


StableGains lost $42M in Anchor Protocol.
StableGains lost millions of dollars in customer funds in Anchor Protocol without telling its users. The Anchor Protocol offered depositors 19-20% APY before its parent ecosystem, Terra LUNA, lost tens of billions of dollars in market capitalization as LUNA fell below $0.01 and its stablecoin (UST) collapsed.
A Terra Research Forum member raised the alarm. StableGains changed its homepage and Terms and Conditions to reflect how it mitigates risk, a tacit admission that it should have done so from the start.
StableGains raised $600,000 in YCombinator's W22 batch. Moonfire, Broom Ventures, and Goodwater Capital invested $3 million more.
StableGains' 15% yield product attracted $42 million in deposits. StableGains kept most of its deposits in Anchor's UST pool earning 19-20% APY, kept one-quarter of the interest as a management fee, and then gave customers their promised 15% APY. It lost almost all customer funds when UST melted down. It changed withdrawal times, hurting customers.
- StableGains said de-pegging was unlikely. According to its website, 1 UST can be bought and sold for $1 of LUNA. LUNA became worthless, and Terra shut down its blockchain.
- It promised to diversify assets across several stablecoins to reduce the risk of one losing its $1 peg, but instead kept almost all of them in one basket.
- StableGains promised withdrawals in three business days, even if a stablecoin needed time to regain its peg. StableGains uses Coinbase for deposits and withdrawals, and customers receive the exact amount of USDC requested.
StableGains scrubs its website squeaky clean
StableGains later edited its website to say it only uses the "most trusted and tested stablecoins" and extended withdrawal times from three days to indefinite time "in extreme cases."
Previously, USDC, TerraUST (UST), and Dai were used (DAI). StableGains changed UST-related website content after the meltdown. It also removed most references to DAI.
Customers noticed a new clause in the Terms and Conditions denying StableGains liability for withdrawal losses. This new clause would have required customers to agree not to sue before withdrawing funds, avoiding a class-action lawsuit.
Customers must sign a waiver to receive a refund.
Erickson Kramer & Osborne law firm has asked StableGains to preserve all internal documents on customer accounts, marketing, and TerraUSD communications. The firm has not yet filed a lawsuit.
Thousands of StableGains customers lost an estimated $42 million.
Celsius Network customers also affected
CEL used Terra LUNA's Anchor Protocol. Celsius users lost money in the crypto market crash and UST meltdown. Many held CEL and LUNA as yielding deposits.
CEO Alex Mashinsky accused "unknown malefactors" of targeting Celsius Network without evidence. Celsius has not publicly investigated this claim as of this article's publication.
CEL fell before UST de-pegged. On June 2, 2021, it reached $8.01. May 19's close: $0.82.
When some Celsius Network users threatened to leave over token losses, Mashinsky replied, "Leave if you don't think I'm sincere and working harder than you, seven days a week."
Celsius Network withdrew $500 million from Anchor Protocol, but smaller holders had trouble.
Read original article here
More on Web3 & Crypto

Percy Bolmér
3 years ago
Ethereum No Longer Consumes A Medium-Sized Country's Electricity To Run
The Merge cut Ethereum's energy use by 99.5%.

The Crypto community celebrated on September 15, 2022. This day, Ethereum Merged. The entire blockchain successfully merged with the Beacon chain, and it was so smooth you barely noticed.
Many have waited, dreaded, and longed for this day.
Some investors feared the network would break down, while others envisioned a seamless merging.
Speculators predict a successful Merge will lead investors to Ethereum. This could boost Ethereum's popularity.
What Has Changed Since The Merge
The merging transitions Ethereum mainnet from PoW to PoS.
PoW sends a mathematical riddle to computers worldwide (miners). First miner to solve puzzle updates blockchain and is rewarded.
The puzzles sent are power-intensive to solve, so mining requires a lot of electricity. It's sent to every miner competing to solve it, requiring duplicate computation.
PoS allows investors to stake their coins to validate a new transaction. Instead of validating a whole block, you validate a transaction and get the fees.
You can validate instead of mine. A validator stakes 32 Ethereum. After staking, the validator can validate future blocks.
Once a validator validates a block, it's sent to a randomly selected group of other validators. This group verifies that a validator is not malicious and doesn't validate fake blocks.
This way, only one computer needs to solve or validate the transaction, instead of all miners. The validated block must be approved by a small group of validators, causing duplicate computation.
