to make the rich richer, and both the mining and price is impacted by the rich. The overwhelming minority of those actually using it are retail investors. The retail investors are basically never the ones generating money from it either.
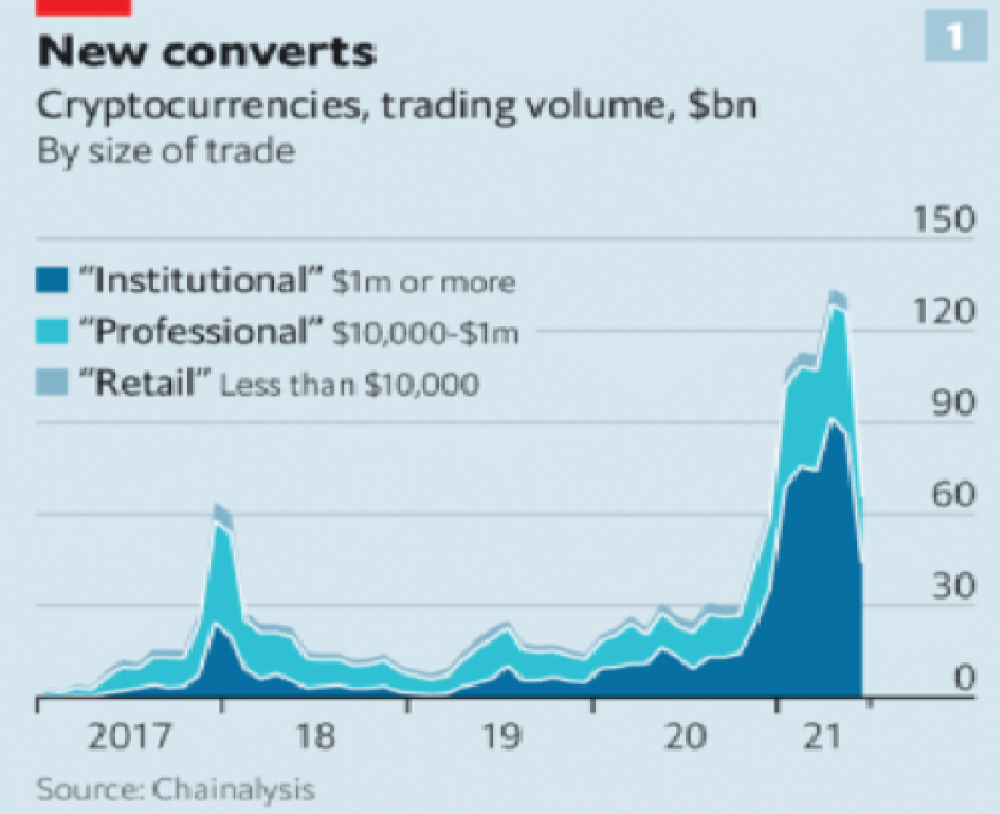
As far as ETH and other cryptos go, there is realistically 0 case for them being decentralized. Vitalik could not only kill it but even walking away from it would likely lead to a significant decline. It has tons of issues right now that Vitalik has promised to fix with the eventual Ethereum 2.0., and stepping away from it wouldn’t help.
Most tokens as well are generally tied to some promise of future developments and creators. The same is true for most NFT projects. The reason 99% of crypto and NFT projects fail is because they failed to deliver on various promises or bad dev teams, or poor innovation, or the founders just straight up stole from everyone. I could go more in-depth than this but go find any project and if there is a dev team, company, or person tied to it then it's likely, not decentralized. The success of that project is directly tied to the dev team, and if they wanted to, most hold large wallets and could sell it all off effectively killing the project. Not to mention, any crypto project that doesn’t have a locked contract can 100% be completely rugged and they can run off with all of the money.
