



More on Science
Daniel Clery
3 years ago
Twisted device investigates fusion alternatives
German stellarator revamped to run longer, hotter, compete with tokamaks

Tokamaks have dominated the search for fusion energy for decades. Just as ITER, the world's largest and most expensive tokamak, nears completion in southern France, a smaller, twistier testbed will start up in Germany.
If the 16-meter-wide stellarator can match or outperform similar-size tokamaks, fusion experts may rethink their future. Stellarators can keep their superhot gases stable enough to fuse nuclei and produce energy. They can theoretically run forever, but tokamaks must pause to reset their magnet coils.
The €1 billion German machine, Wendelstein 7-X (W7-X), is already getting "tokamak-like performance" in short runs, claims plasma physicist David Gates, preventing particles and heat from escaping the superhot gas. If W7-X can go long, "it will be ahead," he says. "Stellarators excel" Eindhoven University of Technology theorist Josefine Proll says, "Stellarators are back in the game." A few of startup companies, including one that Gates is leaving Princeton Plasma Physics Laboratory, are developing their own stellarators.
W7-X has been running at the Max Planck Institute for Plasma Physics (IPP) in Greifswald, Germany, since 2015, albeit only at low power and for brief runs. W7-X's developers took it down and replaced all inner walls and fittings with water-cooled equivalents, allowing for longer, hotter runs. The team reported at a W7-X board meeting last week that the revised plasma vessel has no leaks. It's expected to restart later this month to show if it can get plasma to fusion-igniting conditions.

Wendelstein 7-X's water-cooled inner surface allows for longer runs.
HOSAN/IPP
Both stellarators and tokamaks create magnetic gas cages hot enough to melt metal. Microwaves or particle beams heat. Extreme temperatures create a plasma, a seething mix of separated nuclei and electrons, and cause the nuclei to fuse, releasing energy. A fusion power plant would use deuterium and tritium, which react quickly. Non-energy-generating research machines like W7-X avoid tritium and use hydrogen or deuterium instead.
Tokamaks and stellarators use electromagnetic coils to create plasma-confining magnetic fields. A greater field near the hole causes plasma to drift to the reactor's wall.
Tokamaks control drift by circulating plasma around a ring. Streaming creates a magnetic field that twists and stabilizes ionized plasma. Stellarators employ magnetic coils to twist, not plasma. Once plasma physicists got powerful enough supercomputers, they could optimize stellarator magnets to improve plasma confinement.
W7-X is the first large, optimized stellarator with 50 6- ton superconducting coils. Its construction began in the mid-1990s and cost roughly twice the €550 million originally budgeted.
The wait hasn't disappointed researchers. W7-X director Thomas Klinger: "The machine operated immediately." "It's a friendly machine." It did everything we asked." Tokamaks are prone to "instabilities" (plasma bulging or wobbling) or strong "disruptions," sometimes associated to halted plasma flow. IPP theorist Sophia Henneberg believes stellarators don't employ plasma current, which "removes an entire branch" of instabilities.
In early stellarators, the magnetic field geometry drove slower particles to follow banana-shaped orbits until they collided with other particles and leaked energy. Gates believes W7-X's ability to suppress this effect implies its optimization works.
W7-X loses heat through different forms of turbulence, which push particles toward the wall. Theorists have only lately mastered simulating turbulence. W7-X's forthcoming campaign will test simulations and turbulence-fighting techniques.
A stellarator can run constantly, unlike a tokamak, which pulses. W7-X has run 100 seconds—long by tokamak standards—at low power. The device's uncooled microwave and particle heating systems only produced 11.5 megawatts. The update doubles heating power. High temperature, high plasma density, and extensive runs will test stellarators' fusion power potential. Klinger wants to heat ions to 50 million degrees Celsius for 100 seconds. That would make W7-X "a world-class machine," he argues. The team will push for 30 minutes. "We'll move step-by-step," he says.
W7-X's success has inspired VCs to finance entrepreneurs creating commercial stellarators. Startups must simplify magnet production.
Princeton Stellarators, created by Gates and colleagues this year, has $3 million to build a prototype reactor without W7-X's twisted magnet coils. Instead, it will use a mosaic of 1000 HTS square coils on the plasma vessel's outside. By adjusting each coil's magnetic field, operators can change the applied field's form. Gates: "It moves coil complexity to the control system." The company intends to construct a reactor that can fuse cheap, abundant deuterium to produce neutrons for radioisotopes. If successful, the company will build a reactor.
Renaissance Fusion, situated in Grenoble, France, raised €16 million and wants to coat plasma vessel segments in HTS. Using a laser, engineers will burn off superconductor tracks to carve magnet coils. They want to build a meter-long test segment in 2 years and a full prototype by 2027.
Type One Energy in Madison, Wisconsin, won DOE money to bend HTS cables for stellarator magnets. The business carved twisting grooves in metal with computer-controlled etching equipment to coil cables. David Anderson of the University of Wisconsin, Madison, claims advanced manufacturing technology enables the stellarator.
Anderson said W7-X's next phase will boost stellarator work. “Half-hour discharges are steady-state,” he says. “This is a big deal.”

