More on Entrepreneurship/Creators

Athirah Syamimi
3 years ago
Here's How I Built A Business Offering Unlimited Design Services in Just One Weekend.

Weekend project: limitless design service. It was fun to see whether I could start a business quickly.
I use no-code apps to save time and resources.
TL;DR I started a business utilizing EditorX for my website, Notion for client project management, and a few favors to finish my portfolio.
First step: research (Day 1)
I got this concept from a Kimp Instagram ad. The Minimalist Hustler Daily newsletter mentioned a similar and cheaper service (Graphically).
I Googled other unlimited design companies. Many provide different costs and services. Some supplied solely graphic design, web development, or copywriting.
Step 2: Brainstorming (Day 1)
I did something simple.
What benefits and services to provide
Price to charge
Since it's a one-person performance (for now), I'm focusing on graphic design. I can charge less.
So I don't overwhelm myself and can accommodate budget-conscious clientele.
Step 3: Construction (Day 1 & 2)
This project includes a management tool, a website, and a team procedure.
I built a project management tool and flow first. Once I had the flow and a Notion board, I tested it with design volunteers. They fake-designed while I built the website.
Tool for Project Management
I modified a Notion template. My goal is to keep clients and designers happy.
Team Approach
My sister, my partner, and I kept this business lean. I tweaked the Notion board to make the process smooth. By the end of Sunday, I’d say it’s perfect!
Website
I created the website after they finished the fake design demands. EditorX's drag-and-drop builder attracted me. I didn't need to learn code, and there are templates.
I used a template wireframe.
This project's hardest aspect is developing the site. It's my first time using EditorX and I'm no developer.
People answer all your inquiries in a large community forum.
As a first-time user developing a site in two days, I think I performed OK. Here's the site for feedback.

4th step: testing (Day 2)
Testing is frustrating because it works or doesn't. My testing day was split in two.
testing the workflow from payment to onboarding to the website
the demand being tested
It's working so far. If someone gets the trial, they can request design work.
I've gotten a couple of inquiries about demand. I’ll be working with them as a start.
Completion
Finally! I built my side project in one weekend. It's too early to tell if this is successful. I liked that I didn't squander months of resources testing out an idea.

Bastian Hasslinger
3 years ago
Before 2021, most startups had excessive valuations. It is currently causing issues.

Higher startup valuations are often favorable for all parties. High valuations show a business's potential. New customers and talent are attracted. They earn respect.
Everyone benefits if a company's valuation rises.
Founders and investors have always been incentivized to overestimate a company's value.
Post-money valuations were inflated by 2021 market expectations and the valuation model's mechanisms.
Founders must understand both levers to handle a normalizing market.
2021, the year of miracles
2021 must've seemed miraculous to entrepreneurs, employees, and VCs. Valuations rose, and funding resumed after the first Covid-19 epidemic caution.
In 2021, VC investments increased from $335B to $643B. 518 new worldwide unicorns vs. 134 in 2020; 951 US IPOs vs. 431.
Things can change quickly, as 2020-21 showed.
Rising interest rates, geopolitical developments, and normalizing technology conditions drive down share prices and tech company market caps in 2022. Zoom, the poster-child of early lockdown success, is down 37% since 1st Jan.
Once-inflated valuations can become a problem in a normalizing market, especially for founders, employees, and early investors.
the reason why startups are always overvalued
To see why inflated valuations are a problem, consider one of its causes.
Private company values only fluctuate following a new investment round, unlike publicly-traded corporations. The startup's new value is calculated simply:
(Latest round share price) x (total number of company shares)
This is the industry standard Post-Money Valuation model.
Let’s illustrate how it works with an example. If a VC invests $10M for 1M shares (at $10/share), and the company has 10M shares after the round, its Post-Money Valuation is $100M (10/share x 10M shares).
This approach might seem like the most natural way to assess a business, but the model often unintentionally overstates the underlying value of the company even if the share price paid by the investor is fair. All shares aren't equal.
New investors in a corporation will always try to minimize their downside risk, or the amount they lose if things go wrong. New investors will try to negotiate better terms and pay a premium.
