


More on Technology

Waleed Rikab, PhD
3 years ago
The Enablement of Fraud and Misinformation by Generative AI What You Should Understand
Recent investigations have shown that generative AI can boost hackers and misinformation spreaders.

Since its inception in late November 2022, OpenAI's ChatGPT has entertained and assisted many online users in writing, coding, task automation, and linguistic translation. Given this versatility, it is maybe unsurprising but nonetheless regrettable that fraudsters and mis-, dis-, and malinformation (MDM) spreaders are also considering ChatGPT and related AI models to streamline and improve their operations.
Malign actors may benefit from ChatGPT, according to a WithSecure research. ChatGPT promises to elevate unlawful operations across many attack channels. ChatGPT can automate spear phishing attacks that deceive corporate victims into reading emails from trusted parties. Malware, extortion, and illicit fund transfers can result from such access.
ChatGPT's ability to simulate a desired writing style makes spear phishing emails look more genuine, especially for international actors who don't speak English (or other languages like Spanish and French).
This technique could let Russian, North Korean, and Iranian state-backed hackers conduct more convincing social engineering and election intervention in the US. ChatGPT can also create several campaigns and various phony online personas to promote them, making such attacks successful through volume or variation. Additionally, image-generating AI algorithms and other developing techniques can help these efforts deceive potential victims.
Hackers are discussing using ChatGPT to install malware and steal data, according to a Check Point research. Though ChatGPT's scripts are well-known in the cyber security business, they can assist amateur actors with little technical understanding into the field and possibly develop their hacking and social engineering skills through repeated use.
Additionally, ChatGPT's hacking suggestions may change. As a writer recently indicated, ChatGPT's ability to blend textual and code-based writing might be a game-changer, allowing the injection of innocent content that would subsequently turn out to be a malicious script into targeted systems. These new AI-powered writing- and code-generation abilities allow for unique cyber attacks, regardless of viability.
OpenAI fears ChatGPT usage. OpenAI, Georgetown University's Center for Security and Emerging Technology, and Stanford's Internet Observatory wrote a paper on how AI language models could enhance nation state-backed influence operations. As a last resort, the authors consider polluting the internet with radioactive or misleading data to ensure that AI language models produce outputs that other language models can identify as AI-generated. However, the authors of this paper seem unaware that their "solution" might cause much worse MDM difficulties.
Literally False News
The public argument about ChatGPTs content-generation has focused on originality, bias, and academic honesty, but broader global issues are at stake. ChatGPT can influence public opinion, troll individuals, and interfere in local and national elections by creating and automating enormous amounts of social media material for specified audiences.
ChatGPT's capacity to generate textual and code output is crucial. ChatGPT can write Python scripts for social media bots and give diverse content for repeated posts. The tool's sophistication makes it irrelevant to one's language skills, especially English, when writing MDM propaganda.
I ordered ChatGPT to write a news piece in the style of big US publications declaring that Ukraine is on the verge of defeat in its fight against Russia due to corruption, desertion, and exhaustion in its army. I also gave it a fake reporter's byline and an unidentified NATO source's remark. The outcome appears convincing:

