




More on Web3 & Crypto
Langston Thomas
4 years ago
A Simple Guide to NFT Blockchains
Ethereum's blockchain rules NFTs. Many consider it the one-stop shop for NFTs, and it's become the most talked-about and trafficked blockchain in existence.
Other blockchains are becoming popular in NFTs. Crypto-artists and NFT enthusiasts have sought new places to mint and trade NFTs due to Ethereum's high transaction costs and environmental impact.
When choosing a blockchain to mint on, there are several factors to consider. Size, creator costs, consumer spending habits, security, and community input are important. We've created a high-level summary of blockchains for NFTs to help clarify the fast-paced world of web3 tech.
Ethereum
Ethereum currently has the most NFTs. It's decentralized and provides financial and legal services without intermediaries. It houses popular NFT marketplaces (OpenSea), projects (CryptoPunks and the Bored Ape Yacht Club), and artists (Pak and Beeple).
It's also expensive and energy-intensive. This is because Ethereum works using a Proof-of-Work (PoW) mechanism. PoW requires computers to solve puzzles to add blocks and transactions to the blockchain. Solving these puzzles requires a lot of computer power, resulting in astronomical energy loss.
You should consider this blockchain first due to its popularity, security, decentralization, and ease of use.
Solana
Solana is a fast programmable blockchain. Its proof-of-history and proof-of-stake (PoS) consensus mechanisms eliminate complex puzzles. Reduced validation times and fees result.
PoS users stake their cryptocurrency to become a block validator. Validators get SOL. This encourages and rewards users to become stakers. PoH works with PoS to cryptographically verify time between events. Solana blockchain ensures transactions are in order and found by the correct leader (validator).
Solana's PoS and PoH mechanisms keep transaction fees and times low. Solana isn't as popular as Ethereum, so there are fewer NFT marketplaces and blockchain traders.
Tezos
Tezos is a greener blockchain. Tezos rose in 2021. Hic et Nunc was hailed as an economic alternative to Ethereum-centric marketplaces until Nov. 14, 2021.
Similar to Solana, Tezos uses a PoS consensus mechanism and only a PoS mechanism to reduce computational work. This blockchain uses two million times less energy than Ethereum. It's cheaper than Ethereum (but does cost more than Solana).
Tezos is a good place to start minting NFTs in bulk. Objkt is the largest Tezos marketplace.
Flow
Flow is a high-performance blockchain for NFTs, games, and decentralized apps (dApps). Flow is built with scalability in mind, so billions of people could interact with NFTs on the blockchain.
Flow became the NBA's blockchain partner in 2019. Flow, a product of Dapper labs (the team behind CryptoKitties), launched and hosts NBA Top Shot, making the blockchain integral to the popularity of non-fungible tokens.
Flow uses PoS to verify transactions, like Tezos. Developers are working on a model to handle 10,000 transactions per second on the blockchain. Low transaction fees.
Flow NFTs are tradeable on Blocktobay, OpenSea, Rarible, Foundation, and other platforms. NBA, NFL, UFC, and others have launched NFT marketplaces on Flow. Flow isn't as popular as Ethereum, resulting in fewer NFT marketplaces and blockchain traders.
Asset Exchange (WAX)
WAX is king of virtual collectibles. WAX is popular for digitalized versions of legacy collectibles like trading cards, figurines, memorabilia, etc.
Wax uses a PoS mechanism, but also creates carbon offset NFTs and partners with Climate Care. Like Flow, WAX transaction fees are low, and network fees are redistributed to the WAX community as an incentive to collectors.
WAX marketplaces host Topps, NASCAR, Hot Wheels, and cult classic film franchises like Godzilla, The Princess Bride, and Spiderman.
Binance Smart Chain
BSC is another good option for balancing fees and performance. High-speed transactions and low fees hurt decentralization. BSC is most centralized.
Binance Smart Chain uses Proof of Staked Authority (PoSA) to support a short block time and low fees. The 21 validators needed to run the exchange switch every 24 hours. 11 of the 21 validators are directly connected to the Binance Crypto Exchange, according to reports.
While many in the crypto and NFT ecosystems dislike centralization, the BSC NFT market picked up speed in 2021. OpenBiSea, AirNFTs, JuggerWorld, and others are gaining popularity despite not having as robust an ecosystem as Ethereum.

Scott Hickmann
4 years ago
Welcome
Welcome to Integrity's Web3 community!