How the value of a struggling SpaceX increased
SpaceX's 2008 Series D is an example. Despite the financial crisis and unsuccessful rocket launches, the company's Post-Money Valuation was 36% higher after the investment round. Why?
Series D SpaceX shares were protected. In case of liquidation, Series D investors were guaranteed a 2x return before other shareholders.
Due to downside protection, investors were willing to pay a higher price for this new share class.
The Post-Money Valuation model overpriced SpaceX because it viewed all the shares as equal (they weren't).
Why entrepreneurs, workers, and early investors stand to lose the most
Post-Money Valuation is an effective and sufficient method for assessing a startup's valuation, despite not taking share class disparities into consideration.
In a robust market, where the firm valuation will certainly expand with the next fundraising round or exit, the inflated value is of little significance.
Fairness endures. If a corporation leaves at a greater valuation, each stakeholder will receive a proportional distribution. (i.e., 5% of a $100M corporation yields $5M).
SpaceX's inherent overvaluation was never a problem. Had it been sold for less than its Post-Money Valuation, some shareholders, including founders, staff, and early investors, would have seen their ownership drop.
The unforgiving world of 2022
In 2022, founders, employees, and investors who benefited from inflated values will face below-valuation exits and down-rounds.
For them, 2021 will be a curse, not a blessing.
Some tech giants are worried. Klarna's valuation fell from $45B (Oct 21) to $30B (Jun 22), Canvas from $40B to $27B, and GoPuffs from $17B to $8.3B.
Shazam and Blue Apron have to exit or IPO at a cheaper price. Premium share classes are protected, while others receive less. The same goes for bankrupts.
Those who continue at lower valuations will lose reputation and talent. When their value declines by half, generous employee stock options become less enticing, and their ability to return anything is questioned.
What can we infer about the present situation?
Such techniques to enhance your company's value or stop a normalizing market are fiction.
The current situation is a painful reminder for entrepreneurs and a crucial lesson for future firms.
The devastating market fall of the previous six months has taught us one thing:
Keep in mind that any valuation is speculative. Money Post A startup's valuation is a highly simplified approximation of its true value, particularly in the early phases when it lacks significant income or a cutting-edge product. It is merely a projection of the future and a hypothetical meter. Until it is achieved by an exit, a valuation is nothing more than a number on paper.
Assume the value of your company is lower than it was in the past. Your previous valuation might not be accurate now due to substantial changes in the startup financing markets. There is little reason to think that your company's value will remain the same given the 50%+ decline in many newly listed IT companies. Recognize how the market situation is changing and use caution.
Recognize the importance of the stake you hold. Each share class has a unique value that varies. Know the sort of share class you own and how additional contractual provisions affect the market value of your security. Frameworks have been provided by Metrick and Yasuda (Yale & UC) and Gornall and Strebulaev (Stanford) for comprehending the terms that affect investors' cash-flow rights upon withdrawal. As a result, you will be able to more accurately evaluate your firm and determine the worth of each share class.
Be wary of approving excessively protective share terms.
The trade-offs should be considered while negotiating subsequent rounds. Accepting punitive contractual terms could first seem like a smart option in order to uphold your inflated worth, but you should proceed with caution. Such provisions ALWAYS result in misaligned shareholders, with common shareholders (such as you and your staff) at the bottom of the list.

Matthew O'Riordan
3 years ago
Trends in SaaS Funding from 2016 to 2022
Christopher Janz of Point Nine Capital created the SaaS napkin in 2016. This post shows how founders have raised cash in the last 6 years. View raw data.
