






More on Marketing

Saskia Ketz
3 years ago
I hate marketing for my business, but here's how I push myself to keep going
Start now.

When it comes to building my business, I’m passionate about a lot of things. I love creating user experiences that simplify branding essentials. I love creating new typefaces and color combinations to inspire logo designers. I love fixing problems to improve my product.
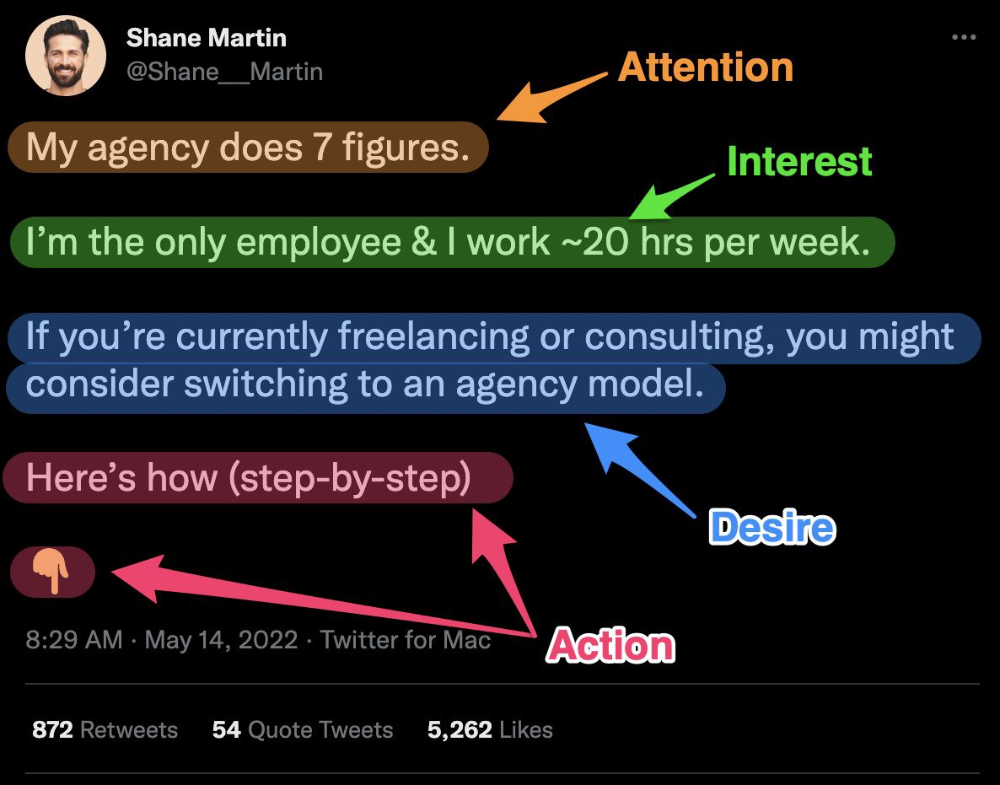
Business marketing isn't my thing.
This is shared by many. Many solopreneurs, like me, struggle to advertise their business and drive themselves to work on it.
Without a lot of promotion, no company will succeed. Marketing is 80% of developing a firm, and when you're starting out, it's even more. Some believe that you shouldn't build anything until you've begun marketing your idea and found enough buyers.
Marketing your business without marketing experience is difficult. There are various outlets and techniques to learn. Instead of figuring out where to start, it's easier to return to your area of expertise, whether that's writing, designing product features, or improving your site's back end. Right?
First, realize that your role as a founder is to market your firm. Being a founder focused on product, I rarely work on it.
Secondly, use these basic methods that have helped me dedicate adequate time and focus to marketing. They're all simple to apply, and they've increased my business's visibility and success.
1. Establish buckets for every task.
You've probably heard to schedule tasks you don't like. As simple as it sounds, blocking a substantial piece of my workday for marketing duties like LinkedIn or Twitter outreach, AppSumo customer support, or SEO has forced me to spend time on them.
