




More on Technology

caroline sinders
3 years ago
Holographic concerts are the AI of the Future.

A few days ago, I was discussing dall-e with two art and tech pals. One artist acquaintance said she knew a frightened illustrator. Would the ability to create anything with a click derail her career? The artist feared this. My curator friend smiled and said this has always been a dread among artists. When the camera was invented, didn't painters say this? Even in the Instagram era, painting exists.
When art and technology collide, there's room for innovation, experimentation, and fear — especially if the technology replicates or replaces art making. What is art's future with dall-e? How does technology affect music, beyond visual art? Recently, I saw "ABBA Voyage," a holographic ABBA concert in London.
"Abba voyage?" my phone asked in early March. A Gen X friend I met through a fashion blogging ring texted me.
"What's abba Voyage?" I asked while opening my front door with keys and coffee.
We're going! Marti, visiting London, took me to a show.
"Absolutely no ABBA songs here." I responded.
My parents didn't play ABBA much, so I don't know much about them. Dad liked Jimi Hendrix, Cream, Deep Purple, and New Orleans jazz. Marti told me ABBA Voyage was a holographic ABBA show with a live band.
The show was fun, extraordinary fun. Nearly everyone on the dance floor wore wigs, ankle-breaking platforms, sequins, and bellbottoms. I saw some millennials and Zoomers among the boomers.
I was intoxicated by the experience.
Automatons date back to the 18th-century mechanical turk. The mechanical turk was a chess automaton operated by a person. The mechanical turk seemed to perform like a human without human intervention, but it required a human in the loop to work properly.
Humans have used non-humans in entertainment for centuries, such as puppets, shadow play, and smoke and mirrors. A show can have animatronic, technological, and non-technological elements, and a live show can blur real and illusion. From medieval puppet shows to mechanical turks to AI filters, bots, and holograms, entertainment has evolved over time.
I'm not a hologram skeptic, but I'm skeptical of technology, especially since I work with it. I love live performances, I love hearing singers breathe, forget lines, and make jokes. Live shows are my favorite because I love watching performers make mistakes or interact with the audience. ABBA Voyage was different.
Marti and I traveled to Manchester after ABBA Voyage to see Liam Gallagher. Similar but different vibe. Similar in that thousands dressed up for the show. ABBA's energy was dizzying. 90s chic replaced sequins in the crowd. Doc Martens, nylon jackets, bucket hats, shaggy hair. The Charlatans and Liam Gallagher opened and closed, respectively. Fireworks. Incredible. People went crazy. Yelling exhausted my voice.
This week in music featured AI-enabled holograms and a decades-old rocker. Both are warm and gooey in our memories.
After seeing both, I'm wondering if we need AI hologram shows. Why? Is it good?
Like everything tech-related, my answer is "maybe." Because context and performance matter. Liam Gallagher and ABBA both had great, different shows.
For a hologram to work, it must be impossible and big. It must be big, showy, and improbable to justify a hologram. It must feel...expensive, like a stadium pop show. According to a quick search, ABBA broke up on bad terms. Reuniting is unlikely. This is also why Prince or Tupac hologram shows work. We can only engage with their legacy through covers or...holograms.
I drove around listening to the radio a few weeks ago. "Dreaming of You" by Selena played. Selena's music defined my childhood. I sang along and turned up the volume (or as loud as my husband would allow me while driving on the highway).
I discovered Selena's music six months after her death, so I never saw her perform live. My babysitter Melissa played me her album after I moved to Houston. Melissa took me to see the Selena movie five times when it came out. I quickly wore out my VHS copy. I constantly sang "Bibi Bibi Bom Bom" and "Como la Flor." I love Selena. A Selena hologram? Yes, probably.
Instagram advertised a cellist's Arthur Russell tribute show. Russell is another deceased artist I love. I almost walked down the aisle to "This is How We Walk on the Moon," but our cellist couldn't find it. Instead, I walked to Magnetic Fields' "The Book of Love." I "discovered" Russell after a friend introduced me to his music a few years ago.
I use these as analogies for the Liam Gallagher and ABBA concerts.
You have no idea how much I'd pay to see a hologram of Selena's 1995 Houston Livestock Show and Rodeo concert. Arthur Russell's hologram is unnecessary. Russell's work was intimate and performance-based. We can't separate his life from his legacy; popular audiences overlooked his genius. He died of AIDS broke. Like Selena, he died prematurely. Given his music and history, another performer would be a better choice than a hologram. He's no Selena. Selena could have rivaled Beyonce.
Pop shows' size works for holograms. Along with ABBA holograms, there was an anime movie and a light show that would put Tron to shame. ABBA created a tourable stadium show. The event was lavish, expensive, and well-planned. Pop, unlike rock, isn't gritty. Liam Gallagher hologram? No longer impossible, it wouldn't work. He's touring. I'm not sure if a rockstar alone should be rendered as a hologram; it was the show that made ABBA a hologram.
Holograms, like AI, are part of the future of entertainment, but not all of it. Because only modern interpretations of Arthur Russell's work reveal his legacy. That's his legacy.

Large-scale arena performers may use holograms in the future, but the experience must be impossible. A teacher once said that the only way to convey emotion in opera is through song, and I feel the same way about holograms, AR, VR, and mixed reality. A story's impossibility must make sense, like in opera. Impossibility and bombastic performance must be present for an immersive element to "work." ABBA was an impossible and improbable experience, which made it magical. It helped the holographic show work.
Marti told me about ABBA Voyage. She said it was a great concert. Marti has worked in music since the 1990s. She's a music expert; she's seen many shows.
Ai isn't a god or sentient, and the ABBA holograms aren't real. The renderings were glassy-eyed, flat, and robotic, like the Polar Express or the Jaws shark. Even today, the uncanny valley is insurmountable. We know it's not real because it's not about reality. It was about a suspended moment and performance feelings.
I knew this was impossible, an 'unreal' experience, but the emotions I felt were real, like watching a movie or tv show. Perhaps this is one of the better uses of AI, like CGI and special effects, like the beauty of entertainment- we were enraptured and entertained for hours. I've been playing ABBA since then.

VIP Graphics
3 years ago
Leaked pitch deck for Metas' new influencer-focused live-streaming service
As part of Meta's endeavor to establish an interactive live-streaming platform, the company is testing with influencers.
The NPE (new product experimentation team) has been testing Super since late 2020.