DANIEL CLERY
3 years ago
Can space-based solar power solve Earth's energy problems?
Better technology and lower launch costs revive science-fiction tech.
Airbus engineers showed off sustainable energy's future in Munich last month. They captured sunlight with solar panels, turned it into microwaves, and beamed it into an airplane hangar, where it lighted a city model. The test delivered 2 kW across 36 meters, but it posed a serious question: Should we send enormous satellites to capture solar energy in space? In orbit, free of clouds and nighttime, they could create power 24/7 and send it to Earth.
Airbus engineer Jean-Dominique Coste calls it an engineering problem. “But it’s never been done at [large] scale.”
Proponents of space solar power say the demand for green energy, cheaper space access, and improved technology might change that. Once someone invests commercially, it will grow. Former NASA researcher John Mankins says it might be a trillion-dollar industry.
Myriad uncertainties remain, including whether beaming gigawatts of power to Earth can be done efficiently and without burning birds or people. Concept papers are being replaced with ground and space testing. The European Space Agency (ESA), which supported the Munich demo, will propose ground tests to member nations next month. The U.K. government offered £6 million to evaluate innovations this year. Chinese, Japanese, South Korean, and U.S. agencies are working. NASA policy analyst Nikolai Joseph, author of an upcoming assessment, thinks the conversation's tone has altered. What formerly appeared unattainable may now be a matter of "bringing it all together"
NASA studied space solar power during the mid-1970s fuel crunch. A projected space demonstration trip using 1970s technology would have cost $1 trillion. According to Mankins, the idea is taboo in the agency.
Space and solar power technology have evolved. Photovoltaic (PV) solar cell efficiency has increased 25% over the past decade, Jones claims. Telecoms use microwave transmitters and receivers. Robots designed to repair and refuel spacecraft might create solar panels.
Falling launch costs have boosted the idea. A solar power satellite large enough to replace a nuclear or coal plant would require hundreds of launches. ESA scientist Sanjay Vijendran: "It would require a massive construction complex in orbit."
SpaceX has made the idea more plausible. A SpaceX Falcon 9 rocket costs $2600 per kilogram, less than 5% of what the Space Shuttle did, and the company promised $10 per kilogram for its giant Starship, slated to launch this year. Jones: "It changes the equation." "Economics rules"
Mass production reduces space hardware costs. Satellites are one-offs made with pricey space-rated parts. Mars rover Perseverance cost $2 million per kilogram. SpaceX's Starlink satellites cost less than $1000 per kilogram. This strategy may work for massive space buildings consisting of many identical low-cost components, Mankins has long contended. Low-cost launches and "hypermodularity" make space solar power economical, he claims.
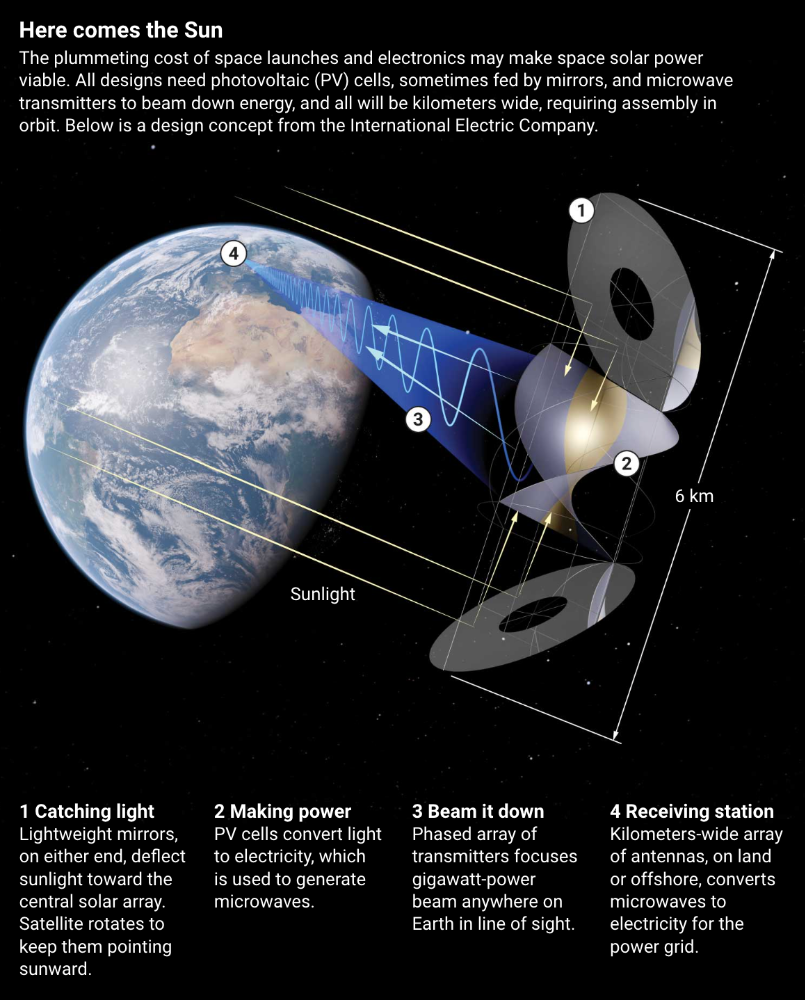
Better engineering can improve economics. Coste says Airbus's Munich trial was 5% efficient, comparing solar input to electricity production. When the Sun shines, ground-based solar arrays perform better. Studies show space solar might compete with existing energy sources on price if it reaches 20% efficiency.
Lighter parts reduce costs. "Sandwich panels" with PV cells on one side, electronics in the middle, and a microwave transmitter on the other could help. Thousands of them build a solar satellite without heavy wiring to move power. In 2020, a team from the U.S. Naval Research Laboratory (NRL) flew on the Air Force's X-37B space plane.
NRL project head Paul Jaffe said the satellite is still providing data. The panel converts solar power into microwaves at 8% efficiency, but not to Earth. The Air Force expects to test a beaming sandwich panel next year. MIT will launch its prototype panel with SpaceX in December.
As a satellite orbits, the PV side of sandwich panels sometimes faces away from the Sun since the microwave side must always face Earth. To maintain 24-hour power, a satellite needs mirrors to keep that side illuminated and focus light on the PV. In a 2012 NASA study by Mankins, a bowl-shaped device with thousands of thin-film mirrors focuses light onto the PV array.
International Electric Company's Ian Cash has a new strategy. His proposed satellite uses enormous, fixed mirrors to redirect light onto a PV and microwave array while the structure spins (see graphic, above). 1 billion minuscule perpendicular antennas act as a "phased array" to electronically guide the beam toward Earth, regardless of the satellite's orientation. This design, argues Cash, is "the most competitive economically"
If a space-based power plant ever flies, its power must be delivered securely and efficiently. Jaffe's team at NRL just beamed 1.6 kW over 1 km, and teams in Japan, China, and South Korea have comparable attempts. Transmitters and receivers lose half their input power. Vijendran says space solar beaming needs 75% efficiency, "preferably 90%."
Beaming gigawatts through the atmosphere demands testing. Most designs aim to produce a beam kilometers wide so every ship, plane, human, or bird that strays into it only receives a tiny—hopefully harmless—portion of the 2-gigawatt transmission. Receiving antennas are cheap to build but require a lot of land, adds Jones. You could grow crops under them or place them offshore.
Europe's public agencies currently prioritize space solar power. Jones: "There's a devotion you don't see in the U.S." ESA commissioned two solar cost/benefit studies last year. Vijendran claims it might match ground-based renewables' cost. Even at a higher price, equivalent to nuclear, its 24/7 availability would make it competitive.
ESA will urge member states in November to fund a technical assessment. If the news is good, the agency will plan for 2025. With €15 billion to €20 billion, ESA may launch a megawatt-scale demonstration facility by 2030 and a gigawatt-scale facility by 2040. "Moonshot"

Tomas Pueyo
3 years ago
Soon, a Starship Will Transform Humanity
SpaceX's Starship.

