



More on Entrepreneurship/Creators

Navdeep Yadav
3 years ago
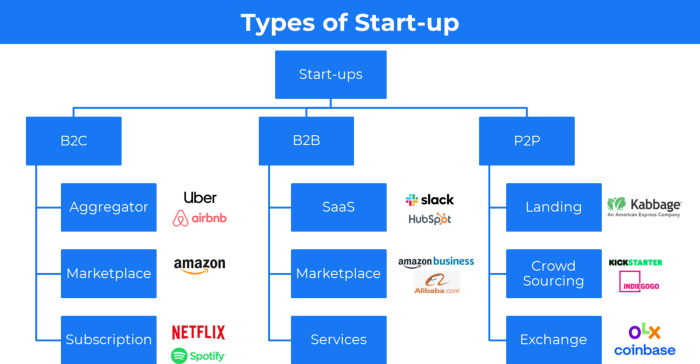
31 startup company models (with examples)
Many people find the internet's various business models bewildering.
This article summarizes 31 startup e-books.
1. Using the freemium business model (free plus premium),
The freemium business model offers basic software, games, or services for free and charges for enhancements.
Examples include Slack, iCloud, and Google Drive
Provide a rudimentary, free version of your product or service to users.
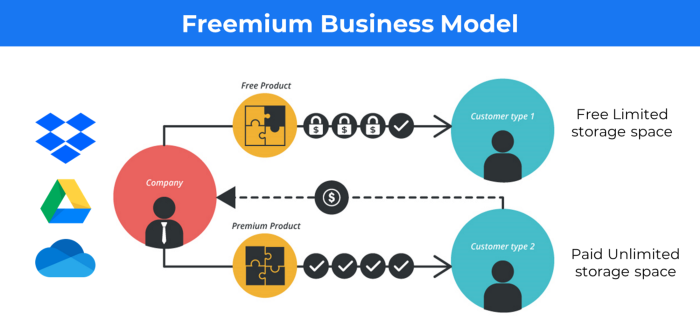
Google Drive and Dropbox offer 15GB and 2GB of free space but charge for more.
Freemium business model details (Click here)
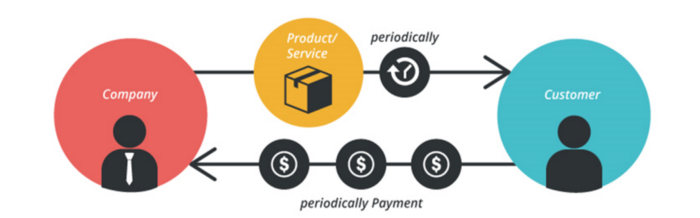
2. The Business Model of Subscription
Subscription business models sell a product or service for recurring monthly or yearly revenue.
Examples: Tinder, Netflix, Shopify, etc
It's the next step to Freemium if a customer wants to pay monthly for premium features.
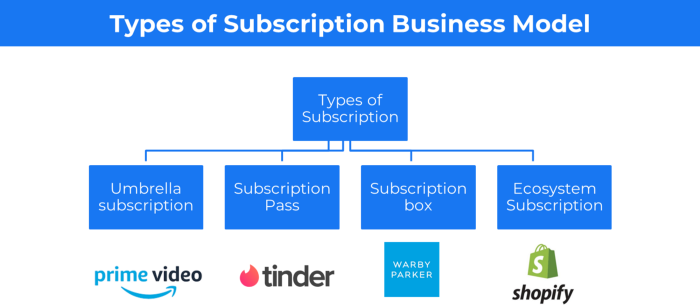
Subscription Business Model (Click here)
3. A market-based business strategy
It's an e-commerce site or app where third-party sellers sell products or services.
Examples are Amazon and Fiverr.
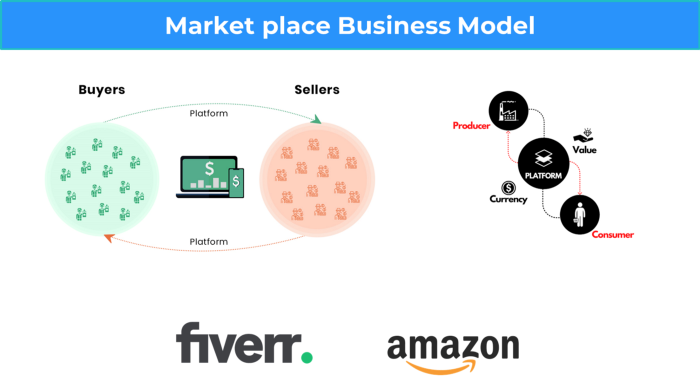
On Amazon's marketplace, a third-party vendor sells a product.
Freelancers on Fiverr offer specialized skills like graphic design.
Marketplace's business concept is explained.
4. Business plans using aggregates
In the aggregator business model, the service is branded.
Uber, Airbnb, and other examples
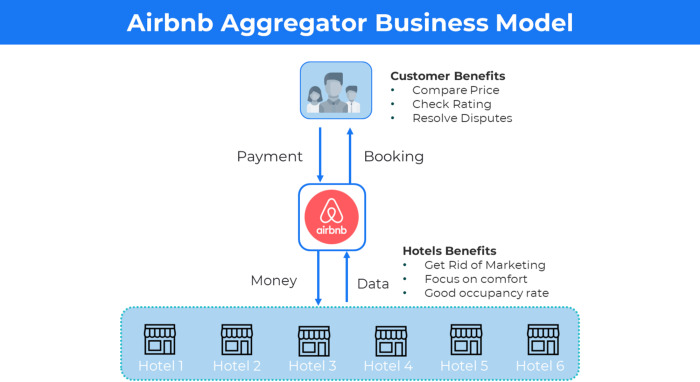
Marketplace and Aggregator business models differ.