PoS is more secure because validating fake blocks results in slashing. You lose your bet tokens. If a validator signs a bad block or double-signs conflicting blocks, their ETH is burned.
Theoretically, Ethereum has one block every 12 seconds, so a validator forging a block risks burning 1 Ethereum for 12 seconds of transactions. This makes mistakes expensive and risky.
What Impact Does This Have On Energy Use?
Cryptocurrency is a natural calamity, sucking electricity and eating away at the earth one transaction at a time.
Many don't know the environmental impact of cryptocurrencies, yet it's tremendous.
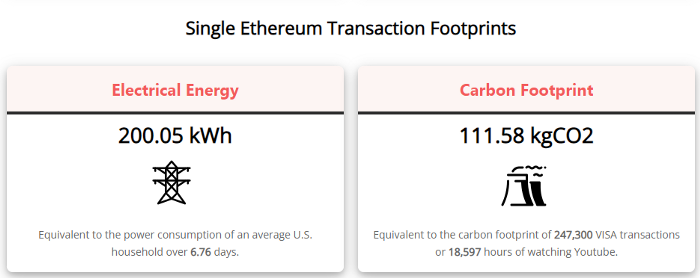
A single Ethereum transaction used to use 200 kWh and leave a large carbon imprint. This update reduces global energy use by 0.2%.
Ethereum will submit a challenge to one validator, and that validator will forward it to randomly selected other validators who accept it.
This reduces the needed computing power.
They expect a 99.5% reduction, therefore a single transaction should cost 1 kWh.
Carbon footprint is 0.58 kgCO2, or 1,235 VISA transactions.
This is a big Ethereum blockchain update.
I love cryptocurrency and Mother Earth.

Rishi Dean
4 years ago
Coinbase's web3 app
Use popular Ethereum dapps with Coinbase’s new dapp wallet and browser
Tl;dr: This post highlights the ability to access web3 directly from your Coinbase app using our new dapp wallet and browser.
Decentralized autonomous organizations (DAOs) and decentralized finance (DeFi) have gained popularity in the last year (DAOs). The total value locked (TVL) of DeFi investments on the Ethereum blockchain has grown to over $110B USD, while NFTs sales have grown to over $30B USD in the last 12 months (LTM). New innovative real-world applications are emerging every day.
Today, a small group of Coinbase app users can access Ethereum-based dapps. Buying NFTs on Coinbase NFT and OpenSea, trading on Uniswap and Sushiswap, and borrowing and lending on Curve and Compound are examples.
Our new dapp wallet and dapp browser enable you to access and explore web3 directly from your Coinbase app.
Web3 in the Coinbase app
Users can now access dapps without a recovery phrase. This innovative dapp wallet experience uses Multi-Party Computation (MPC) technology to secure your on-chain wallet. This wallet's design allows you and Coinbase to share the 'key.' If you lose access to your device, the key to your dapp wallet is still safe and Coinbase can help recover it.
Set up your new dapp wallet by clicking the "Browser" tab in the Android app's navigation bar. Once set up, the Coinbase app's new dapp browser lets you search, discover, and use Ethereum-based dapps.
Looking forward
We want to enable everyone to seamlessly and safely participate in web3, and today’s launch is another step on that journey. We're rolling out the new dapp wallet and browser in the US on Android first to a small subset of users and plan to expand soon. Stay tuned!
Olga Kharif
4 years ago
A month after freezing customer withdrawals, Celsius files for bankruptcy.

Alex Mashinsky, CEO of Celsius, speaks at Web Summit 2021 in Lisbon.
Celsius Network filed for Chapter 11 bankruptcy a month after freezing customer withdrawals, joining other crypto casualties.
Celsius took the step to stabilize its business and restructure for all stakeholders. The filing was done in the Southern District of New York.
The company, which amassed more than $20 billion by offering 18% interest on cryptocurrency deposits, paused withdrawals and other functions in mid-June, citing "extreme market conditions."
As the Fed raises interest rates aggressively, it hurts risk sentiment and squeezes funding costs. Voyager Digital Ltd. filed for Chapter 11 bankruptcy this month, and Three Arrows Capital has called in liquidators.
Celsius called the pause "difficult but necessary." Without the halt, "the acceleration of withdrawals would have allowed certain customers to be paid in full while leaving others to wait for Celsius to harvest value from illiquid or longer-term asset deployment activities," it said.
Celsius declined to comment. CEO Alex Mashinsky said the move will strengthen the company's future.
