



More on Entrepreneurship/Creators

ʟ ᴜ ᴄ ʏ
3 years ago
The Untapped Gold Mine of Inspiration and Startup Ideas
I joined the 1000 Digital Startups Movement (Gerakan 1000 Startup Digital) in 2017 and learned a lot about the startup sector. My previous essay outlined what a startup is and what must be prepared. Here I'll offer raw ideas for better products.

Intro
A good startup solves a problem. These can include environmental, economic, energy, transportation, logistics, maritime, forestry, livestock, education, tourism, legal, arts and culture, communication, and information challenges. Everything I wrote is simply a basic idea (as inspiration) and requires more mapping and validation. Learn how to construct a startup to maximize launch success.
Adrian Gunadi (Investree Co-Founder) taught me that a Founder or Co-Founder must be willing to be CEO (Chief Everything Officer). Everything is independent, including drafting a proposal, managing finances, and scheduling appointments. The best individuals will come to you if you're the best. It's easier than consulting Andy Zain (Kejora Capital Founder).
Description
To help better understanding from your idea, try to answer this following questions:
- Describe your idea/application
Maximum 1000 characters.
- Background
Explain the reasons that prompted you to realize the idea/application.
- Objective
Explain the expected goals of the creation of the idea/application.
- Solution
A solution that tells your idea can be the right solution for the problem at hand.
- Uniqueness
What makes your idea/app unique?
- Market share
Who are the people who need and are looking for your idea?
- Marketing Ways and Business Models
What is the best way to sell your idea and what is the business model?
Not everything here is a startup idea. It's meant to inspire creativity and new perspectives.
Ideas
#Application
1. Medical students can operate on patients or not. Applications that train prospective doctors to distinguish body organs and their placement are useful. In the advanced stage, the app can be built with numerous approaches so future doctors can practice operating on patients based on their ailments. If they made a mistake, they'd start over. Future doctors will be more assured and make fewer mistakes this way.
2. VR (virtual reality) technology lets people see 3D space from afar. Later, similar technology was utilized to digitally sell properties, so buyers could see the inside and room contents. Every gadget has flaws. It's like a gold mine for robbers. VR can let prospective students see a campus's facilities. This facility can also help hotels promote their products.
3. How can retail entrepreneurs maximize sales? Most popular goods' sales data. By using product and brand/type sales figures, entrepreneurs can avoid overstocking. Walmart computerized their procedures to track products from the manufacturer to the store. As Retail Link products sell out, suppliers can immediately step in.
4. Failing to marry is something to be avoided. But if it had to happen, the loss would be like the proverb “rub salt into the wound”. On the I do Now I dont website, Americans who don't marry can resell their jewelry to other brides-to-be. If some want to cancel the wedding and receive their down money and dress back, others want a wedding with particular criteria, such as a quick date and the expected building. Create a DP takeover marketplace for both sides.
#Games
1. Like in the movie, players must exit the maze they enter within 3 minutes or the shape will change, requiring them to change their strategy. The maze's transformation time will shorten after a few stages.
2. Treasure hunts involve following clues to uncover hidden goods. Here, numerous sponsors are combined in one boat, and participants can choose a game based on the prizes. Let's say X-mart is a sponsor and provides riddles or puzzles to uncover the prize in their store. After gathering enough points, the player can trade them for a gift utilizing GPS and AR (augmented reality). Players can collaborate to increase their chances of success.
3. Where's Wally? Where’s Wally displays a thick image with several things and various Wally-like characters. We must find the actual Wally, his companions, and the desired object. Make a game with a map where players must find objects for the next level. The player must find 5 artifacts randomly placed in an Egyptian-style mansion, for example. In the room, there are standard tickets, pass tickets, and gold tickets that can be removed for safekeeping, as well as a wall-mounted carpet that can be stored but not searched and turns out to be a flying rug that can be used to cross/jump to a different place. Regular tickets are spread out since they can buy life or stuff. At a higher level, a black ticket can lower your ordinary ticket. Objects can explode, scattering previously acquired stuff. If a player runs out of time, they can exchange a ticket for more.
#TVprogram
1. At the airport there are various visitors who come with different purposes. Asking tourists to live for 1 or 2 days in the city will be intriguing to witness.
