


More on Entrepreneurship/Creators

Mircea Iosif
3 years ago
How To Start An Online Business That Will Be Profitable Without Investing A Lot Of Time

Don't know how to start an online business? Here's a guide. By following these recommendations, you can build a lucrative and profitable online business.
What Are Online Businesses Used For?
Most online businesses are websites. A self-created, self-managed website. You may sell things and services online.
To establish an internet business, you must locate a host and set up accounts with numerous companies. Once your accounts are set up, you may start publishing content and selling products or services.
How to Make Money from Your Online Business
Advertising and marketing are the best ways to make money online. You must develop strategies to contact new customers and generate leads. Make sure your website is search engine optimized so people can find you online.
Top 5 Online Business Tips for Startups:
1. Know your target audience's needs.
2. Make your website as appealing as possible.
3. Generate leads and sales with marketing.
4. Track your progress and learn from your mistakes to improve.
5. Be prepared to expand into new markets or regions.
How to Launch a Successful Online Business Without Putting in a Lot of Work
Build with a solid business model to start a profitable online business. By using these tips, you can start your online business without paying much.
First, develop a user-friendly website. You can use an internet marketing platform or create your own website. Once your website is live, optimize it for search engines and add relevant content.
Second, sell online. This can be done through ads or direct sales to website visitors. Finally, use social media to advertise your internet business. By accomplishing these things, you'll draw visitors to your website and make money.
When launching a business, invest long-term. This involves knowing your goals and how you'll pay for them. Volatility can have several effects on your business. If you offer things online, you may need to examine if the market is ready for them.
Invest wisely
Investing all your money in one endeavor can lead to too much risk and little ROI. Diversify your investments to take advantage of all available chances. So, your investments won't encounter unexpected price swings and you'll be immune to economic upheavals.
Financial news updates
When launching or running a thriving online business, financial news is crucial. By knowing current trends and upcoming developments, you can keep your business lucrative.
Keeping up with financial news can also help you avoid potential traps that could harm your bottom line. If you don't know about new legislation that could affect your industry, potential customers may choose another store when they learn about your business's problems.
Volatility ahead
You should expect volatility in the financial sector. Without a plan for coping with volatility, you could run into difficulty. If your organization relies on client input, you may not be able to exploit customer behavior shifts.
Your company could go bankrupt if you don't understand how fickle the stock market can be. By preparing for volatility, you can ensure your organization survives difficult times and market crashes.
Conclusion
Many internet businesses can be profitable. Start quickly with a few straightforward steps. Diversify your investments, follow financial news, and be prepared for volatility to develop a successful business.
Thanks for reading!

Jim Siwek
3 years ago
In 2022, can a lone developer be able to successfully establish a SaaS product?

In the early 2000s, I began developing SaaS. I helped launch an internet fax service that delivered faxes to email inboxes. Back then, it saved consumers money and made the procedure easier.
Google AdWords was young then. Anyone might establish a new website, spend a few hundred dollars on keywords, and see dozens of new paying clients every day. That's how we launched our new SaaS, and these clients stayed for years. Our early ROI was sky-high.
Changing times
The situation changed dramatically after 15 years. Our paid advertising cost $200-$300 for every new customer. Paid advertising takes three to four years to repay.
Fortunately, we still had tens of thousands of loyal clients. Good organic rankings gave us new business. We needed less sponsored traffic to run a profitable SaaS firm.
Is it still possible?
Since selling our internet fax firm, I've dreamed about starting a SaaS company. One I could construct as a lone developer and progressively grow a dedicated customer base, as I did before in a small team.
It seemed impossible to me. Solo startups couldn't afford paid advertising. SEO was tough. Even the worst SaaS startup ideas attracted VC funding. How could I compete with startups that could hire great talent and didn't need to make money for years (or ever)?
The One and Only Way to Learn
After years of talking myself out of SaaS startup ideas, I decided to develop and launch one. I needed to know if a solitary developer may create a SaaS app in 2022.
Thus, I did. I invented webwriter.ai, an AI-powered writing tool for website content, from hero section headlines to blog posts, this year. I soft-launched an MVP in July.
Considering the Issue
Now that I've developed my own fully capable SaaS app for site builders and developers, I wonder if it's still possible. Can webwriter.ai be successful?
I know webwriter.ai's proposal is viable because Jasper.ai and Grammarly are also AI-powered writing tools. With competition comes validation.
To Win, Differentiate
To compete with well-funded established brands, distinguish to stand out to a portion of the market. So I can speak directly to a target user, unlike larger competition.
I created webwriter.ai to help web builders and designers produce web content rapidly. This may be enough differentiation for now.
Budget-Friendly Promotion
When paid search isn't an option, we get inventive. There are more tools than ever to promote a new website.
Organic Results
on social media (Twitter, Instagram, TikTok, LinkedIn)
Marketing with content that is compelling
Link Creation
Listings in directories
references made in blog articles and on other websites
Forum entries
The Beginning of the Journey
As I've labored to construct my software, I've pondered a new mantra. Not sure where that originated from, but I like it. I'll live by it and teach my kids:
“Do the work.”