Giving me lots of room to focus on product development has helped even more. Sure, this means scheduling time to work on product enhancements after my four-hour marketing sprint.
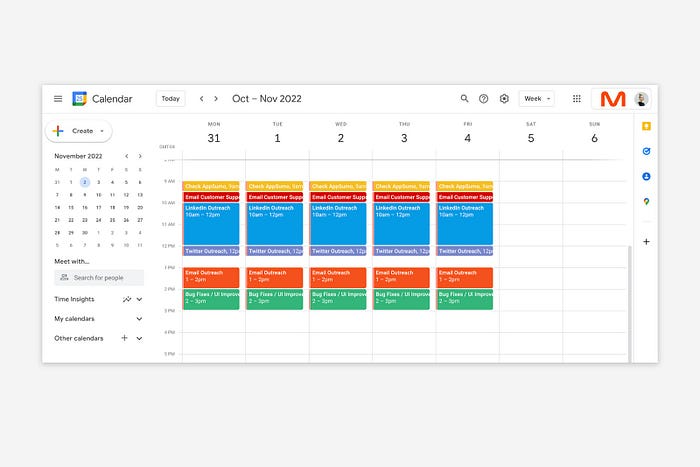
It also involves making space to store product inspiration and ideas throughout the day so I don't get distracted. This is like the advice to keep a notebook beside your bed to write down your insomniac ideas. I keep fonts, color palettes, and product ideas in folders on my desktop. Knowing these concepts won't be lost lets me focus on marketing in the moment. When I have limited time to work on something, I don't have to conduct the research I've been collecting, so I can get more done faster.
2. Look for various accountability systems
Accountability is essential for self-discipline. To keep focused on my marketing tasks, I've needed various streams of accountability, big and little.
Accountability groups are great for bigger things. SaaS Camp, a sales outreach coaching program, is mine. We discuss marketing duties and results every week. This motivates me to do enough each week to be proud of my accomplishments. Yet hearing what works (or doesn't) for others gives me benchmarks for my own marketing outcomes and plenty of fresh techniques to attempt.
… say, I want to DM 50 people on Twitter about my product — I get that many Q-tips and place them in one pen holder on my desk.
The best accountability group can't watch you 24/7. I use a friend's simple method that shouldn't work (but it does). When I have a lot of marketing chores, like DMing 50 Twitter users about my product, That many Q-tips go in my desk pen holder. After each task, I relocate one Q-tip to an empty pen holder. When you have a lot of minor jobs to perform, it helps to see your progress. You might use toothpicks, M&Ms, or anything else you have a lot of.