Launched last week.
Four minutes in:
SpaceX will succeed. When it does, its massiveness will matter.
Its payload will revolutionize space economics.
Civilization will shift.
We don't yet understand how this will affect space and Earth culture. Grab it.
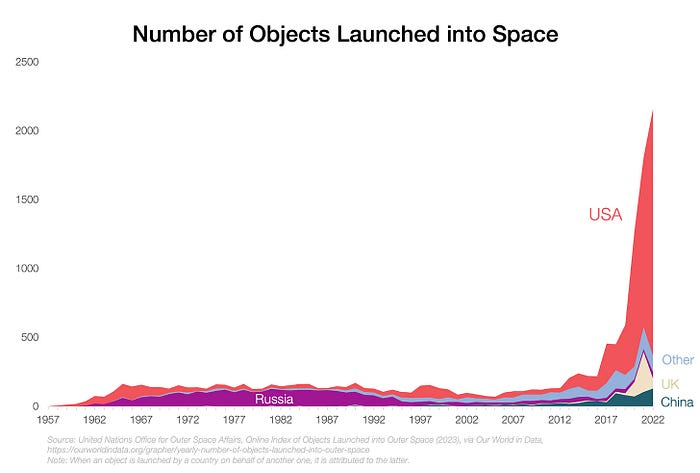
The Cost of Space Transportation Has Decreased Exponentially
Space launches have increased dramatically in recent years.
We mostly send items to LEO, the green area below:
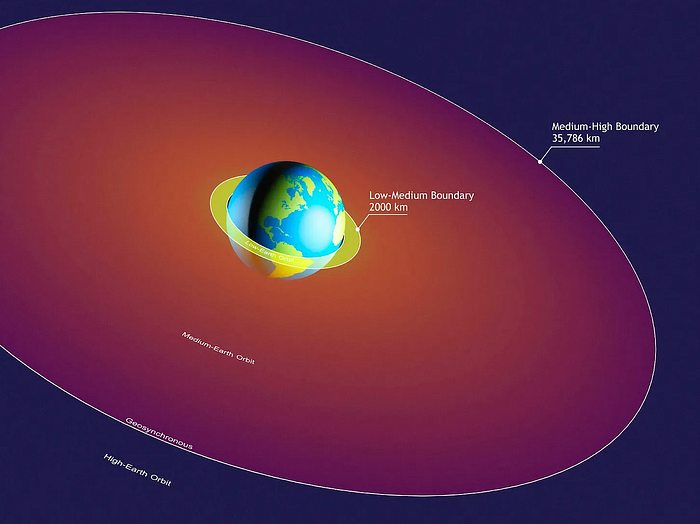
SpaceX's reusable rockets can send these things to LEO. Each may launch dozens of payloads into space.
With all these launches, we're sending more than simply things to space. Volume and mass. Since the 1980s, launching a kilogram of payload to LEO has become cheaper:
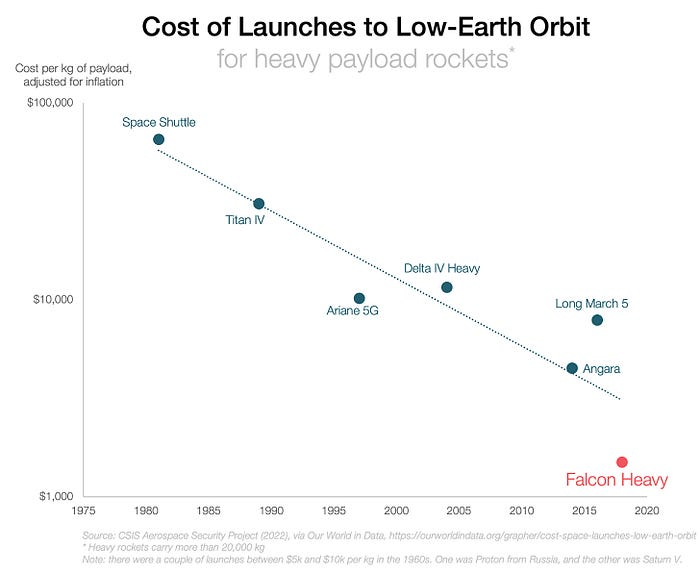
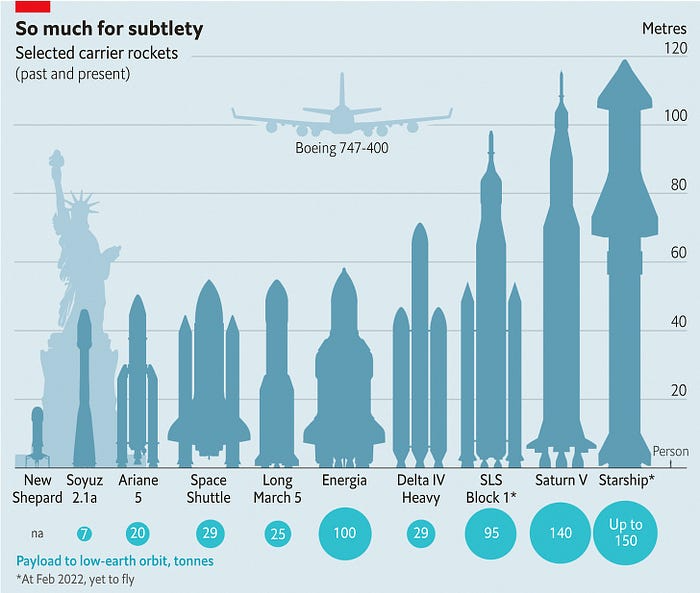
One kilogram in a large rocket cost over $75,000 in the 1980s. Carrying one astronaut cost nearly $5M! Falcon Heavy's $1,500/kg price is 50 times lower. SpaceX's larger, reusable rockets are amazing.
SpaceX's Starship rocket will continue. It can carry over 100 tons to LEO, 50% more than the current Falcon heavy. Thousands of launches per year. Elon Musk predicts Falcon Heavy's $1,500/kg cost will plummet to $100 in 23 years.
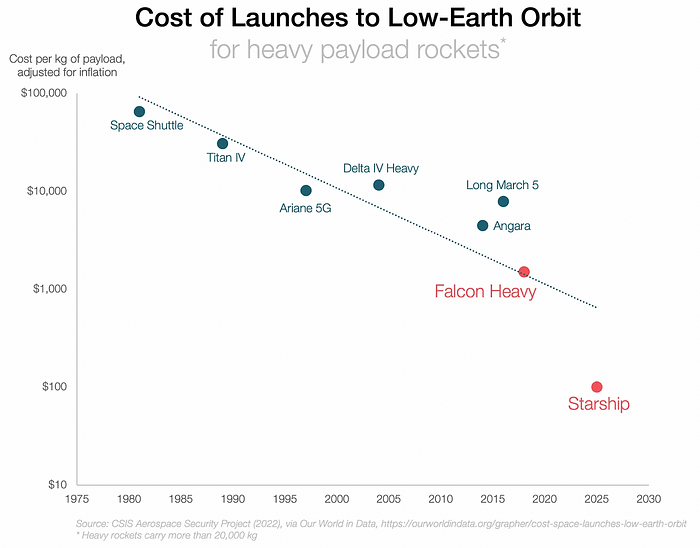
In context:
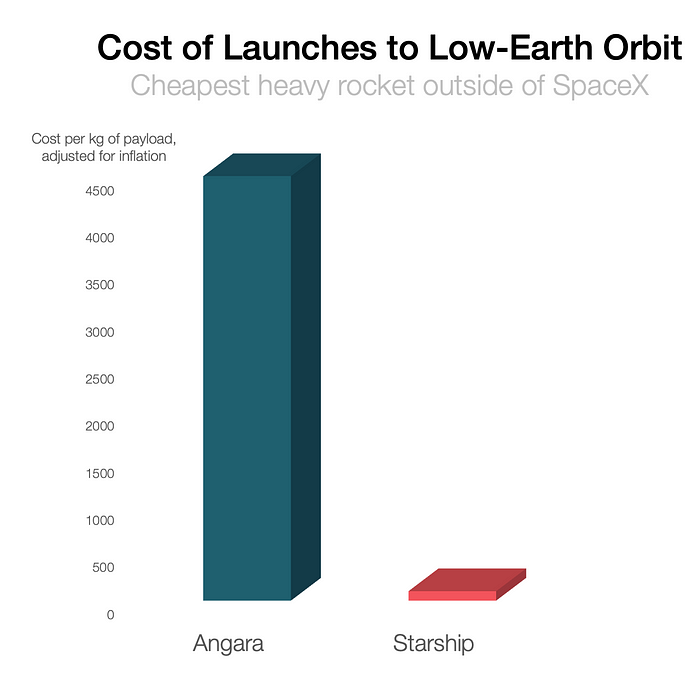
People underestimate this.
2. The Benefits of Affordable Transportation
Compare Earth's transportation costs:
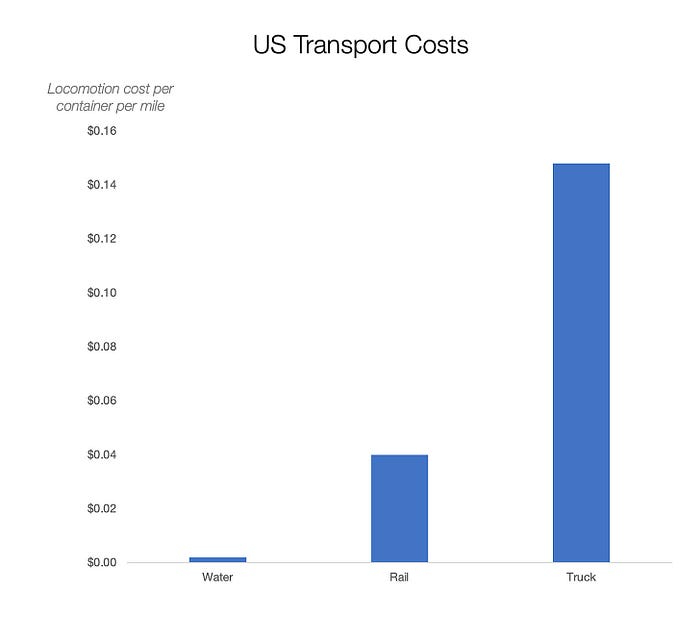
It's no surprise that the US and Northern Europe are the wealthiest and have the most navigable interior waterways.