Decentralization is undesirable
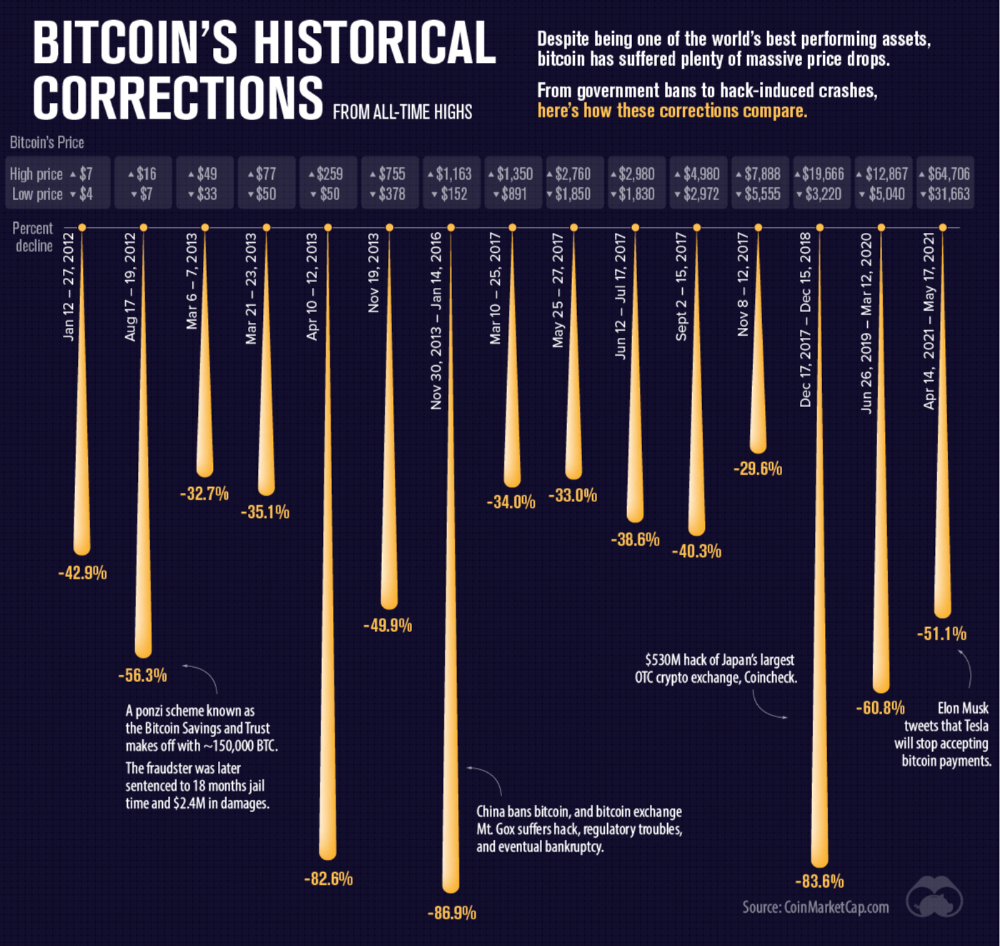
Even if they were decentralized then it would not be a good thing. The graphic above indicates this is effectively a rich person’s unregulated playground… so it’s exactly like… the very issue it tried to solve?
Not to mention, it’s supposedly meant to prevent things like 2008, but is regularly subjected to 50–90% drawdowns in value? Back when Bitcoin was only known in niche parts of the dark web and illegal markets, it would regularly drop as much as 90% and has a long history of massive drawdowns.
The majority of crypto is blatant scams, and ALL of crypto is a “zero” or “negative” sum game in that it relies on the next person buying for people to make money. This is not a good thing. This has yet to solve any issues around what caused the 2008 crisis. Rather, it seemingly amplified all of the bad parts of it actually. Crypto is the ultimate speculative asset and realistically has no valuation metric. People invest in Apple because it has revenue and cash on hand. People invest in crypto purely for speculation. The lack of regulation or accountability means this is amplified to the most extreme degree where anything goes: Fraud, deception, pump and dumps, scams, etc. This results in a pure speculative madhouse where, unsurprisingly, only the rich win. Not only that but the deck is massively stacked in against the everyday investor because you can’t do a pump and dump without money.