Aaron Dinin, PhD
3 years ago
I put my faith in a billionaire, and he destroyed my business.
How did his money blind me?

Like most fledgling entrepreneurs, I wanted a mentor. I met as many nearby folks with "entrepreneur" in their LinkedIn biographies for coffee.
These meetings taught me a lot, and I'd suggest them to any new creator. Attention! Meeting with many experienced entrepreneurs means getting contradictory advice. One entrepreneur will tell you to do X, then the next one you talk to may tell you to do Y, which are sometimes opposites. You'll have to chose which suggestion to take after the chats.
I experienced this. Same afternoon, I had two coffee meetings with experienced entrepreneurs. The first meeting was with a billionaire entrepreneur who took his company public.
I met him in a swanky hotel lobby and ordered a drink I didn't pay for. As a fledgling entrepreneur, money was scarce.
During the meeting, I demoed the software I'd built, he liked it, and we spent the hour discussing what features would make it a success. By the end of the meeting, he requested I include a killer feature we both agreed would attract buyers. The feature was complex and would require some time. The billionaire I was sipping coffee with in a beautiful hotel lobby insisted people would love it, and that got me enthusiastic.
The second meeting was with a young entrepreneur who had recently raised a small amount of investment and looked as eager to pitch me as I was to pitch him. I forgot his name. I mostly recall meeting him in a filthy coffee shop in a bad section of town and buying his pricey cappuccino. Water for me.
After his pitch, I demoed my app. When I was done, he barely noticed. He questioned my customer acquisition plan. Who was my client? What did they offer? What was my plan? Etc. No decent answers.
After our meeting, he insisted I spend more time learning my market and selling. He ignored my questions about features. Don't worry about features, he said. Customers will request features. First, find them.
Putting your faith in results over relevance
Problems plagued my afternoon. I met with two entrepreneurs who gave me differing advice about how to proceed, and I had to decide which to pursue. I couldn't decide.
Ultimately, I followed the advice of the billionaire.
Obviously.
Who wouldn’t? That was the guy who clearly knew more.
A few months later, I constructed the feature the billionaire said people would line up for.
The new feature was unpopular. I couldn't even get the billionaire to answer an email showing him what I'd done. He disappeared.
Within a few months, I shut down the company, wasting all the time and effort I'd invested into constructing the killer feature the billionaire said I required.
Would follow the struggling entrepreneur's advice have saved my company? It would have saved me time in retrospect. Potential consumers would have told me they didn't want what I was producing, and I could have shut down the company sooner or built something they did want. Both outcomes would have been better.
Now I know, but not then. I favored achievement above relevance.
Success vs. relevance
The millionaire gave me advice on building a large, successful public firm. A successful public firm is different from a startup. Priorities change in the last phase of business building, which few entrepreneurs reach. He gave wonderful advice to founders trying to double their stock values in two years, but it wasn't beneficial for me.
The other failing entrepreneur had relevant, recent experience. He'd recently been in my shoes. We still had lots of problems. He may not have achieved huge success, but he had valuable advice on how to pass the closest hurdle.
The money blinded me at the moment. Not alone So much of company success is defined by money valuations, fundraising, exits, etc., so entrepreneurs easily fall into this trap. Money chatter obscures the value of knowledge.
Don't base startup advice on a person's income. Focus on what and when the person has learned. Relevance to you and your goals is more important than a person's accomplishments when considering advice.
You might also like

Alex Mathers
3 years ago
12 habits of the zenith individuals I know
Calmness is a vital life skill.
It aids communication. It boosts creativity and performance.
I've studied calm people's habits for years. Commonalities:
Have mastered the art of self-humor.
Protectors take their job seriously, draining the room's energy.
They are fixated on positive pursuits like making cool things, building a strong physique, and having fun with others rather than on depressing influences like the news and gossip.
Every day, spend at least 20 minutes moving, whether it's walking, yoga, or lifting weights.
Discover ways to take pleasure in life's challenges.
Since perspective is malleable, they change their view.
Set your own needs first.
Stressed people neglect themselves and wonder why they struggle.
Prioritize self-care.
Don't ruin your life to please others.
Make something.
Calm people create more than react.
They love creating beautiful things—paintings, children, relationships, and projects.
Don’t hold their breath.
If you're stressed or angry, you may be surprised how much time you spend holding your breath and tightening your belly.
Release, breathe, and relax to find calm.
Stopped rushing.
Rushing is disadvantageous.
Calm people handle life better.
Are aware of their own dietary requirements.
They avoid junk food and eat foods that keep them healthy, happy, and calm.
Don’t take anything personally.
Stressed people control everything.
Self-conscious.
Calm people put others and their work first.
Keep their surroundings neat.
Maintaining an uplifting and clutter-free environment daily calms the mind.
Minimise negative people.
Calm people are ruthless with their boundaries and avoid negative and drama-prone people.
Colin Faife
3 years ago
The brand-new USB Rubber Ducky is much riskier than before.
The brand-new USB Rubber Ducky is much riskier than before.