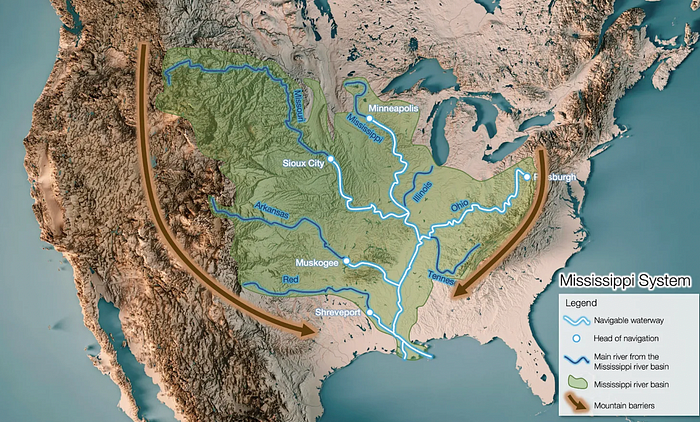
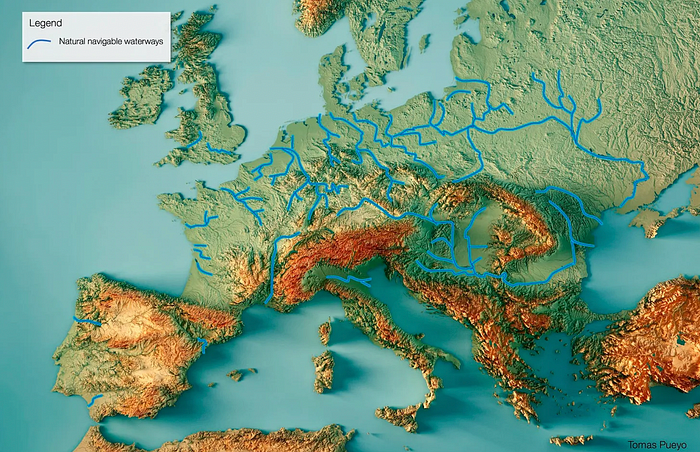
So what? since sea transportation is cheaper than land. Inland waterways are even better than sea transportation since weather is less of an issue, currents can be controlled, and rivers serve two banks instead of one for coastal transportation.
In France, because population density follows river systems, rivers are valuable. Cheap transportation brought people and money to rivers, especially their confluences.
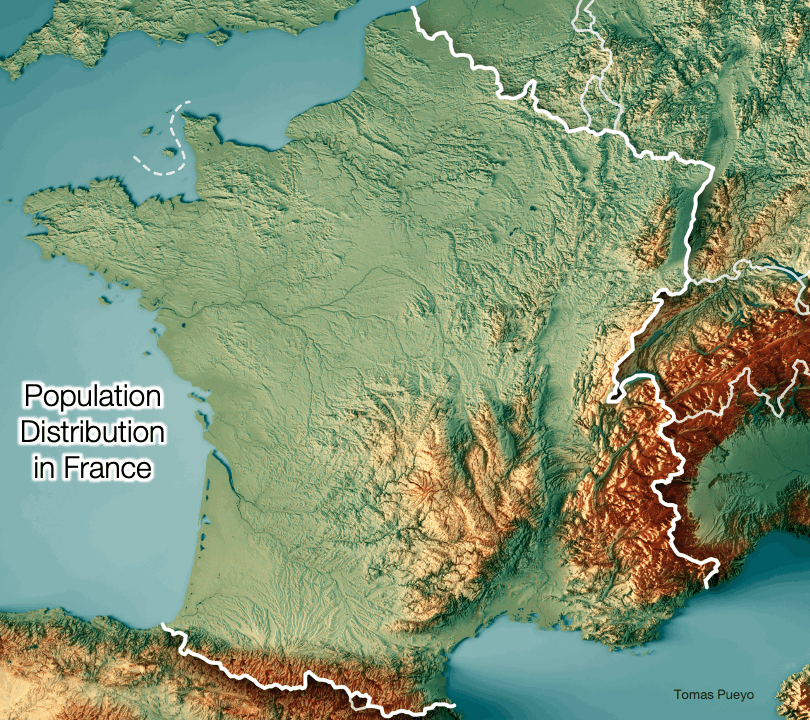
How come? Why were humans surrounding rivers?
Imagine selling meat for $10 per kilogram. Transporting one kg one kilometer costs $1. Your margin decreases $1 each kilometer. You can only ship 10 kilometers. For example, you can only trade with four cities:
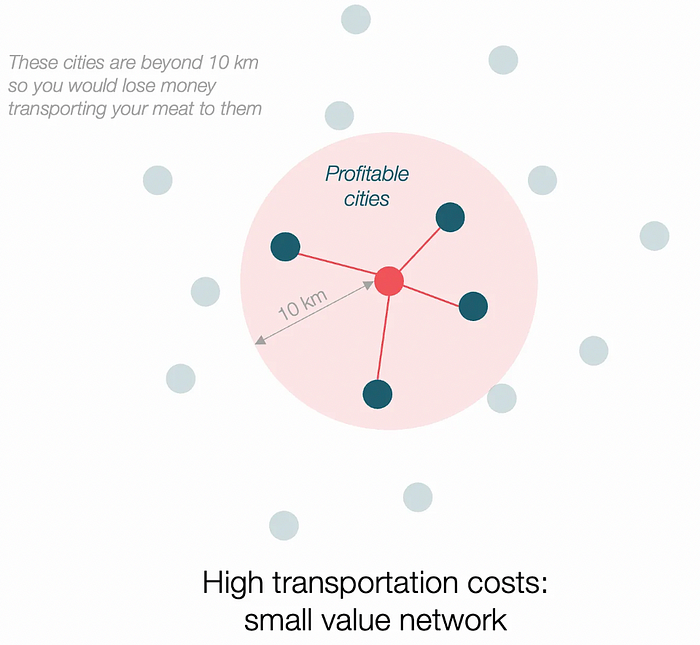
If instead, your cost of transportation is half, what happens? It costs you $0.5 per km. You now have higher margins with each city you traded with. More importantly, you can reach 20-km markets.
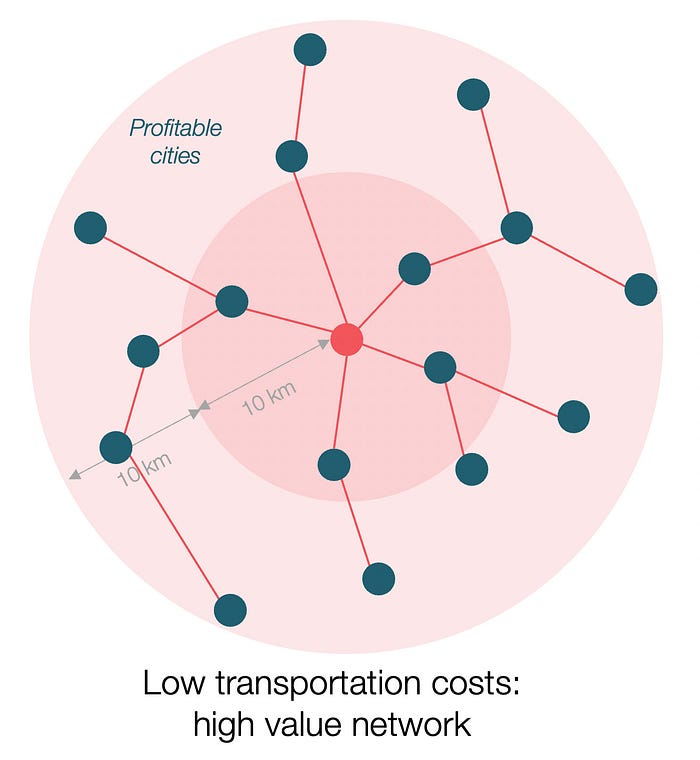
However, 2x distance 4x surface! You can now trade with sixteen cities instead of four! Metcalfe's law states that a network's value increases with its nodes squared. Since now sixteen cities can connect to yours. Each city now has sixteen connections! They get affluent and can afford more meat.
Rivers lower travel costs, connecting many cities, which can trade more, get wealthy, and buy more.
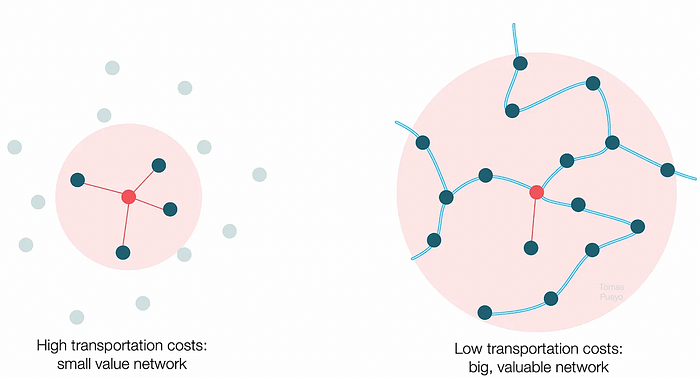
The right network is worth at least an order of magnitude more than the left! The cheaper the transport, the more trade at a lower cost, the more income generated, the more that wealth can be reinvested in better canals, bridges, and roads, and the wealth grows even more.
