



More on Entrepreneurship/Creators

Jared Heyman
3 years ago
The survival and demise of Y Combinator startups
I've written a lot about Y Combinator's success, but as any startup founder or investor knows, many startups fail.
Rebel Fund invests in the top 5-10% of new Y Combinator startups each year, so we focus on identifying and supporting the most promising technology startups in our ecosystem. Given the power law dynamic and asymmetric risk/return profile of venture capital, we worry more about our successes than our failures. Since the latter still counts, this essay will focus on the proportion of YC startups that fail.
Since YC's launch in 2005, the figure below shows the percentage of active, inactive, and public/acquired YC startups by batch.
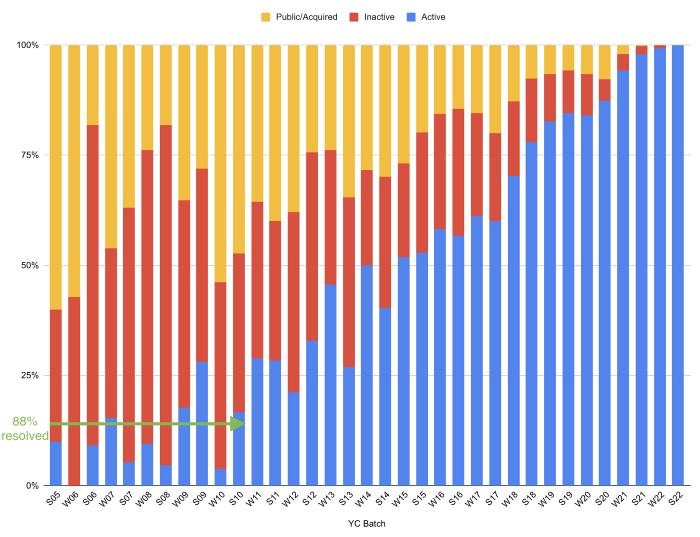
As more startups finish, the blue bars (active) decrease significantly. By 12 years, 88% of startups have closed or exited. Only 7% of startups reach resolution each year.
YC startups by status after 12 years:
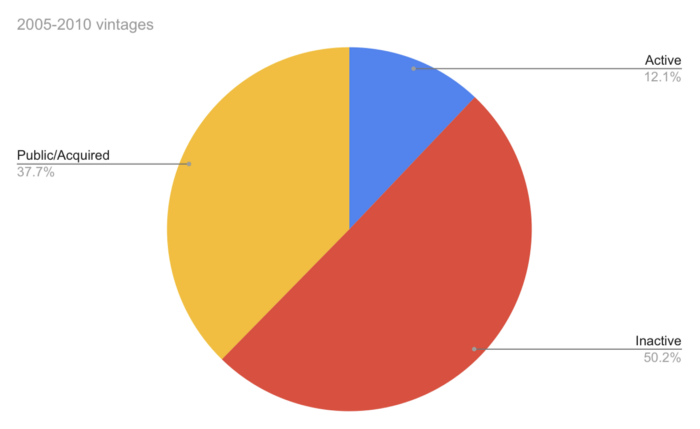
Half the startups have failed, over one-third have exited, and the rest are still operating.
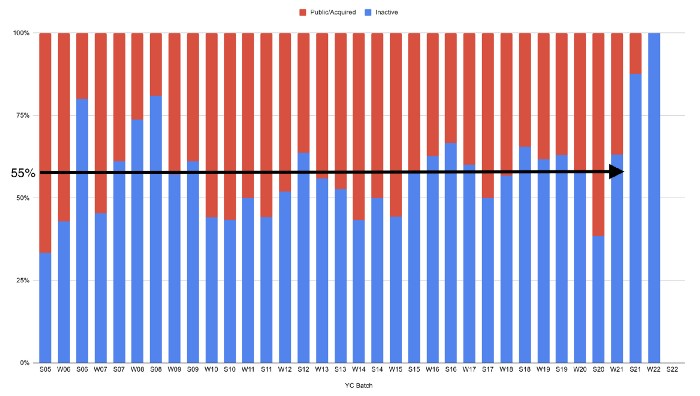
In venture investing, it's said that failed investments show up before successful ones. This is true for YC startups, but only in their early years.
Below, we only present resolved companies from the first chart. Some companies fail soon after establishment, but after a few years, the inactive vs. public/acquired ratio stabilizes around 55:45. After a few years, a YC firm is roughly as likely to quit as fail, which is better than I imagined.