Worse, terrible performers can modify this piece to make it more credible. They can edit the general's name or add facts about current wars. Furthermore, such actors can create many versions of this report in different forms and distribute them separately, boosting its impact.
In this example, ChatGPT produced a news story regarding (fictional) greater moviegoer fatality rates:
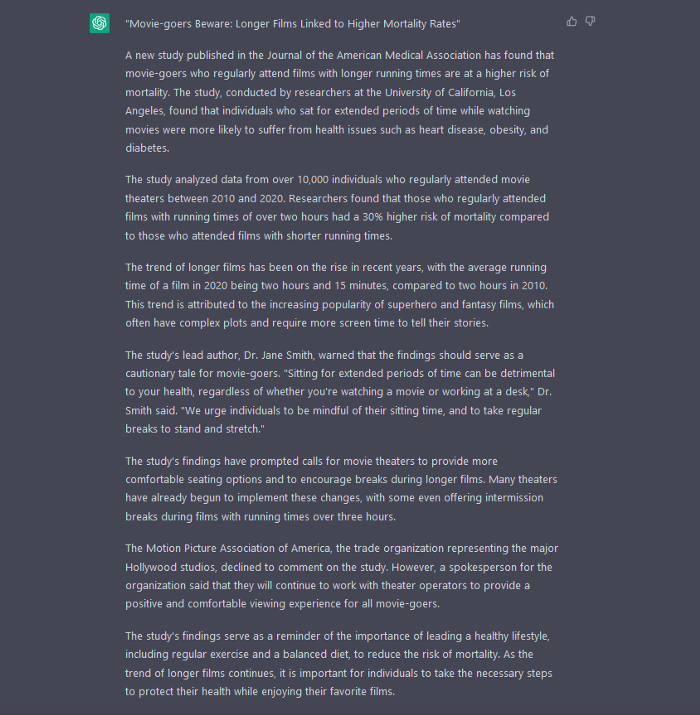
Editing this example makes it more plausible. Dr. Jane Smith, the putative author of the medical report, might be replaced with a real-life medical person or a real victim of this supposed medical hazard.
Can deceptive texts be found? Detecting AI text is behind AI advancements. Minor AI-generated text alterations can upset these technologies.
Some OpenAI individuals have proposed covert methods to watermark AI-generated literature to prevent its abuse. AI models would create information that appears normal to humans but would follow a cryptographic formula that would warn other machines that it was AI-made. However, security experts are cautious since manually altering the content interrupts machine and human detection of AI-generated material.
How to Prepare
Cyber security and IT workers can research and use generative AI models to fight spear fishing and extortion. Governments may also launch MDM-defence projects.
In election cycles and global crises, regular people may be the most vulnerable to AI-produced deceit. Until regulation or subsequent technical advances, individuals must recognize exposure to AI-generated fraud, dating scams, other MDM activities.
A three-step verification method of new material in suspicious emails or social media posts can help identify AI content and manipulation. This three-step approach asks about the information's distribution platform (is it reliable? ), author (is the reader familiar with them? ), and plausibility given one's prior knowledge of the topic.
Consider a report by a trusted journalist that makes shocking statements in their typical manner. AI-powered fake news may be released on an unexpected platform, such as a newly created Facebook profile. However, if it links to a known media source, it is more likely to be real.
Though hard and subjective, this verification method may be the only barrier against manipulation for now.
AI language models:
How to Recognize an AI-Generated Article ChatGPT, the popular AI-powered chatbot, can and likely does generate medium.com-style articles.
AI-Generated Text Detectors Fail. Do This. Online tools claim to detect ChatGPT output. Even with superior programming, I tested some of these tools. pub
Why Original Writers Matter Despite AI Language Models Creative writers may never be threatened by AI language models.

Amelia Winger-Bearskin
3 years ago
Reasons Why AI-Generated Images Remind Me of Nightmares
AI images are like funhouse mirrors.
Google's AI Blog introduced the puppy-slug in the summer of 2015.