2. Many professions exist. Carpenters, cooks, and lawyers must have known about job desks. Does HRD (Human Resource Development) only recruit new employees? Many don't know how to become a CEO, CMO, COO, CFO, or CTO. Showing young people what a Program Officer in an NGO does can help them choose a career.
#StampsCreations
Philatelists know that only the government can issue stamps. I hope stamps are creative so they have more worth.
1. Thermochromic pigments (leuco dyes) are well-known for their distinctive properties. By putting pigments to black and white batik stamps, for example, the black color will be translucent and display the basic color when touched (at a hot temperature).
2. In 2012, Liechtenstein Post published a laser-art Chinese zodiac stamp. Belgium (Bruges Market Square 2012), Taiwan (Swallow Tail Butterfly 2009), etc. Why not make a stencil of the president or king/queen?
3. Each country needs its unique identity, like Taiwan's silk and bamboo stamps. Create from your country's history. Using traditional paper like washi (Japan), hanji (Korea), and daluang/saeh (Indonesia) can introduce a country's culture.
4. Garbage has long been a problem. Bagasse, banana fronds, or corn husks can be used as stamp material.
5. Austria Post published a stamp containing meteor dust in 2006. 2004 meteorite found in Morocco produced the dust. Gibraltar's Rock of Gilbraltar appeared on stamps in 2002. What's so great about your country? East Java is muddy (Lapindo mud). Lapindo mud stamps will be popular. Red sand at Pink Beach, East Nusa Tenggara, could replace the mud.
#PostcardCreations
1. Map postcards are popular because they make searching easier. Combining laser-cut road map patterns with perforated 200-gram paper glued on 400-gram paper as a writing medium. Vision-impaired people can use laser-cut maps.
2. Regional art can be promoted by tucking traditional textiles into postcards.
3. A thin canvas or plain paper on the card's front allows the giver to be creative.
4. What is local crop residue? Cork lids, maize husks, and rice husks can be recycled into postcard materials.
5. Have you seen a dried-flower bookmark? Cover the postcard with mica and add dried flowers. If you're worried about losing the flowers, you can glue them or make a postcard envelope.
6. Wood may be ubiquitous; try a 0.2-mm copper plate engraved with an image and connected to a postcard as a writing medium.
7. Utilized paper pulp can be used to hold eggs, smartphones, and food. Form a smooth paper pulp on the plate with the desired image, the Golden Gate bridge, and paste it on your card.
8. Postcards can promote perfume. When customers rub their hands on the card with the perfume image, they'll smell the aroma.
#Tour #Travel
Tourism activities can be tailored to tourists' interests or needs. Each tourist benefits from tourism's distinct aim.
Let's define tourism's objective and purpose.
Holiday Tour is a tour that its participants plan and do in order to relax, have fun, and amuse themselves.
A familiarization tour is a journey designed to help travelers learn more about (survey) locales connected to their line of work.
An educational tour is one that aims to give visitors knowledge of the field of work they are visiting or an overview of it.
A scientific field is investigated and knowledge gained as the major goal of a scientific tour.
A pilgrimage tour is one designed to engage in acts of worship.
A special mission tour is one that has a specific goal, such a commerce mission or an artistic endeavor.
A hunting tour is a destination for tourists that plans organized animal hunting that is only allowed by local authorities for entertainment purposes.
Every part of life has tourism potential. Activities include:
1. Those who desire to volunteer can benefit from the humanitarian theme and collaboration with NGOs. This activity's profit isn't huge but consider the environmental impact.
2. Want to escape the city? Meditation travel can help. Beautiful spots around the globe can help people forget their concerns. A certified yoga/meditation teacher can help travelers release bad energy.
3. Any prison visitors? Some prisons, like those for minors under 17, are open to visitors. This type of tourism helps mental convicts reach a brighter future.
4. Who has taken a factory tour/study tour? Outside-of-school study tour (for ordinary people who have finished their studies). Not everyone in school could tour industries, workplaces, or embassies to learn and be inspired. Shoyeido (an incense maker) and Royce (a chocolate maker) offer factory tours in Japan.
5. Develop educational tourism like astronomy and archaeology. Until now, only a few astronomy enthusiasts have promoted astronomy tourism. In Indonesia, archaeology activities focus on site preservation, and to participate, office staff must undertake a series of training (not everyone can take a sabbatical from their routine). Archaeological tourist activities are limited, whether held by history and culture enthusiasts or in regional tours.