The company wants to keep operating. It's not requesting permission to allow customer withdrawals right now; Chapter 11 will handle customer claims. The filing estimates assets and liabilities between $1 billion and $10 billion.
Celsius is advised by Kirkland & Ellis, Centerview Partners, and Alvarez & Marsal.
Yield-promises
Celsius promised 18% returns on crypto loans. It lent those coins to institutional investors and participated in decentralized-finance apps.
When TerraUSD (UST) and Luna collapsed in May, Celsius pulled its funds from Terra's Anchor Protocol, which offered 20% returns on UST deposits. Recently, another large holding, staked ETH, or stETH, which is tied to Ether, became illiquid and discounted to Ether.
The lender is one of many crypto companies hurt by risky bets in the bear market. Also, Babel halted withdrawals. Voyager Digital filed for bankruptcy, and crypto hedge fund Three Arrows Capital filed for Chapter 15 bankruptcy.
According to blockchain data and tracker Zapper, Celsius repaid all of its debt in Aave, Compound, and MakerDAO last month.
Celsius charged Symbolic Capital Partners Ltd. 2,000 Ether as collateral for a cash loan on June 13. According to company filings, Symbolic was charged 2,545.25 Ether on June 11.
In July 6 filings, it said it reshuffled its board, appointing two new members and firing others.
You might also like

Alex Mathers
3 years ago Draft
12 practices of the zenith individuals I know
Calmness is a vital life skill.
It aids communication. It boosts creativity and performance.
I've studied calm people's habits for years. Commonalities:
Have learned to laugh at themselves.
Those who have something to protect can’t help but make it a very serious business, which drains the energy out of the room.
They are fixated on positive pursuits like making cool things, building a strong physique, and having fun with others rather than on depressing influences like the news and gossip.
Every day, spend at least 20 minutes moving, whether it's walking, yoga, or lifting weights.
Discover ways to take pleasure in life's challenges.
Since perspective is malleable, they change their view.
Set your own needs first.
Stressed people neglect themselves and wonder why they struggle.
Prioritize self-care.
Don't ruin your life to please others.
Make something.
Calm people create more than react.
They love creating beautiful things—paintings, children, relationships, and projects.
Hold your breath, please.
If you're stressed or angry, you may be surprised how much time you spend holding your breath and tightening your belly.
Release, breathe, and relax to find calm.
Stopped rushing.
Rushing is disadvantageous.
Calm people handle life better.
Are attuned to their personal dietary needs.
They avoid junk food and eat foods that keep them healthy, happy, and calm.
Don’t take anything personally.
Stressed people control everything.
Self-conscious.
Calm people put others and their work first.
Keep their surroundings neat.
Maintaining an uplifting and clutter-free environment daily calms the mind.
Minimise negative people.
Calm people are ruthless with their boundaries and avoid negative and drama-prone people.

SAHIL SAPRU
3 years ago
How I grew my business to a $5 million annual recurring revenue
Scaling your startup requires answering customer demands, not growth tricks.
I cofounded Freedo Rentals in 2019. I reached 50 lakh+ ARR in 6 months before quitting owing to the epidemic.
Freedo aimed to solve 2 customer pain points:
Users lacked a reliable last-mile transportation option.
The amount that Auto walas charge for unmetered services
Solution?
Effectively simple.
Build ports at high-demand spots (colleges, residential societies, metros). Electric ride-sharing can meet demand.
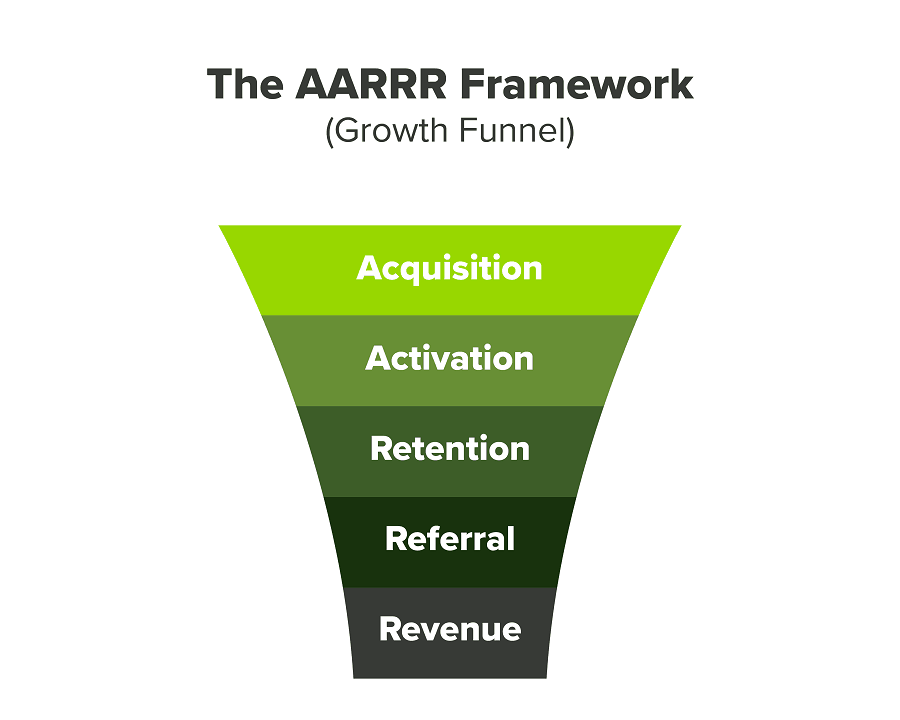
We had many problems scaling. I'll explain using the AARRR model.