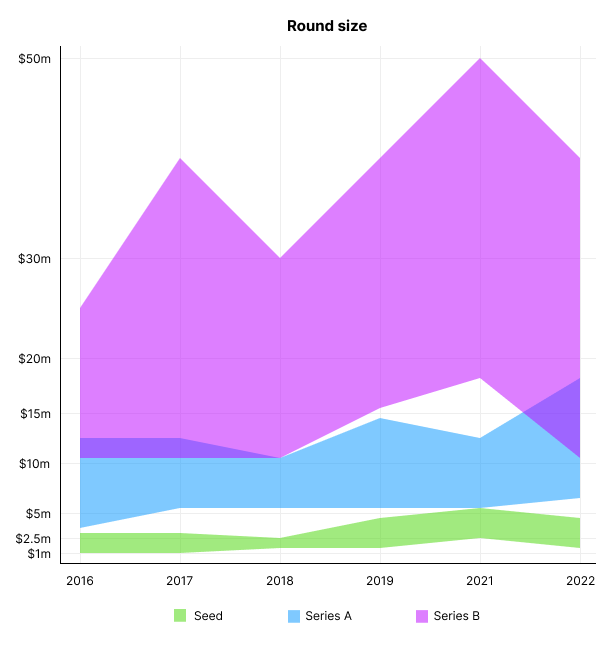
Round size
Unsurprisingly, round sizes have expanded and will taper down in 2022. In 2016, pre-seed rounds were $200k to $500k; currently, they're $1-$2m. Despite the macroeconomic scenario, Series A have expanded from $3m to $12m in 2016 to $6m and $18m in 2022.
Valuation
There are hints that valuations are rebounding this year. Pre-seed valuations in 2022 are $12m from $3m in 2016, and Series B prices are $270m from $100m in 2016.
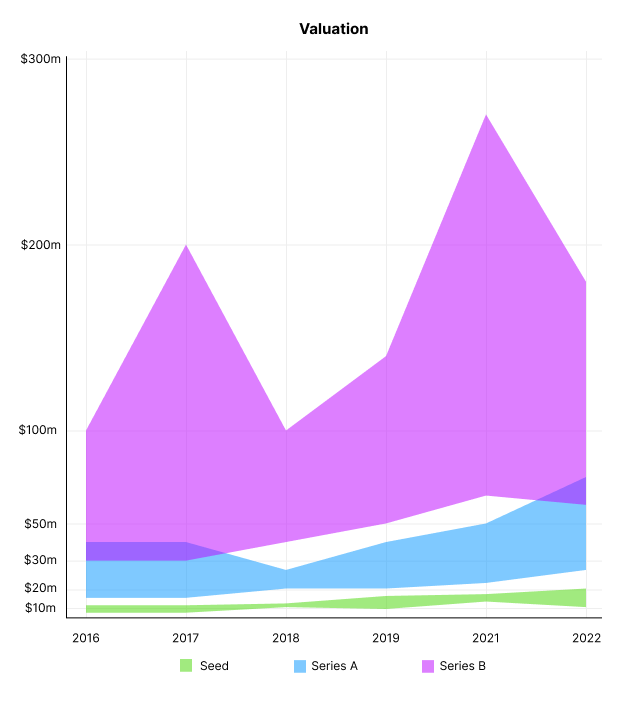
Compared to public SaaS multiples, Series B valuations more closely reflect the market, but Seed and Series A prices seem to be inflated regardless of the market.
I'd like to know how each annual cohort performed for investors, based on the year they invested and the valuations. I can't access this information.
ARR
Seed firms' ARR forecasts have risen from $0 to $0.6m to $0 to $1m. 2016 expected $1.2m to $3m, 2021 $0.5m to $4m, and this year $0.5m to $2.5m, suggesting that Series A firms may raise with less ARR today. Series B minutes fell from $4.2m to $3m.