3. Continue to monitor your feedback loops
Knowing which marketing methods work best requires monitoring results. As an entrepreneur with little go-to-market expertise, every tactic I pursue is an experiment. I need to know how each trial is doing to maximize my time.
I placed Google and Facebook advertisements on hold since they took too much time and money to obtain Return. LinkedIn outreach has been invaluable to me. I feel that talking to potential consumers one-on-one is the fastest method to grasp their problem areas, figure out my messaging, and find product market fit.
Data proximity offers another benefit. Seeing positive results makes it simpler to maintain doing a work you don't like. Why every fitness program tracks progress.
Marketing's goal is to increase customers and revenues, therefore I've found it helpful to track those metrics and celebrate monthly advances. I provide these updates for extra accountability.
Finding faster feedback loops is also motivating. Marketing brings more clients and feedback, in my opinion. Product-focused founders love that feedback. Positive reviews make me proud that my product is benefitting others, while negative ones provide me with suggestions for product changes that can improve my business.
The best advice I can give a lone creator who's afraid of marketing is to just start. Start early to learn by doing and reduce marketing stress. Start early to develop habits and successes that will keep you going. The sooner you start, the sooner you'll have enough consumers to return to your favorite work.

Sammy Abdullah
3 years ago
How to properly price SaaS
Price Intelligently put out amazing content on pricing your SaaS product. This blog's link to the whole report is worth reading. Our key takeaways are below.

Don't base prices on the competition. Competitor-based pricing has clear drawbacks. Their pricing approach is yours. Your company offers customers something unique. Otherwise, you wouldn't create it. This strategy is static, therefore you can't add value by raising prices without outpricing competitors. Look, but don't touch is the competitor-based moral. You want to know your competitors' prices so you're in the same ballpark, but they shouldn't guide your selections. Competitor-based pricing also drives down prices.
Value-based pricing wins. This is customer-based pricing. Value-based pricing looks outward, not inward or laterally at competitors. Your clients are the best source of pricing information. By valuing customer comments, you're focusing on buyers. They'll decide if your pricing and packaging are right. In addition to asking consumers about cost savings or revenue increases, look at data like number of users, usage per user, etc.
Value-based pricing increases prices. As you learn more about the client and your worth, you'll know when and how much to boost rates. Every 6 months, examine pricing.
Cloning top customers. You clone your consumers by learning as much as you can about them and then reaching out to comparable people or organizations. You can't accomplish this without knowing your customers. Segmenting and reproducing them requires as much detail as feasible. Offer pricing plans and feature packages for 4 personas. The top plan should state Contact Us. Your highest-value customers want more advice and support.
Question your 4 personas. What's the one item you can't live without? Which integrations matter most? Do you do analytics? Is support important or does your company self-solve? What's too cheap? What's too expensive?
Not everyone likes per-user pricing. SaaS organizations often default to per-user analytics. About 80% of companies utilizing per-user pricing should use an alternative value metric because their goods don't give more value with more users, so charging for them doesn't make sense.
At least 3:1 LTV/CAC. Break even on the customer within 2 years, and LTV to CAC is greater than 3:1. Because customer acquisition costs are paid upfront but SaaS revenues accrue over time, SaaS companies face an early financial shortfall while paying back the CAC.
ROI should be >20:1. Indeed. Ensure the customer's ROI is 20x the product's cost. Microsoft Office costs $80 a year, but consumers would pay much more to maintain it.
A/B Testing. A/B testing is guessing. When your pricing page varies based on assumptions, you'll upset customers. You don't have enough customers anyway. A/B testing optimizes landing pages, design decisions, and other site features when you know the problem but not pricing.
Don't discount. It cheapens the product, makes it permanent, and increases churn. By discounting, you're ruining your pricing analysis.