6. Have you ever longed to observe a film being made or your favorite musician rehearsing? Such tours can motivate young people to pursue entertainment careers.
7. Pamper your pets to reduce stress. Many pet owners don't have time for walks or treats. These premium services target the wealthy.
8. A quirky idea to provide tours for imaginary couples or things. Some people marry inanimate objects or animals and seek to make their lover happy; others cherish their ashes after death.
#MISCideas
1. Fashion is a lifestyle, thus people often seek fresh materials. Chicken claws, geckos, snake skin casings, mice, bats, and fish skins are also used. Needs some improvement, definitely.
2. As fuel supplies become scarcer, people hunt for other energy sources. Sound is an underutilized renewable energy. The Batechsant technology converts environmental noise into electrical energy, according to study (Battery Technology Of Sound Power Plant). South Korean researchers use Sound-Driven Piezoelectric Nanowire based on Nanogenerators to recharge cell phone batteries. The Batechsant system uses existing noise levels to provide electricity for street lamp lights, aviation, and ships. Using waterfall sound can also energize hard-to-reach locations.
3. A New York Times reporter said IQ doesn't ensure success. Our school system prioritizes IQ above EQ (Emotional Quotient). EQ is a sort of human intelligence that allows a person to perceive and analyze the dynamics of his emotions when interacting with others (and with himself). EQ is suspected of being a bigger source of success than IQ. EQ training can gain greater attention to help people succeed. Prioritize role models from school stakeholders, teachers, and parents to improve children' EQ.
4. Teaching focuses more on theory than practice, so students are less eager to explore and easily forget if they don't pay attention. Has an engineer ever made bricks from arid red soil? Morocco's non-college-educated builders can create weatherproof bricks from red soil without equipment. Can mechanical engineering grads create a water pump to solve water shortages in remote areas? Art graduates can innovate beyond only painting. Artists may create kinetic sculpture by experimenting so much. Young people should understand these sciences so they can be more creative with their potential. These might be extracurricular activities in high school and university.
5. People have been trying to recycle agricultural waste for a long time. Mycelium helps replace light, easily crushed tiles and bricks (a collection of hyphae like in the manufacture of tempe). Waste must contain lignocellulose. In this vein, anti-mainstream painting canvases can be made. The goal is to create the canvas uneven like an amoeba outline, not square or spherical. The resulting canvas is lightweight and needs no frame. Then what? Open source your idea like Precious Plastic to establish a community. By propagating this notion, many knowledgeable people will help improve your product's quality and impact.
6. As technology and humans adapt, fraud increases. Making phony doctor's letters to fool superiors, fake credentials to get hired, fraudulent land certificates to make money, and fake news (hoax). The existence of a Wikimedia can aid the community by comparing bogus and original information.
7. Do you often hit a problem-solving impasse? Since the Doraemon bag hasn't been made, construct an Idea Bank. Everyone can contribute to solving problems here. How do you recruit volunteers? Obviously, a reward is needed. Contributors can become moderators or gain complimentary tickets to TIA (Tech in Asia) conferences. Idea Bank-related concepts: the rise of startups without a solid foundation generates an age as old as corn that does not continue. Those with startup ideas should describe them here so they can be validated by other users. Other users can contribute input if a comparable notion is produced to improve the product or integrate it. Similar-minded users can become Co-Founders.
8. Why not invest in fruit/vegetables, inspired by digital farming? The landowner obtains free fruit without spending much money on maintenance. Investors can get fruits/vegetables in larger quantities, fresher, and cheaper during harvest. Fruits and vegetables are often harmed if delivered too slowly. Rich investors with limited land can invest in teak, agarwood, and other trees. When harvesting, investors might choose raw results or direct wood sales earnings. Teak takes at least 7 years to harvest, therefore long-term wood investments carry the risk of crop failure.
9. Teenagers in distant locations can't count, read, or write. Many factors hinder locals' success. Life's demands force them to work instead of study. Creating a learning playground may attract young people to learning. Make a skatepark at school. Skateboarders must learn in school. Donations buy skateboards.