Throughout history. Rome was established around cheap Mediterranean transit and preoccupied with cutting overland transportation costs with their famous roadways. Communications restricted their empire.
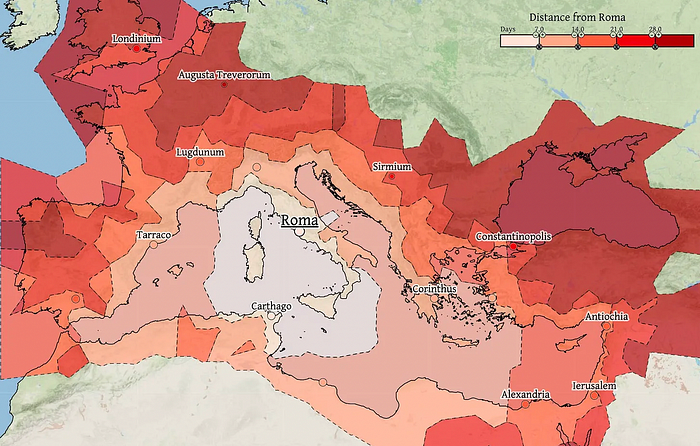
The Egyptians lived around the Nile, the Vikings around the North Sea, early Japan around the Seto Inland Sea, and China started canals in the 5th century BC.
Transportation costs shaped empires.Starship is lowering new-world transit expenses. What's possible?
3. Change Organizations, Change Companies, Change the World
Starship is a conveyor belt to LEO. A new world of opportunity opens up as transportation prices drop 100x in a decade.
Satellite engineers have spent decades shedding milligrams. Weight influenced every decision: pricing structure, volumes to be sent, material selections, power sources, thermal protection, guiding, navigation, and control software. Weight was everything in the mission. To pack as much science into every millimeter, NASA missions had to be miniaturized. Engineers were indoctrinated against mass.
No way.
Starship is not constrained by any space mission, robotic or crewed.
Starship obliterates the mass constraint and every last vestige of cultural baggage it has gouged into the minds of spacecraft designers. A dollar spent on mass optimization no longer buys a dollar saved on launch cost. It buys nothing. It is time to raise the scope of our ambition and think much bigger. — Casey Handmer, Starship is still not understood
A Tesla Roadster in space makes more sense.