Amazon and Fiverr link merchants and customers and take a 10-20% revenue split.
Uber and Airbnb-style aggregator Join these businesses and provide their products.
5. The pay-as-you-go concept of business
This is a consumption-based pricing system. Cloud companies use it.
Example: Amazon Web Service and Google Cloud Platform (GCP) (AWS)
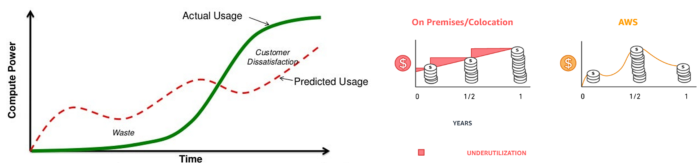
AWS, an Amazon subsidiary, offers over 200 pay-as-you-go cloud services.
“In short, the more you use the more you pay”
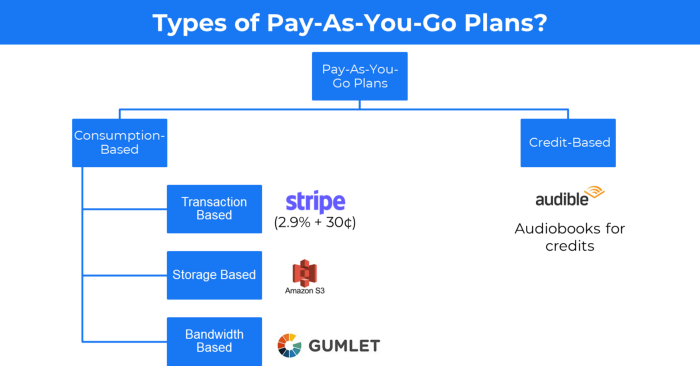
When it's difficult to divide clients into pricing levels, pay-as-you is employed.
6. The business model known as fee-for-service (FFS)
FFS charges fixed and variable fees for each successful payment.
For instance, PayU, Paypal, and Stripe
Stripe charges 2.9% + 30 per payment.
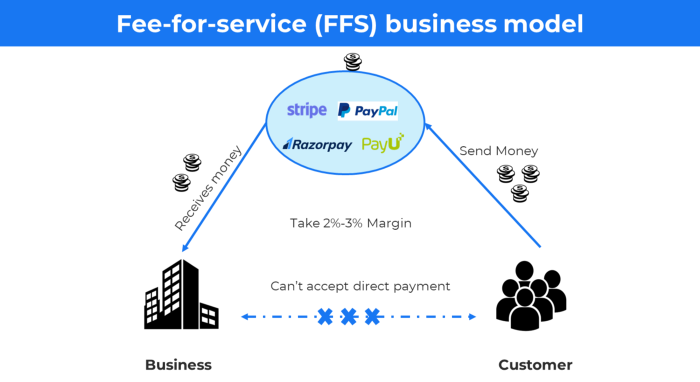
These firms offer a payment gateway to take consumer payments and deposit them to a business account.
Fintech business model
7. EdTech business strategy
In edtech, you generate money by selling material or teaching as a service.
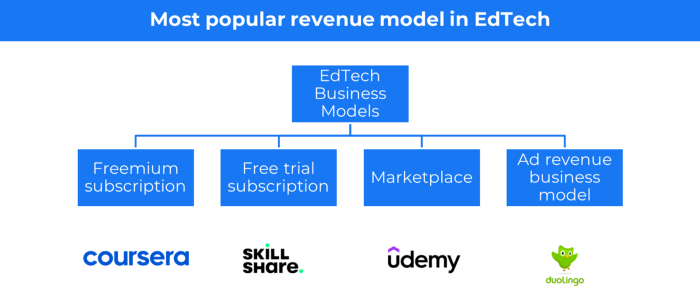
edtech business models
Freemium When course content is free but certification isn't, e.g. Coursera
FREE TRIAL SkillShare offers free trials followed by monthly or annual subscriptions.
Self-serving marketplace approach where you pick what to learn.
Ad-revenue model The company makes money by showing adverts to its huge user base.
Lock-in business strategy
Lock in prevents customers from switching to a competitor's brand or offering.
It uses switching costs or effort to transmit (soft lock-in), improved brand experience, or incentives.
Apple, SAP, and other examples
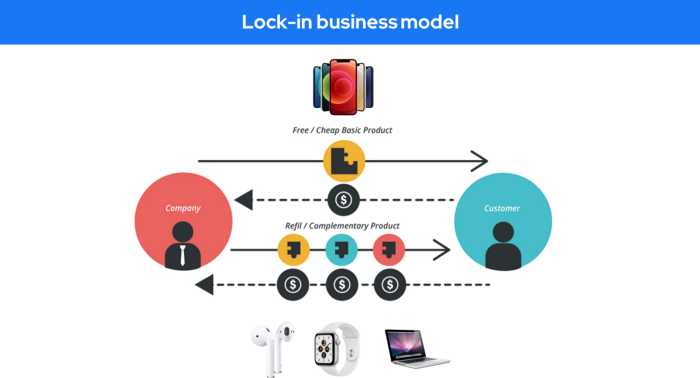
Apple offers an iPhone and then locks you in with extra hardware (Watch, Airpod) and platform services (Apple Store, Apple Music, cloud, etc.).
9. Business Model for API Licensing
APIs let third-party apps communicate with your service.
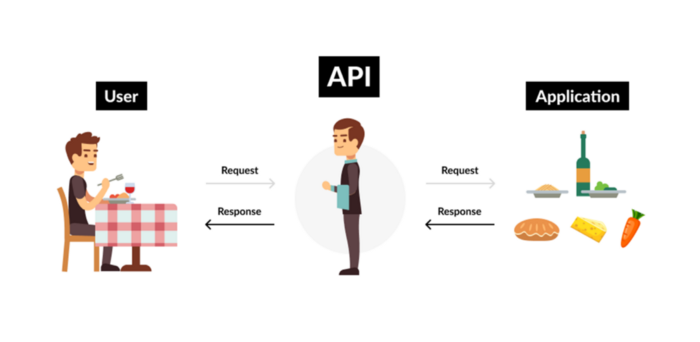
Uber and Airbnb use Google Maps APIs for app navigation.
Examples are Google Map APIs (Map), Sendgrid (Email), and Twilio (SMS).
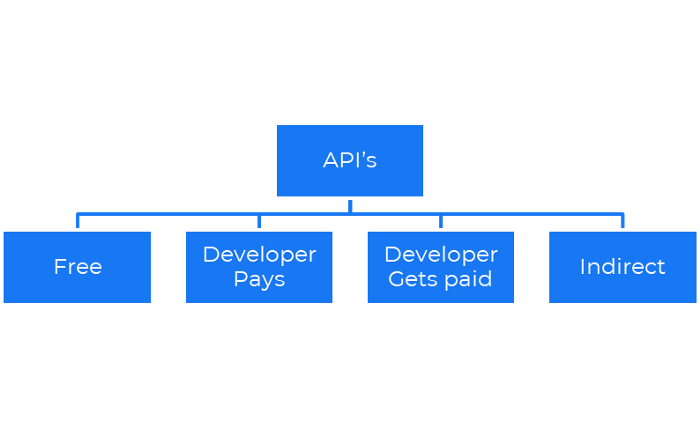
Business models for APIs
Free: The simplest API-driven business model that enables unrestricted API access for app developers. Google Translate and Facebook are two examples.
Developer Pays: Under this arrangement, service providers such as AWS, Twilio, Github, Stripe, and others must be paid by application developers.
The developer receives payment: These are the compensated content producers or developers who distribute the APIs utilizing their work. For example, Amazon affiliate programs
10. Open-source enterprise
Open-source software can be inspected, modified, and improved by anybody.
For instance, use Firefox, Java, or Android.
Google paid Mozilla $435,702 million to be their primary search engine in 2018.
Open-source software profits in six ways.
Paid assistance The Project Manager can charge for customization because he is quite knowledgeable about the codebase.
A full database solution is available as a Software as a Service (MongoDB Atlas), but there is a fee for the monitoring tool.
Open-core design R studio is a better GUI substitute for open-source applications.
sponsors of GitHub Sponsorships benefit the developers in full.
demands for paid features Earn Money By Developing Open Source Add-Ons for Current Products
Open-source business model
11. The business model for data
If the software or algorithm collects client data to improve or monetize the system.