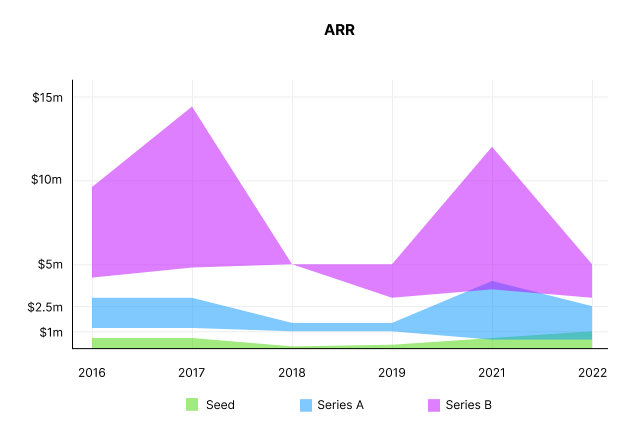
Capitalization Rate
2022 is the year that VCs start discussing capital efficiency in portfolio meetings. Given the economic shift in the markets and the stealthy VC meltdown, it's not surprising. Christopher Janz added capital efficiency to the SaaS Napkin as a new statistic for Series A (3.5x) and Series B. (2.5x). Your investors must live under a rock if they haven't asked about capital efficiency. If you're unsure:
The Capital Efficiency Ratio is the ratio of how much a company has spent growing revenue and how much they’re receiving in return. It is the broadest measure of company effectiveness in generating ARR
What next?
No one knows what's next, including me. All startup and growing enterprises around me are tightening their belts and extending their runways in anticipation of a difficult fundraising ride. If you're wanting to raise money but can wait, wait till the market is more stable and access to money is easier.
You might also like

Bloomberg
4 years ago
Expulsion of ten million Ukrainians
According to recent data from two UN agencies, ten million Ukrainians have been displaced.
The International Organization for Migration (IOM) estimates nearly 6.5 million Ukrainians have relocated. Most have fled the war zones around Kyiv and eastern Ukraine, including Dnipro, Zhaporizhzhia, and Kharkiv. Most IDPs have fled to western and central Ukraine.
Since Russia invaded on Feb. 24, 3.6 million people have crossed the border to seek refuge in neighboring countries, according to the latest UN data. While most refugees have fled to Poland and Romania, many have entered Russia.
Internally displaced figures are IOM estimates as of March 19, based on 2,000 telephone interviews with Ukrainians aged 18 and older conducted between March 9-16. The UNHCR compiled the figures for refugees to neighboring countries on March 21 based on official border crossing data and its own estimates. The UNHCR's top-line total is lower than the country totals because Romania and Moldova totals include people crossing between the two countries.
Sources: IOM, UNHCR
According to IOM estimates based on telephone interviews with a representative sample of internally displaced Ukrainians, over 53% of those displaced are women, and over 60% of displaced households have children.

Aniket
3 years ago
Yahoo could have purchased Google for $1 billion
Let's see this once-dominant IT corporation crumble.

What's the capital of Kazakhstan? If you don't know the answer, you can probably find it by Googling. Google Search returned results for Nur-Sultan in 0.66 seconds.
Google is the best search engine I've ever used. Did you know another search engine ruled the Internet? I'm sure you guessed Yahoo!
Google's friendly UI and wide selection of services make it my top choice. Let's explore Yahoo's decline.
Yahoo!
YAHOO stands for Yet Another Hierarchically Organized Oracle. Jerry Yang and David Filo established Yahoo.
Yahoo is primarily a search engine and email provider. It offers News and an advertising platform. It was a popular website in 1995 that let people search the Internet directly. Yahoo began offering free email in 1997 by acquiring RocketMail.
According to a study, Yahoo used Google Search Engine technology until 2000 and then developed its own in 2004.
Yahoo! rejected buying Google for $1 billion
Larry Page and Sergey Brin, Google's founders, approached Yahoo in 1998 to sell Google for $1 billion so they could focus on their studies. Yahoo denied the offer, thinking it was overvalued at the time.
Yahoo realized its error and offered Google $3 billion in 2002, but Google demanded $5 billion since it was more valuable. Yahoo thought $5 billion was overpriced for the existing market.
In 2022, Google is worth $1.56 Trillion.
What happened to Yahoo!
Yahoo refused to buy Google, and Google's valuation rose, making a purchase unfeasible.
Yahoo started losing users when Google launched Gmail. Google's UI was far cleaner than Yahoo's.
Yahoo offered $1 billion to buy Facebook in July 2006, but Zuckerberg and the board sought $1.1 billion. Yahoo rejected, and Facebook's valuation rose, making it difficult to buy.
Yahoo was losing users daily while Google and Facebook gained many. Google and Facebook's popularity soared. Yahoo lost value daily.