Bloomberg defined Super as a Cameo-inspired FaceTime-like gadget in 2020. The tool has evolved into a Twitch-like live streaming application.
Less than 100 creators have utilized Super: Creators can request access on Meta's website. Super isn't an Instagram, Facebook, or Meta extension.
“It’s a standalone project,” the spokesperson said about Super. “Right now, it’s web only. They have been testing it very quietly for about two years. The end goal [of NPE projects] is ultimately creating the next standalone project that could be part of the Meta family of products.” The spokesperson said the outreach this week was part of a drive to get more creators to test Super.
A 2021 pitch deck from Super reveals the inner workings of Meta.
The deck gathered feedback on possible sponsorship models, with mockups of brand deals & features. Meta reportedly paid creators $200 to $3,000 to test Super for 30 minutes.
Meta's pitch deck for Super live streaming was leaked.
What were the slides in the pitch deck for Metas Super?
Embed not supported: see full deck & article here →
View examples of Meta's pitch deck for Super:
Product Slides, first
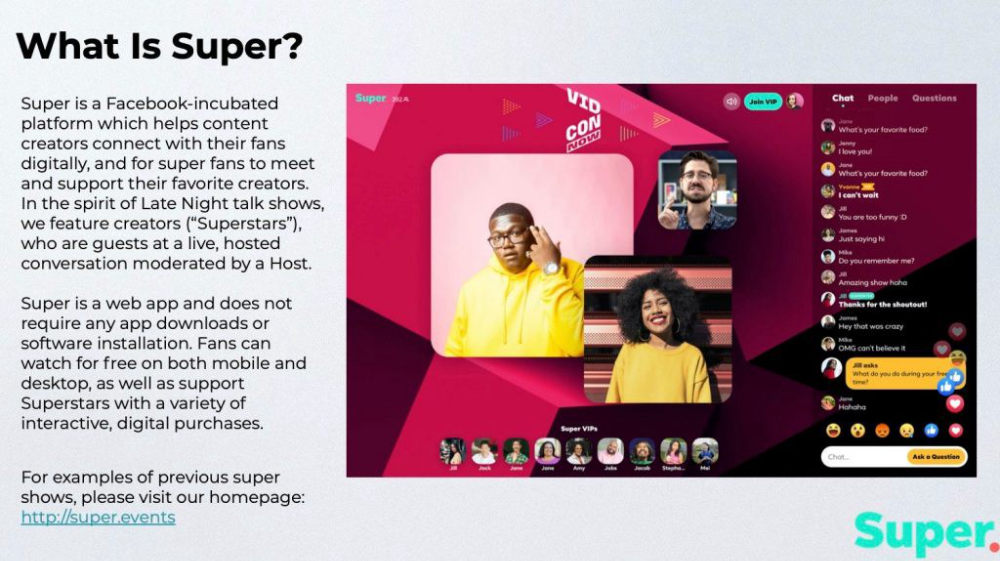
The pitch deck begins with Super's mission:
Super is a Facebook-incubated platform which helps content creators connect with their fans digitally, and for super fans to meet and support their favorite creators. In the spirit of Late Night talk shows, we feature creators (“Superstars”), who are guests at a live, hosted conversation moderated by a Host.
This slide (and most of the deck) is text-heavy, with few icons, bullets, and illustrations to break up the content. Super's online app status (which requires no download or installation) might be used as a callout (rather than paragraph-form).

Meta's Super platform focuses on brand sponsorships and native placements, as shown in the slide above.
One of our theses is the idea that creators should benefit monetarily from their Super experiences, and we believe that offering a menu of different monetization strategies will enable the right experience for each creator. Our current focus is exploring sponsorship opportunities for creators, to better understand what types of sponsor placements will facilitate the best experience for all Super customers (viewers, creators, and advertisers).
Colorful mockups help bring Metas vision for Super to life.
2. Slide Features
Super's pitch deck focuses on the platform's features. The deck covers pre-show, pre-roll, and post-event for a Sponsored Experience.
Pre-show: active 30 minutes before the show's start
Pre-roll: Play a 15-minute commercial for the sponsor before the event (auto-plays once)
Meet and Greet: This event can have a branding, such as Meet & Greet presented by [Snickers]
Super Selfies: Makers and followers get a digital souvenir to post on social media.
Post-Event: Possibility to draw viewers' attention to sponsored content/links during the after-show
Almost every screen displays the Sponsor logo, link, and/or branded background. Viewers can watch sponsor video while waiting for the event to start.
Slide 3: Business Model
Meta's presentation for Super is incomplete without numbers. Super's first slide outlines the creator, sponsor, and Super's obligations. Super does not charge creators any fees or commissions on sponsorship earnings.

How to make a great pitch deck
We hope you can use the Super pitch deck to improve your business. Bestpitchdeck.com/super-meta is a bookmarkable link.
You can also use one of our expert-designed templates to generate a pitch deck.
Our team has helped close $100M+ in agreements and funding for premier companies and VC firms. Use our presentation templates, one-pagers, or financial models to launch your pitch.
Every pitch must be audience-specific. Our team has prepared pitch decks for various sectors and fundraising phases.

Pitch Deck Software VIP.graphics produced a popular SaaS & Software Pitch Deck based on decks that closed millions in transactions & investments for orgs of all sizes, from high-growth startups to Fortune 100 enterprises. This easy-to-customize PowerPoint template includes ready-made features and key slides for your software firm.

Accelerator Pitch Deck The Accelerator Pitch Deck template is for early-stage founders seeking funding from pitch contests, accelerators, incubators, angels, or VC companies. Winning a pitch contest or getting into a top accelerator demands a strategic investor pitch.

Pitch Deck Template Series Startup and founder pitch deck template: Workable, smart slides. This pitch deck template is for companies, entrepreneurs, and founders raising seed or Series A finance.

M&A Pitch Deck Perfect Pitch Deck is a template for later-stage enterprises engaging more sophisticated conversations like M&A, late-stage investment (Series C+), or partnerships & funding. Our team prepared this presentation to help creators confidently pitch to investment banks, PE firms, and hedge funds (and vice versa).
Browse our growing variety of industry-specific pitch decks.

Nitin Sharma
3 years ago
The result of my side-hustle blog post with ChatGPT is remarkable.
It's free now.