Open AI GPT3 gets smarter with use.
Foursquare allows users to exchange check-in locations.
Later, they compiled large datasets to enable retailers like Starbucks launch new outlets.
12. Business Model Using Blockchain
Blockchain is a distributed ledger technology that allows firms to deploy smart contracts without a central authority.
Examples include Alchemy, Solana, and Ethereum.
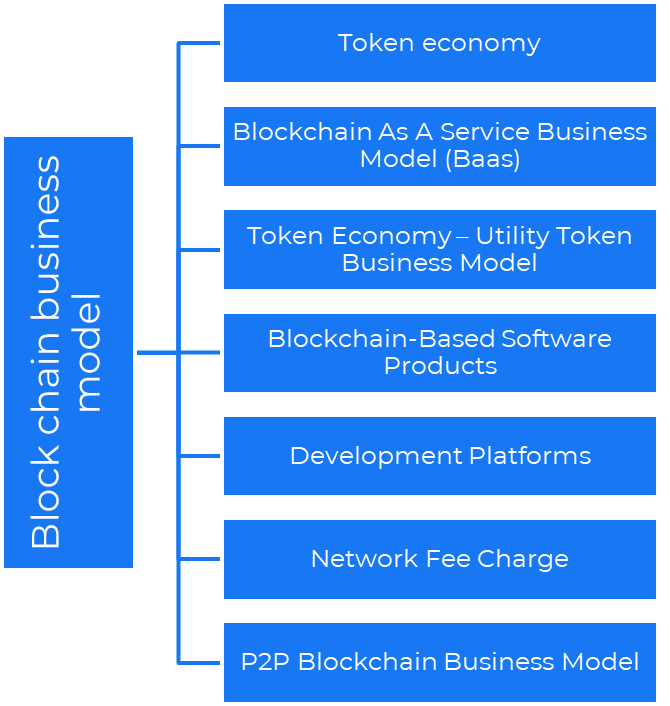
Business models using blockchain
Economy of tokens or utility When a business uses a token business model, it issues some kind of token as one of the ways to compensate token holders or miners. For instance, Solana and Ethereum
Bitcoin Cash P2P Business Model Peer-to-peer (P2P) blockchain technology permits direct communication between end users. as in IPFS
Enterprise Blockchain as a Service (Baas) BaaS focuses on offering ecosystem services similar to those offered by Amazon (AWS) and Microsoft (Azure) in the web 3 sector. Example: Ethereum Blockchain as a Service with Bitcoin (EBaaS).
Blockchain-Based Aggregators With AWS for blockchain, you can use that service by making an API call to your preferred blockchain. As an illustration, Alchemy offers nodes for many blockchains.
13. The free-enterprise model
In the freeterprise business model, free professional accounts are led into the funnel by the free product and later become B2B/enterprise accounts.
For instance, Slack and Zoom
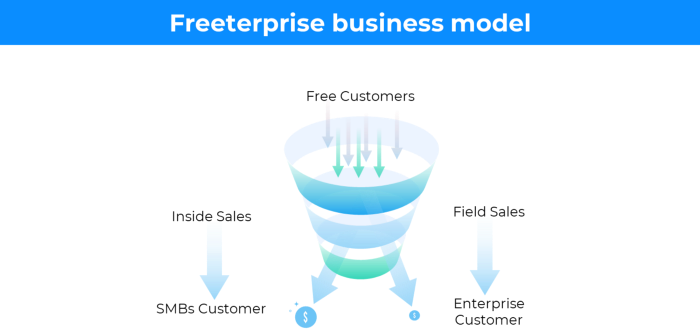
Freeterprise companies flourish through collaboration.
Start with a free professional account to build an enterprise.
14. Business plan for razor blades
It's employed in hardware where one piece is sold at a loss and profits are made through refills or add-ons.
Gillet razor & blades, coffee machine & beans, HP printer & cartridge, etc.
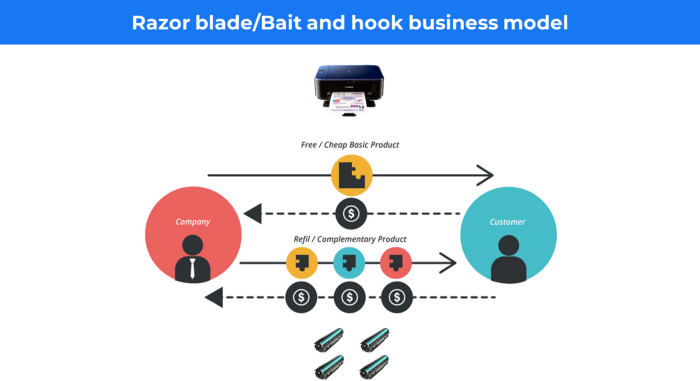
Sony sells the Playstation console at a loss but makes up for it by selling games and charging for online services.
Advantages of the Razor-Razorblade Method
lowers the risk a customer will try a product. enables buyers to test the goods and services without having to pay a high initial investment.
The product's ongoing revenue stream has the potential to generate sales that much outweigh the original investments.
Razor blade business model
15. The business model of direct-to-consumer (D2C)
In D2C, the company sells directly to the end consumer through its website using a third-party logistic partner.
Examples include GymShark and Kylie Cosmetics.
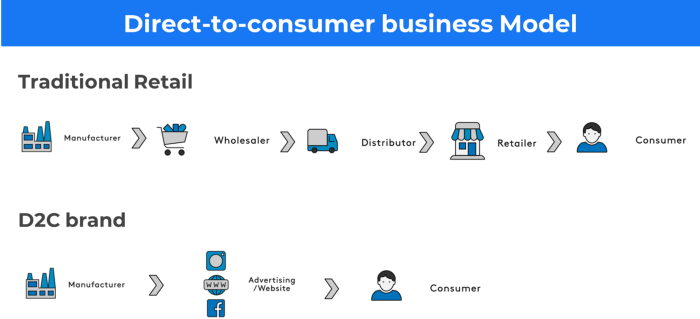
D2C brands can only expand via websites, marketplaces (Amazon, eBay), etc.
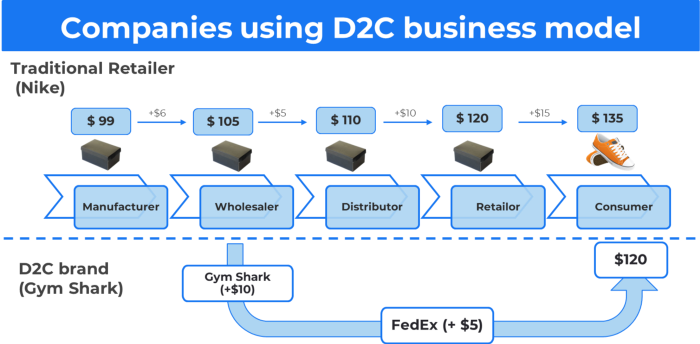
D2C benefits
Lower reliance on middlemen = greater profitability
You now have access to more precise demographic and geographic customer data.
Additional space for product testing
Increased customisation throughout your entire product line-Inventory Less
16. Business model: White Label vs. Private Label
Private label/White label products are made by a contract or third-party manufacturer.
Most amazon electronics are made in china and white-labeled.
Amazon supplements and electronics.
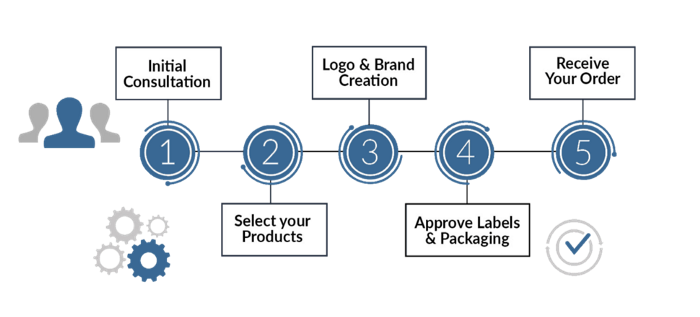
Contract manufacturers handle everything after brands select product quantities on design labels.
17. The franchise model
The franchisee uses the franchisor's trademark, branding, and business strategy (company).
For instance, KFC, Domino's, etc.
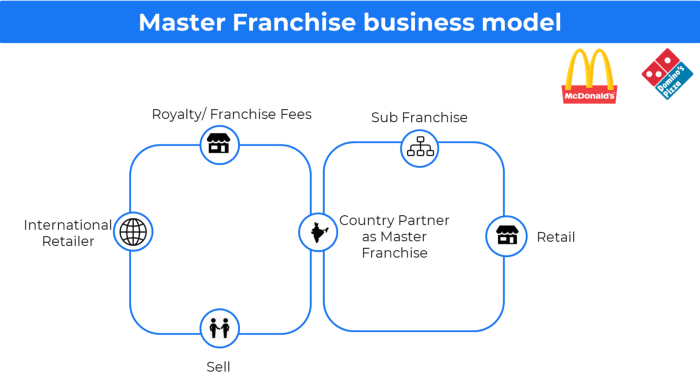
Subway, Domino, Burger King, etc. use this business strategy.