Microsoft offered $45 billion to buy Yahoo in February 2008, but Yahoo declined. Microsoft increased its bid to $47 billion after Yahoo said it was too low, but Yahoo rejected it. Then Microsoft rejected Yahoo’s 10% bid increase in May 2008.
In 2015, Verizon bought Yahoo for $4.5 billion, and Apollo Global Management bought 90% of Yahoo's shares for $5 billion in May 2021. Verizon kept 10%.
Yahoo's opportunity to acquire Google and Facebook could have been a turning moment. It declined Microsoft's $45 billion deal in 2008 and was sold to Verizon for $4.5 billion in 2015. Poor decisions and lack of vision caused its downfall. Yahoo's aim wasn't obvious and it didn't stick to a single domain.
Hence, a corporation needs a clear vision and a leader who can see its future.
Liked this article? Join my tech and programming newsletter here.

Jack Shepherd
3 years ago
A Dog's Guide to Every Type of Zoom Call Participant
Are you one of these Zoom dogs?
The Person Who Is Apparently Always on Mute
Waffles thinks he can overpower the mute button by shouting loudly.
The person who believed their camera to be off
Barkley's used to remote work, but he hasn't mastered the "Stop Video" button. Everyone is affected.
Who is driving for some reason, exactly?
Why is Pumpkin always late? Who knows? Shouldn't she be driving? If you could hear her over the freeway, she'd answer these questions.
The Person With the Amazing Bookcase
Cicero likes to use SAT-words like "leverage" and "robust" in Zoom sessions, presumably from all the books he wants you to see behind him.
The Individual Who Is Unnecessarily Dressed
We hope Bandit is going somewhere beautiful after this meeting, or else he neglected the quarterly earnings report and is overcompensating to distract us.
The person who works through lunch in between zoom calls
Barksworth has back-to-back meetings all day, so you can watch her eat while she talks.
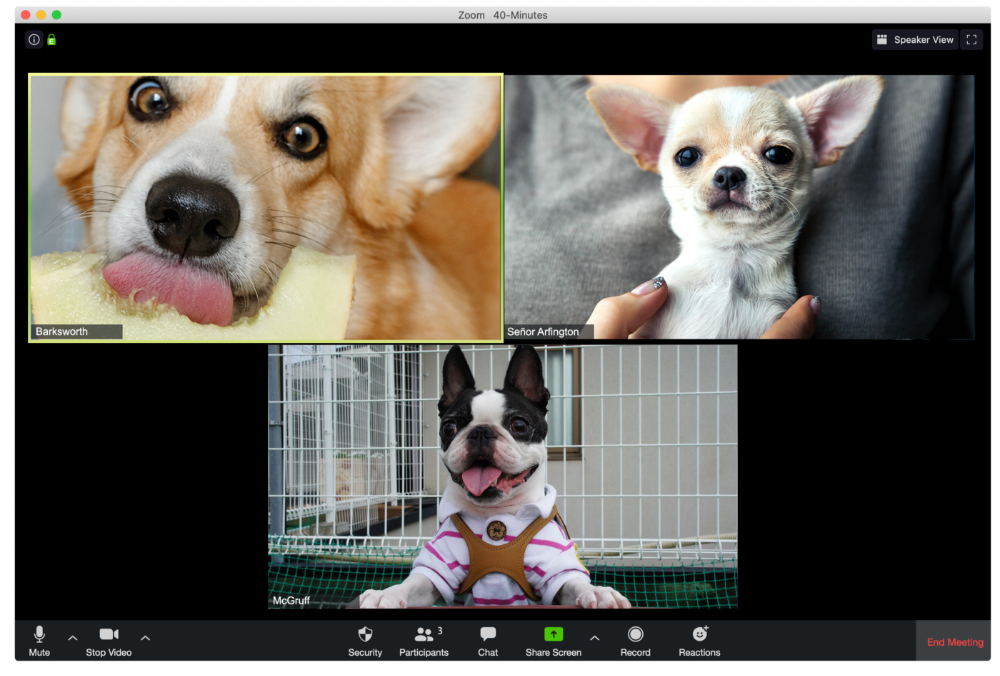
The Person Who Is A Little Too Comfy
Hercules thinks Zoom meetings happen between sleeps. He'd appreciate everyone speaking more quietly.