Guillaume Dumortier
3 years ago
Mastering the Art of Rhetoric: A Guide to Rhetorical Devices in Successful Headlines and Titles
Unleash the power of persuasion and captivate your audience with compelling headlines.
As the old adage goes, "You never get a second chance to make a first impression."
In the world of content creation and social ads, headlines and titles play a critical role in making that first impression.
A well-crafted headline can make the difference between an article being read or ignored, a video being clicked on or bypassed, or a product being purchased or passed over.
To make an impact with your headlines, mastering the art of rhetoric is essential. In this post, we'll explore various rhetorical devices and techniques that can help you create headlines that captivate your audience and drive engagement.
tl;dr : Headline Magician will help you craft the ultimate headline titles powered by rhetoric devices
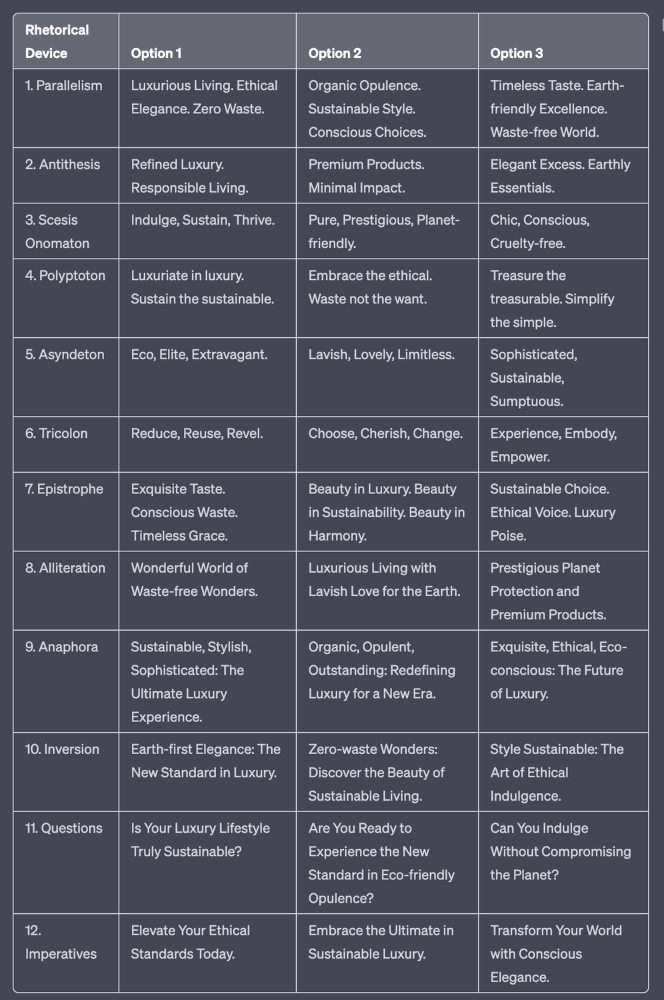
Example with a high-end luxury organic zero-waste skincare brand
✍️ The Power of Alliteration
Alliteration is the repetition of the same consonant sound at the beginning of words in close proximity. This rhetorical device lends itself well to headlines, as it creates a memorable, rhythmic quality that can catch a reader's attention.
By using alliteration, you can make your headlines more engaging and easier to remember.
Examples:
"Crafting Compelling Content: A Comprehensive Course"
"Mastering the Art of Memorable Marketing"
🔁 The Appeal of Anaphora
Anaphora is the repetition of a word or phrase at the beginning of successive clauses. This rhetorical device emphasizes a particular idea or theme, making it more memorable and persuasive.
In headlines, anaphora can be used to create a sense of unity and coherence, which can draw readers in and pique their interest.
Examples:
"Create, Curate, Captivate: Your Guide to Social Media Success"
"Innovation, Inspiration, and Insight: The Future of AI"
🔄 The Intrigue of Inversion
Inversion is a rhetorical device where the normal order of words is reversed, often to create an emphasis or achieve a specific effect.
In headlines, inversion can generate curiosity and surprise, compelling readers to explore further.
Examples:
"Beneath the Surface: A Deep Dive into Ocean Conservation"
"Beyond the Stars: The Quest for Extraterrestrial Life"
⚖️ The Persuasive Power of Parallelism
Parallelism is a rhetorical device that involves using similar grammatical structures or patterns to create a sense of balance and symmetry.
In headlines, parallelism can make your message more memorable and impactful, as it creates a pleasing rhythm and flow that can resonate with readers.
Examples:
"Eat Well, Live Well, Be Well: The Ultimate Guide to Wellness"
"Learn, Lead, and Launch: A Blueprint for Entrepreneurial Success"
⏭️ The Emphasis of Ellipsis
Ellipsis is the omission of words, typically indicated by three periods (...), which suggests that there is more to the story.
In headlines, ellipses can create a sense of mystery and intrigue, enticing readers to click and discover what lies behind the headline.
Examples:
"The Secret to Success... Revealed"
"Unlocking the Power of Your Mind... A Step-by-Step Guide"
🎭 The Drama of Hyperbole
Hyperbole is a rhetorical device that involves exaggeration for emphasis or effect.
In headlines, hyperbole can grab the reader's attention by making bold, provocative claims that stand out from the competition. Be cautious with hyperbole, however, as overuse or excessive exaggeration can damage your credibility.
Examples:
"The Ultimate Guide to Mastering Any Skill in Record Time"
"Discover the Revolutionary Technique That Will Transform Your Life"