Elnaz Sarraf
4 years ago
Why Bitcoin's Crash Could Be Good for Investors

The crypto market crashed in June 2022. Bitcoin and other cryptocurrencies hit their lowest prices in over a year, causing market panic. Some believe this crash will benefit future investors.
Before I discuss how this crash might help investors, let's examine why it happened. Inflation in the U.S. reached a 30-year high in 2022 after Russia invaded Ukraine. In response, the U.S. Federal Reserve raised interest rates by 0.5%, the most in almost 20 years. This hurts cryptocurrencies like Bitcoin. Higher interest rates make people less likely to invest in volatile assets like crypto, so many investors sold quickly.
The crypto market collapsed. Bitcoin, Ethereum, and Binance dropped 40%. Other cryptos crashed so hard they were delisted from almost every exchange. Bitcoin peaked in April 2022 at $41,000, but after the May interest rate hike, it crashed to $28,000. Bitcoin investors were worried. Even in bad times, this crash is unprecedented.
Bitcoin wasn't "doomed." Before the crash, LUNA was one of the top 5 cryptos by market cap. LUNA was trading around $80 at the start of May 2022, but after the rate hike?
Less than 1 cent. LUNA lost 99.99% of its value in days and was removed from every crypto exchange. Bitcoin's "crash" isn't as devastating when compared to LUNA.
Many people said Bitcoin is "due" for a LUNA-like crash and that the only reason it hasn't crashed is because it's bigger. Still false. If so, Bitcoin should be worth zero by now. We didn't. Instead, Bitcoin reached 28,000, then 29k, 30k, and 31k before falling to 18k. That's not the world's greatest recovery, but it shows Bitcoin's safety.
Bitcoin isn't falling constantly. It fell because of the initial shock of interest rates, but not further. Now, Bitcoin's value is more likely to rise than fall. Bitcoin's low price also attracts investors. They know what prices Bitcoin can reach with enough hype, and they want to capitalize on low prices before it's too late.

Bitcoin's crash was bad, but in a way it wasn't. To understand, consider 2021. In March 2021, Bitcoin surpassed $60k for the first time. Elon Musk's announcement in May that he would no longer support Bitcoin caused a massive crash in the crypto market. In May 2017, Bitcoin's price hit $29,000. Elon Musk's statement isn't worth more than the Fed raising rates. Many expected this big announcement to kill Bitcoin.

Not so. Bitcoin crashed from $58k to $31k in 2021. Bitcoin fell from $41k to $28k in 2022. This crash is smaller. Bitcoin's price held up despite tensions and stress, proving investors still believe in it. What happened after the initial crash in the past?
Bitcoin fell until mid-July. This is also something we’re not seeing today. After a week, Bitcoin began to improve daily. Bitcoin's price rose after mid-July. Bitcoin's price fluctuated throughout the rest of 2021, but it topped $67k in November. Despite no major changes, the peak occurred after the crash. Elon Musk seemed uninterested in crypto and wasn't likely to change his mind soon. What triggered this peak? Nothing, really. What really happened is that people got over the initial statement. They forgot.
Internet users have goldfish-like attention spans. People quickly forgot the crash's cause and were back investing in crypto months later. Despite the market's setbacks, more crypto investors emerged by the end of 2017. Who gained from these peaks? Bitcoin investors who bought low. Bitcoin not only recovered but also doubled its ROI. It was like a movie, and it shows us what to expect from Bitcoin in the coming months.
The current Bitcoin crash isn't as bad as the last one. LUNA is causing market panic. LUNA and Bitcoin are different cryptocurrencies. LUNA crashed because Terra wasn’t able to keep its peg with the USD. Bitcoin is unanchored. It's one of the most decentralized investments available. LUNA's distrust affected crypto prices, including Bitcoin, but it won't last forever.
This is why Bitcoin will likely rebound in the coming months. In 2022, people will get over the rise in interest rates and the crash of LUNA, just as they did with Elon Musk's crypto stance in 2021. When the world moves on to the next big controversy, Bitcoin's price will soar.
Bitcoin may recover for another reason. Like controversy, interest rates fluctuate. The Russian invasion caused this inflation. World markets will stabilize, prices will fall, and interest rates will drop.
Next, lower interest rates could boost Bitcoin's price. Eventually, it will happen. The U.S. economy can't sustain such high interest rates. Investors will put every last dollar into Bitcoin if interest rates fall again.
Bitcoin has proven to be a stable investment. This boosts its investment reputation. Even if Ethereum dethrones Bitcoin as crypto king one day (or any other crypto, for that matter). Bitcoin may stay on top of the crypto ladder for a while. We'll have to wait a few months to see if any of this is true.
This post is a summary. Read the full article here.
You might also like

Tim Denning
3 years ago
I Posted Six Times a Day for 210 Days on Twitter. Here's What Happened.
I'd spend hours composing articles only to find out they were useless. Twitter solved the problem.