I prepared this post because Rebel investors regularly question me about YC startup failure rates and how long it takes for them to exit or shut down.
Early-stage venture investors can overlook it because 100x investments matter more than 0x investments.
YC founders can ignore it because it shouldn't matter if many of their peers succeed or fail ;)
Evgenii Nelepko
3 years ago
My 3 biggest errors as a co-founder and CEO
Reflections on the closed company Hola! Dating app

I'll discuss my fuckups as an entrepreneur and CEO. All of them refer to the dating app Hola!, which I co-founded and starred in.
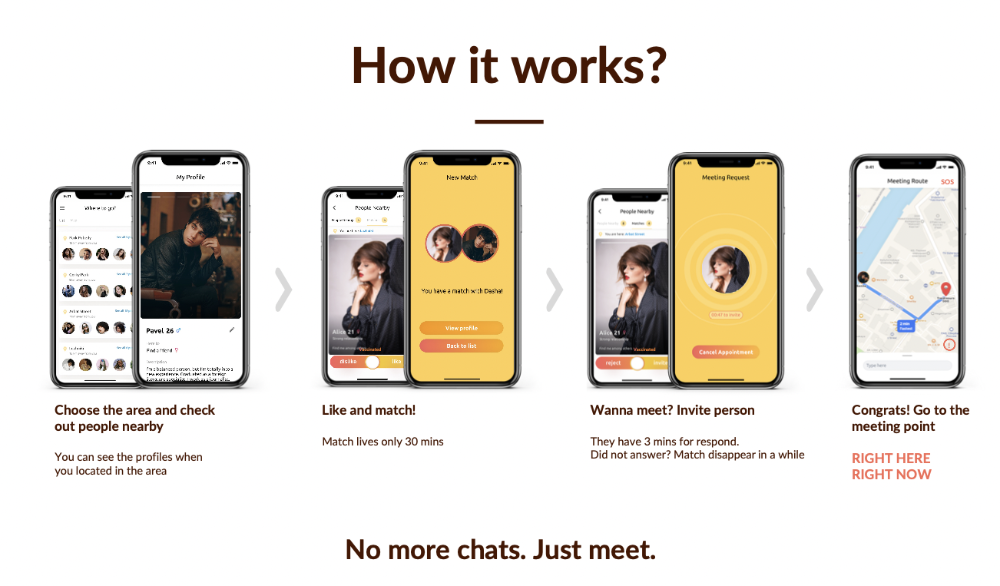
Spring 2021 was when we started. Two techies and two non-techies created a dating app. Pokemon Go and Tinder were combined.
Online dating is a business, and it takes two weeks from a like to a date. We questioned online dating app users if they met anyone offline last year.
75% replied yes, 50% sometimes, 25% usually.
Offline dating is popular, yet people have concerns.
Men are reluctant to make mistakes in front of others.
Women are curious about the background of everyone who approaches them.
We designed unique mechanics that let people date after a match. No endless chitchat. Women would be safe while men felt like cowboys.
I wish to emphasize three faults that lead to founders' estrangement.
This detachment ultimately led to us shutting down the company.
The wrong technology stack
Situation
Instead of generating a faster MVP and designing an app in a universal stack for iOS and Android, I argued we should pilot the app separately for iOS and Android. Technical founders' expertise made this possible.
Self-reflection
Mistaken strategy. We lost time and resources developing two apps at once. We chose iOS since it's more profitable. Apple took us out after the release, citing Guideline 4.3 Spam. After 4 months, we had nothing. We had a long way to go to get the app on Android and the Store.
I suggested creating a uniform platform for the company's growth. This makes parallel product development easier. The strategist's lack of experience and knowledge made it a piece of crap.
What would I have changed if I could?
We should have designed an Android universal stack. I expected Apple to have issues with a dating app.
Our approach should have been to launch something and subsequently improve it, but prejudice won.
The lesson
Discuss the IT stack with your CTO. It saves time and money. Choose the easiest MVP method.
2. A tardy search for investments
Situation
Though the universe and other founders encouraged me to locate investors first, I started pitching when we almost had an app.
When angels arrived, it was time to close. The app was banned, war broke out, I left the country, and the other co-founders stayed. We had no savings.
Self-reflection
I loved interviewing users. I'm proud of having done 1,000 interviews. I wanted to understand people's pain points and improve the product.