❓The Curiosity of Questions
Posing questions in your headlines can be an effective way to pique the reader's curiosity and encourage engagement.
Questions compel the reader to seek answers, making them more likely to click on your content. Additionally, questions can create a sense of connection between the content creator and the audience, fostering a sense of dialogue and discussion.
Examples:
"Are You Making These Common Mistakes in Your Marketing Strategy?"
"What's the Secret to Unlocking Your Creative Potential?"
💥 The Impact of Imperatives
Imperatives are commands or instructions that urge the reader to take action. By using imperatives in your headlines, you can create a sense of urgency and importance, making your content more compelling and actionable.
Examples:
"Master Your Time Management Skills Today"
"Transform Your Business with These Innovative Strategies"
💢 The Emotion of Exclamations
Exclamations are powerful rhetorical devices that can evoke strong emotions and convey a sense of excitement or urgency.
Including exclamations in your headlines can make them more attention-grabbing and shareable, increasing the chances of your content being read and circulated.
Examples:
"Unlock Your True Potential: Find Your Passion and Thrive!"
"Experience the Adventure of a Lifetime: Travel the World on a Budget!"
🎀 The Effectiveness of Euphemisms
Euphemisms are polite or indirect expressions used in place of harsher, more direct language.
In headlines, euphemisms can make your message more appealing and relatable, helping to soften potentially controversial or sensitive topics.
Examples:
"Navigating the Challenges of Modern Parenting"
"Redefining Success in a Fast-Paced World"
⚡Antithesis: The Power of Opposites
Antithesis involves placing two opposite words side-by-side, emphasizing their contrasts. This device can create a sense of tension and intrigue in headlines.
Examples:
"Once a day. Every day"
"Soft on skin. Kill germs"
"Mega power. Mini size."
To utilize antithesis, identify two opposing concepts related to your content and present them in a balanced manner.
🎨 Scesis Onomaton: The Art of Verbless Copy
Scesis onomaton is a rhetorical device that involves writing verbless copy, which quickens the pace and adds emphasis.
Example:
"7 days. 7 dollars. Full access."
To use scesis onomaton, remove verbs and focus on the essential elements of your headline.
🌟 Polyptoton: The Charm of Shared Roots
Polyptoton is the repeated use of words that share the same root, bewitching words into memorable phrases.
Examples:
"Real bread isn't made in factories. It's baked in bakeries"
"Lose your knack for losing things."
To employ polyptoton, identify words with shared roots that are relevant to your content.
✨ Asyndeton: The Elegance of Omission
Asyndeton involves the intentional omission of conjunctions, adding crispness, conviction, and elegance to your headlines.
Examples:
"You, Me, Sushi?"
"All the latte art, none of the environmental impact."
To use asyndeton, eliminate conjunctions and focus on the core message of your headline.
🔮 Tricolon: The Magic of Threes
Tricolon is a rhetorical device that uses the power of three, creating memorable and impactful headlines.
Examples:
"Show it, say it, send it"
"Eat Well, Live Well, Be Well."
To use tricolon, craft a headline with three key elements that emphasize your content's main message.
🔔 Epistrophe: The Chime of Repetition
Epistrophe involves the repetition of words or phrases at the end of successive clauses, adding a chime to your headlines.
Examples:
"Catch it. Bin it. Kill it."
"Joint friendly. Climate friendly. Family friendly."
To employ epistrophe, repeat a key phrase or word at the end of each clause.
You might also like