Most content writers—including me—write about side hustles because they do well.
I wrote several articles on a profitable programming side hustle.
Later, I learnt about AI content-generating platforms like Jasper.ai and Copy.ai, which I thought were terrible because they required subscriptions and had bad content. Even I dislike automatic online posting.
Since ChatGPT is becoming more popular, I tried it. It's free now.
Note: I wasn’t compensated to write this piece by this tool. In other words, I don’t receive any payment from their founders. There is no affiliate link, and right now it is free to use. Also, ChatGPT can do a lot more than what I ever did.
Begin.
OpenAI account registration requires visiting the website (if you don’t have one). Just write anything into the chatbot and get a response.
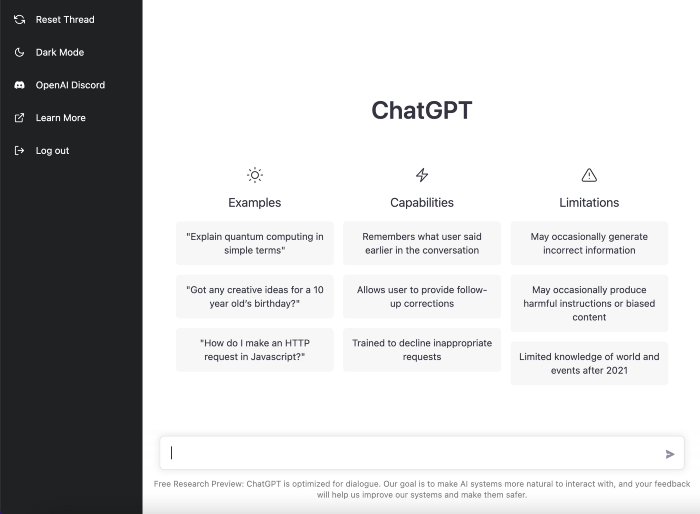
First, I wrote about the top 10 2023 side businesses.
This came in seconds.
2023 is shaping up to be a year of growth and opportunity for entrepreneurs and side hustlers. With the rise of remote work and the growing gig economy, there are many income streams to consider launching in the coming year. Here are the top 10 income streams to launch in 2023:
Virtual Assistant — The demand for virtual assistants is on the rise as more businesses move online. As a virtual assistant, you can offer administrative, technical, or creative services to clients remotely.
Online Tutoring — If you have expertise in a particular subject, consider becoming an online tutor. There are many platforms that connect tutors with students looking for help with their studies.
Freelance Writing — If you have a knack for writing, consider becoming a freelance writer. You can offer your services to businesses, bloggers, and individuals looking for content for their websites or social media platforms.
Graphic Design — If you have a talent for design, consider starting a graphic design side hustle. You can create logos, banners, and other visual content for businesses and individuals.
Social Media Management — Many businesses are looking for help with managing their social media accounts. As a social media manager, you can help businesses create and execute social media strategies to reach their target audience.
Dropshipping — Dropshipping is a business model where you sell products without actually holding any inventory. You can partner with suppliers and ship the products directly to the customer on behalf of the business.
Pet Sitting — If you love animals, consider starting a pet-sitting side hustle. You can offer your services to pet owners who need someone to take care of their pets while they are away.
Home Cleaning — With busy schedules, many people are looking for help with cleaning their homes. As a home cleaning service provider, you can offer your services to help keep homes tidy and organized.
Event Planning — If you have a talent for organization and planning, consider starting an event planning side hustle. You can offer your services to help plan and execute events for businesses and individuals.
Online Teaching — With the rise of online education, there is a growing demand for online teachers. If you have expertise in a particular subject, consider becoming an online teacher and offer your services to students looking for personalized instruction.
In conclusion, 2023 is shaping up to be a great year for launching new income streams. Whether you are looking to start a virtual assistant business, become an online tutor, or offer home cleaning services, there are many opportunities to turn your skills and expertise into a profitable side hustle.
Better than most online side hustle posts, right?
Write about the top 10 programming side hustles to start in 2023.
I got this.
If you are a programmer looking to start a side hustle, 2023 is the perfect time to launch your own business. With the growing demand for software and app development, there are many opportunities for programmers to turn their skills into a profitable side hustle. Here are the top 10 programming side hustles to start in 2023:
App Development — With the rise of smartphones and tablets, there is a growing demand for app development. You can offer your services to businesses and individuals looking to create custom apps for their needs.
Website Development — Many businesses and individuals are looking for help with creating and maintaining their websites. As a website developer, you can offer your services to help design, build, and manage websites for your clients.
Software Development — If you have expertise in a particular programming language, consider starting a software development side hustle. You can offer your services to businesses and individuals looking to create custom software solutions for their needs.
Game Development — The gaming industry is thriving, and there is a growing demand for game development. If you have experience in game development, you can offer your services to businesses and individuals looking to create custom games.
Data Analysis — With the rise of big data, there is a growing demand for data analysts. As a data analyst, you can offer your services to businesses and individuals looking to make sense of their data and gain insights from it.
Machine Learning — Machine learning is a rapidly growing field, and there is a growing demand for machine learning experts. If you have experience in machine learning, you can offer your services to businesses and individuals looking to develop custom machine learning solutions.
Cloud Computing — With the rise of cloud computing, there is a growing demand for cloud experts. If you have experience in cloud computing, you can offer your services to businesses and individuals looking to migrate their applications and data to the cloud.
Blockchain Development — Blockchain technology is gaining popularity, and there is a growing demand for blockchain developers. If you have experience in blockchain development, you can offer your services to businesses and individuals looking to develop custom blockchain solutions.
Artificial Intelligence — Artificial intelligence is a rapidly growing field, and there is a growing demand for AI experts. If you have experience in artificial intelligence, you can offer your services to businesses and individuals looking to develop custom AI solutions.
Virtual Reality — Virtual reality is an exciting and emerging technology, and there is a growing demand for VR developers. If you have experience in VR development, you can offer your services to businesses and individuals looking to create custom VR experiences.
In conclusion, 2023 is a great time to start a programming side hustle. Whether you are interested in app development, website development, or machine learning, there are many opportunities for programmers to turn their skills into a profitable business.
These two blogs show that AI can simplify blog authoring.
I asked some tough programming questions, and most were suitable.
The content may occasionally not be what we want, but it will almost always be very helpful to you.
Enjoy.
You might also like

Percy Bolmér
3 years ago
Ethereum No Longer Consumes A Medium-Sized Country's Electricity To Run
The Merge cut Ethereum's energy use by 99.5%.