10. Globally, online taxi-bike is known. By hiring a motorcycle/car online, people no longer bother traveling without a vehicle. What if you wish to cross the island or visit remote areas? Is online boat or helicopter rental possible like online taxi-bike? Such a renting process has been done independently thus far and cannot be done quickly.
11. What do startups need now? A startup or investor consultant. How many startups fail to become Unicorns? Many founders don't know how to manage investor money, therefore they waste it on promotions and other things. Many investors only know how to invest and can't guide a struggling firm.
“In times of crisis, the wise build bridges, while the foolish build barriers.” — T’Challa [Black Panther]
Don't chase cash. Money is a byproduct. Profit-seeking is stressful. Market requirements are opportunities. If you have something to say, please comment.
This is only informational. Before implementing ideas, do further study.

Greg Lim
3 years ago
How I made $160,000 from non-fiction books
I've sold over 40,000 non-fiction books on Amazon and made over $160,000 in six years while writing on the side.
I have a full-time job and three young sons; I can't spend 40 hours a week writing. This article describes my journey.
I write mainly tech books:
Thanks to my readers, many wrote positive evaluations. Several are bestsellers.
A few have been adopted by universities as textbooks:
My books' passive income allows me more time with my family.
Knowing I could quit my job and write full time gave me more confidence. And I find purpose in my work (i am in christian ministry).
I'm always eager to write. When work is a dread or something bad happens, writing gives me energy. Writing isn't scary. In fact, I can’t stop myself from writing!
Writing has also established my tech authority. Universities use my books, as I've said. Traditional publishers have asked me to write books.
These mindsets helped me become a successful nonfiction author:
1. You don’t have to be an Authority
Yes, I have computer science experience. But I'm no expert on my topics. Before authoring "Beginning Node.js, Express & MongoDB," my most profitable book, I had no experience with those topics. Node was a new server-side technology for me. Would that stop me from writing a book? It can. I liked learning a new technology. So I read the top three Node books, took the top online courses, and put them into my own book (which makes me know more than 90 percent of people already).
I didn't have to worry about using too much jargon because I was learning as I wrote. An expert forgets a beginner's hardship.
"The fellow learner can aid more than the master since he knows less," says C.S. Lewis. The problem he must explain is recent. The expert has forgotten.”
2. Solve a micro-problem (Niching down)
I didn't set out to write a definitive handbook. I found a market with several challenges and wrote one book. Ex:
- Instead of web development, what about web development using Angular?
- Instead of Blockchain, what about Blockchain using Solidity and React?
- Instead of cooking recipes, how about a recipe for a specific kind of diet?
- Instead of Learning math, what about Learning Singapore Math?
3. Piggy Backing Trends
The above topics may still be a competitive market. E.g. Angular, React. To stand out, include the latest technologies or trends in your book. Learn iOS 15 instead of iOS programming. Instead of personal finance, what about personal finance with NFTs.
Even though you're a newbie author, your topic is well-known.
4. Publish short books
My books are known for being direct. Many people like this:
Your reader will appreciate you cutting out the fluff and getting to the good stuff. A reader can finish and review your book.
Second, short books are easier to write. Instead of creating a 500-page book for $50 (which few will buy), write a 100-page book that answers a subset of the problem and sell it for less. (You make less, but that's another subject). At least it got published instead of languishing. Less time spent creating a book means less time wasted if it fails. Write a small-bets book portfolio like Daniel Vassallo!
Third, it's $2.99-$9.99 on Amazon (gets 70 percent royalties for ebooks). Anything less receives 35% royalties. $9.99 books have 20,000–30,000 words. If you write more and charge more over $9.99, you get 35% royalties. Why not make it a $9.99 book?
(This is the ebook version.) Paperbacks cost more. Higher royalties allow for higher prices.
5. Validate book idea
Amazon will tell you if your book concept, title, and related phrases are popular. See? Check its best-sellers list.
150,000 is preferable. It sells 2–3 copies daily. Consider your rivals. Profitable niches have high demand and low competition.
Don't be afraid of competitive niches. First, it shows high demand. Secondly, what are the ways you can undercut the completion? Better book? Or cheaper option? There was lots of competition in my NodeJS book's area. None received 4.5 stars or more. I wrote a NodeJS book. Today, it's a best-selling Node book.
What’s Next
So long. Part II follows. Meanwhile, I will continue to write more books!