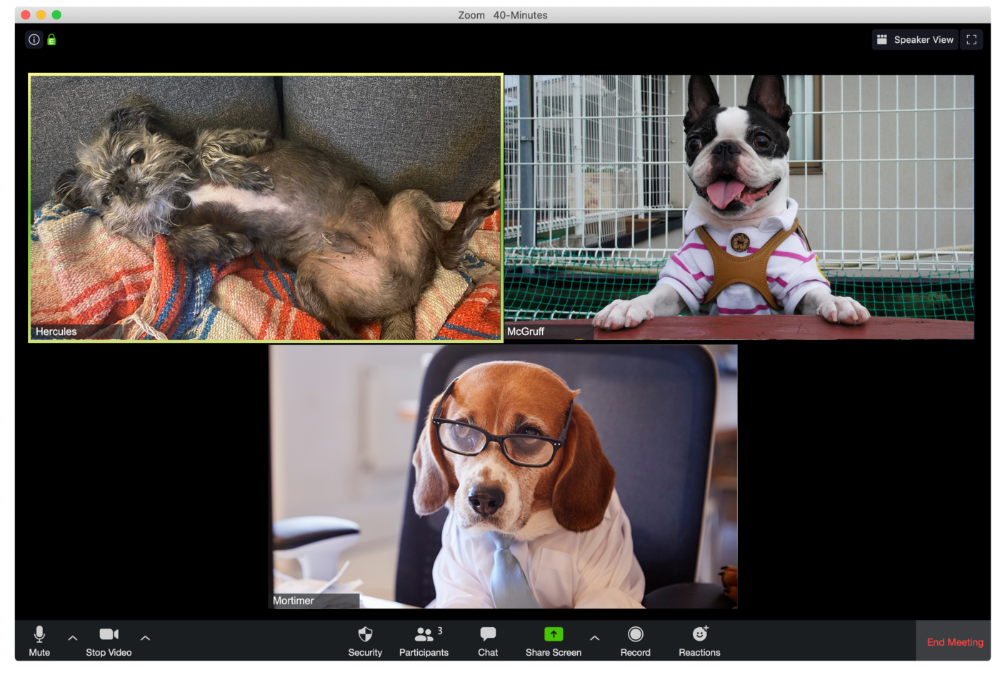
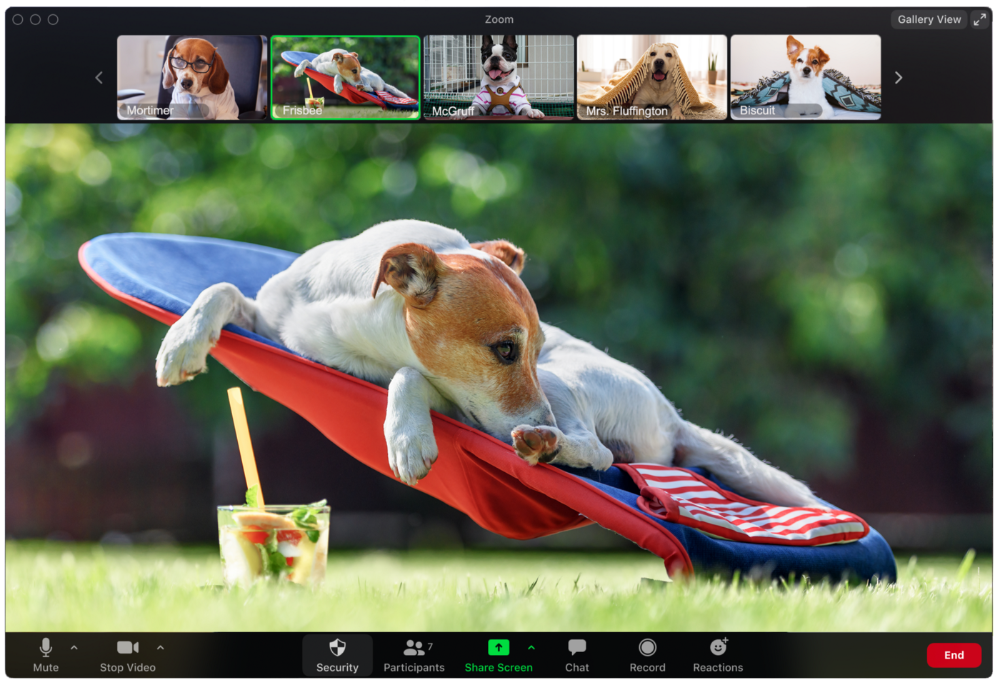
The Person Who Answered the Phone Outside
Frisbee has a gorgeous backyard and lives in a place with great weather year-round, and she wants you to think about that during the daily team huddle.