Interview results no longer affected the product. I was terrified to start pitching. I filled out accelerator applications and redid my presentation. You must go through that so you won't be terrified later.
What would I have changed if I could?
Get an external or internal mentor to help me with my first pitch as soon as possible. I'd be supported if criticized. He'd cheer with me if there was enthusiasm.
In 99% of cases, I'm comfortable jumping into the unknown, but there are exceptions. The mentor's encouragement would have prompted me to act sooner.
The lesson
Begin fundraising immediately. Months may pass. Show investors your pre-MVP project. Draw inferences from feedback.
3. Role ambiguity
Situation
My technical co-founders were also part-time lead developers, which produced communication issues. As co-founders, we communicated well and recognized the problems. Stakes, vesting, target markets, and approach were agreed upon.
We were behind schedule. Technical debt and strategic gap grew.
Bi-daily and weekly reviews didn't help. Each time, there were explanations. Inside, I was freaking out.
Self-reflection
I am a fairly easy person to talk to. I always try to stick to agreements; otherwise, my head gets stuffed with unnecessary information, interpretations, and emotions.
Sit down -> talk -> decide -> do -> evaluate the results. Repeat it.
If I don't get detailed comments, I start ruining everyone's mood. If there's a systematic violation of agreements without a good justification, I won't join the project or I'll end the collaboration.
What would I have done otherwise?
This is where it’s scariest to draw conclusions. Probably the most logical thing would have been not to start the project as we started it. But that was already a completely different project. So I would not have done anything differently and would have failed again.
But I drew conclusions for the future.
The lesson
First-time founders should find an adviser or team coach for a strategic session. It helps split the roles and responsibilities.

Mircea Iosif
3 years ago
How To Start An Online Business That Will Be Profitable Without Investing A Lot Of Time

Don't know how to start an online business? Here's a guide. By following these recommendations, you can build a lucrative and profitable online business.
What Are Online Businesses Used For?
Most online businesses are websites. A self-created, self-managed website. You may sell things and services online.
To establish an internet business, you must locate a host and set up accounts with numerous companies. Once your accounts are set up, you may start publishing content and selling products or services.
How to Make Money from Your Online Business
Advertising and marketing are the best ways to make money online. You must develop strategies to contact new customers and generate leads. Make sure your website is search engine optimized so people can find you online.
Top 5 Online Business Tips for Startups:
1. Know your target audience's needs.
2. Make your website as appealing as possible.
3. Generate leads and sales with marketing.
4. Track your progress and learn from your mistakes to improve.
5. Be prepared to expand into new markets or regions.
How to Launch a Successful Online Business Without Putting in a Lot of Work
Build with a solid business model to start a profitable online business. By using these tips, you can start your online business without paying much.
First, develop a user-friendly website. You can use an internet marketing platform or create your own website. Once your website is live, optimize it for search engines and add relevant content.
Second, sell online. This can be done through ads or direct sales to website visitors. Finally, use social media to advertise your internet business. By accomplishing these things, you'll draw visitors to your website and make money.
When launching a business, invest long-term. This involves knowing your goals and how you'll pay for them. Volatility can have several effects on your business. If you offer things online, you may need to examine if the market is ready for them.
Invest wisely
Investing all your money in one endeavor can lead to too much risk and little ROI. Diversify your investments to take advantage of all available chances. So, your investments won't encounter unexpected price swings and you'll be immune to economic upheavals.
Financial news updates
When launching or running a thriving online business, financial news is crucial. By knowing current trends and upcoming developments, you can keep your business lucrative.
Keeping up with financial news can also help you avoid potential traps that could harm your bottom line. If you don't know about new legislation that could affect your industry, potential customers may choose another store when they learn about your business's problems.
Volatility ahead
You should expect volatility in the financial sector. Without a plan for coping with volatility, you could run into difficulty. If your organization relies on client input, you may not be able to exploit customer behavior shifts.
Your company could go bankrupt if you don't understand how fickle the stock market can be. By preparing for volatility, you can ensure your organization survives difficult times and market crashes.
Conclusion
Many internet businesses can be profitable. Start quickly with a few straightforward steps. Diversify your investments, follow financial news, and be prepared for volatility to develop a successful business.
Thanks for reading!
You might also like

Scott Galloway
3 years ago
Don't underestimate the foolish
ZERO GRACE/ZERO MALICE
Big companies and wealthy people make stupid mistakes too.