Follow my journey on Twitter.
This post is a summary. Read full article here

Jared Heyman
3 years ago
The survival and demise of Y Combinator startups
I've written a lot about Y Combinator's success, but as any startup founder or investor knows, many startups fail.
Rebel Fund invests in the top 5-10% of new Y Combinator startups each year, so we focus on identifying and supporting the most promising technology startups in our ecosystem. Given the power law dynamic and asymmetric risk/return profile of venture capital, we worry more about our successes than our failures. Since the latter still counts, this essay will focus on the proportion of YC startups that fail.
Since YC's launch in 2005, the figure below shows the percentage of active, inactive, and public/acquired YC startups by batch.
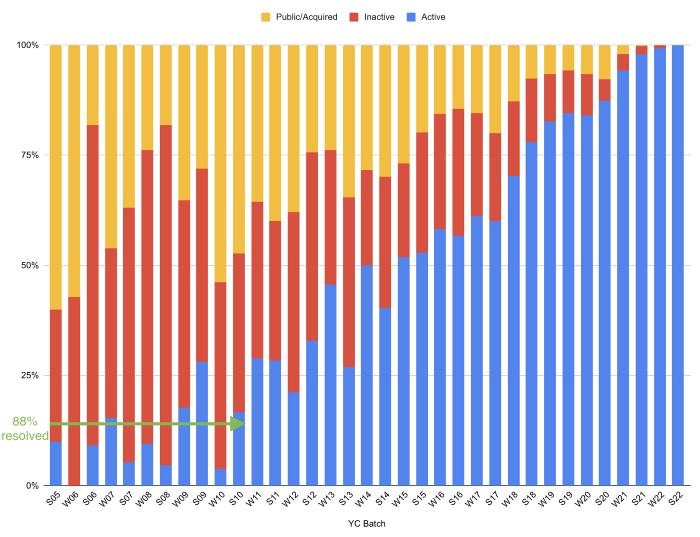
As more startups finish, the blue bars (active) decrease significantly. By 12 years, 88% of startups have closed or exited. Only 7% of startups reach resolution each year.
YC startups by status after 12 years:
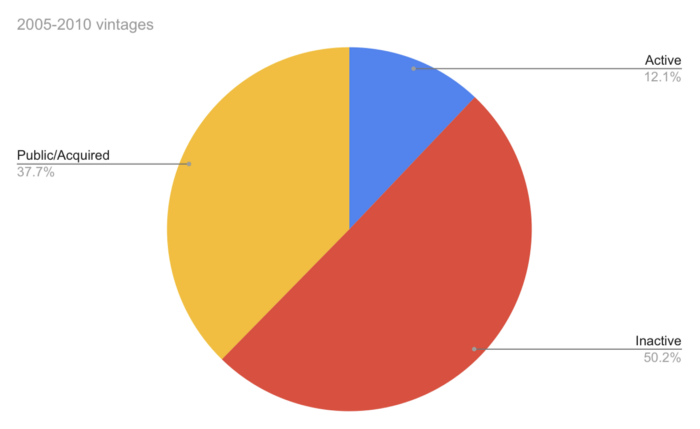
Half the startups have failed, over one-third have exited, and the rest are still operating.
In venture investing, it's said that failed investments show up before successful ones. This is true for YC startups, but only in their early years.
Below, we only present resolved companies from the first chart. Some companies fail soon after establishment, but after a few years, the inactive vs. public/acquired ratio stabilizes around 55:45. After a few years, a YC firm is roughly as likely to quit as fail, which is better than I imagined.
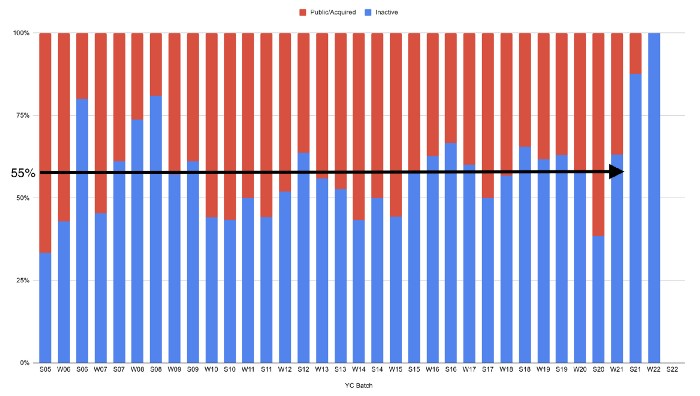
I prepared this post because Rebel investors regularly question me about YC startup failure rates and how long it takes for them to exit or shut down.