Twitter is wrinkled, say critics.
Nope. Writing is different. It won't make sense until you write there.
Twitter is resurgent. People are reading again. 15-second TikToks overloaded our senses.
After nuking my 20,000-follower Twitter account and starting again, I wrote every day for 210 days.
I'll explain.
I came across the strange world of microblogging.
Traditional web writing is filler-heavy.
On Twitter, you must be brief. I played Wordle.
Twitter Threads are the most popular writing format. Like a blog post. It reminds me of the famous broetry posts on LinkedIn a few years ago.

Threads combine tweets into an article.
Sharp, concise sentences
No regard for grammar
As important as the information is how the text looks.
Twitter Threads are like Michael Angelo's David monument. He chipped away at an enormous piece of marble until a man with a big willy appeared.
That's Twitter Threads.
I tried to remove unnecessary layers from several of my Wordpress blog posts. Then I realized something.
Tweeting from scratch is easier and more entertaining. It's quicker and makes you think more concisely.
Superpower: saying much with little words. My long-form writing has improved. My article sentences resemble tweets.
You never know what will happen.
Twitter's subcultures are odd. Best-performing tweets are strange.
Unusual trend: working alone and without telling anyone. It's a rebellion against Instagram influencers who share their every moment.
Early on, random thoughts worked:
My friend’s wife is Ukrainian. Her family are trapped in the warzone. He is devastated. And here I was complaining about my broken garage door. War puts everything in perspective. Today is a day to be grateful for peace.
Documenting what's happening triggers writing. It's not about viral tweets. Helping others matters.
There are numerous anonymous users.
Twitter uses pseudonyms.
You don't matter. On sites like LinkedIn, you must use your real name. Welcome to the Cyberpunk metaverse of Twitter :)
One daily piece of writing is a powerful habit.
Habits build creator careers. Read that again.
Twitter is an easy habit to pick up. If you can't tweet in one sentence, something's wrong. Easy-peasy-japanese.
Not what I tweeted, but my constancy, made the difference.
Daily writing is challenging, especially if your supervisor is on your back. Twitter encourages writing.
Tweets evolved as the foundation of all other material.
During my experiment, I enjoyed Twitter's speed.
Tweets get immediate responses, comments, and feedback. My popular tweets become newspaper headlines. I've also written essays from tweet discussions.
Sometimes the tweet and article were clear. Twitter sometimes helped me overcome writer's block.
I used to spend hours composing big things that had little real-world use.
Twitter helped me. No guessing. Data guides my coverage and validates concepts.
Test ideas on Twitter.
It took some time for my email list to grow.
Subscribers are a writer's lifeblood.
Without them, you're broke and homeless when Mark Zuckerberg tweaks the algorithms for ad dollars. Twitter has three ways to obtain email subscribers:
1. Add a link to your bio.
Twitter allows bio links (LinkedIn now does too). My eBook's landing page is linked. I collect emails there.
2. Start an online newsletter.
Twitter bought newsletter app Revue. They promote what they own.
I just established up a Revue email newsletter. I imported them weekly into my ConvertKit email list.
3. Create Twitter threads and include a link to your email list in the final tweet.
Write Twitter Threads and link the last tweet to your email list (example below).
Initial email subscribers were modest.
Numbers are growing. Twitter provides 25% of my new email subscribers. Some days, 50 people join.
Without them, my writing career is over. I'd be back at a 9-5 job begging for time off to spend with my newborn daughter. Nope.
Collect email addresses or die trying.
As insurance against unsubscribes and Zucks, use a second email list or Discord community.
What I still need to do
Twitter's fun. I'm wiser. I need to enable auto-replies and auto-DMs (direct messages).
This adds another way to attract subscribers. I schedule tweets with Tweet Hunter.
It’s best to go slow. People assume you're an internet marketer if you spam them with click requests.
A human internet marketer is preferable to a robot. My opinion.
210 days on Twitter taught me that. I plan to use the platform until I'm a grandfather unless Elon ruins it.