Your ancestors kept snakes and drank bad water. You (probably) don't because you've learnt from their failures via instinct+, the ultimate life-lessons streaming network in your head. Instincts foretell the future. If you approach a lion, it'll eat you. Our society's nuanced/complex decisions have surpassed instinct. Human growth depends on how we handle these issues. 80% of people believe they are above-average drivers, yet few believe they make many incorrect mistakes that make them risky. Stupidity hurts others like death. Basic Laws of Human Stupidity by Carlo Cipollas:
Everyone underestimates the prevalence of idiots in our society.
Any other trait a person may have has no bearing on how likely they are to be stupid.
A dumb individual is one who harms someone without benefiting themselves and may even lose money in the process.
Non-dumb people frequently underestimate how destructively powerful stupid people can be.
The most dangerous kind of person is a moron.
Professor Cippola defines stupid as bad for you and others. We underestimate the corporate world's and seemingly successful people's ability to make bad judgments that harm themselves and others. Success is an intoxication that makes you risk-aggressive and blurs your peripheral vision.

Stupid companies and decisions:
Big Dumber
Big-company bad ideas have more bulk and inertia. The world's most valuable company recently showed its board a VR headset. Jony Ive couldn't destroy Apple's terrible idea in 2015. Mr. Ive said that VR cut users off from the outer world, made them seem outdated, and lacked practical uses. Ives' design team doubted users would wear headsets for lengthy periods.
VR has cost tens of billions of dollars over a decade to prove nobody wants it. The next great SaaS startup will likely come from Florence, not Redmond or San Jose.
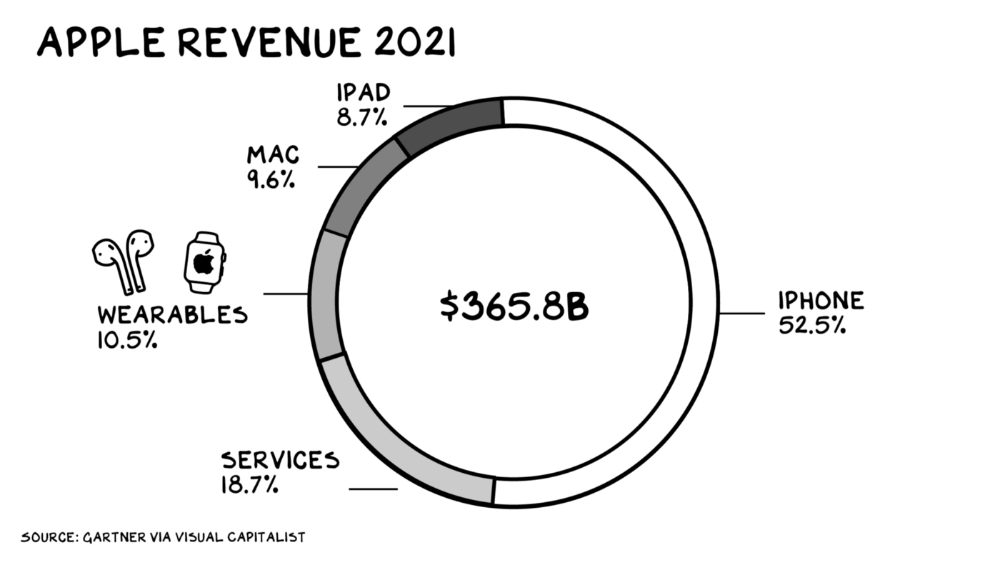
Apple Watch and Airpods have made the Cupertino company the world's largest jewelry maker. 10.5% of Apple's income, or $38 billion, comes from wearables in 2021. (seven times the revenue of Tiffany & Co.). Jewelry makes you more appealing and useful. Airpods and Apple Watch do both.
Headsets make you less beautiful and useful and promote isolation, loneliness, and unhappiness among American teenagers. My sons pretend they can't hear or see me when on their phones. VR headsets lack charisma.