The Crypto community celebrated on September 15, 2022. This day, Ethereum Merged. The entire blockchain successfully merged with the Beacon chain, and it was so smooth you barely noticed.
Many have waited, dreaded, and longed for this day.
Some investors feared the network would break down, while others envisioned a seamless merging.
Speculators predict a successful Merge will lead investors to Ethereum. This could boost Ethereum's popularity.
What Has Changed Since The Merge
The merging transitions Ethereum mainnet from PoW to PoS.
PoW sends a mathematical riddle to computers worldwide (miners). First miner to solve puzzle updates blockchain and is rewarded.
The puzzles sent are power-intensive to solve, so mining requires a lot of electricity. It's sent to every miner competing to solve it, requiring duplicate computation.
PoS allows investors to stake their coins to validate a new transaction. Instead of validating a whole block, you validate a transaction and get the fees.
You can validate instead of mine. A validator stakes 32 Ethereum. After staking, the validator can validate future blocks.
Once a validator validates a block, it's sent to a randomly selected group of other validators. This group verifies that a validator is not malicious and doesn't validate fake blocks.
This way, only one computer needs to solve or validate the transaction, instead of all miners. The validated block must be approved by a small group of validators, causing duplicate computation.
PoS is more secure because validating fake blocks results in slashing. You lose your bet tokens. If a validator signs a bad block or double-signs conflicting blocks, their ETH is burned.
Theoretically, Ethereum has one block every 12 seconds, so a validator forging a block risks burning 1 Ethereum for 12 seconds of transactions. This makes mistakes expensive and risky.
What Impact Does This Have On Energy Use?
Cryptocurrency is a natural calamity, sucking electricity and eating away at the earth one transaction at a time.
Many don't know the environmental impact of cryptocurrencies, yet it's tremendous.
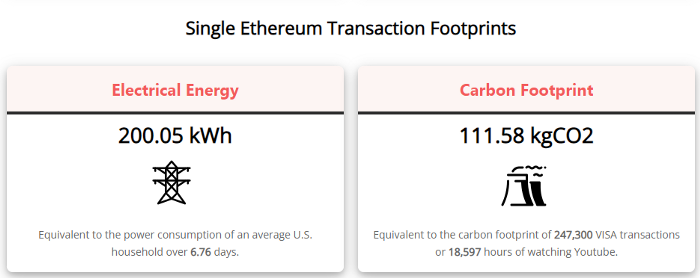
A single Ethereum transaction used to use 200 kWh and leave a large carbon imprint. This update reduces global energy use by 0.2%.
Ethereum will submit a challenge to one validator, and that validator will forward it to randomly selected other validators who accept it.
This reduces the needed computing power.
They expect a 99.5% reduction, therefore a single transaction should cost 1 kWh.
Carbon footprint is 0.58 kgCO2, or 1,235 VISA transactions.
This is a big Ethereum blockchain update.
I love cryptocurrency and Mother Earth.

Deon Ashleigh
3 years ago
You can dominate your daily productivity with these 9 little-known Google Calendar tips.
Calendars are great unpaid employees.
After using Notion to organize my next three months' goals, my days were a mess.
I grew very chaotic afterward. I was overwhelmed, unsure of what to do, and wasting time attempting to plan the day after it had started.
Imagine if our skeletons were on the outside. Doesn’t work.
The goals were too big; I needed to break them into smaller chunks. But how?
Enters Google Calendar
RescueTime’s recommendations took me seven hours to make a daily planner. This epic narrative begins with a sheet of paper and concludes with a daily calendar that helps me focus and achieve more goals. Ain’t nobody got time for “what’s next?” all day.
Onward!
Return to the Paleolithic Era
Plan in writing.
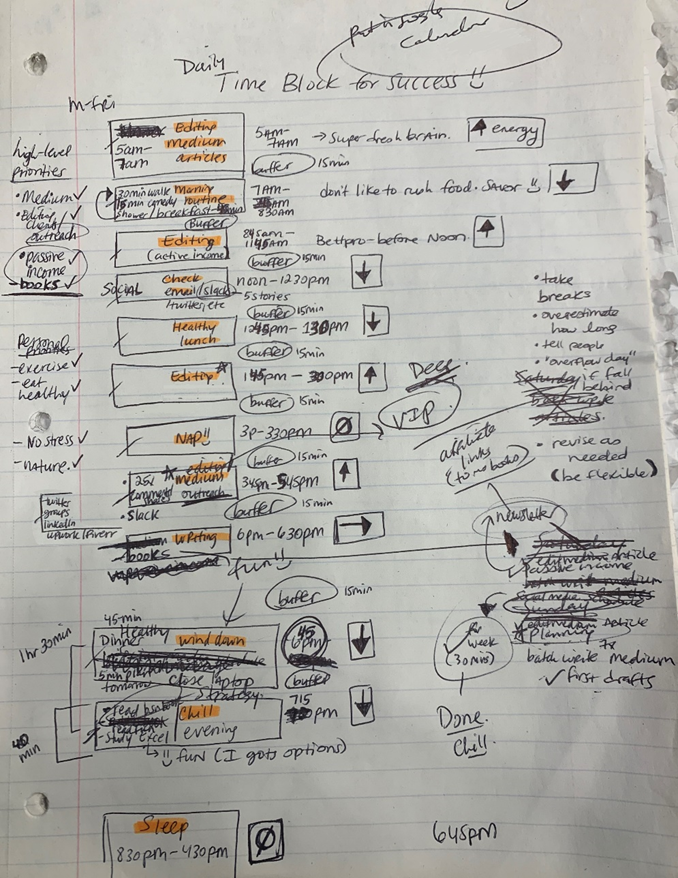
Not on the list, but it helped me plan my day. Physical writing boosts creativity and recall.
Find My Heart
i.e. prioritize
RescueTime suggested I prioritize before planning. Personal and business goals were proposed.
My top priorities are to exercise, eat healthily, spend time in nature, and avoid stress.
Priorities include writing and publishing Medium articles, conducting more freelance editing and Medium outreach, and writing/editing sci-fi books.
These eight things will help me feel accomplished every day.
Make a baby calendar.
Create daily calendar templates.
Make family, pleasure, etc. calendars.
Google Calendar instructions:
Other calendars
Press the “+” button
Create a new calendar
Create recurring events for each day
My calendar, without the template:
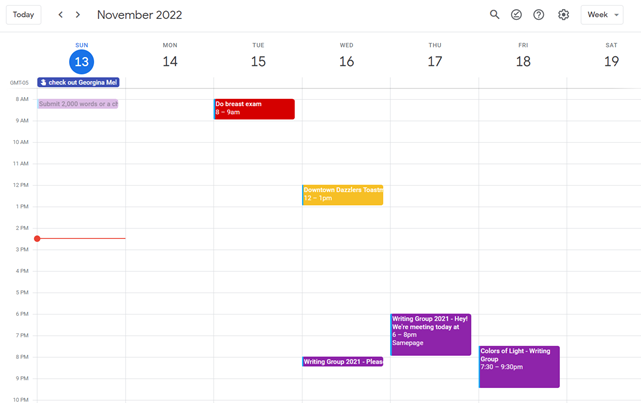
Empty, so I can fill it with vital tasks.
With the template:
My daily skeleton corresponds with my priorities. I've been overwhelmed for years because I lack daily, weekly, monthly, and yearly structure.
Google Calendars helps me reach my goals and focus my energy.
Get your colored pencils ready
Time-block color-coding.
Color labeling lets me quickly see what's happening. Maybe you are too.
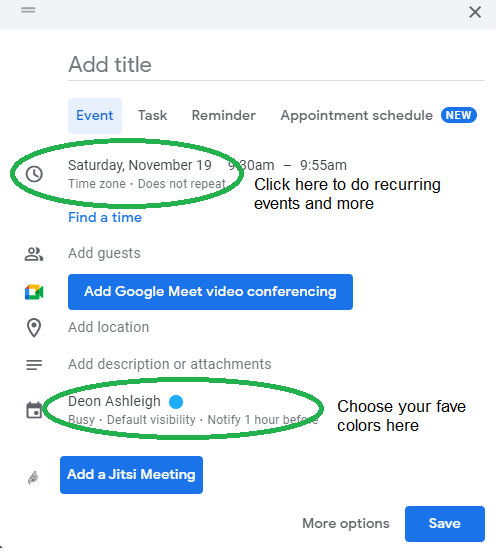
Google Calendar instructions:
Determine which colors correspond to each time block.
When establishing new events, select a color.
Save
My calendar is color-coded as follows:
Yellow — passive income or other future-related activities
Red — important activities, like my monthly breast exam
Flamingo — shallow work, like emails, Twitter, etc.
Blue — all my favorite activities, like walking, watching comedy, napping, and sleeping. Oh, and eating.
Green — money-related events required for this adulting thing
Purple — writing-related stuff
Associating a time block with a color helps me stay focused. Less distractions mean faster work.
Open My Email
aka receive a daily email from Google Calendar.
Google Calendar sends a daily email feed of your calendars. I sent myself the template calendar in this email.
Google Calendar instructions:
Access settings
Select the calendar that you want to send (left side)
Go down the page to see more alerts
Under the daily agenda area, click Email.