Early-stage venture investors can overlook it because 100x investments matter more than 0x investments.
YC founders can ignore it because it shouldn't matter if many of their peers succeed or fail ;)
You might also like

Asher Umerie
3 years ago
What is Bionic Reading?
Senses help us navigate a complicated world. They shape our worldview - how we hear, smell, feel, and taste. People claim a sixth sense, an intuitive capacity that extends perception.
Our brain is a half-pool of grey and white matter that stores data from our senses. Brains provide us context, so zombies' obsession makes sense.
Bionic reading uses the brain's visual information and context to simplify text comprehension.
Stay with me.
What is Bionic Reading?
Bionic reading is a software application established by Swiss typographic designer Renato Casutt. The term honors the brain (bio) and technology's collaboration to better text comprehension.
The image above shows two similar paragraphs with bionic reading.
Notice anything yet?
This Twitter user did.
I did too...
Image text describes bionic reading-
New method to aid reading by using artificial fixation points. The reader focuses on the highlighted starting letters, and the brain completes the word.
How is Bionic Reading possible?
Do you remember seeing social media posts asking you to stare at a black dot for 30 seconds (or more)? You blink and see an after-image on your wall.
Our brains are skilled at identifying patterns and'seeing' familiar objects, therefore optical illusions are conceivable.
Brain and sight collaborate well. Text comprehension proves it.
Considering evolutionary patterns, humans' understanding skills may be cosmic luck.
Scientists don't know why people can read and write, but they do know what reading does to the brain.
One portion of your brain recognizes words, while another analyzes their meaning. Fixation, saccade, and linguistic transparency/opacity aid.
Let's explain some terms.
-
Fixation is how the eyes move when reading. It's where you look. If the eyes fixate less, a reader can read quicker. [Eye fixation is a physiological process](Eye fixation is a naturally occurring physiological process) impacted by the reader's vocabulary, vision span, and text familiarity.
-
Saccade - Pause and look around. That's a saccade. Rapid eye movements that alter the place of fixation, as reading text or looking around a room. They can happen willingly (when you choose) or instinctively, even when your eyes are fixed.
-
Linguistic transparency and opacity analyze how well a composite word or phrase may be deduced from its constituents.
The Bionic reading website compares these tools.
Text highlights lead the eye. Fixation, saccade, and opacity can transfer visual stimuli to text, changing typeface.
## Final Thoughts on Bionic Reading
I'm excited about how this could influence my long-term assimilation and productivity.
This technology is still in development, with prototypes working on only a few apps. Like any new tech, it will be criticized.
I'll be watching Bionic Reading closely. Comment on it!
Josh Chesler
4 years ago
10 Sneaker Terms Every Beginner Should Know
So you want to get into sneakers? Buying a few sneakers and figuring it out seems simple. Then you miss out on the weekend's instant-sellout releases, so you head to eBay, Twitter, or your local sneaker group to see what's available, since you're probably not ready to pay Flight Club prices just yet.
That's when you're bombarded with new nicknames, abbreviations, and general sneaker slang. It would take months to explain every word and sneaker, so here's a starter kit of ten simple terms to get you started. (Yeah, mostly Jordan. Does anyone really start with Kith or Nike SB?)
10. Colorways
Colorways are a common term in fashion, design, and other visual fields. It's just the product's color scheme. In the case of sneakers, the colorway is often as important as the actual model. Are this year's "Chicago" Air Jordan 1s more durable than last year's "Black/Gum" colorway? Because of their colorway and rarity, the Chicagos are worth roughly three pairs of the Black/Gum kicks.
Pro Tip: A colorway with a well-known nickname is almost always worth more than one without, and the same goes for collaborations.
9. Beaters
A “beater” is a well-worn, likely older model of shoe that has significant wear and tear on it. Rarely sold with the original box or extra laces, beaters rarely sell for much. Unlike most “worn” sneakers, beaters are used for rainy days and the gym. It's exactly what it sounds like, a box full of beaters, and they're a good place to start if you're looking for some cheap old kicks.