Many people pick a franchise because opening a restaurant is risky.
18. Ad-based business model
Social media and search engine giants exploit search and interest data to deliver adverts.
Google, Meta, TikTok, and Snapchat are some examples.
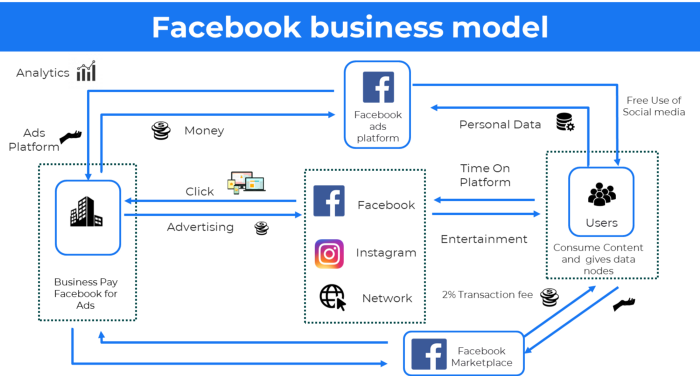
Users don't pay for the service or product given, e.g. Google users don't pay for searches.
In exchange, they collected data and hyper-personalized adverts to maximize revenue.
19. Business plan for octopuses
Each business unit functions separately but is connected to the main body.
Instance: Oyo