At the heart of all of this is still the same issues: greed and human nature. However, in setting out to solve the issues that allowed 2008 to happen, they made something that literally took all of the bad parts of 2008 and then amplified it. 2008, similarly, was due to greed and human nature but was allowed to happen due to lack of oversite, rich people's excessive leverage over the poor, and excessive speculation. Crypto trades SOLELY on human emotion, has 0 oversite, is pure speculation, and the power dynamic is just as bad or worse.
Why should each individual be their own bank?
This is the last one, and it's short and basic. Why do we want people functioning as their own bank? Everything we do relies on another person. Without the internet, and internet providers there is no crypto. We don’t have people functioning as their own home and car manufacturers or internet service providers. Sure, you might specialize in some of these things, but masquerading as your own bank is a horrible idea.
I am not in the banking industry so I don’t know all the issues with banking. Most people aren’t in banking or crypto, so they don’t know the ENDLESS scams associated with it, and they are bound to lose their money eventually.
If you appreciate this article and want to read more from me and authors like me, without any limits, consider buying me a coffee: buymeacoffee.com/calebnaysmith
You might also like

middlemarch.eth
4 years ago
ERC721R: A new ERC721 contract for random minting so people don’t snipe all the rares!
That is, how to snipe all the rares without using ERC721R!
Introduction: Blessed and Lucky
Mphers was the first mfers derivative, and as a Phunks derivative, I wanted one.
I wanted an alien. And there are only 8 in the 6,969 collection. I got one!
In case it wasn't clear from the tweet, I meant that I was lucky to have figured out how to 100% guarantee I'd get an alien without any extra luck.
Read on to find out how I did it, how you can too, and how developers can avoid it!
How to make rare NFTs without luck.
# How to mint rare NFTs without needing luck
The key to minting a rare NFT is knowing the token's id ahead of time.
For example, once I knew my alien was #4002, I simply refreshed the mint page until #3992 was minted, and then mint 10 mphers.
How did I know #4002 was extraterrestrial? Let's go back.
First, go to the mpher contract's Etherscan page and look up the tokenURI of a previously issued token, token #1:
As you can see, mphers creates metadata URIs by combining the token id and an IPFS hash.
This method gives you the collection's provenance in every URI, and while that URI can be changed, it affects everyone and is public.
Consider a token URI without a provenance hash, like https://mphers.art/api?tokenId=1.
As a collector, you couldn't be sure the devs weren't changing #1's metadata at will.
The API allows you to specify “if #4002 has not been minted, do not show any information about it”, whereas IPFS does not allow this.
It's possible to look up the metadata of any token, whether or not it's been minted.
Simply replace the trailing “1” with your desired id.
Mpher #4002
These files contain all the information about the mpher with the specified id. For my alien, we simply search all metadata files for the string “alien mpher.”
Take a look at the 6,969 meta-data files I'm using OpenSea's IPFS gateway, but you could use ipfs.io or something else.
Use curl to download ten files at once. Downloading thousands of files quickly can lead to duplicates or errors. But with a little tweaking, you should be able to get everything (and dupes are fine for our purposes).
Now that you have everything in one place, grep for aliens:
The numbers are the file names that contain “alien mpher” and thus the aliens' ids.
The entire process takes under ten minutes. This technique works on many NFTs currently minting.
In practice, manually minting at the right time to get the alien is difficult, especially when tokens mint quickly. Then write a bot to poll totalSupply() every second and submit the mint transaction at the exact right time.
You could even look for the token you need in the mempool before it is minted, and get your mint into the same block!
However, in my experience, the “big” approach wins 95% of the time—but not 100%.