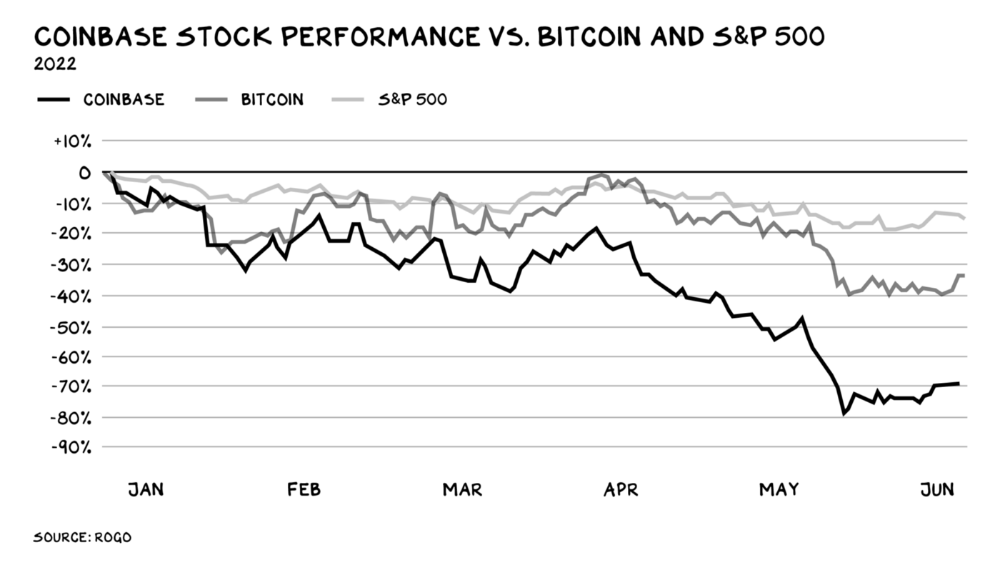
Coinbase disclosed a plan to generate division and tension within its workplace weeks after Apple was pitched $2,000 smokes. The crypto-trading platform is piloting a program that rates staff after every interaction. If a coworker says anything you don't like, you should tell them how to improve. Everyone gets a 110-point scorecard. Coworkers should evaluate a person's rating while deciding whether to listen to them. It's ridiculous.
Organizations leverage our superpower of cooperation. This encourages non-cooperation, period. Bridgewater's founder Ray Dalio designed the approach to promote extreme transparency. Dalio has 223 billion reasons his managerial style works. There's reason to suppose only a small group of people, largely traders, will endure a granular scorecard. Bridgewater has 20% first-year turnover. Employees cry in bathrooms, and sex scandals are settled by ignoring individuals with poor believability levels. Coinbase might take solace that the stock is 80% below its initial offering price.
Poor Stupid
Fools' ledgers are valuable. More valuable are lists of foolish rich individuals.
Robinhood built a $8 billion corporation on financial ignorance. The firm's median account value is $240, and its stock has dropped 75% since last summer. Investors, customers, and society lose. Stupid. Luna published a comparable list on the blockchain, grew to $41 billion in market cap, then plummeted.
A podcast presenter is recruiting dentists and small-business owners to invest in Elon Musk's Twitter takeover. Investors pay a 7% fee and 10% of the upside for the chance to buy Twitter at a 35% premium to the current price. The proposal legitimizes CNBC's Trade Like Chuck advertising (Chuck made $4,600 into $460,000 in two years). This is stupid because it adds to the Twitter deal's desperation. Mr. Musk made an impression when he urged his lawyers to develop a legal rip-cord (There are bots on the platform!) to abandon the share purchase arrangement (for less than they are being marketed by the podcaster). Rolls-Royce may pay for this list of the dumb affluent because it includes potential Cullinan buyers.
Worst company? Flowcarbon, founded by WeWork founder Adam Neumann, operates at the convergence of carbon and crypto to democratize access to offsets and safeguard the earth's natural carbon sinks. Can I get an ayahuasca Big Gulp?
Neumann raised $70 million with their yogababble drink. More than half of the consideration came from selling GNT. Goddess Nature Token. I hope the company gets an S-1. Or I'll start a decentralized AI Meta Renewable NFTs company. My Community Based Ebitda coin will fund the company. Possible.
Stupidity inside oneself
This weekend, I was in NYC with my boys. My 14-year-old disappeared. He's realized I'm not cool and is mad I let the charade continue. When out with his dad, he likes to stroll home alone and depart before me. Friends told me hell would return, but I was surprised by how fast the eye roll came.
Not so with my 11-year-old. We went to The Edge, a Hudson Yards observation platform where you can see the city from 100 storeys up for $38. This is hell's seventh ring. Leaning into your boys' interests is key to engaging them (dad tip). Neither loves Crossfit, WW2 history, or antitrust law.