The Secret Developer
3 years ago
What Elon Musk's Take on Bitcoin Teaches Us

Tesla Q2 earnings revealed unethical dealings.
As of end of Q2, we have converted approximately 75% of our Bitcoin purchases into fiat currency
That’s OK then, isn’t it?
Elon Musk, Tesla's CEO, is now untrustworthy.
It’s not about infidelity, it’s about doing the right thing
And what can we learn?
The Opening Remark
Musk tweets on his (and Tesla's) future goals.
Don’t worry, I’m not expecting you to read it.
What's crucial?
Tesla will not be selling any Bitcoin
The Situation as It Develops
2021 Tesla spent $1.5 billion on Bitcoin. In 2022, they sold 75% of the ownership for $946 million.
That’s a little bit of a waste of money, right?
Musk predicted the reverse would happen.
What gives? Why would someone say one thing, then do the polar opposite?
The Justification For Change
Tesla's public. They must follow regulations. When a corporation trades, they must record what happens.
At least this keeps Musk some way in line.
We now understand Musk and Tesla's actions.
Musk claimed that Tesla sold bitcoins to maximize cash given the unpredictability of COVID lockdowns in China.
Tesla may buy Bitcoin in the future, he said.
That’s fine then. He’s not knocking the NFT at least.
Tesla has moved investments into cash due to China lockdowns.
That doesn’t explain the 180° though
Musk's Tweet isn't company policy. Therefore, the CEO's change of heart reflects the organization. Look.
That's okay, since
Leaders alter their positions when circumstances change.
Leaders must adapt to their surroundings. This isn't embarrassing; it's a leadership prerequisite.
Yet
The Man
Someone stated if you're not in the office full-time, you need to explain yourself. He doesn't treat his employees like adults.
This is the individual mentioned in the quote.
If Elon was not happy, you knew it. Things could get nasty
also, He fired his helper for requesting a raise.
This public persona isn't good. Without mentioning his disastrous performances on Twitter (pedo dude) or Joe Rogan. This image sums up the odd Podcast appearance:

Which describes the man.
I wouldn’t trust this guy to feed a cat
What we can discover
When Musk's company bet on Bitcoin, what happened?
Exactly what we would expect
The company's position altered without the CEO's awareness. He seems uncaring.
This article is about how something happened, not what happened. Change of thinking requires contrition.
This situation is about a lack of respect- although you might argue that followers on Twitter don’t deserve any
Tesla fans call the sale a great move.
It's absurd.
As you were, then.
Conclusion
Good luck if you gamble.
When they pay off, congrats!
When wrong, admit it.
You must take chances if you want to succeed.
Risks don't always pay off.
Mr. Musk lacks insight and charisma to combine these two attributes.
I don’t like him, if you hadn’t figured.
It’s probably all of the cheating.
Isobel Asher Hamilton
3 years ago
$181 million in bitcoin buried in a dump. $11 million to get them back

James Howells lost 8,000 bitcoins. He has $11 million to get them back.
His life altered when he threw out an iPhone-sized hard drive.
Howells, from the city of Newport in southern Wales, had two identical laptop hard drives squirreled away in a drawer in 2013. One was blank; the other had 8,000 bitcoins, currently worth around $181 million.
He wanted to toss out the blank one, but the drive containing the Bitcoin went to the dump.
He's determined to reclaim his 2009 stash.
Howells, 36, wants to arrange a high-tech treasure hunt for bitcoins. He can't enter the landfill.