Quant Galore
3 years ago
I created BAW-IV Trading because I was short on money.
More retail traders means faster, more sophisticated, and more successful methods.
Tech specifications
Only requires a laptop and an internet connection.
We'll use OpenBB's research platform for data/analysis.
Pricing and execution on Options-Quant

Background
You don't need to know the arithmetic details to use this method.
Black-Scholes is a popular option pricing model. It's best for pricing European options. European options are only exercisable at expiration, unlike American options. American options are always exercisable.
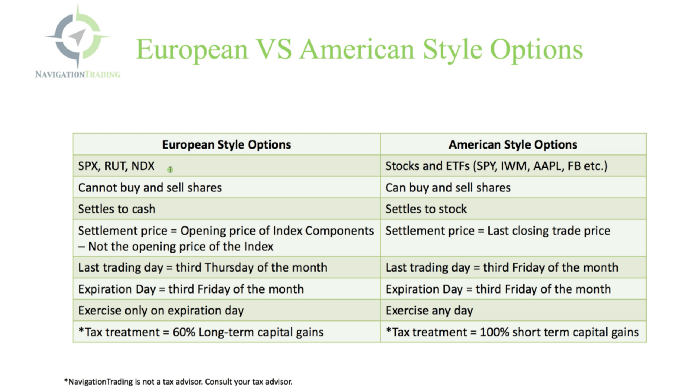
American options carry a premium to cover for the risk of early exercise. The Black-Scholes model doesn't account for this premium, hence it can't price genuine, traded American options.
Barone-Adesi-Whaley (BAW) model. BAW modifies Black-Scholes. It accounts for exercise risk premium and stock dividends. It adds the option's early exercise value to the Black-Scholes value.
The trader need not know the formulaic derivations of this model.
https://ir.nctu.edu.tw/bitstream/11536/14182/1/000264318900005.pdf
Strategy
This strategy targets implied volatility. First, we'll locate liquid options that expire within 30 days and have minimal implied volatility.
After selecting the option that meets the requirements, we price it to get the BAW implied volatility (we choose BAW because it's a more accurate Black-Scholes model). If estimated implied volatility is larger than market volatility, we'll capture the spread.
(Calculated IV — Market IV) = (Profit)
Some approaches to target implied volatility are pricey and inaccessible to individual investors. The best and most cost-effective alternative is to acquire a straddle and delta hedge. This may sound terrifying and pricey, but as shown below, it's much less so.
The Trade
First, we want to find our ideal option, so we use OpenBB terminal to screen for options that:
Have an IV at least 5% lower than the 20-day historical IV
Are no more than 5% out-of-the-money
Expire in less than 30 days
We query:
stocks/options/screen/set low_IV/scr --export Output.csv
This uses the screener function to screen for options that satisfy the above criteria, which we specify in the low IV preset (more on custom presets here). It then saves the matching results to a csv(Excel) file for viewing and analysis.
Stick to liquid names like SPY, AAPL, and QQQ since getting out of a position is just as crucial as getting in. Smaller, illiquid names have higher inefficiencies, which could restrict total profits.

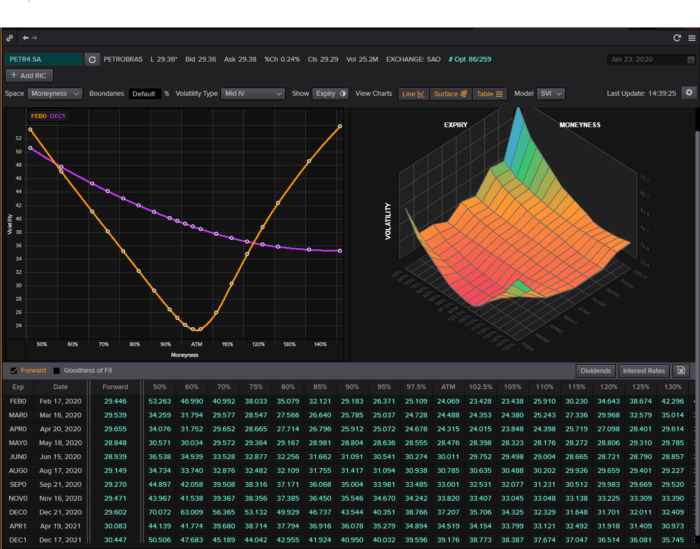
We calculate IV using the BAWbisection model (the bisection is a method of calculating IV, more can be found here.) We price the IV first.

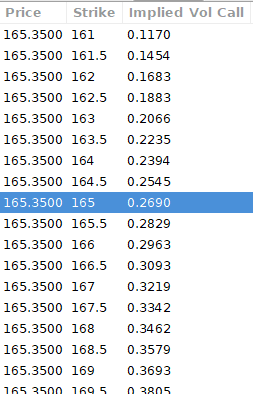
According to the BAW model, implied volatility at this level should be priced at 26.90%. When re-pricing the put, IV is 24.34%, up 3%.
Now it's evident. We must purchase the straddle (long the call and long the put) assuming the computed implied volatility is more appropriate and efficient than the market's. We just want to speculate on volatility, not price fluctuations, thus we delta hedge.
The Fun Starts
We buy both options for $7.65. (x100 multiplier). Initial delta is 2. For every dollar the stock price swings up or down, our position value moves $2.