It went beyond bad PR. It told the industry: Did you care about every microgram? No more. My rockets are big enough to send a Tesla without noticing. Industry watchers should have noticed.
Most didn’t. Artemis is a global mission to send astronauts to the Moon and build a base. Artemis uses disposable Space Launch System rockets. Instead of sending two or three dinky 10-ton crew habitats over the next decade, Starship might deliver 100x as much cargo and create a base for 1,000 astronauts in a year or two. Why not? Because Artemis remains in a pre-Starship paradigm where each kilogram costs a million dollars and we must aggressively descope our objective.

Space agencies can deliver 100x more payload to space for the same budget with 100x lower costs and 100x higher transportation volumes. How can space economy saturate this new supply?
Before Starship, NASA supplied heavy equipment for Moon base construction. After Starship, Caterpillar and Deere may space-qualify their products with little alterations. Instead than waiting decades for NASA engineers to catch up, we could send people to build a space outpost with John Deere equipment in a few years.
History is littered with the wreckage of former industrial titans that underestimated the impact of new technology and overestimated their ability to adapt: Blockbuster, Motorola, Kodak, Nokia, RIM, Xerox, Yahoo, IBM, Atari, Sears, Hitachi, Polaroid, Toshiba, HP, Palm, Sony, PanAm, Sega, Netscape, Compaq, GM… — Casey Handmer, Starship is still not understood
Everyone saw it coming, but senior management failed to realize that adaption would involve moving beyond their established business practice. Others will if they don't.
4. The Starship Possibilities
It's Starlink.