OYO is Asia's Airbnb, operating hotels, co-working, co-living, and vacation houses.
20, Transactional business model, number
Sales to customers produce revenue.
E-commerce sites and online purchases employ SSL.
Goli is an ex-GymShark.
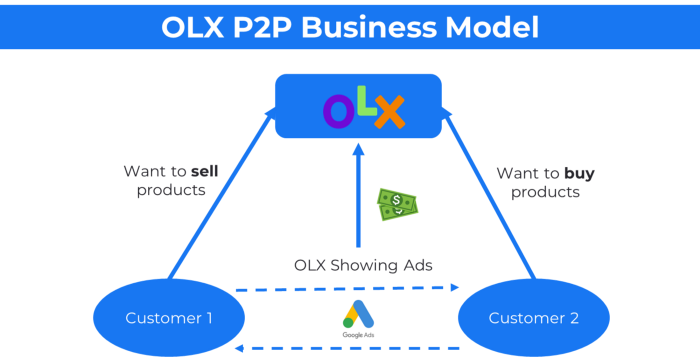
21. The peer-to-peer (P2P) business model
In P2P, two people buy and sell goods and services without a third party or platform.
Consider OLX.
22. P2P lending as a manner of operation
In P2P lending, one private individual (P2P Lender) lends/invests or borrows money from another (P2P Borrower).
Instance: Kabbage
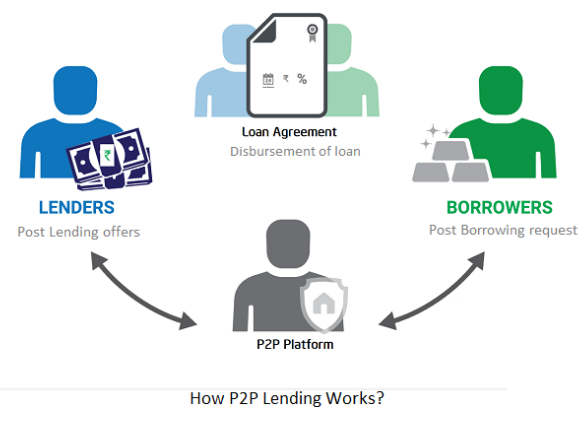
Social lending lets people lend and borrow money directly from each other without an intermediary financial institution.
23. A business model for brokers
Brokerages charge a commission or fee for their services.
Examples include eBay, Coinbase, and Robinhood.
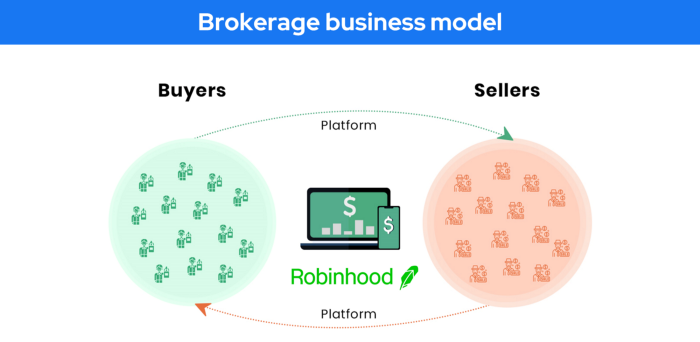
Brokerage businesses are common in Real estate, finance, and online and operate on this model.

Buy/sell similar models Examples include financial brokers, insurance brokers, and others who match purchase and sell transactions and charge a commission.
These brokers charge an advertiser a fee based on the date, place, size, or type of an advertisement. This is known as the classified-advertiser model. For instance, Craiglist
24. Drop shipping as an industry
Dropshipping allows stores to sell things without holding physical inventories.
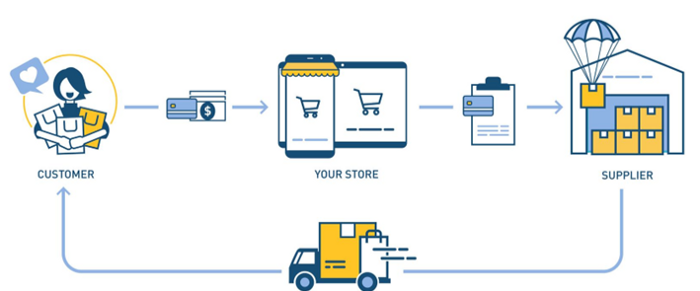
When a customer orders, use a third-party supplier and logistic partners.
Retailer product portfolio and customer experience Fulfiller The consumer places the order.
Dropshipping advantages
Less money is needed (Low overhead-No Inventory or warehousing)
Simple to start (costs under $100)
flexible work environment
New product testing is simpler
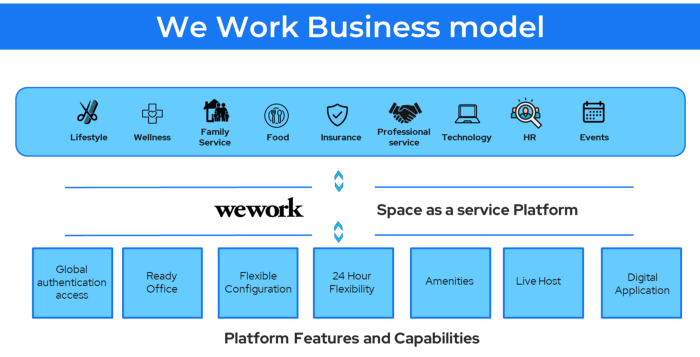
25. Business Model for Space as a Service
It's centered on a shared economy that lets millennials live or work in communal areas without ownership or lease.
Consider WeWork and Airbnb.
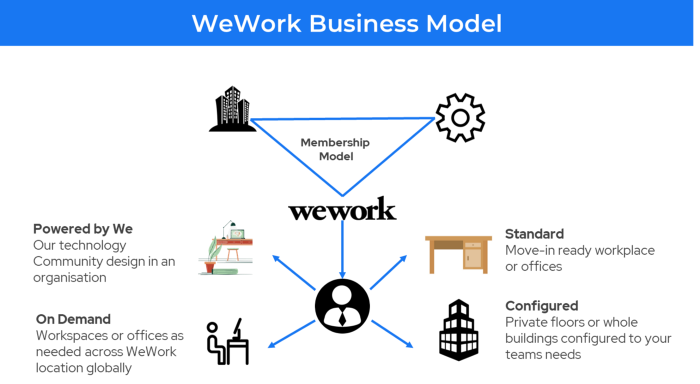
WeWork helps businesses with real estate, legal compliance, maintenance, and repair.
26. The business model for third-party logistics (3PL)
In 3PL, a business outsources product delivery, warehousing, and fulfillment to an external logistics company.
Examples include Ship Bob, Amazon Fulfillment, and more.