With its own programming language, the well-liked hacking tool may now pwn you.
With a vengeance, the USB Rubber Ducky is back.
This year's Def Con hacking conference saw the release of a new version of the well-liked hacking tool, and its author, Darren Kitchen, was on hand to explain it. We put a few of the new features to the test and discovered that the most recent version is riskier than ever.
WHAT IS IT?
The USB Rubber Ducky seems to the untrained eye to be an ordinary USB flash drive. However, when you connect it to a computer, the computer recognizes it as a USB keyboard and will accept keystroke commands from the device exactly like a person would type them in.
Kitchen explained to me, "It takes use of the trust model built in, where computers have been taught to trust a human, in that anything it types is trusted to the same degree as the user is trusted. And a computer is aware that clicks and keystrokes are how people generally connect with it.

Over ten years ago, the first Rubber Ducky was published, quickly becoming a hacker favorite (it was even featured in a Mr. Robot scene). Since then, there have been a number of small upgrades, but the most recent Rubber Ducky takes a giant step ahead with a number of new features that significantly increase its flexibility and capability.
WHERE IS ITS USE?
The options are nearly unlimited with the proper strategy.
The Rubber Ducky has already been used to launch attacks including making a phony Windows pop-up window to collect a user's login information or tricking Chrome into sending all saved passwords to an attacker's web server. However, these attacks lacked the adaptability to operate across platforms and had to be specifically designed for particular operating systems and software versions.

The nuances of DuckyScript 3.0 are described in a new manual.
The most recent Rubber Ducky seeks to get around these restrictions. The DuckyScript programming language, which is used to construct the commands that the Rubber Ducky will enter into a target machine, receives a significant improvement with it. DuckyScript 3.0 is a feature-rich language that allows users to write functions, store variables, and apply logic flow controls, in contrast to earlier versions that were primarily limited to scripting keystroke sequences (i.e., if this... then that).
This implies that, for instance, the new Ducky can check to see if it is hooked into a Windows or Mac computer and then conditionally run code specific to each one, or it can disable itself if it has been attached to the incorrect target. In order to provide a more human effect, it can also generate pseudorandom numbers and utilize them to add a configurable delay between keystrokes.
The ability to steal data from a target computer by encoding it in binary code and transferring it through the signals intended to instruct a keyboard when the CapsLock or NumLock LEDs should light up is perhaps its most astounding feature. By using this technique, a hacker may plug it in for a brief period of time, excuse themselves by saying, "Sorry, I think that USB drive is faulty," and then take it away with all the credentials stored on it.
HOW SERIOUS IS THE RISK?
In other words, it may be a significant one, but because physical device access is required, the majority of people aren't at risk of being a target.
The 500 or so new Rubber Duckies that Hak5 brought to Def Con, according to Kitchen, were his company's most popular item at the convention, and they were all gone on the first day. It's safe to suppose that hundreds of hackers already possess one, and demand is likely to persist for some time.
Additionally, it has an online development toolkit that can be used to create attack payloads, compile them, and then load them onto the target device. A "payload hub" part of the website makes it simple for hackers to share what they've generated, and the Hak5 Discord is also busy with conversation and helpful advice. This makes it simple for users of the product to connect with a larger community.
It's too expensive for most individuals to distribute in volume, so unless your favorite cafe is renowned for being a hangout among vulnerable targets, it's doubtful that someone will leave a few of them there. To that end, if you intend to plug in a USB device that you discovered outside in a public area, pause to consider your decision.
WOULD IT WORK FOR ME?
Although the device is quite straightforward to use, there are a few things that could cause you trouble if you have no prior expertise writing or debugging code. For a while, during testing on a Mac, I was unable to get the Ducky to press the F4 key to activate the launchpad, but after forcing it to identify itself using an alternative Apple keyboard device ID, the problem was resolved.
From there, I was able to create a script that, when the Ducky was plugged in, would instantly run Chrome, open a new browser tab, and then immediately close it once more without requiring any action from the laptop user. Not bad for only a few hours of testing, and something that could be readily changed to perform duties other than reading technology news.