Brand unfamiliarity or a novel product offering were the problems with awareness. Nobody knew what Freedo was or what it did.
Problem with awareness: Content and advertisements did a poor job of communicating the task at hand. The advertisements clashed with the white-collar part because they were too cheesy.
Retention Issue: We encountered issues, indicating that the product was insufficient. Problems with keyless entry, creating bills, stealing helmets, etc.
Retention/Revenue Issue: Costly compared to established rivals. Shared cars were 1/3 of our cost.
Referral Issue: Missing the opportunity to seize the AHA moment. After the ride, nobody remembered us.
Once you know where you're struggling with AARRR, iterative solutions are usually best.
Once you have nailed the AARRR model, most startups use paid channels to scale. This dependence, on paid channels, increases with scale unless you crack your organic/inbound game.
Over-index growth loops. Growth loops increase inflow and customers as you scale.
When considering growth, ask yourself:
Who is the solution's ICP (Ideal Customer Profile)? (To whom are you selling)
What are the most important messages I should convey to customers? (This is an A/B test.)
Which marketing channels ought I prioritize? (Conduct analysis based on the startup's maturity/stage.)
Choose the important metrics to monitor for your AARRR funnel (not all metrics are equal)
Identify the Flywheel effect's growth loops (inertia matters)
My biggest mistakes:
not paying attention to consumer comments or satisfaction. It is the main cause of problems with referrals, retention, and acquisition for startups. Beyond your NPS, you should consider second-order consequences.
The tasks at hand should be quite clear.
Here's my scaling equation:
Growth = A x B x C
A = Funnel top (Traffic)
B = Product Valuation (Solving a real pain point)
C = Aha! (Emotional response)
Freedo's A, B, and C created a unique offering.
Freedo’s ABC:
A — Working or Studying population in NCR
B — Electric Vehicles provide last-mile mobility as a clean and affordable solution
C — One click booking with a no-noise scooter
Final outcome:
FWe scaled Freedo to Rs. 50 lakh MRR and were growing 60% month on month till the pandemic ceased our growth story.
How we did it?