3PL partners warehouse, fulfill, and return inbound and outbound items for a charge.
Inbound logistics involves bringing products from suppliers to your warehouse.
Outbound logistics refers to a company's production line, warehouse, and customer.

27. The last-mile delivery paradigm as a commercial strategy
Last-mile delivery is the collection of supply chain actions that reach the end client.
Examples include Rappi, Gojek, and Postmates.
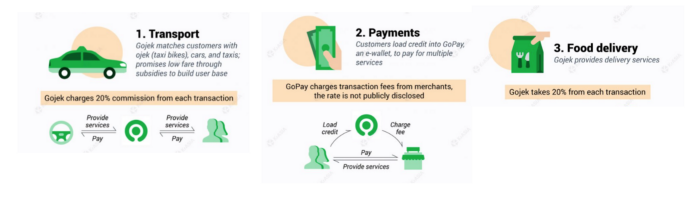
Last-mile is tied to on-demand and has a nighttime peak.
28. The use of affiliate marketing
Affiliate marketing involves promoting other companies' products and charging commissions.
Examples include Hubspot, Amazon, and Skillshare.

Your favorite youtube channel probably uses these short amazon links to get 5% of sales.
Affiliate marketing's benefits
In exchange for a success fee or commission, it enables numerous independent marketers to promote on its behalf.
Ensure system transparency by giving the influencers a specific tracking link and an online dashboard to view their profits.
Learn about the newest bargains and have access to promotional materials.
29. The business model for virtual goods
This is an in-app purchase for an intangible product.
Examples include PubG, Roblox, Candy Crush, etc.
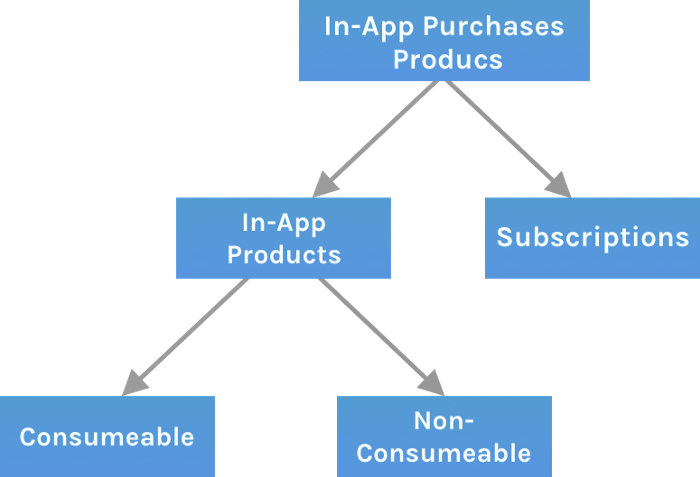
Consumables are like gaming cash that runs out. Non-consumable products provide a permanent advantage without repeated purchases.
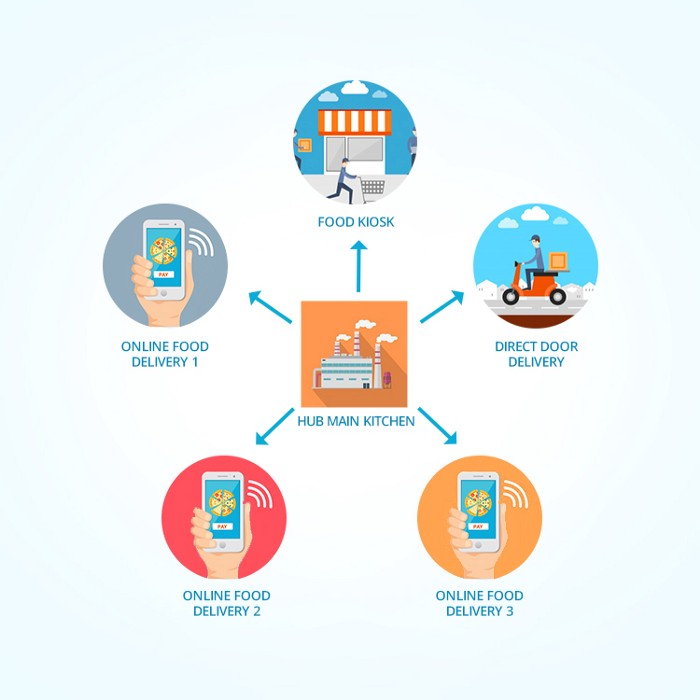
30. Business Models for Cloud Kitchens
Ghost, Dark, Black Box, etc.
Delivery-only restaurant.
These restaurants don't provide dine-in, only delivery.
For instance, NextBite and Faasos
31. Crowdsourcing as a Business Model
Crowdsourcing = Using the crowd as a platform's source.
In crowdsourcing, you get support from people around the world without hiring them.
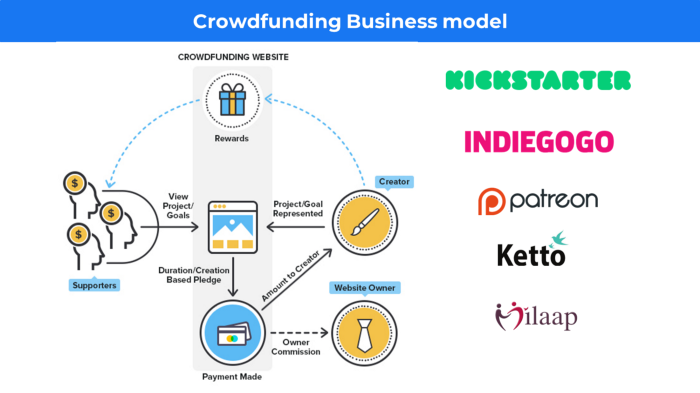
Crowdsourcing sites
Open-Source Software gives access to the software's source code so that developers can edit or enhance it. Examples include Firefox browsers and Linux operating systems.
Crowdfunding The oculus headgear would be an example of crowdfunding in essence, with no expectations.

Edward Williams
3 years ago
I currently manage 4 profitable online companies. I find all the generic advice and garbage courses very frustrating. The only advice you need is this.

This is for young entrepreneurs, especially in tech.
People give useless success advice on TikTok and Reddit. Early risers, bookworms, etc. Entrepreneurship courses. Work hard and hustle.
False. These aren't successful traits.
I mean, organization is good. As someone who founded several businesses and now works at a VC firm, I find these tips to be clichés.
Based on founding four successful businesses and working with other successful firms, here's my best actionable advice:
1. Choose a sector or a niche and become an expert in it.
This is more generic than my next tip, but it's a must-do that's often overlooked. Become an expert in the industry or niche you want to enter. Discover everything.
Buy (future) competitors' products. Understand consumers' pain points. Market-test. Target keyword combos. Learn technical details.
The most successful businesses I've worked with were all formed by 9-5 employees. They knew the industry's pain points. They started a business targeting these pain points.
2. Choose a niche or industry crossroads to target.
How do you choose an industry or niche? What if your industry is too competitive?
List your skills and hobbies. Randomness is fine. Find an intersection between two interests or skills.
Say you build websites well. You like cars.
Web design is a *very* competitive industry. Cars and web design?
Instead of web design, target car dealers and mechanics. Build a few fake demo auto mechanic websites, then cold call shops with poor websites. Verticalize.
I've noticed a pattern:
Person works in a particular industry for a corporation.
Person gains expertise in the relevant industry.
Person quits their job and launches a small business to address a problem that their former employer was unwilling to address.
I originally posted this on Reddit and it seemed to have taken off so I decided to share it with you all.
Focus on the product. When someone buys from you, you convince them the product's value exceeds the price. It's not fair and favors the buyer.
Creating a superior product or service will win. Narrowing this helps you outcompete others.
You may be their only (lucky) option.