Get in Touch With Your Red Bull Wings — Naturally
aka audit your energy levels.
My daily planner has arrows. These indicate how much energy each activity requires or how much I have.
Rightward arrow denotes medium energy.
I do my Medium and professional editing in the morning because it's energy-intensive.
Niharikaa Sodhi recommends morning Medium editing.
I’m a morning person. As long as I go to bed at a reasonable time, 5 a.m. is super wild GO-TIME. It’s like the world was just born, and I marvel at its wonderfulness.
Freelance editing lets me do what I want. An afternoon snooze will help me finish on time.
Ditch Schedule View
aka focus on the weekly view.
RescueTime advocated utilizing the weekly view of Google Calendar, so I switched.
When you launch the phone app or desktop calendar, a red line shows where you are in the day.
I'll follow the red line's instructions. My digital supervisor is easy to follow.
In the image above, it's almost 3 p.m., therefore the red line implies it's time to snooze.
I won't forget this block ;).
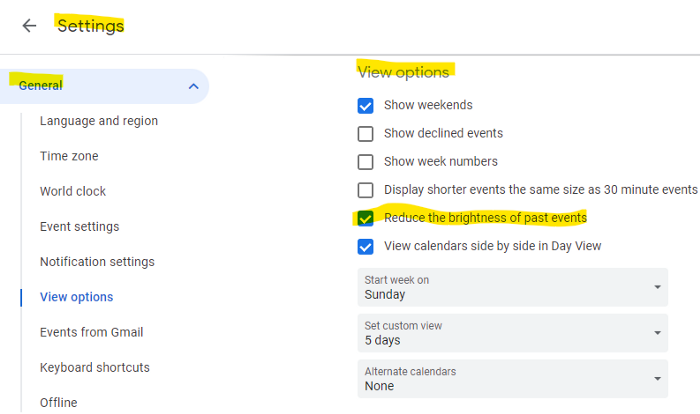
Reduce the Lighting
aka dim previous days.
This is another Google Calendar feature I didn't know about. Once the allotted time passes, the time block dims. This keeps me present.
Google Calendar instructions:
Access settings
remaining general
To view choices, click.
Check Diminish the glare of the past.
Bonus
Two additional RescueTimes hacks:
Maintain a space between tasks
I left 15 minutes between each time block to transition smoothly. This relates to my goal of less stress. If I set strict start and end times, I'll be stressed.
With a buffer, I can breathe, stroll around, and start the following time block fresh.
Find a time is related to the buffer.
This option allows you conclude small meetings five minutes early and longer ones ten. Before the next meeting, relax or go wild.
Decide on a backup day.
This productivity technique is amazing.
Spend this excess day catching up on work. It helps reduce tension and clutter.
That's all I can say about Google Calendar's functionality.