Pro Tip: Know which shoes clean up nicely. The shape of lower top sneakers with wider profiles, like SB Dunk Lows and Air Jordan 3s, tends to hold better over time than their higher and narrower cousins.
8. Retro
In the world of Jordan Brand, a “Retro” release is simply a release (or re-release) of a colorway after the shoe model's initial release. For example, the original Air Jordan 7 was released in 1992, but the Bordeaux colorway was re-released in 2011 and recently (2015). An Air Jordan model is released every year, and while half of them are unpopular and unlikely to be Retroed soon, any of them could be re-released whenever Nike and Jordan felt like it.
Pro Tip: Now that the Air Jordan line has been around for so long, the model that tends to be heavily retroed in a year is whichever shoe came out 23 (Michael Jordan’s number during the prime of his career) years ago. The Air Jordan 6 (1991) got new colorways last year, the Air Jordan 7 this year, and more Air Jordan 8s will be released later this year and early next year (1993).
7. PP/Inv
In spite of the fact that eBay takes roughly 10% of the final price, many sneaker buyers and sellers prefer to work directly with PayPal. Selling sneakers for $100 via PayPal invoice or $100 via PayPal friends/family is common on social media. Because no one wants their eBay account suspended for promoting PayPal deals, many eBay sellers will simply state “Message me for a better price.”
Pro Tip: PayPal invoices protect buyers well, but gifting or using Google Wallet does not. Unless you're certain the seller is legitimate, only use invoiced goods/services payments.
6. Yeezy
Kanye West and his sneakers are known as Yeezys. The rapper's first two Yeezys were made by Nike before switching to Adidas. Everything Yeezy-related will be significantly more expensive (and therefore have significantly more fakes made). Not only is the Nike Air Yeezy 2 “Red October” one of the most sought-after sneakers, but the Yeezy influence can be seen everywhere.
Pro Tip: If you're going to buy Yeezys, make sure you buy them from a reputable retailer or reseller. With so many fakes out there, it's not worth spending a grand on something you're not 100% sure is real.
5. GR/Limited
Regardless of how visually repulsive, uncomfortable, and/or impractical a sneaker is, if it’s rare enough, people will still want it. GR stands for General Release, which means they're usually available at retail. Reselling a “Limited Edition” release is costly. Supply and demand, but in this case, the limited supply drives up demand. If you want to get some of the colorways made for rappers, NBA players (Player Exclusive or PE models), and other celebrities, be prepared to pay a premium.
Pro Tip: Limited edition sneakers, like the annual Doernbecher Freestyle sneakers Nike creates with kids from Portland's Doernbecher Children's Hospital, will always be more expensive and limited. Or, you can use automated sneaker-buying software.
4. Grails
A “grail” is a pair of sneakers that someone desires above all others. To obtain their personal grails, people are willing to pay significantly more than the retail price. There doesn't have to be any rhyme or reason why someone chose a specific pair as their grails.
Pro Tip: For those who don't have them, the OG "Bred" or "Royal" Air Jordan 1s, the "Concord" Air Jordan 11s, etc., are all grails.
3. Bred
Anything released in “Bred” (black and red) will sell out quickly. Most resale Air Jordans (and other sneakers) come in the Bred colorway, which is a fan favorite. Bred is a good choice for a first colorway, especially on a solid sneaker silhouette.
Pro Tip: Apart from satisfying the world's hypebeasts, Bred sneakers will probably match a lot of your closet.
2. DS
DS = Deadstock = New. That's it. If something has been worn or tried on, it is no longer DS. Very Near Deadstock (VNDS) Pass As Deadstock It's a cute way of saying your sneakers have been worn but are still in good shape. In the sneaker world, “worn” means they are no longer new, but not too old or beat up.
Pro Tip: Ask for photos of any marks or defects to see what you’re getting before you buy used shoes, also find out if they come with the original box and extra laces, because that can be a sign that they’re in better shape.
1. Fake/Unauthorized
The words “Unauthorized,” “Replica,” “B-grades,” and “Super Perfect” all mean the shoes are fake. It means they aren't made by the actual company, no matter how close or how good the quality. If that's what you want, go ahead and get them. Do not wear them if you do not want the rest of the sneaker world to mock them.