We take selfies on the Thrilling Glass Floor he spots. Dad, there's a bar! Coke? I nod, he rushes to the bar, stops, runs back for money, and sprints back. Sitting on stone seats, drinking Atlanta Champagne, he turns at me and asks, Isn't this amazing? I'll never reach paradise.
Later that night, the lads are asleep and I've had two Zacapas and Cokes. I SMS some friends about my day and how I feel about sons/fatherhood/etc. How I did. They responded and approached. The next morning, I'm sober, have distance from my son, and feel ashamed by my texts. Less likely to impulsively share my emotions with others. Stupid again.
:max_bytes(150000):strip_icc():gifv():format(webp)/reiff_headshot-5bfc2a60c9e77c00519a70bd.jpg)
Nathan Reiff
3 years ago
Howey Test and Cryptocurrencies: 'Every ICO Is a Security'
What Is the Howey Test?
To determine whether a transaction qualifies as a "investment contract" and thus qualifies as a security, the Howey Test refers to the U.S. Supreme Court cass: the Securities Act of 1933 and the Securities Exchange Act of 1934. According to the Howey Test, an investment contract exists when "money is invested in a common enterprise with a reasonable expectation of profits from others' efforts."
The test applies to any contract, scheme, or transaction. The Howey Test helps investors and project backers understand blockchain and digital currency projects. ICOs and certain cryptocurrencies may be found to be "investment contracts" under the test.
Understanding the Howey Test
The Howey Test comes from the 1946 Supreme Court case SEC v. W.J. Howey Co. The Howey Company sold citrus groves to Florida buyers who leased them back to Howey. The company would maintain the groves and sell the fruit for the owners. Both parties benefited. Most buyers had no farming experience and were not required to farm the land.
The SEC intervened because Howey failed to register the transactions. The court ruled that the leaseback agreements were investment contracts.
This established four criteria for determining an investment contract. Investing contract:
- An investment of money
- n a common enterprise
- With the expectation of profit
- To be derived from the efforts of others
In the case of Howey, the buyers saw the transactions as valuable because others provided the labor and expertise. An income stream was obtained by only investing capital. As a result of the Howey Test, the transaction had to be registered with the SEC.
Howey Test and Cryptocurrencies
Bitcoin is notoriously difficult to categorize. Decentralized, they evade regulation in many ways. Regardless, the SEC is looking into digital assets and determining when their sale qualifies as an investment contract.
The SEC claims that selling digital assets meets the "investment of money" test because fiat money or other digital assets are being exchanged. Like the "common enterprise" test.
Whether a digital asset qualifies as an investment contract depends on whether there is a "expectation of profit from others' efforts."
For example, buyers of digital assets may be relying on others' efforts if they expect the project's backers to build and maintain the digital network, rather than a dispersed community of unaffiliated users. Also, if the project's backers create scarcity by burning tokens, the test is met. Another way the "efforts of others" test is met is if the project's backers continue to act in a managerial role.
These are just a few examples given by the SEC. If a project's success is dependent on ongoing support from backers, the buyer of the digital asset is likely relying on "others' efforts."
Special Considerations
If the SEC determines a cryptocurrency token is a security, many issues arise. It means the SEC can decide whether a token can be sold to US investors and forces the project to register.
In 2017, the SEC ruled that selling DAO tokens for Ether violated federal securities laws. Instead of enforcing securities laws, the SEC issued a warning to the cryptocurrency industry.
Due to the Howey Test, most ICOs today are likely inaccessible to US investors. After a year of ICOs, then-SEC Chair Jay Clayton declared them all securities.
SEC Chairman Gensler Agrees With Predecessor: 'Every ICO Is a Security'
Howey Test FAQs
How Do You Determine If Something Is a Security?
The Howey Test determines whether certain transactions are "investment contracts." Securities are transactions that qualify as "investment contracts" under the Securities Act of 1933 and the Securities Exchange Act of 1934.
The Howey Test looks for a "investment of money in a common enterprise with a reasonable expectation of profits from others' efforts." If so, the Securities Act of 1933 and the Securities Exchange Act of 1934 require disclosure and registration.
Why Is Bitcoin Not a Security?
Former SEC Chair Jay Clayton clarified in June 2018 that bitcoin is not a security: "Cryptocurrencies: Replace the dollar, euro, and yen with bitcoin. That type of currency is not a security," said Clayton.