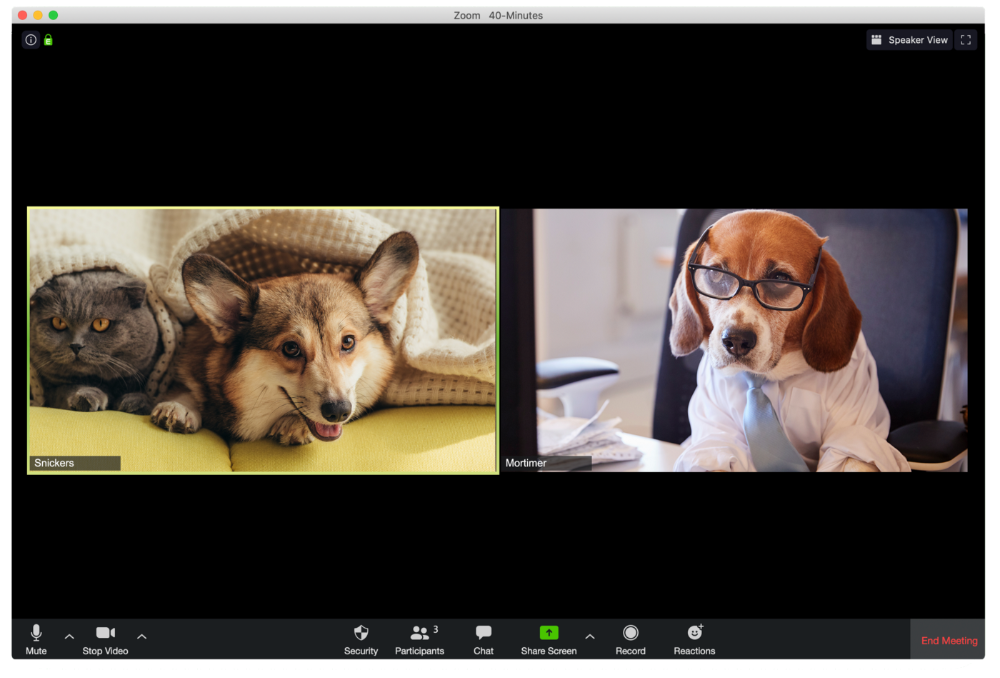
Who Wants You to Pay Attention to Their Pet
Snickers hasn't listened to you in 20 minutes unless you tell her how cute her kitten is.
One who is, for some reason, positioned incorrectly on the screen
Nelson's meetings consist primarily of attempting to figure out how he positioned his laptop so absurdly.

The person who says too many goodbyes
Zeus waves farewell like it's your first day of school while everyone else searches for the "Leave Meeting" button. It's nice.
He who has a poor internet connection
Ziggy's connectivity problems continue... She gives a long speech as everyone waits awkwardly to inform her they missed it.
The Clearly Multitasking Person
Tinkerbell can play fetch during the monthly staff meeting if she works from home, but that's not a good idea.
The Person Using Zoom as a Makeup and Hair Mirror
If Gail and Bob knew Zoom had a "hide self view" option, they'd be distraught.

The person who feels at ease with simply leaving
Rusty bails when a Zoom conference is over. Rusty's concept is decent.