“Am I being set up all along?”
Is a question you might ask yourself if you're new to this.
It's disheartening to think you had no chance of minting anything that someone else wanted.
But, did you have no opportunity? You had an equal chance as everyone else!
Take me, for instance: I figured this out using open-source tools and free public information. Anyone can do this, and not understanding how a contract works before minting will lead to much worse issues.
The mpher mint was fair.
While a fair game, “snipe the alien” may not have been everyone's cup of tea.
People may have had more fun playing the “mint lottery” where tokens were distributed at random and no one could gain an advantage over someone simply clicking the “mint” button.
How might we proceed?
Minting For Fashion Hats Punks, I wanted to create a random minting experience without sacrificing fairness. In my opinion, a predictable mint beats an unfair one. Above all, participants must be equal.
Sadly, the most common method of creating a random experience—the post-mint “reveal”—is deeply unfair. It works as follows:
- During the mint, token metadata is unavailable. Instead, tokenURI() returns a blank JSON file for each id.
- An IPFS hash is updated once all tokens are minted.
- You can't tell how the contract owner chose which token ids got which metadata, so it appears random.
Because they alone decide who gets what, the person setting the metadata clearly has a huge unfair advantage over the people minting. Unlike the mpher mint, you have no chance of winning here.
But what if it's a well-known, trusted, doxxed dev team? Are reveals okay here?
No! No one should be trusted with such power. Even if someone isn't consciously trying to cheat, they have unconscious biases. They might also make a mistake and not realize it until it's too late, for example.
You should also not trust yourself. Imagine doing a reveal, thinking you did it correctly (nothing is 100%! ), and getting the rarest NFT. Isn't that a tad odd Do you think you deserve it? An NFT developer like myself would hate to be in this situation.
Reveals are bad*
UNLESS they are done without trust, meaning everyone can verify their fairness without relying on the developers (which you should never do).
An on-chain reveal powered by randomness that is verifiably outside of anyone's control is the most common way to achieve a trustless reveal (e.g., through Chainlink).
Tubby Cats did an excellent job on this reveal, and I highly recommend their contract and launch reflections. Their reveal was also cool because it was progressive—you didn't have to wait until the end of the mint to find out.
In his post-launch reflections, @DefiLlama stated that he made the contract as trustless as possible, removing as much trust as possible from the team.
In my opinion, everyone should know the rules of the game and trust that they will not be changed mid-stream, while trust minimization is critical because smart contracts were designed to reduce trust (and it makes it impossible to hack even if the team is compromised). This was a huge mistake because it limited our flexibility and our ability to correct mistakes.
And @DefiLlama is a superstar developer. Imagine how much stress maximizing trustlessness will cause you!
That leaves me with a bad solution that works in 99 percent of cases and is much easier to implement: random token assignments.
Introducing ERC721R: A fully compliant IERC721 implementation that picks token ids at random.
ERC721R implements the opposite of a reveal: we mint token ids randomly and assign metadata deterministically.
This allows us to reveal all metadata prior to minting while reducing snipe chances.
Then import the contract and use this code:
What is ERC721R and how does it work
First, a disclaimer: ERC721R isn't truly random. In this sense, it creates the same “game” as the mpher situation, where minters compete to exploit the mint. However, ERC721R is a much more difficult game.
To game ERC721R, you need to be able to predict a hash value using these inputs:
This is impossible for a normal person because it requires knowledge of the block timestamp of your mint, which you do not have.
To do this, a miner must set the timestamp to a value in the future, and whatever they do is dependent on the previous block's hash, which expires in about ten seconds when the next block is mined.
This pseudo-randomness is “good enough,” but if big money is involved, it will be gamed. Of course, the system it replaces—predictable minting—can be manipulated.
The token id is chosen in a clever implementation of the Fisher–Yates shuffle algorithm that I copied from CryptoPhunksV2.