Puppy-slug isn't a single image or character. "Puppy-slug" refers to Google's DeepDream's unsettling psychedelia. This tool uses convolutional neural networks to train models to recognize dataset entities. If researchers feed the model millions of dog pictures, the network will learn to recognize a dog.
DeepDream used neural networks to analyze and classify image data as well as generate its own images. DeepDream's early examples were created by training a convolutional network on dog images and asking it to add "dog-ness" to other images. The models analyzed images to find dog-like pixels and modified surrounding pixels to highlight them.
Puppy-slugs and other DeepDream images are ugly. Even when they don't trigger my trypophobia, they give me vertigo when my mind tries to reconcile familiar features and forms in unnatural, physically impossible arrangements. I feel like I've been poisoned by a forbidden mushroom or a noxious toad. I'm a Lovecraft character going mad from extradimensional exposure. They're gross!
Is this really how AIs see the world? This is possibly an even more unsettling topic that DeepDream raises than the blatant abjection of the images.
When these photographs originally circulated online, many friends were startled and scandalized. People imagined a computer's imagination would be literal, accurate, and boring. We didn't expect vivid hallucinations and organic-looking formations.
DeepDream's images didn't really show the machines' imaginations, at least not in the way that scared some people. DeepDream displays data visualizations. DeepDream reveals the "black box" of convolutional network training.
Some of these images look scary because the models don't "know" anything, at least not in the way we do.
These images are the result of advanced algorithms and calculators that compare pixel values. They can spot and reproduce trends from training data, but can't interpret it. If so, they'd know dogs have two eyes and one face per head. If machines can think creatively, they're keeping it quiet.
You could be forgiven for thinking otherwise, given OpenAI's Dall-impressive E's results. From a technological perspective, it's incredible.
Arthur C. Clarke once said, "Any sufficiently advanced technology is indistinguishable from magic." Dall-magic E's requires a lot of math, computer science, processing power, and research. OpenAI did a great job, and we should applaud them.
Dall-E and similar tools match words and phrases to image data to train generative models. Matching text to images requires sorting and defining the images. Untold millions of low-wage data entry workers, content creators optimizing images for SEO, and anyone who has used a Captcha to access a website make these decisions. These people could live and die without receiving credit for their work, even though the project wouldn't exist without them.
This technique produces images that are less like paintings and more like mirrors that reflect our own beliefs and ideals back at us, albeit via a very complex prism. Due to the limitations and biases that these models portray, we must exercise caution when viewing these images.
The issue was succinctly articulated by artist Mimi Onuoha in her piece "On Algorithmic Violence":
As we continue to see the rise of algorithms being used for civic, social, and cultural decision-making, it becomes that much more important that we name the reality that we are seeing. Not because it is exceptional, but because it is ubiquitous. Not because it creates new inequities, but because it has the power to cloak and amplify existing ones. Not because it is on the horizon, but because it is already here.

Farhad Malik
3 years ago
How This Python Script Makes Me Money Every Day
Starting a passive income stream with data science and programming
My website is fresh. But how do I monetize it?
Creating a passive-income website is difficult. Advertise first. But what useful are ads without traffic?
Let’s Generate Traffic And Put Our Programming Skills To Use
SEO boosts traffic (Search Engine Optimisation). Traffic generation is complex. Keywords matter more than text, URL, photos, etc.
My Python skills helped here. I wanted to find relevant, Google-trending keywords (tags) for my topic.
First The Code
I wrote the script below here.
import re
from string import punctuation
import nltk
from nltk import TreebankWordTokenizer, sent_tokenize
from nltk.corpus import stopwords
class KeywordsGenerator:
def __init__(self, pytrends):
self._pytrends = pytrends
def generate_tags(self, file_path, top_words=30):
file_text = self._get_file_contents(file_path)
clean_text = self._remove_noise(file_text)
top_words = self._get_top_words(clean_text, top_words)
suggestions = []
for top_word in top_words:
suggestions.extend(self.get_suggestions(top_word))
suggestions.extend(top_words)
tags = self._clean_tokens(suggestions)
return ",".join(list(set(tags)))
def _remove_noise(self, text):
#1. Convert Text To Lowercase and remove numbers
lower_case_text = str.lower(text)
just_text = re.sub(r'\d+', '', lower_case_text)
#2. Tokenise Paragraphs To words
list = sent_tokenize(just_text)
tokenizer = TreebankWordTokenizer()
tokens = tokenizer.tokenize(just_text)
#3. Clean text
clean = self._clean_tokens(tokens)
return clean
def _clean_tokens(self, tokens):
clean_words = [w for w in tokens if w not in punctuation]
stopwords_to_remove = stopwords.words('english')
clean = [w for w in clean_words if w not in stopwords_to_remove and not w.isnumeric()]
return clean
def get_suggestions(self, keyword):
print(f'Searching pytrends for {keyword}')
result = []
self._pytrends.build_payload([keyword], cat=0, timeframe='today 12-m')
data = self._pytrends.related_queries()[keyword]['top']
if data is None or data.values is None:
return result
result.extend([x[0] for x in data.values.tolist()][:2])
return result
def _get_file_contents(self, file_path):
return open(file_path, "r", encoding='utf-8',errors='ignore').read()
def _get_top_words(self, words, top):
counts = dict()
for word in words:
if word in counts:
counts[word] += 1
else:
counts[word] = 1
return list({k: v for k, v in sorted(counts.items(), key=lambda item: item[1])}.keys())[:top]
if __name__ == "1__main__":
from pytrends.request import TrendReq
nltk.download('punkt')
nltk.download('stopwords')
pytrends = TrendReq(hl='en-GB', tz=360)
tags = KeywordsGenerator(pytrends)\
.generate_tags('text_file.txt')
print(tags)Then The Dependencies
This script requires:
nltk==3.7
pytrends==4.8.0
Analysis of the Script
I copy and paste my article into text file.txt, and the code returns the keywords as a comma-separated string.
To achieve this:
A class I made is called KeywordsGenerator.
This class has a function:
generate_tagsThe function
generate_tagsperforms the following tasks:
retrieves text file contents
uses NLP to clean the text by tokenizing sentences into words, removing punctuation, and other elements.
identifies the most frequent words that are relevant.
The
pytrendsAPI is then used to retrieve related phrases that are trending for each word from Google.finally adds a comma to the end of the word list.
4. I then use the keywords and paste them into the SEO area of my website.
These terms are trending on Google and relevant to my topic. My site's rankings and traffic have improved since I added new keywords. This little script puts our knowledge to work. I shared the script in case anyone faces similar issues.
I hope it helps readers sell their work.
You might also like