Newport's city council has rebuffed Howells' requests to dig for his hard drive for almost a decade, stating it would be expensive and environmentally destructive.
I got an early look at his $11 million idea to search 110,000 tons of trash. He expects submitting it to the council would convince it to let him recover the hard disk.
110,000 tons of trash, 1 hard drive
Finding a hard disk among heaps of trash may seem Herculean.
Former IT worker Howells claims it's possible with human sorters, robot dogs, and an AI-powered computer taught to find hard drives on a conveyor belt.
His idea has two versions, depending on how much of the landfill he can search.
His most elaborate solution would take three years and cost $11 million to sort 100,000 metric tons of waste. Scaled-down version costs $6 million and takes 18 months.
He's created a team of eight professionals in AI-powered sorting, landfill excavation, garbage management, and data extraction, including one who recovered Columbia's black box data.
The specialists and their companies would be paid a bonus if they successfully recovered the bitcoin stash.
Howells: "We're trying to commercialize this project."
Howells claimed rubbish would be dug up by machines and sorted near the landfill.
Human pickers and a Max-AI machine would sort it. The machine resembles a scanner on a conveyor belt.
Remi Le Grand of Max-AI told us it will train AI to recognize Howells-like hard drives. A robot arm would select candidates.
Howells has added security charges to his scheme because he fears people would steal the hard drive.
He's budgeted for 24-hour CCTV cameras and two robotic "Spot" canines from Boston Dynamics that would patrol at night and look for his hard drive by day.
Howells said his crew met in May at the Celtic Manor Resort outside Newport for a pitch rehearsal.
Richard Hammond's narrative swings from banal to epic.
Richard Hammond filmed the meeting and created a YouTube documentary on Howells.
Hammond said of Howells' squad, "They're committed and believe in him and the idea."
Hammond: "It goes from banal to gigantic." "If I were in his position, I wouldn't have the strength to answer the door."
Howells said trash would be cleaned and repurposed after excavation. Reburying the rest.
"We won't pollute," he declared. "We aim to make everything better."

After the project is finished, he hopes to develop a solar or wind farm on the dump site. The council is unlikely to accept his vision soon.
A council representative told us, "Mr. Howells can't convince us of anything." "His suggestions constitute a significant ecological danger, which we can't tolerate and are forbidden by our permit."
Will the recovered hard drive work?
The "platter" is a glass or metal disc that holds the hard drive's data. Howells estimates 80% to 90% of the data will be recoverable if the platter isn't damaged.
Phil Bridge, a data-recovery expert who consulted Howells, confirmed these numbers.

If the platter is broken, Bridge adds, data recovery is unlikely.
Bridge says he was intrigued by the proposal. "It's an intriguing case," he added. Helping him get it back and proving everyone incorrect would be a great success story.
Who'd pay?
Swiss and German venture investors Hanspeter Jaberg and Karl Wendeborn told us they would fund the project if Howells received council permission.
Jaberg: "It's a needle in a haystack and a high-risk investment."
Howells said he had no contract with potential backers but had discussed the proposal in Zoom meetings. "Until Newport City Council gives me something in writing, I can't commit," he added.
Suppose he finds the bitcoins.
Howells said he would keep 30% of the data, worth $54 million, if he could retrieve it.
A third would go to the recovery team, 30% to investors, and the remainder to local purposes, including gifting £50 ($61) in bitcoin to each of Newport's 150,000 citizens.
Howells said he opted to spend extra money on "professional firms" to help convince the council.
What if the council doesn't approve?
If Howells can't win the council's support, he'll sue, claiming its actions constitute a "illegal embargo" on the hard drive. "I've avoided that path because I didn't want to cause complications," he stated. I wanted to cooperate with Newport's council.
Howells never met with the council face-to-face. He mentioned he had a 20-minute Zoom meeting in May 2021 but thought his new business strategy would help.
He met with Jessica Morden on June 24. Morden's office confirmed meeting.
After telling the council about his proposal, he can only wait. "I've never been happier," he said. This is our most professional operation, with the best employees.
The "crypto proponent" buys bitcoin every month and sells it for cash.
Howells tries not to think about what he'd do with his part of the money if the hard disk is found functional. "Otherwise, you'll go mad," he added.
This post is a summary. Read the full article here.

The woman
3 years ago
The renowned and highest-paid Google software engineer
His story will inspire you.