Michael Salim
3 years ago
300 Signups, 1 Landing Page, 0 Products
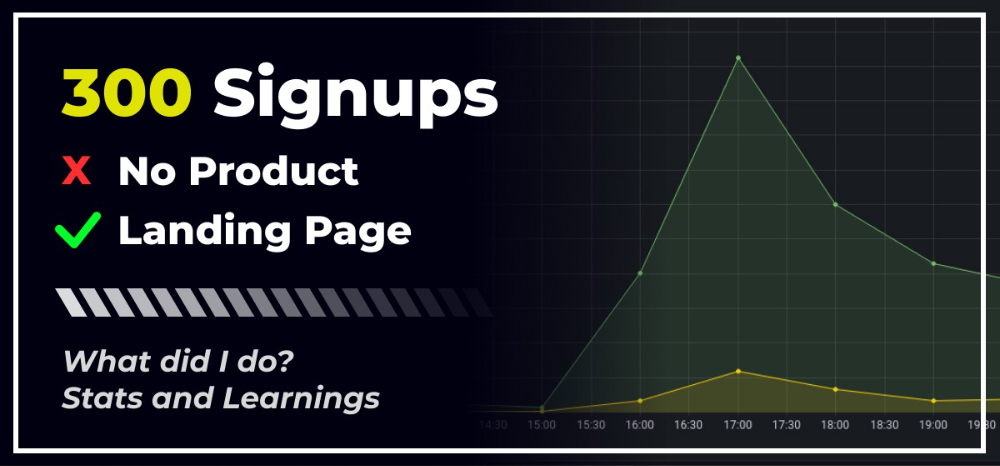
I placed a link on HackerNews and got 300 signups in a week. This post explains what happened.
Product Concept
The product is DbSchemaLibrary. A library of Database Schema.
I'm not sure where this idea originated from. Very fast. Build fast, fail fast, test many ideas, and one will be a hit. I tried it. Let's try it anyway, even though it'll probably fail. I finished The Lean Startup book and wanted to use it.
Database job bores me. Important! I get drowsy working on it. Someone must do it. I remember this happening once. I needed examples at the time. Something similar to Recall (my other project) that I can copy — or at least use as a reference.
Frequently googled. Many tabs open. The results were useless. I raised my hand and agreed to construct the database myself.
It resurfaced. I decided to do something.
Due Diligence
Lean Startup emphasizes validated learning. Everything the startup does should result in learning. I may build something nobody wants otherwise. That's what happened to Recall.
So, I wrote a business plan document. This happens before I code. What am I solving? What is my proposed solution? What is the leap of faith between the problem and solution? Who would be my target audience?
My note:

In my previous project, I did the opposite!
I wrote my expectations after reading the book's advice.
“Failure is a prerequisite to learning. The problem with the notion of shipping a product and then seeing what happens is that you are guaranteed to succeed — at seeing what happens.” — The Lean Startup book
These are successful metrics. If I don't reach them, I'll drop the idea and try another. I didn't understand numbers then. Below are guesses. But it’s a start!

I then wrote the project's What and Why. I'll use this everywhere. Before, I wrote a different pitch each time. I thought certain words would be better. I felt the audience might want something unusual.
Occasionally, this works. I'm unsure if it's a good idea. No stats, just my writing-time opinion. Writing every time is time-consuming and sometimes hazardous. Having a copy saved me duplication.
I can measure and learn from performance.