We want delta to be 0 to avoid price vulnerability. A delta of 0 suggests our position's value won't change from underlying price changes. Being delta-hedged allows us to profit/lose from implied volatility. Shorting 2 shares makes us delta-neutral.

That's delta hedging. (Share price * shares traded) = $330.7 to become delta-neutral. You may have noted that delta is not truly 0.00. This is common since delta-hedging means getting as near to 0 as feasible, since it is rare for deltas to align at 0.00.
Now we're vulnerable to changes in Vega (and Gamma, but given we're dynamically hedging, it's not a big risk), or implied volatility. We wanted to gamble that the position's IV would climb by at least 2%, so we'll maintain it delta-hedged and watch IV.
Because the underlying moves continually, the option's delta moves continuously. A trader can short/long 5 AAPL shares at most. Paper trading lets you practice delta-hedging. Being quick-footed will help with this tactic.
Profit-Closing
As expected, implied volatility rose. By 10 minutes before market closure, the call's implied vol rose to 27% and the put's to 24%. This allowed us to sell the call for $4.95 and the put for $4.35, creating a profit of $165.

You may pull historical data to see how this trade performed. Note the implied volatility and pricing in the final options chain for August 5, 2022 (the position date).

Final Thoughts
Congratulations, that was a doozy. To reiterate, we identified tickers prone to increased implied volatility by screening OpenBB's low IV setting. We double-checked the IV by plugging the price into Options-BAW Quant's model. When volatility was off, we bought a straddle and delta-hedged it. Finally, implied volatility returned to a normal level, and we profited on the spread.
The retail trading space is very quickly catching up to that of institutions. Commissions and fees used to kill this method, but now they cost less than $5. Watching momentum, technical analysis, and now quantitative strategies evolve is intriguing.
I'm not linked with these sites and receive no financial benefit from my writing.
Tell me how your experience goes and how I helped; I love success tales.

Jayden Levitt
3 years ago
How to Explain NFTs to Your Grandmother, in Simple Terms

In simple terms, you probably don’t.
But try. Grandma didn't grow up with Facebook, but she eventually joined.
Perhaps the fear of being isolated outweighed the discomfort of learning the technology.
Grandmas are Facebook likers, sharers, and commenters.
There’s no stopping her.
Not even NFTs. Web3 is currently very complex.
It's difficult to explain what NFTs are, how they work, and why we might use them.
Three explanations.
1. Everything will be ours to own, both physically and digitally.
Why own something you can't touch? What's the point?
Blockchain technology proves digital ownership.
Untouchables need ownership proof. What?
Digital assets reduce friction, save time, and are better for the environment than physical goods.
Many valuable things are intangible. Feeling like your favorite brands. You'll pay obscene prices for clothing that costs pennies.
Secondly, NFTs Are Contracts. Agreements Have Value.
Blockchain technology will replace all contracts and intermediaries.
Every insurance contract, deed, marriage certificate, work contract, plane ticket, concert ticket, or sports event is likely an NFT.
We all have public wallets, like Grandma's Facebook page.
3. Your NFT Purchases Will Be Visible To Everyone.
Everyone can see your public wallet. What you buy says more about you than what you post online.
NFTs issued double as marketing collateral when seen on social media.
While I doubt Grandma knows who Snoop Dog is, imagine him or another famous person holding your NFT in his public wallet and the attention that could bring to you, your company, or brand.
This Technical Section Is For You
The NFT is a contract; its founders can add value through access, events, tuition, and possibly royalties.
Imagine Elon Musk releasing an NFT to his network. Or yearly business consultations for three years.
Christ-alive.
It's worth millions.
These determine their value.
No unsuspecting schmuck willing to buy your hot potato at zero. That's the trend, though.
Overpriced NFTs for low-effort projects created a bubble that has burst.
During a market bubble, you can make money by buying overvalued assets and selling them later for a profit, according to the Greater Fool Theory.
People are struggling. Some are ruined by collateralized loans and the gold rush.
Finances are ruined.
It's uncomfortable.
The same happened in 2018, during the ICO crash or in 1999/2000 when the dot com bubble burst. But the underlying technology hasn’t gone away.