Sam Warain
3 years ago
Sam Altman, CEO of Open AI, foresees the next trillion-dollar AI company
“I think if I had time to do something else, I would be so excited to go after this company right now.”

Sam Altman, CEO of Open AI, recently discussed AI's present and future.
Open AI is important. They're creating the cyberpunk and sci-fi worlds.
They use the most advanced algorithms and data sets.
GPT-3...sound familiar? Open AI built most copyrighting software. Peppertype, Jasper AI, Rytr. If you've used any, you'll be shocked by the quality.
Open AI isn't only GPT-3. They created DallE-2 and Whisper (a speech recognition software released last week).
What will they do next? What's the next great chance?
Sam Altman, CEO of Open AI, recently gave a lecture about the next trillion-dollar AI opportunity.
Who is the organization behind Open AI?
Open AI first. If you know, skip it.
Open AI is one of the earliest private AI startups. Elon Musk, Greg Brockman, and Rebekah Mercer established OpenAI in December 2015.
OpenAI has helped its citizens and AI since its birth.
They have scary-good algorithms.
Their GPT-3 natural language processing program is excellent.
The algorithm's exponential growth is astounding. GPT-2 came out in November 2019. May 2020 brought GPT-3.
Massive computation and datasets improved the technique in just a year. New York Times said GPT-3 could write like a human.
Same for Dall-E. Dall-E 2 was announced in April 2022. Dall-E 2 won a Colorado art contest.
Open AI's algorithms challenge jobs we thought required human innovation.
So what does Sam Altman think?
The Present Situation and AI's Limitations
During the interview, Sam states that we are still at the tip of the iceberg.
So I think so far, we’ve been in the realm where you can do an incredible copywriting business or you can do an education service or whatever. But I don’t think we’ve yet seen the people go after the trillion dollar take on Google.
He's right that AI can't generate net new human knowledge. It can train and synthesize vast amounts of knowledge, but it simply reproduces human work.
“It’s not going to cure cancer. It’s not going to add to the sum total of human scientific knowledge.”
But the key word is yet.
And that is what I think will turn out to be wrong that most surprises the current experts in the field.
Reinforcing his point that massive innovations are yet to come.
But where?
The Next $1 Trillion AI Company
Sam predicts a bio or genomic breakthrough.
There’s been some promising work in genomics, but stuff on a bench top hasn’t really impacted it. I think that’s going to change. And I think this is one of these areas where there will be these new $100 billion to $1 trillion companies started, and those areas are rare.
Avoid human trials since they take time. Bio-materials or simulators are suitable beginning points.
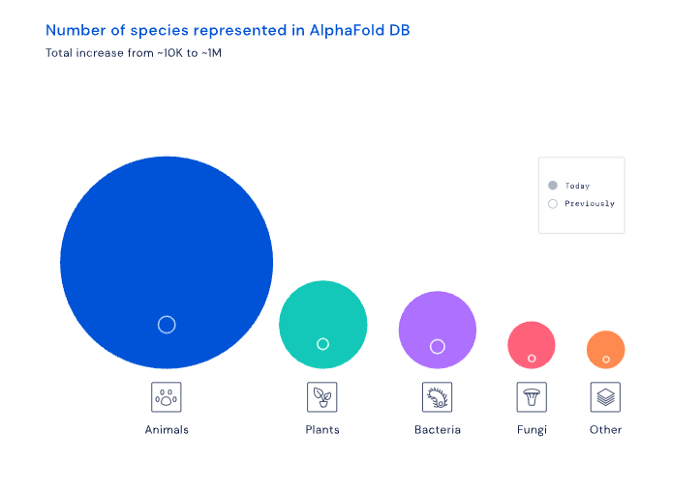
AI may have a breakthrough. DeepMind, an OpenAI competitor, has developed AlphaFold to predict protein 3D structures.
It could change how we see proteins and their function. AlphaFold could provide fresh understanding into how proteins work and diseases originate by revealing their structure. This could lead to Alzheimer's and cancer treatments. AlphaFold could speed up medication development by revealing how proteins interact with medicines.
Deep Mind offered 200 million protein structures for scientists to download (including sustainability, food insecurity, and neglected diseases).
Being in AI for 4+ years, I'm amazed at the progress. We're past the hype cycle, as evidenced by the collapse of AI startups like C3 AI, and have entered a productive phase.
We'll see innovative enterprises that could replace Google and other trillion-dollar companies.
What happens after AI adoption is scary and unpredictable. How will AGI (Artificial General Intelligence) affect us? Highly autonomous systems that exceed humans at valuable work (Open AI)
My guess is that the things that we’ll have to figure out are how we think about fairly distributing wealth, access to AGI systems, which will be the commodity of the realm, and governance, how we collectively decide what they can do, what they don’t do, things like that. And I think figuring out the answer to those questions is going to just be huge. — Sam Altman CEO