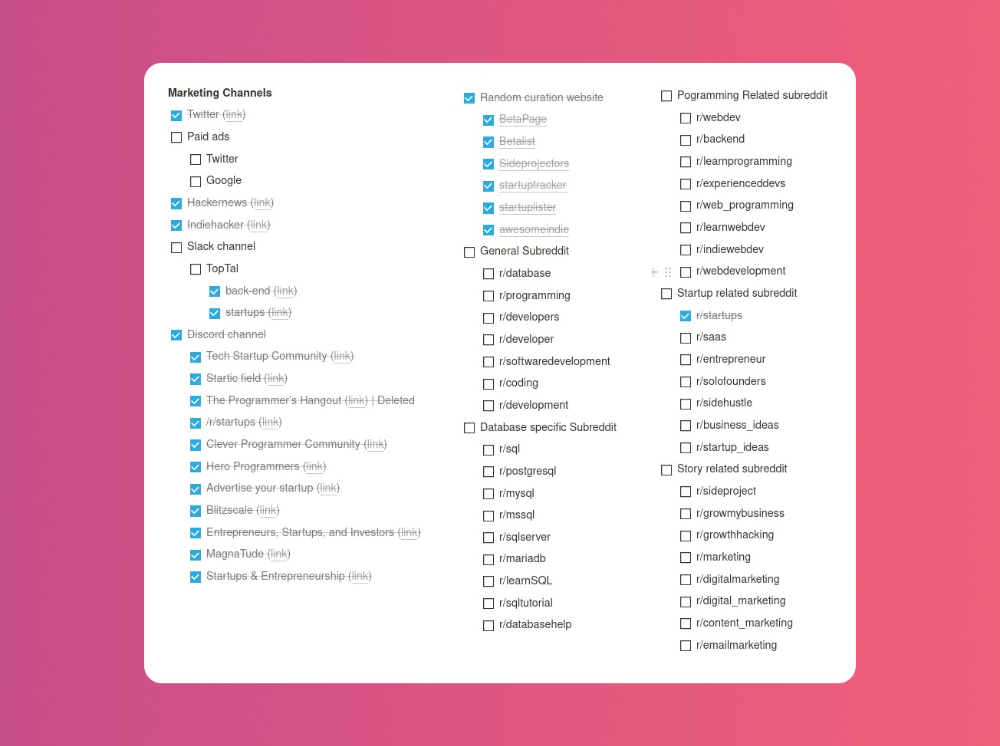
Last, I identified communities that might demand the product. This became an exercise in creativity.
The MVP
So now it’s time to build.
A MVP can test my assumptions. Business may learn from it. Not low-quality. We should learn from the tiniest thing.
I like the example of how Dropbox did theirs. They assumed that if the product works, people will utilize it. How can this be tested without a quality product? They made a movie demonstrating the software's functionality. Who knows how much functionality existed?
So I tested my biggest assumption. Users want schema references. How can I test if users want to reference another schema? I'd love this. Recall taught me that wanting something doesn't mean others do.
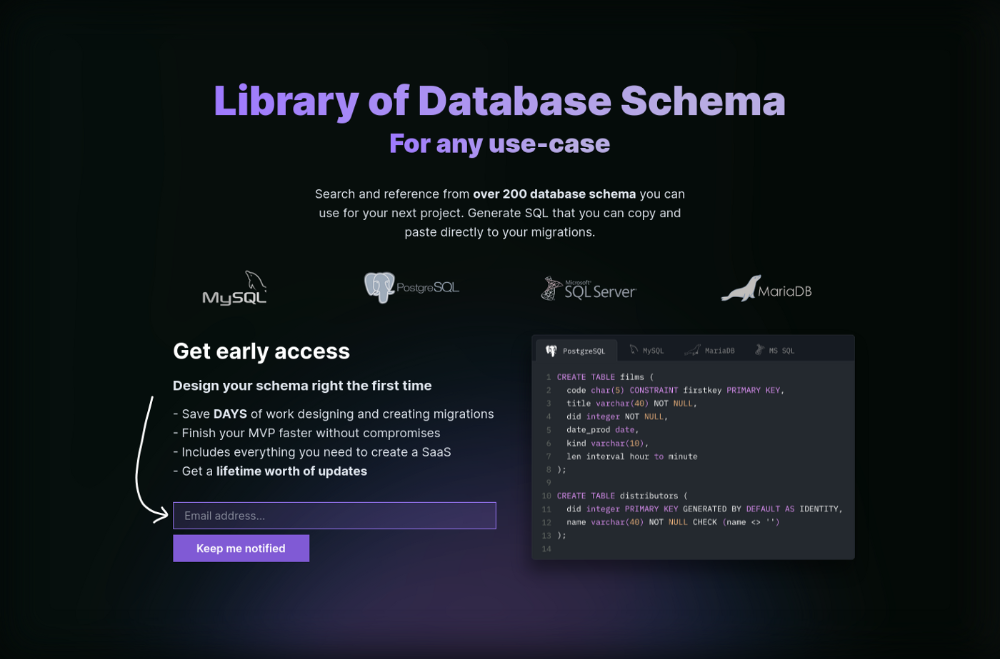
I made an email-collection landing page. Describe it briefly. Reference library. Each email sender wants a reference. They're interested in the product. Few other reasons exist.
Header and footer were skipped. No name or logo. DbSchemaLibrary is a name I thought of after the fact. 5-minute logo. I expected a flop. Recall has no users after months of labor. What could happen to a 2-day project?
I didn't compromise learning validation. How many visitors sign up? To draw a conclusion, I must track these results.
Posting Time
Now that the job is done, gauge interest. The next morning, I posted on all my channels. I didn't want to be spammy, therefore it required more time.
I made sure each channel had at least one fan of this product. I also answer people's inquiries in the channel.
My list stinks. Several channels wouldn't work. The product's target market isn't there. Posting there would waste our time. This taught me to create marketing channels depending on my persona.
Statistics! What actually happened
My favorite part! 23 channels received the link.
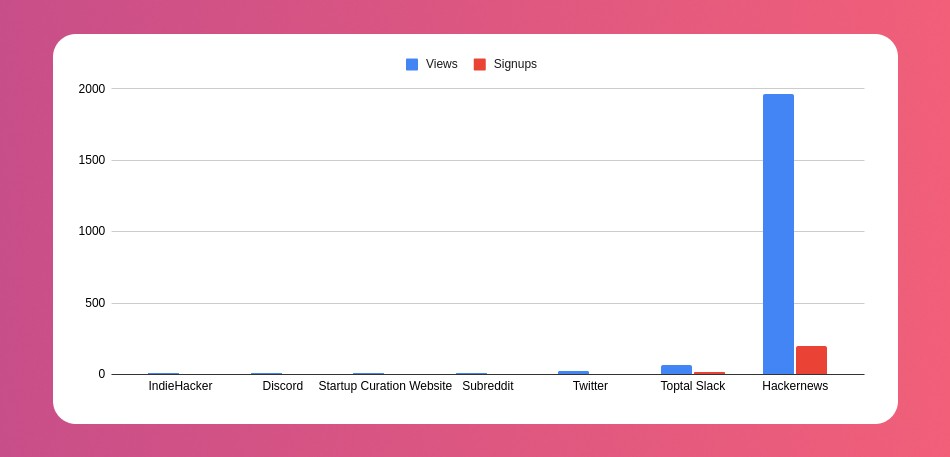
I stopped posting to Discord despite its high conversion rate. I eliminated some channels because they didn't fit. According to the numbers, some users like it. Most users think it's spam.
I was skeptical. And 12 people viewed it.
I didn't expect much attention on a startup subreddit. I'll likely examine Reddit further in the future. As I have enough info, I didn't post much. Time for the next validated learning
No comment. The post had few views, therefore the numbers are low.
The targeted people come next.
I'm a Toptal freelancer. There's a member-only Slack channel. Most people can't use this marketing channel, but you should! It's not as spectacular as discord's 27% conversion rate. But I think the users here are better.