“Google search went down for a few hours in 2002; Jeff Dean handled all the queries by hand and checked quality doubled.”- Jeff Dean Facts.
One of many Jeff Dean jokes, but you get the idea.
Google's top six engineers met in a war room in mid-2000. Google's crawling system, which indexed the Web, stopped working. Users could still enter queries, but results were five months old.
Google just signed a deal with Yahoo to power a ten-times-larger search engine. Tension rose. It was crucial. If they failed, the Yahoo agreement would likely fall through, risking bankruptcy for the firm. Their efforts could be lost.
A rangy, tall, energetic thirty-one-year-old man named Jeff dean was among those six brilliant engineers in the makeshift room. He had just left D. E. C. a couple of months ago and started his career in a relatively new firm Google, which was about to change the world. He rolled his chair over his colleague Sanjay and sat right next to him, cajoling his code like a movie director. The history started from there.
When you think of people who shaped the World Wide Web, you probably picture founders and CEOs like Larry Page and Sergey Brin, Marc Andreesen, Tim Berners-Lee, Bill Gates, and Mark Zuckerberg. They’re undoubtedly the brightest people on earth.
Under these giants, legions of anonymous coders work at keyboards to create the systems and products we use. These computer workers are irreplaceable.
Let's get to know him better.
It's possible you've never heard of Jeff Dean. He's American. Dean created many behind-the-scenes Google products. Jeff, co-founder and head of Google's deep learning research engineering team, is a popular technology, innovation, and AI keynote speaker.
While earning an MS and Ph.D. in computer science at the University of Washington, he was a teaching assistant, instructor, and research assistant. Dean joined the Compaq Computer Corporation Western Research Laboratory research team after graduating.
Jeff co-created ProfileMe and the Continuous Profiling Infrastructure for Digital at Compaq. He co-designed and implemented Swift, one of the fastest Java implementations. He was a senior technical staff member at mySimon Inc., retrieving and caching electronic commerce content.
Dean, a top young computer scientist, joined Google in mid-1999. He was always trying to maximize a computer's potential as a child.
An expert
His high school program for processing massive epidemiological data was 26 times faster than professionals'. Epi Info, in 13 languages, is used by the CDC. He worked on compilers as a computer science Ph.D. These apps make source code computer-readable.
Dean never wanted to work on compilers forever. He left Academia for Google, which had less than 20 employees. Dean helped found Google News and AdSense, which transformed the internet economy. He then addressed Google's biggest issue, scaling.
Growing Google faced a huge computing challenge. They developed PageRank in the late 1990s to return the most relevant search results. Google's popularity slowed machine deployment.
Dean solved problems, his specialty. He and fellow great programmer Sanjay Ghemawat created the Google File System, which distributed large data over thousands of cheap machines.
These two also created MapReduce, which let programmers handle massive data quantities on parallel machines. They could also add calculations to the search algorithm. A 2004 research article explained MapReduce, which became an industry sensation.
Several revolutionary inventions
Dean's other initiatives were also game-changers. BigTable, a petabyte-capable distributed data storage system, was based on Google File. The first global database, Spanner, stores data on millions of servers in dozens of data centers worldwide.
It underpins Gmail and AdWords. Google Translate co-founder Jeff Dean is surprising. He contributes heavily to Google News. Dean is Senior Fellow of Google Research and Health and leads Google AI.
Recognitions
The National Academy of Engineering elected Dean in 2009. He received the 2009 Association for Computing Machinery fellowship and the 2016 American Academy of Arts and Science fellowship. He received the 2007 ACM-SIGOPS Mark Weiser Award and the 2012 ACM-Infosys Foundation Award. Lists could continue.
A sneaky question may arrive in your mind: How much does this big brain earn? Well, most believe he is one of the highest-paid employees at Google. According to a survey, he is paid $3 million a year.
He makes espresso and chats with a small group of Googlers most mornings. Dean steams milk, another grinds, and another brews espresso. They discuss families and technology while making coffee. He thinks this little collaboration and idea-sharing keeps Google going.
“Some of us have been working together for more than 15 years,” Dean said. “We estimate that we’ve collectively made more than 20,000 cappuccinos together.”
We all know great developers and software engineers. It may inspire many.