Consider first the naive solution: (a 10,000 item collection is assumed):
- Make an array with 0–9999.
- To create a token, pick a random item from the array and use that as the token's id.
- Remove that value from the array and shorten it by one so that every index corresponds to an available token id.
This works, but it uses too much gas because changing an array's length and storing a large array of non-zero values is expensive.
How do we avoid them both? What if we started with a cheap 10,000-zero array? Let's assign an id to each index in that array.
Assume we pick index #6500 at random—#6500 is our token id, and we replace the 0 with a 1.
But what if we chose #6500 again? A 1 would indicate #6500 was taken, but then what? We can't just "roll again" because gas will be unpredictable and high, especially later mints.
This allows us to pick a token id 100% of the time without having to keep a separate list. Here's how it works:
- Make a 10,000 0 array.
- Create a 10,000 uint numAvailableTokens.
- Pick a number between 0 and numAvailableTokens. -1
- Think of #6500—look at index #6500. If it's 0, the next token id is #6500. If not, the value at index #6500 is your next token id (weird!)
- Examine the array's last value, numAvailableTokens — 1. If it's 0, move the value at #6500 to the end of the array (#9999 if it's the first token). If the array's last value is not zero, update index #6500 to store it.
- numAvailableTokens is decreased by 1.
- Repeat 3–6 for the next token id.
So there you go! The array stays the same size, but we can choose an available id reliably. The Solidity code is as follows:
Unfortunately, this algorithm uses more gas than the leading sequential mint solution, ERC721A.
This is most noticeable when minting multiple tokens in one transaction—a 10 token mint on ERC721R costs 5x more than on ERC721A. That said, ERC721A has been optimized much further than ERC721R so there is probably room for improvement.
Conclusion
Listed below are your options:
- ERC721A: Minters pay lower gas but must spend time and energy devising and executing a competitive minting strategy or be comfortable with worse minting results.
- ERC721R: Higher gas, but the easy minting strategy of just clicking the button is optimal in all but the most extreme cases. If miners game ERC721R it’s the worst of both worlds: higher gas and a ton of work to compete.
- ERC721A + standard reveal: Low gas, but not verifiably fair. Please do not do this!
- ERC721A + trustless reveal: The best solution if done correctly, highly-challenging for dev, potential for difficult-to-correct errors.
Did I miss something? Comment or tweet me @dumbnamenumbers.
Check out the code on GitHub to learn more! Pull requests are welcome—I'm sure I've missed many gas-saving opportunities.
Thanks!
Read the original post here

Nicolas Tresegnie
3 years ago
Launching 10 SaaS applications in 100 days

Apocodes helps entrepreneurs create SaaS products without writing code. This post introduces micro-SaaS and outlines its basic strategy.
Strategy
Vision and strategy differ when starting a startup.
The company's long-term future state is outlined in the vision. It establishes the overarching objectives the organization aims to achieve while also justifying its existence. The company's future is outlined in the vision.
The strategy consists of a collection of short- to mid-term objectives, the accomplishment of which will move the business closer to its vision. The company gets there through its strategy.
The vision should be stable, but the strategy must be adjusted based on customer input, market conditions, or previous experiments.
Begin modestly and aim high.
Be truthful. It's impossible to automate SaaS product creation from scratch. It's like climbing Everest without running a 5K. Physical rules don't prohibit it, but it would be suicide.
Apocodes 5K equivalent? Two options:
(A) Create a feature that includes every setting option conceivable. then query potential clients “Would you choose us to build your SaaS solution if we offered 99 additional features of the same caliber?” After that, decide which major feature to implement next.
(B) Build a few straightforward features with just one or two configuration options. Then query potential clients “Will this suffice to make your product?” What's missing if not? Finally, tweak the final result a bit before starting over.
(A) is an all-or-nothing approach. It's like training your left arm to climb Mount Everest. My right foot is next.