I don’t really have a following anywhere so this isn’t something I can leverage.
The best yet. 10% is converted. With more data, I expect to attain a 10% conversion rate from other channels. Stable number.
This number required some work. Did you know that people use many different clients to read HN?
Unknowns
Untrackable views and signups abound. 1136 views and 135 signups are untraceable. It's 11%. I bet much of that came from Hackernews.
Overall Statistics
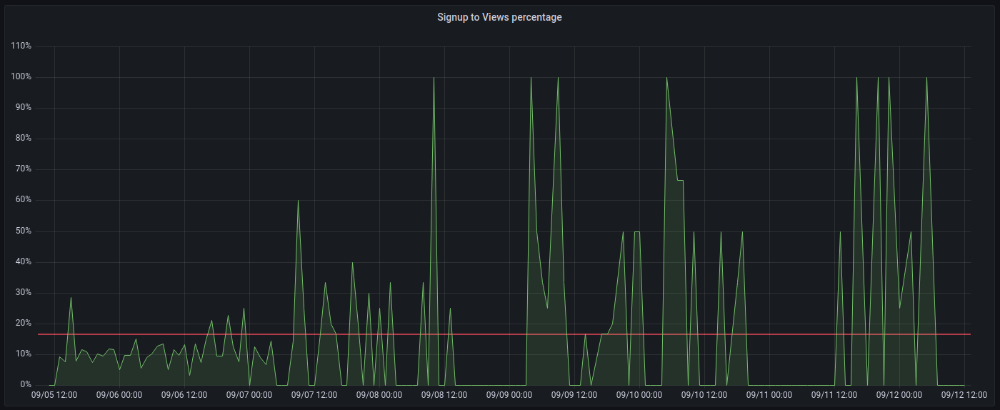
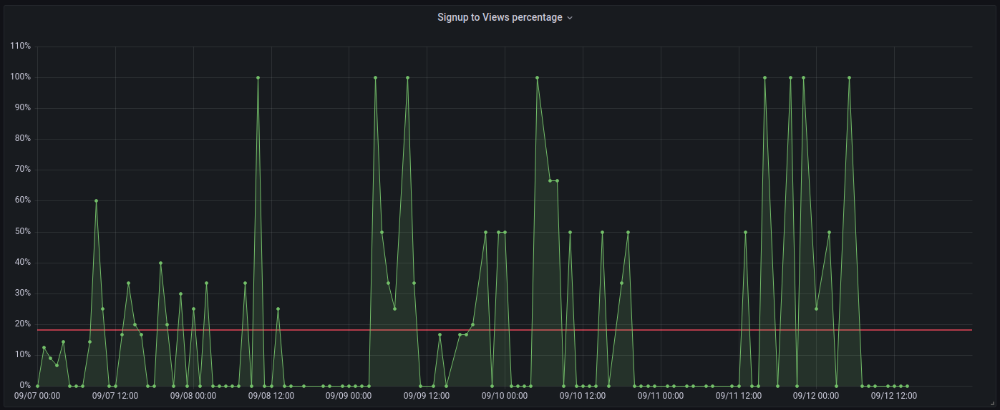
The 7-day signup-to-visit ratio was 17%. (Hourly data points)
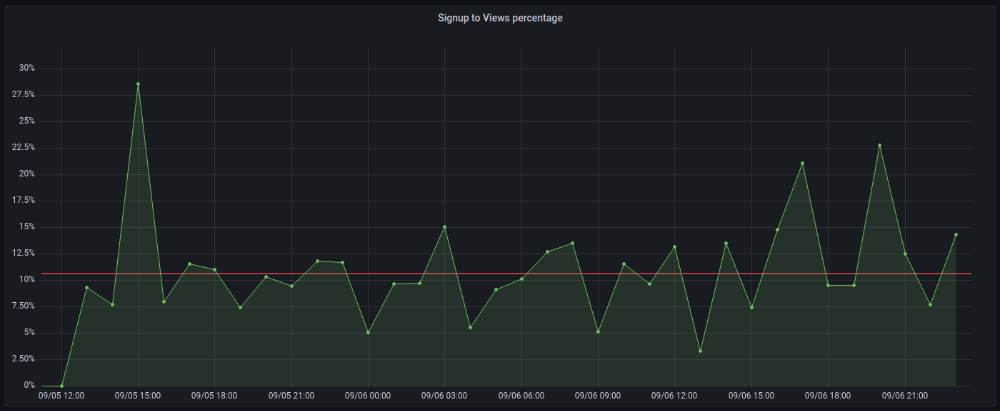
First-day percentages were lower, which is noteworthy. Initially, it was little above 10%. The HN post started getting views then.
When traffic drops, the number reaches just around 20%. More individuals are interested in the connection. hn.algolia.com sent 2 visitors. This means people are searching and finding my post.
Interesting discoveries
1. HN post struggled till the US woke up.
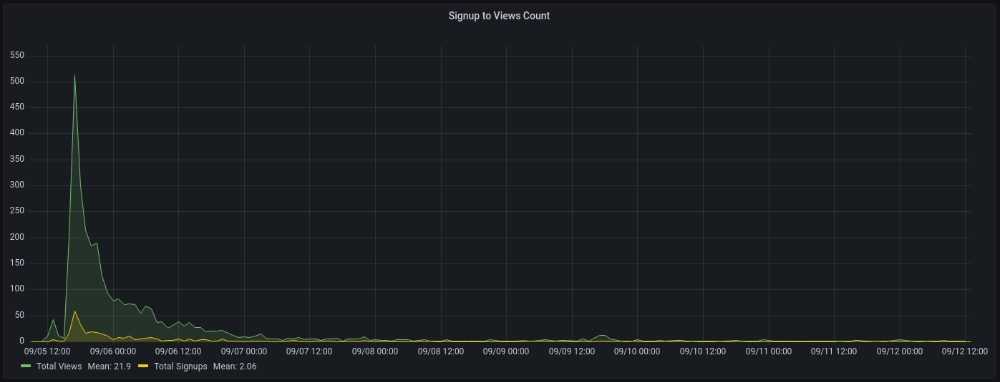
11am UTC. After an hour, it lost popularity. It seemed over. 7 signups converted 13%. Not amazing, but I would've thought ahead.
After 4pm UTC, traffic grew again. 4pm UTC is 9am PDT. US awakened. 10am PDT saw 512 views.
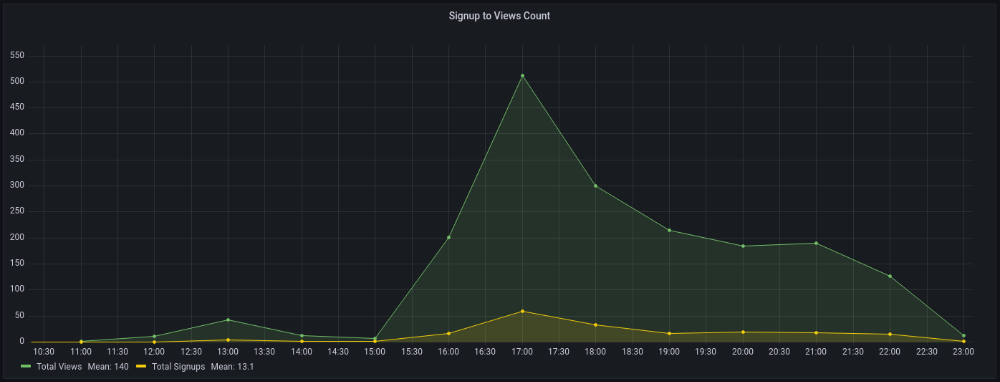
2. The product was highlighted in a newsletter.
I found Revue references when gathering data. Newsletter platform. Someone posted the newsletter link. 37 views and 3 registrations.
3. HN numbers are extremely reliable
I don't have a time-lapse graph (yet). The statistics were constant all day.
2717 views later 272 new users, or 10.1%
With 293 signups at 2856 views, 10.25%
At 306 signups at 2965 views, 10.32%
Learnings
1. My initial estimations were wildly inaccurate
I wrote 30% conversion. Reading some articles, looks like 10% is a good number to aim for.
2. Paying attention to what matters rather than vain metrics
The Lean Startup discourages vanity metrics. Feel-good metrics that don't measure growth or traction. Considering the proportion instead of the total visitors made me realize there was something here.
What’s next?
There are lots of work to do. Data aggregation, display, website development, marketing, legal issues. Fun! It's satisfying to solve an issue rather than investigate its cause.
In the meantime, I’ve already written the first project update in another post. Continue reading it if you’d like to know more about the project itself! Shifting from Quantity to Quality — DbSchemaLibrary