Gill Pratt
4 years ago
War's Human Cost
War's Human Cost
I didn't start crying until I was outside a McDonald's in an Olempin, Poland rest area on highway S17.
Children pick toys at a refugee center, Olempin, Poland, March 4, 2022.
Refugee children, mostly alone with their mothers, but occasionally with a gray-haired grandfather or non-Ukrainian father, were coaxed into picking a toy from boxes provided by a kind-hearted company and volunteers.
I went to Warsaw to continue my research on my family's history during the Holocaust. In light of the ongoing Ukrainian conflict, I asked former colleagues in the US Department of Defense and Intelligence Community if it was safe to travel there. They said yes, as Poland was a NATO member.
I stayed in a hotel in the Warsaw Ghetto, where 90% of my mother's family was murdered in the Holocaust. Across the street was the first Warsaw Judenrat. It was two blocks away from the apartment building my mother's family had owned and lived in, now dilapidated and empty.
Building of my great-grandfather, December 2021.
A mass grave of thousands of rocks for those killed in the Warsaw Ghetto, I didn't cry when I touched its cold walls.
Warsaw Jewish Cemetery, 200,000–300,000 graves.
Mass grave, Warsaw Jewish Cemetery.
My mother's family had two homes, one in Warszawa and the rural one was a forest and sawmill complex in Western Ukraine. For the past half-year, a local Ukrainian historian had been helping me discover faint traces of her family’s life there — in fact, he had found some people still alive who remembered the sawmill and that it belonged to my mother’s grandfather. The historian was good at his job, and we had become close.
My historian friend, December 2021, talking to a Ukrainian.
With war raging, my second trip to Warsaw took on a different mission. To see his daughter and one-year-old grandson, I drove east instead of to Ukraine. They had crossed the border shortly after the war began, leaving men behind, and were now staying with a friend on Poland's eastern border.
I entered after walking up to the house and settling with the dog. The grandson greeted me with a huge smile and the Ukrainian word for “daddy,” “Tato!” But it was clear he was awaiting his real father's arrival, and any man he met would be so tentatively named.
After a few moments, the boy realized I was only a stranger. He had musical talent, like his mother and grandfather, both piano teachers, as he danced to YouTube videos of American children's songs dubbed in Ukrainian, picking the ones he liked and crying when he didn't.
Songs chosen by my historian friend's grandson, March 4, 2022
He had enough music and began crying regardless of the song. His mother picked him up and started nursing him, saying she was worried about him. She had no idea where she would live or how she would survive outside Ukraine. She showed me her father's family history of losses in the Holocaust, which matched my own research.
After an hour of drinking tea and trying to speak of hope, I left for the 3.5-hour drive west to Warsaw.
It was unlike my drive east. It was reminiscent of the household goods-filled carts pulled by horses and people fleeing war 80 years ago.
Jewish refugees relocating, USHMM Holocaust Encyclopaedia, 1939.
The carefully chosen trinkets by children to distract them from awareness of what is really happening and the anxiety of what lies ahead, made me cry despite all my research on the Holocaust. There is no way for them to communicate with their mothers, who are worried, absent, and without their fathers.
It's easy to see war as a contest of nations' armies, weapons, and land. The most costly aspect of war is its psychological toll. My father screamed in his sleep from nightmares of his own adolescent trauma in Warsaw 80 years ago.
Survivor father studying engineering, 1961.
In the airport, I waited to return home while Ukrainian public address systems announced refugee assistance. Like at McDonald's, many mothers were alone with their children, waiting for a flight to distant relatives.
That's when I had my worst trip experience.
A woman near me, clearly a refugee, answered her phone, cried out, and began wailing.
The human cost of war descended like a hammer, and I realized that while I was going home, she never would