Pro Tip: If you’re not sure if shoes are real or not, do a “Legit Check” on Twitter or Facebook. You'll get dozens of responses in no time.

Amelie Carver
3 years ago
Web3 Needs More Writers to Educate Us About It
WRITE FOR THE WEB3
Why web3’s messaging is lost and how crypto winter is growing growth seeds

People interested in crypto, blockchain, and web3 typically read Bitcoin and Ethereum's white papers. It's a good idea. Documents produced for developers and academia aren't always the ideal resource for beginners.
Given the surge of extremely technical material and the number of fly-by-nights, rug pulls, and other scams, it's little wonder mainstream audiences regard the blockchain sector as an expensive sideshow act.
What's the solution?
Web3 needs more than just builders.
After joining TikTok, I followed Amy Suto of SutoScience. Amy switched from TV scriptwriting to IT copywriting years ago. She concentrates on web3 now. Decentralized autonomous organizations (DAOs) are seeking skilled copywriters for web3.
Amy has found that web3's basics are easy to grasp; you don't need technical knowledge. There's a paradigm shift in knowing the basics; be persistent and patient.
Apple is positioning itself as a data privacy advocate, leveraging web3's zero-trust ethos on data ownership.
Finn Lobsien, who writes about web3 copywriting for the Mirror and Twitter, agrees: acronyms and abstractions won't do.
Web3 preached to the choir. Curious newcomers have only found whitepapers and scams when trying to learn why the community loves it. No wonder people resist education and buy-in.
Due to the gender gap in crypto (Crypto Bro is not just a stereotype), it attracts people singing to the choir or trying to cash in on the next big thing.
Last year, the industry was booming, so writing wasn't necessary. Now that the bear market has returned (for everyone, but especially web3), holding readers' attention is a valuable skill.
White papers and the Web3
Why does web3 rely so much on non-growth content?
Businesses must polish and improve their messaging moving into the 2022 recession. The 2021 tech boom provided such a sense of affluence and (unsustainable) growth that no one needed great marketing material. The market found them.
This was especially true for web3 and the first-time crypto believers. Obviously. If they knew which was good.
White papers help. White papers are highly technical texts that walk a reader through a product's details. How Does a White Paper Help Your Business and That White Paper Guy discuss them.
They're meant for knowledgeable readers. Investors and the technical (academic/developer) community read web3 white papers. White papers are used when a product is extremely technical or difficult to assist an informed reader to a conclusion. Web3 uses them most often for ICOs (initial coin offerings).

White papers for web3 education help newcomers learn about the web3 industry's components. It's like sending a first-grader to the Annotated Oxford English Dictionary to learn to read. It's a reference, not a learning tool, for words.
Newcomers can use platforms that teach the basics. These included Coinbase's Crypto Basics tutorials or Cryptochicks Academy, founded by the mother of Ethereum's inventor to get more women utilizing and working in crypto.
Discord and Web3 communities
Discord communities are web3's opposite. Discord communities involve personal communications and group involvement.
Online audience growth begins with community building. User personas prefer 1000 dedicated admirers over 1 million lukewarm followers, and the language is much more easygoing. Discord groups are renowned for phishing scams, compromised wallets, and incorrect information, especially since the crypto crisis.
White papers and Discord increase industry insularity. White papers are complicated, and Discord has a high risk threshold.
Web3 and writing ads
Copywriting is emotional, but white papers are logical. It uses the brain's quick-decision centers. It's meant to make the reader invest immediately.
Not bad. People think sales are sleazy, but they can spot the poor things.
Ethical copywriting helps you reach the correct audience. People who gain a following on Medium are likely to have copywriting training and a readership (or three) in mind when they publish. Tim Denning and Sinem Günel know how to identify a target audience and make them want to learn more.
In a fast-moving market, copywriting is less about long-form content like sales pages or blogs, but many organizations do. Instead, the copy is concise, individualized, and high-value. Tweets, email marketing, and IM apps (Discord, Telegram, Slack to a lesser extent) keep engagement high.
What does web3's messaging lack? As DAOs add stricter copyrighting, narrative and connecting tales seem to be missing.
Web3 is passionate about constructing the next internet. Now, they can connect their passion to a specific audience so newcomers understand why.