SpaceX invented affordable cargo space and grasped its implications first. How can we use all this inexpensive cargo nobody knows how to use?
Satellite communications seemed like the best way to capitalize on it. They tried. Starlink, designed by SpaceX, provides fast, dependable Internet worldwide. Beaming information down is often cheaper than cable. Already profitable.
Starlink is one use for all this cheap cargo space. Many more. The longer firms ignore the opportunity, the more SpaceX will acquire.
What are these chances?
Satellite imagery is outdated and lacks detail. We can improve greatly. Synthetic aperture radar can take beautiful shots like this:

Have you ever used Google Maps and thought, "I want to see this in more detail"? What if I could view Earth live? What if we could livestream an infrared image of Earth?

We could launch hundreds of satellites with such mind-blowing visual precision of the Earth that we would dramatically improve the accuracy of our meteorological models; our agriculture; where crime is happening; where poachers are operating in the savannah; climate change; and who is moving military personnel where. Is that useful?
What if we could see Earth in real time? That affects businesses? That changes society?
You might also like

Jenn Leach
3 years ago
I created a faceless TikTok account. Six months later.
Follower count, earnings, and more

I created my 7th TikTok account six months ago. TikTok's great. I've developed accounts for Amazon products, content creators/brand deals education, website flipping, and more.
Introverted or shy people use faceless TikTok accounts.
Maybe they don't want millions of people to see their face online, or they want to remain anonymous so relatives and friends can't locate them.
Going faceless on TikTok can help you grow a following, communicate your message, and make money online.
Here are 6 steps I took to turn my Tik Tok account into a $60,000/year side gig.
From nothing to $60K in 6 months
It's clickbait, but it’s true. Here’s what I did to get here.
Quick context:
I've used social media before. I've spent years as a social creator and brand.
I've built Instagram, TikTok, and YouTube accounts to nearly 100K.
How I did it
First, select a niche.
If you can focus on one genre on TikTok, you'll have a better chance of success, however lifestyle creators do well too.
Niching down is easier, in my opinion.
Examples:
Travel
Food
Kids
Earning cash
Finance
You can narrow these niches if you like.
During the pandemic, a travel blogger focused on Texas-only tourism and gained 1 million subscribers.
Couponing might be a finance specialization.
One of my finance TikTok accounts gives credit tips and grants and has 23K followers.
Tons of ways you can get more specific.
Consider how you'll monetize your TikTok account. I saw many enormous TikTok accounts that lose money.
Why?
They can't monetize their niche. Not impossible to commercialize, but tough enough to inhibit action.
First, determine your goal.
In this first step, consider what your end goal is.
Are you trying to promote your digital products or social media management services?
You want brand deals or e-commerce sales.
This will affect your TikTok specialty.
This is the first step to a TikTok side gig.
Step 2: Pick a content style
Next, you want to decide on your content style.
Do you do voiceover and screenshots?
You'll demonstrate a product?
Will you faceless vlog?
Step 3: Look at the competition
Find anonymous accounts and analyze what content works, where they thrive, what their audience wants, etc.
This can help you make better content.
Like the skyscraper method for TikTok.
Step 4: Create a content strategy.
Your content plan is where you sit down and decide:
How many videos will you produce each day or each week?
Which links will you highlight in your biography?
What amount of time can you commit to this project?
You may schedule when to post videos on a calendar. Make videos.
5. Create videos.
No video gear needed.
Using a phone is OK, and I think it's preferable than posting drafts from a computer or phone.
TikTok prefers genuine material.
Use their app, tools, filters, and music to make videos.
And imperfection is preferable. Tik okers like to see videos made in a bedroom, not a film studio.
Make sense?
When making videos, remember this.
I personally use my phone and tablet.
Step 6: Monetize
Lastly, it’s time to monetize How will you make money? You decided this in step 1.
Time to act!
For brand agreements
Include your email in the bio.
Share several sites and use a beacons link in your bio.
Make cold calls to your favorite companies to get them to join you in a TikTok campaign.
For e-commerce
Include a link to your store's or a product's page in your bio.
For client work
Include your email in the bio.
Use a beacons link to showcase your personal website, portfolio, and other resources.
For affiliate marketing
Include affiliate product links in your bio.
Join the Amazon Influencer program and provide a link to your storefront in your bio.
$60,000 per year from Tik Tok?
Yes, and some creators make much more.
Tori Dunlap (herfirst100K) makes $100,000/month on TikTok.
My TikTok adventure took 6 months, but by month 2 I was making $1,000/month (or $12K/year).
By year's end, I want this account to earn $100K/year.
Imagine if my 7 TikTok accounts made $100K/year.
7 Tik Tok accounts X $100K/yr = $700,000/year

nft now
4 years ago
Instagram NFTs Are Here… How does this affect artists?
Instagram (IG) is officially joining NFT. With the debut of new in-app NFT functionalities, influential producers can interact with blockchain tech on the social media platform.
Meta unveiled intentions for an Instagram NFT marketplace in March, but these latest capabilities focus more on content sharing than commerce. And why shouldn’t they? IG's entry into the NFT market is overdue, given that Twitter and Discord are NFT hotspots.
The NFT marketplace/Web3 social media race has continued to expand, with the expected Coinbase NFT Beta now live and blazing a trail through the NFT ecosystem.
IG's focus is on visual art. It's unlike any NFT marketplace or platform. IG NFTs and artists: what's the deal? Let’s take a look.
What are Instagram’s NFT features anyways?
As said, not everyone has Instagram's new features. 16 artists, NFT makers, and collectors can now post NFTs on IG by integrating third-party digital wallets (like Rainbow or MetaMask) in-app. IG doesn't charge to publish or share digital collectibles.
NFTs displayed on the app have a "shimmer" aesthetic effect. NFT posts also have a "digital collectable" badge that lists metadata such as the creator and/or owner, the platform it was created on, a brief description, and a blockchain identification.
Meta's social media NFTs have launched on Instagram, but the company is also preparing to roll out digital collectibles on Facebook, with more on the way for IG. Currently, only Ethereum and Polygon are supported, but Flow and Solana will be added soon.
How will artists use these new features?
Artists are publishing NFTs they developed or own on IG by linking third-party digital wallets. These features have no NFT trading aspects built-in, but are aimed to let authors share NFTs with IG audiences.
Creators, like IG-native aerial/street photographer Natalie Amrossi (@misshattan), are discovering novel uses for IG NFTs.
Amrossi chose to not only upload his own NFTs but also encourage other artists in the field. "That's the beauty of connecting your wallet and sharing NFTs. It's not just what you make, but also what you accumulate."
Amrossi has been producing and posting Instagram art for years. With IG's NFT features, she can understand Instagram's importance in supporting artists.
Web2 offered Amrossi the tools to become an artist and make a life. "Before 'influencer' existed, I was just making art. Instagram helped me reach so many individuals and brands, giving me a living.
Even artists without millions of viewers are encouraged to share NFTs on IG. Wilson, a relatively new name in the NFT space, seems to have already gone above and beyond the scope of these new IG features. By releasing "Losing My Mind" via IG NFT posts, she has evaded the lack of IG NFT commerce by using her network to market her multi-piece collection.
"'Losing My Mind' is a long-running photo series. Wilson was preparing to release it as NFTs before IG approached him, so it was a perfect match.
Wilson says the series is about Black feminine figures and media depiction. Respectable effort, given POC artists have been underrepresented in NFT so far.
“Over the past year, I've had mental health concerns that made my emotions so severe it was impossible to function in daily life, therefore that prompted this photo series. Every Wednesday and Friday for three weeks, I'll release a new Meta photo for sale.
Wilson hopes these new IG capabilities will help develop a connection between the NFT community and other internet subcultures that thrive on Instagram.
“NFTs can look scary as an outsider, but seeing them on your daily IG feed makes it less foreign,” adds Wilson. I think Instagram might become a hub for NFT aficionados, making them more accessible to artists and collectors.
What does it all mean for the NFT space?
Meta's NFT and metaverse activities will continue to impact Instagram's NFT ecosystem. Many think it will be for the better, as IG NFT frauds are another problem hurting the NFT industry.
IG's new NFT features seem similar to Twitter's PFP NFT verifications, but Instagram's tools should help cut down on scams as users can now verify the creation and ownership of whole NFT collections included in IG posts.
Given the number of visual artists and NFT creators on IG, it might become another hub for NFT fans, as Wilson noted. If this happens, it raises questions about Instagram success. Will artists be incentivized to distribute NFTs? Or will those with a large fanbase dominate?
Elise Swopes (@swopes) believes these new features should benefit smaller artists. Swopes was one of the first profiles placed to Instagram's original suggested user list in 2012.
Swopes says she wants IG to be a magnet for discovery and understands the value of NFT artists and producers.
"I'd love to see IG become a focus of discovery for everyone, not just the Beeples and Apes and PFPs. That's terrific for them, but [IG NFT features] are more about using new technology to promote emerging artists, Swopes added.
“Especially music artists. It's everywhere. Dancers, writers, painters, sculptors, musicians. My element isn't just for digital artists; it can be anything. I'm delighted to witness people's creativity."
Swopes, Wilson, and Amrossi all believe IG's new features can help smaller artists. It remains to be seen how these new features will effect the NFT ecosystem once unlocked for the rest of the IG NFT community, but we will likely see more social media NFT integrations in the months and years ahead.
Read the full article here