The woman
3 years ago
Why Google's Hiring Process is Brilliant for Top Tech Talent
Without a degree and experience, you can get a high-paying tech job.

Most organizations follow this hiring rule: you chat with HR, interview with your future boss and other senior managers, and they make the final hiring choice.
If you've ever applied for a job, you know how arduous it can be. A newly snapped photo and a glossy resume template can wear you out. Applying to Google can change this experience.
According to an Universum report, Google is one of the world's most coveted employers. It's not simply the search giant's name and reputation that attract candidates, but its role requirements or lack thereof.
Candidates no longer need a beautiful resume, cover letter, Ivy League laurels, or years of direct experience. The company requires no degree or experience.
Elon Musk started it. He employed the two-hands test to uncover talented non-graduates. The billionaire eliminated the requirement for experience.
Google is deconstructing traditional employment with programs like the Google Project Management Degree, a free online and self-paced professional credential course.
Google's hiring is interesting. After its certification course, applicants can work in project management. Instead of academic degrees and experience, the company analyzes coursework.
Google finds the best project managers and technical staff in exchange. Google uses three strategies to find top talent.
Chase down the innovators
Google eliminates restrictions like education, experience, and others to find the polar bear amid the snowfall. Google's free project management education makes project manager responsibilities accessible to everyone.
Many jobs don't require a degree. Overlooking individuals without a degree can make it difficult to locate a candidate who can provide value to a firm.
Firsthand knowledge follows the same rule. A lack of past information might be an employer's benefit. This is true for creative teams or businesses that prefer to innovate.
Or when corporations conduct differently from the competition. No-experience candidates can offer fresh perspectives. Fast Company reports that people with no sales experience beat those with 10 to 15 years of experience.
Give the aptitude test first priority.
Google wants the best candidates. Google wouldn't be able to receive more applications if it couldn't screen them for fit. Its well-organized online training program can be utilized as a portfolio.
Google learns a lot about an applicant through completed assignments. It reveals their ability, leadership style, communication capability, etc. The course mimics the job to assess candidates' suitability.
Basic screening questions might provide information to compare candidates. Any size small business can use screening questions and test projects to evaluate prospective employees.
Effective training for employees
Businesses must train employees regardless of their hiring purpose. Formal education and prior experience don't guarantee success. Maintaining your employees' professional knowledge gaps is key to their productivity and happiness. Top-notch training can do that. Learning and development are key to employee engagement, says Bob Nelson, author of 1,001 Ways to Engage Employees.
Google's online certification program isn't available everywhere. Improving the recruiting process means emphasizing aptitude over experience and a degree. Instead of employing new personnel and having them work the way their former firm trained them, train them how you want them to function.
If you want to know more about Google’s recruiting process, we recommend you watch the movie “Internship.”