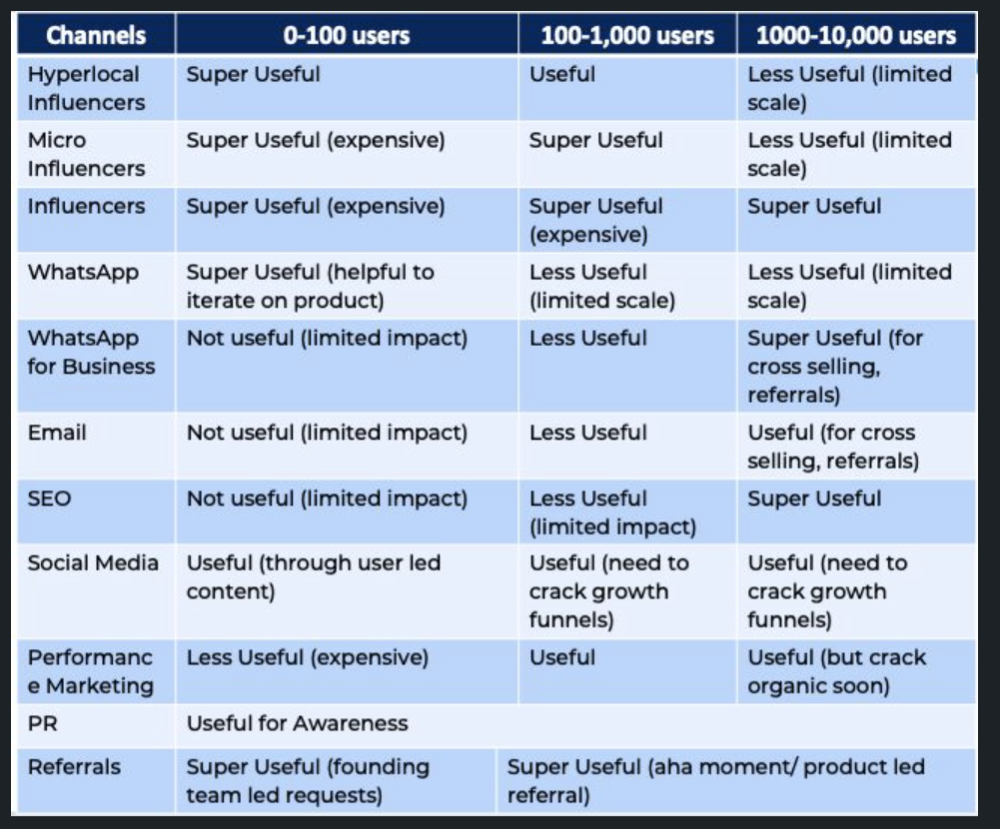
We tried ambassadors and coupons. WhatsApp was our most successful A/B test.
We grew widespread adoption through college and society WhatsApp groups. We requested users for referrals in community groups.
What worked for us won't work for others. This scale underwent many revisions.
Every firm is different, thus you must know your customers. Needs to determine which channel to prioritize and when.
Users desired a safe, time-bound means to get there.
This (not mine) growth framework helped me a lot. You should follow suit.

Sarah Bird
3 years ago
Memes Help This YouTube Channel Earn Over $12k Per Month
Take a look at a YouTube channel making anything up to over $12k a month from making very simple videos.
And the best part? Its replicable by anyone. Basic videos can be generated for free without design abilities.
Join me as I deconstruct the channel to estimate how much they make, how they do it, and how you can too.
What Do They Do Exactly?
Happy Land posts memes with a simple caption they wrote. So, it's new. The videos are a slideshow of meme photos with stock music.
The site posts 12 times a day.
8-10-minute videos show 10 second images. Thus, each video needs 48-60 memes.
Memes are video titles (e.g. times a boyfriend was hilarious, back to school fails, funny restaurant signs).
Some stats about the channel:
Founded on October 30, 2020
873 videos were added.
81.8k subscribers
67,244,196 views of the video
What Value Are They Adding?
Everyone can find free memes online. This channel collects similar memes into a single video so you don't have to scroll or click for more. It’s right there, you just keep watching and more will come.
By theming it, the audience is prepared for the video's content.
If you want hilarious animal memes or restaurant signs, choose the video and you'll get up to 60 memes without having to look for them. Genius!
How much money do they make?
According to www.socialblade.com, the channel earns $800-12.8k (image shown in my home currency of GBP).
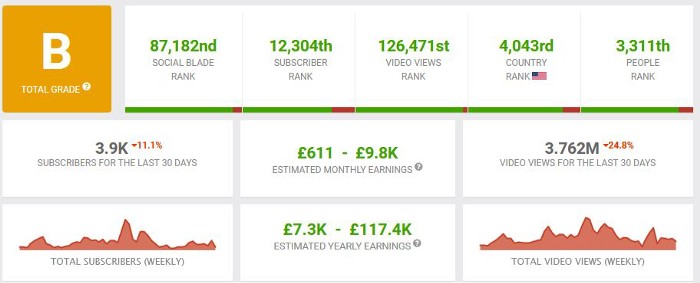
That's a crazy estimate, but it highlights the unbelievable potential of a channel that presents memes.
This channel thrives on quantity, thus putting out videos is necessary to keep the flow continuing and capture its audience's attention.
How Are the Videos Made?
Straightforward. Memes are added to a presentation without editing (so you could make this in PowerPoint or Keynote).
Each slide should include a unique image and caption. Set 10 seconds per slide.
Add music and post the video.
Finding enough memes for the material and theming is difficult, but if you enjoy memes, this is a fun job.
This case study should have shown you that you don't need expensive software or design expertise to make entertaining videos. Why not try fresh, easy-to-do ideas and see where they lead?