Bitcoin, which has never sought public funding to develop its technology, fails the SEC's Howey Test. However, according to Clayton, ICO tokens are securities.
A Security Defined by the SEC
In the public and private markets, securities are fungible and tradeable financial instruments. The SEC regulates public securities sales.
The Supreme Court defined a security offering in SEC v. W.J. Howey Co. In its judgment, the court defines a security using four criteria:
- An investment contract's existence
- The formation of a common enterprise
- The issuer's profit promise
- Third-party promotion of the offering
Read original post.

Isaiah McCall
3 years ago
Is TikTok slowly destroying a new generation?
It's kids' digital crack

TikTok is a destructive social media platform.
The interface shortens attention spans and dopamine receptors.
TikTok shares more data than other apps.
Seeing an endless stream of dancing teens on my glowing box makes me feel like a Blade Runner extra.
TikTok did in one year what MTV, Hollywood, and Warner Music tried to do in 20 years. TikTok has psychotized the two-thirds of society Aldous Huxley said were hypnotizable.
Millions of people, mostly kids, are addicted to learning a new dance, lip-sync, or prank, and those who best dramatize this collective improvisation get likes, comments, and shares.
TikTok is a great app. So what?
The Commercial Magnifying Glass TikTok made me realize my generation's time was up and the teenage Zoomers were the target.
I told my 14-year-old sister, "Enjoy your time under the commercial magnifying glass."
TikTok sells your every move, gesture, and thought. Data is the new oil. If you tell someone, they'll say, "Yeah, they collect data, but who cares? I have nothing to hide."
It's a George Orwell novel's beginning. Look up Big Brother Award winners to see if TikTok won.

TikTok shares your data more than any other social media app, and where it goes is unclear. TikTok uses third-party trackers to monitor your activity after you leave the app.
Consumers can't see what data is shared or how it will be used. — Genius URL
32.5 percent of Tiktok's users are 10 to 19 and 29.5% are 20 to 29.
TikTok is the greatest digital marketing opportunity in history, and they'll use it to sell you things, track you, and control your thoughts. Any of its users will tell you, "I don't care, I just want to be famous."
TikTok manufactures mental illness
TikTok's effect on dopamine and the brain is absurd. Dopamine controls the brain's pleasure and reward centers. It's like a switch that tells your brain "this feels good, repeat."
Dr. Julie Albright, a digital culture and communication sociologist, said TikTok users are "carried away by dopamine." It's hypnotic, you'll keep watching."
TikTok constantly releases dopamine. A guy on TikTok recently said he didn't like books because they were slow and boring.
The US didn't ban Tiktok.
Biden and Trump agree on bad things. Both agree that TikTok threatens national security and children's mental health.
The Chinese Communist Party owns and operates TikTok, but that's not its only problem.
There’s borderline child porn on TikTok
It's unsafe for children and violated COPPA.
It's also Chinese spyware. I'm not a Trump supporter, but I was glad he wanted TikTok regulated and disappointed when he failed.
Full-on internet censorship is rare outside of China, so banning it may be excessive. US should regulate TikTok more.
We must reject a low-quality present for a high-quality future.
TikTok vs YouTube
People got mad when I wrote about YouTube's death.
They didn't like when I said TikTok was YouTube's first real challenger.
Indeed. TikTok is the fastest-growing social network. In three years, the Chinese social media app TikTok has gained over 1 billion active users. In the first quarter of 2020, it had the most downloads of any app in a single quarter.
TikTok is the perfect social media app in many ways. It's brief and direct.

Can you believe they had a YouTube vs TikTok boxing match? We are doomed as a species.
YouTube hosts my favorite videos. That’s why I use it. That’s why you use it. New users expect more. They want something quicker, more addictive.
TikTok's impact on other social media platforms frustrates me. YouTube copied TikTok to compete.
It's all about short, addictive content.
I'll admit I'm probably wrong about TikTok. My friend says his feed is full of videos about food, cute animals, book recommendations, and hot lesbians.
Whatever.
TikTok makes us bad
TikTok is the opposite of what the Ancient Greeks believed about wisdom.
It encourages people to be fake. It's like a never-ending costume party where everyone competes.
It does not mean that Gen Z is doomed.
They could be the saviors of the world for all I know.
TikTok feels like a step towards Mike Judge's "Idiocracy," where the average person is a pleasure-seeking moron.