(B) is a better method because it's iterative and provides value to customers throughout.
Focus on a small market sector, meet its needs, and expand gradually. Micro-SaaS is Apocode's first market.
What is micro-SaaS.
Micro-SaaS enterprises have these characteristics:
A limited range: They address a specific problem with a small number of features.
A small group of one to five individuals.
Low external funding: The majority of micro-SaaS companies have Total Addressable Markets (TAM) under $100 million. Investors find them unattractive as a result. As a result, the majority of micro-SaaS companies are self-funded or bootstrapped.
Low competition: Because they solve problems that larger firms would rather not spend time on, micro-SaaS enterprises have little rivalry.
Low upkeep: Because of their simplicity, they require little care.
Huge profitability: Because providing more clients incurs such a small incremental cost, high profit margins are possible.
Micro-SaaS enterprises created with no-code are Apocode's ideal first market niche.
We'll create our own micro-SaaS solutions to better understand their needs. Although not required, we believe this will improve community discussions.
The challenge
In 100 days (September 12–December 20, 2022), we plan to build 10 micro-SaaS enterprises using Apocode.
They will be:
Self-serve: Customers will be able to use the entire product experience without our manual assistance.
Real: They'll deal with actual issues. They won't be isolated proofs of concept because we'll keep up with them after the challenge.
Both free and paid options: including a free plan and a free trial period. Although financial success would be a good result, the challenge's stated objective is not financial success.
This will let us design Apocodes features, showcase them, and talk to customers.
(Edit: The first micro-SaaS was launched!)
Follow along
If you want to follow the story of Apocode or our progress in this challenge, you can subscribe here.
If you are interested in using Apocode, sign up here.
If you want to provide feedback, discuss the idea further or get involved, email me at nicolas.tresegnie@gmail.com

Nik Nicholas
4 years ago
A simple go-to-market formula

“Poor distribution, not poor goods, is the main reason for failure” — Peter Thiel.
Here's an easy way to conceptualize "go-to-market" for your distribution plan.
One equation captures the concept:
Distribution = Ecosystem Participants + Incentives
Draw your customers' ecosystem. Set aside your goods and consider your consumer's environment. Who do they deal with daily?
First, list each participant. You want an exhaustive list, but here are some broad categories.
In-person media services
Websites
Events\Networks
Financial education and banking
Shops
Staff
Advertisers
Twitter influencers
Draw influence arrows. Who's affected? I'm not just talking about Instagram selfie-posters. Who has access to your consumer and could promote your product if motivated?
The thicker the arrow, the stronger the relationship. Include more "influencers" if needed. Customer ecosystems are complex.
3. Incentivize ecosystem players. “Show me the incentive and I will show you the result.“, says Warren Buffet's business partner Charlie Munger.
Strong distribution strategies encourage others to promote your product to your target market by incentivizing the most prominent players. Incentives can be financial or non-financial.
Financial rewards
Usually, there's money. If you pay Facebook, they'll run your ad. Salespeople close deals for commission. Giving customers bonus credits will encourage referrals.
Most businesses underuse non-financial incentives.
Non-cash incentives
Motivate key influencers without spending money to expand quickly and cheaply. What can you give a client-connector for free?
Here are some ideas:
Are there any other features or services available?
Titles or status? Tinder paid college "ambassadors" for parties to promote its dating service.
Can I get early/free access? Facebook gave a select group of developers "exclusive" early access to their AR platform.
Are you a good host? Pharell performed at YPlan's New York launch party.
Distribution? Apple's iPod earphones are white so others can see them.
Have an interesting story? PR rewards journalists by giving them a compelling story to boost page views.
Prioritize distribution.
More time spent on distribution means more room in your product design and business plan. Once you've identified the key players in your customer's ecosystem, talk to them.
Money isn't your only resource. Creative non-monetary incentives may be more effective and scalable. Give people something useful and easy to deliver.