Duane Michael
3 years ago
Don't Fall Behind: 7 Subjects You Must Understand to Keep Up with Technology
As technology develops, you should stay up to date

You don't want to fall behind, do you? This post covers 7 tech-related things you should know.
You'll learn how to operate your computer (and other electronic devices) like an expert and how to leverage the Internet and social media to create your brand and business. Read on to stay relevant in today's tech-driven environment.
You must learn how to code.
Future-language is coding. It's how we and computers talk. Learn coding to keep ahead.
Try Codecademy or Code School. There are also numerous free courses like Coursera or Udacity, but they take a long time and aren't necessarily self-paced, so it can be challenging to find the time.
Artificial intelligence (AI) will transform all jobs.
Our skillsets must adapt with technology. AI is a must-know topic. AI will revolutionize every employment due to advances in machine learning.
Here are seven AI subjects you must know.
What is artificial intelligence?
How does artificial intelligence work?
What are some examples of AI applications?
How can I use artificial intelligence in my day-to-day life?
What jobs have a high chance of being replaced by artificial intelligence and how can I prepare for this?
Can machines replace humans? What would happen if they did?
How can we manage the social impact of artificial intelligence and automation on human society and individual people?
Blockchain Is Changing the Future
Few of us know how Bitcoin and blockchain technology function or what impact they will have on our lives. Blockchain offers safe, transparent, tamper-proof transactions.
It may alter everything from business to voting. Seven must-know blockchain topics:
Describe blockchain.
How does the blockchain function?
What advantages does blockchain offer?
What possible uses for blockchain are there?
What are the dangers of blockchain technology?
What are my options for using blockchain technology?
What does blockchain technology's future hold?
Cryptocurrencies are here to stay
Cryptocurrencies employ cryptography to safeguard transactions and manage unit creation. Decentralized cryptocurrencies aren't controlled by governments or financial institutions.

Bitcoin, the first cryptocurrency, was launched in 2009. Cryptocurrencies can be bought and sold on decentralized exchanges.
Bitcoin is here to stay.
Bitcoin isn't a fad, despite what some say. Since 2009, Bitcoin's popularity has grown. Bitcoin is worth learning about now. Since 2009, Bitcoin has developed steadily.
With other cryptocurrencies emerging, many people are wondering if Bitcoin still has a bright future. Curiosity is natural. Millions of individuals hope their Bitcoin investments will pay off since they're popular now.
Thankfully, they will. Bitcoin is still running strong a decade after its birth. Here's why.
The Internet of Things (IoT) is no longer just a trendy term.
IoT consists of internet-connected physical items. These items can share data. IoT is young but developing fast.
20 billion IoT-connected devices are expected by 2023. So much data! All IT teams must keep up with quickly expanding technologies. Four must-know IoT topics:
Recognize the fundamentals: Priorities first! Before diving into more technical lingo, you should have a fundamental understanding of what an IoT system is. Before exploring how something works, it's crucial to understand what you're working with.
Recognize Security: Security does not stand still, even as technology advances at a dizzying pace. As IT professionals, it is our duty to be aware of the ways in which our systems are susceptible to intrusion and to ensure that the necessary precautions are taken to protect them.
Be able to discuss cloud computing: The cloud has seen various modifications over the past several years once again. The use of cloud computing is also continually changing. Knowing what kind of cloud computing your firm or clients utilize will enable you to make the appropriate recommendations.
Bring Your Own Device (BYOD)/Mobile Device Management (MDM) is a topic worth discussing (MDM). The ability of BYOD and MDM rules to lower expenses while boosting productivity among employees who use these services responsibly is a major factor in their continued growth in popularity.
IoT Security is key
As more gadgets connect, they must be secure. IoT security includes securing devices and encrypting data. Seven IoT security must-knows:
fundamental security ideas
Authorization and identification
Cryptography
electronic certificates
electronic signatures
Private key encryption
Public key encryption
Final Thoughts
With so much going on in the globe, it can be hard to stay up with technology. We've produced a list of seven tech must-knows.