ʟ ᴜ ᴄ ʏ
3 years ago
The Untapped Gold Mine of Inspiration and Startup Ideas
I joined the 1000 Digital Startups Movement (Gerakan 1000 Startup Digital) in 2017 and learned a lot about the startup sector. My previous essay outlined what a startup is and what must be prepared. Here I'll offer raw ideas for better products.

Intro
A good startup solves a problem. These can include environmental, economic, energy, transportation, logistics, maritime, forestry, livestock, education, tourism, legal, arts and culture, communication, and information challenges. Everything I wrote is simply a basic idea (as inspiration) and requires more mapping and validation. Learn how to construct a startup to maximize launch success.
Adrian Gunadi (Investree Co-Founder) taught me that a Founder or Co-Founder must be willing to be CEO (Chief Everything Officer). Everything is independent, including drafting a proposal, managing finances, and scheduling appointments. The best individuals will come to you if you're the best. It's easier than consulting Andy Zain (Kejora Capital Founder).
Description
To help better understanding from your idea, try to answer this following questions:
- Describe your idea/application
Maximum 1000 characters.
- Background
Explain the reasons that prompted you to realize the idea/application.
- Objective
Explain the expected goals of the creation of the idea/application.
- Solution
A solution that tells your idea can be the right solution for the problem at hand.
- Uniqueness
What makes your idea/app unique?
- Market share
Who are the people who need and are looking for your idea?
- Marketing Ways and Business Models
What is the best way to sell your idea and what is the business model?
Not everything here is a startup idea. It's meant to inspire creativity and new perspectives.
Ideas
#Application
1. Medical students can operate on patients or not. Applications that train prospective doctors to distinguish body organs and their placement are useful. In the advanced stage, the app can be built with numerous approaches so future doctors can practice operating on patients based on their ailments. If they made a mistake, they'd start over. Future doctors will be more assured and make fewer mistakes this way.
2. VR (virtual reality) technology lets people see 3D space from afar. Later, similar technology was utilized to digitally sell properties, so buyers could see the inside and room contents. Every gadget has flaws. It's like a gold mine for robbers. VR can let prospective students see a campus's facilities. This facility can also help hotels promote their products.
3. How can retail entrepreneurs maximize sales? Most popular goods' sales data. By using product and brand/type sales figures, entrepreneurs can avoid overstocking. Walmart computerized their procedures to track products from the manufacturer to the store. As Retail Link products sell out, suppliers can immediately step in.
4. Failing to marry is something to be avoided. But if it had to happen, the loss would be like the proverb “rub salt into the wound”. On the I do Now I dont website, Americans who don't marry can resell their jewelry to other brides-to-be. If some want to cancel the wedding and receive their down money and dress back, others want a wedding with particular criteria, such as a quick date and the expected building. Create a DP takeover marketplace for both sides.
#Games
1. Like in the movie, players must exit the maze they enter within 3 minutes or the shape will change, requiring them to change their strategy. The maze's transformation time will shorten after a few stages.
2. Treasure hunts involve following clues to uncover hidden goods. Here, numerous sponsors are combined in one boat, and participants can choose a game based on the prizes. Let's say X-mart is a sponsor and provides riddles or puzzles to uncover the prize in their store. After gathering enough points, the player can trade them for a gift utilizing GPS and AR (augmented reality). Players can collaborate to increase their chances of success.
3. Where's Wally? Where’s Wally displays a thick image with several things and various Wally-like characters. We must find the actual Wally, his companions, and the desired object. Make a game with a map where players must find objects for the next level. The player must find 5 artifacts randomly placed in an Egyptian-style mansion, for example. In the room, there are standard tickets, pass tickets, and gold tickets that can be removed for safekeeping, as well as a wall-mounted carpet that can be stored but not searched and turns out to be a flying rug that can be used to cross/jump to a different place. Regular tickets are spread out since they can buy life or stuff. At a higher level, a black ticket can lower your ordinary ticket. Objects can explode, scattering previously acquired stuff. If a player runs out of time, they can exchange a ticket for more.
#TVprogram
1. At the airport there are various visitors who come with different purposes. Asking tourists to live for 1 or 2 days in the city will be intriguing to witness.
2. Many professions exist. Carpenters, cooks, and lawyers must have known about job desks. Does HRD (Human Resource Development) only recruit new employees? Many don't know how to become a CEO, CMO, COO, CFO, or CTO. Showing young people what a Program Officer in an NGO does can help them choose a career.
#StampsCreations
Philatelists know that only the government can issue stamps. I hope stamps are creative so they have more worth.
1. Thermochromic pigments (leuco dyes) are well-known for their distinctive properties. By putting pigments to black and white batik stamps, for example, the black color will be translucent and display the basic color when touched (at a hot temperature).
2. In 2012, Liechtenstein Post published a laser-art Chinese zodiac stamp. Belgium (Bruges Market Square 2012), Taiwan (Swallow Tail Butterfly 2009), etc. Why not make a stencil of the president or king/queen?
3. Each country needs its unique identity, like Taiwan's silk and bamboo stamps. Create from your country's history. Using traditional paper like washi (Japan), hanji (Korea), and daluang/saeh (Indonesia) can introduce a country's culture.
4. Garbage has long been a problem. Bagasse, banana fronds, or corn husks can be used as stamp material.
5. Austria Post published a stamp containing meteor dust in 2006. 2004 meteorite found in Morocco produced the dust. Gibraltar's Rock of Gilbraltar appeared on stamps in 2002. What's so great about your country? East Java is muddy (Lapindo mud). Lapindo mud stamps will be popular. Red sand at Pink Beach, East Nusa Tenggara, could replace the mud.
#PostcardCreations
1. Map postcards are popular because they make searching easier. Combining laser-cut road map patterns with perforated 200-gram paper glued on 400-gram paper as a writing medium. Vision-impaired people can use laser-cut maps.
2. Regional art can be promoted by tucking traditional textiles into postcards.
3. A thin canvas or plain paper on the card's front allows the giver to be creative.
4. What is local crop residue? Cork lids, maize husks, and rice husks can be recycled into postcard materials.
5. Have you seen a dried-flower bookmark? Cover the postcard with mica and add dried flowers. If you're worried about losing the flowers, you can glue them or make a postcard envelope.
6. Wood may be ubiquitous; try a 0.2-mm copper plate engraved with an image and connected to a postcard as a writing medium.
7. Utilized paper pulp can be used to hold eggs, smartphones, and food. Form a smooth paper pulp on the plate with the desired image, the Golden Gate bridge, and paste it on your card.
8. Postcards can promote perfume. When customers rub their hands on the card with the perfume image, they'll smell the aroma.
#Tour #Travel
Tourism activities can be tailored to tourists' interests or needs. Each tourist benefits from tourism's distinct aim.
Let's define tourism's objective and purpose.
Holiday Tour is a tour that its participants plan and do in order to relax, have fun, and amuse themselves.
A familiarization tour is a journey designed to help travelers learn more about (survey) locales connected to their line of work.
An educational tour is one that aims to give visitors knowledge of the field of work they are visiting or an overview of it.
A scientific field is investigated and knowledge gained as the major goal of a scientific tour.
A pilgrimage tour is one designed to engage in acts of worship.
A special mission tour is one that has a specific goal, such a commerce mission or an artistic endeavor.
A hunting tour is a destination for tourists that plans organized animal hunting that is only allowed by local authorities for entertainment purposes.
Every part of life has tourism potential. Activities include:
1. Those who desire to volunteer can benefit from the humanitarian theme and collaboration with NGOs. This activity's profit isn't huge but consider the environmental impact.
2. Want to escape the city? Meditation travel can help. Beautiful spots around the globe can help people forget their concerns. A certified yoga/meditation teacher can help travelers release bad energy.
3. Any prison visitors? Some prisons, like those for minors under 17, are open to visitors. This type of tourism helps mental convicts reach a brighter future.
4. Who has taken a factory tour/study tour? Outside-of-school study tour (for ordinary people who have finished their studies). Not everyone in school could tour industries, workplaces, or embassies to learn and be inspired. Shoyeido (an incense maker) and Royce (a chocolate maker) offer factory tours in Japan.
5. Develop educational tourism like astronomy and archaeology. Until now, only a few astronomy enthusiasts have promoted astronomy tourism. In Indonesia, archaeology activities focus on site preservation, and to participate, office staff must undertake a series of training (not everyone can take a sabbatical from their routine). Archaeological tourist activities are limited, whether held by history and culture enthusiasts or in regional tours.
6. Have you ever longed to observe a film being made or your favorite musician rehearsing? Such tours can motivate young people to pursue entertainment careers.
7. Pamper your pets to reduce stress. Many pet owners don't have time for walks or treats. These premium services target the wealthy.
8. A quirky idea to provide tours for imaginary couples or things. Some people marry inanimate objects or animals and seek to make their lover happy; others cherish their ashes after death.
#MISCideas
1. Fashion is a lifestyle, thus people often seek fresh materials. Chicken claws, geckos, snake skin casings, mice, bats, and fish skins are also used. Needs some improvement, definitely.
2. As fuel supplies become scarcer, people hunt for other energy sources. Sound is an underutilized renewable energy. The Batechsant technology converts environmental noise into electrical energy, according to study (Battery Technology Of Sound Power Plant). South Korean researchers use Sound-Driven Piezoelectric Nanowire based on Nanogenerators to recharge cell phone batteries. The Batechsant system uses existing noise levels to provide electricity for street lamp lights, aviation, and ships. Using waterfall sound can also energize hard-to-reach locations.
3. A New York Times reporter said IQ doesn't ensure success. Our school system prioritizes IQ above EQ (Emotional Quotient). EQ is a sort of human intelligence that allows a person to perceive and analyze the dynamics of his emotions when interacting with others (and with himself). EQ is suspected of being a bigger source of success than IQ. EQ training can gain greater attention to help people succeed. Prioritize role models from school stakeholders, teachers, and parents to improve children' EQ.
4. Teaching focuses more on theory than practice, so students are less eager to explore and easily forget if they don't pay attention. Has an engineer ever made bricks from arid red soil? Morocco's non-college-educated builders can create weatherproof bricks from red soil without equipment. Can mechanical engineering grads create a water pump to solve water shortages in remote areas? Art graduates can innovate beyond only painting. Artists may create kinetic sculpture by experimenting so much. Young people should understand these sciences so they can be more creative with their potential. These might be extracurricular activities in high school and university.
5. People have been trying to recycle agricultural waste for a long time. Mycelium helps replace light, easily crushed tiles and bricks (a collection of hyphae like in the manufacture of tempe). Waste must contain lignocellulose. In this vein, anti-mainstream painting canvases can be made. The goal is to create the canvas uneven like an amoeba outline, not square or spherical. The resulting canvas is lightweight and needs no frame. Then what? Open source your idea like Precious Plastic to establish a community. By propagating this notion, many knowledgeable people will help improve your product's quality and impact.
6. As technology and humans adapt, fraud increases. Making phony doctor's letters to fool superiors, fake credentials to get hired, fraudulent land certificates to make money, and fake news (hoax). The existence of a Wikimedia can aid the community by comparing bogus and original information.
7. Do you often hit a problem-solving impasse? Since the Doraemon bag hasn't been made, construct an Idea Bank. Everyone can contribute to solving problems here. How do you recruit volunteers? Obviously, a reward is needed. Contributors can become moderators or gain complimentary tickets to TIA (Tech in Asia) conferences. Idea Bank-related concepts: the rise of startups without a solid foundation generates an age as old as corn that does not continue. Those with startup ideas should describe them here so they can be validated by other users. Other users can contribute input if a comparable notion is produced to improve the product or integrate it. Similar-minded users can become Co-Founders.
8. Why not invest in fruit/vegetables, inspired by digital farming? The landowner obtains free fruit without spending much money on maintenance. Investors can get fruits/vegetables in larger quantities, fresher, and cheaper during harvest. Fruits and vegetables are often harmed if delivered too slowly. Rich investors with limited land can invest in teak, agarwood, and other trees. When harvesting, investors might choose raw results or direct wood sales earnings. Teak takes at least 7 years to harvest, therefore long-term wood investments carry the risk of crop failure.
9. Teenagers in distant locations can't count, read, or write. Many factors hinder locals' success. Life's demands force them to work instead of study. Creating a learning playground may attract young people to learning. Make a skatepark at school. Skateboarders must learn in school. Donations buy skateboards.
10. Globally, online taxi-bike is known. By hiring a motorcycle/car online, people no longer bother traveling without a vehicle. What if you wish to cross the island or visit remote areas? Is online boat or helicopter rental possible like online taxi-bike? Such a renting process has been done independently thus far and cannot be done quickly.
11. What do startups need now? A startup or investor consultant. How many startups fail to become Unicorns? Many founders don't know how to manage investor money, therefore they waste it on promotions and other things. Many investors only know how to invest and can't guide a struggling firm.
“In times of crisis, the wise build bridges, while the foolish build barriers.” — T’Challa [Black Panther]
Don't chase cash. Money is a byproduct. Profit-seeking is stressful. Market requirements are opportunities. If you have something to say, please comment.
This is only informational. Before implementing ideas, do further study.
You might also like