Darius Foroux
2 years ago
My financial life was changed by a single, straightforward mental model.
Prioritize big-ticket purchases
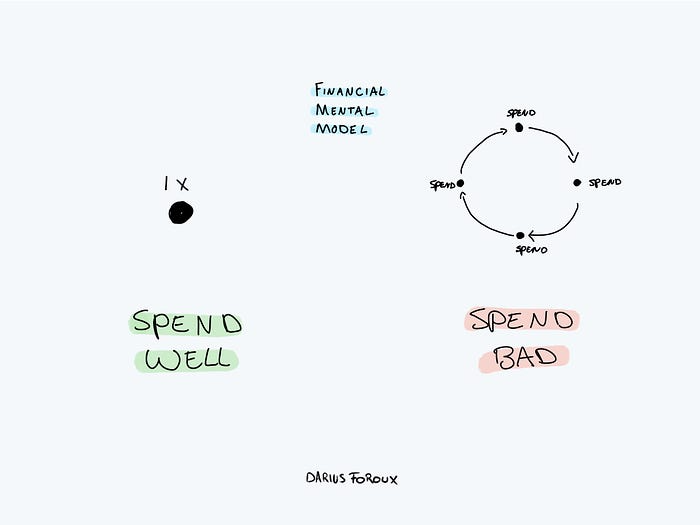
I've made several spending blunders. I get sick thinking about how much money I spent.
My financial mental model was poor back then.
Stoicism and mindfulness keep me from attaching to those feelings. It still hurts.
Until four or five years ago, I bought a new winter jacket every year.
Ten years ago, I spent twice as much. Now that I have a fantastic, warm winter parka, I don't even consider acquiring another one. No more spending. I'm not looking for jackets either.
Saving time and money by spending well is my thinking paradigm.
The philosophy is expressed in most languages. Cheap is expensive in the Netherlands. This applies beyond shopping.
In this essay, I will offer three examples of how this mental paradigm transformed my financial life.
Publishing books
In 2015, I presented and positioned my first book poorly.
I called the book Huge Life Success and made a funny Canva cover in 30 minutes. This:

That looks nothing like my present books. No logo or style. The book felt amateurish.
The book started bothering me a few weeks after publication. The advice was good, but it didn't appear professional. I studied the book business extensively.
I created a style for all my designs. Branding. Win Your Inner Wars was reissued a year later.
Title, cover, and description changed. Rearranging the chapters improved readability.
Seven years later, the book sells hundreds of copies a month. That taught me a lot.
Rushing to finish a project is enticing. Send it and move forward.
Avoid rushing everything. Relax. Develop your projects. Perform well. Perform the job well.
My first novel was underfunded and underworked. A bad book arrived. I then invested time and money in writing the greatest book I could.
That book still sells.
Traveling
I hate travel. Airports, flights, trains, and lines irritate me.
But, I enjoy traveling to beautiful areas.
I do it strangely. I make up travel rules. I never go to airports in summer. I hate being near airports on holidays. Unworthy.
No vacation packages for me. Those airline packages with a flight, shuttle, and hotel. I've had enough.
I try to avoid crowds and popular spots. July Paris? Nuts and bolts, please. Christmas in NYC? No, please keep me sane.
I fly business class behind. I accept upgrades upon check-in. I prefer driving. I drove from the Netherlands to southern Spain.
Thankfully, no lines. What if travel costs more? Thus? I enjoy it from the start. I start traveling then.
I rarely travel since I'm so difficult. One great excursion beats several average ones.
Personal effectiveness
New apps, tools, and strategies intrigue most productivity professionals.
No.
I researched years ago. I spent years investigating productivity in university.
I bought books, courses, applications, and tools. It was expensive and time-consuming.
Im finished. Productivity no longer costs me time or money. OK. I worked on it once and now follow my strategy.
I avoid new programs and systems. My stuff works. Why change winners?
Spending wisely saves time and money.
Spending wisely means spending once. Many people ignore productivity. It's understudied. No classes.
Some assume reading a few articles or a book is enough. Productivity is personal. You need a personal system.
Time invested is one-time. You can trust your system for life once you find it.
Concentrate on the expensive choices.
Life's short. Saving money quickly is enticing.
Spend less on groceries today. True. That won't fix your finances.
Adopt a lifestyle that makes you affluent over time. Consider major choices.
Are they causing long-term poverty? Are you richer?
Leasing cars comes to mind. The automobile costs a fortune today. The premium could accomplish a million nice things.
Focusing on important decisions makes life easier. Consider your future. You want to improve next year.