Greg Satell
3 years ago
Focus: The Deadly Strategic Idea You've Never Heard Of (But Definitely Need To Know!

Steve Jobs' initial mission at Apple in 1997 was to destroy. He killed the Newton PDA and Macintosh clones. Apple stopped trying to please everyone under Jobs.
Afterward, there were few highly targeted moves. First, the pink iMac. Modest success. The iPod, iPhone, and iPad made Apple the world's most valuable firm. Each maneuver changed the company's center of gravity and won.
That's the idea behind Schwerpunkt, a German military term meaning "focus." Jobs didn't need to win everywhere, just where it mattered, so he focused Apple's resources on a few key goods. Finding your Schwerpunkt is more important than charts and analysis for excellent strategy.
Comparison of Relative Strength and Relative Weakness
The iPod, Apple's first major hit after Jobs' return, didn't damage Microsoft and the PC, but instead focused Apple's emphasis on a fledgling, fragmented market that generated "sucky" products. Apple couldn't have taken on the computer titans at this stage, yet it beat them.
The move into music players used Apple's particular capabilities, especially its ability to build simple, easy-to-use interfaces. Jobs' charisma and stature, along his understanding of intellectual property rights from Pixar, helped him build up iTunes store, which was a quagmire at the time.
In Good Strategy | Bad Strategy, management researcher Richard Rumelt argues that good strategy uses relative strength to counter relative weakness. To discover your main point, determine your abilities and where to effectively use them.
Steve Jobs did that at Apple. Microsoft and Dell, who controlled the computer sector at the time, couldn't enter the music player business. Both sought to produce iPod competitors but failed. Apple's iPod was nobody else's focus.
Finding The Center of Attention
In a military engagement, leaders decide where to focus their efforts by assessing commanders intent, the situation on the ground, the topography, and the enemy's posture on that terrain. Officers spend their careers learning about schwerpunkt.
Business executives must assess internal strengths including personnel, technology, and information, market context, competitive environment, and external partner ecosystems. Steve Jobs was a master at analyzing forces when he returned to Apple.
He believed Apple could integrate technology and design for the iPod and that the digital music player industry sucked. By analyzing competitors' products, he was convinced he could produce a smash by putting 1000 tunes in my pocket.
The only difficulty was there wasn't the necessary technology. External ecosystems were needed. On a trip to Japan to meet with suppliers, a Toshiba engineer claimed the company had produced a tiny memory drive approximately the size of a silver dollar.
Jobs knew the memory drive was his focus. He wrote a $10 million cheque and acquired exclusive technical rights. For a time, none of his competitors would be able to recreate his iPod with the 1000 songs in my pocket.
How to Enter the OODA Loop
John Boyd invented the OODA loop as a pilot to better his own decision-making. First OBSERVE your surroundings, then ORIENT that information using previous knowledge and experiences. Then you DECIDE and ACT, which changes the circumstance you must observe, orient, decide, and act on.
Steve Jobs used the OODA loop to decide to give Toshiba $10 million for a technology it had no use for. He compared the new information with earlier observations about the digital music market.
Then something much more interesting happened. The iPod was an instant hit, changing competition. Other computer businesses that competed in laptops, desktops, and servers created digital music players. Microsoft's Zune came out in 2006, Dell's Digital Jukebox in 2004. Both flopped.
By then, Apple was poised to unveil the iPhone, which would cause its competitors to Observe, Orient, Decide, and Act. Boyd named this OODA Loop infiltration. They couldn't gain the initiative by constantly reacting to Apple.
Microsoft and Dell were titans back then, but it's hard to recall. Apple went from near bankruptcy to crushing its competition via Schwerpunkt.
Rather than a destination, it is a journey
Trying to win everywhere is a strategic blunder. Win significant fights, not trivial skirmishes. Identifying a focal point to direct resources and efforts is the essence of Schwerpunkt.
When Steve Jobs returned to Apple, PC firms were competing, but he focused on digital music players, and the iPod made Apple a player. He launched the iPhone when his competitors were still reacting. When Steve Jobs said, "One more thing," at the end of a product presentation, he had a new focus.
Schwerpunkt isn't static; it's dynamic. Jobs' ability to observe, refocus, and modify the competitive backdrop allowed Apple to innovate consistently. His strategy was tailored to Apple's capabilities, customers, and ecosystem. Microsoft or Dell, better suited for the enterprise sector, couldn't succeed with a comparable approach.
There is no optimal strategy, only ones suited to a given environment, when relative strength might be used against relative weakness. Discovering the center of gravity where you can break through is more of a journey than a destination; it will become evident after you reach.
JEFF JOHN ROBERTS
3 years ago
What just happened in cryptocurrency? A plain-English Q&A about Binance's FTX takedown.

Crypto people have witnessed things. They've seen big hacks, mind-boggling swindles, and amazing successes. They've never seen a day like Tuesday, when the world's largest crypto exchange murdered its closest competition.
Here's a primer on Binance and FTX's lunacy and why it matters if you're new to crypto.
What happened?
CZ, a shrewd Chinese-Canadian billionaire, runs Binance. FTX, a newcomer, has challenged Binance in recent years. SBF (Sam Bankman-Fried)—a young American with wild hair—founded FTX (initials are a thing in crypto).
Last weekend, CZ complained about SBF's lobbying and then exploited Binance's market power to attack his competition.
How did CZ do that?
CZ invested in SBF's new cryptocurrency exchange when they were friends. CZ sold his investment in FTX for FTT when he no longer wanted it. FTX clients utilize those tokens to get trade discounts, although they are less liquid than Bitcoin.
SBF made a mistake by providing CZ just too many FTT tokens, giving him control over FTX. It's like Pepsi handing Coca-Cola a lot of stock it could sell at any time. CZ got upset with SBF and flooded the market with FTT tokens.
SBF owns a trading fund with many FTT tokens, therefore this was catastrophic. SBF sought to defend FTT's worth by selling other assets to buy up the FTT tokens flooding the market, but it didn't succeed, and as FTT's value plummeted, his liabilities exceeded his assets. By Tuesday, his companies were insolvent, so he sold them to his competition.
Crazy. How could CZ do that?
CZ likely did this to crush a rising competition. It was also personal. In recent months, regulators have been tough toward the crypto business, and Binance and FTX have been trying to stay on their good side. CZ believed SBF was poisoning U.S. authorities by saying CZ was linked to China, so CZ took retribution.
“We supported previously, but we won't pretend to make love after divorce. We're neutral. But we won't assist people that push against other industry players behind their backs," CZ stated in a tragic tweet on Sunday. He crushed his rival's company two days later.
So does Binance now own FTX?
No. Not yet. CZ has only stated that Binance signed a "letter of intent" to acquire FTX. CZ and SBF say Binance will protect FTX consumers' funds.
Who’s to blame?
You could blame CZ for using his control over FTX to destroy it. SBF is also being criticized for not disclosing the full overlap between FTX and his trading company, which controlled plenty of FTT. If he had been upfront, someone might have warned FTX about this vulnerability earlier, preventing this mess.
Others have alleged that SBF utilized customer monies to patch flaws in his enterprises' balance accounts. That happened to multiple crypto startups that collapsed this spring, which is unfortunate. These are allegations, not proof.
Why does this matter? Isn't this common in crypto?
Crypto is notorious for shady executives and pranks. FTX is the second-largest crypto business, and SBF was largely considered as the industry's golden boy who would help it get on authorities' good side. Thus far.
Does this affect cryptocurrency prices?
Short-term, it's bad. Prices fell on suspicions that FTX was in peril, then rallied when Binance rescued it, only to fall again later on Tuesday.
These occurrences have hurt FTT and SBF's Solana token. It appears like a huge token selloff is affecting the rest of the market. Bitcoin fell 10% and Ethereum 15%, which is bad but not catastrophic for the two largest coins by market cap.

David G Chen
3 years ago
If you want to earn money, stop writing for entertainment.
When you stop blogging for a few weeks, your views and profits plummet.
Because you're writing fascinating posts for others. Everyone's done ithat…
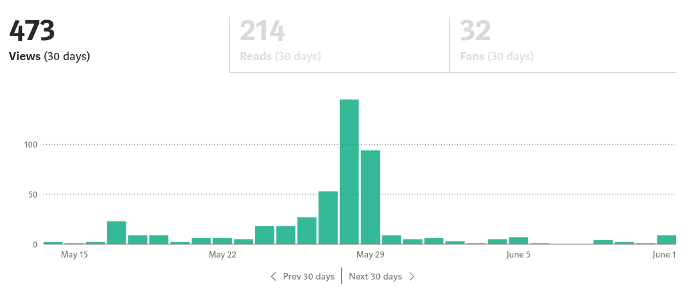
If I keep writing, the graph should maintain velocity, you could say. If I wrote more, it could rise.
However, entertaining pieces still tend to roller coaster and jump.
this type of writing is like a candle. They burn out and must be replaced. You must continuously light new ones to maintain the illumination.
When you quit writing, your income stops.
A substitute
Instead of producing amusing articles, try solving people's issues. You should answer their search questions.
Here's what happens when you answer their searches.
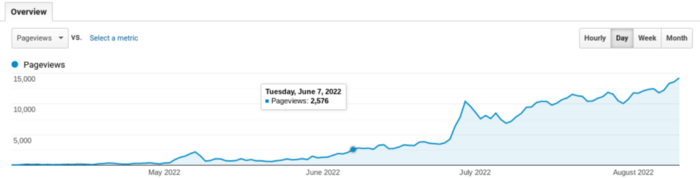
My website's Google analytics. As a dentist, I answer oral health questions.
This chart vs. Medium is pretty glaring, right?
As of yesterday, it was averaging 15k page views each day.
How much would you make on Medium with 15k daily views?
Evergreen materials
In SEO, this is called evergreen content.
Your content is like a lush, evergreen forest, and by green I mean Benjamins.

Do you have knowledge that you can leverage? Why not help your neighbors and the world?
Answer search inquiries and help others. You'll be well rewarded.
This is better than crafting candle-like content that fizzles out quickly.
Is beauty really ephemeral like how flowers bloom? Nah, I prefer watching forests grow instead (: